

ComicEnhancerPro 系列教程 附录七:CEP处理之弯曲页面自动展平
作者:马健
邮箱:stronghorse_mj@hotmail.com
主页:http://www.comicer.com/stronghorse/
发布:2020.12.31
附录七:CEP处理之弯曲页面自动展平
CEP从v5.00开始,在“书籍处理”界面中提供弯曲页面自动展平(dewarping)功能,可以把在没有用压板把书页压平情况下拍摄的弯曲页面(曲面页)自动展平。
目前我见过的弯曲页面自动展平思路大概可以归类为三类:基于文本行、基于激光线、基于模型。
一、基于文本行的曲面页展平
这种思路的核心是在页面上找文本行,然后把弯曲的文本行拉直,看起来就是把页面展平了。图文并茂的说明可以看开源项目leptonica的文档,具体实现可以看leptonica的源代码:
www.leptonica.org/dewarping.html
国内的一些简单开源资源:
http://read.pudn.com/downloads216/sourcecode/windows/bitmap/1018996/ImageDewarp/Form1.cs__.htm
https://github.com/syOpt/Dewarp
从逻辑上说这种方法的实用性不是太高,因为很多页面除了文本行还有其他内容,很容易出现误判,leptonica的文档在最后也对此有所说明。但确实为以后的工作打下了良好的基础,如后面基于模型的展平方法在做文本行跟踪时,就可以参考leptonica的实现。
二、基于激光线的曲面页展平
成者科技等公司推出的商业版成册书籍扫描仪就在主推这种方法:扫描时不需要用压板把书籍压平,所以厚书就不需要拆开来扫,只需直接把成册的书籍放在底座上摊开拍照即可。每次在内部连拍两张,其中 第一张拍摄时从顶上照射三道线性激光到书页上,通过对这三道激光线在弯曲书页上形成的曲线进行解析,可以建立从曲面到平面的映射方程,即可把第二张无激光线的照片从曲面映射成平面并输出。
具体操作过程及展平效果的样张见成者科技官网:
https://www.czur.com/cn/
具体求解过程可以看成者科技申请的发明专利《扫描图像的无标定展平方法》,申请号201710774266.5,所有申请资料依法公开。
这种方法的优点是:展平效果与页面内容无关。即曲面模型的建立只依赖于外部照射在页面上的激光线,而不管页面内容究竟是文本还是插图。
但从我在展会现场实际试用成者科技的扫描仪情况看,我认为这种方法也不是没有缺点:
- 不知道是为了适应不同开本的书籍,还是因为工艺问题,我见到的成者扫描仪上的三道激光线距离并不远,因此在扫描开本大一点的书籍时,上下两条激光线在书页上的弯曲程度远远不能代表页面上下边界处文本行的弯曲程度,只能代表页面中间部分的文本行弯曲程度。但实际看一下成者官网上提供的官方样张即可知道,上下边界处文本行比中间部分的文本行弯曲得更厉害。这种情况下难免会有部分文本行矫不直。
- 对操作者的姿势有要求:在中间那条激光线正好穿过书籍中央,并与中缝垂直情况下,自动展平效果最好,其他姿势都会造成展平效果下降。
当然对DIY扫描仪来说还有其他缺点:贵,而且安装麻烦。所以在众多的DIY扫描仪方案里我没有见到采用激光线展平的。
三、基于模型的曲面页展平
基于模型的页面展平原理可以看这里,其中第二个链接还是开源的,不过是基于python:
CiteSeerX — A model-based book dewarping method using text line detection (psu.edu)
Page dewarping (mzucker.github.io)
如果原文实在看不下去,可以看我简单粗暴解释一下:展平时根据从页面中提取的特征,在弯曲页面上建立坐标系,并求解与展平后的正常坐标系之间的映射关系(模型),然后按照求解出来的映射关系进行映射(展平)。其中的关键技术包括:
- 图像去噪:从所拍摄的图像中,去除各种干扰,突出页面特征。以从第1篇论文中引用的图1为例,就要去掉黑边,从而突出页面边界曲线、文本行等能够体现页面弯曲程度的特征量。
- 特征提取:包括竖向特征即左右边界(图1中蓝色竖线),及横向特征,包括文本行(图1中横向红线、绿线)、页边界曲线(图中未标示)等,最终选取最具代表性的上、下两条横向特征(曲线),及左、右两条竖向特征(直线)建立映射模型。 图1是上面那篇论文的插图。
- 插值映射:按照所建立的模型进行展平,并用插值算法进行平滑。

图1
从关键技术中可以分析出这种思路的局限性:
- 如果横向特征为文本行,则只能用于横排文本,竖排文本没戏,页面中不含文本行(插图页)或文本行不够长(诗歌)也没戏。
- 如果横向特征为页边界(上下边界)曲线,则不受文本行影响,但要求页边界清晰、完整。如果页面是深色插图页,背景也是深色的,则拍出照片后连人眼都看不出页边界在哪里,自然也就提取不了横向特征。但从成者提供的样张看,激光线这时仍可成功建模,因此这种思路的普适性不如激光线,但胜在便宜,所以是DIY扫描仪的首选。
这种方法与激光线方法的异同:
- 从成者的专利文献看,激光线展平其实也是基于模型展平,只不过大家建模方法不一样。
- 激光线展平建模只需要针对激光线提取特征,技术实现难度、抗干扰性都会好一些。而针对文本行、页边界等提取特征,在抗干扰性性上会很吃亏。
回到技术本身。上面给的论文和python项目都不容易看到中间结果,所以下面结合ScanTailor(ST)、ScanTailor-Experimental(STE)对建模过程进行详细说明。ST、STE、CEP的页面展平其实都是采用这种思路,但在提取特征上有所不同。
1、横向特征提取之文本行
ST、STE的横向特征都包括文本行、页边界,但在文本行追踪器(Text Line Tracer)却是不同。点选“Tools -> Debug”菜单可以看到展平过程的中间结果,更便于比较:
- ST的页面展平放在Output,前面已经对页面进行了分页、纠斜、裁边等,得到的是只含版心的部分,可以采用与leptonica类似的技术对文本行进行跟踪, 跟踪结果如图2所示。图2~图5所处理的样张可从我的网盘下载,“DIY零边距扫描仪 > 无压板方案 > 样张 > 800万像素 > 16开单页_彩色_手持.rar”
- STE的页面展平放在几何矫正(Geometric Distortions)里,前面只经过分页,所以要先采用一大堆眼花缭乱的处理(说实话我完全看不懂)找到页面内容部分,然后对这里面的文本行进行跟踪, 结果参见图3。
- 在用参数化样条曲线对跟踪到的文本行进行拟合时,ST除了左右端点外,其他点并不要求点点通过,所以拟合出来的曲线比较平滑,参见图4。而STE对所有点均要求点点通过,所以拟合出来的曲线看起来不是那么顺溜,参见图5。导致的结果就是如果最终特征选取时刚好选到了不那么顺溜的曲线,则页面用STE展平后,文本行可能是大波浪。
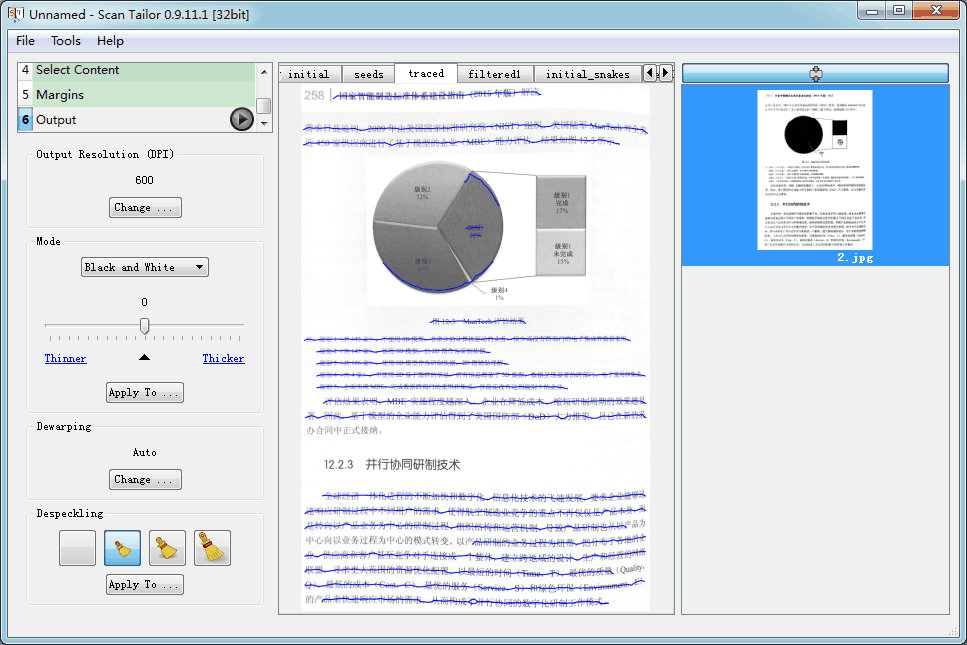
图2
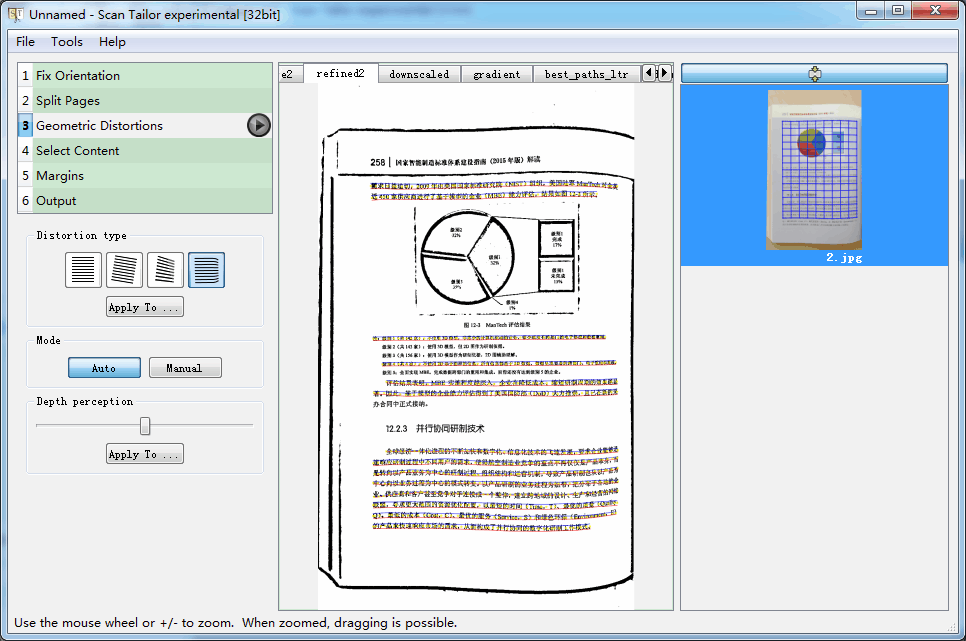
图3

图4

图5
CEP的页面展平和STE差不多,也放在分页之后、裁边之前,所以在展平之前先用与mzucker相似的方法获得版心,然后用类似leptonica的技术对文本行进行跟踪 ,再对跟踪结果进行曲线拟合、建模。但在曲线拟合时,没敢像STE那样要求点点通过,只是像ST那样要求左右端点通过即可。另外不论是ST还是STE,在曲线拟合时初始控制点都只有5个,简单是简单,但在靠近中缝的曲率较大处拟合误差也较大。CEP则取初始控制点为8个,误差更小。
另外在做文本跟踪的时候,很容易受横向光照影响:在跟踪文本行之前要先对图像二值化,但如果页面上存在横向光照不均匀,例如左半边黑、右半边亮,或者两边黑、中间亮,则在二值化后可能会在亮区造成文本行中断,影响文本行跟踪效果。所以在CEP中设置了不均匀、一般、均匀三种选项,内部对应三组经验值,用于解决横向光照不均匀问题。横向光照不均匀的例子参见图6,该页就是中间亮、两边黑,所以“光照”必须选“不均匀”。
图6
2、横向特征提取之页边界
ST、STE的上下页边界曲线跟踪器(Top Bottom Edge Tracer)代码是一样的,都存在以下问题:
- 鲁棒性不佳,在页面与背景反差不足时,容易漏找边界曲线。例如图4、图5中,都只跟踪到了下边界曲线,没有跟踪到上边界曲线。
- 边界曲线的跟踪并不是一个独立的过程,而是严重依赖于纵向特征提取。即要先提取出纵向特征(图4、图5中的两条蓝色竖线),然后才能在这两条竖线框定的范围内对边界曲线进行跟踪。如果竖向特征提取失败,就不能进行页边界跟踪。而ST、STE的竖向特征提取都在文本行跟踪过程中完成。
所以在ST、STE中都没有把边界曲线单独拿出来说事,而是作为文本行跟踪的一种补充,有当然更好,没有也无所谓。某些魔改版,如scantailor-featured、scantailor-advanced也曾试图把边界(Marginal)单独作为一个展平选项,但在基本模型没有突破的情况下,只能是然并卵。
这种佛系的态度在碰到没有文本行,或者文本行很少、很短的页面时就该哭了,因为这个时候文本行跟踪完全指望不上,页边界曲线跟踪又不能独立使用,你还有什么办法?
所以CEP宁愿花费大量精力,也务必要让上下页边界曲线跟踪成为一个独立的过程,不需要以文本行跟踪、纵向特征提取的结果作为前置条件,相反的是从边界曲线中还能提取出纵向特征,这样上下两条边界曲线加上左右边界就构成一个完整的模型。 例如下图这个样张(下载自成者科技官网),因为没有足够的文本行,所以不论是ST还是STE,或者任何他们的魔改版,都完全无法展平,但CEP却可以。

图7
正因为CEP中的页边界曲线跟踪是能完全独立运行的,所以在CEP中提供三种自动展平方法供用户选择:
- 扩展文本行:和ST、STE一样,先对文本行进行跟踪,从中提取纵向边界,再在纵向边界范围内找页边界曲线,作为文本行跟踪的补充,所以称为“扩展文本行”。在页边界比较清晰,页面内也有一定数量的、足够长的横向文本时,展平效果较好。而且页边界跟踪能力优于ST、STE,至少不那么容易漏掉页边界。
- 文本行:只对横向文本行进行跟踪,不管页边界,所以速度略快。适用于纯文字页面,而且是横排、文本行足够长的纯文字页面。
- 页边界:只对页面的上下边界进行跟踪,不管页面内容是什么。所以在页面内容是竖排文字、插图页等难以从文本行提取横向特征使,可以用这个。不过速度略慢,而且要求照片中包含完整、清晰的页面 上下边界。
3、纵向特征提取
ST其实是先做纵向特征提取,然后再在这个范围内提取文本行、左右边界。原因我猜是想把周围各种干扰尽可能去掉,只留下最干净的文本行,才好进行跟踪。提取 左右边界的方法是分别求取版心的左、右外包络线,然后从中选取最长的一条线作为该侧的边界。在页面内容是整齐的文本行时,这种方法没毛病,但如果上、下半页有插图,插图就会对外包络线造成干扰,如图8中的左外包络线(红线部分),上半部分受插图影响向内收缩,导致最终出来的边界不是想要的,参见图9中左侧的蓝色斜线。 图9中右侧边界线则是因为右上角那行文字拦了一下,所以就比较准确。图8~图10所处理的样张可从我的网盘下载,“DIY零边距扫描仪 > 无压板方案 > 样张 > 800万像素 > 16开单页_彩色_手持.rar”。
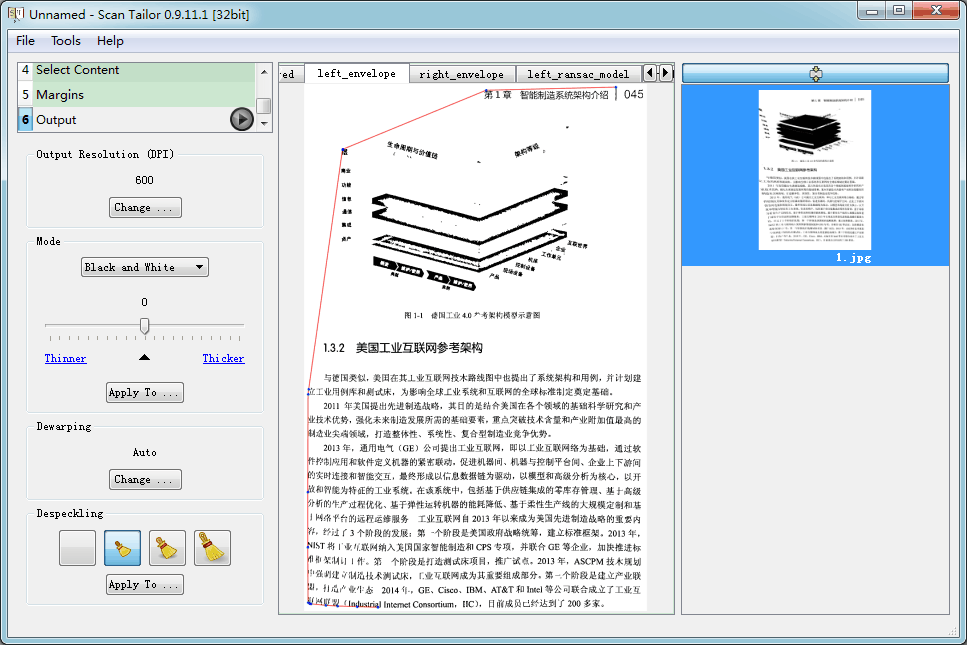
图8
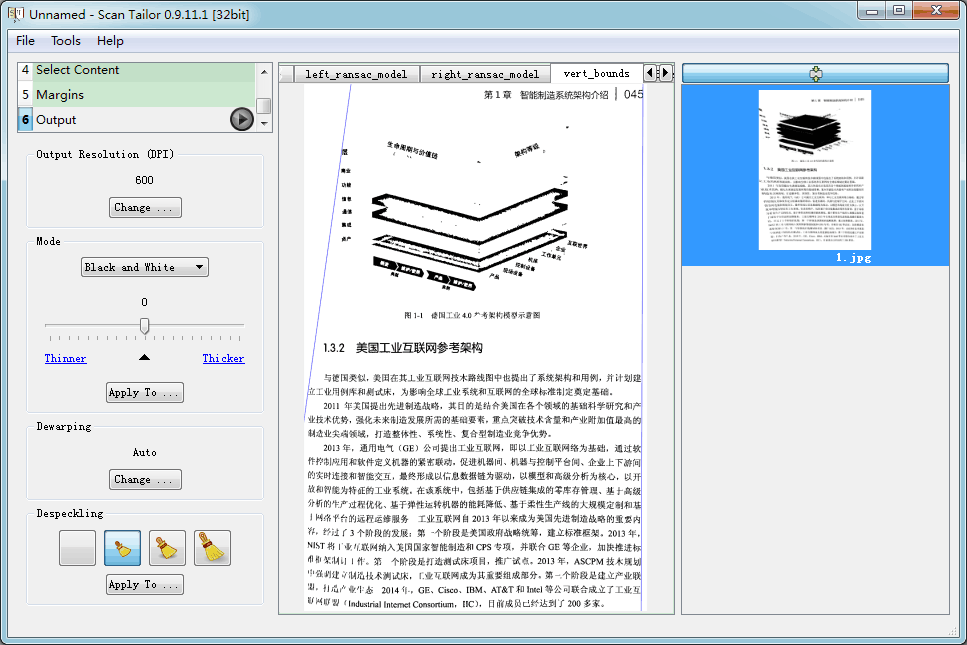
图9
STE与ST完全不同,是先做文本行跟踪,然后根据文本行的左、右端点,取通过最多端点的直线作为左右边界,所以不受插图的影响,参见图10中的左右边界线 (蓝线)。与图8、图9相比,虽然处理的是同一张原始照片,但STE的左右边界判别就好得多,但文本行跟踪结果则是歪七扭八,实在不敢恭维。
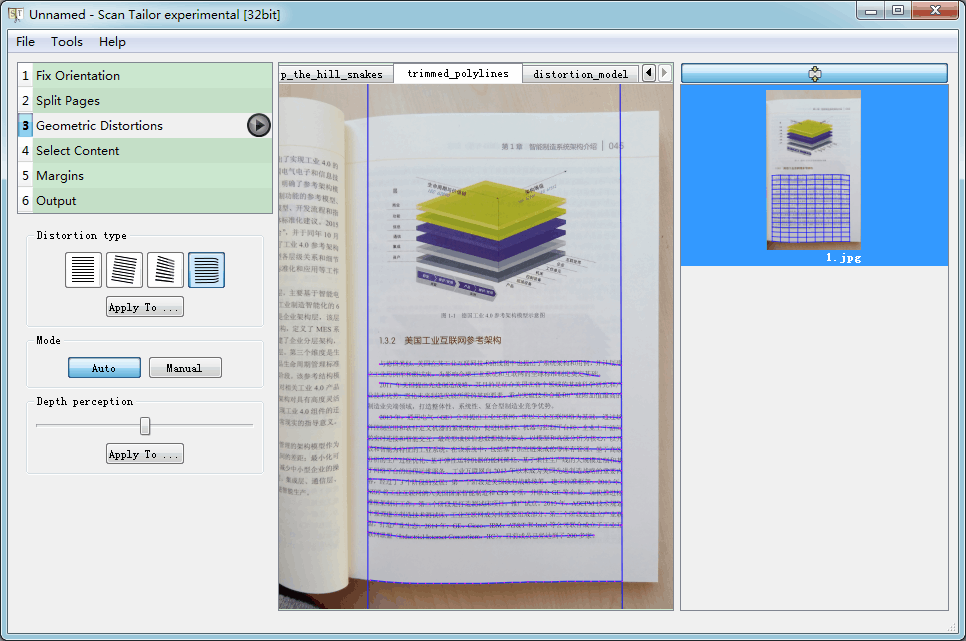
图10
CEP的左右边界提取方法要看用户选择了哪种展平方法:
-
如果用户选择了按扩展文本行或按文本行展平,则采用与STE相似的方法,从文本行的左右端点找左右边界。 因为既然用户敢选这两项,说明页面上是以横向文本行为主,那么通过文本行左右端点取左右边界就没毛病。
-
如果用户选择了按页边界展平,则在跟踪出上下边界曲线后,在曲线左右侧分别找尖点、断点、斜率巨变点等,作为页边界曲线的端点。上下边界曲线的4个端点找出来后,就构成了左右边界。所以在选择按页边界展平时,与文本行 或页面内容完全无关,只要页面上下边界清晰、完整即可。在曲线中找尖点及斜率计算方法详见《高等数学》教材,实现时主要是靠数值微分。神奇的是我在实现过程中发现,某高校2018年出版的《数值计算方法》教材中,居然把数值微分的5点公式都抄错了,还真是误人子弟。
另外为了弥补自动找竖向边界时可能出现的失误,在CEP中还提供了“自动1”按钮:如果看到自动找出来的左右边界不对,可以手工拖拽曲线的左右端点改变边界位置,然后点击“自动1”按钮,就会按照拖拽后的边界重新找曲线、建模、展平。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号