OO Unit1 单元总结
OO Unit1 单元总结
三周的OO系列作业就此告一段落,就此做一个小结。
程序结构分析
第一次作业
UML类图
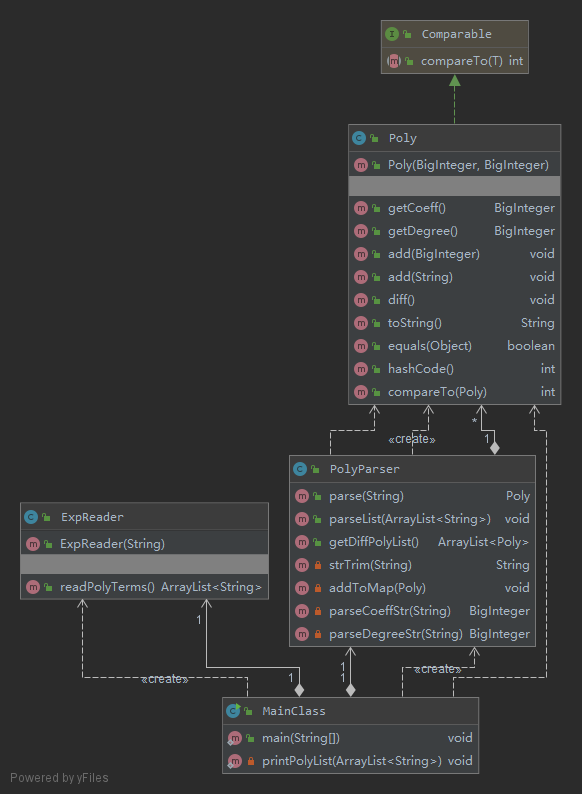
-
MainClass类负责顶级流程调度,先实例化
ExpReader并使其解析输入字符串并分割成项,调用readPolyTerms方法获取解析完成项字符串ArrayList。之后使用PolyParser分析这些项,并使用getDiffPolyList方法直接获取求导、化简完成的项用于输出。 -
ExpReader类负责将输入切分成项字符串,给出
ArrayList -
PolyParser类将项字符串解析为项,构造
Poly类。使用HashMap管理这些类,提供将所有类求导与输出的方法。 -
Poly类这里有单词理解错误,Poly指的是幂函数(当时以为Poly是幂函数),第二次作业之后就修正了
核心部分,有求导
diff和相加add方法,当时情况较为简单设计成了可变对象。对于第一次作业来说,设计类的时候有一些失误。
PolyParser承担了对poly求导的功能,实际上其应当直接返回Poly,而不是做不属于其工作内容的事- 主函数中设计不合理,
printPolyList直接一步从获取Parser得到的项到输出最终求导结果 Poly类设计为可变类,对之后扩展时面对的复杂逻辑不利
但也有其积极作用
- 一开始进行分类,为之后的逐步细分打下了基础
- 求导方法归属于相应的数据类,避免了代码过度耦合
总之,第一次类的设计只能恰好完成这项任务,留下的扩展余地很小。
复杂度分析
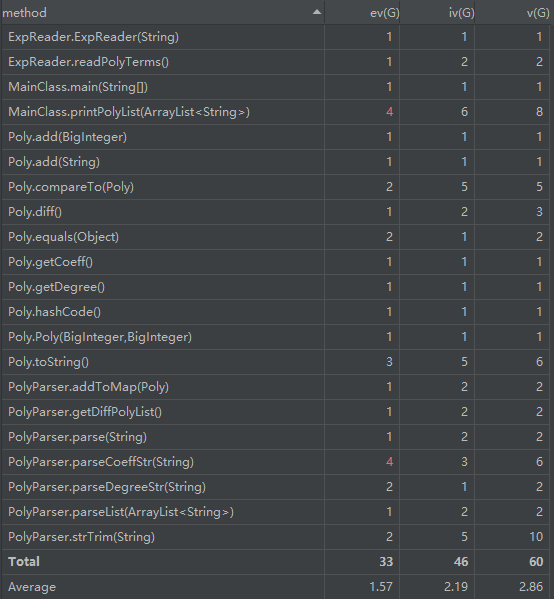
由于把各项工作分给了多个子函数,方法数很多,并且为了调用方便,使用了一些重载方法,总体复杂度较高的是解析字符串方法和输出字符串方法,以及Poly函数的toString方法。可以看出输入输出方面复杂度较高。
类规模分析
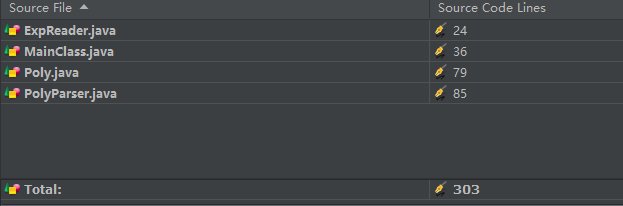
由于分了多个类,且功能较为简单,故每个类的规模都不是很大,如图所示。
第二次作业
第二次作业的新内容是增加了额外的项和链式求导法则,之前第一次作业的结构变得不适用,故需要重新调整结构。
UML类图
由于第二次类图导出十分复杂,故此处手动绘制UML类图,并只保留设计核心部分。(可能部分标识有误)
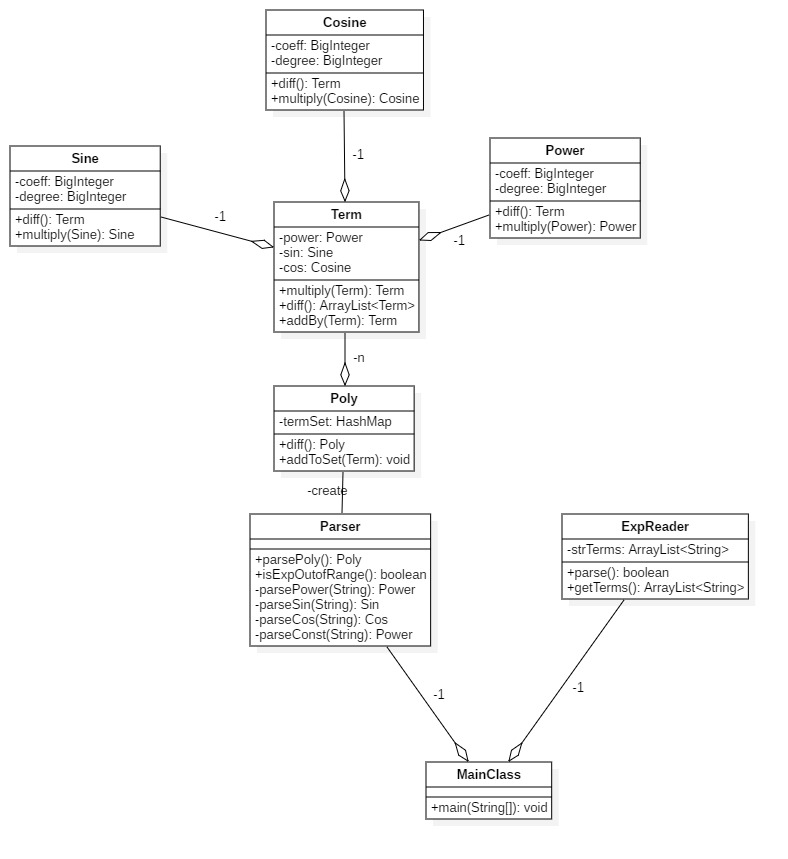
-
数据存储方面
管理了三个基本类:Sine、Cosine和Power,作为Term的组成成分。由于本次作业的三角函数内部只有x,所以每一项最终都可化简为只有三个基本元素,就是上面提到的三个基本类,故每一个Term保有基本类的一个实例。Poly则包含多个Term,并使用
HashMap存储,以便进行合并同类项。 -
数据流
MainClass从ExpReader读取按项划分的字符串ArrayList后,交给Parser进行解析,Parser的解析过程则是使用内部的解析方法进行尝试,获取各项的因子,构造项。最终返回一个Poly类,此时直接调用Poly类中的diff()方法,即可通过其组件(Term)的diff()方法,依次类推逐层下传,得到最终的结果。由于之前的设计方式已经不能满足需要,故进行了重新优化和拓展。
设计优点:
- 对每个基本数据类定义好求导,求和等基本方法后,可在包含这些对象的类中直接调用
- 本次基本实现了全静态类,内部数据不可改动,只能返回新的对象,减小了逻辑复杂度
- 相对第一次优化了流程与架构
设计缺点:
-
ExpReader仍然保留了原有设计,即按项读取并检查合法性,后期扩展时将遇到较大问题问题的主要来源是
Parser在每项内逐个获取因子,并假设ExpReader已经检查了合法性。但在之后的问题中,表达式嵌套需要递归检查时,ExpReader实际上也需要逐个获取因子,功能上与Parser有很大重合,浪费了时间和空间。另一种可能的设计方案是将这两个类合并,直接从表达式逐因子读取并检查合法性之后,构造对象,而不是进行一次中转。本质上是关系紧密的类可以选择合并。 -
多层数据嵌套的情况下,不利于优化时数据的获取
复杂度分析
由于方法和类数量较多,故这里选择复杂度最高的十个方法展示
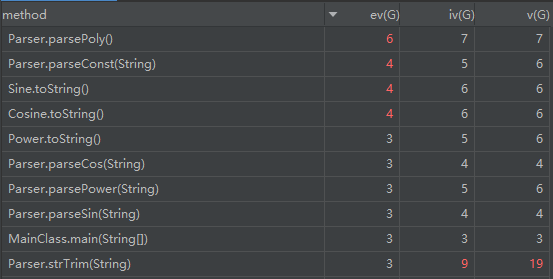
可见,复杂度最高的方法仍然是和输入、输出相关的内容,由于输入、输出格式有较为严格的限制,并且在考虑优化的情况下,输出逻辑十分复杂,较难避免出现高复杂度。
类规模分析
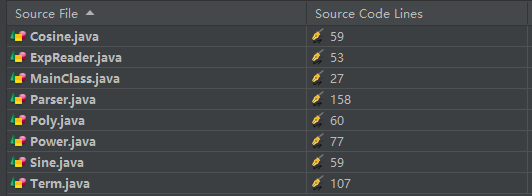
可见,Parser作为工厂类,代码行数上升;同时求导规则与输出规则toString较为复杂的Term类代码规模也开始上升。
Parser类中有最多数量的长方法,包括解析Poly的方法parsePoly(),和去除重复加减号的方法strTrim()。而其他的基本类不具有较复杂的方法。
第三次作业
UML类图
项目包结构如图所示
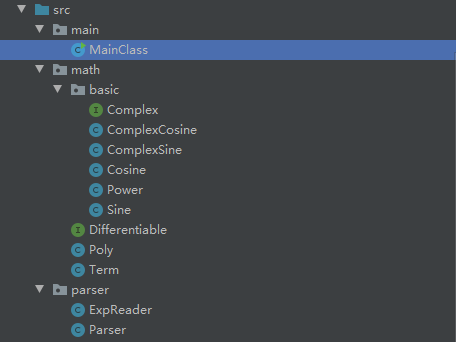
本图展示math.basic包下的类依赖关系
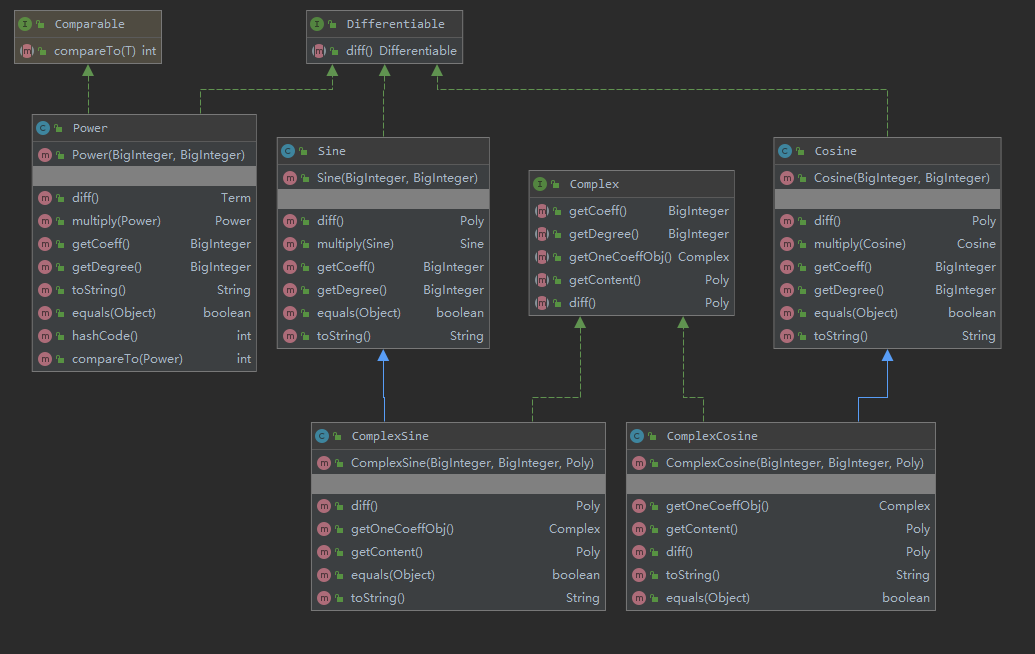
本图展示math包下的类依赖关系
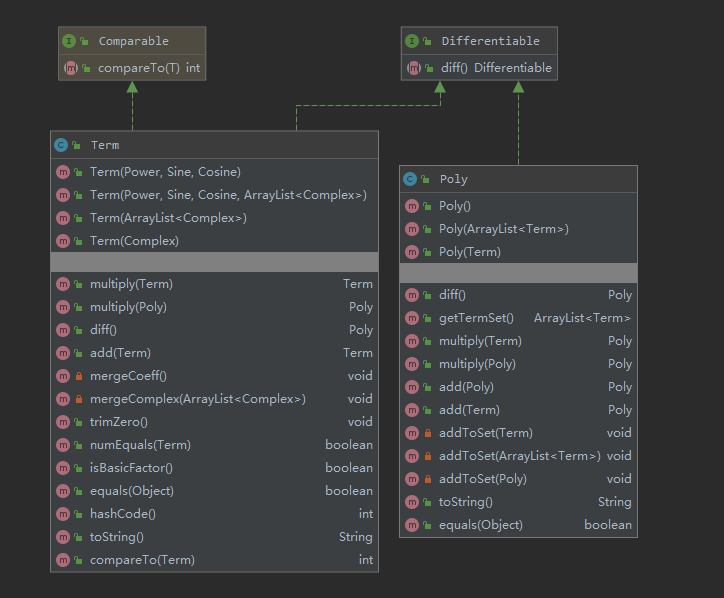
由于Parser,ExpReader和MainClass类关联不强,故不予展示。现给出精简UML图,仅仅保留核心部分。

- 本次作业更改点:
- 在Sine和Cosine的基础上创建子类,保存内部不为x的三角函数项,提供全新的求导方法。使用Complex抽象接口对这些内容不为x的三角函数类进行存储,以便于在Term中放入同一个数组。
- Term中,在原有结构基础上(原来只保存Power、Sine和Cosine),增加一个数组用于保存新增的嵌套三角函数。并修改相应Term求导法则,使其适应任意多项求导的需要。
- 对于所有可求导的类,均继承了Differentiable接口,分别实现其diff()方法。
优缺点分析:
-
优点:
- 使用Complex接口对复合三角函数统一管理,避免了麻烦
- 尽可能保有原有结构,数据处理部分重构较少(其实也造成了很大的困扰)
- 对每个可求导的因子都实现了
diff()方法,对整体(Poly)求导,可自动分解递归为对其包含的因子(Term)进行求导,隐藏了递归细节,使得逻辑清晰。
-
缺点:
-
Differentiable接口只起到了显式定义diff()方法作用,在项(Term)的存储结构上,仍然采用了第二次作业的Sine、Cosine、Power结构,只是添加了ArrayList<Complex>对新增数据类型进行保存。这种数据保存方式没有利用接口的作用,其实这里可以将所有因子放入ArrayList<Differentiable>中,实现统一求导。实际上为了保留原有结构,对Term的求导逻辑变得十分复杂。需要先对Power求导,然后对其子结构式再构造Term进行求导。Sine、Cosine、Power和所有的complexes都求导完成后才返回。倘若采用统一管理模式,则可以较大程度上简化求导这一过程,不用创建新的Term即可递归创建对象。
-
ExpReader与Parser功能出现重叠在加入嵌套表达式后,
ExpReader在使用大型正则表达式时读取的是整项,但难以对其内容进行检查(使用了sin(.*)正则表达式)。而之前设计的时候Parser对数据的期望是完全合法的,此时要求ExpReader对嵌套表达式进行格式检查,而格式检查的实质和创建类的过程完全一样,即逐个因子读取,若一路都能顺利读取,则为合法表达式。这项工作在Parser中又被执行了一次,实际上造成了时间的浪费。
-
复杂度分析
同样,由于方法数量较多,只选择复杂度最高的10个方法进行分析。可以发现,排名靠前的基本都是输入、输出相关的方法。有一个例外,即Term.diff(),正如之前提到的,保留Task2中的Term数据存储方式,其实造成了很大的困扰,使得逻辑变得极为复杂,不但编写时非常难,debug也花费了一些时间。
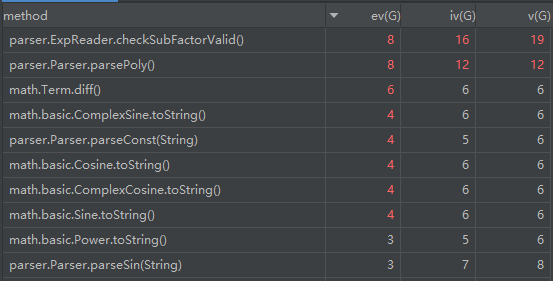
类规模分析

由于继续延续了简单工厂方法,Parser类的规模不断增长,并且Parser类中也出现了即将达到check style限制的60行长方法parsePoly()。同时,随着嵌套规则的增长,作为控制求导的核心单元Term的规模也开始上升。
在检查了代码后,发现最长的方法有以下特征:
- 作为输入处理方法
- 求导方法
- 输出方法
求导方法的复杂度难以避免,但输入和输出如果能够得到更好的分解,可以化解部分复杂度。
程序Bug分析
前两次的程序逻辑较为清晰,设计之前也充分且正确地理解了需求,测试相对充分,没有被发现bug。但第三次,设计逻辑较为复杂,写完之后自测都发现数十个bug。修复之后,仍然有漏网之鱼,在强测和互测中被暴露出来。
第三次作业
-
输出格式出现的问题
由于最开始没看清指导书,认为三角函数括号内可以直接是一项。最后再去改的时候,输入确实没有问题了,但是在输出上却出现了瑕疵。即当输出的复合三角函数内部为一个常数乘以幂函数时,将没有括号,导致
sin(2*x**2)输出。- 问题特征:输出情况未考虑清楚
- 问题所在类:
ComplexSine与ComplexCosine - 方法:
toString()
在设计的时候,具体是否输出括号是根据三角函数内部包含因子数决定的。由于程序中存储项(Term)的结构不包含常数项,故当常数项乘以幂函数的时候,将被统计为一项,导致错误。
-
不可变对象突然被改变导致的问题:
在计算过程中,难免会出现系数为0的项,为合并方便,常常把这些项变成一个相同规格的“零项”,在
HashMap中将成为与常数相同的元素。而本bug就出现在这里,在索引一个对象之后,马上对该对象进行了trimZero操作,该操作实际上改变了该对象。在<Term, Term>这个自映射HashMap中,先用改变前的对象去索引,再将改变后的对象放入HashMap,将导致映射不再是自映射。- 问题特征:习惯于因子不可变,而无视顺序。实际上这里虽然感觉没变(都是0项),但对于
HashMap是不同的两项 - 问题所在类:
Term - 方法:
trimZero()
设计之时,本来想使得所有因子都不可变。这里把0项归一化处理。虽然看起来对计算毫无影响,却忽略了
HashMap认为该对象已经改变的事实,导致最终结果错误。 - 问题特征:习惯于因子不可变,而无视顺序。实际上这里虽然感觉没变(都是0项),但对于
-
细节问题
仍然是没有看清指导书提供的格式,
sin(- x)实际上是不合法数据,因为这种方式实际上已经成为表达式- 问题特征:对题目理解不清晰
- 问题所在类:
ExpReader - 方法:
checkSubFactorValid()
设计时没考虑这种情况,自然会被忽略。
总结
通过自身的bug总结发现,bug出现的地点常常在输入、输出相关的地方。在写完代码自测的时候,输入、输出的格式检查和解析,也是问题频发的地方。恰好经过复杂度分析发现,出现问题频率最高的地方就在这里。所以,尽可能优化代码逻辑,在逻辑复杂度和运行性能上做出trade-off,有利于开发出质量更高的软件。
发现他人问题策略
每次构造测试样例时,都会从几个方面进行考虑:输入的处理、边界数据的考察、极端数据的考察、覆盖性测试。
以我互测最为激烈的第三次作业举例,本次作业提升了复杂度。
-
输入处理
输入的处理是漏洞的高发地,在阅读指导书,分析输入结构的时候,就开始构造部分容易出现格式问题的测试点。经过测试,发现部分同学的程序在处理过程中卡死(等待输入)的情况。
-
边界数据的考察
大数据点、0这个特殊的数据在嵌套情况下的处理,这些都成为了这次测试的边界条件之一。
-
极端数据的考察
本次嵌套函数,递归基本上是每位同学都使用的方法。故针对这一点构造深递归数据,事实证明处理不当很容易造成超时问题。
-
覆盖性测试
完成了对点测试之后,就只能对一般情况进行覆盖测试。采用分类的方法,将可能出问题的点逐个测试,尽可能覆盖最多情况。
有效性最高的是极端数据的考察,很多深层递归都导致了很多问题。其次是输入的处理,输入过程中导致的问题可能使程序卡住或者无法得到正确结果
针对代码的结构设计的测试用例,其实主要体现在代码的复杂度上。由于大家的代码习惯仍然在建立过程中,很多同学的程序仍然不是很好理解。但对于一main到底的同学(或者就23个类解决问题的同学),常常浏览观察复杂度最高的部分在哪个区域,针对该区域设计一些测试用例(代码是不可能仔细看的)~。这样的测试用例往往更容易找到问题。
应用对象创建模式
第一次作业
第一次作业的项相对比较简单,只有简单幂函数,故一个简单工厂即可实现其功能。在我的第一次作业中,也使用了Parser类作为工厂,这个简单工厂也延续到了我后面的作业中。
第二次作业
第二次作业的项包含了较多项,可分为幂函数、三角函数两类。简单工厂在这个时候也能够胜任,但倘若使用工厂方法模式更有利于扩展,而我却仍然延续了简单工厂模式,在Parser类中解析并创建新的类。
第三次作业
第三次作业的项包含了更加复杂的内容,这时候工厂方法模式的可扩展性就体现出来了。由于继续延续原有的简单工厂模式Parser类变得十分臃肿和复杂,不利于编写与调试。
总结
如果可以预测到未来的产品数量会增长的话,使用工厂方法模式或者抽象工厂模式更有利于扩展。
对比与心得体会
优秀代码学习对比
经过阅读优秀代码,学习他们的构造思路,我发现我有以下不足之处:
- 工厂方法的实际应用:本次作业我使用的是简单工厂模式,即只使用Parser类对输入的字符串对象进行解析并构造Term。但实际上当因子种类变多的时候,使用单一工厂将使得工厂代码长度变长,逻辑更加复杂。如Parser中的主要生产函数
parsePoly()就一度将超过Check Style行数限制。 - 对表达式的处理:表达式层抽象不足,仅仅将表达式作为一个字符串这一简单的数据格式。张家树同学将表达式抽象成了一个类,从而在其内部可以自行检查合法性和解析,是一种化解输入解析复杂性的独特思路。
- 分工明确:由于加入新需求,检查表达式内部结构导致代码内部功能出现重叠,不仅使得代码体积膨胀且逻辑复杂化,而且浪费了宝贵的运行时间。这个问题的主要原因是来自功能的变化考虑不清晰,导致没有设计符合功能的体系结构。
心得体会
第一次OO作业,其实说难也不是完全做不到的难度,但在结构设计、代码编写和Debug这些过程中,都遇到了大大小小各种问题。前两次作业虽然做的途中有点坎坷,但结果都还不错。最后一次作业由于没有读清楚指导书的要求,没考虑清晰问题,导致写完的代码不能符合要求。在这一结构上修补,使得代码的复杂度急剧上升。所以明确需求,确定解决方案再动手,是代码编写中不可或缺的一环。
遇到问题的时候,思考良久也不能得到一个最好的解决方案,只能在复杂度和效率之间做一个权衡。Debug的时候,发现难以解决的bug的时候,在重构和修补之间做抉择时的挣扎心态。确实有难度,想要放弃的时候,鼓励自己再解决一个子问题,或者再修复一个小bug。
虽然路途艰难,但一步步向前走,当程序能够正常运行的时候,之前的各种迷茫、在bug中痛苦挣扎都转换成了更强的成就感。人都是在历练中学习的,在OO中“痛苦挣扎”,等到了终点,这些“伤痛”愈合之后,你会发现自己变得比原来更强大。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号