
爬虫基础 - feapder框架
1. 基本介绍
简介
feapder是一款上手简单,功能强大的Python爬虫框架,内置AirSpider、Spider、TaskSpider、BatchSpider四种爬虫解决不同场景的需求。- 支持断点续爬、监控报警、浏览器渲染、海量数据去重等功能。
- 更有功能强大的爬虫管理系统
feaplat为其提供方便的部署及调度。
文档地址与环境配置
官方文档:https://feapder.com
# 在安装之前建议使用miniconda3创建一个新的虚拟环境
conda create -n feapder_base python=3.9
conda activate feapder_base
# 完整版安装指令
pip install "feapder[all]"
架构设计
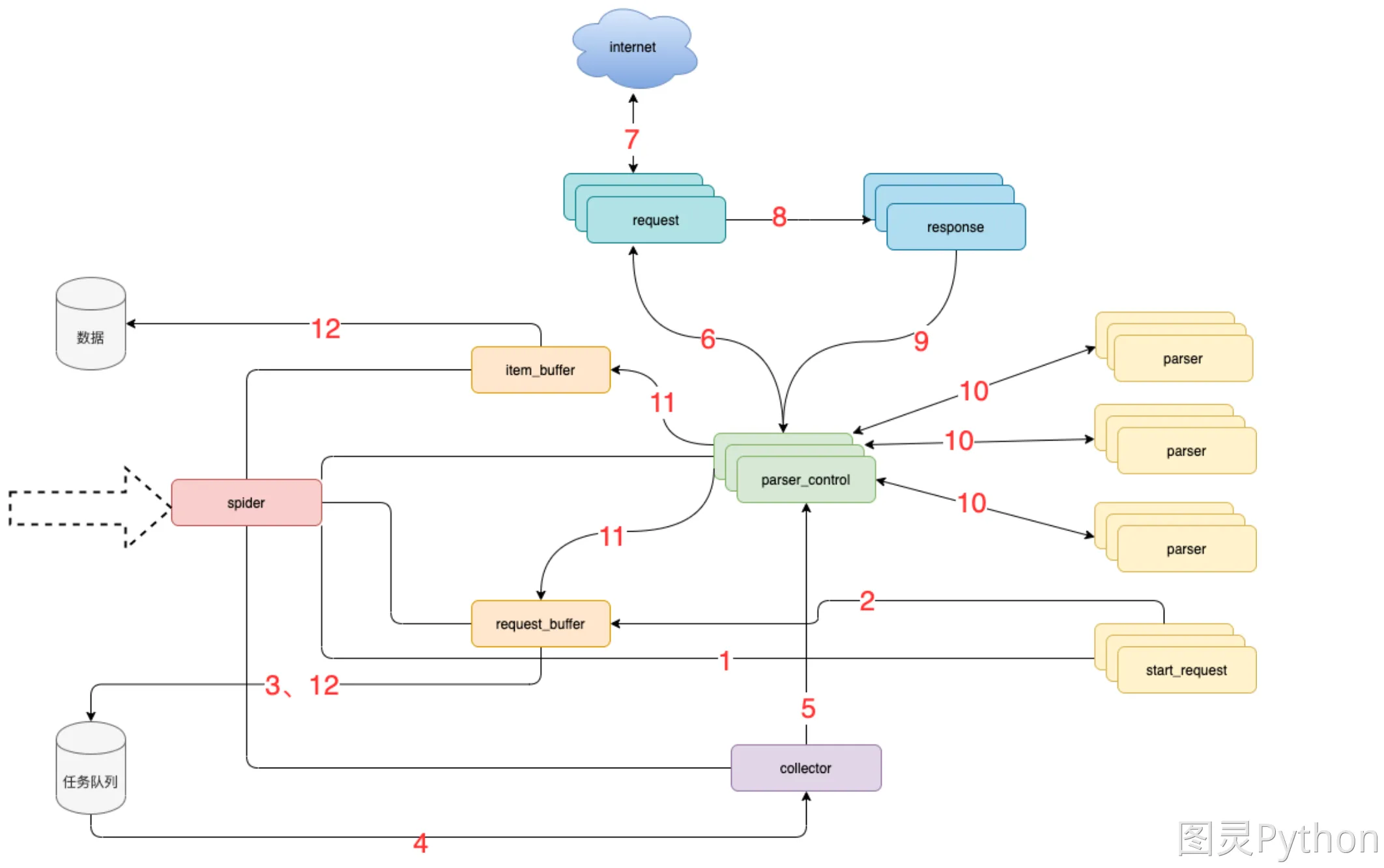
| 模块名称 | 模块功能 |
|---|---|
spider |
框架调度核心 |
parser_control模版控制器 |
负责调度parser |
collector任务收集器 |
负责从任务队里中批量取任务到内存,以减少爬虫对任务队列数据库的访问频率及并发量 |
parser |
数据解析器 |
start_request |
初始任务下发函数 |
item_buffer数据缓冲队列 |
批量将数据存储到数据库中 |
request_buffer请求任务缓冲队列 |
批量将请求任务存储到任务队列中 |
request数据下载器 |
封装了requests,用于从互联网上下载数据 |
response请求响应 |
封装了response, 支持xpath、css、re等解析方式,自动处理中文乱码 |
执行流程
spider调度start_request生产任务start_request下发任务到request_buffer中spider调度request_buffer批量将任务存储到任务队列数据库中spider调度collector从任务队列中批量获取任务到内存队列spider调度parser_control从collector的内存队列中获取任务parser_control调度request请求数据request请求与下载数据request将下载后的数据给response,进一步封装- 将封装好的
response返回给parser_control(图示为多个parser_control,表示多线程) parser_control调度对应的parser,解析返回的response(图示多组parser表示不同的网站解析器)parser_control将parser解析到的数据item及新产生的request分发到item_buffer与request_bufferspider调度item_buffer与request_buffer将数据批量入库
2. 组件详解
2.1 创建爬虫
feapder create -h # 查看帮助
feapder create -s douban # 创建爬虫文件
执行命令后需要手动选择对应的爬虫模板,模板功能如下:
AirSpider轻量爬虫:学习成本低,可快速上手Spider分布式爬虫:支持断点续爬、爬虫报警、数据自动入库等功能TaskSpider分布式爬虫:内部封装了取种子任务的逻辑,内置支持从redis或者mysql获取任务,也可通过自定义实现从其他来源获取任务BatchSpider批次爬虫:可周期性的采集数据,自动将数据按照指定的采集周期划分。(如每7天全量更新一次商品销量的需求)
命令执行成功后选择AirSpider模板。默认生成的代码继承了feapder.AirSpider,包含 start_requests 及 parser 两个函数,含义如下:
feapder.AirSpider:轻量爬虫基类start_requests:初始任务下发入口feapder.Request:基于requests库类似,表示一个请求,支持requests所有参数,同时也可携带些自定义的参数,详情可参考Requestparse:数据解析函数response:请求响应的返回体,支持xpath、re、css等解析方式,详情可参考Response
除了start_requests、parser两个函数。系统还内置了下载中间件等函数,具体支持可参考BaseParser
2.2 使用AirSpider模板
# douban.py
# -*- coding: utf-8 -*-
"""
Created on 2023-12-18 19:10:28
---------
@summary:
---------
@author: poppies
"""
import feapder
class Douban(feapder.AirSpider):
def start_requests(self):
for page in range(10):
yield feapder.Request(f"https://movie.douban.com/top250?start={page * 25}&filter=")
def parse(self, request, response):
li_list = response.xpath('//ol/li/div[@class="item"]')
for li in li_list:
item = dict()
item['title'] = li.xpath('./div[@class="info"]/div/a/span[1]/text()').extract_first()
item['detail_url'] = li.xpath('./div[@class="info"]/div/a/@href').extract_first()
item['score'] = li.xpath('.//div[@class="star"]/span[2]/text()').extract_first()
yield feapder.Request(item['detail_url'], callback=self.parse_detail, item=item)
def parse_detail(self, request, response):
if response.xpath('//div[@class="indent"]/span[@class="all hidden"]//text()'):
request.item['detail_text'] = response.xpath(
'//div[@class="indent"]/span[@class="all hidden"]//text()').extract_first().strip()
else:
request.item['detail_text'] = response.xpath(
'//div[@class="indent"]/span[1]//text()').extract_first().strip()
print(request.item)
if __name__ == "__main__":
# 开启五个线程完成爬虫任务
Douban(thread_count=5).start()
2.3 对接MySQL
在当前目录下创建insert_sql_info.py文件用于数据库建表:
from feapder.db.mysqldb import MysqlDB
db = MysqlDB(ip='localhost', port=3306, user_name='root', user_pass='root', db='py_spider')
sql = """
create table if not exists douban_feapder(
id int primary key auto_increment,
title varchar(255) not null,
score varchar(255) not null,
detail_url varchar(255) not null,
detail_text text
);
"""
db.execute(sql)
# insert ignore: 数据插入,如果数据重复则忽略,例如id重复
insert_sql = """
insert ignore into douban_feapder (id, title, score, detail_url, detail_text) values (
0, '测试数据', 10, 'https://www.baidu.com', '测试数据'
);
"""
db.add(insert_sql)
根据以上案例将豆瓣爬虫中获取的数据存储到MySQL中:
-
在项目文件夹之下创建配置文件用于连接
MySQLfeapder create --setting -
在
setting.py文件中激活MySQL数据库配置# MYSQL MYSQL_IP = "localhost" MYSQL_PORT = 3306 MYSQL_DB = "py_spider" MYSQL_USER_NAME = "root" MYSQL_USER_PASS = "123456" -
创建
items文件# 在创建items文件之前必须确保文件名与数据库已存在的表名一致 feapder create -i douban_feapder# -*- coding: utf-8 -*- """ Created on 2023-12-18 20:10:06 --------- @summary: --------- @author: poppies """ from feapder import Item class DoubanFeapderItem(Item): """ This class was generated by feapder command: feapder create -i douban_feapder """ __table_name__ = "douban_feapder" def __init__(self, *args, **kwargs): # self.id = None self.title = None self.score = None self.detail_url = None self.detail_text = None -
将生成的
DoubanFeapderItem类载入到douban.py文件中# -*- coding: utf-8 -*- """ Created on 2023-12-18 19:10:28 --------- @summary: --------- @author: poppies """ import feapder from douban_feapder_item import DoubanFeapderItem class Douban(feapder.AirSpider): def start_requests(self): for page in range(11): yield feapder.Request(f"https://movie.douban.com/top250?start={page * 25}&filter=") def parse(self, request, response): li_list = response.xpath('//ol/li/div[@class="item"]') for li in li_list: # 将字典类型替换成DoubanFeapderItem用于数据校验 item = DoubanFeapderItem() item['title'] = li.xpath('./div[@class="info"]/div/a/span[1]/text()').extract_first() item['detail_url'] = li.xpath('./div[@class="info"]/div/a/@href').extract_first() item['score'] = li.xpath('.//div[@class="star"]/span[2]/text()').extract_first() yield feapder.Request(item['detail_url'], callback=self.parse_detail, item=item) def parse_detail(self, request, response): if response.xpath('//div[@class="indent"]/span[@class="all hidden"]//text()'): request.item['detail_text'] = response.xpath( '//div[@class="indent"]/span[@class="all hidden"]//text()').extract_first().strip() else: request.item['detail_text'] = response.xpath( '//div[@class="indent"]/span[1]//text()').extract_first().strip() # 执行yield会将解析好的数据保存到数据库中 yield request.item if __name__ == "__main__": Douban().start()
2.4 下载中间件
- 下载中间件用于在请求之前,对请求做一些处理,如添加
cookie、header等 - 默认所有的解析函数在请求之前都会经过此下载中间件
# -*- coding: utf-8 -*-
"""
Created on 2023-12-18 19:10:28
---------
@summary:
---------
@author: poppies
"""
import feapder
class Douban(feapder.AirSpider):
def start_requests(self):
for page in range(11):
yield feapder.Request(f"https://movie.douban.com/top250?start={page * 25}&filter=")
# 默认的下载中间件
def download_midware(self, request):
request.headers = {
'User-Agent': 'abc'
}
request.proxies = {
"http": "http://127.0.0.1:7890"
}
return request
if __name__ == "__main__":
Douban().start()
除了可以重写默认的下载中间件之外,也可以自定义下载中间件:使用Request对象中的download_midware参数指定自己创建的中间件方法名即可。
# -*- coding: utf-8 -*-
"""
Created on 2023-12-18 19:10:28
---------
@summary:
---------
@author: poppies
"""
import feapder
class Douban(feapder.AirSpider):
def start_requests(self):
for page in range(11):
yield feapder.Request(f"https://movie.douban.com/top250?start={page * 25}&filter=",
download_midware=self.custom_download_midware)
def custom_download_midware(self, request):
request.headers = {
'User-Agent': '123'
}
return request
if __name__ == "__main__":
Douban().start()
2.5 校验响应对象
feapder框架给到一个方法validate用来检验返回的数据是否正常。- 框架支持重试机制,下载失败或解析函数抛出异常会自动重试请求。
- 默认最大重试次数为
10次,我们可以引入配置文件或自定义配置来修改重试次数
# 校验函数源码
def validate(self, request, response):
"""
@summary: 校验函数, 可用于校验response是否正确
若函数内抛出异常,则重试请求
若返回True或None,则进入解析函数
若返回False,则抛弃当前请求
可通过request.callback_name 区分不同的回调函数,编写不同的校验逻辑
---------
@param request:
@param response:
---------
@result: True / None / False
"""
pass
代码示例
# -*- coding: utf-8 -*-
"""
Created on 2023-12-18 19:10:28
---------
@summary:
---------
@author: poppies
"""
import feapder
from douban_feapder_item import DoubanFeapderItem
class Douban(feapder.AirSpider):
def start_requests(self):
for page in range(11):
yield feapder.Request(f"https://movie.douban.com/top250?start={page * 25}&filter=", download_midware=self.custom_download_midware)
def custom_download_midware(self, request):
request.headers = {
'User-Agent': '123'
}
request.proxies = {
"http": "http://127.0.0.1:7890"
}
return request
def parse(self, request, response):
li_list = response.xpath('//ol/li/div[@class="item"]')
for li in li_list:
# 将字典类型替换成DoubanFeapderItem用于数据校验
item = DoubanFeapderItem()
item['title'] = li.xpath('./div[@class="info"]/div/a/span[1]/text()').extract_first()
item['detail_url'] = li.xpath('./div[@class="info"]/div/a/@href').extract_first()
item['score'] = li.xpath('.//div[@class="star"]/span[2]/text()').extract_first()
yield feapder.Request(item['detail_url'], callback=self.parse_detail, item=item)
def parse_detail(self, request, response):
if response.xpath('//div[@class="indent"]/span[@class="all hidden"]//text()'):
request.item['detail_text'] = response.xpath(
'//div[@class="indent"]/span[@class="all hidden"]//text()').extract_first().strip()
else:
request.item['detail_text'] = response.xpath(
'//div[@class="indent"]/span[1]//text()').extract_first().strip()
# 执行yield会将解析好的数据保存到数据库中
yield request.item
def validate(self, request, response):
print('响应状态码:', response.status_code)
if response.status_code != 200:
raise Exception("状态码异常") # 请求重试
if __name__ == "__main__":
Douban().start()
2.6 浏览器渲染 - selenium
采集动态页面时(Ajax渲染的页面),常用的有两种方案。一种是找接口拼参数,这种方式比较复杂但效率高,需要一定的爬虫功底;另外一种是采用浏览器渲染的方式,直接获取源码,简单方便
框架内置一个浏览器渲染池,默认的池大小为1,请求时重复利用浏览器实例,只有当代理失效请求异常时,才会销毁、创建一个新的浏览器实例
内置浏览器渲染支持 CHROME、EDGE、PHANTOMJS、FIREFOX
使用方式
def start_requests(self):
# 在返回的Request中传递render=True即可。
yield feapder.Request("https://news.qq.com/", render=True)
注意点:需要在setting.py文件中开启自动化配置。
# 在setting.py中有以下代码配置
# 浏览器渲染
WEBDRIVER = dict(
pool_size=1, # 浏览器的数量
load_images=True, # 是否加载图片
user_agent=None, # 字符串 或 无参函数,返回值为user_agent
proxy=None, # xxx.xxx.xxx.xxx:xxxx 或 无参函数,返回值为代理地址
headless=False, # 是否为无头浏览器
driver_type="CHROME", # CHROME、EDGE、PHANTOMJS、FIREFOX
timeout=30, # 请求超时时间
window_size=(1024, 800), # 窗口大小
executable_path=None, # 浏览器路径,默认为默认路径
render_time=0, # 渲染时长,即打开网页等待指定时间后再获取源码
custom_argument=[
"--ignore-certificate-errors",
"--disable-blink-features=AutomationControlled",
], # 自定义浏览器渲染参数
xhr_url_regexes=None, # 拦截xhr接口,支持正则,数组类型
auto_install_driver=True, # 自动下载浏览器驱动 支持chrome 和 firefox
download_path=None, # 下载文件的路径
use_stealth_js=False, # 使用stealth.min.js隐藏浏览器特征
)
以上配置含有浏览器驱动路径:executable_path,如果在默认情况下启动报错则手动配置浏览器驱动文件路径。
示例代码
import feapder
from selenium.webdriver.common.by import By
from feapder.utils.webdriver import WebDriver
class Baidu(feapder.AirSpider):
def start_requests(self):
yield feapder.Request("https://www.baidu.com", render=True)
def parse(self, request, response):
browser: WebDriver = response.browser
browser.find_element(By.ID, 'kw').send_keys('feapder')
browser.find_element(By.ID, 'su').click()
if __name__ == "__main__":
Baidu().start()
拦截动态数据接口
可以对api数据接口进行拦截,需要在settings.py中配置xhr_url_regexes项。
# 需要在settings.py中配置
WEBDRIVER = dict(
...
xhr_url_regexes=[
"接口1正则",
"接口2正则",
]
)
获取数据
browser: WebDriver = response.browser
# 提取文本
text = browser.xhr_text("接口1正则")
# 提取json
data = browser.xhr_json("接口2正则")
获取对象
browser: WebDriver = response.browser
xhr_response = browser.xhr_response("接口正则")
print("请求接口", xhr_response.request.url)
print("请求头", xhr_response.request.headers)
print("请求体", xhr_response.request.data)
print("返回头", xhr_response.headers)
print("返回地址", xhr_response.url)
print("返回内容", xhr_response.content)
3. 创建完整项目
3.1 创建项目指令
feapder create -p <project_name>
feapder create -p wp_shop
项目创建成功后会存在以下目录:
items文件夹: 存放与数据库表映射的itemspiders文件夹: 文件夹存放爬虫脚本main.py文件: 运行入口setting.py文件: 爬虫配置文件
3.2 数据入库
settings.py配置
# MYSQL
MYSQL_IP = "localhost"
MYSQL_PORT = 3306
MYSQL_DB = "py_spider"
MYSQL_USER_NAME = "root"
MYSQL_USER_PASS = "root"
在项目根目录下创建
create_table.py文件
from feapder.db.mysqldb import MysqlDB
db = MysqlDB(ip='localhost', user_name='root', user_pass='root', db='py_spider')
create_table_sql = """
create table wp_shop_info(
id int primary key auto_increment,
title varchar(255) default null,
price varchar(255) default null
);
"""
db.execute(create_table_sql)
创建items文件
cd items
# item文件名称是数据表名称
feapder create -i wp_shop_info
3.3 创建爬虫脚本
cd spiders
feapder create -s wp_spider
wp_spider.py
# -*- coding: utf-8 -*-
"""
Created on 2024-03-19 20:32:21
---------
@summary:
---------
@author: poppies
"""
import time
import feapder
from random import randint
from items import wp_shop_info_item
from selenium.webdriver.common.by import By
from feapder.utils.webdriver import WebDriver
class WpSpider(feapder.AirSpider):
def start_requests(self):
url = 'https://category.vip.com/suggest.php?keyword=%E7%94%B5%E8%84%91&ff=235%7C12%7C1%7C1&page={}'
for page in range(1, 13):
yield feapder.Request(url=url.format(page), render=True)
def parse(self, request, response):
browser: WebDriver = response.browser
# 让浏览器等待加载数据
time.sleep(2)
# 页面下滑
self.drop_down(browser)
div_list = browser.find_elements(
By.XPATH,
'//section[@id="J_searchCatList"]/div[@class="c-goods-item J-goods-item c-goods-item--auto-width"]'
)
for div in div_list:
price = div.find_element(By.XPATH,
'.//div[@class="c-goods-item__sale-price J-goods-item__sale-price"]').text
title = div.find_element(By.XPATH, './/div[2]/div[2]').text
item = wp_shop_info_item.WpShopInfoItem()
item['title'] = title
item['price'] = price
# print(item)
yield item # 将商品数据保存到MySQL中
def drop_down(self, browser):
for i in range(1, 12):
js_code = f'document.documentElement.scrollTop = {i * 1000}'
browser.execute_script(js_code)
time.sleep(randint(1, 2))
if __name__ == "__main__":
# thread_count表示开启的线程数量
WpSpider(thread_count=1).start()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号