

python学习笔记-scarpy
一、scrapy介绍
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架
应用原理
1、指定初始url
2、解析响应内容
-给调度器
-给item;pipeline;用于做格式化;持久化
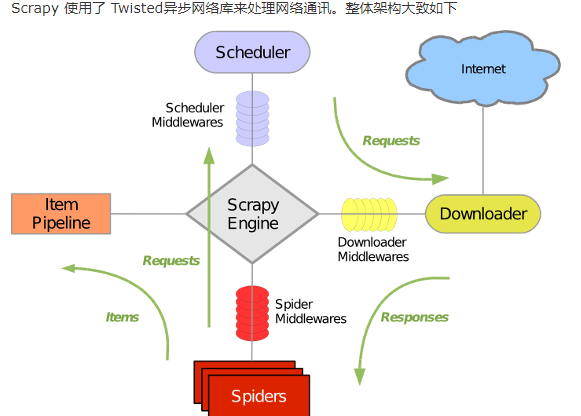
- 引擎(Scrapy)
用来处理整个系统的数据流处理, 触发事务(框架核心) - 调度器(Scheduler)
用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. 可以想像成一个URL(抓取网页的网址或者说是链接)的优先队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址 - 下载器(Downloader)
用于下载网页内容, 并将网页内容返回给蜘蛛(Scrapy下载器是建立在twisted这个高效的异步模型上的) - 爬虫(Spiders)
爬虫是主要干活的, 用于从特定的网页中提取自己需要的信息, 即所谓的实体(Item)。用户也可以从中提取出链接,让Scrapy继续抓取下一个页面 - 项目管道(Pipeline)
负责处理爬虫从网页中抽取的实体,主要的功能是持久化实体、验证实体的有效性、清除不需要的信息。当页面被爬虫解析后,将被发送到项目管道,并经过几个特定的次序处理数据。 - 下载器中间件(Downloader Middlewares)
位于Scrapy引擎和下载器之间的框架,主要是处理Scrapy引擎与下载器之间的请求及响应。 - 爬虫中间件(Spider Middlewares)
介于Scrapy引擎和爬虫之间的框架,主要工作是处理蜘蛛的响应输入和请求输出。 - 调度中间件(Scheduler Middewares)
介于Scrapy引擎和调度之间的中间件,从Scrapy引擎发送到调度的请求和响应。
工作流程理解,调度器可看作存放url的队列,引擎相当于循环,从队列中拿url到下载器中处理。。
具体流程
1、引擎从调度器中取出一个链接(URL)用于接下来的抓取
2、引擎把URL封装成一个请求(Request)传给下载器
3、下载器把资源下载下来,并封装成应答包(Response)
4、爬虫解析Response
5、解析出实体(Item),则交给实体管道进行进一步的处理
6、解析出的是链接(URL),则把URL交给调度器等待抓取
二、scrapy创建项目
windows安装scrapy
pip3 install scrapy
1、创建项目命令
命令行中输入如下命令创建
scrapy startproject scrapytmp1

cd scrapytmp1
scrapy genspider chouti chouti.com

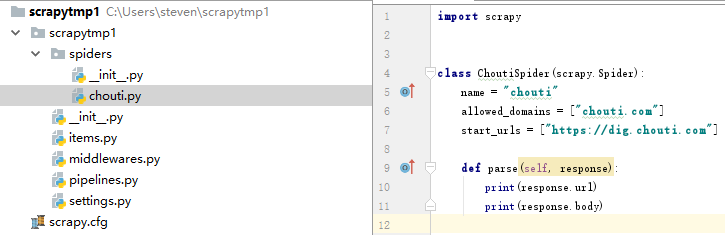
创建后生成的项目结构
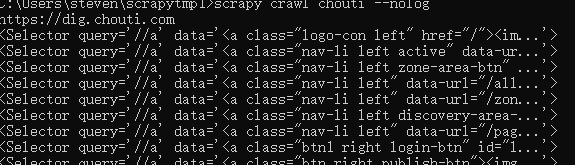
执行,修改chouti.py文件后输入命令运行爬虫
scrapy crawl chouti
执行不打印日志
scrapy crawl chouti --nolog
可创建多个爬虫,新建一个爬虫时
scrapy genspider cnblog cnblogs.com
2、示例,获取新闻标题
找到想要的标签,导入选择器,编写代码找所有a标签
def parse(self, response): print(response.url) hxs=Selector(response=response).xpath('//a') #标签对象列表 for i in hxs: print(i)


import scrapy from scrapy.selector import Selector class ChoutiSpider(scrapy.Spider): name = "chouti" allowed_domains = ["chouti.com"] start_urls = ["https://dig.chouti.com"] def parse(self, response): print(response.url) hxs=Selector(response=response).xpath('//div[@class="outer-container"]//div[@class="link-detail"]') #标签对象列表 for obj in hxs: a=obj.xpath('.//a[@class="link-title link-statistics"]/text()').extract_first() print(a.strip())
2.1、选择器用法
//表示子孙中找
.//表示对象的子孙中
/儿子
/div 儿子中的div标签
/div[@id='il'] 儿子中的div标签且id=il
obj.extract() #列表中的每一个对象转换字符串=》[]
obj.extract_first() # #列表中的每一个对象转换字符串=》列表第一个元素
//div/text() #获取某个标签的文本
3、示例,获取页码
3.1、用不同的方式找到页码a标签
#hxs = Selector(response=response).xpath('//div[@id="paging_block"]//a/@href').extract() #以什么开头的方式找页码标签,获取属性 #hxs = Selector(response=response).xpath('//a[starts-with(@href,"/sitehome/p/")]/@href').extract() #以正则的方式 hxs = Selector(response=response).xpath('//a[re:test(@href,"/sitehome/p/\d+")]/@href').extract()
3.2、去除重复,并对url进行md5加密
import scrapy from scrapy.selector import Selector class CnblogSpider(scrapy.Spider): name = "cnblog" allowed_domains = ["cnblogs.com"] start_urls = ["https://www.cnblogs.com"] visited_ruls=set() def parse(self, response): #hxs = Selector(response=response).xpath('//div[@id="paging_block"]//a/@href').extract() #以什么开头的方式找页码标签,获取属性 #hxs = Selector(response=response).xpath('//a[starts-with(@href,"/sitehome/p/")]/@href').extract() #以正则的方式 hxs = Selector(response=response).xpath('//a[re:test(@href,"/sitehome/p/\d+")]/@href').extract() for url in hxs: md5_url=self.md5(url) if md5_url in self.visited_ruls: print('已经存在',url) else: self.visited_ruls.add(md5_url) print(url) #url太长,进行md5加密处理 def md5(self,url): import hashlib obj=hashlib.md5() obj.update(bytes(url,encoding="utf-8")) return obj.hexdigest()
3.3、只找到首页看到的页码,要显示所有的页码,需要把url添加到调度器
import scrapy from scrapy.selector import Selector from scrapy.http import Request class CnblogSpider(scrapy.Spider): name = "cnblog" allowed_domains = ["cnblogs.com"] start_urls = ["https://www.cnblogs.com"] visited_ruls=set() def parse(self,response): #hxs = Selector(response=response).xpath('//div[@id="paging_block"]//a/@href').extract() #以什么开头的方式找页码标签,获取属性 #hxs = Selector(response=response).xpath('//a[starts-with(@href,"/sitehome/p/")]/@href').extract() #以正则的方式 hxs = Selector(response=response).xpath('//a[re:test(@href,"/sitehome/p/\d+")]/@href').extract() for url in hxs: md5_url=self.md5(url) if md5_url in self.visited_ruls: pass else: print(url) self.visited_ruls.add(md5_url) url="https://www.cnblogs.com%s"%url yield Request(url=url,callback=self.parse) #将新要访问的url添加到调度器,就能一层一层的往下执行 #url太长,进行md5加密处理 def md5(self,url): import hashlib obj=hashlib.md5() obj.update(bytes(url,encoding="utf-8")) return obj.hexdigest()
设置爬取的深度
setting中配置
DEPTH_LIMIT=2 #表示往下再访问一层,最多取2层数据
*重写start_requests.可指定最开始处理请求的方法
4、基于pipeline实现标题和url的持久化
使用示例,取文章的标题和链接
hxs1=Selector(response=response).xpath('//div[@id="main_flow"]/div//article[@class="post-item"]') for obj in hxs1: title=obj.xpath('.//div[@class="post-item-text"]/a/text()').extract_first() href=obj.xpath('.//div[@class="post-item-text"]/a/@href').extract_first()
4.1、将标签的title和href封装到一个对象
#items.py import scrapy class cnblogItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() title=scrapy.Field() href=scrapy.Field()
#cnblog.py hxs1=Selector(response=response).xpath('//div[@id="main_flow"]/div//article[@class="post-item"]') for obj in hxs1: title=obj.xpath('.//div[@class="post-item-text"]/a/text()').extract_first() href=obj.xpath('.//div[@class="post-item-text"]/a/@href').extract_first() item_obj=cnblogItem(title=title,href=href) #将item对象传递给pipeline yield item_obj
4.2、pipeline要在setting注册一下
#settings.py ITEM_PIPELINES = { "scrapytmp1.pipelines.cnblogPipeline": 300, }
300数字表示权重,越小权重越大,越先执行
4.3、pipeline持久化,将内容输出到文件中
class cnblogPipeline: def process_item(self, item, spider): print(spider,item) tpl="%s\n%s\n\n"%(item['title'],item['href']) f=open('news.json','a') f.write(tpl) f.close()
4.4、url去重优化,使去重功能和爬虫代码分离
要点
重写scrapy.dupefiter中的BaseDupeFilter方法实现,其中的方法名要保持一致
settings中进行配置
重写方法,新建duplication.py
class RepeatFilter(object): def __init__(self): self.visited_set=set() @classmethod def from_settings(cls,settings): return cls() def request_seen(self,request): if request.url in self.visited_set: return True else: self.visited_set.add(request.url) return False def open(self): print('open') def close(self,reason): print('close') def log(self,request,spider): pass
配置settings
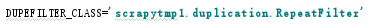
修改爬虫代码去除去重功能部分,查看结果
import scrapy from scrapy.selector import Selector from scrapy.http import Request from ..items import cnblogItem class CnblogSpider(scrapy.Spider): name = "cnblog" allowed_domains = ["cnblogs.com"] start_urls = ["https://www.cnblogs.com"] def parse(self,response): print(response.url) hxs = Selector(response=response).xpath('//a[re:test(@href,"/sitehome/p/\d+")]/@href').extract() #response hxs1=Selector(response=response).xpath('//div[@id="main_flow"]/div//article[@class="post-item"]') for obj in hxs1: title=obj.xpath('.//div[@class="post-item-text"]/a/text()').extract_first() href=obj.xpath('.//div[@class="post-item-text"]/a/@href').extract_first() item_obj=cnblogItem(title=title,href=href) #将item对象传递给pipeline yield item_obj for url in hxs: url="https://www.cnblogs.com%s"%url yield Request(url=url,callback=self.parse)
4.5、pipeline补充
要点
pipeline四个方法
from_crawller :初始化时创建对象,读取配置,crawler.settings.get('setting中的配置文件名称必须大写')
open_spider :爬虫开始执行时调用
close_spider :爬虫关闭时调用
process_item :每当数据需要持久化时,就会被调用
多个pipeline时,交给下一个pipeline处理return item,丢弃item不交给下一个处理raise DropItem()
示例优化,持久化时打开和关闭文件等操作放在不同的方法中处理
from itemadapter import ItemAdapter from scrapy.exceptions import DropItem class cnblogPipeline: def __init__(self,conn_str): self.conn_str=conn_str @classmethod def from_crawler(cls,crawler): conn_str=crawler.settings.get('DB')#获取setting的DB配置项 print(conn_str) return cls(conn_str) def open_spider(self,spider): self.f = open('news.json', 'a') def close_spider(self,spider): self.f.close() def process_item(self, item, spider): ''' 每当数据需要持久化时,就会被调用 :param item: :param spider: :return: ''' #print(spider,item) tpl="%s\n%s\n\n"%(item['title'],item['href']) self.f.write(tpl) return item #多个pipeline示例 class cnbacPipeline: def open_spider(self,spider): self.f = open('pipe2.txt', 'a') def close_spider(self,spider): self.f.close() def process_item(self, item, spider): tpl="%s\n%s\n\n"%(item['title'],item['href']) self.f.write(tpl) raise DropItem
*配置,在setting中配置多个pipeline和自定义配置项,略
5、cookie
用法
cookie_obj=CookieJar()
cookie_obj.extract_cookies(response,response.request)
self.cookie_dict=cookie_obj._cookies
示例:对文章点赞(未调试)
import scrapy from scrapy.selector import Selector from scrapy.http.cookies import CookieJar from scrapy.http import Request class ChoutiSpider(scrapy.Spider): name = "chouti" allowed_domains = ["chouti.com"] start_urls = ["https://dig.chouti.com"] cookie_dict=None def parse(self,response): cookie_obj=CookieJar() cookie_obj.extract_cookies(response,response.request) self.cookie_dict=cookie_obj._cookies #带上用户名密码+cookie yield Request(url='https://dig.chouti.com/login', method='POST', body="phone=8617628230960&password=shanjiaoyu&oneMonth=1", headers={'Content_Type': 'application/x-www-form-rulencoded;charset=URF-8'}, cookies=self.cookie_dict, callback=self.check_login ) def check_login(self,response): print(response.text) yield Request(url='https://dig.chouti.com/',callback=self.good) def good(self,response): id_list=Selector(response=response).xpath("//div[@share-linkid]/@share-linkid").extract() for nid in id_list: url='https://dig.chouti.com/link/vote?linksId=%s'% nid yield Request(url=url, method='POST', cookies=self.cookie_dict, callback=self.show ) page_urls = Selector(response=response).xpath('//div[@id="dig_lcpage"]//a/@href').extract() for page in page_urls: url = "http://dig.couti.com%s" % page yield Request(url=url, callback=self.good) def show(self,response): print(response.text)
6、scrapy扩展
配置项

示例:
from scrapy import signals class MyExtend: def __init__(self,crawler): self.crawler=crawler #在指定信号上注册操作 crawler.signals.connect(self.start,signals.engine_started) crawler.signals.connect(self.close,signals.spider_closed) @classmethod def from_crawler(cls,crawler): return cls(crawler) def start(self): print('signals.engine_started.start') def close(self): print('signals.spider_closed.close')
要点:
常用到的方法是__init__,from_crawler
原理相当于在不同的流程段做信号标记,在信号上注册自定义的操作
可进行操作的信号如下:

7、配置文件
- 爬虫名字

- 客户端user_agent

- 遵守爬虫规则
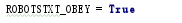
- 并发请求数

- 下载延迟
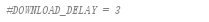
- 每个域名与ip的并发数

- 是否帮你爬取cookie,决定response是否会拿cookie,另外还有设置项debug
COOKIES_DEBUG=True
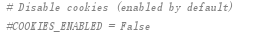
- 查看爬虫的运行状态,爬了多少哪些没爬,命令行执行telent 127.0.0.1 6023进入,查看命令est()
支持的其他命令

- 默认的请求头
- 更细化的延迟设置

- 缓存相关的

- 设置广度优先还是深度优先,1是深度优先

#缓存策略:素有请求均缓存,下次再请求直接访问原理的缓存 HTTPCACHE_POLICY="scrapy.extensionshttpcache.DummyPolicy" #缓存策略:根据Http响应头:Cache-Control,Last_modified等进行缓存的策略 HTTPCACHE_POLICY="scrapy.extensions.httpcache.RFC2616Policy"
- scrapy默认代理与扩展
第一种:原生
默认代理依赖环境变量,扩展性差
from scrapy.downloadermiddleware.httpproxy import HttpProxyMiddleware
第二种:自定义代理
import random,base64 from scrapy.utils.python import to_bytes class ProxyMiddleware(object): def process_request(self, request, spider): PROXIES = [ {'ip_port': '111.11.228.75:80', 'user_pass': ''}, {'ip_port': '120.198.243.22:80', 'user_pass': ''}, {'ip_port': '111.8.60.9:8123', 'user_pass': ''}, {'ip_port': '101.71.27.120:80', 'user_pass': ''}, ] proxy = random.choice(PROXIES) if proxy['user_pass'] is not None: request.meta['proxy'] = to_bytes("http://%s" % proxy['ip_port']) encoded_user_pass = base64.b64encode(to_bytes(proxy['user_pass'])) request.headers['Proxy-Authorization'] = to_bytes('Basic ' + encoded_user_pass) print("**************ProxyMiddleware have pass************" + proxy['ip_port']) else: print("**************ProxyMiddleware no pass************" + proxy['ip_port']) request.meta['proxy'] = to_bytes("http://%s" % proxy['ip_port'])
配置文件
DOWNLOADER_MIDDLEWARES = { 'scrapytmp1.middlewares.ProxyMiddleware': 500, }
- 自定义https证书
涉及的配置,默认是不可见的
#要爬取网站使用的可信任证书(默认支持) DOWNLOADER_HTTPCLIENTFACTORY = "scrapy.core.downloader.webclient.ScrapyHTTPClientFactory" DOWNLOADER_CLIENTCONTEXTFACTORY = "scrapy.core.downloader.contextfactory.ScrapyClientContextFactory" #要爬取网站使用的自定义证书 DOWNLOADER_HTTPCLIENTFACTORY = "scrapy.core.downloader.webclient.ScrapyHTTPClientFactory" DOWNLOADER_CLIENTCONTEXTFACTORY = "scrapytmp1.https.MySSLFactory"
自定义证书方法,使用场景少,很少爬取这样的网站
from scrapy.core.downloader.contextfactory import ScrapyClientContextFactory from twisted.internet.ssl import (optionsForClientTLS, CertificateOptions, PrivateCertificate) class MySSLFactory(ScrapyClientContextFactory): def getCertificateOptions(self): from OpenSSL import crypto v1 = crypto.load_privatekey(crypto.FILETYPE_PEM,open('/Users/z/client.key.unsecure', mode='r').read()) v2 = crypto.load_certificate(crypto.FILETYPE_PEM, open('/Users/z/client.pem', mode='rb').read()) return CertificateOptions( privateKey=v1, # pKey对象 certificate=v2, # X509对象 verify=False, method=getattr(self, 'method', getattr(self, '_ssl_method', None)) )
8、下载中间件
配置
DOWNLOADER_MIDDLEWARES = { "scrapytmp1.middlewares.DownloaderMiddleware1": 300, "scrapytmp1.middlewares.DownloaderMiddleware2": 500, }
中间件
class DownloaderMiddleware1: def process_request(self, request, spider): ''' 请求需要被下载时,经过所有下载器中间件的process_request调用 :param request: :param spider: :return: None,继续后续中间件去下载 Response对象:停止process_request的执行,开始执行process_response Request对象:停止中间件的执行,将Request重新调度器 raise IgnoreRequest异常,停止process_request的执行,开始执行process_exception ''' print('DownMiddleware1.process_request',request.url) def process_response(self, request, response, spider): ''' :param request: :param response: :param spider: :return: Response对象:转交给其他中间件process_response Request对象:停止中间件,request会被重新调度下载 raise IgnoreRequest异常:调用Request.errback ''' print('DownMiddleware1.process_response') return response def process_exception(self, request, exception, spider): ''' 当下载处理器(download handler)或process_request()(下载中间件)抛出异常 :param request: :param exception: :param spider: :return: None:继续交给后续中间件处理异常 Response对象:停止后续process_exception方法 Request对象:停止中间件,request将会被重新调用下载 ''' print("exception") class DownloaderMiddleware2: def process_request(self, request, spider): print('DownMiddleware2.process_request',request.url) def process_response(self, request, response, spider): print('DownMiddleware2.process_response') return response def process_exception(self, request, exception, spider): print("exception2")
执行顺序结果如下:
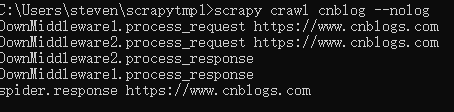
先执行request,在执行response,再执行spider
response必须加返回值,不然到不了spider
*执行时抛出异常,先交给process_exception处理
9、spider中间件
下载器执行完后,先交给spider中间件,再到的spider
中间件的方法名不能修改
自定义spider中间件
class Scrapytmp1SpiderMiddleware: def process_spider_input(self, response, spider): ''' 下载完成,执行,然后交给parse处理 :param response: :param spider: :return: ''' return None def process_spider_output(self, response, result, spider): ''' spider处理完成,返回时调用 :param response: :param result: :param spider: :return: ''' # 必须返回包含Reqquest或item对象的可迭代对象. for i in result: yield i def process_spider_exception(self, response, exception, spider): ''' 异常调用 :param response: :param exception: :param spider: :return: ''' # return None,继续交给后续中间件处理异常 #返回Response或Item的可迭代对象,交给调度器或pipeline pass def process_start_requests(self, start_requests, spider): ''' 爬虫启动时调用 :param start_requests: :param spider: :return: ''' # return:包含Request对象的可迭代对象 for r in start_requests: yield r
配置
SPIDER_MIDDLEWARES = { "scrapytmp1.middlewares.SpiderMiddleware": 543, }
内置的一些默认下载中间件
{ 'scrapy.contrib.downloadermiddleware.robotstxt.RobotsTxtMiddleware': 100, 'scrapy.contrib.downloadermiddleware.httpauth.HttpAuthMiddleware': 300, 'scrapy.contrib.downloadermiddleware.downloadtimeout.DownloadTimeoutMiddleware': 350, 'scrapy.contrib.downloadermiddleware.useragent.UserAgentMiddleware': 400, 'scrapy.contrib.downloadermiddleware.retry.RetryMiddleware': 500, 'scrapy.contrib.downloadermiddleware.defaultheaders.DefaultHeadersMiddleware': 550, 'scrapy.contrib.downloadermiddleware.redirect.MetaRefreshMiddleware': 580, 'scrapy.contrib.downloadermiddleware.httpcompression.HttpCompressionMiddleware': 590, 'scrapy.contrib.downloadermiddleware.redirect.RedirectMiddleware': 600, 'scrapy.contrib.downloadermiddleware.cookies.CookiesMiddleware': 700, 'scrapy.contrib.downloadermiddleware.httpproxy.HttpProxyMiddleware': 750, 'scrapy.contrib.downloadermiddleware.chunked.ChunkedTransferMiddleware': 830, 'scrapy.contrib.downloadermiddleware.stats.DownloaderStats': 850, 'scrapy.contrib.downloadermiddleware.httpcache.HttpCacheMiddleware': 900, }
10、配置之自定义scrapy命令
spider的同级目录,新增目录如commands,创建py文件crawlall.py
from scrapy.commands import ScrapyCommand from scrapy.utils.project import get_project_settings class Command(ScrapyCommand): requires_project = True def syntax(self): return '[options]' def short_desc(self): return 'Runs all of the spiders' def run(self, args, opts): spider_list = self.crawler_process.spider_loader.list() for name in spider_list: self.crawler_process.crawl(name, **opts.__dict__) self.crawler_process.start()
setting中注册,COMMANDS_MODULE='项目名.目录名'
COMMANDS_MODULE='scrapytmp1.commands'
执行命令scrapy crawlall,就能批量执行爬虫

 浙公网安备 33010602011771号
浙公网安备 33010602011771号