

转载-网络-网络收包详细过程
原文链接:十年码农内功:网络收包详细过程(一) - 科英的文章 - 知乎 https://zhuanlan.zhihu.com/p/643195830
基于 Linux 内核 6.0、64 位系统和 Intel 网卡驱动 igb。
前面主要介绍了系统启动时的初始化操作,接下来开始正式介绍网络的详细收包过程,从网络接口层(L1)、网络层(L2)、传输层(L3)、套接字(L3.5)再到应用层(L4)的整个过程。

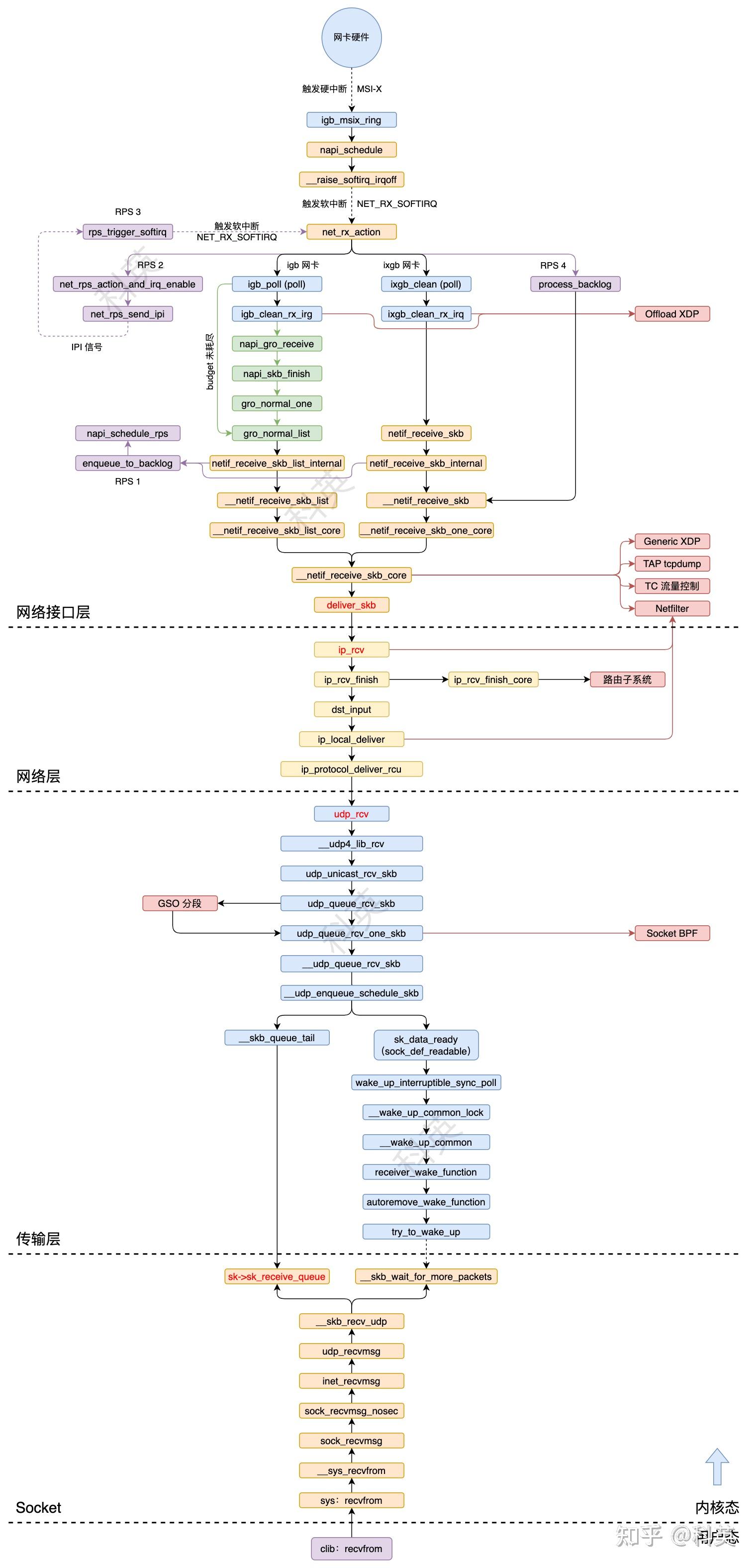
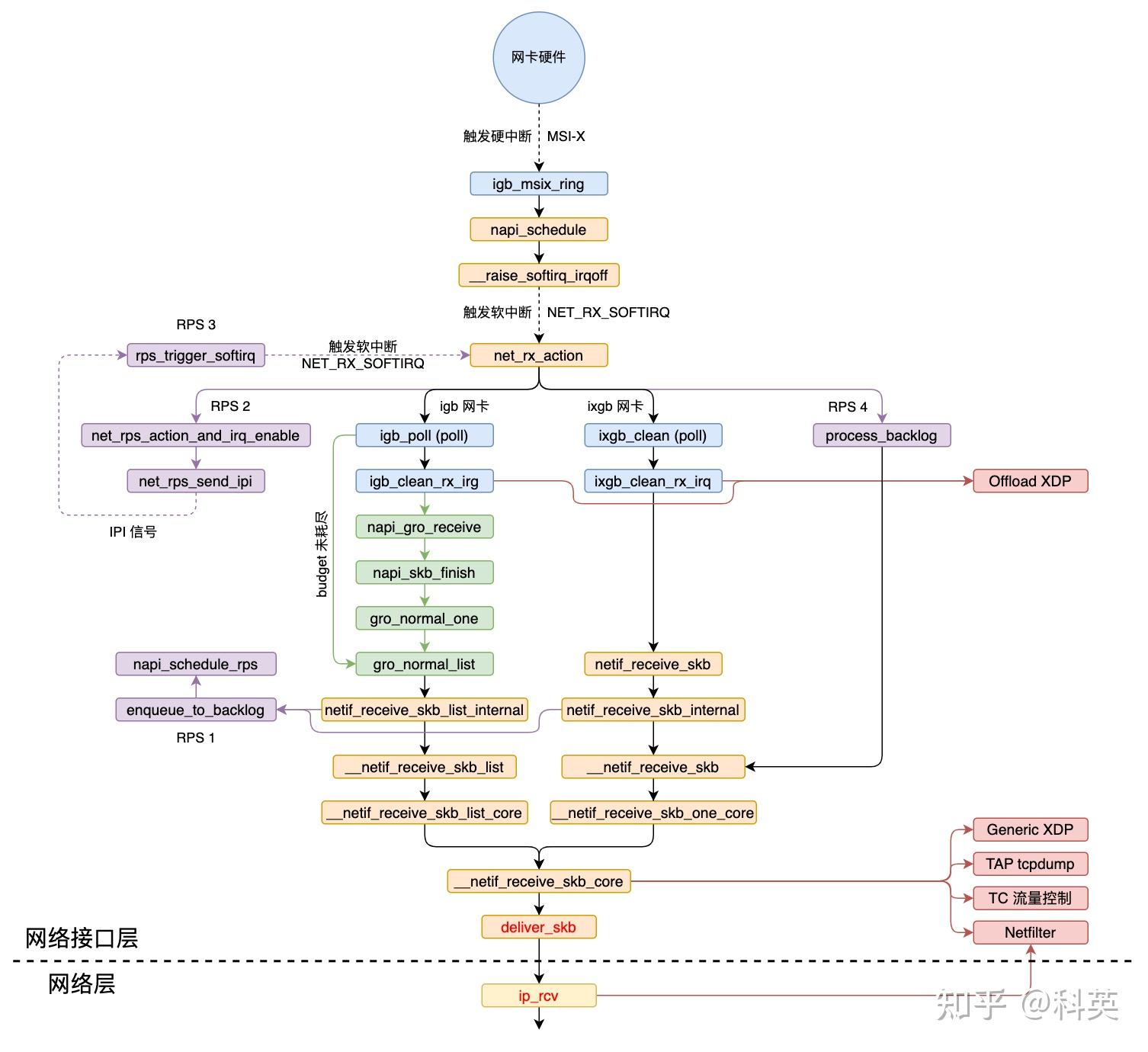
从硬中断到协议栈的调用链:
一、系统启动
1.1 概述
- 网卡驱动的加载
- 网卡驱动的初始化(probe)
- 网卡设备的启用(ndo_open)
- 软中断进程初始化(ksoftirqd)
- 网络子系统初始化(net)
- 网络协议栈初始化
1.2 网卡驱动的加载
网卡需要有驱动才能工作,驱动是加载到内核中的模块,负责衔接网卡和内核。当相应的网卡收到数据包时,网络模块会调用相应的驱动程序处理数据。网卡驱动程序 igb 向 Linux 内核通过 module_init 宏注册一个初始化函数 igb_init_module,当驱动加载的时候,该函数被内核调用。
static struct pci_driver igb_driver = {
.name = igb_driver_name, //igb
.id_table = igb_pci_tbl,
.probe = igb_probe,
.remove = igb_remove,
#ifdef CONFIG_PM
.driver.pm = &igb_pm_ops,
#endif
.shutdown = igb_shutdown,
.sriov_configure = igb_pci_sriov_configure,
.err_handler = &igb_err_handler
};
static int __init igb_init_module(void)
{
int ret;
pr_info("%s\n", igb_driver_string);
pr_info("%s\n", igb_copyright);
#ifdef CONFIG_IGB_DCA
dca_register_notify(&dca_notifier);
#endif
ret = pci_register_driver(&igb_driver);
return ret;
}
module_init(igb_init_module);
igb_init_module 函数的大部分工作是通过 pci_register_driver 内 __pci_register_driver 函数来完成的。
int __pci_register_driver(struct pci_driver *drv, struct module *owner, const char *mod_name)
{
/* initialize common driver fields */
drv->driver.name = drv->name;
drv->driver.bus = &pci_bus_type;
drv->driver.owner = owner;
drv->driver.mod_name = mod_name;
drv->driver.groups = drv->groups;
drv->driver.dev_groups = drv->dev_groups;
spin_lock_init(&drv->dynids.lock);
INIT_LIST_HEAD(&drv->dynids.list);
/* register with core */
return driver_register(&drv->driver);
}
最后 driver_register 函数把网卡的驱动(driver)加载到内核 PCI 子系统。
1.3 网卡驱动的初始化(probe)
一个驱动程序可以支持一个或多个设备,而一个设备只会绑定一个驱动程序。驱动程序将其支持的所有设备保存在一个列表 struct pci_device_id 中。igb 驱动程序所支持的 PCI 设备列表部分如下:
static const struct pci_device_id igb_pci_tbl[] = {
{ PCI_VDEVICE(INTEL, E1000_DEV_ID_I354_BACKPLANE_1GBPS) },
{ PCI_VDEVICE(INTEL, E1000_DEV_ID_I354_SGMII) },
{ PCI_VDEVICE(INTEL, E1000_DEV_ID_I354_BACKPLANE_2_5GBPS) },
{ PCI_VDEVICE(INTEL, E1000_DEV_ID_I211_COPPER), board_82575 },
{ PCI_VDEVICE(INTEL, E1000_DEV_ID_I210_COPPER), board_82575 },
{ PCI_VDEVICE(INTEL, E1000_DEV_ID_I210_FIBER), board_82575 },
{ PCI_VDEVICE(INTEL, E1000_DEV_ID_I210_SERDES), board_82575 },
{ PCI_VDEVICE(INTEL, E1000_DEV_ID_I210_SGMII), board_82575 },
{ PCI_VDEVICE(INTEL, E1000_DEV_ID_I210_COPPER_FLASHLESS), board_82575 },
{ PCI_VDEVICE(INTEL, E1000_DEV_ID_I210_SERDES_FLASHLESS), board_82575 },
/* required last entry */
{0, }
};
内核通过设备 ID 与驱动支持的设备列表匹配,选择合适的驱动控制网卡,然后调用之前注册到内核 PCI 子系统的探测函数(probe)完成初始化。例如 igb 驱动程序的 igb_probe 函数,其处理流程包括:
- 设置 DMA 寻址限制和缓存一致性;
- 申请内核内存;
- struct net_device 结构体的创建、初始化和注册;
- 注册 struct net_device_ops (里面有 igb_open ) 到 net_device;
- 注册驱动支持的 ethtool 调用函数;
- 注册 poll 函数到 NAPI 子系统;
igb 驱动程序中 igb_probe 函数的部分代码如下:
static int igb_probe(struct pci_dev *pdev, const struct pci_device_id *ent)
{
/* 设置 DMA 寻址限制和缓存一致性 */
err = dma_set_mask_and_coherent(&pdev->dev, DMA_BIT_MASK(64));
/* 申请内存 */
err = pci_request_mem_regions(pdev, igb_driver_name);
/* 网络设备 */
netdev = alloc_etherdev_mq(sizeof(struct igb_adapter), IGB_MAX_TX_QUEUES);
/* net_device_ops 结构体,代表一个网络设备 */
netdev->netdev_ops = &igb_netdev_ops;
/* 注册驱动支持的 ethtool 调用函数 */
igb_set_ethtool_ops(netdev);
/* 函数里面注册了 poll 函数 */
err = igb_sw_init(adapter);
}
DMA(Direct Memory Access)顾名思义就是「直接内存访问」,是指一个设备和 CPU 共享内存总线。DMA 主要优点: 通过和 CPU 共享内存总线,DMA 可以实现 IO 设备和内存之间快速的数据复制(不论内存到设备还是设备到内存,都能够加速数据传输)。
1.3.1 注册 net_device_ops 到 net_device
net_device_ops 结构体包含了指向打开设备、发送数据和设置 MAC 地址等操作函数的指针,代码如下:
static const struct net_device_ops igb_netdev_ops = {
.ndo_open = igb_open,
.ndo_stop = igb_close,
.ndo_start_xmit = igb_xmit_frame,
.ndo_get_stats64 = igb_get_stats64,
.ndo_set_rx_mode = igb_set_rx_mode,
.ndo_set_mac_address= igb_set_mac,
.ndo_change_mtu = igb_change_mtu,
.ndo_eth_ioctl = igb_ioctl,
.ndo_tx_timeout = igb_tx_timeout,
.ndo_validate_addr = eth_validate_addr,
.ndo_vlan_rx_add_vid= igb_vlan_rx_add_vid,
.ndo_vlan_rx_kill_vid= igb_vlan_rx_kill_vid,
.ndo_set_vf_mac = igb_ndo_set_vf_mac,
.ndo_set_vf_vlan = igb_ndo_set_vf_vlan,
.ndo_set_vf_rate = igb_ndo_set_vf_bw,
.ndo_set_vf_spoofchk= igb_ndo_set_vf_spoofchk,
.ndo_set_vf_trust = igb_ndo_set_vf_trust,
.ndo_get_vf_config = igb_ndo_get_vf_config,
.ndo_fix_features = igb_fix_features,
.ndo_set_features = igb_set_features,
.ndo_fdb_add = igb_ndo_fdb_add,
.ndo_features_check = igb_features_check,
.ndo_setup_tc = igb_setup_tc,
.ndo_bpf = igb_xdp,
.ndo_xdp_xmit = igb_xdp_xmit,
};
1.3.2 注册 poll 函数到 NAPI 子系统
网卡驱动程序都会实现poll函数,igb驱动程序实现的poll函数是 igb_poll 函数,通过调用netif_napi_add函数将其注册到 NAPI 子系统。调用链:igb_sw_init -> igb_init_interrupt_scheme -> igb_alloc_q_vectors -> igb_alloc_q_vector。
igb_alloc_q_vector 函数部分代码如下:
static int igb_alloc_q_vector(struct igb_adapter *adapter, int v_count, int v_idx, int txr_count, int txr_idx, int rxr_count, int rxr_idx)
{
/* allocate q_vector and rings */
q_vector = adapter->q_vector[v_idx];
/* 初始化 NAPI */
netif_napi_add(adapter->netdev, &q_vector->napi, igb_poll, 64);
}
其中,weight代表 RX 队列的处理权重,budget表示一种惩罚措施,用于多 CPU 多队列之间的公平性调度
1.4 网卡设备的启用(ndo_open)
当网络设备被启用时(比如使用 ifconfig eth0 up 命令)net_device_ops 中的 ndo_open 所指向的函数将会被调用。完成以下处理:
- 分配多 TX/RX 队列的内核内存空间;
- 给网卡配置 RX/TX 队列,给 RX 申请 DMA 空间;
- 注册硬中断处理函数;
- 打开 NAPI;
- 打开网卡硬中断;
igb 驱动程序中 ndo_open 指向的是 igb_open,部分代码如下:
static int __igb_open(struct net_device *netdev, bool resuming)
{
/* 分配多 TX 队列的内存空间 */
err = igb_setup_all_tx_resources(adapter);
/* 分配多 RX 队列的内存空间 */
err = igb_setup_all_rx_resources(adapter);
/* 给网卡配置 RX/TX 队列,给 RX 申请 DMA 空间 */
igb_configure(adapter);
/* 注册中断处理函数 */
err = igb_request_irq(adapter);
/* 打开 NAPI */
for (i = 0; i < adapter->num_q_vectors; i++)
napi_enable(&(adapter->q_vector[i]->napi));
/* 打开硬中断 */
igb_irq_enable(adapter);
/* 启动所有 TX 队列 */
netif_tx_start_all_queues(netdev);
}
int igb_open(struct net_device *netdev)
{
return __igb_open(netdev, false);
}
1.4.1 分配 TX/RX 多队列(Ring Buffer)内存空间
目前大部分网络都采用基于环形缓冲区的队列来进行 DMA 的收发数据包。igb_open 代码中 igb_setup_all_rx_resources 会循环调用 igb_setup_rx_resources 函数 num_rx_queues 次,每次申请一个 Ring Buffer 内存空间,元素是 struct igb_rx_buffer,并且通过 DMA 申请连续内核空间用来存放 Ring Buffer 对应的网络数据。部分代码如下:
static int igb_setup_all_rx_resources(struct igb_adapter *adapter)
{
for (i = 0; i < adapter->num_rx_queues; i++)
err = igb_setup_rx_resources(adapter->rx_ring[i]);
}
int igb_setup_rx_resources(struct igb_ring *rx_ring)
{
/* Ring Buffer 的元素是 struct igb_rx_buffer */
size = sizeof(struct igb_rx_buffer) * rx_ring->count;
/* 申请 Ring Buffer 内存空间 */
rx_ring->rx_buffer_info = vmalloc(size);
/* Round up to nearest 4K */
rx_ring->size = rx_ring->count * sizeof(union e1000_adv_rx_desc);
rx_ring->size = ALIGN(rx_ring->size, 4096);
/* 通过 DMA 申请连续内核空间,数量与 Ring Buffer 长度一致 */
rx_ring->desc = dma_alloc_coherent(dev, rx_ring->size, &rx_ring->dma, GFP_KERNEL);
/* 复位 */
rx_ring->next_to_alloc = 0;
rx_ring->next_to_clean = 0;
rx_ring->next_to_use = 0;
}
struct igb_rx_buffer {
dma_addr_t dma; /* DMA 内核空间地址 */
struct page *page;
__u16 page_offset;
__u16 pagecnt_bias;
};
1.4.2 网卡配置 TX/RX 队列
创建完 RX 和 TX 队列后,需要把他们关联到网卡硬件,关联方式是通过把 RX/TX 的首元素写入网卡寄存器等操作,最后需要申请 RX 队列内长度 - 1个 igb_rx_buffer 元素的 DMA 地址(总线地址)空间,便于网卡收到数据好有地方存。igb_configure 和 igb_alloc_rx_buffers 函数部分代码如下:
static void igb_configure(struct igb_adapter *adapter)
{
struct net_device *netdev = adapter->netdev;
int i;
/* 给网卡配置 TX/RX 队列,收发数据均从一个元素开始 */
igb_configure_tx(adapter);
igb_configure_rx(adapter);
/* 清空网卡内的 RX FIFO */
igb_rx_fifo_flush_82575(&adapter->hw);
/* 给每个 RX 队列分配 DMA 空间,便于网卡硬件接收数据写入其中 */
for (i = 0; i < adapter->num_rx_queues; i++) {
struct igb_ring *ring = adapter->rx_ring[i];
igb_alloc_rx_buffers(ring, igb_desc_unused(ring));
}
}
void igb_alloc_rx_buffers(struct igb_ring *rx_ring, u16 cleaned_count)
{
union e1000_adv_rx_desc *rx_desc;
struct igb_rx_buffer *bi;
u16 i = rx_ring->next_to_use;
u16 bufsz;
rx_desc = IGB_RX_DESC(rx_ring, i);
bi = &rx_ring->rx_buffer_info[i];
i -= rx_ring->count;
bufsz = igb_rx_bufsz(rx_ring);
do {
/* 申请 DMA 地址(总线地址)空间供网卡写入接收的数据,sync the buffer for use by the device */
dma_sync_single_range_for_device(rx_ring->dev, bi->dma, bi->page_offset, bufsz, DMA_FROM_DEVICE);
/* Refresh the desc even if buffer_addrs didn't change
* because each write-back erases this info.
*/
rx_desc->read.pkt_addr = cpu_to_le64(bi->dma + bi->page_offset);
rx_desc++;
bi++;
i++;
if (unlikely(!i)) {
rx_desc = IGB_RX_DESC(rx_ring, 0);
bi = rx_ring->rx_buffer_info;
i -= rx_ring->count;
}
/* clear the length for the next_to_use descriptor */
rx_desc->wb.upper.length = 0;
cleaned_count--;
} while (cleaned_count);
}
1.4.3 注册中断函数
通常设备可以采用不同的中断方式:MSI-X、MSI 和 legacy 模式的中断方式。MSI-X 中断是较好的方法,特别是对于支持多 RX 队列的网卡,每个 RX 队列都有其分配的特定硬中断号,可以绑定固定的 CPU 处理。 根据设备所支持的中断方式,驱动程序采用最合适的中断方式注册处理函数。
在 igb 驱动中,igb_msix_ring、igb_intr_msi 和 igb_intr 分别是 MSI-X、MSI 和 legacy 模式的中断处理函数。igb 按照 MSI-X -> MSI -> legacy 的顺序尝试注册中断处理函数。igb_request_irq 部分代码如下:
static int igb_request_irq(struct igb_adapter *adapter)
{
struct net_device *netdev = adapter->netdev;
struct pci_dev *pdev = adapter->pdev;
int err = 0;
/* MSI-X */
if (adapter->flags & IGB_FLAG_HAS_MSIX) {
err = igb_request_msix(adapter);
if (!err)
goto request_done;
/* fall back to MSI */
}
/* MSI */
if (adapter->flags & IGB_FLAG_HAS_MSI) {
err = request_irq(pdev->irq, igb_intr_msi, 0, netdev->name, adapter);
if (!err)
goto request_done;
/* fall back to legacy interrupts */
}
/* legacy interrupts */
err = request_irq(pdev->irq, igb_intr, IRQF_SHARED, netdev->name, adapter);
}
多数情况下网卡驱动会选择 MSI-X 中断方式,调用 igb_request_msix 函数,然后注册 igb_msix_ring 函数为中断处理函数,部分代码如下:
static int igb_request_msix(struct igb_adapter *adapter)
{
/* 注册 igb_msix_ring 硬中断函数 */
err = request_irq(adapter->msix_entries[vector].vector, igb_msix_ring, 0, q_vector->name, q_vector);
}
当 NIC 收到数据后发出一个硬件中断信号时,上面注册的中断函数将会执行,具体执行到收包过程再讲。
1.4.4 打开 NAPI
NAPI 的核心概念是不采用频繁硬中断的方式读取数据,而是首先采用硬中断唤醒 NAPI 子系统,然后触发软中断,网络子系统处理软中断,然后循环调用 poll_list 中的 NAPI 实例的 poll 函数来循环接收数据包,这样可以防止高频硬中断影响系统的运行效率。当然,NAPI 也有缺陷,系统不能及时接收每一个包,而是多个包一起处理,进而增加了部分数据包的延时。
前面驱动程序介绍了如何将 poll 函数注册到 NAPI 子系统,但是 NAPI 通常会等到设备被打开之后才会开始工作。 打开 NAPI 比较简单。在 igb 驱动中,调用 napi_enable 实现。
/* 打开 NAPI */
for (i = 0; i < adapter->num_q_vectors; i++)
napi_enable(&(adapter->q_vector[i]->napi));
1.4.5 打开硬中断
打开 NIC 硬中断,等待数据包的到来。打开中断是一个硬件操作,igb 驱动通过函数 igb_irq_enable 写寄存器实现。
static void igb_irq_enable(struct igb_adapter *adapter)
{
struct e1000_hw *hw = &adapter->hw;
if (adapter->flags & IGB_FLAG_HAS_MSIX) {
u32 ims = E1000_IMS_LSC | E1000_IMS_DOUTSYNC | E1000_IMS_DRSTA;
u32 regval = rd32(E1000_EIAC);
wr32(E1000_EIAC, regval | adapter->eims_enable_mask);
regval = rd32(E1000_EIAM);
wr32(E1000_EIAM, regval | adapter->eims_enable_mask);
wr32(E1000_EIMS, adapter->eims_enable_mask);
if (adapter->vfs_allocated_count) {
wr32(E1000_MBVFIMR, 0xFF);
ims |= E1000_IMS_VMMB;
}
wr32(E1000_IMS, ims);
} else {
wr32(E1000_IMS, IMS_ENABLE_MASK | E1000_IMS_DRSTA);
wr32(E1000_IAM, IMS_ENABLE_MASK | E1000_IMS_DRSTA);
}
}
1.5 软中断 ksoftirqd 内核进程
CPU 在执行硬中断处理函数时可能会短暂的关闭硬中断,中断处理函数处理时间越长,关闭时间越长,丢掉其他硬中断事件的机会就越大。因此,硬中断处理函数处理的事情越少越好,这样可以尽快完成中断处理函数并且重新打开硬中断。
中断处理函数的总工作量不变的情况下,还得减少硬中断的工作量,就引入了软中断,复杂的事情交给软中断来处理。软中断在 ksoftirq 内核进程来处理,与硬中断不在一个层面,其可以被硬中断打断。每个 CPU 负责执行一个 ksoftirq 内核进程,比如 ksoftirqd/0 运行在 CPU 0上,这些内核进程执行不同软中断注册的中断处理函数。 内核通过 open_softirq 函数来注册软中断处理函数。
一个重要知识点:执行硬中断的处理函数的 CPU 核心,也会执行该硬中断后续的软中断处理函数,也就是同一中断事件的软/硬中断处理函数会被同一个 CPU 核心执行。
ksoftirqd 内核进程通过 spawn_ksoftirqd 函数初始化,代码如下:
static struct smp_hotplug_thread softirq_threads = {
.store = &ksoftirqd,
.thread_should_run = ksoftirqd_should_run,
.thread_fn = run_ksoftirqd,
.thread_comm = "ksoftirqd/%u",
};
static __init int spawn_ksoftirqd(void) {
cpuhp_setup_state_nocalls(CPUHP_SOFTIRQ_DEAD, "softirq:dead", NULL, takeover_tasklets);
BUG_ON(smpboot_register_percpu_thread(&softirq_threads));
return 0;
}
early_initcall(spawn_ksoftirqd);
1.6 网络子系统
上面讲解了网络驱动和软中断的初始化流程,下面介绍下「网络子系统」的初始化。「网络子系统」通过 net_dev_init 函数进行初始化,部分代码如下:
static int __init net_dev_init(void)
{
int i, rc = -ENOMEM;
/* Initialise the packet receive queues. */
for_each_possible_cpu(i) {
struct work_struct *flush = per_cpu_ptr(&flush_works, i);
struct softnet_data *sd = &per_cpu(softnet_data, i);
INIT_WORK(flush, flush_backlog);
skb_queue_head_init(&sd->input_pkt_queue);
skb_queue_head_init(&sd->process_queue);
#ifdef CONFIG_XFRM_OFFLOAD
skb_queue_head_init(&sd->xfrm_backlog);
#endif
INIT_LIST_HEAD(&sd->poll_list);
sd->output_queue_tailp = &sd->output_queue;
#ifdef CONFIG_RPS
/* 注册 IPI 信号的处理函数,然后发出 NET_RX_SOFTIRQ 软中断信号 */
INIT_CSD(&sd->csd, rps_trigger_softirq, sd);
sd->cpu = i;
#endif
INIT_CSD(&sd->defer_csd, trigger_rx_softirq, sd);
spin_lock_init(&sd->defer_lock);
init_gro_hash(&sd->backlog);
/* 软中断中通过调用 backlog(napi_struct)的 poll 处理 cpu 的 sd 的 input_pkt_queue(skb) 队列 */
sd->backlog.poll = process_backlog;
/* weight_p 可以调整,网卡的 poll 权重是 hardcode 64 */
sd->backlog.weight = weight_p;
}
open_softirq(NET_TX_SOFTIRQ, net_tx_action);
open_softirq(NET_RX_SOFTIRQ, net_rx_action);
}
/* 内核通过调用 subsys_initcall 初始化各个子系统 */
subsys_initcall(net_dev_init);
该函数会给每个 CPU 创建一个 softnet_data 结构体,该结构体包含了很多数据,其中包括:
- 注册到该 CPU 的 NAPI 结构体列表(poll_list);
- 接收和发送队列;
- backlog(napi_struct)初始化;
- RPS 相关的指针;
struct softnet_data {
struct list_head poll_list;
struct sk_buff_head process_queue;
/* stats */
unsigned int processed;
unsigned int time_squeeze;
unsigned int received_rps;
#ifdef CONFIG_RPS
struct softnet_data *rps_ipi_list;
#endif
#ifdef CONFIG_NET_FLOW_LIMIT
struct sd_flow_limit __rcu *flow_limit;
#endif
struct Qdisc *output_queue;
struct Qdisc **output_queue_tailp;
struct sk_buff *completion_queue;
#ifdef CONFIG_XFRM_OFFLOAD
struct sk_buff_head xfrm_backlog;
#endif
/* written and read only by owning cpu: */
struct {
u16 recursion;
u8 more;
#ifdef CONFIG_NET_EGRESS
u8 skip_txqueue;
#endif
} xmit;
#ifdef CONFIG_RPS
/* input_queue_head should be written by cpu owning this struct,
* and only read by other cpus. Worth using a cache line.
*/
unsigned int input_queue_head ____cacheline_aligned_in_smp;
/* Elements below can be accessed between CPUs for RPS/RFS */
call_single_data_t csd ____cacheline_aligned_in_smp;
struct softnet_data *rps_ipi_next;
unsigned int cpu;
unsigned int input_queue_tail;
#endif
unsigned int dropped;
struct sk_buff_head input_pkt_queue;
struct napi_struct backlog;
/* Another possibly contended cache line */
spinlock_t defer_lock ____cacheline_aligned_in_smp;
int defer_count;
int defer_ipi_scheduled;
struct sk_buff *defer_list;
call_single_data_t defer_csd;
};
此外,net_dev_init 注册了两个软中断处理函数,分别用 net_rx_action 和 net_tc_action 中断函数处理接收和发送的数据包。
open_softirq(NET_TX_SOFTIRQ, net_tc_action);
open_softirq(NET_RX_SOFTIRQ, net_rx_action);
open_softirq 函数将软中断类型和处理函数对存在 softirq_vec 里,当有软中断到来时,通过查此表来找对应的中断处理函数,代码如下:
void open_softirq(int nr, void (*action)(struct softirq_action *))
{
/* softirq_vec 是静态变量 */
softirq_vec[nr].action = action;
}
1.7 协议栈初始化
内核中的fs_initcall和subsys_initcall类似,也是模块初始化的入口。fs_initcall调用 inet_init 完成网络协议栈模块初始化,主要流程有:
- 将 TCP、UDP 和 ICMP 的接收函数注册到 inet_protos 数组中;
- 注册 Socket 相关的信息到 inetsw 链表数组中,便于 inet_create 函数创建套接字;
- 将 IP 的接收函数注册到 ptype_base 哈希表中。
inet_init 部分代码如下:
static int __init inet_init(void) {
struct inet_protosw *q;
struct list_head *r;
int rc;
sock_skb_cb_check_size(sizeof(struct inet_skb_parm));
raw_hashinfo_init(&raw_v4_hashinfo);
/* 注册各种协议的各种处理函数 */
rc = proto_register(&tcp_prot, 1);
rc = proto_register(&udp_prot, 1);
rc = proto_register(&raw_prot, 1);
rc = proto_register(&ping_prot, 1);
/* Tell SOCKET that we are alive... */
(void)sock_register(&inet_family_ops);
#ifdef CONFIG_SYSCTL
ip_static_sysctl_init();
#endif
/* 添加所有基础网络协议,eg. 添加到 inet_protos[IPPROTO_ICMP] = icmp_protocol 数组里 */
if (inet_add_protocol(&icmp_protocol, IPPROTO_ICMP) < 0)
pr_crit("%s: Cannot add ICMP protocol\n", __func__);
if (inet_add_protocol(&udp_protocol, IPPROTO_UDP) < 0)
pr_crit("%s: Cannot add UDP protocol\n", __func__);
if (inet_add_protocol(&tcp_protocol, IPPROTO_TCP) < 0)
pr_crit("%s: Cannot add TCP protocol\n", __func__);
#ifdef CONFIG_IP_MULTICAST
if (inet_add_protocol(&igmp_protocol, IPPROTO_IGMP) < 0)
pr_crit("%s: Cannot add IGMP protocol\n", __func__);
#endif
/* Register the socket-side information for inet_create. */
for (r = &inetsw[0]; r < &inetsw[SOCK_MAX]; ++r)
INIT_LIST_HEAD(r);
for (q = inetsw_array; q < &inetsw_array[INETSW_ARRAY_LEN]; ++q)
inet_register_protosw(q);
/* 加载 arp 模块 */
arp_init();
/* 加载 ip 模块 */
ip_init();
/* Initialise per-cpu ipv4 mibs */
if (init_ipv4_mibs())
panic("%s: Cannot init ipv4 mibs\n", __func__);
/* Setup TCP slab cache for open requests. */
tcp_init();
/* Setup UDP memory threshold */
udp_init();
/* Add UDP-Lite (RFC 3828) */
udplite4_register();
/* RAW 类型数据包 */
raw_init();
ping_init();
/* 加载 icmp 模块 */
if (icmp_init() < 0)
panic("Failed to create the ICMP control socket.\n");
/* Initialise the multicast router */
#if defined(CONFIG_IP_MROUTE)
if (ip_mr_init())
pr_crit("%s: Cannot init ipv4 mroute\n", __func__);
#endif
if (init_inet_pernet_ops())
pr_crit("%s: Cannot init ipv4 inet pernet ops\n", __func__);
ipv4_proc_init();
ipfrag_init();
/* 将 IP 的接收函数 ip_rcv 注册到 ptype_base 列表里 */
dev_add_pack(&ip_packet_type);
ip_tunnel_core_init();
rc = 0;
}
fs_initcall(inet_init);
1.7.1 inet_protos 数组
TCP、UDP 和 ICMP 的net_protocol结构体定义如下,其中有 tcp_v4_rcv、udp_rcv 和 icmp_rcv 函数用来接收数据。
static const struct net_protocol tcp_protocol = {
.handler = tcp_v4_rcv,
.err_handler = tcp_v4_err,
.no_policy = 1,
.icmp_strict_tag_validation = 1,
};
static const struct net_protocol udp_protocol = {
.handler = udp_rcv,
.err_handler = udp_err,
.no_policy = 1,
};
static const struct net_protocol icmp_protocol = {
.handler = icmp_rcv,
.err_handler = icmp_err,
.no_policy = 1,
};
inet_init 函数中调用 inet_add_protocol 函数将上面三个结构体注册到 inet_protos 数组里:
struct net_protocol __rcu *inet_protos[MAX_INET_PROTOS] __read_mostly;
int inet_add_protocol(const struct net_protocol *prot, unsigned char protocol) {
return !cmpxchg((const struct net_protocol **)&inet_protos[protocol], NULL, prot) ? 0 : -1;
}
1.7.2 inetsw 链表数组
/* The inetsw table contains everything that inet_create needs to
* build a new socket.
*/
static struct list_head inetsw[SOCK_MAX];
/* Upon startup we insert all the elements in inetsw_array[] into
* the linked list inetsw.
*/
static struct inet_protosw inetsw_array[] = {
{
.type = SOCK_STREAM,
.protocol = IPPROTO_TCP,
.prot = &tcp_prot,
.ops = &inet_stream_ops,
.flags = INET_PROTOSW_PERMANENT | INET_PROTOSW_ICSK,
},
{
.type = SOCK_DGRAM,
.protocol = IPPROTO_UDP,
.prot = &udp_prot,
.ops = &inet_dgram_ops,
.flags = INET_PROTOSW_PERMANENT,
},
{
.type = SOCK_DGRAM,
.protocol = IPPROTO_ICMP,
.prot = &ping_prot,
.ops = &inet_sockraw_ops,
.flags = INET_PROTOSW_REUSE,
},
{
.type = SOCK_RAW,
.protocol = IPPROTO_IP, /* wild card */
.prot = &raw_prot,
.ops = &inet_sockraw_ops,
.flags = INET_PROTOSW_REUSE,
}
};
inet_init 函数遍历所有协议,循环调用 inet_register_protosw 函数将 inetsw_array 数组中各个协议的操作注册到 inetsw 链表数组中,便于 inet_create 函数根据具体协议类型创建套接字。
/* Register the socket-side information for inet_create. */
for (q = inetsw_array; q < &inetsw_array[INETSW_ARRAY_LEN]; ++q)
inet_register_protosw(q);
inet_register_protosw 函数部分代码如下:
void inet_register_protosw(struct inet_protosw *p)
{
struct list_head *lh;
struct inet_protosw *answer;
int protocol = p->protocol;
struct list_head *last_perm;
...
last_perm = &inetsw[p->type];
list_for_each(lh, &inetsw[p->type]) {
answer = list_entry(lh, struct inet_protosw, list);
/* Check only the non-wild match. */
if ((INET_PROTOSW_PERMANENT & answer->flags) == 0)
break;
if (protocol == answer->protocol)
goto out_permanent;
last_perm = lh;
}
...
}
TCP 和 UDP Scoket 使用的ops结构体如下:
const struct proto_ops inet_stream_ops = {
.family = PF_INET,
.owner = THIS_MODULE,
.release = inet_release,
.bind = inet_bind,
.connect = inet_stream_connect,
.socketpair = sock_no_socketpair,
.accept = inet_accept,
.getname = inet_getname,
.poll = tcp_poll,
.ioctl = inet_ioctl,
.gettstamp = sock_gettstamp,
.listen = inet_listen,
.shutdown = inet_shutdown,
.setsockopt = sock_common_setsockopt,
.getsockopt = sock_common_getsockopt,
.sendmsg = inet_sendmsg,
.recvmsg = inet_recvmsg,// 接收数据
#ifdef CONFIG_MMU
.mmap = tcp_mmap,
#endif
.sendpage = inet_sendpage,
.splice_read = tcp_splice_read,
.read_sock = tcp_read_sock,
.read_skb = tcp_read_skb,
.sendmsg_locked = tcp_sendmsg_locked,
.sendpage_locked= tcp_sendpage_locked,
.peek_len = tcp_peek_len,
#ifdef CONFIG_COMPAT
.compat_ioctl = inet_compat_ioctl,
#endif
.set_rcvlowat = tcp_set_rcvlowat,
};
const struct proto_ops inet_dgram_ops = {
.family = PF_INET,
.owner = THIS_MODULE,
.release = inet_release,
.bind = inet_bind,
.connect = inet_dgram_connect,
.socketpair = sock_no_socketpair,
.accept = sock_no_accept,
.getname = inet_getname,
.poll = udp_poll,
.ioctl = inet_ioctl,
.gettstamp = sock_gettstamp,
.listen = sock_no_listen,
.shutdown = inet_shutdown,
.setsockopt = sock_common_setsockopt,
.getsockopt = sock_common_getsockopt,
.sendmsg = inet_sendmsg,
.read_skb = udp_read_skb,
.recvmsg = inet_recvmsg,// 接收数据
.mmap = sock_no_mmap,
.sendpage = inet_sendpage,
.set_peek_off = sk_set_peek_off,
#ifdef CONFIG_COMPAT
.compat_ioctl = inet_compat_ioctl,
#endif
};
TCP 和 UDP Scoket 使用的prot结构体如下:
struct proto tcp_prot = {
.name = "TCP",
.owner = THIS_MODULE,
.close = tcp_close,
.pre_connect = tcp_v4_pre_connect,
.connect = tcp_v4_connect,
.disconnect = tcp_disconnect,
.accept = inet_csk_accept,
.ioctl = tcp_ioctl,
.init = tcp_v4_init_sock,
.destroy = tcp_v4_destroy_sock,
.shutdown = tcp_shutdown,
.setsockopt = tcp_setsockopt,
.getsockopt = tcp_getsockopt,
.bpf_bypass_getsockopt = tcp_bpf_bypass_getsockopt,
.keepalive = tcp_set_keepalive,
.recvmsg = tcp_recvmsg,// 接收数据
.sendmsg = tcp_sendmsg,
.sendpage = tcp_sendpage,
.backlog_rcv = tcp_v4_do_rcv,
.release_cb = tcp_release_cb,
.hash = inet_hash,
.unhash = inet_unhash,
.get_port = inet_csk_get_port,
.put_port = inet_put_port,
#ifdef CONFIG_BPF_SYSCALL
.psock_update_sk_prot = tcp_bpf_update_proto,
#endif
.enter_memory_pressure = tcp_enter_memory_pressure,
.leave_memory_pressure = tcp_leave_memory_pressure,
.stream_memory_free = tcp_stream_memory_free,
.sockets_allocated = &tcp_sockets_allocated,
.orphan_count = &tcp_orphan_count,
.memory_allocated = &tcp_memory_allocated,
.per_cpu_fw_alloc = &tcp_memory_per_cpu_fw_alloc,
.memory_pressure = &tcp_memory_pressure,
.sysctl_mem = sysctl_tcp_mem,
.sysctl_wmem_offset = offsetof(struct net, ipv4.sysctl_tcp_wmem),
.sysctl_rmem_offset = offsetof(struct net, ipv4.sysctl_tcp_rmem),
.max_header = MAX_TCP_HEADER,
.obj_size = sizeof(struct tcp_sock),
.slab_flags = SLAB_TYPESAFE_BY_RCU,
.twsk_prot = &tcp_timewait_sock_ops,
.rsk_prot = &tcp_request_sock_ops,
.h.hashinfo = &tcp_hashinfo,
.no_autobind = true,
.diag_destroy = tcp_abort,
};
struct proto udp_prot = {
.name = "UDP",
.owner = THIS_MODULE,
.close = udp_lib_close,
.pre_connect = udp_pre_connect,
.connect = ip4_datagram_connect,
.disconnect = udp_disconnect,
.ioctl = udp_ioctl,
.init = udp_init_sock,
.destroy = udp_destroy_sock,
.setsockopt = udp_setsockopt,
.getsockopt = udp_getsockopt,
.sendmsg = udp_sendmsg,
.recvmsg = udp_recvmsg,// 接收数据
.sendpage = udp_sendpage,
.release_cb = ip4_datagram_release_cb,
.hash = udp_lib_hash,
.unhash = udp_lib_unhash,
.rehash = udp_v4_rehash,
.get_port = udp_v4_get_port,
.put_port = udp_lib_unhash,
#ifdef CONFIG_BPF_SYSCALL
.psock_update_sk_prot = udp_bpf_update_proto,
#endif
.memory_allocated = &udp_memory_allocated,
.per_cpu_fw_alloc = &udp_memory_per_cpu_fw_alloc,
.sysctl_mem = sysctl_udp_mem,
.sysctl_wmem_offset = offsetof(struct net, ipv4.sysctl_udp_wmem_min),
.sysctl_rmem_offset = offsetof(struct net, ipv4.sysctl_udp_rmem_min),
.obj_size = sizeof(struct udp_sock),
.h.udp_table = &udp_table,
.diag_destroy = udp_abort,
};
1.7.3 ptype_base 哈希表
后面调用 dev_add_pack 函数将 ip_packet_type 结构体注册到 ptype_base 哈希表中,type 是 ETH_P_IP(0x0800),func 是 ip_rcv 函数。
static struct packet_type ip_packet_type __read_mostly = {
.type = cpu_to_be16(ETH_P_IP),
.func = ip_rcv,
.list_func = ip_list_rcv,
};
extern struct list_head ptype_all __read_mostly;
struct list_head ptype_base[PTYPE_HASH_SIZE] __read_mostly;
void dev_add_pack(struct packet_type *pt) {
struct list_head *head = ptype_head(pt);
spin_lock(&ptype_lock);
list_add_rcu(&pt->list, head);
spin_unlock(&ptype_lock);
}
static inline struct list_head *ptype_head(const struct packet_type *pt) {
if (pt->type == htons(ETH_P_ALL))
return pt->dev ? &pt->dev->ptype_all : &ptype_all;
else
return pt->dev ? &pt->dev->ptype_specific : &ptype_base[ntohs(pt->type) & PTYPE_HASH_MASK];
}
除了 IP 还有下面协议:
$ grep -R dev_add_pack net/{ipv4,packet}/*
net/ipv4/af_inet.c: dev_add_pack(&ip_packet_type); //IP
net/ipv4/arp.c: dev_add_pack(&arp_packet_type); //ARP
net/ipv4/ipconfig.c: dev_add_pack(&rarp_packet_type);
net/ipv4/ipconfig.c: dev_add_pack(&bootp_packet_type);
net/packet/af_packet.c: dev_add_pack(&po->prot_hook); //用于抓包
net/packet/af_packet.c: dev_add_pack(&f->prot_hook); //用于抓包
包的类型可以通过下面命令查看:
$ cat /proc/net/ptype # packet type (skb->protocol)
Type Device Function
0800 ip_rcv
0806 arp_rcv
86dd ipv6_rcv
1.7.4 小结
好了,inet_protos 存储着 TCP、UDP 和 ICMP 接收数据的 udp_rcv 和 icmp_rcv 函数地址,ptype_base 存储着接收数据的 ip_rcv 函数地址。后面会看到软中断中会通过 ptype_base 找到 ip_rcv 函数地址,进而将 IP 包正确地送到 ip_rcv 中执行。在 ip_rcv 中将会通过 inet_protos 找到 TCP 或者 UDP 的处理函数,再而把包转发给 tcp_v4_rcv 或者 udp_rcv 函数。
ip_rcv、tcp_v4_rcv、udp_rcv 和 icmp_rcv 函数已经注册好了,就等待数据包的到来。最后通过 inet_create 函数根据具体协议类型和 inetsw 链表数组创建套接字来完成接收数据。
二、网络收包概述
前面主要介绍了系统启动时的初始化操作,接下来开始正式介绍网络的详细收包过程,从网络接口层(L1)、网络层(L2)、传输层(L3)、套接字(L3.5)再到应用层(L4)的整个过程。
从硬中断到协议栈的调用链:
三、网络接口层
3.1 概述
数据包在本层主要处理流程有五:
- 网卡收到数据包,DMA 方式写入
Ring Buffer,发出硬中断; - 内核收到硬中断,NAPI 加入本 CPU 的轮询列表,发出软中断;
- 内核收到软中断,轮询 NAPI 并执行
poll函数从Ring Buffer取数据; - GRO 操作(默认开启),合并多个数据包为一个数据包,如果 RPS 关闭,则把数据包递交到协议栈;
- RPS 操作(默认关闭),如果开启,使数据包通过别的(也可能是当前的) CPU 递交到协议栈;
3.1.1 Ring Buffer
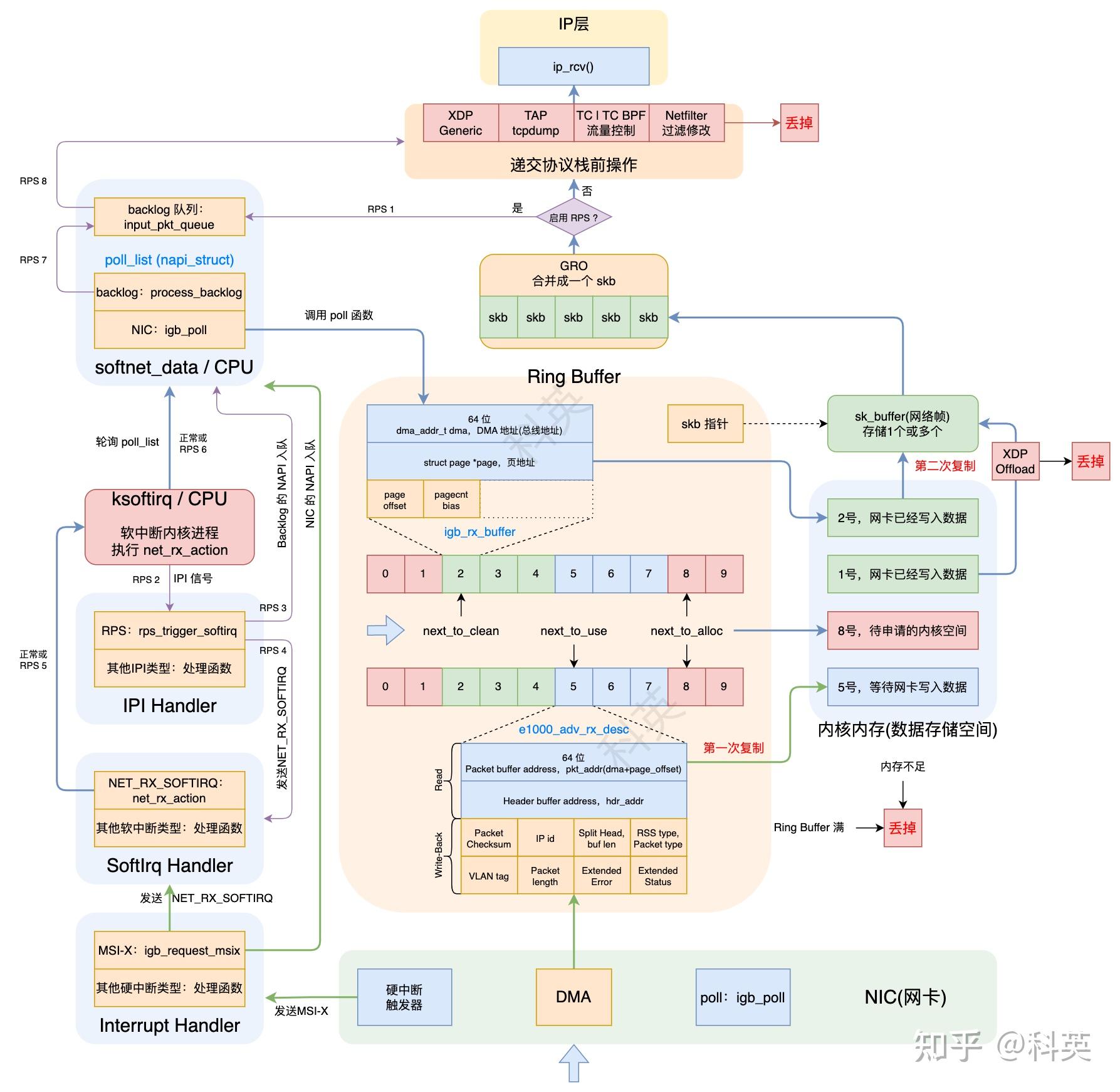
这一层里有一个大名鼎鼎的数据结构Ring Buffer,后面统称它的中文名字叫环形缓冲区。
接收Ring Buffer实际上有两个环形队列,一个是 CPU 使用的rx_buffer_info数组,数组元素是rx_buffer,另一个是网卡硬件使用的desc数组,元素是rx_desc,它们都存储在主内存上的内核空间。igb网卡驱动中rx_buffer是 igb_rx_buffer,rx_desc是e1000_adv_rx_desc。
igb_rx_buffer 结构体代码如下,结构图如图2:
struct igb_rx_buffer {
/* DMA 地址 */
dma_addr_t dma;
/* 物理页,与 dma 指向同一个内存区域 */
struct page *page;
#if (BITS_PER_LONG > 32) || (PAGE_SIZE >= 65536)
__u32 page_offset;
#else
__u16 page_offset;
#endif
__u16 pagecnt_bias;
};

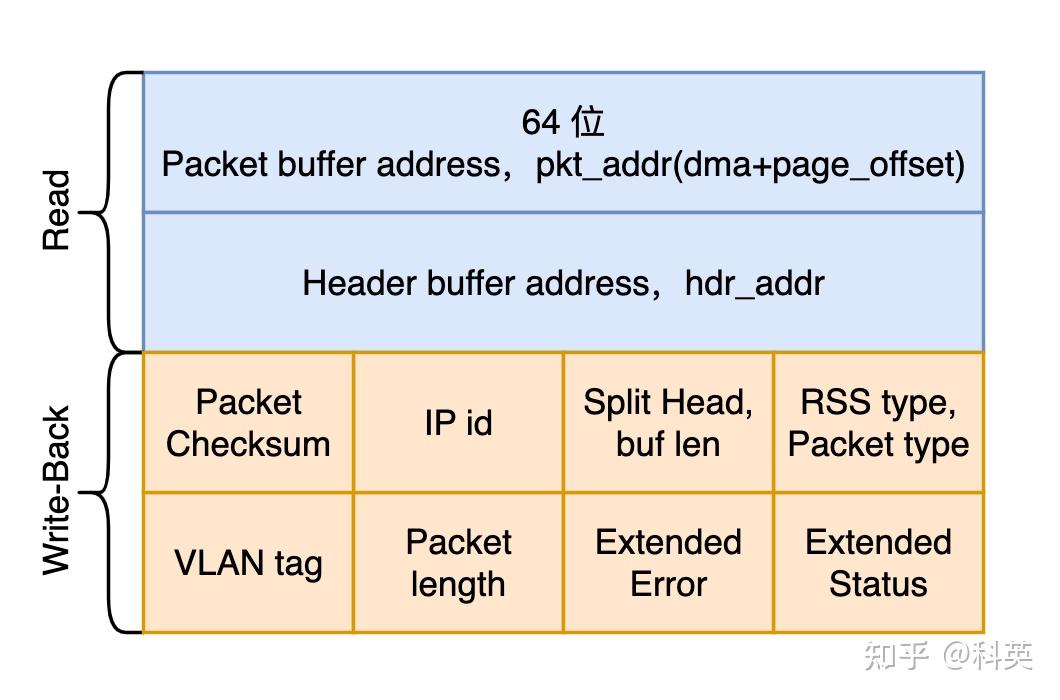
e1000_adv_rx_desc 结构体代码如下,结构图如图3:
union e1000_adv_rx_desc {
struct {
__le64 pkt_addr; /* Packet buffer address */
__le64 hdr_addr; /* Header buffer address */
} read;
struct {
struct {
struct {
__le16 pkt_info; /* RSS type, Packet type */
__le16 hdr_info; /* Split Head, buf len */
} lo_dword;
union {
__le32 rss; /* RSS Hash */
struct {
__le16 ip_id; /* IP id */
__le16 csum; /* Packet Checksum */
} csum_ip;
} hi_dword;
} lower;
struct {
__le32 status_error; /* ext status/error */
__le16 length; /* Packet length */
__le16 vlan; /* VLAN tag */
} upper;
} wb; /* writeback */
};
3.2 网卡收到数据包
网卡收到数据包后,通过 DMA 写入Ring Buffer(rx_ring)内rx_buffer_info数组的下一个可用元素(igb_rx_buffer)的 dma 指向的内核内存,dma实际是网卡可以使用的总线地址,一个网络帧可能占用多个igb_rx_buffer。
这是第一次复制,从网卡到 Ring Buffer 的复制。
3.3 内核收到硬中断
复制完后,如果硬中断没有被关闭,则网卡发出硬中断。假设启动时硬中断类型选择的是MSI-X,那么硬中断注册的函数就 igb_msix_ring,从下面的代码可以看出,硬中断处理函数逻辑非常简单,仅仅调用了 igb_write_itr 和 napi_schedule 两个函数,igb_msix_ring 函数代码如下:
static irqreturn_t igb_msix_ring(int irq, void *data)
{
struct igb_q_vector *q_vector = data;
/* Write the ITR value calculated from the previous interrupt. */
igb_write_itr(q_vector);
napi_schedule(&q_vector->napi);
return IRQ_HANDLED;
}
igb_write_itr 负责更新特定的硬件中的寄存器,而 napi_schedule 才是重点工作,负责调度 NAPI,napi_schedule 调用__napi_schedule 再调用 ____napi_schedule 函数,后者部分代码如下:
static inline void ____napi_schedule(struct softnet_data *sd, struct napi_struct *napi)
{
list_add_tail(&napi->poll_list, &sd->poll_list);
__raise_softirq_irqoff(NET_RX_SOFTIRQ);
}
其主要逻辑有二:
- 把
napi_struct结构体的poll_list添加到当前 CPU 所关联的softnet_data结构体的poll_list链表尾部; - 然后调用 __raise_softirq_irqoff 函数触发
NET_RX_SOFTIRQ软中断,从而内核执行网络子系统初始化时注册的 net_rx_action 软中断处理函数。
3.4 内核收到软中断
处理硬中断的 CPU 同样也会执行该硬中断触发的软中断注册的处理函数,软中断函数 net_rx_action 在ksoftirqd内核进程执行。 net_rx_action 遍历当前 CPU 队列中的 NAPI 列表,依次取出列表中的 NAPI 结构对其进行 napi_poll 操作。net_rx_action 函数非常重要。
3.4.1 net_rx_action 函数
// 部分代码
static __latent_entropy void net_rx_action(struct softirq_action *h)
{
struct softnet_data *sd = this_cpu_ptr(&softnet_data);
unsigned long time_limit = jiffies + usecs_to_jiffies(READ_ONCE(netdev_budget_usecs));
int budget = READ_ONCE(netdev_budget);
LIST_HEAD(list);
LIST_HEAD(repoll);
local_irq_disable();
list_splice_init(&sd->poll_list, &list);
local_irq_enable();
for (;;) {
struct napi_struct *n;
skb_defer_free_flush(sd);
if (list_empty(&list)) {
if (!sd_has_rps_ipi_waiting(sd) && list_empty(&repoll))
goto end;
break;
}
n = list_first_entry(&list, struct napi_struct, poll_list);
budget -= napi_poll(n, &repoll);
/* If softirq window is exhausted then punt.
* Allow this to run for 2 jiffies since which will allow
* an average latency of 1.5/HZ.
*/
if (unlikely(budget <= 0 || time_after_eq(jiffies, time_limit))) {
sd->time_squeeze++;
break;
}
}
local_irq_disable();
list_splice_tail_init(&sd->poll_list, &list);
list_splice_tail(&repoll, &list);
list_splice(&list, &sd->poll_list);
if (!list_empty(&sd->poll_list))
__raise_softirq_irqoff(NET_RX_SOFTIRQ);
/* 通过 smp_call_function_single_async 远程激活 sd->rps_ipi_list 中的其他 CPU 的软中断,
* 使其他 CPU 执行初始化时注册的软中断函数 csd = rps_trigger_softirq 来处理数据包 */
net_rps_action_and_irq_enable(sd);
end:;
}
napi_poll 函数调用 __napi_poll 函数对napi_struct进行操作,然后判断napi_struct是否加回poll_list列表尾部,budget是控制消费rx_buffer的数量,避免 CPU 一直被软中断占用。
3.4.2 __napi_poll 函数
// 部分代码
static int __napi_poll(struct napi_struct *n, bool *repoll)
{
int work, weight;
weight = n->weight;
work = 0;
if (test_bit(NAPI_STATE_SCHED, &n->state)) {
work = n->poll(n, weight);
trace_napi_poll(n, work, weight);
}
if (likely(work < weight))
return work;
if (unlikely(napi_disable_pending(n))) {
napi_complete(n);
return work;
}
*repoll = true;
return work;
}
上面代码中weight代表 RX 队列的处理优先级(网卡驱动对应权重是固定的 64),napi_struct里的poll函数被调用,igb驱动对应的是先前注册的 igb_poll 函数。
3.4.3 igb_poll 函数
// 部分代码
static int igb_poll(struct napi_struct *napi, int budget)
{
struct igb_q_vector *q_vector = container_of(napi, struct igb_q_vector, napi);
bool clean_complete = true;
int work_done = 0;
#ifdef CONFIG_IGB_DCA
if (q_vector->adapter->flags & IGB_FLAG_DCA_ENABLED)
igb_update_dca(q_vector);
#endif
if (q_vector->tx.ring)
clean_complete = igb_clean_tx_irq(q_vector, budget);
if (q_vector->rx.ring) {
int cleaned = igb_clean_rx_irq(q_vector, budget);
work_done += cleaned;
if (cleaned >= budget)
clean_complete = false;
}
/* If all work not completed, return budget and keep polling */
if (!clean_complete)
return budget;
/* Exit the polling mode, but don't re-enable interrupts if stack might
* poll us due to busy-polling
*/
if (likely(napi_complete_done(napi, work_done)))
igb_ring_irq_enable(q_vector);
return work_done;
}
其主要逻辑有三:
- 如果内核支持 DCA(Direct Cache Access),CPU 缓存命中率将会提升;
- 调用 igb_clean_rx_irq 循环处理数据包,直到处理完毕或者
budget耗尽,下面详细解读; - 检查
clean_complete判断是否所有的工作已经完成; - 如果不是,返回剩下的
budget值; - 否则调用 napi_complete_done 函数继续处理。
- 调用 gro_normal_list 函数,因为数据包处理完了,及时把 igb_clean_rx_irq 处理完的多个包一次性送到协议栈;
- 然后检查 NAPI 的
poll_list是否都处理完,如果是则关闭 NAPI,并通过 igb_ring_irq_enable 重新打开硬中断,以保证下次中断会重新打开 NAPI。
3.4.4 igb_clean_rx_irq 函数
//部分代码
static int igb_clean_rx_irq(struct igb_q_vector *q_vector, const int budget)
{
struct igb_adapter *adapter = q_vector->adapter;
struct igb_ring *rx_ring = q_vector->rx.ring;
struct sk_buff *skb = rx_ring->skb;
unsigned int total_bytes = 0, total_packets = 0;
u16 cleaned_count = igb_desc_unused(rx_ring);
int rx_buf_pgcnt;
while (likely(total_packets < budget)) {
union e1000_adv_rx_desc *rx_desc;
struct igb_rx_buffer *rx_buffer;
ktime_t timestamp = 0;
unsigned int size;
/* return some buffers to hardware, one at a time is too slow */
if (cleaned_count >= IGB_RX_BUFFER_WRITE) {
/* 1 */
igb_alloc_rx_buffers(rx_ring, cleaned_count);
cleaned_count = 0;
}
/* 2 */
rx_desc = IGB_RX_DESC(rx_ring, rx_ring->next_to_clean);
size = le16_to_cpu(rx_desc->wb.upper.length);
/* 3 */
rx_buffer = igb_get_rx_buffer(rx_ring, size, &rx_buf_pgcnt);
/* 4 retrieve a buffer from the ring */
if (!skb) {
unsigned char *hard_start = pktbuf - igb_rx_offset(rx_ring);
unsigned int offset = pkt_offset + igb_rx_offset(rx_ring);
xdp_prepare_buff(&xdp, hard_start, offset, size, true);
xdp_buff_clear_frags_flag(&xdp);
#if (PAGE_SIZE > 4096)
/* At larger PAGE_SIZE, frame_sz depend on len size */
xdp.frame_sz = igb_rx_frame_truesize(rx_ring, size);
#endif
skb = igb_run_xdp(adapter, rx_ring, &xdp);
}
/* 5 retrieve a buffer from the ring */
if (skb)
igb_add_rx_frag(rx_ring, rx_buffer, skb, size);
else if (ring_uses_build_skb(rx_ring))
skb = igb_build_skb(rx_ring, rx_buffer, &xdp, timestamp);
else
skb = igb_construct_skb(rx_ring, rx_buffer, &xdp, timestamp);
/* 6 */
igb_put_rx_buffer(rx_ring, rx_buffer, rx_buf_pgcnt);
cleaned_count++;
/* 7 fetch next buffer in frame if non-eop */
if (igb_is_non_eop(rx_ring, rx_desc))
continue;
/* 8 verify the packet layout is correct */
if (igb_cleanup_headers(rx_ring, rx_desc, skb)) {
skb = NULL;
continue;
}
/* 9 probably a little skewed due to removing CRC */
total_bytes += skb->len;
/* 10 populate checksum, timestamp, VLAN, and protocol */
igb_process_skb_fields(rx_ring, rx_desc, skb);
/* 11 GRO,合并数据包 */
napi_gro_receive(&q_vector->napi, skb);
/* reset skb pointer */
skb = NULL;
/* 12 update budget accounting */
total_packets++;
}
/* place incomplete frames back on ring for completion */
rx_ring->skb = skb;
if (cleaned_count)
igb_alloc_rx_buffers(rx_ring, cleaned_count);
return total_packets;
}
igb_clean_rx_irq 函数中的 while 循环完成下面操作:
- 首先申请一批 rx_buffer 和 rx_desc,通常 IGB_RX_BUFFER_WRITE(16)个,避免一个个申请,效率低,操作由 igb_alloc_rx_buffers 函数完成:使用 dev_alloc_pages 申请新的物理页保存到 rx_buffer->page,然后通过 dma_map_page_attrs 将 page 映射结果保存到 rx_buffer->dma ;修改 rx_desc->read.pkt_addr(rx_buffer->dma + rx_buffer->page_offset),rx_desc->wb.upper.length = 0,方便网卡将收到的数据包 DMA 到 rx_desc->read.pkt_addr 地址,这是第一次复制,从网卡到 Ring Buffer 的复制;
- 从 Ring Buffer 中取出下一个可读位置(next_to_clean)的 rx_desc,检查它状态是否正常,然后从 rx_desc 获取接收的数据 buffer 大小(wb.upper.length);
- 通过 igb_get_rx_buffer 函数将下一个可读位置(next_to_clean)的 rx_buffer 获取到;
- 计算数据包开始地址,page_address(rx_buffer->page) + rx_buffer->page_offset,转换成 xdp_buff 地址,然后交给 BPF 的 xdp 处理;
- 内核把 rx_buffer 的 page(物理页)对应的 buffer 数据拷贝到 Ring Buffer 的 skb(sk_buff)中,然后把 skb 直接传给协议栈,这是第二次复制,从 Ring Buffer 到网络协议栈的复制。为了减少复制次数,skb 直到上层处理完以后才会被 __kfree_skb 释放;
- 通过 igb_put_rx_buffer 函数将 rx_buffer->page=NULL,如果可以重用,将 page、dma 等数据移动到rx_ring->next_to_alloc 位置的 rx_buffer;反之,解除 DMA 映射,回收内存;
- 通过 igb_is_non_eop 函数检查 rx_desc 是不是包含 eop(End of Packet),如果包含,说明 skb 中已经收录一个完整的网络包(帧);反之,需要获取下一个 rx_buffer 里的数据继续复制到 skb 中直到 rx_desc 包含 eop;也就是说一个网络包(存储在 skb 中)可能包含 1 个或多个 rx_buffer 中的 buffer 数据,也可以说 1 个 skb 对应 1 个或多个 Ring Buffer 队列里连续的元素;
- 通过 igb_cleanup_headers 检查网络包(skb)的头部等信息是否正确;
- 把 skb 的长度累计到 total_bytes,用于统计数据;
- 调用 igb_process_skb_fields 设置skb 的 checksum、timestamp、VLAN 和 protocol 等信息,这些信息由硬件提供;
- 将构建好的 skb 通过 napi_gro_receive 函数上交到网络协议栈,具体细节移步 2.4 章节;
- 累加处理数据包个数 total_packets,用于消耗 budget;
- 如果没数据或者 budget 耗尽就退出循环,否则回到 1;
上面第 5 步中,skb 的创建有两种情况,当网卡配置了 legacy 模式,使用 igb_build_skb(napi_build_skb)创建 skb 并复制 rx_buffer->page 数据;否则使用 igb_construct_skb(napi_alloc_skb) 创建 skb 并复制 rx_buffer->page 数据。当 skb 不为空时,就是前一个包被 GRO 合并了,使用 igb_add_rx_frag 复制数据。
budget 的大小会影响到 CPU 的利用率,当数据包特别多的情况下,budget 越大可以减少数据包的延时,但是会影响 CPU 处理其他任务。 budget 默认 300,可以调整使用下面命令修改:
$ sysctl -w net.core.netdev_budget=500
前面收包过程都是内核跟网卡硬件和驱动配合来完成的,也就是说不同网卡收包的具体实现可能不同(同一家厂商的网卡的实现基本相同),但是大体实现思路上是一样的,都是用到了 Ring Buffer、DMA、硬中断和软中断等操作。
后面就是由内核和用户程序来完成了,与网卡没有关系了。
3.5 GRO
3.5.1 概述
GRO(Generic Receive Offloading)是 LGO(Large Receive Offload,多数是在 NIC 上实现的一种硬件优化机制)的一种软件实现,从而能让所有 NIC 都支持这个功能。网络上大部分 MTU 都是 1500 字节,开启 Jumbo Frame 后能到 9000 字节,如果发送的数据超过 MTU 就需要切割成多个数据包。通过合并「足够类似」的包来减少传送给网络协议栈的包数,有助于减少 CPU 的使用量。GRO 使协议层只需处理一个 header,而将包含大量数据的整个大包送到用户程序。如果用tcpdump抓包看到机器收到了不现实的、非常大的包,这很可能是系统开启了 GRO。
GRO 和硬中断合并的思想类似,不过阶段不同。硬中断合并是在中断发起之前,而 GRO 已经在软中断处理中了。
查看 GRO 是否开启命令:
$ ethtool -k eth0 | grep generic-receive-offload
generic-receive-offload: on
开启 GRO 命令:
$ ethtool -K eth0 gro on
napi_gro_receive 就是实现 GRO 机制的入口函数之一。
3.5.2 napi_gro_receive 函数
// 部分代码
gro_result_t napi_gro_receive(struct napi_struct *napi, struct sk_buff *skb)
{
gro_result_t ret;
skb_mark_napi_id(skb, napi);
trace_napi_gro_receive_entry(skb);
skb_gro_reset_offset(skb, 0);
ret = napi_skb_finish(napi, skb, dev_gro_receive(napi, skb));
trace_napi_gro_receive_exit(ret);
return ret;
}
其主要逻辑有二:
- 调用 dev_gro_receive 函数具体完成多个数据包的合并,即把
skb加入到 NAPI 中,这个操作调用链很长,根据包类型 TCP/UDP 分别判断数据包的完整性和判断需不需要合并; - 把上步的返回结果传入 napi_skb_finish 函数继续处理。
3.5.3 napi_skb_finish 函数
static gro_result_t napi_skb_finish(struct napi_struct *napi, struct sk_buff *skb, gro_result_t ret) {
switch (ret) {
case GRO_NORMAL:
gro_normal_one(napi, skb, 1);
break;
case GRO_MERGED_FREE:
if (NAPI_GRO_CB(skb)->free == NAPI_GRO_FREE_STOLEN_HEAD)
napi_skb_free_stolen_head(skb);
else if (skb->fclone != SKB_FCLONE_UNAVAILABLE)
__kfree_skb(skb);
else
__kfree_skb_defer(skb);
break;
case GRO_HELD:
case GRO_MERGED:
case GRO_CONSUMED:
break;
}
return ret;
}
- 如果是 ret 是 GRO_MERGED_FREE,说明 skb 已经被合并,释放 skb;
- 如果是 ret 是 GRO_NORMAL,会调用 gro_normal_one,它会更新当前 napi->rx_count 计数, 当数量足够多时,将调用 gro_normal_list 函数,将多个包一次性送到协议栈。
3.5.4 gro_normal_one 函数
static inline void gro_normal_one(struct napi_struct *napi, struct sk_buff *skb, int segs) {
list_add_tail(&skb->list, &napi->rx_list);
napi->rx_count += segs;
if (napi->rx_count >= READ_ONCE(gro_normal_batch))
gro_normal_list(napi);
}
这里的阈值gro_normal_batch默认是 8,即攒够 8 个数据包一起送到协议栈,可以通过sysctl修改,命令如下:
$ sysctl net.core.gro_normal_batch
net.core.gro_normal_batch = 8
3.5.5 gro_normal_list 函数
/* Pass the currently batched GRO_NORMAL SKBs up to the stack. */
static inline void gro_normal_list(struct napi_struct *napi)
{
if (!napi->rx_count) // 没有包直接返回
return;
netif_receive_skb_list_internal(&napi->rx_list);
INIT_LIST_HEAD(&napi->rx_list); // 初始化 napi->rx_list
napi->rx_count = 0; // 计数清零
}
到这里 GRO 的工作就完成了,然后经过 netif_receive_skb_list_internal 函数多层调用,最终调用 __netif_receive_skb_core 函数把数据包递交网络协议栈。
3.5.6 napi_complete_done 函数
// 部分代码
bool napi_complete_done(struct napi_struct *n, int work_done)
{
unsigned long flags, val, new, timeout = 0;
bool ret = true;
if (unlikely(n->state & (NAPIF_STATE_NPSVC | NAPIF_STATE_IN_BUSY_POLL)))
return false;
if (work_done) {
if (n->gro_bitmask)
timeout = READ_ONCE(n->dev->gro_flush_timeout);
n->defer_hard_irqs_count = READ_ONCE(n->dev->napi_defer_hard_irqs);
}
if (n->defer_hard_irqs_count > 0) {
n->defer_hard_irqs_count--;
timeout = READ_ONCE(n->dev->gro_flush_timeout);
if (timeout)
ret = false;
}
if (n->gro_bitmask) {
napi_gro_flush(n, !!timeout);
}
gro_normal_list(n);
...
}
3.4.4 中提到过,poll 函数(igb_poll)在检查是否已经将现有的所有数据包合并完成,如果完成了,则调用 napi_complete_done 函数直接调用 gro_normal_list 函数,及时把 dev_gro_receive 处理完的多个包一次性送到协议栈;
3.6 RPS
3.6.1 概述
RPS(Receive Packet Steering)是 RSS 的一种软件实现。
- 因为是软件实现的,所以任何网卡都可以使用 RPS,单队列和多队列网卡都可以使用;
- RPS 在数据包从 Ring Buffer 中取出来后开始工作,将 Packet hash 到对应 CPU 的 backlog 中,并触发 IPI(Inter-processorInterrupt,进程间中断)告知目标 CPU 来处理 backlog。该 Packet 将被目标 CPU 交到协议栈。从而实现将负载分散到多个 CPU 的目的;
- 单队列网卡使用 RPS 可以提升传输效率,多队列网卡在硬中断不均匀时同样可以使用来提升效率;
IPI 既像软件中断又像硬件中断,它的产生像软件中断,是在程序中用代码发送的,而它的处理像硬件中断
3.6.2 GRO 后执行 RPS
GRO 机制的最后一个函数 gro_normal_list 调用了 netif_receive_skb_list_internal 函数,后者和 netif_receive_skb_internal 函数均有下面类似的代码:
void netif_receive_skb_list_internal(struct list_head *head)
{
#ifdef CONFIG_RPS
if (static_branch_unlikely(&rps_needed)) {
list_for_each_entry_safe(skb, next, head, list) {
struct rps_dev_flow voidflow, *rflow = &voidflow;
/* 目标 CPU 的 id */
int cpu = get_rps_cpu(skb->dev, skb, &rflow);
if (cpu >= 0) {
/* Will be handled, remove from list */
skb_list_del_init(skb);
enqueue_to_backlog(skb, cpu, &rflow->last_qtail);
}
}
}
#endif
}
上面代码判断是否设置了 RPS 对数据包进行不同的处理:
- 如果没有配置 RPS,
netif_receive_skb*将数据包交到网络协议栈; - 如果配置了 RPS,
netif_receive_skb*调用 get_rps_cpu 来计算网络包的 hash 并决定压入哪个 CPU 的 backlog,具体压入操作由 enqueue_to_backlog 函数完成。
3.6.3 压入 backlog 队列
enqueue_to_backlog 函数如下:
// 部分代码
static int enqueue_to_backlog(struct sk_buff *skb, int cpu, unsigned int *qtail) {
enum skb_drop_reason reason;
struct softnet_data *sd;
unsigned long flags;
unsigned int qlen;
reason = SKB_DROP_REASON_NOT_SPECIFIED;
sd = &per_cpu(softnet_data, cpu);
rps_lock_irqsave(sd, &flags);
if (!netif_running(skb->dev))
goto drop;
qlen = skb_queue_len(&sd->input_pkt_queue);
if (qlen <= READ_ONCE(netdev_max_backlog) && !skb_flow_limit(skb, qlen)) {
if (qlen) {
enqueue:
__skb_queue_tail(&sd->input_pkt_queue, skb);
input_queue_tail_incr_save(sd, qtail);
rps_unlock_irq_restore(sd, &flags);
return NET_RX_SUCCESS;
}
if (!__test_and_set_bit(NAPI_STATE_SCHED, &sd->backlog.state))
// 将目标 CPU 的 sd 挂到当前 CPU 的 sd 的 rps_ipi_list 便于后续向目标 CPU 发送 IPI 信号。
napi_schedule_rps(sd);
goto enqueue;
}
reason = SKB_DROP_REASON_CPU_BACKLOG;
drop:
sd->dropped++;
rps_unlock_irq_restore(sd, &flags);
dev_core_stats_rx_dropped_inc(skb->dev);
kfree_skb_reason(skb, reason);
return NET_RX_DROP;
}
- 当目标 CPU 的
sd(softnet_data )中input_pkt_queue队列长度同时不超过netdev_max_backlog和flow limit的值,将skb数据包压入input_pkt_queue,否则将会被丢弃。 - 调用 napi_schedule_rps,将目标 CPU 的
sd挂到本 CPU 的sd的rps_ipi_list便于后续向目标 CPU 发送 IPI 信号; - 当返回到 net_rx_action 函数中,最后一步经过调用链 net_rps_action_and_irq_enable -> net_rps_send_ipi -> smp_call_function_single_async 远程激活
sd->rps_ipi_list中的其他 CPU 的软中断,使其他 CPU 执行初始化时注册的软中断函数csd= rps_trigger_softirq 来处理数据包; - rps_trigger_softirq 函数将 backlog(napi)加入
poll_list里,然后发出软中断信号 NET_RX_SOFTIRQ; - 当处理软中断函数 net_rx_action 处理
poll_list时,backlog的poll是 process_backlog 函数,process_backlog 函数消费 CPU 的input_pkt_queue队列数据包,经过 __netif_receive_skb 函数多层调用,最终也调用 __netif_receive_skb_core 函数把数据包递交网络协议栈。
伪文件 /proc/net/softnet_stat 的第 10 列记录了每个 CPU 收到了多少次 IPI。

上面的命令最终会调用下面的 softnet_seq_show 函数:
static int softnet_seq_show(struct seq_file *seq, void *v)
{
struct softnet_data *sd = v;
unsigned int flow_limit_count = 0;
#ifdef CONFIG_NET_FLOW_LIMIT
struct sd_flow_limit *fl;
rcu_read_lock();
fl = rcu_dereference(sd->flow_limit);
if (fl)
flow_limit_count = fl->count;
rcu_read_unlock();
#endif
seq_printf(seq, "%08x %08x %08x %08x %08x %08x %08x %08x %08x %08x %08x %08x %08x\n",
sd->processed, sd->dropped, sd->time_squeeze, 0, 0, 0, 0,
0, /* was fastroute */
0, /* was cpu_collision */
sd->received_rps, flow_limit_count, softnet_backlog_len(sd),
(int)seq->index);
return 0;
}
从代码可以看出 IPI 的次数记录在了 softnet_data 的 received_rps 里,除了 IPI 还有第 12 列的 backlog 队列长度。
3.7 递交协议栈
如图4 调用链所示,netif_receive_skb_list_internal 函数经过多层调用,最后会执行 __netif_receive_skb_core 函数,这是网络数据包接收的核心函数,负责处理接收到的数据包并决定如何传递给上层协议处理。这里面做的事情非常多, 按顺序包括:
- 准备工作;
- XDP 处理;
- VLAN 标记;
- TAP 处理;
- TC 处理;
- Netfilter 处理;
- 递交协议栈。
有的网卡会在 poll 函数里调用 netif_receive_skb 将数据包交到上层网络栈继续处理。最后发现同样会调用到 __netif_receive_skb_core 函数。
__netif_receive_skb_core 函数代码如下:
static int __netif_receive_skb_core(struct sk_buff **pskb, bool pfmemalloc, struct packet_type **ppt_prev)
{
struct packet_type *ptype, *pt_prev;
rx_handler_func_t *rx_handler;
struct sk_buff *skb = *pskb;
struct net_device *orig_dev;
bool deliver_exact = false;
int ret = NET_RX_DROP;
__be16 type;
// 检查网络包的时间戳。
net_timestamp_check(!READ_ONCE(netdev_tstamp_prequeue), skb);
// 跟踪网络数据包的接收过程,用于调试和性能分析。
trace_netif_receive_skb(skb);
// 将接收到的数据包的网络设备指针保存到 orig_dev 变量中,以备后续使用。
orig_dev = skb->dev;
// 重置网络头部的偏移量,使其指向正确的位置。
skb_reset_network_header(skb);
if (!skb_transport_header_was_set(skb))
//如果传输头部未设置,则重置传输层头部的偏移量,使其指向正确的位置。
skb_reset_transport_header(skb);
// 重置数据包的 MAC 长度。
skb_reset_mac_len(skb);
// 将 pt_prev 变量初始化为空,用于存储上一个处理函数。
pt_prev = NULL;
another_round: //这是一个标签,用于在处理过程中跳转到此处重新执行一轮处理。
// 设置数据包的 skb_iif 字段,表示skb 是从哪个网络设备接收的。
skb->skb_iif = skb->dev->ifindex;
// 增加当前 CPU 上的 softnet_data.processed 字段的计数。
__this_cpu_inc(softnet_data.processed);
// 如果启用了 Generic XDP(软件实现 XDP 功能),则调用do_xdp_generic()函数执行 XDP 通用程序的处理。
if (static_branch_unlikely(&generic_xdp_needed_key)) {
int ret2;
migrate_disable();
ret2 = do_xdp_generic(rcu_dereference(skb->dev->xdp_prog), skb);
migrate_enable();
// 如果返回结果不是XDP_PASS,则将返回值设置为NET_RX_DROP并跳转到标签out处。
if (ret2 != XDP_PASS) {
ret = NET_RX_DROP;
goto out;
}
}
// 如果数据包是以太网 VLAN 数据包,则调用skb_vlan_untag()函数将 VLAN 标签从数据包中移除。
if (eth_type_vlan(skb->protocol)) {
skb = skb_vlan_untag(skb);
// 如果 skb 为空,则跳转到 out 标签
if (unlikely(!skb))
goto out;
}
// 如果需要跳过 TC 分类,则直接跳转到 skip_classify 标签。
if (skb_skip_tc_classify(skb))
goto skip_classify;
// 如果 pfmemalloc 为 true,则跳转到 skip_taps 标签。
if (pfmemalloc)
goto skip_taps;
// 这个循环遍历全局的注册的协议处理函数 ptype_all 链表,依次调用 deliver_skb 函数传递数据包给每个注册的协议处理程序。
list_for_each_entry_rcu(ptype, &ptype_all, list) {
if (pt_prev)
ret = deliver_skb(skb, pt_prev, orig_dev); // 抓包:dev_add_pack(&po->prot_hook) 注册的钩子函数
pt_prev = ptype;
}
// 这个循环遍历接收数据包的网络设备的协议处理函数 ptype_all 链表,同样依次调用 deliver_skb 函数传递数据包给每个注册的协议处理程序。
list_for_each_entry_rcu(ptype, &skb->dev->ptype_all, list) {
if (pt_prev)
ret = deliver_skb(skb, pt_prev, orig_dev); // 抓包:dev_add_pack(&po->prot_hook) 注册的钩子函数
pt_prev = ptype;
}
skip_taps: // 如果是使用 goto 跳转过来的,那跳过了抓包逻辑(libpcap、tcpdump 等)
#ifdef CONFIG_NET_INGRESS // 这部分代码用于处理网络数据包的入口(ingress)功能,即在数据包进入网络协议栈之前进行处理。
// 如果需要进行 TC ingress 处理
if (static_branch_unlikely(&ingress_needed_key)) {
bool another = false;
// 跳过 egress
nf_skip_egress(skb, true);
// 处理 ingress
skb = sch_handle_ingress(skb, &pt_prev, &ret, orig_dev, &another);
// 如果还需要进行下一轮处理,则跳转到 another_round 标签
if (another) //TC BPF 优化,通过 another round 将包从宿主机网卡直接送到容器 netns 内网卡 ?
goto another_round;
if (!skb)
goto out;
// 跳过 egress
nf_skip_egress(skb, false);
// 处理 Netfilter ingress
if (nf_ingress(skb, &pt_prev, &ret, orig_dev) < 0)
goto out;
}
#endif
// 重置数据包的重定向标志
skb_reset_redirect(skb);
skip_classify: // 如果是使用 goto 跳转过来的,那跳过了抓包、TC、Netfilter 逻辑
// 如果 pfmemalloc 为 true,并且 skb 没有设置 pfmemalloc 协议,则跳转到 drop 标签
if (pfmemalloc && !skb_pfmemalloc_protocol(skb))
goto drop;
if (skb_vlan_tag_present(skb)) {
// 如果数据包中存在 VLAN 标签,则调用 deliver_skb() 函数将数据包传递给之前注册的协议处理函数进行处理
if (pt_prev) {
ret = deliver_skb(skb, pt_prev, orig_dev);
pt_prev = NULL;
}
// 调用 vlan_do_receive() 函数处理 VLAN 相关操作
if (vlan_do_receive(&skb))
goto another_round;
else if (unlikely(!skb))
goto out;
}
// 获取接收该数据包的网络设备的接收处理函数(rx_handler)
rx_handler = rcu_dereference(skb->dev->rx_handler);
if (rx_handler) {
// 如果接收处理函数存在,则调用 deliver_skb() 函数将数据包传递给接收处理函数进行处理
if (pt_prev) {
ret = deliver_skb(skb, pt_prev, orig_dev);
pt_prev = NULL;
}
// 根据接收处理函数的返回值,有不同的处理逻辑
switch (rx_handler(&skb)) {
case RX_HANDLER_CONSUMED:
ret = NET_RX_SUCCESS;
goto out;
case RX_HANDLER_ANOTHER:
goto another_round;
case RX_HANDLER_EXACT:
deliver_exact = true;
break;
case RX_HANDLER_PASS:
break;
default:
BUG();
}
}
// 如果存在 VLAN 标签,并且网络设备不使用 DSA(Distributed Switch Architecture)
if (unlikely(skb_vlan_tag_present(skb)) && !netdev_uses_dsa(skb->dev)) {
check_vlan_id:
if (skb_vlan_tag_get_id(skb)) {
// VLAN ID 非 0,并且无法找到 VLAN 设备
skb->pkt_type = PACKET_OTHERHOST;
} else if (eth_type_vlan(skb->protocol)) {
// 外部头部是 802.1P 带有 VLAN 0,内部头部是 802.1Q 或 802.1AD,并且无法找到 VLAN ID 0 对应的 VLAN 设备
__vlan_hwaccel_clear_tag(skb);
skb = skb_vlan_untag(skb);
if (unlikely(!skb))
goto out;
if (vlan_do_receive(&skb))
goto another_round;
else if (unlikely(!skb))
goto out;
else
goto check_vlan_id;
}
__vlan_hwaccel_clear_tag(skb);
}
// 获取数据包的协议类型
type = skb->protocol;
if (likely(!deliver_exact))
// 如果没有设置精确匹配,将调用 deliver_ptype_list_skb() 函数传递数据包给指定的注册的协议处理函数处理。
deliver_ptype_list_skb(skb, &pt_prev, orig_dev, type, &ptype_base[ntohs(type) & PTYPE_HASH_MASK]);
// 调用 deliver_ptype_list_skb() 函数传递数据包给指定的协议处理函数处理
deliver_ptype_list_skb(skb, &pt_prev, orig_dev, type, &orig_dev->ptype_specific);
if (unlikely(skb->dev != orig_dev))
// 如果数据包的网络设备与接收时的网络设备不一致,将调用 deliver_ptype_list_skb() 函数传递数据包给指定的协议处理函数处理。
deliver_ptype_list_skb(skb, &pt_prev, orig_dev, type, &skb->dev->ptype_specific);
if (pt_prev) {
// 如果存在上一个协议处理函数,将调用该处理函数来处理数据包。说明数据包有未处理的分片数据,调用 skb_orphan_frags_rx 函数处理剩余的分片数据。
if (unlikely(skb_orphan_frags_rx(skb, GFP_ATOMIC)))
goto drop;
*ppt_prev = pt_prev;
} else {
// 如果不存在上一个协议处理函数,表示没有合适的处理函数来处理数据包,将丢弃数据包并增加接收丢弃计数。
drop:
if (!deliver_exact)
// 更新网卡的 rx_dropped 统计
dev_core_stats_rx_dropped_inc(skb->dev);
else
// 更新网卡的 rx_nohandler 统计
dev_core_stats_rx_nohandler_inc(skb->dev);
kfree_skb_reason(skb, SKB_DROP_REASON_UNHANDLED_PROTO);
ret = NET_RX_DROP;
}
out:
//将处理完的 skb 赋值回 pskb 指针
*pskb = skb;
return ret;
}
3.7.1 准备工作
函数开始时,对传入的数据包进行一些准备工作,如:
- 处理 skb 时间戳;
- 重置网络头;
- 重置传输头;
- 重置 MAC 长度;
- 设置数据包的接收接口索引。
3.7.2 XDP(eXpress Data Path)处理
这里的 XDP 是软件层面的实现,当硬件网卡不支持 offload 模式的 XDP,可以选择 Generic 模式的 XDP。
- 前者早在 igb_clean_rx_irq 中执行(前面讲过)避免了后面很多流程所以效率很高;
- 后者效率低,做了很多无用功,所以主要用来功能验证和测试。
3.7.3 VLAN 处理
如果数据包使用了 VLAN 标记,首先去除 VLAN 标记,并判断是否成功。
- 如果成功,继续处理去除标记后的数据包;
- 否则,跳过该数据包。
3.7.4 TAP 处理
根据数据包的 packet_type,按照 ptype_all 链表中的顺序遍历所有的 packet_type,逐个尝试将数据包交给相应的处理函数进行处理。比如交给前面初始化注册的函数,一般通过 libpcap 库埋的探测点(TAP),用于 tcpdump 抓包。
net/packet/af_packet.c: dev_add_pack(&po->prot_hook); //用于抓包
net/packet/af_packet.c: dev_add_pack(&f->prot_hook); //用于抓包
3.7.5 TC 处理
TC(Traffic Control)是 Linux 的流量控制子系统,通过调用 sch_handle_ingress 函数进入 TC ingress 处理。
- 以前主要用于限速;
- 5.10 版本之后,可以使用 TC BPF 编程来做流量的透明拦截和负载均衡。
3.7.6 Netfilter 处理
Netfilter 是 Linux 的包过滤子系统,iptables 是其用户空间的客户端。通过调用 nf_ingress 函数进入 Netfilter ingress 处理。
3.7.7 递交协议栈
根据协议类型packet_type.type在 ptype_base 哈希表中找到对应函数保存在packet_type.func,最终通过 deliver_skb 函数调用packet_type.func把skb交到对应的处理函数处理。
- 例如
packet_type.func = prot_hook,就会递交到af_packe,可以被tcpdump抓包; - 例如
packet_type.func = ip_rcv,就会递交到协议栈入口。
static inline int deliver_skb(struct sk_buff *skb, struct packet_type *pt_prev, struct net_device *orig_dev)
{
if (unlikely(skb_orphan_frags_rx(skb, GFP_ATOMIC)))
return -ENOMEM;
refcount_inc(&skb->users);
return pt_prev->func(skb, skb->dev, pt_prev, orig_dev);
}
四、网络层(IP)
上一步调用 ip_rcv 把skb递交到了协议栈,接下来继续跟踪skb的去向。
4.1 概述
数据包在本层主要处理流程有三(有序):
- 数据包进入协议栈入口,接收检查,以及 Netfilter 的过滤和修改等操作;
- 通过 Early Demux(早期解复用)和查询 IP Route System(路由子系统)为数据包找到
目标入口; - 如果
目标入口在本机器,则转发出去;反之,根据协议类型递交到传输层的不同协议入口。

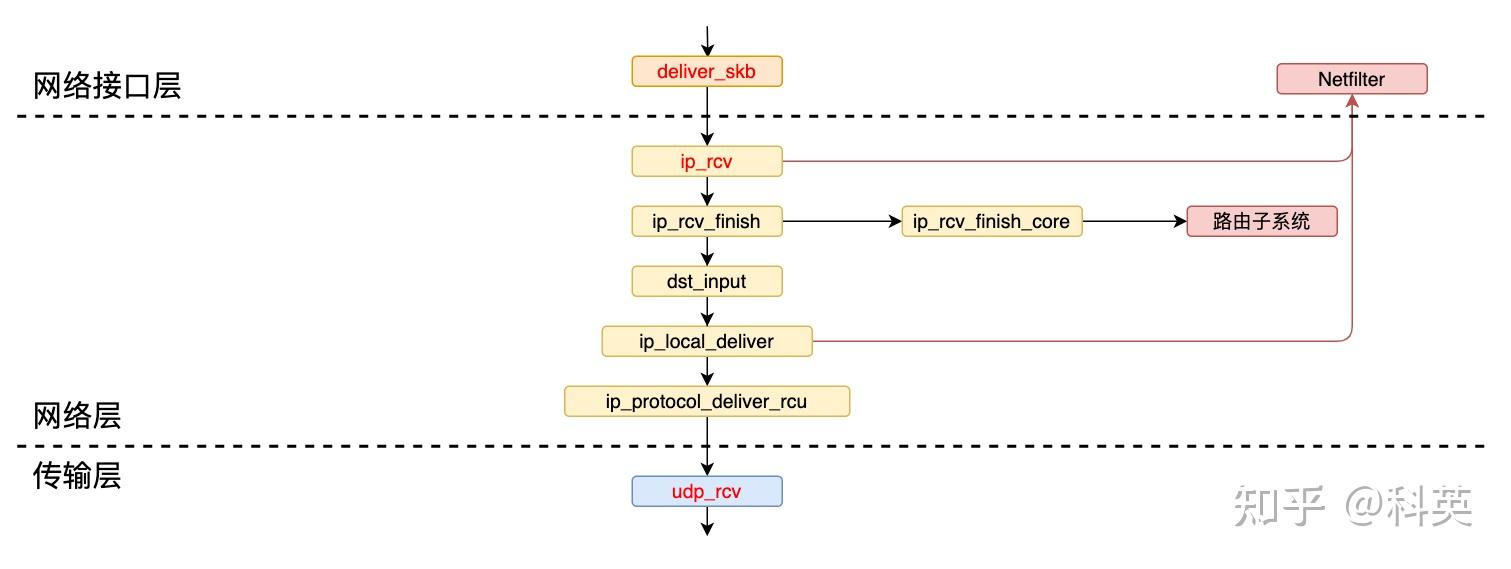
4.2 协议栈入口
4.1.1 ip_rcv 函数
// IP receive entry point
int ip_rcv(struct sk_buff *skb, struct net_device *dev, struct packet_type *pt, struct net_device *orig_dev)
{
struct net *net = dev_net(dev);
skb = ip_rcv_core(skb, net);
if (skb == NULL)
return NET_RX_DROP;
return NF_HOOK(NFPROTO_IPV4, NF_INET_PRE_ROUTING, net, NULL, skb, dev, NULL, ip_rcv_finish);
}
这是 IP 层的入口点,其逻辑比较简单,主要用于执行各种检查,以及 Netfilter 规则过滤和修改:
- 一旦通过了所有的检查,它会执行 NF_HOOK 函数;
- 如果某个检查失败需要丢弃数据包,函数会返回
NET_RX_DROP并计数丢弃的数据包数量。
#ifdef CONFIG_NETFILTER
static inline int
NF_HOOK(uint8_t pf, unsigned int hook, struct net *net, struct sock *sk, struct sk_buff *skb,
struct net_device *in, struct net_device *out,
int (*okfn)(struct net *, struct sock *, struct sk_buff *))
{
int ret = nf_hook(pf, hook, net, sk, skb, in, out, okfn);
if (ret == 1)
ret = okfn(net, sk, skb);
return ret;
}
#else /* !CONFIG_NETFILTER */
static inline int
NF_HOOK(uint8_t pf, unsigned int hook, struct net *net, struct sock *sk,
struct sk_buff *skb, struct net_device *in, struct net_device *out,
int (*okfn)(struct net *, struct sock *, struct sk_buff *))
{
return okfn(net, sk, skb);
}
#endif /*CONFIG_NETFILTER*/
NF_HOOK 函数会调用 nf_hook 来根据不同的规则对数据包进行过滤和修改,这些规则都是事先用户通过 iptables 工具调用 Netfilter 模块添加的。
- 如果 nf_hook 返回非 1,将 nf_hook 的结果返回给 ip_rcv,
skb将不会继续被处理,到此为止; - 如果 nf_hook 返回 1,表示 Netfilter 允许继续处理该数据包,然后将
skb传入 ip_rcv_finish 函数继续执行。
4.3 寻找目标入口
4.3.1 ip_rcv_finish 函数
static int ip_rcv_finish(struct net *net, struct sock *sk, struct sk_buff *skb)
{
struct net_device *dev = skb->dev;
int ret;
// 如果入口设备被绑定到一个 L3 主设备上,将把 skb 传递给该设备的处理程序进行处理。
skb = l3mdev_ip_rcv(skb);
if (!skb)
// 意味着该数据包由 L3 主设备处理
return NET_RX_SUCCESS;
ret = ip_rcv_finish_core(net, sk, skb, dev, NULL);
if (ret != NET_RX_DROP)
ret = dst_input(skb);
return ret;
}
其主要逻辑有二:
- 一是调用 ip_rcv_finish_core 函数完成对
skb->dst_entry的设置; - 二是调用 dst_input 函数,根据上一步设置的
skb->dst_entry来跳到下一个处理该skb的函数。
下面分别详细解释这两个逻辑。
4.3.2 ip_rcv_finish_core 函数
static int ip_rcv_finish_core(struct net *net, struct sock *sk, struct sk_buff *skb, struct net_device *dev, const struct sk_buff *hint) {
//声明了指向 iph 的指针,它指向 skb 中的 IP 数据报头。还声明了整型变量 err 和 drop_reason,用于存储错误码和丢弃原因。
const struct iphdr *iph = ip_hdr(skb);
int err, drop_reason;
struct rtable *rt;
drop_reason = SKB_DROP_REASON_NOT_SPECIFIED;
// 检查是否可以使用 hint 进行路由选择,如果可能,使用 hint 进行路由选择
if (ip_can_use_hint(skb, iph, hint)) {
err = ip_route_use_hint(skb, iph->daddr, iph->saddr, iph->tos, dev, hint);
if (unlikely(err))
goto drop_error;
}
// 检查是否启用了早期解复用(early demultiplexing)选项,且 dst_entry(目标入口)为空,且没有与之关联的套接字(skb->sk),且数据包不是一个 IP 分片。
if (READ_ONCE(net->ipv4.sysctl_ip_early_demux) && !skb_dst(skb) && !skb->sk && !ip_is_fragment(iph)) {
// 根据 IP 协议字段的值,它分别处理 TCP 和 UDP 数据包。如果早期解复用选项启用并且相应协议的早期解复用也启用,则调用相应的早期解复用函数,如 tcp_v4_early_demux 或 udp_v4_early_demux。
switch (iph->protocol) {
case IPPROTO_TCP:
if (READ_ONCE(net->ipv4.sysctl_tcp_early_demux)) {
tcp_v4_early_demux(skb);
iph = ip_hdr(skb);
}
break;
case IPPROTO_UDP:
if (READ_ONCE(net->ipv4.sysctl_udp_early_demux)) {
err = udp_v4_early_demux(skb);
if (unlikely(err))
goto drop_error;
iph = ip_hdr(skb);
}
break;
}
}
// 检查数据包的目的地址 dst_entry dst 是否有效。
if (!skb_valid_dst(skb)) {
// 如果目的地址 dst_entry dst 为空,即找不到与之对应的路由表项,将调用 ip_route_input_noref 函数来进行路由选择,并为数据包设置目的地址 dst_entry dst。
err = ip_route_input_noref(skb, iph->daddr, iph->saddr, iph->tos, dev);
if (unlikely(err))
goto drop_error;
}
#ifdef CONFIG_IP_ROUTE_CLASSID
// 如果系统启用了 IP 路由分类(ip route classid)功能,并且数据包的目的地缓冲区(skb_dst)的 tclassid 字段非零,将对分类统计信息进行更新。
if (unlikely(skb_dst(skb)->tclassid)) {
struct ip_rt_acct *st = this_cpu_ptr(ip_rt_acct);
u32 idx = skb_dst(skb)->tclassid;
st[idx & 0xFF].o_packets++;
st[idx & 0xFF].o_bytes += skb->len;
st[(idx >> 16) & 0xFF].i_packets++;
st[(idx >> 16) & 0xFF].i_bytes += skb->len;
}
#endif
// 检查 IP 数据报头的 IHL 字段(即 IP 头部长度)是否大于 5,并调用 ip_rcv_options 函数来处理 IP 选项字段。
if (iph->ihl > 5 && ip_rcv_options(skb, dev))
// 如果处理过程中发生错误,将跳转到 drop 标签处,丢弃数据包。
goto drop;
// 获取数据包的路由表项(rt)并检查其类型。
rt = skb_rtable(skb);
if (rt->rt_type == RTN_MULTICAST) {
// 如果路由表项类型是多播(RTN_MULTICAST),则更新多播接收统计信息。
__IP_UPD_PO_STATS(net, IPSTATS_MIB_INMCAST, skb->len);
} else if (rt->rt_type == RTN_BROADCAST) {
// 如果路由表项类型是广播(RTN_BROADCAST),则更新广播接收统计信息。
__IP_UPD_PO_STATS(net, IPSTATS_MIB_INBCAST, skb->len);
} else if (skb->pkt_type == PACKET_BROADCAST || skb->pkt_type == PACKET_MULTICAST) {
// 如果数据包的包类型是广播或多播,还会进行额外的处理。
struct in_device *in_dev = __in_dev_get_rcu(dev);
if (in_dev && IN_DEV_ORCONF(in_dev, DROP_UNICAST_IN_L2_MULTICAST)) {
drop_reason = SKB_DROP_REASON_UNICAST_IN_L2_MULTICAST;
goto drop;
}
}
// 函数返回 NET_RX_SUCCESS 或 NET_RX_DROP,表示数据包的处理结果。
return NET_RX_SUCCESS;
drop:
// 如果数据包被丢弃,将使用 kfree_skb_reason 函数释放数据包,并附带丢弃的原因。
kfree_skb_reason(skb, drop_reason);
return NET_RX_DROP;
drop_error:
// 路由选择失败。
if (err == -EXDEV) {
drop_reason = SKB_DROP_REASON_IP_RPFILTER;
__NET_INC_STATS(net, LINUX_MIB_IPRPFILTER);
}
goto drop;
}
其主要逻辑有二:
- 如果开启了 ip_early_demux(早期解复用),这是一项优化,为了 TCP 和 UDP 可以提前获得 skb 的 dst_entry(目标入口);
- 当 skb 为 TCP 报文并且开启了 tcp_early_demux 选项,则调用 tcp_v4_early_demux 函数,根据 skb 的源地址、目的地址等信息从 ESTABLISHED 连接列表中找到对应的 Socket,把 Socket 中缓存的 sk_rx_dst(struct dst_entry)设置到 skb->dst 中。还会将 Socket 的 struct sock 指针设置到 skb->sk,这样 TCP 层就不用重复查连接列表了;
- 当 skb 为 UDP 报文并且开启了 udp_early_demux 选项,则调用 udp_v4_early_demux 函数,拿 skb 的 UDP 头信息在 UDP 「解复用表」中寻找 Socket,如果有,把 Socket 中缓存的 dst_entry 设置到 skb->dst;
- 如果没开启 ip_early_demux 或者开启了上步中没有完成对 skb->dst 的设置,那么就需要调用 ip_route_input_noref 函数去「路由子系统」查询来获得 skb 的 dst_entry,这个过程比较复杂。
TCP 新建立的 Socket 会把 skb->dst 设置到 struct sock 的 sk_rx_dst 中。
Early Demux(早期解复用)和查询 IP Route System(路由子系统)目的都是为了设置 skb->dst,如果 skb 是发给本机器,那么 Early Demux 和查询 IP Route System 获得的 dst_entry 会是同一个函数 ip_local_deliver;如果不是本机器,那么会转发出去,不在本文讨论范围内。
early_demux 的作用
对于 TCP,创建好 Socket 并且进入 ESTABLISHED 状态后,后续包的「目标入口」跟握手时包的「目标入口」完全相同;对于 UDP 没有状态限制,五元组相同的包的「目标入口」完全相同。如果能找到对应的已经缓存好「目标入口」的 Socket,那么就不需要查询一次「路由子系统」,所以就有了 Early Demux 机制。默认 Early Demux 是打开的。
$ sysctl -a |grep early demux
net.ipv4.ip_early_demux = 1 #IP
net.ipv4.tcp_early_demux = 1 #TCP
net.ipv4.udp_early_demux = 1 #UDP
early_demux 的缺点
Early Demux 机制的引入可以在大多数情况下减少查询次数,提高性能。然而,它并非没有代价。在某些场景下,特别是大量短连接的情况下,开启该机制可能会导致性能损耗,比如,对于那些在 TCP ESTABLISHED 表中找不到对应 Socket 的数据包,会经历 Early Demux 过程、查询「路由子系统」和 TCP 层又要再查一次 Socket 表,增加总体开销。在特定场景下,有人测试 Early Demux 机制会带来最大 5% 的性能损耗。因此,Linux 提供了关闭 Early Demux 机制的选项,以满足特定需求。
$ sysctl -w net.ipv4.ip_early_demux=0
4.4 递交传输层
4.4.1 dst_input 函数
/* Input packet from network to transport. */
static inline int dst_input(struct sk_buff *skb)
{
return INDIRECT_CALL_INET(skb_dst(skb)->input, ip6_input, ip_local_deliver, skb);
}
前面已经获取到 skb 的 dst_entry(目标入口),然后调用 dst_input(skb),skb->dst.input 是一个函数指针,创建 Socket 时就被「路由子系统」初始化了。如果 skb 是发给本机器的,那么 skb->dst.input 就是 ip_local_deliver。最后调用 ip_local_deliver(skb)。
4.4.2 ip_local_deliver 函数
/* Deliver IP Packets to the higher protocol layers. */
int ip_local_deliver(struct sk_buff *skb)
{
struct net *net = dev_net(skb->dev);
// 使用 ip_is_fragment 函数检查 IP 数据包是否是一个片段。
if (ip_is_fragment(ip_hdr(skb))) {
// 如果是片段,则使用 ip_defrag 函数进行 IP 片段重组。
if (ip_defrag(net, skb, IP_DEFRAG_LOCAL_DELIVER))
return 0;
}
// 调用 NF_HOOK 宏将数据包传递给 Netfilter 框架中的 NF_INET_LOCAL_IN 钩子,以进行进一步处理。
return NF_HOOK(NFPROTO_IPV4, NF_INET_LOCAL_IN, net, NULL, skb, skb->dev, NULL, ip_local_deliver_finish);
}
其主要逻辑有三:
- 使用 ip_is_fragment 函数检查 IP 数据包是否是一个片段。如果是,则使用 ip_defrag 函数进行 IP 片段重组;
- 调用 NF_HOOK 宏将数据包传递给 Netfilter 框架中的 NF_INET_LOCAL_IN 钩子,进一步处理。和 ip_rcv 函数中调用 NF_HOOK 类似;
- 如果数据包没有被 Netfilter 过滤掉,那么执行 ip_local_deliver_finish 函数继续处理 skb 。
4.4.3 ip_local_deliver_finish 函数
static int ip_local_deliver_finish(struct net *net, struct sock *sk, struct sk_buff *skb)
{
// 清除数据包的传递时间信息
skb_clear_delivery_time(skb);
// 移动数据指针,将 skb 的偏移设置为网络头部的长度
__skb_pull(skb, skb_network_header_len(skb));
// 锁定 RCU(Read-Copy-Update)机制,以确保数据包处理期间的数据一致性。
rcu_read_lock();
// 使用 IP 协议号调用 ip_protocol_deliver_rcu 函数进行数据包的处理
// 这行代码使用 IP 协议号(从 IP 头部获取)调用 ip_protocol_deliver_rcu 函数来处理数据包。该函数将根据协议号选择适当的处理方式,将数据包传递给相应的协议处理函数。
ip_protocol_deliver_rcu(net, skb, ip_hdr(skb)->protocol);
//解锁 RCU,释放对数据包的访问锁定。
rcu_read_unlock();
return 0;
}
其主要逻辑有二:
- 清除数据包的时间信息和移动 skb 偏移量指向 IP 头部;
- 调用 ip_protocol_deliver_rcu 函数根据协议类型寻找处理 skb 的传输层入口函数。
4.4.4 ip_protocol_deliver_rcu 函数
void ip_protocol_deliver_rcu(struct net *net, struct sk_buff *skb, int protocol)
{
const struct net_protocol *ipprot;
int raw, ret;
resubmit:
// 进行原始数据包的本地传递
raw = raw_local_deliver(skb, protocol);
// 根据协议号 protocol 从 inet_protos 数组中获取对应的协议处理函数
ipprot = rcu_dereference(inet_protos[protocol]);
if (ipprot) {
if (!ipprot->no_policy) {
// 检查是否需要进行安全策略检查
if (!xfrm4_policy_check(NULL, XFRM_POLICY_IN, skb)) {
// 未通过安全策略检查,释放数据包并返回
kfree_skb_reason(skb, SKB_DROP_REASON_XFRM_POLICY);
return;
}
// 重置数据包的连接追踪信息
nf_reset_ct(skb);
}
// 调用相应的协议处理函数,如 TCP 协议调用 tcp_v4_rcv(skb)
ret = INDIRECT_CALL_2(ipprot->handler, tcp_v4_rcv, udp_rcv, skb);
if (ret < 0) {
// 如果失败,需要重新提交数据包给另一个协议处理函数
protocol = -ret;
goto resubmit;
}
// 增加 IP 数据包传递的统计信息
__IP_INC_STATS(net, IPSTATS_MIB_INDELIVERS);
} else {
if (!raw) {
// 未找到协议处理函数且数据包不是原始数据包
if (xfrm4_policy_check(NULL, XFRM_POLICY_IN, skb)) {
// 安全策略检查通过,发送 ICMP 目的不可达消息
__IP_INC_STATS(net, IPSTATS_MIB_INUNKNOWNPROTOS);
icmp_send(skb, ICMP_DEST_UNREACH, ICMP_PROT_UNREACH, 0);
}
// 释放数据包
kfree_skb_reason(skb, SKB_DROP_REASON_IP_NOPROTO);
} else {
// 数据包是原始数据包,增加 IP 数据包传递的统计信息
__IP_INC_STATS(net, IPSTATS_MIB_INDELIVERS);
// 释放数据包
consume_skb(skb);
}
}
}
其主要逻辑就是根据skb的协议类型ip_hdr(skb)->protocol在协议栈初始化时注册的inet_protos数组中寻找对应的处理函数,并调用该函数。下面是 TCP 和 UDP 协议以及对应的处理函数handler。
static const struct net_protocol tcp_protocol = {
.handler = tcp_v4_rcv,
.err_handler = tcp_v4_err,
.no_policy = 1,
.icmp_strict_tag_validation = 1,
};
static const struct net_protocol udp_protocol = {
.handler = udp_rcv,
.err_handler = udp_err,
.no_policy = 1,
};
五、传输层(UDP)
假如上节中的skb的协议类型是 UDP,那么处理函数handler是 udp_rcv,skb进入 UDP 层继续处理。
5.1 概述
数据包在本层主要处理流程有五(有序):
- 数据包进入传输层(UDP)入口,接收检查,以及获取对应的 Socket;
- 判断数据包是否超过 GSO 阈值,如果没有跳过,反之,需要把skb分段处理;
- 特殊类型套接字(比如,封装套接字)的处理和处理挂在的 Socket BPF 程序;
- 检查套接字的接收队列是否满了,满了则丢掉skb,没满则把skb插入接收队列;
- 唤醒 Socket 上因为没有数据而阻塞等待数据的线程;
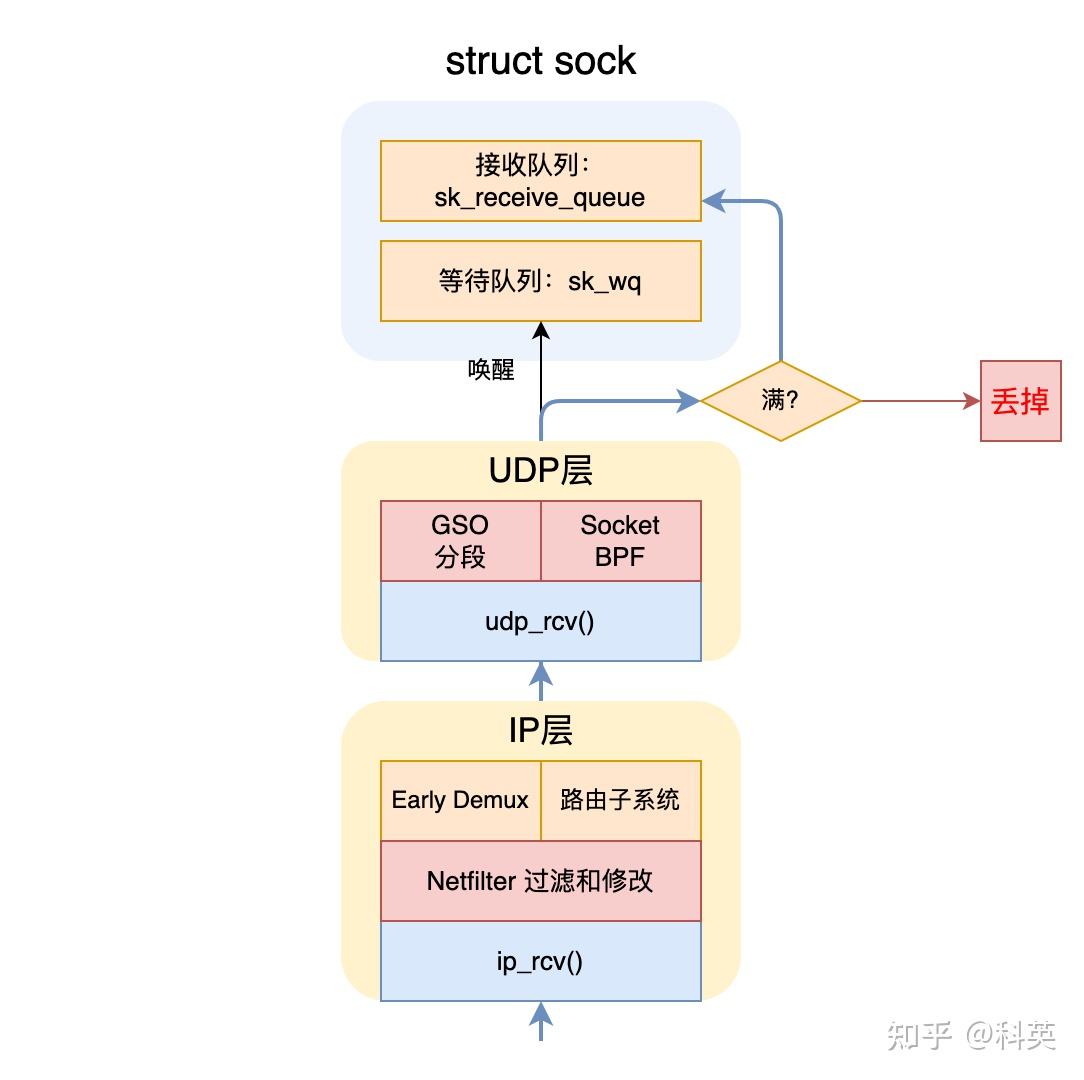
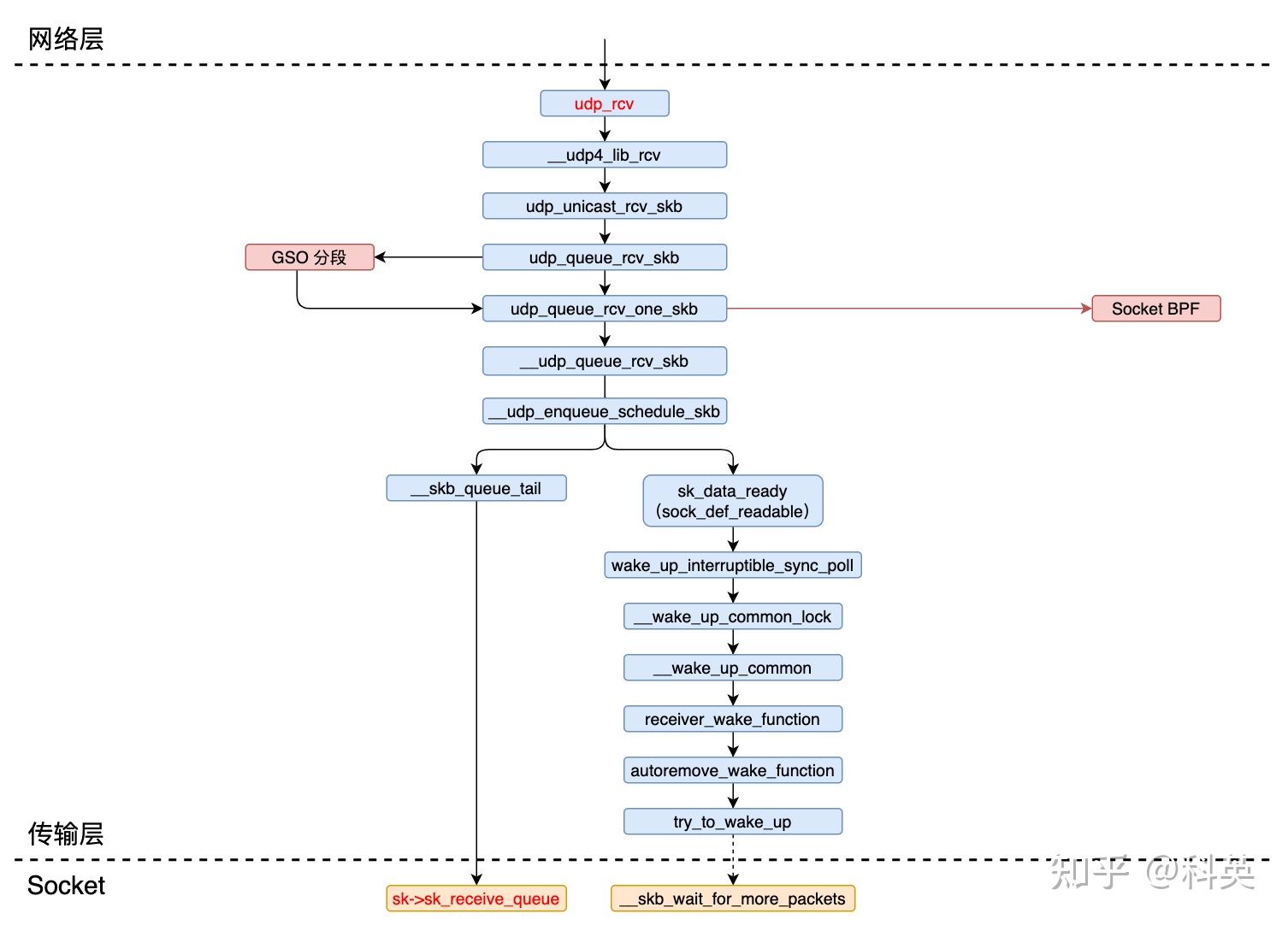
5.2 传输层(UDP)入口
5.2.1 udp_rcv 函数
int udp_rcv(struct sk_buff *skb)
{
return __udp4_lib_rcv(skb, &udp_table, IPPROTO_UDP);
}
该函数只有一行代码,其主要逻辑封装在 __udp4_lib_rcv 函数中,udp_table是 UDP 套接字表。
5.2.2 __udp4_lib_rcv 函数
int __udp4_lib_rcv(struct sk_buff *skb, struct udp_table *udptable, int proto)
{
struct sock *sk;
struct udphdr *uh;
unsigned short ulen;
struct rtable *rt = skb_rtable(skb);
__be32 saddr, daddr;
struct net *net = dev_net(skb->dev);
bool refcounted;
int drop_reason;
drop_reason = SKB_DROP_REASON_NOT_SPECIFIED;
// 验证数据包。
if (!pskb_may_pull(skb, sizeof(struct udphdr)))
// 没有足够的空间来存储头部。
goto drop;
uh = udp_hdr(skb);
ulen = ntohs(uh->len);
saddr = ip_hdr(skb)->saddr;
daddr = ip_hdr(skb)->daddr;
// 检查数据包长度是否正确
if (ulen > skb->len)
goto short_packet;
if (proto == IPPROTO_UDP) {
// 如果是 UDP 协议,验证 ulen
if (ulen < sizeof(*uh) || pskb_trim_rcsum(skb, ulen))
goto short_packet;
uh = udp_hdr(skb);
}
// 初始化 UDP 校验和
if (udp4_csum_init(skb, uh, proto))
goto csum_error;
// 尝试从 skb 中获取套接字 Socket
sk = skb_steal_sock(skb, &refcounted);
if (sk) {
struct dst_entry *dst = skb_dst(skb);
int ret;
// 如果套接字的 sk_rx_dst 不等于当前数据包的目标入口,则更新 sk_rx_dst
if (unlikely(rcu_dereference(sk->sk_rx_dst) != dst))
udp_sk_rx_dst_set(sk, dst);
// 调用 udp_unicast_rcv_skb 处理套接字,并返回。
ret = udp_unicast_rcv_skb(sk, skb, uh);
if (refcounted)
sock_put(sk);
return ret;
}
// 检查数据包是否广播或多播
if (rt->rt_flags & (RTCF_BROADCAST|RTCF_MULTICAST))
return __udp4_lib_mcast_deliver(net, skb, uh, saddr, daddr, udptable, proto);
// 在 UDP 套接字表(udptable)中查找套接字
sk = __udp4_lib_lookup_skb(skb, uh->source, uh->dest, udptable);
if (sk)
// 调用 udp_unicast_rcv_skb 处理套接字,并返回。
return udp_unicast_rcv_skb(sk, skb, uh);
// 检查安全策略
if (!xfrm4_policy_check(NULL, XFRM_POLICY_IN, skb))
goto drop;
nf_reset_ct(skb);
// 没有套接字。如果校验和错误,则静默地丢弃数据包。
if (udp_lib_checksum_complete(skb))
goto csum_error;
// 数据包无法传递到套接字,发送 ICMP 目的地不可达消息
drop_reason = SKB_DROP_REASON_NO_SOCKET;
__UDP_INC_STATS(net, UDP_MIB_NOPORTS, proto == IPPROTO_UDPLITE);
icmp_send(skb, ICMP_DEST_UNREACH, ICMP_PORT_UNREACH, 0);
// 我们收到了一个发送到我们不想侦听的端口的 UDP 数据包。忽略它。
kfree_skb_reason(skb, drop_reason);
return 0;
short_packet:
drop_reason = SKB_DROP_REASON_PKT_TOO_SMALL;
net_dbg_ratelimited("UDP%s: short packet: From %pI4:%u %d/%d to %pI4:%u\n",
proto == IPPROTO_UDPLITE ? "Lite" : "",
&saddr, ntohs(uh->source),
ulen, skb->len,
&daddr, ntohs(uh->dest));
goto drop;
csum_error:
// RFC1122: 根据 4.1.3.4 的规定(必须),静默地丢弃坏的数据包(就网络而言)。
drop_reason = SKB_DROP_REASON_UDP_CSUM;
net_dbg_ratelimited("UDP%s: bad checksum. From %pI4:%u to %pI4:%u ulen %d\n",
proto == IPPROTO_UDPLITE ? "Lite" : "",
&saddr, ntohs(uh->source), &daddr, ntohs(uh->dest),
ulen);
__UDP_INC_STATS(net, UDP_MIB_CSUMERRORS, proto == IPPROTO_UDPLITE);
drop:
__UDP_INC_STATS(net, UDP_MIB_INERRORS, proto == IPPROTO_UDPLITE);
kfree_skb_reason(skb, drop_reason);
return 0;
}
其主要逻辑有二:
- 对数据包进行合法性检查,包括数据包的长度和校验和等,并获取 UDP 头的指针和长度,以及数据包的源地址和目的地址。
- 获取skb对应的套接字Socket,有两种可能:
- 如果在 IP 层通过 udp_v4_early_demux 函数skb获取到了其对应的Socket和dst_entry,那么调用 udp_unicast_rcv_skb 函数继续处理,节省了对udptable的查询;
- 否则,在 UDP 套接字表udptable中查找skb对应的套接字,如果找到了同样调用 udp_unicast_rcv_skb 函数,否则丢掉skb,并发送 ICMP 消息不可达报文。
5.3 校验和转换和 GSO 分段处理
5.3.1 udp_unicast_rcv_skb 函数
static int udp_unicast_rcv_skb(struct sock *sk, struct sk_buff *skb, struct udphdr *uh)
{
int ret;
// 如果套接字启用了校验和转换,并且数据包的校验和字段非零,并且不是 UDPLITE 协议,则尝试转换校验和
if (inet_get_convert_csum(sk) && uh->check && !IS_UDPLITE(sk))
skb_checksum_try_convert(skb, IPPROTO_UDP, inet_compute_pseudo);
// 将数据包放入套接字接收队列中进行处理,并获取返回值
ret = udp_queue_rcv_skb(sk, skb);
// 返回值 > 0 表示需要重新提交输入,但要求返回值为 -protocol 或 0
if (ret > 0)
return -ret;
return 0;
}
该函数先则尝试转换校验和,然后调用其主要逻辑 udp_queue_rcv_skb 函数。
5.3.2 udp_queue_rcv_skb 函数
static int udp_queue_rcv_skb(struct sock *sk, struct sk_buff *skb)
{
struct sk_buff *next, *segs;
int ret;
// 如果数据包的大小不超过预期的 GSO(Generic Segmentation Offload)阈值。
if (likely(!udp_unexpected_gso(sk, skb)))
// 直接将数据包放入套接字的接收队列中,并调用 udp_queue_rcv_one_skb 函数处理数据包。
return udp_queue_rcv_one_skb(sk, skb);
// 对数据包进行预处理,将数据包的数据部分前移,以排除以太网头部。
BUILD_BUG_ON(sizeof(struct udp_skb_cb) > SKB_GSO_CB_OFFSET);
__skb_push(skb, -skb_mac_offset(skb));
// 进行 UDP 分段操作,将数据包分成多个段。
segs = udp_rcv_segment(sk, skb, true);
// 使用 skb_list_walk_safe 宏遍历分段后的数据包链表。
skb_list_walk_safe(segs, skb, next) {
// 通过 __skb_pull 将数据包的数据部分前移,以排除传输层头部。
__skb_pull(skb, skb_transport_offset(skb));
// 修复分段后的数据包的校验和。
udp_post_segment_fix_csum(skb);
// 调用 udp_queue_rcv_one_skb 函数将分段后的数据包放入套接字的接收队列中进行处理。
ret = udp_queue_rcv_one_skb(sk, skb);
if (ret > 0)
// 如果返回值大于 0,表示需要重新提交输入,调用 ip_protocol_deliver_rcu 函数进行处理。
ip_protocol_deliver_rcu(dev_net(skb->dev), skb, ret);
}
return 0;
}
其主要逻辑有二:
- 判断数据包是否超过GSO阈值,如果没有那么直接调用 udp_queue_rcv_one_skb 函数将继续处理skb;
- 如果超过GSO阈值,那么需要把skb分段,每段分别修复校验和,然后每段调用一次 udp_queue_rcv_one_skb 函数继续处理。
GSO(Generic Segmentation Offload)是一种网络传输的优化技术,旨在提高数据包处理的效率和性能。它通过将大型数据包分段成较小的数据块,在网络适配器中进行分段和重新组装任务,以减轻主机负担,并优化网络带宽利用。这样可以加快传输速度、减少网络延迟,并提高网络应用的性能和减少响应时间。
5.4 处理特殊套接字和 BPF 程序
5.4.1 udp_queue_rcv_one_skb 函数
/* 返回值:
* -1:错误
* 0:成功
* >0:需要重新提交的 "udp encap" 协议
* 注意,在成功和错误的情况下,假设 skb 已经被重新排队或释放。
*/
static int udp_queue_rcv_one_skb(struct sock *sk, struct sk_buff *skb)
{
int drop_reason = SKB_DROP_REASON_NOT_SPECIFIED;
struct udp_sock *up = udp_sk(sk);
int is_udplite = IS_UDPLITE(sk);
// 对 IPv4 转发策略进行检查和验证。
if (!xfrm4_policy_check(sk, XFRM_POLICY_IN, skb)) {
// 如果不通过则丢弃数据包,并跳转到 drop 标签处。
drop_reason = SKB_DROP_REASON_XFRM_POLICY;
goto drop;
}
// 重置数据包的连接跟踪状态。
nf_reset_ct(skb);
// 如果启用了静态分支 udp_encap_needed_key,并且套接字的封装类型不为空,则进入封装套接字的处理分支。
if (static_branch_unlikely(&udp_encap_needed_key) && up->encap_type) {
int (*encap_rcv)(struct sock *sk, struct sk_buff *skb);
// 通过 READ_ONCE 读取封装套接字的 encap_rcv 函数指针。
encap_rcv = READ_ONCE(up->encap_rcv);
if (encap_rcv) {
int ret;
// 验证数据包的校验和
if (udp_lib_checksum_complete(skb))
goto csum_error;
ret = encap_rcv(sk, skb);
if (ret <= 0) {
// 如果返回值小于等于 0,则增加相应的统计信息,并返回 -ret,表示需要重新提交的协议。
__UDP_INC_STATS(sock_net(sk), UDP_MIB_INDATAGRAMS, is_udplite);
return -ret;
}
}
// 如果没有封装处理程序,则继续执行,表示数据包为普通的 UDP 数据包.
}
// 对于 UDP-Lite 套接字,执行特定的测试。如果设置了接收完全覆盖标志 UDPLITE_RECV_CC,并且数据包具有部分覆盖,则进入 if 分支。对于 UDP 套接字将被忽略
if ((up->pcflag & UDPLITE_RECV_CC) && UDP_SKB_CB(skb)->partial_cov) {
// 如果期望的覆盖范围为 0(完全覆盖),但实际部分覆盖,则输出警告信息并丢弃数据包。
if (up->pcrlen == 0) {
net_dbg_ratelimited("UDPLite: partial coverage %d while full coverage %d requested\n", UDP_SKB_CB(skb)->cscov, skb->len);
goto drop;
}
// 如果实际覆盖范围小于期望的最小覆盖范围,则输出警告信息并丢弃数据包。
if (UDP_SKB_CB(skb)->cscov < up->pcrlen) {
net_dbg_ratelimited("UDPLite: coverage %d too small, need min %d\n", UDP_SKB_CB(skb)->cscov, up->pcrlen);
goto drop;
}
}
// 对套接字的接收缓冲区进行预取,以优化后续的访问。
prefetch(&sk->sk_rmem_alloc);
// 应用 sk_filter,这允许在 socket 上执行 BPF 程序。
if (rcu_access_pointer(sk->sk_filter) && udp_lib_checksum_complete(skb))
// 如果套接字使用了 BPF 程序,并且数据包校验和验证失败,则跳转到 csum_error 标签处。
goto csum_error;
// 如果套接字的接收缓冲区大小小于 UDP 头部的大小,调整数据包的大小以适应套接字的接收缓冲区。
if (sk_filter_trim_cap(sk, skb, sizeof(struct udphdr))) {
drop_reason = SKB_DROP_REASON_SOCKET_FILTER;
goto drop;
}
// 对数据包进行 UDP 头部校验和的计算和校正。
udp_csum_pull_header(skb);
// 准备 IPv4 包信息,以备后续处理使用。
ipv4_pktinfo_prepare(sk, skb);
//将数据包放入套接字的接收队列中进行处理。
return __udp_queue_rcv_skb(sk, skb);
csum_error:
// 如果校验和验证失败,则设置丢弃原因为 UDP 校验和错误,并增加相应的统计信息。
drop_reason = SKB_DROP_REASON_UDP_CSUM;
__UDP_INC_STATS(sock_net(sk), UDP_MIB_CSUMERRORS, is_udplite);
drop:
// 设置丢弃原因,并增加相应的统计信息。
__UDP_INC_STATS(sock_net(sk), UDP_MIB_INERRORS, is_udplite);
// 增加套接字的丢弃计数。
atomic_inc(&sk->sk_drops);
// 释放数据包。
kfree_skb_reason(skb, drop_reason);
return -1;
}
其主要逻辑有六:
- 检查数据包的源 IP、目的 IP、传输层协议、端口号等信息,并与系统中配置的IPsec(Internet Protocol Security)策略进行匹配。如果匹配成功,内核将按照策略要求对数据包进行相应的处理,例如应用加密算法对数据包进行加密。如果没有匹配到合适的策略,数据包可能会被丢弃或按照默认策略进行处理;
- 如果skb关联的套接字是encapsulation socket(封装套接字),那么将skb送到对应的encap_rcv函数处理并返回,反之跳过;
- 如果skb是 UDP-Lite 数据报,那么需要检查一些完整性;
- 如果挂载了 Socket BPF 程序,那么执行该程序,有可能skb被 BPF 程序过滤掉,假如没有被过滤掉还需要验证校验和,通过才能继续往下走,否则丢掉;
- 对数据包进行 UDP 头部校验和的计算和校正,并且准备 IPv4 包信息,以备后续处理;
- 最后调用 __udp_queue_rcv_skb 函数继续处理skb。
封装套接字(encapsulation socket)是一种特殊类型的套接字,用于在协议栈中对数据包进行封装或解封装操作。它允许将一个协议的数据包封装在另一个协议的数据包中进行传输,在目的地处,封装套接字会解封装数据包,将其还原为原始的协议数据包。通过套接字的特定接口(例如 udp_encap_rcv 函数)与协议栈进行交互,实现封装和解封装的逻辑。使用场景包括虚拟专用网(VPN)、网络隧道(tunneling)协议(如 IPsec、GRE、L2TP)、网络功能虚拟化(NFV)等,可以在不同网络层级间进行数据包的封装和解封装操作,提供更灵活的网络通信方式。
上面提到的 Socket BPF 程序保存在sk_filter->prog中。
struct sk_filter {
refcount_t refcnt;
struct rcu_head rcu;
struct bpf_prog *prog;
};
5.5 把数据包插入接收队列
5.5.1 __udp_queue_rcv_skb 函数
static int __udp_queue_rcv_skb(struct sock *sk, struct sk_buff *skb)
{
int rc;
// 检查套接字的目的 IP 地址是否已设置。
if (inet_sk(sk)->inet_daddr) {
// 保存接收哈希值,用于接收包的分发。
sock_rps_save_rxhash(sk, skb);
// 标记套接字的 NAPI ID,用于后续的 NAPI 处理。
sk_mark_napi_id(sk, skb);
// 更新套接字的 incoming CPU,用于负载均衡。
sk_incoming_cpu_update(sk);
} else {
// 标记套接字的 NAPI ID。
sk_mark_napi_id_once(sk, skb);
}
// 将数据包加入套接字的接收队列进行调度处理。
rc = __udp_enqueue_schedule_skb(sk, skb);
if (rc < 0) {
// rc < 0,表示加入队列失败。
int is_udplite = IS_UDPLITE(sk);
int drop_reason;
// 根据返回值设置相应的统计信息增加计数,如接收缓冲区错误。根据返回值设置相应的丢弃原因(drop_reason)。
if (rc == -ENOMEM) {
UDP_INC_STATS(sock_net(sk), UDP_MIB_RCVBUFERRORS, is_udplite);
drop_reason = SKB_DROP_REASON_SOCKET_RCVBUFF;
} else {
UDP_INC_STATS(sock_net(sk), UDP_MIB_MEMERRORS, is_udplite);
drop_reason = SKB_DROP_REASON_PROTO_MEM;
}
// 增加相应的错误统计计数(UDP_MIB_INERRORS)。
UDP_INC_STATS(sock_net(sk), UDP_MIB_INERRORS, is_udplite);
// 释放数据包,并设置相应的丢弃原因。
kfree_skb_reason(skb, drop_reason);
// 记录失败的队列接收数据包事件。
trace_udp_fail_queue_rcv_skb(rc, sk);
return -1;
}
// rc > 0,加入接收队列成功。
return 0;
}
其主要逻辑有二:
- 根据目的 IP 是否设置,更新套接字的 incoming CPU 用于负载均衡和标记套接字的 NAPI ID;
- 调用 __udp_enqueue_schedule_skb 函数继续处理skb,如果返回值小于 0,表示加入接收队列失败,更新统计信息并丢弃skb。
5.5.2 __udp_enqueue_schedule_skb 函数
int __udp_enqueue_schedule_skb(struct sock *sk, struct sk_buff *skb)
{
// 声明并初始化一些变量,包括接收队列(sk_receive_queue)指针、内存分配变量、错误码和自旋锁变量。
struct sk_buff_head *list = &sk->sk_receive_queue;
int rmem, delta, amt, err = -ENOMEM;
spinlock_t *busy = NULL;
int size;
// 检查套接字接收缓冲区(sk_rcvbuf)是否已满,如果满了,则跳转到 drop 标签处。
rmem = atomic_read(&sk->sk_rmem_alloc);
if (rmem > sk->sk_rcvbuf)
goto drop;
// 如果接收缓冲区超过一半已使用
if (rmem > (sk->sk_rcvbuf >> 1)) {
// 对数据包进行压缩,减小内存开销。
skb_condense(skb);
// 获取套接字的繁忙锁。
busy = busylock_acquire(sk);
}
// 获取数据包的真实大小
size = skb->truesize;
// 设置设备 scratch 字段。
udp_set_dev_scratch(skb);
// 将数据包的大小加入套接字的接收缓冲区已分配大小。
rmem = atomic_add_return(size, &sk->sk_rmem_alloc);
// 检查是否超过了接收缓冲区的总大小。
if (rmem > (size + (unsigned int)sk->sk_rcvbuf))
// 如果超过了,则跳转到 uncharge_drop 标签处。
goto uncharge_drop;
// 获取接收队列的自旋锁。
spin_lock(&list->lock);
// 如果数据包的大小大于等于套接字的预先分配大小(sk_forward_alloc)
if (size >= sk->sk_forward_alloc) {
// 计算所需的页数和增量大小。
amt = sk_mem_pages(size);
delta = amt << PAGE_SHIFT;
// 增加套接字的已分配内存大小,用于接收缓冲区。
if (!__sk_mem_raise_allocated(sk, delta, amt, SK_MEM_RECV)) {
err = -ENOBUFS;
spin_unlock(&list->lock);
goto uncharge_drop;
}
// 更新套接字的预先分配大小。
sk->sk_forward_alloc += delta;
}
// 减去数据包的大小,更新套接字的预先分配大小。
sk->sk_forward_alloc -= size;
// 设置数据包的丢弃计数。
sock_skb_set_dropcount(sk, skb);
// 将数据包添加到接收队列的尾部。
__skb_queue_tail(list, skb);
// 释放接收队列的自旋锁。
spin_unlock(&list->lock);
// 如果套接字不是关闭状态。
if (!sock_flag(sk, SOCK_DEAD))
// 通知套接字数据准备就绪。
sk->sk_data_ready(sk);
// 释放繁忙锁。
busylock_release(busy);
// 返回 0 表示处理成功。
return 0;
uncharge_drop:
// 减去数据包的大小,更新套接字的接收缓冲区已分配大小。
atomic_sub(skb->truesize, &sk->sk_rmem_alloc);
drop:
// 增加套接字的丢弃计数。
atomic_inc(&sk->sk_drops);
// 释放繁忙锁。
busylock_release(busy);
// 返回错误码 err 表示处理失败。
return err;
}
其主要逻辑有二:
- 检查套接字接收缓冲区sk_rcvbuf是否已满,如果满了,丢弃这个包并更新计数。
- 如果sk_rcvbuf没满,调用 __skb_queue_tail 函数将skb插到 Socket 的接收队列(sk->sk_receive_queue)。
5.5.3 __skb_queue_tail 函数
static inline void __skb_queue_tail(struct sk_buff_head *list, struct sk_buff *newsk)
{
__skb_queue_before(list, (struct sk_buff *)list, newsk);
}
static inline void __skb_queue_before(struct sk_buff_head *list,
struct sk_buff *next, struct sk_buff *newsk)
{
__skb_insert(newsk, ((struct sk_buff_list *)next)->prev, next, list);
}
/* Insert an sk_buff on a list. */
static inline void __skb_insert(struct sk_buff *newsk, struct sk_buff *prev, struct sk_buff *next, struct sk_buff_head *list)
{
WRITE_ONCE(newsk->next, next);
WRITE_ONCE(newsk->prev, prev);
WRITE_ONCE(((struct sk_buff_list *)next)->prev, newsk);
WRITE_ONCE(((struct sk_buff_list *)prev)->next, newsk);
WRITE_ONCE(list->qlen, list->qlen + 1);
}
__skb_queue_tail 函数将一个skb插到链表的尾部。它使用了 __skb_queue_before 函数来在链表中插入skb。注意,调用此函数前需要持有所需的锁来保证线程安全。同时,一个skb不能同时存在于两个链表中。
5.6 唤醒 Socket 上线程
5.6.1 sk_data_ready 函数
最后,__udp_enqueue_schedule_skb 通过调用 sk_data_ready 函数指针来唤醒在 Socket 上等待的进程和线程。实际上 sk_data_ready 函数指针指向的是 sock_def_readable 函数。Socket 在创建时,会把 sock_def_readable 函数赋值给sk->sk_data_ready函数指针,代码如下:
// 初始化套接字 Socket
void sock_init_data(struct socket *sock, struct sock *sk)
{
...
sk->sk_data_ready = sock_def_readable;
sk->sk_write_space = sock_def_write_space;
sk->sk_error_report = sock_def_error_report;
...
}
void sock_def_readable(struct sock *sk)
{
struct socket_wq *wq;
rcu_read_lock();
// 读取 sk->sk_wq 字段的值,即 struct sock 结构体中的 sk_wq 成员。它是在 RCU 临界区内执行的。
wq = rcu_dereference(sk->sk_wq);
// 检查 wq 所指向的 struct socket_wq 是否有等待唤醒的进程。
if (skwq_has_sleeper(wq))
// 如果有等待唤醒的进程,那么 wake_up_interruptible_sync_poll 函数会触发对等待队列中的进程的唤醒,并传递相应的事件掩码,其中 EPOLLIN、EPOLLPRI、EPOLLRDNORM、EPOLLRDBAND 是用于表示可读事件的标志。
wake_up_interruptible_sync_poll(&wq->wait, EPOLLIN | EPOLLPRI | EPOLLRDNORM | EPOLLRDBAND);
// 异步唤醒与给定套接字关联的进程。SOCK_WAKE_WAITD 是指定唤醒类型的标志,表示等待可读事件。POLL_IN 是传递给唤醒函数的事件掩码,表示可读事件。
sk_wake_async(sk, SOCK_WAKE_WAITD, POLL_IN);
rcu_read_unlock();
}
其主要逻辑有二:
- 读取sk->sk_wq字段的值,即 struct sock 结构体中的成员 struct socket_wq 成员;
- 检查 sk->sk_wq->wait(wait_queue_head_t 包含一个自旋锁和双向链表头)是否有等待唤醒的线程,如果有,调用 wake_up_interruptible_sync_poll 函数继续处理。
回忆下我们前面调用 recvfrom 执行的最后,通过 DEFINE_WAIT(wait) 将当前进程关联的等待队列添加到 sock->sk_wq 下的 wait 里了。
那接下来就是调用 wake_up_interruptible_sync_poll 来唤醒在 socket 上因为等待数据而被阻塞掉的进程了。
5.6.2 wake_up_interruptible_sync_poll 函数
#define wake_up_interruptible_sync_poll(x, m) \
__wake_up_sync_key((x), TASK_INTERRUPTIBLE, poll_to_key(m))
/**
* __wake_up_sync_key - wake up threads blocked on a waitqueue.
* @wq_head: the waitqueue
* @mode: which threads
* @key: opaque value to be passed to wakeup targets
*
* The sync wakeup differs that the waker knows that it will schedule
* away soon, so while the target thread will be woken up, it will not
* be migrated to another CPU - ie. the two threads are 'synchronized'
* with each other. This can prevent needless bouncing between CPUs.
*
* On UP it can prevent extra preemption.
*
* If this function wakes up a task, it executes a full memory barrier before
* accessing the task state.
*/
void __wake_up_sync_key(struct wait_queue_head *wq_head, unsigned int mode, void *key)
{
if (unlikely(!wq_head))
return;
__wake_up_common_lock(wq_head, mode, 1, WF_SYNC, key);
}
EXPORT_SYMBOL_GPL(__wake_up_sync_key);
wake_up_interruptible_sync_poll 是个宏定义,实际调用的是 __wake_up_sync_key 函数,它又调用了 __wake_up_common_lock 函数,传入的参数nr_exclusive是 1,指的是即使有多个线程阻塞在同一个 Socket 上,也只唤醒 1 个线程,目的是避免惊群。
5.6.3 __wake_up_common_lock 函数
static void __wake_up_common_lock(struct wait_queue_head *wq_head, unsigned int mode, int nr_exclusive, int wake_flags, void *key)
{
unsigned long flags;
wait_queue_entry_t bookmark;
bookmark.flags = 0;
bookmark.private = NULL;
bookmark.func = NULL;
INIT_LIST_HEAD(&bookmark.entry);
do {
spin_lock_irqsave(&wq_head->lock, flags);
nr_exclusive = __wake_up_common(wq_head, mode, nr_exclusive, wake_flags, key, &bookmark);
spin_unlock_irqrestore(&wq_head->lock, flags);
} while (bookmark.flags & WQ_FLAG_BOOKMARK);
}
其主要逻辑封装在 __wake_up_common 函数中。
5.6.4 __wake_up_common 函数
/*
* The core wakeup function. Non-exclusive wakeups (nr_exclusive == 0) just
* wake everything up. If it's an exclusive wakeup (nr_exclusive == small +ve
* number) then we wake that number of exclusive tasks, and potentially all
* the non-exclusive tasks. Normally, exclusive tasks will be at the end of
* the list and any non-exclusive tasks will be woken first. A priority task
* may be at the head of the list, and can consume the event without any other
* tasks being woken.
*
* There are circumstances in which we can try to wake a task which has already
* started to run but is not in state TASK_RUNNING. try_to_wake_up() returns
* zero in this (rare) case, and we handle it by continuing to scan the queue.
*/
static int __wake_up_common(struct wait_queue_head *wq_head, unsigned int mode, int nr_exclusive, int wake_flags, void *key, wait_queue_entry_t *bookmark)
{
wait_queue_entry_t *curr, *next;
int cnt = 0;
lockdep_assert_held(&wq_head->lock);
if (bookmark && (bookmark->flags & WQ_FLAG_BOOKMARK)) {
curr = list_next_entry(bookmark, entry);
list_del(&bookmark->entry);
bookmark->flags = 0;
} else
curr = list_first_entry(&wq_head->head, wait_queue_entry_t, entry);
if (&curr->entry == &wq_head->head)
return nr_exclusive;
list_for_each_entry_safe_from(curr, next, &wq_head->head, entry) {
unsigned flags = curr->flags;
int ret;
if (flags & WQ_FLAG_BOOKMARK)
continue;
ret = curr->func(curr, mode, wake_flags, key);
if (ret < 0)
break;
if (ret && (flags & WQ_FLAG_EXCLUSIVE) && !--nr_exclusive)
break;
// WAITQUEUE_WALK_BREAK_CNT(64) 阈值
if (bookmark && (++cnt > WAITQUEUE_WALK_BREAK_CNT) && (&next->entry != &wq_head->head)) {
bookmark->flags = WQ_FLAG_BOOKMARK;
list_add_tail(&bookmark->entry, &next->entry);
break;
}
}
return nr_exclusive;
}
找出一个等待队列条目curr(wait_queue_entry结构体,定义在下面),然后调用其curr->func。在后面讲解调用recv和recvfrom函数执行的时候,使用 DEFINE_WAIT_FUNC 初始化了等待队列条目,然后把curr->func设置成了 receiver_wake_function 函数。
struct wait_queue_entry {
unsigned int flags;
void *private;
wait_queue_func_t func;
struct list_head entry;
};
struct wait_queue_head {
spinlock_t lock;
struct list_head head;
};
5.6.5 receiver_wake_function 函数
static int receiver_wake_function(wait_queue_entry_t *wait, unsigned int mode, int sync, void *key)
{
// Avoid a wakeup if event not interesting for us
if (key && !(key_to_poll(key) & (EPOLLIN | EPOLLERR)))
return 0;
return autoremove_wake_function(wait, mode, sync, key);
}
该函数先是判断是否有EPOLLIN或EPOLLERR事件,如果没有直接返回,如果有继续调用 autoremove_wake_function 函数继续执行。
5.6.6 autoremove_wake_function 函数
int autoremove_wake_function(struct wait_queue_entry *wq_entry, unsigned mode, int sync, void *key)
{
int ret = default_wake_function(wq_entry, mode, sync, key);
if (ret)
list_del_init_careful(&wq_entry->entry);
return ret;
}
int default_wake_function(wait_queue_entry_t *curr, unsigned mode, int wake_flags, void *key)
{
WARN_ON_ONCE(IS_ENABLED(CONFIG_SCHED_DEBUG) && wake_flags & ~WF_SYNC);
return try_to_wake_up(curr->private, mode, wake_flags);
}
其调用 try_to_wake_up 函数传入的task_struct参数是curr->private,这就是当时因为 Socket 接收队列没有数据而被阻塞的线程对象。
/**
* try_to_wake_up - wake up a thread
* @p: the thread to be awakened
* @state: the mask of task states that can be woken
* @wake_flags: wake modifier flags (WF_*)
*/
static int
try_to_wake_up(struct task_struct *p, unsigned int state, int wake_flags)
{
unsigned long flags;
int cpu, success = 0;
preempt_disable();
if (p == current) {
if (!ttwu_state_match(p, state, &success))
goto out;
trace_sched_waking(p);
WRITE_ONCE(p->__state, TASK_RUNNING);
trace_sched_wakeup(p);
goto out;
}
raw_spin_lock_irqsave(&p->pi_lock, flags);
smp_mb__after_spinlock();
if (!ttwu_state_match(p, state, &success))
goto unlock;
trace_sched_waking(p);
smp_rmb();
if (READ_ONCE(p->on_rq) && ttwu_runnable(p, wake_flags))
goto unlock;
#ifdef CONFIG_SMP
smp_acquire__after_ctrl_dep();
WRITE_ONCE(p->__state, TASK_WAKING);
if (smp_load_acquire(&p->on_cpu) &&
ttwu_queue_wakelist(p, task_cpu(p), wake_flags))
goto unlock;
smp_cond_load_acquire(&p->on_cpu, !VAL);
cpu = select_task_rq(p, p->wake_cpu, wake_flags | WF_TTWU);
if (task_cpu(p) != cpu) {
if (p->in_iowait) {
delayacct_blkio_end(p);
atomic_dec(&task_rq(p)->nr_iowait);
}
wake_flags |= WF_MIGRATED;
psi_ttwu_dequeue(p);
set_task_cpu(p, cpu);
}
#else
cpu = task_cpu(p);
#endif /* CONFIG_SMP */
ttwu_queue(p, cpu, wake_flags);
unlock:
raw_spin_unlock_irqrestore(&p->pi_lock, flags);
out:
if (success)
ttwu_stat(p, task_cpu(p), wake_flags);
preempt_enable();
return success;
}
当这个函数执行完的时,在 Socket 上因等待数据而被阻塞的线程会被推入可运行队列里。
从 3.4 到目前为止一直处在软中断中,占用用户的 si 使用率。
六、传输层(TCP)
假如 2.7 中的skb的协议类型是 TCP,那么处理函数handler是 tcp_v4_rcv,skb进入 TCP 层继续处理。TCP 层非常复杂,前面逻辑的总和可能没有 TCP 一层逻辑多。
TODO
七、Socket
7.1 概述
主要有两个逻辑:
- 创建套接字收数据;
- 读取套接字的数据。

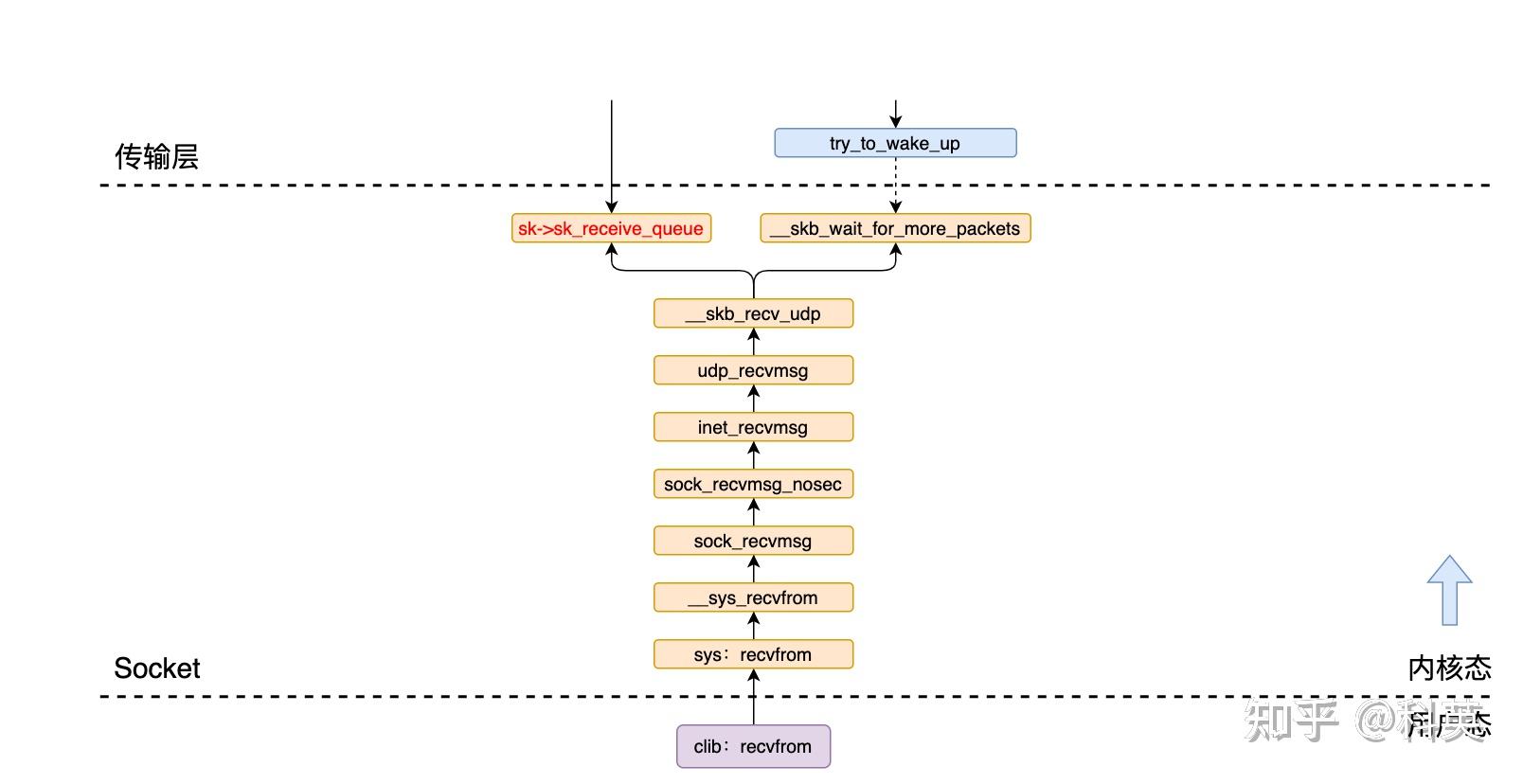
7.2 创建套接字
7.2.1 用户调用 socket 函数创建套接字(用户态)
创建 TCP 套接字
int fd = socket(AF_INET, SOCK_STREAM, 0);
创建 UDP 套接字
int fd = socket(AF_INET, SOCK_DGRAM, 0);
7.2.2 socket 系统调用(内核态)
SYSCALL_DEFINE3(socket, int, family, int, type, int, protocol)
{
return __sys_socket(family, type, protocol);
}
该系统调用的主要逻辑封装在 __sys_socket 函数中。
7.2.3 __sys_socket 函数
int __sys_socket(int family, int type, int protocol)
{
struct socket *sock;
int flags;
// 创建套接字对象
sock = __sys_socket_create(family, type, protocol);
if (IS_ERR(sock))
return PTR_ERR(sock);
// 获取套接字类型中的附加标志
flags = type & ~SOCK_TYPE_MASK;
// 如果套接字类型中包含 SOCK_NONBLOCK 标志且不等于 O_NONBLOCK,则将其转换为 O_NONBLOCK 标志
if (SOCK_NONBLOCK != O_NONBLOCK && (flags & SOCK_NONBLOCK))
flags = (flags & ~SOCK_NONBLOCK) | O_NONBLOCK;
// 将套接字对象映射到文件描述符,并应用标志(O_CLOEXEC 和 O_NONBLOCK)
return sock_map_fd(sock, flags & (O_CLOEXEC | O_NONBLOCK));
}
该函数是用于创建套接字的系统调用的实现,它负责创建套接字对象并将其映射到文件描述符。同时,它还处理套接字类型中的附加标志,如将SOCK_NONBLOCK转换为O_NONBLOCK,以及应用O_CLOEXEC和O_NONBLOCK标志位。最终返回与套接字关联的文件描述符。
7.2.4 __sys_socket_create 函数
static struct socket *__sys_socket_create(int family, int type, int protocol)
{
struct socket *sock;
int retval;
// 检查编译期间 SOCK_CLOEXEC 和 O_CLOEXEC 的值是否相等。如果不相等,会触发一个编译期间的错误。
BUILD_BUG_ON(SOCK_CLOEXEC != O_CLOEXEC);
// 检查编译期间 SOCK_MAX 和 SOCK_TYPE_MASK 的值是否按位或运算后等于 SOCK_TYPE_MASK。如果不等于,会触发一个编译期间的错误。
BUILD_BUG_ON((SOCK_MAX | SOCK_TYPE_MASK) != SOCK_TYPE_MASK);
// 检查编译期间 SOCK_CLOEXEC 和 SOCK_TYPE_MASK 的值进行按位与运算后是否为零。如果不为零,会触发一个编译期间的错误。
BUILD_BUG_ON(SOCK_CLOEXEC & SOCK_TYPE_MASK);
// 检查编译期间 SOCK_NONBLOCK 和 SOCK_TYPE_MASK 的值进行按位与运算后是否为零。如果不为零,会触发一个编译期间的错误。
BUILD_BUG_ON(SOCK_NONBLOCK & SOCK_TYPE_MASK);
// 检查套接字类型和标志是否有效。如果套接字类型和标志中有无效的位,则返回错误指针 -EINVAL。
if ((type & ~SOCK_TYPE_MASK) & ~(SOCK_CLOEXEC | SOCK_NONBLOCK))
return ERR_PTR(-EINVAL);
// 将套接字类型中的附加标志位清除,只保留套接字类型部分。
type &= SOCK_TYPE_MASK;
// 调用 sock_create 函数创建一个套接字对象,并将其保存在 sock 变量中。
retval = sock_create(family, type, protocol, &sock);
if (retval < 0)
return ERR_PTR(retval);
return sock;
}
该函数用于创建一个套接字对象。它先进行一些编译期间的一致性检查,然后根据传入的套接字类型和标志参数,调用 sock_create 函数创建套接字对象,并返回该对象的指针。
7.2.5 sock_create 函数
/**
* sock_create - creates a socket
* @family: protocol family (AF_INET, ...)
* @type: communication type (SOCK_STREAM, ...)
* @protocol: protocol (0, ...)
* @res: new socket
*/
int sock_create(int family, int type, int protocol, struct socket **res)
{
return __sock_create(current->nsproxy->net_ns, family, type, protocol, res, 0);
}
EXPORT_SYMBOL(sock_create);
该函数是用于创建套接字的包装函数。它将传递的参数传递给内部的 __sock_create 函数,并返回该函数的结果。通过导出 __sock_create 函数的符号,其他模块可以使用它来创建套接字。
7.2.6 __sock_create 函数
/**
* __sock_create - creates a socket 创建套接字
* @net: net namespace 网络命名空间
* @family: protocol family (AF_INET, ...) 协议族
* @type: communication type (SOCK_STREAM, ...) 通信类型
* @protocol: protocol (0, ...) 协议
* @res: new socket 新套接字
* @kern: boolean for kernel space sockets 内核空间套接字标志
*
* 创建一个新的套接字并将其分配给 @res,经过 LSM(Linux Security Modules)处理。
* 返回 0 或错误码。失败时,@res 被设置为 %NULL。如果套接字位于内核空间,则必须将 @kern 设置为 true。
* 此函数在内部使用 GFP_KERNEL 进行内存分配。
*/
int __sock_create(struct net *net, int family, int type, int protocol, struct socket **res, int kern)
{
int err;
struct socket *sock;
const struct net_proto_family *pf;
// 检查协议族和通信类型的范围
if (family < 0 || family >= NPROTO)
return -EAFNOSUPPORT;
// 检查通信类型是否在合法范围内
if (type < 0 || type >= SOCK_MAX)
return -EINVAL;
// 兼容性处理,当协议族为 PF_INET 且通信类型为 SOCK_PACKET 时。
if (family == PF_INET && type == SOCK_PACKET) {
// 将协议族更改为 PF_PACKET,并发出一条警告信息。
pr_info_once("%s uses obsolete (PF_INET,SOCK_PACKET)\n", current->comm);
family = PF_PACKET;
}
// 调用 LSM(Linux Security Modules)处理套接字创建的安全检查,确保权限和安全策略的一致性。
err = security_socket_create(family, type, protocol, kern);
if (err)
return err;
// 分配套接字对象。
sock = sock_alloc();
if (!sock) {
net_warn_ratelimited("socket: no more sockets\n");
// Not exactly a match, but its the closest posix thing
return -ENFILE;
}
// 设置套接字对象的通信类型。
sock->type = type;
#ifdef CONFIG_MODULES
// 如果配置支持协议族模块,并且协议族模块尚未加载,尝试加载相关模块。
if (rcu_access_pointer(net_families[family]) == NULL)
request_module("net-pf-%d", family);
#endif
// 通过 RCU 读锁访问协议族,并获取相关的协议族结构。
rcu_read_lock();
pf = rcu_dereference(net_families[family]);
err = -EAFNOSUPPORT;
if (!pf)
// 如果获取协议族结构失败,则转到 out_release 进行释放资源。
goto out_release;
// 如果成功获取协议族结构,尝试增加该协议族模块的引用计数。
if (!try_module_get(pf->owner))
goto out_release;
/* Now protected by module ref count */
rcu_read_unlock();
// 调用协议族的 create 函数,创建套接字对象。
err = pf->create(net, sock, protocol, kern);
if (err < 0)
// 如果协议族的 create 函数调用失败,则转到 out_module_put 进行模块引用计数的释放。
goto out_module_put;
// 如果成功创建套接字对象,尝试增加套接字操作函数的模块引用计数。
if (!try_module_get(sock->ops->owner))
goto out_module_busy;
// 释放协议族模块的引用计数。
module_put(pf->owner);
// 调用 LSM 处理套接字创建后的安全检查。
err = security_socket_post_create(sock, family, type, protocol, kern);
if (err)
goto out_sock_release;
// 将创建的套接字对象赋值给 res,并返回 0 表示成功创建套接字。
*res = sock;
return 0;
out_module_busy:
// 如果在模块引用计数增加时失败,则转到 out_module_busy 进行错误处理。
err = -EAFNOSUPPORT;
out_module_put:
// 如果在模块引用计数增加后的套接字操作函数的引用计数增加时失败,则转到 out_module_put 进行模块引用计数的释放。
// 将套接字对象的操作函数设置为 NULL。
sock->ops = NULL;
// 释放协议族模块的引用计数。
module_put(pf->owner);
out_sock_release:
// 释放套接字对象资源。
sock_release(sock);
// 返回错误码。
return err;
out_release:
rcu_read_unlock();
goto out_sock_release;
}
EXPORT_SYMBOL(__sock_create);
该函数用于创建一个套接字对象,其主要逻辑有三:
- 它首先进行一些参数的合法性检查,然后调用 LSM 处理套接字创建的安全检查;
- 接着,它分配套接字对象,并通过调用协议族的
create函数进行协议族特定的套接字对象的创建,对于AF_INET协议族来说,create函数指针指向 inet_create 函数; - 最后,它进行一些模块引用计数的管理,并进行安全检查后返回创建的套接字对象。
7.2.7 inet_create 函数
static int inet_create(struct net *net, struct socket *sock, int protocol, int kern)
{
struct sock *sk;
struct inet_protosw *answer;
struct inet_sock *inet;
struct proto *answer_prot;
unsigned char answer_flags;
int try_loading_module = 0;
int err;
// 检查协议值是否在合法范围内。
if (protocol < 0 || protocol >= IPPROTO_MAX)
return -EINVAL;
// 将套接字的状态设置为未连接状态。
sock->state = SS_UNCONNECTED;
lookup_protocol:
err = -ESOCKTNOSUPPORT;
rcu_read_lock();
// 在协议族列表中查找请求的套接字类型和协议对。
list_for_each_entry_rcu(answer, &inetsw[sock->type], list) {
err = 0;
/* Check the non-wild match. */
if (protocol == answer->protocol) {
if (protocol != IPPROTO_IP)
break;
} else {
/* Check for the two wild cases. */
if (IPPROTO_IP == protocol) {
protocol = answer->protocol;
break;
}
if (IPPROTO_IP == answer->protocol)
break;
}
err = -EPROTONOSUPPORT;
}
// 如果找不到匹配的协议,则尝试加载相关的协议模块,并重新查找。
if (unlikely(err)) {
if (try_loading_module < 2) {
rcu_read_unlock();
if (++try_loading_module == 1)
request_module("net-pf-%d-proto-%d-type-%d", PF_INET, protocol, sock->type);
else
request_module("net-pf-%d-proto-%d", PF_INET, protocol);
goto lookup_protocol;
} else
goto out_rcu_unlock;
}
err = -EPERM;
// 检查是否有足够的权限创建 SOCK_RAW 类型的套接字
if (sock->type == SOCK_RAW && !kern &&
!ns_capable(net->user_ns, CAP_NET_RAW))
goto out_rcu_unlock;
// 设置套接字的操作函数和协议
sock->ops = answer->ops;
answer_prot = answer->prot;
answer_flags = answer->flags;
rcu_read_unlock();
WARN_ON(!answer_prot->slab);
// 分配套接字对象
err = -ENOMEM;
sk = sk_alloc(net, PF_INET, GFP_KERNEL, answer_prot, kern);
if (!sk)
goto out;
err = 0;
// 根据协议特性设置套接字的属性
if (INET_PROTOSW_REUSE & answer_flags)
sk->sk_reuse = SK_CAN_REUSE;
inet = inet_sk(sk);
inet->is_icsk = (INET_PROTOSW_ICSK & answer_flags) != 0;
inet->nodefrag = 0;
if (SOCK_RAW == sock->type) {
inet->inet_num = protocol;
if (IPPROTO_RAW == protocol)
inet->hdrincl = 1;
}
// 设置套接字的路径 MTU 发现属性
if (READ_ONCE(net->ipv4.sysctl_ip_no_pmtu_disc))
inet->pmtudisc = IP_PMTUDISC_DONT;
else
inet->pmtudisc = IP_PMTUDISC_WANT;
inet->inet_id = 0;
// 初始化套接字和套接字对象
sock_init_data(sock, sk);
sk->sk_destruct = inet_sock_destruct;
sk->sk_protocol = protocol;
sk->sk_backlog_rcv = sk->sk_prot->backlog_rcv;
// 设置套接字的 TTL 和多播相关属性
inet->uc_ttl = -1;
inet->mc_loop = 1;
inet->mc_ttl = 1;
inet->mc_all = 1;
inet->mc_index = 0;
inet->mc_list = NULL;
inet->rcv_tos = 0;
// 增加套接字对象的引用计数。
sk_refcnt_debug_inc(sk);
// 如果协议允许在套接字创建时为其分配一个数字。
if (inet->inet_num) {
// 将该数字作为套接字的端口号。
inet->inet_sport = htons(inet->inet_num);
// 并将套接字添加到协议的哈希链中。
err = sk->sk_prot->hash(sk);
if (err) {
sk_common_release(sk);
goto out;
}
}
// 如果协议有初始化函数,则调用该函数进行初始化。
if (sk->sk_prot->init) {
err = sk->sk_prot->init(sk);
if (err) {
sk_common_release(sk);
goto out;
}
}
// 如果不是内核空间套接字,则在用户空间执行 BPF 程序进行套接字的过滤和控制。
if (!kern) {
err = BPF_CGROUP_RUN_PROG_INET_SOCK(sk);
if (err) {
sk_common_release(sk);
goto out;
}
}
out:
// 返回错误码或成功创建套接字。
return err;
out_rcu_unlock:
// 如果发生错误,在释放 RCU 读锁之前先释放资源。
rcu_read_unlock();
goto out;
}
该函数用于在给定的网络命名空间中创建一个 IPv4 套接字。它在协议族列表中查找匹配的套接字类型和协议对,并根据协议的特性和要求进行套接字对象的设置和初始化。负责初始化的函数是 sock_init_data。
这里想解释下 inet_create 函数中下面的代码,还记得前面协议栈初始化时对 inetsw 链表数组的初始化吗?这里的ops和prot根据协议类型的不同对应的值有所不同,比如是 TCP 协议对应的 inet_stream_ops 和 tcp_prot 或者是 UDP 协议对应的 inet_dgram_ops 和 udp_prot,再或者是其他协议的。
// 设置套接字的操作函数和协议
sock->ops = answer->ops;
answer_prot = answer->prot;
7.2.8 sock_init_data 函数
void sock_init_data(struct socket *sock, struct sock *sk)
{
sk_init_common(sk);
sk->sk_send_head = NULL;
timer_setup(&sk->sk_timer, NULL, 0);
sk->sk_allocation = GFP_KERNEL;
sk->sk_rcvbuf = READ_ONCE(sysctl_rmem_default);
sk->sk_sndbuf = READ_ONCE(sysctl_wmem_default);
sk->sk_state = TCP_CLOSE;
sk_set_socket(sk, sock);
sock_set_flag(sk, SOCK_ZAPPED);
if (sock) {
sk->sk_type = sock->type;
RCU_INIT_POINTER(sk->sk_wq, &sock->wq);
sock->sk = sk;
sk->sk_uid = SOCK_INODE(sock)->i_uid;
} else {
RCU_INIT_POINTER(sk->sk_wq, NULL);
sk->sk_uid = make_kuid(sock_net(sk)->user_ns, 0);
}
rwlock_init(&sk->sk_callback_lock);
if (sk->sk_kern_sock)
lockdep_set_class_and_name(
&sk->sk_callback_lock,
af_kern_callback_keys + sk->sk_family,
af_family_kern_clock_key_strings[sk->sk_family]);
else
lockdep_set_class_and_name(
&sk->sk_callback_lock,
af_callback_keys + sk->sk_family,
af_family_clock_key_strings[sk->sk_family]);
sk->sk_state_change = sock_def_wakeup;
sk->sk_data_ready = sock_def_readable;
sk->sk_write_space = sock_def_write_space;
sk->sk_error_report = sock_def_error_report;
sk->sk_destruct = sock_def_destruct;
sk->sk_frag.page = NULL;
sk->sk_frag.offset = 0;
sk->sk_peek_off = -1;
sk->sk_peer_pid = NULL;
sk->sk_peer_cred = NULL;
spin_lock_init(&sk->sk_peer_lock);
sk->sk_write_pending= 0;
sk->sk_rcvlowat = 1;
sk->sk_rcvtimeo = MAX_SCHEDULE_TIMEOUT;
sk->sk_sndtimeo = MAX_SCHEDULE_TIMEOUT;
sk->sk_stamp = SK_DEFAULT_STAMP;
#if BITS_PER_LONG==32
seqlock_init(&sk->sk_stamp_seq);
#endif
atomic_set(&sk->sk_zckey, 0);
#ifdef CONFIG_NET_RX_BUSY_POLL
sk->sk_napi_id = 0;
sk->sk_ll_usec = READ_ONCE(sysctl_net_busy_read);
#endif
sk->sk_max_pacing_rate = ~0UL;
sk->sk_pacing_rate = ~0UL;
WRITE_ONCE(sk->sk_pacing_shift, 10);
sk->sk_incoming_cpu = -1;
sk->sk_txrehash = SOCK_TXREHASH_DEFAULT;
sk_rx_queue_clear(sk);
/*
* Before updating sk_refcnt, we must commit prior changes to memory
* (Documentation/RCU/rculist_nulls.rst for details)
*/
smp_wmb();
refcount_set(&sk->sk_refcnt, 1);
atomic_set(&sk->sk_drops, 0);
}
EXPORT_SYMBOL(sock_init_data);
其主要逻辑就是完成套接字的各种属性初始化。
7.3 读取套接字
7.3.1 用户调用 recv 函数接收数据(用户态)
当应用程序调用clib的recv或recvfrom函数接收数据时,通过strace命令可以跟踪到分别执行了recv和recvfrom系统调用。
// recv
unsigned char buff[1024] = {0};
int count = recv(socket_fd, buff, 1024, 0);
// recvfrom
struct sockaddr_in recvAddr;
socklen_t in_len = sizeof(struct sockaddr_in);
ssize_t count = recvfrom(sfd, buff, 1024, MSG_DONTWAIT, (struct sockaddr *)&recvAddr, &in_len);
recv和recvfrom的主要区别是,recvfrom比recv多了地址参数,用来获取数据包来自的 <IP:PORT>。这两个函数 TCP 和 UDP 的套接字都可以使用,只不过是recv更适合 TCP,因为 TCP 在建立连接后就已经知道了对端 <IP:PORT>,所以就不用每次都获取没有意义并且也浪费开销;而 UDP 没有连接概念,除非它不关心来自的 <IP:PORT>,也不给对端回数据,那也可以使用recv,否则必须使用recvfrom来获取对端 <IP:PORT>。
7.3.2 recvfrom 系统调用(内核态)
SYSCALL_DEFINE4(recv, int, fd, void __user *, ubuf, size_t, size, unsigned int, flags)
{
return __sys_recvfrom(fd, ubuf, size, flags, NULL, NULL);
}
SYSCALL_DEFINE6(recvfrom, int, fd, void __user *, ubuf, size_t, size, unsigned int, flags, struct sockaddr __user *, addr, int __user *, addr_len)
{
return __sys_recvfrom(fd, ubuf, size, flags, addr, addr_len);
}
recv和recvfrom系统调用的主要逻辑都封装在 __sys_recvfrom 函数中。
7.3.3 __sys_recvfrom 函数
/*
* Receive a frame from the socket and optionally record the address of the
* sender. We verify the buffers are writable and if needed move the
* sender address from kernel to user space.
*/
int __sys_recvfrom(int fd, void __user *ubuf, size_t size, unsigned int flags, struct sockaddr __user *addr, int __user *addr_len)
{
struct sockaddr_storage address;
struct msghdr msg = {
/* Save some cycles and don't copy the address if not needed */
.msg_name = addr ? (struct sockaddr *)&address : NULL,
};
struct socket *sock;
struct iovec iov;
int err, err2;
int fput_needed;
err = import_single_range(READ, ubuf, size, &iov, &msg.msg_iter);
if (unlikely(err))
return err;
// 根据用户传入的 fd 找到 Socket 对象
sock = sockfd_lookup_light(fd, &err, &fput_needed);
if (!sock)
goto out;
// 如果 Socket 对象为非阻塞,设置 flags 为 MSG_DONTWAIT
if (sock->file->f_flags & O_NONBLOCK)
flags |= MSG_DONTWAIT;
err = sock_recvmsg(sock, &msg, flags);
if (err >= 0 && addr != NULL) {
err2 = move_addr_to_user(&address, msg.msg_namelen, addr, addr_len);
if (err2 < 0)
err = err2;
}
fput_light(sock->file, fput_needed);
out:
return err;
}
其主要逻辑有五:
- 根据传入的
addr是否为空判断是否需要从内核获取对端地址; - 根据用户传入的
fd找到 Socket 对象; - 如果 Socket 对象在创建时设置为非阻塞,那么设置
flags为MSG_DONTWAIT,这里要注意,假设 Socket 是阻塞的,也可以通过调用recv时传入flags为MSG_DONTWAIT来设置本次接收数据操作为非阻塞的; - 最后调用 sock_recvmsg 函数具体获取数据;
- 如果获取数据成功后,如果第一步中是需要对端地址的,那么将内核获取的对端地址传递给用户。
7.3.4 sock_recvmsg 函数
/**
* sock_recvmsg - receive a message from @sock
* @sock: socket
* @msg: message to receive
* @flags: message flags
*
* Receives @msg from @sock, passing through LSM. Returns the total number
* of bytes received, or an error.
*/
int sock_recvmsg(struct socket *sock, struct msghdr *msg, int flags)
{
int err = security_socket_recvmsg(sock, msg, msg_data_left(msg), flags);
return err ?: sock_recvmsg_nosec(sock, msg, flags);
}
EXPORT_SYMBOL(sock_recvmsg);
其主要逻辑封装在 sock_recvmsg_nosec 函数中。
7.3.5 sock_recvmsg_nosec 函数
static inline int sock_recvmsg_nosec(struct socket *sock, struct msghdr *msg, int flags)
{
return INDIRECT_CALL_INET(sock->ops->recvmsg, inet6_recvmsg, inet_recvmsg,
sock, msg, msg_data_left(msg), flags);
}
看到类似INDIRECT_CALL_INET这种宏定义,并且后面跟着两个函数,就知道要么执行 inet6_recvmsg,要么执行 inet_recvmsg。咱们这里只讨论 IPv4,那就会调用 inet_recvmsg 函数。在调用 inet_create 函数创建套接字时sock->ops->recvmsg函数指针指向了 inet_recvmsg 函数,TCP 和 UDP 协议对应的都是它。
7.3.6 inet_recvmsg 函数
int inet_recvmsg(struct socket *sock, struct msghdr *msg, size_t size, int flags)
{
struct sock *sk = sock->sk;
int addr_len = 0;
int err;
if (likely(!(flags & MSG_ERRQUEUE)))
sock_rps_record_flow(sk);
err = INDIRECT_CALL_2(sk->sk_prot->recvmsg, tcp_recvmsg, udp_recvmsg, sk,
msg, size, flags, &addr_len);
if (err >= 0)
msg->msg_namelen = addr_len;
return err;
}
在这个函数中根据不同协议调用各自的recvmsg函数接收数据,比如 TCP 的是 tcp_recvmsg,而 UDP 的是 udp_recvmsg。 UDP 相比 TCP 简单多了,先来简单的。
7.3.7 udp_recvmsg 函数
//部分代码
int udp_recvmsg(struct sock *sk, struct msghdr *msg, size_t len,
int flags, int *addr_len)
{
struct inet_sock *inet = inet_sk(sk);
DECLARE_SOCKADDR(struct sockaddr_in *, sin, msg->msg_name);
struct sk_buff *skb;
unsigned int ulen, copied;
int off, err, peeking = flags & MSG_PEEK;
int is_udplite = IS_UDPLITE(sk);
bool checksum_valid = false;
// 检查是否需要处理错误队列(MSG_ERRQUEUE),如果是,则调用ip_recv_error函数进行错误处理,并返回结果。
if (flags & MSG_ERRQUEUE)
return ip_recv_error(sk, msg, len, addr_len);
try_again:
// 准备接收数据的偏移量,然后调用__skb_recv_udp函数接收UDP消息的sk_buff结构体。
off = sk_peek_offset(sk, flags);
skb = __skb_recv_udp(sk, flags, &off, &err);
if (!skb)
return err;
// 检查接收到的 UDP 消息的长度,根据需要对接收缓冲区长度进行调整,并在需要截断数据时设置相应的消息标志。
ulen = udp_skb_len(skb);
copied = len;
if (copied > ulen - off)
copied = ulen - off;
else if (copied < ulen)
msg->msg_flags |= MSG_TRUNC;
// 根据数据的长度和类型,确定是否需要进行校验和验证。
if (copied < ulen || peeking || (is_udplite && UDP_SKB_CB(skb)->partial_cov)) {
checksum_valid = udp_skb_csum_unnecessary(skb) || !__udp_lib_checksum_complete(skb);
if (!checksum_valid)
goto csum_copy_err;
}
// 根据校验和验证的结果,选择不同的数据拷贝方式。
if (checksum_valid || udp_skb_csum_unnecessary(skb)) {
if (udp_skb_is_linear(skb))
// 如果数据包是线性的(没有分片),则调用copy_linear_skb函数进行数据拷贝。
err = copy_linear_skb(skb, copied, off, &msg->msg_iter);
else
// 否则,调用skb_copy_datagram_msg函数复制数据到用户提供的缓冲区中。
err = skb_copy_datagram_msg(skb, off, msg, copied);
} else {
// 如果校验和无效,则调用skb_copy_and_csum_datagram_msg函数复制数据到用户提供的缓冲区中,并进行校验和计算。
err = skb_copy_and_csum_datagram_msg(skb, off, msg);
if (err == -EINVAL)
// 处理拷贝数据时可能发生的错误。
goto csum_copy_err;
}
// 更新统计信息。
if (unlikely(err)) {
if (!peeking) {
atomic_inc(&sk->sk_drops);
UDP_INC_STATS(sock_net(sk), UDP_MIB_INERRORS, is_udplite);
}
kfree_skb(skb);
return err;
}
if (!peeking)
UDP_INC_STATS(sock_net(sk), UDP_MIB_INDATAGRAMS, is_udplite);
// 处理相关的控制消息(Control Message)。
sock_recv_cmsgs(msg, sk, skb);
// 复制源地址信息到 msg 结构体中。
if (sin) {
sin->sin_family = AF_INET;
sin->sin_port = udp_hdr(skb)->source;
sin->sin_addr.s_addr = ip_hdr(skb)->saddr;
memset(sin->sin_zero, 0, sizeof(sin->sin_zero));
*addr_len = sizeof(*sin);
BPF_CGROUP_RUN_PROG_UDP4_RECVMSG_LOCK(sk, (struct sockaddr *)sin);
}
// 如果启用了GRO(Generic Receive Offload),处理相关的控制消息。
if (udp_sk(sk)->gro_enabled)
udp_cmsg_recv(msg, sk, skb);
// 如果存在其他控制标志,处理相应的控制消息。
if (inet->cmsg_flags)
ip_cmsg_recv_offset(msg, sk, skb, sizeof(struct udphdr), off);
err = copied;
if (flags & MSG_TRUNC)
err = ulen;
// 返回已复制的字节数。
skb_consume_udp(sk, skb, peeking ? -err : err);
return err;
csum_copy_err: // 处理校验和错误时的逻辑。
if (!__sk_queue_drop_skb(sk, &udp_sk(sk)->reader_queue, skb, flags, udp_skb_destructor)) {
UDP_INC_STATS(sock_net(sk), UDP_MIB_CSUMERRORS, is_udplite);
UDP_INC_STATS(sock_net(sk), UDP_MIB_INERRORS, is_udplite);
}
// 释放sk_buff并重新开始处理新的数据包。
kfree_skb(skb);
/* starting over for a new packet, but check if we need to yield */
cond_resched();
msg->msg_flags &= ~MSG_TRUNC;
goto try_again;
}
其主要逻辑有四:
- 调用 __skb_recv_udp 函数接收 UDP 数据包保存到
sk_buff结构体指针; - 复制
skb中的数据到用户提供的缓冲区中struct msghdr *msg,并进行校验和计算;这是第三次复制,从接收接收队列到用户缓冲区; - 复制
skb中源地址信息到 msg 结构体中; - 更新统计信息,然后返回已复制的字节数。
7.3.8 __skb_recv_udp 函数
struct sk_buff *__skb_recv_udp(struct sock *sk, unsigned int flags, int *off, int *err)
{
// 指向套接字「接收队列」的指针
struct sk_buff_head *sk_queue = &sk->sk_receive_queue;
// 指向「读取队列」的指针
struct sk_buff_head *queue;
// 指向最后一个数据包的指针
struct sk_buff *last;
// 超时时间
long timeo;
// 错误码
int error;
// queue 指向 UDP 套接字的「读取队列」reader_queue。
queue = &udp_sk(sk)->reader_queue;
// 判断 flags 是否设置了 MSG_DONTWAIT 标志位,并计算接收超时时间。
timeo = sock_rcvtimeo(sk, flags & MSG_DONTWAIT);
// 下面循环用于接收数据包并处理「接收队列」中的数据。
do {
// skb 指向接收到的数据包
struct sk_buff *skb;
// 读取套接字当前的错误码
error = sock_error(sk);
if (error)
// 如果有错误,跳出循环,直接返回调用层。
break;
// 设置错误码为 -EAGAIN(表示暂无数据可接收)
error = -EAGAIN;
do {
// 加自旋锁,保护套接字的「读取队列」
spin_lock_bh(&queue->lock);
// 尝试从「读取队列」获取一个数据包
skb = __skb_try_recv_from_queue(sk, queue, flags, off, err, &last);
// 如果成功获取到数据包
if (skb) {
// 如果 flags 没有设置 MSG_PEEK 标志,则销毁数据包
if (!(flags & MSG_PEEK))
udp_skb_destructor(sk, skb);
// 解锁「读取队列」
spin_unlock_bh(&queue->lock);
// 返回接收到的数据包
return skb;
}
// 如果套接字的「接收队列」为空,解锁「读取队列」,并跳到 busy_check 标签处,进行忙等待
if (skb_queue_empty_lockless(sk_queue)) {
spin_unlock_bh(&queue->lock);
goto busy_check;
}
// 加自旋锁,保护套接字的「接收队列」
spin_lock(&sk_queue->lock);
// 将「接收队列」中所有数据包添加到「读取队列」中,初始化「接收队列」为空的双向链表
skb_queue_splice_tail_init(sk_queue, queue);
// 尝试从「读取队列」获取一个数据包
skb = __skb_try_recv_from_queue(sk, queue, flags, off, err, &last);
// 如果成功获取到数据包,并且 flags 没有设置 MSG_PEEK 标志,则销毁数据包
if (skb && !(flags & MSG_PEEK))
udp_skb_dtor_locked(sk, skb);
// 解锁套接字的「接收队列」
spin_unlock(&sk_queue->lock);
// 解锁套接字的「读取队列」
spin_unlock_bh(&queue->lock);
// 如果成功获取到数据包,返回接收到的数据包
if (skb)
return skb;
// 忙等待的标签,用于等待「接收队列」中有可读的数据包
busy_check:
// 如果套接字不支持忙等待,则跳出循环
if (!sk_can_busy_loop(sk))
break;
// 进行忙循环等待数据到达,根据 MSG_DONTWAIT 决定是否阻塞等待,翻看很多资料,阻塞的话超时时间为 50 微秒;不阻塞的话调用一次就返回。
sk_busy_loop(sk, flags & MSG_DONTWAIT);
// 如果「接收队列」不为空,则继续循环。
} while (!skb_queue_empty_lockless(sk_queue));
// sk_queue is empty, reader_queue may contain peeked packets.
// 判断是否超时且调用 __skb_wait_for_more_packets 函数阻塞等待更多的数据包到达。
} while (timeo && !__skb_wait_for_more_packets(sk, &sk->sk_receive_queue, &error, &timeo, (struct sk_buff *)sk_queue));
*err = error;
return NULL;
}
其主要逻辑是接收 UDP 数据包并将其存储在 sk_buff 结构体中,具体流程如下:
- 首先判断
flags是否设置了MSG_DONTWAIT标志位,并计算接收超时时间; - 如果
flags设置了MSG_DONTWAIT,那么timeo值为 0; - 如果
flags没有设置MSG_DONTWAIT,那么timeo值为7 * HZ(后面会介绍)。 - 接着,尝试从 UDP 套接字的
读取队列获取一个已接收到的数据包。如果成功获取到数据包,则根据flags是否包含MSG_PEEK标志来决定保留数据包在队列中还是从队列中删除数据包,然后,解锁读取队列,返回指向读取到的数据包的sk_buff结构体指针,进而整个函数退出,反之继续往下走; - 如果
读取队列为空,说明目前没有数据包,然后判断是否进入忙碌循环等待; - 如果不进入,则跳出内层循环,然后判断是否超时,
timeo > 0进入sleep,直到超时进行下一次外层循环; - 如果进入,根据 MSG_DONTWAIT 决定是否阻塞等待,翻看很多资料,阻塞的话超时时间为 50 微秒;不阻塞的话调用一次就返回,然后如果
接收队列还是空的退出内循环,进入外循环;如果接收队列不为空,进入下一次内循环,获取数据包。 - 如果
读取队列不为空,将接收队列中所有数据包添加到读取队列中,初始化接收队列为空的双向链表; - 然后再尝试从 UDP 套接字的
读取队列获取一个已接收到的数据包。如果成功获取到数据包,则根据flags是否包含MSG_PEEK标志来决定是否保留数据包在队列中或者从队列中删除数据包。
到此完成了从 Socket 的接收队列(sk->sk_receive_queue)中获取数据skb,然后经过后续处理变成应用层使用的buff(unsigned char *)。
下面是几点扩展和补充:
timeo超时时间
# define HZ 1024 // ia64 架构
socket->sk->sk_rcvtimeo = 7 * HZ;
socket->sk->sk_sndtimeo = 5 * HZ;
MSG_PEEK标志
设置MSG_PEEK标志会将套接字接收队列中的可读数据拷贝到缓冲区,但并不会从接收队列中删除数据。这样,可以查看接收到的数据,然后可以选择在后续的接收操作中再次读取相同的数据。例如,在某些情况下,你可能需要查看接收缓冲区中的数据,以确定下一步的操作,而不希望将数据从缓冲区中移除。
skb_queue_splice_tail_init 函数用于将双向链表list连接到双向链表head上,形成一个新的双向链表head,并将原来list变成空的双向链表。下面是代码和对应的示例图。
static inline void skb_queue_splice_tail_init(struct sk_buff_head *list, struct sk_buff_head *head)
{
if (!skb_queue_empty(list)) {
__skb_queue_splice(list, head->prev, (struct sk_buff *) head);
head->qlen += list->qlen;
__skb_queue_head_init(list);
}
}
static inline void __skb_queue_splice(const struct sk_buff_head *list, struct sk_buff *prev, struct sk_buff *next)
{
struct sk_buff *first = list->next;
struct sk_buff *last = list->prev;
WRITE_ONCE(first->prev, prev); // first->prev = prev
WRITE_ONCE(prev->next, first);
WRITE_ONCE(last->next, next);
WRITE_ONCE(next->prev, last);
}
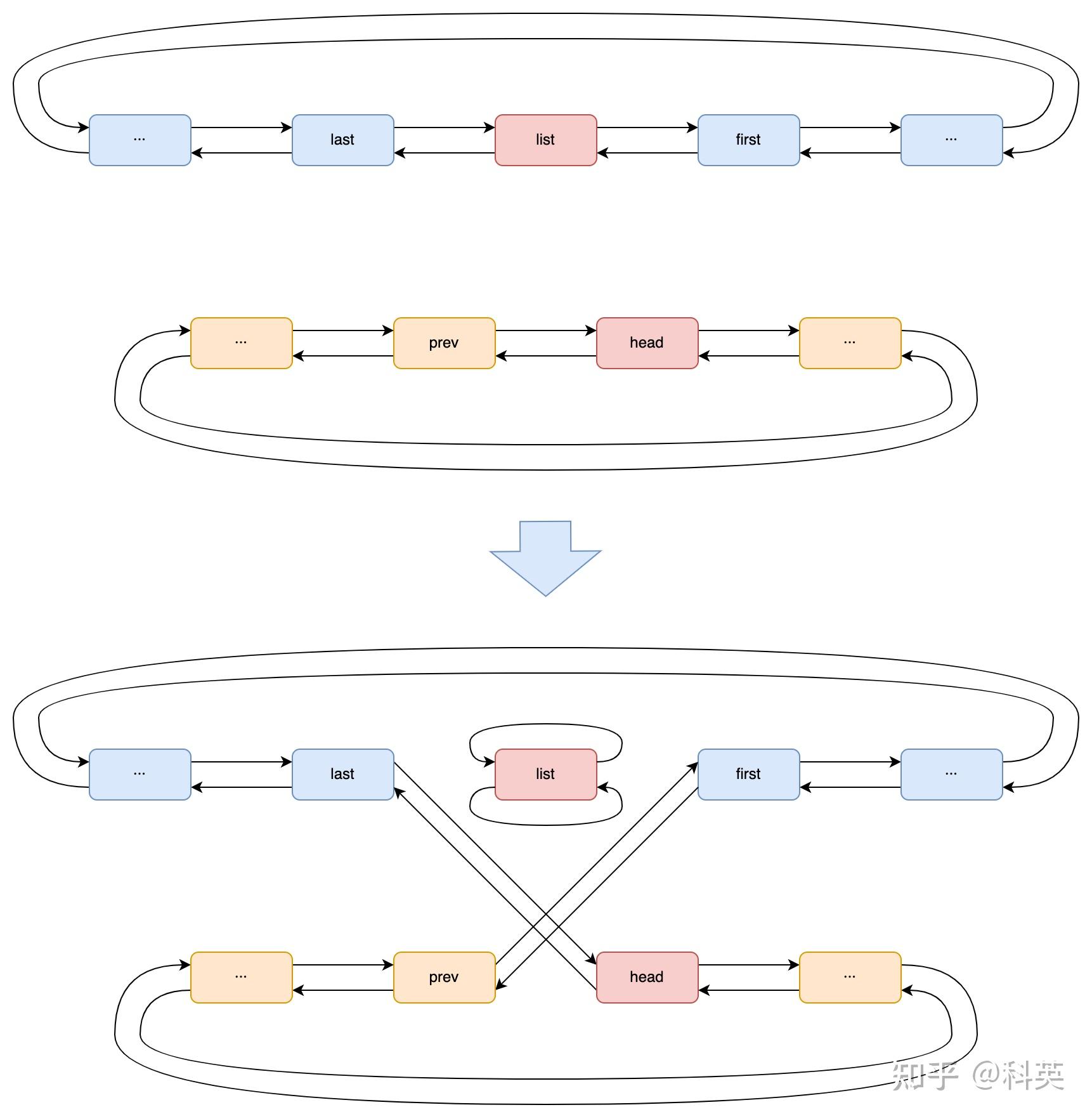
7.3.9 __skb_wait_for_more_packets 函数
int __skb_wait_for_more_packets(struct sock *sk, struct sk_buff_head *queue, int *err, long *timeo_p, const struct sk_buff *skb)
{
int error;
// 初始化「等待队列条目」wait,func = receiver_wake_function
DEFINE_WAIT_FUNC(wait, receiver_wake_function);
// sk_sleep(sk) = sk->sk_wq->wait
// 把「等待队列条目」wait 加入到 Socket 的等待队列(sk->sk_wq->wait)
prepare_to_wait_exclusive(sk_sleep(sk), &wait, TASK_INTERRUPTIBLE);
/* Socket errors? */
error = sock_error(sk);
if (error)
goto out_err;
if (READ_ONCE(queue->prev) != skb)
goto out;
/* Socket shut down? */
if (sk->sk_shutdown & RCV_SHUTDOWN)
goto out_noerr;
/* Sequenced packets can come disconnected.
* If so we report the problem
*/
error = -ENOTCONN;
if (connection_based(sk) && !(sk->sk_state == TCP_ESTABLISHED || sk->sk_state == TCP_LISTEN))
goto out_err;
/* handle signals */
if (signal_pending(current))
goto interrupted;
error = 0;
*timeo_p = schedule_timeout(*timeo_p);
out:
finish_wait(sk_sleep(sk), &wait);
return error;
interrupted:
error = sock_intr_errno(*timeo_p);
out_err:
*err = error;
goto out;
out_noerr:
*err = 0;
error = 1;
goto out;
}
__skb_recv_udp 函数中调用 __skb_wait_for_more_packets 函数阻塞等待更多的数据包到达。
其主要逻辑有三:
- 使用 DEFINE_WAIT_FUNC 宏定义
等待队列条目(wait_queue_entry),并完初始化,func= receiver_wake_function; - 调用 prepare_to_wait_exclusive 函数把
等待队列条目wait加入到 Socket 的等待队列sk->sk_wq->wait; - 最后调用 schedule_timeout 函数进入
timer等待超时或被唤醒,通过 schedule 函数让出 CPU。
上面代码中 DEFINE_WAIT_FUNC 的定义:
#define DEFINE_WAIT_FUNC(name, function) \
struct wait_queue_entry name = { \
// current 返回值就是当前线程的结构体 struct task_struct
.private = current, \
.func = function, \
.entry = LIST_HEAD_INIT((name).entry), \
}
/* Returns true if we are the first waiter in the queue, false otherwise. */
bool prepare_to_wait_exclusive(struct wait_queue_head *wq_head, struct wait_queue_entry *wq_entry, int state)
{
unsigned long flags;
bool was_empty = false;
wq_entry->flags |= WQ_FLAG_EXCLUSIVE;
spin_lock_irqsave(&wq_head->lock, flags);
if (list_empty(&wq_entry->entry)) {
was_empty = list_empty(&wq_head->head);
__add_wait_queue_entry_tail(wq_head, wq_entry);
}
set_current_state(state);
spin_unlock_irqrestore(&wq_head->lock, flags);
return was_empty;
}
八、应用层
应用程序一般都是通过epoll、poll和select等多路复用的方式等待 Socket 可读事件,然后通过调用recv、read或recvfrom等函数读取 Socket 接收缓冲区里的数据。当然也可以以阻塞的方式等待 sock_def_readable 函数唤醒,然后recv、read或recvfrom函数就可以读到数据。
九、参考
本文来自博客园,作者:LiYanbin,转载请注明原文链接:https://www.cnblogs.com/stellar-liyanbin/p/18795517

 浙公网安备 33010602011771号
浙公网安备 33010602011771号