

爬虫基础 - scrapy框架
1. 启动命令和配置
创建scrapy项目的命令:
1. scrapy startproject 项目名称
2. scrapy genspider 爬虫名称 域名(创建爬虫文件之前需要手动进入到这个项目的根目录之下)
启动scrapy项目的命令:
scrapy crawl 爬虫名称
如果大家在执行这个脚本之后控制台报错:
pip install Twisted==22.10.0
pip install urllib3==1.26.18
pip install parsel==1.7.0
scrapy默认遵守rebots协议,如果要关闭robots协议的检测,需要在settings.py文件中设置ROBOTSTXT_OBEY = False
日志等级设置(在settings.py中):默认DEBUG
LOG_LEVEL = 'WARNING'
2. scrapy内置模块

注意:爬虫中间件和下载中间件只是运行逻辑的位置不同,作用是重复的:如替换User-Agent等。
3. scrapy框架的执行流程
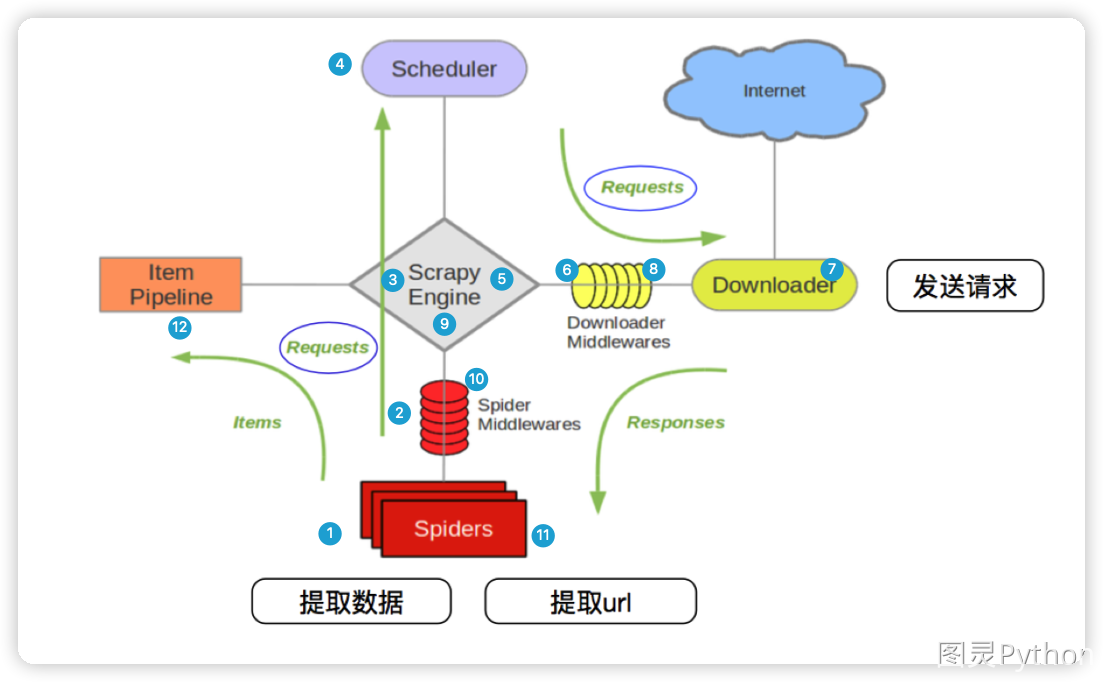
上图中的1 - 12序号的解释说明:
scrapy从spider子类中提取start_urls,然后构造为request请求对象- 将
request请求对象传递给爬虫中间件 - 将
request请求对象传递给scrapy引擎(就是核心代码) - 将
request请求对象传递给调度器(它负责对多个request调度,好比交通管理员负责交通的指挥员) - 将
request请求对象传递给scrapy引擎 scrapy引擎将request请求对象传递给下载中间件(可以更换代理IP,更换Cookies,更换User-Agent,自动重试。等)request请求对象传给到下载器(下载器通过异步的方式发送HTTP(S)请求),得到响应封装为response对象- 将
response对象传递给下载中间件 - 下载中间件将
response对象传递给scrapy引擎 scrapy引擎将response对象传递给爬虫中间件(这里可以处理异常等情况)- 爬虫对象中的
parse函数被调用(在这里可以对得到的response对象进行处理,例如用status得到响应状态码,xpath可以进行提取数据等) - 将提取到的数据传递给
scrapy引擎,它将数据再传递给管道(在管道中我们可以将数据存储到csv、MongoDB等)
4. 多数据存储
spider文件: fm/spiders/qingting.py
import scrapy
from scrapy import cmdline
from scrapy.http import HtmlResponse
class QingTingSpider(scrapy.Spider):
name = 'qingting'
start_urls = ['https://m.qingting.fm/rank/']
def parse(self, response: HtmlResponse, **kwargs):
rank_list = response.xpath('//div[@class="rank-list"]/a')
for rank in rank_list:
rank_number = rank.xpath('./div[@class="badge"]/text()').extract_first()
img_url = rank.xpath('./img/@src').extract_first()
title = rank.xpath('.//div[@class="title"]/text()').extract_first()
description = rank.xpath('.//div[@class="desc"]/text()').extract_first()
data_info_dict = {
'type': 'text',
'rank_number': rank_number,
'img_url': img_url,
'title': title,
'description': description,
}
yield data_info_dict
# yield关键字可以返回request对象/如果你解析出来的数据包含了这条数据的详情页面 我就需要二次发包去请求这个详情页面
yield scrapy.Request(img_url, callback=self.parse_image, cb_kwargs={'image_name': title})
def parse_image(self, response: HtmlResponse, image_name):
# 清理文件名中的非法字符
import re
clean_name = re.sub(r'[\\/:*?"<>|]', '_', image_name)
image_info_dict = {
'type': 'image',
'image_name': clean_name + '.png',
'image_content': response.body
}
yield image_info_dict
if __name__ == '__main__':
cmdline.execute('scrapy crawl qingting'.split())
管道文件:fm/pipelines.py
import os
import pymongo
from itemadapter import ItemAdapter
# 在使用管道时需要在settings中激活
class FmPipeline:
def __del__(self): # 析构函数, 当对象被销毁时自动调用
print('数据库链接即将关闭...')
self.mongo_client.close()
mongo_client = pymongo.MongoClient()
db = mongo_client['py_spider']['scrapy_fm_info']
def process_item(self, item, spider):
type_ = item.get('type')
if type_ == 'text':
self.db.insert_one(item)
elif type_ == 'image':
download_path = os.getcwd() + '/download_images/'
print('创建的文件夹路径信息为:', download_path)
if not os.path.exists(download_path):
os.mkdir(download_path)
image_name = item.get('image_name')
image_content = item.get('image_content')
with open(download_path + image_name, 'wb') as f:
f.write(image_content)
print('图片保存成功:', image_name)
else:
print('未知类型, 无法处理...')
5. 通过下载器中间件配置随机UA
# 自定义下载器中间件(自定义的中间件类需要在配置文件中注册)
class DoubanSetUADownloaderMiddleware:
user_agent_list = [
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Win64; x64; Trident/5.0; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 2.0.50727; Media Center PC 6.0)",
"Mozilla/5.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0; WOW64; Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 1.0.3705; .NET CLR 1.1.4322)",
"Mozilla/4.0 (compatible; MSIE 7.0b; Windows NT 5.2; .NET CLR 1.1.4322; .NET CLR 2.0.50727; InfoPath.2; .NET CLR 3.0.04506.30)",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN) AppleWebKit/523.15 (KHTML, like Gecko, Safari/419.3) Arora/0.3 (Change: 287 c9dfb30)",
"Mozilla/5.0 (X11; U; Linux; en-US) AppleWebKit/527+ (KHTML, like Gecko, Safari/419.3) Arora/0.6",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.8.1.2pre) Gecko/20070215 K-Ninja/2.1.1",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN; rv:1.9) Gecko/20080705 Firefox/3.0 Kapiko/3.0",
"Mozilla/5.0 (X11; Linux i686; U;) Gecko/20070322 Kazehakase/0.4.5"
]
def process_request(self, request, spider):
print('这是我自定义的一个下载中间件...')
request.headers['User-Agent'] = random.choice(self.user_agent_list)
print('通过中间件设置的UA信息:', request.headers)
6. 使用中间件配置代理
spider文件:douban/spiders/top250.py
import scrapy
from scrapy.http import HtmlResponse
from scrapy import cmdline
class Top250Spider(scrapy.Spider):
name = 'top250'
def start_requests(self):
# for page in range(0, 1):
# url = f'https://movie.douban.com/top250?start={page * 25}&filter='
# yield scrapy.Request(url)
url = "https://dev.kdlapi.com/testproxy"
yield scrapy.Request(url)
def parse(self, response: HtmlResponse, **kwargs):
print('这是在解析函数中获取到的请求头信息:', response.request.headers)
print('这是在解析函数中获取到的代理信息:', response.request.meta.get('proxy'))
print(response.text)
if __name__ == '__main__':
cmdline.execute('scrapy crawl top250 --nolog'.split())
快代理api文件:douban/my_extend.py
#!/usr/bin/env python
# -- coding: utf-8 --
import time
import threading
import requests
from scrapy import signals
# 提取代理IP的api: 在快代理中:私密代理-代理提取-生成api链接(返回格式选json)-生成链接
api_url = 'https://dps.kdlapi.com/api/getdps/?secret_id=olu122c9ruw7k63zj9cq&signature=on4xst0s8m4ksn4qn3bq3x50nn&num=1&format=json&sep=1'
foo = True
class Proxy:
def __init__(self, ):
self._proxy_list = requests.get(api_url).json().get('data').get('proxy_list')
@property
def proxy_list(self):
return self._proxy_list
@proxy_list.setter
def proxy_list(self, list):
self._proxy_list = list
pro = Proxy()
# print(pro.proxy_list)
class MyExtend:
def __init__(self, crawler):
self.crawler = crawler
# 将自定义方法绑定到scrapy信号上,使程序与spider引擎同步启动与关闭
# scrapy信号文档: https://www.osgeo.cn/scrapy/topics/signals.html
# scrapy自定义拓展文档: https://www.osgeo.cn/scrapy/topics/extensions.html
crawler.signals.connect(self.start, signals.engine_started)
crawler.signals.connect(self.close, signals.spider_closed)
@classmethod
def from_crawler(cls, crawler):
return cls(crawler)
def start(self):
t = threading.Thread(target=self.extract_proxy)
t.start()
def extract_proxy(self):
while foo:
pro.proxy_list = requests.get(api_url).json().get('data').get('proxy_list')
# 设置每15秒提取一次ip
time.sleep(15)
def close(self):
global foo
foo = False
下载器中间件增加代理下载器中间件:douban/middlewares.py
import random
from my_extend import pro
from scrapy import signals
class ProxyDownloaderMiddleware:
def process_request(self, request, spider):
proxy = random.choice(pro.proxy_list)
# 用户名密码认证(私密代理/独享代理)
username = "d4672593640"
password = "njoz8c6s"
request.meta['proxy'] = "http://%(user)s:%(pwd)s@%(proxy)s/" % {"user": username, "pwd": password,
"proxy": proxy}
# 白名单认证(私密代理/独享代理)
# request.meta['proxy'] = "http://%(proxy)s/" % {"proxy": proxy}
return None
7. 使用中间件对接selenium
需要在middlewares.py中配置下载器中间件。
import scrapy.http
from scrapy import signals
from selenium import webdriver
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
class SeleniumDownloaderMiddleware:
def __init__(self):
self.browser = webdriver.Chrome()
@classmethod
def from_crawler(cls, crawler):
# This method is used by Scrapy to create your spiders.
s = cls()
# 如果scrapy关闭则关闭browser
crawler.signals.connect(s.spider_closed, signal=signals.spider_closed)
return s
def process_request(self, request, spider):
self.browser.get(request.url)
wait = WebDriverWait(self.browser, 10)
wait.until(EC.presence_of_all_elements_located((By.CLASS_NAME, 'recruit-list')))
# 返回渲染之后html源代码
body = self.browser.page_source
return scrapy.http.HtmlResponse(url=request.url, body=body, encoding='utf-8', request=request)
def spider_closed(self, spider):
self.browser.quit()
8. 利用多管道分别保存数据
from itemadapter import ItemAdapter
import json
import pymongo
class TxWorkFilePipeline:
def __init__(self):
self.file_obj = None
def open_spider(self, spider):
if spider.name == 'tx_work_info':
self.file_obj = open('tx_work.txt', 'a', encoding='utf-8')
def process_item(self, item, spider):
if spider.name == 'tx_work_info':
self.file_obj.write(json.dumps(item, ensure_ascii=False, indent=4) + '\n')
print('数据写入文件成功: ', item.get('title'))
return item
def close_spider(self, spider):
if spider.name == 'tx_work_info':
self.file_obj.close()
class TxWorkMongoPipeline:
def __init__(self):
self.mongo_client = None
self.db = None
def open_spider(self, spider):
if spider.name == 'tx_work_info':
self.mongo_client = pymongo.MongoClient()
self.db = self.mongo_client['py_spider']['tx_work_info']
def process_item(self, item, spider):
if spider.name == 'tx_work_info':
self.db.insert_one(item)
print('数据插入数据库成功: ', item['title'])
return item
def close_spider(self, spider):
if spider.name == 'tx_work_info':
self.mongo_client.close()
9. 使用中间件对返回的数据进行解密
spider文件
import scrapy
from scrapy import cmdline
from scrapy.http import HtmlResponse, FormRequest
class DecryptInfoSpider(scrapy.Spider):
name = 'decrypt_info'
def start_requests(self):
url = 'https://www.endata.com.cn/API/GetData.ashx'
data = {
"startTime": "2025-05-01",
"MethodName": "BoxOffice_GetMonthBox"
}
yield FormRequest(url=url, formdata=data, callback=self.parse)
def parse(self, response: HtmlResponse, **kwargs):
print(type(response.text))
print(type(response.json()))
print('解密后的数据为:', response.json())
if __name__ == '__main__':
cmdline.execute('scrapy crawl decrypt_info --nolog'.split())
加入js解密文件
在spiders目录下新增utils目录,加入decrypt_info.js文件。
解密下载器中间件
import os
import subprocess
from scrapy import signals
from scrapy.http import HtmlResponse
from functools import partial
# 在导入execjs之前需要先修改编码集
# 资料:https://blog.51cto.com/YangPC/5482985
subprocess.Popen = partial(subprocess.Popen, encoding="utf-8")
import execjs # pip install pyexecjs
class DesDecryptDownloaderMiddleware:
def __init__(self):
js_path = os.path.join(os.getcwd(), 'utils', 'decrypt_info.js')
if not os.path.exists(js_path):
raise FileNotFoundError(f'解密文件未找到,文件地址为: {js_path}')
with open(js_path, 'r', encoding='utf-8') as f:
self.js_code = f.read()
self.ctx = execjs.compile(self.js_code)
def process_response(self, request, response, spider):
try:
# 解密响应内容
decrypt_data = self.ctx.call('webInstace.shell', response.text)
return HtmlResponse(request=request, body=decrypt_data.encode('utf-8'), encoding='utf-8', url=response.url)
except Exception as e:
spider.logger.error('解密失败: ', e)
return response
10. 数据去重
利用下载器中间件对重复url进行过滤
from scrapy.exceptions import IgnoreRequest
import redis
class FilterDuplicateDownloaderMiddleware:
def __init__(self):
self.redis_client = redis.Redis()
def process_request(self, request, spider):
md5_hash = hashlib.md5()
md5_hash.update(request.url.encode('utf-8'))
hash_value = md5_hash.hexdigest()
if self.redis_client.get(f'tx_work_url_filter: {hash_value}'):
spider.logger.warning(f'请求url重复: {request.url}')
raise IgnoreRequest('请求url重复: ', request.url)
else:
self.redis_client.set(f'tx_work_url_filter: {hash_value}', request.url)
return None
def spider_closed(self, spider):
self.redis_client.close()
在管道中对重复item进行去重
import json
import pymongo
import redis
import hashlib
from scrapy.exceptions import DropItem
class TxWorkPipeline:
def __init__(self):
self.redis_client = None
self.mongo_client = None
self.mongo_db = None
def open_spider(self, spider):
self.redis_client = redis.Redis()
self.mongo_client = pymongo.MongoClient()
self.mongo_db = self.mongo_client['py_spider']['tx_work_info']
spider.logger.info('打开redis和mongoDB')
def process_item(self, item, spider):
if spider.name == 'tx_work_info':
item_str = json.dumps(item)
md5_hash = hashlib.md5()
md5_hash.update(item_str.encode('utf-8'))
hash_value = md5_hash.hexdigest()
if self.redis_client.get(f'tx_work_item_filter:{hash_value}'):
raise DropItem('数据已存在...')
else:
self.redis_client.set(f'tx_work_item_filter:{hash_value}', item_str)
self.mongo_db.insert_one(item)
spider.logger.info('数据插入成功: ', item['title'])
return item
def close_spider(self, spider):
self.redis_client.close()
self.mongo_client.close()
spider.logger.info('关闭redis和mongoDB')
11. scrapy-redis组件
11.1 概念
scrapy是一个通用的爬虫框架,能够耗费很少的时间就能够写出爬虫代码。scrapy-redis是scrapy的一个组件,它使用了redis数据库做为基础,目的为了更方便地让scrapy`实现分布式爬取。
scrapy能做的事情很多,但是要做到大规模的分布式应用则捉襟见肘。有人改变了scrapy的队列调度,将起始的网址从start_urls里分离出来,改为从redis读取,多个客户端可以同时读取同一个redis,从而实现了分布式的爬虫。
11.2 作用
scrapy-redis在scrapy的基础上实现了更多更强大的功能,具体体现在:
通过持久化请求队列和请求的指纹集合来实现:
- 断点续爬(增量爬虫)
通俗的说:这次爬取的数据,下载再运行时不会爬取,只爬取之前没有爬过的数据 - 分布式快速抓取
通俗的说:多个电脑(也可以在一个电脑上运行多个程序来模拟)可以一起爬取数据,而且不会有冲突
11.3 scrapy-redis的工作流程
scrapy的流程(与之前所讲的scrapy图解一样,只是表现形式不一样)

- scrapy-redis`实现分布式图解
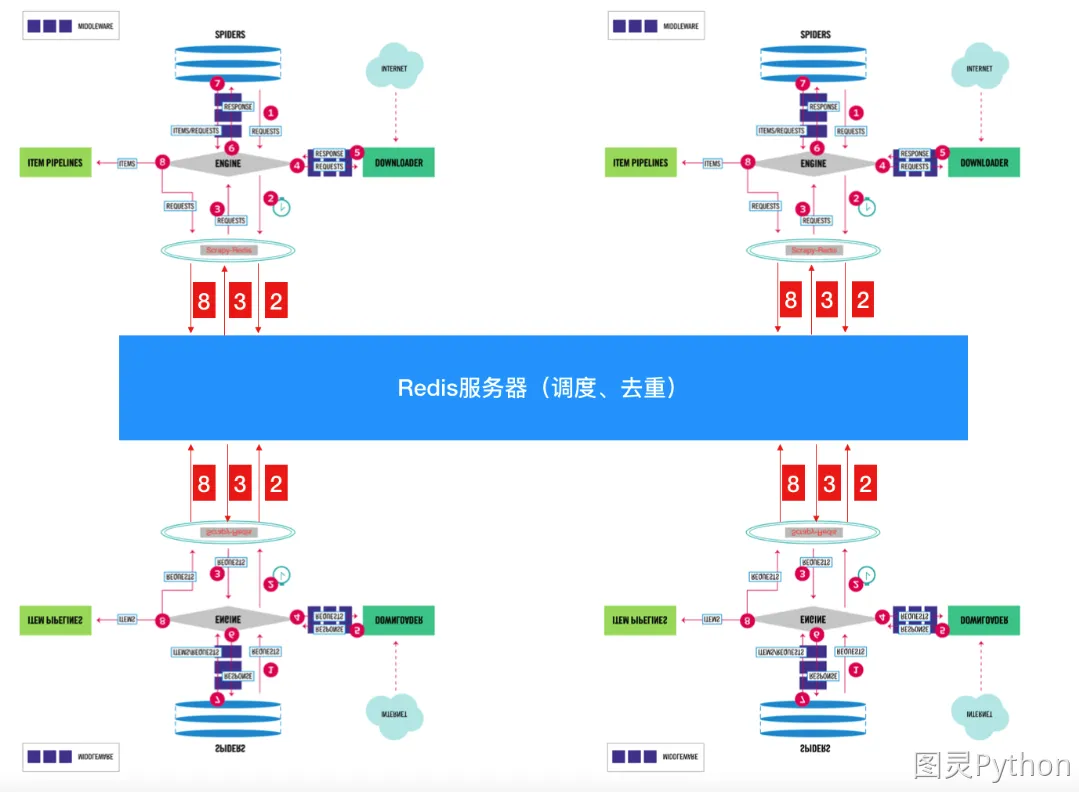
说明:原本只有1个scrapy时,它所有的请求对象request都直接存放到了内存中,此时可以完成本台电脑上scrapy的功能,但是其他电脑上的scrapy是不能够获取另外一台电脑内存中的数据的,所以借助了Redis数据库。将原本直接存储到内存中的数据(像请求对象等)放到了Redis数据库中(因为Redis效率非常高,所以用它而不用MySQL、MongoDB),又因为Redis是支持网络访问的,所以在本电脑上的Redis中存储的数据,就可以让其他电脑上的scrapy去共用,此时哪个请求对象已经处理过,哪个没有并处理过,一目了然。
注意点
- 在
scrapy-redis中,所有的待抓取的request对象和去重的request对象指纹都存在共用的redis中(待抓取的在名为requests的zset集中,已抓取的对象指纹在名为dupefilter集合中) - 所有的服务器中的
scrapy进程共用同一个redis中的request对象的队列 - 所有的
request对象存入redis前,都会通过该redis中的request指纹集合进行判断,之前是否已经存入过 - 在默认情况下所有的数据会保存在
redis中

11.4 scrapy-redis分布式架构的思路分析
假设有四台电脑:Windows 10、Mac OS X、Ubuntu 16.04、CentOS 7.2任意一台电脑都可以作为Master端或Slaver端。
Master端(核心服务器) :使用Windows 10,搭建一个Redis数据库,不负责爬取,只负责url指纹判重、Request的分配,以及数据的存储Slaver端(爬虫程序执行端) :使用Mac OS X、Ubuntu 16.04、CentOS 7.2负责执行爬虫程序,运行过程中提交新的Request给Master
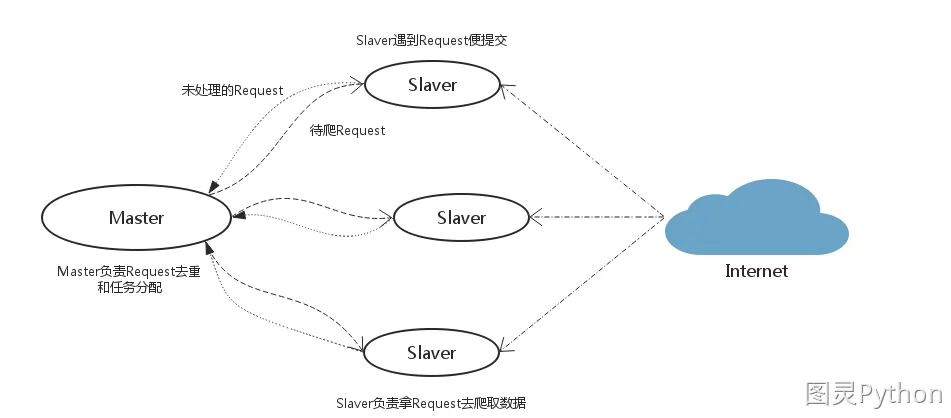
执行流程
- 首先
Slaver端从Master端拿任务(Request、url)进行数据抓取,Slaver抓取数据的同时,产生新任务的Request便提交给Master处理; Master端只有一个Redis数据库,负责将未处理的Request去重和任务分配,将处理后的Request加入待爬队列,并且存储爬取的数据。
scrapy-redis默认使用的就是这种策略,我们实现起来很简单,因为任务调度等工作scrapy-redis都已经帮我们做好了,我们只需要继承RedisSpider、指定redis_key就行了。
缺点:scrapy-redis调度的任务是Request对象,里面信息量比较大(不仅包含url,还有callback函数、headers等信息),可能导致的结果就是会降低爬虫速度、而且会占用Redis大量的存储空间,所以如果要保证效率,那么就需要一定硬件水平。
11.5 增量爬虫
想要让scrapy实现增量爬取(即暂停、恢复)功能,只需要在scrapy项目中的settings.py文件中进行配置。其它与scrapy项目一致即可。
scrapy-redis配置详解
""" scrapy-redis配置 """
# 调度器类
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
# 指纹去重类
"""
指纹是指使用哈希值标识一个请求对象
确保每个对象都是唯一的
"""
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
# 可以替换成布隆过滤器
# 下载 - pip install scrapy-redis-bloomfilter
# from scrapy_redis_bloomfilter.dupefilter import RFPDupeFilter
# DUPEFILTER_CLASS = 'scrapy_redis_bloomfilter.dupefilter.RFPDupeFilter'
# 是否在关闭时候保留原来的调度器和去重记录,True=保留,False=清空
SCHEDULER_PERSIST = True
# Redis服务器地址
REDIS_URL = "redis://127.0.0.1:6379/0" # Redis默认有16库,/1的意思是使用序号为2的库,默认是0号库(这个可以任意)
SCHEDULER_QUEUE_CLASS = 'scrapy_redis.queue.PriorityQueue' # 优先级队列, 使用有序集合来存储
# SCHEDULER_QUEUE_CLASS = 'scrapy_redis.queue.FifoQueue' # 先进先出
# SCHEDULER_QUEUE_CLASS = 'scrapy_redis.queue.LifoQueue' # 先进后出、后进先出
# 配置redis管道
# from scrapy_redis.pipelines import RedisPipeline
ITEM_PIPELINES = {
"douban.pipelines.DoubanPipeline": 300,
# 可以将获取到的数据存储在redis中, 如果不期望将数据存储在redis则注释以下中间件
# 'scrapy_redis.pipelines.RedisPipeline': 301
}
# 重爬: 一般不配置,在分布式中使用重爬机制会导致数据混乱,默认是False
# SCHEDULER_FLUSH_ON_START = True
通常简化为:
"""scrapy-redis配置项"""
SCHEDULER_PERSIST = True
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
REDIS_URL = 'redis://localhost:6379/2' # 这里的2为redis仓库索引
SCHEDULER_QUEUE_CLASS = 'scrapy_redis.queue.PriorityQueue'
11.6 分布式爬虫
get请求类型
-
settings.py增加以下配置项
"""scrapy-redis配置项""" SCHEDULER_PERSIST = True SCHEDULER = "scrapy_redis.scheduler.Scheduler" DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter" REDIS_URL = 'redis://localhost:6379/2' # 这里的2为redis仓库索引 SCHEDULER_QUEUE_CLASS = 'scrapy_redis.queue.PriorityQueue' -
手写insert_start_url.py,手动向redis注入start_urls
import redis with redis.Redis() as redis_client: for page in range(0, 5): redis_client.lpush('top250:start_urls', f'https://movie.douban.com/top250?start={page * 25}&filter=') print('插入完成...') """ 如果这个脚本没有被执行,那么在执行爬虫的时候,会从redis中获取start_urls, 如果redis中没有start_urls, 整个程序会堵塞 """ -
spider.py文件
- 继承类改为RedisSpider
- 增加类属性:redis_key
import scrapy from scrapy import cmdline from scrapy.http import HtmlResponse from scrapy_redis.spiders import RedisSpider class Top250Spider(RedisSpider): name = 'top250' redis_key = 'top250:start_urls' # 在redis中配置指定的key用于存放起始访问地址 def parse(self, response: HtmlResponse, **kwargs): li_list = response.xpath('//ol[@class="grid_view"]/li') for li_temp in li_list: info_dict = dict() image = li_temp.xpath(".//img/@src").extract_first() title = li_temp.xpath(".//span[@class='title'][1]/text()").extract_first() rating_num = li_temp.xpath(".//span[@class='rating_num']/text()").extract_first() people_num = li_temp.xpath(".//div[@class='star']/span[4]/text()").extract_first() # 如果使用items验证字段, 在缺少字段的情况下能验证通过, 多出的字段不行 info_dict['type_'] = 'info' info_dict['image'] = image info_dict['title'] = title info_dict['rating_num'] = rating_num # info_dict['people_num'] = people_num yield info_dict yield scrapy.Request(image, callback=self.parse_image, cb_kwargs={'image_name': title}) def parse_image(self, response, image_name): yield { 'type_': 'image', 'image_name': image_name + '.jpg', 'image_content': response.body } if __name__ == '__main__': cmdline.execute('scrapy crawl top250'.split())
post请求类型
由于post请求url不变,需要将所有的请求参数提前注入redis。
-
发送表单数据
手动向redis中注入全部请求参数
import json import redis def push_start_form(redis_client_obj, form_data_detail): redis_client_obj.lpush('jc_json_detail:start_forms', form_data_detail) print('数据上传成功:', form_data_detail) if __name__ == '__main__': with redis.Redis(db=3) as redis_client: for page in range(1, 11): form_data = { "column": "szse_latest", "pageNum": str(page), "pageSize": "30", "sortName": "", "sortType": "", "clusterFlag": "true" } form_data_dict = { 'form_data': form_data } # redis数据库无法直接存储字典对象 push_start_form(redis_client, json.dumps(form_data_dict))spider文件
import json import scrapy from scrapy import cmdline from scrapy.http import HtmlResponse from scrapy_redis.spiders import RedisSpider class JcJsonDetailSpider(RedisSpider): name = 'jc_json_detail' redis_key = 'jc_json_detail:start_forms' def make_request_from_data(self, data): """ data: 在当前参数中可能会包含form表单、json载荷信息、url请求地址 """ api_url = 'http://www.cninfo.com.cn/new/disclosure' dict_data = json.loads(data) # redis返回的数据都是字符串 form_data = dict_data.get('form_data') # make_request_from_data方法中返回请求对象必须使用return而不是yield return scrapy.FormRequest(api_url, formdata=form_data, callback=self.parse) def parse(self, response: HtmlResponse, **kwargs): print('响应信息:', response.json()) if __name__ == '__main__': cmdline.execute('scrapy crawl jc_json_detail'.split()) -
发送载荷数据
手动向redis中注入全部请求参数
import json import redis def push_start_payload(redis_client_obj, payload_detail): redis_client_obj.lpush('job_info:start_payload', payload_detail) print('载荷信息上传成功:', payload_detail) if __name__ == '__main__': with redis.Redis(db=4) as redis_client: for page in range(1, 238): payload_info = { "currentPage": page, "pageSize": 10 } json_data = { 'json_data': payload_info } push_start_payload(redis_client, json.dumps(json_data))spider文件
import json import scrapy from scrapy import cmdline from scrapy_redis.spiders import RedisSpider from scrapy.http import HtmlResponse, JsonRequest class JobInfoSpider(RedisSpider): name = 'job_info' redis_key = 'job_info:start_payload' def make_request_from_data(self, data): api_url = 'https://hr.163.com/api/hr163/position/queryPage' data = json.loads(data) json_data = data.get('json_data') return JsonRequest(api_url, data=json_data, callback=self.parse) def parse(self, response: HtmlResponse, **kwargs): print('返回的数据信息为:', response.json()) if __name__ == '__main__': cmdline.execute('scrapy crawl job_info'.split())

 浙公网安备 33010602011771号
浙公网安备 33010602011771号