
nodejs天生是单线程的,因此不能在nodejs中启动多个线程,但可以实现多进程
process模块常用方法
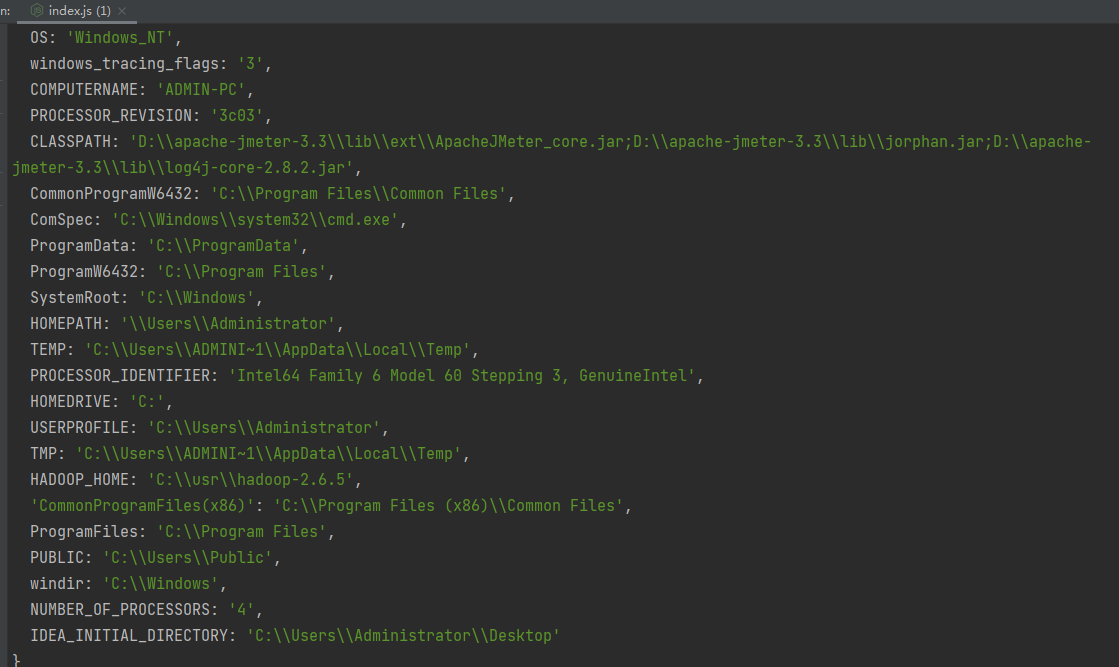
process.env 返回包含用户环境的对象,可设置环境变量,例如Process.env.NODE_ENV

打印process.env:
process.pid 返回进程的pid
process.platform 返回当前进程的操作系统平台
process.title 获取或指定进程名称
process.on(‘uncaughtException’,cb) 捕获异常信息
process.on(‘exit’,cb) 监听进程退出
process.cwd() 返回当前进程的工作目录
process.uptime() 返回当前进程运行时间,单位秒
使用child_process模块创建子进程
有四种方式可供选择:
1、child_process.spawn():能运行所有命令;没有回调;
2、child_process.exec():能运行所有命令;有回调,回调中打印;衍生shell运行慢
3、child_process.execFile():能运行所有命令;有回调,回调中打印;不会衍生shell运行快
4、child_process.fork() : 只能运行node命令;没有回调可以直接打印;
演示spawn:访问/compute路径打印子进程work.js的输出结果
主程序
const http = require('http')
const {spawn} = require('child_process')
const server = http.createServer((req,res)=>{
if(req.url== '/compute'){
const work = spawn('node',['work.js'])
//监听子进程的标准输出流,获取子进程的打印结果
work.stdout.on('data', (data) => {
console.log(`stdout: ${data}`);
});
}
})
server.listen(3000,()=>{
console.log('listen sucess')
})
work.js
process.title = '计算' let sum = 0; for(let i = 0;i<1e10;i++){ sum += i } console.log(sum)
//console.error("出错")
演示exec:访问/compute路径打印子进程work.js的输出结果
主程序:
const http = require('http')
const {exec} = require('child_process')
const server = http.createServer((req,res)=>{
if(req.url== '/compute'){
exec('node work.js',(err,stdout,stderr)=>{
if(err) throw err
console.log(stdout) //直接打印
})
}
})
server.listen(3000,()=>{
console.log('listen sucess')
})
演示execFile:访问/compute路径打印子进程work.js的输出结果
主程序
const http = require('http')
const {execFile} = require('child_process')
const server = http.createServer((req,res)=>{
if(req.url== '/compute'){
//execFile类似于exec,但默认情况下不会衍生shell,比exec稍微高效一点
execFile('node',['work.js'],(err,stdout,stderr)=>{
if(err) throw err
console.log(stdout) //不用on data直接获取
console.log(stderr)
})
}
})
server.listen(3000,()=>{
console.log('listen sucess')
})
演示fork:访问/compute路径打印子进程work.js的输出结果
const http = require('http')
const {fork} = require('child_process')
const server = http.createServer((req,res)=>{
if(req.url== '/compute'){
// fork只能运行node命令,不能运行其他的方法。跟直接运行js代码一样,不需要使用stdout来输出,直接就打印在控制台了
fork('work.js')
}
})
server.listen(3000,()=>{
console.log('listen sucess')
})
使用cluster模块创建子进程
主进程做分发,工作进程是真正干事的
/**
* cluster模块支持两种分发连接的方法:
* 第一种:循环法(除Windows外所有平台的默认方法),由主进程负责监听端口,接收新连接后再将连接循环分发给工作进程,在分发中使用了一些内置技巧防止工作进程任务过载
* 第二种:主进程创建监听socket后发送给感兴趣的工作进程,由工作进程负责直接接收连接
*/
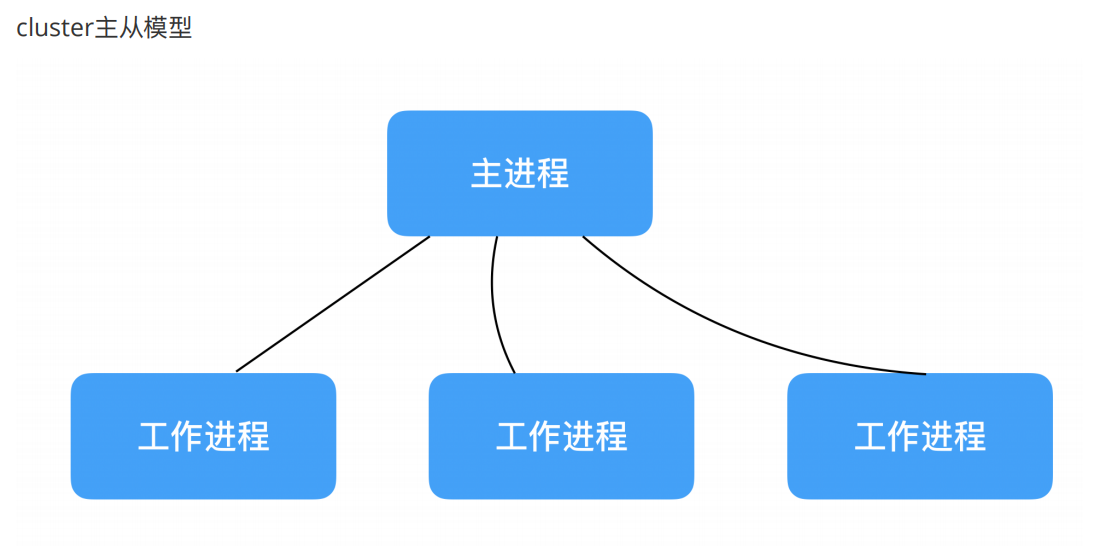
cluster创建工作进程的案例:
const cluster = require('cluster');
const http = require('http');
const numCPUs = require('os').cpus().length; //获取CPU的核数,一般有多少个CPU就创建多少个工作进程
//如果该进程是主进程,isMaster=true。这是由process.env.NODE_UNIQUE_ID决定,如果NODE_UNIQUE_ID未定义,则isMaster=true
if (cluster.isMaster) {
console.log(`主进程 ${process.pid} 正在运行`);
// 创建工作进程。
for (let i = 0; i < numCPUs; i++) {
cluster.fork();
}
//监听进程的退出
cluster.on('exit', (worker, code, signal) => {
console.log(`工作进程 ${worker.process.pid} 已退出`);
});
} else {
// 为什么不存在端口占用的问题???cluster模块支持两种分发连接的方法,这里用的是第一种
// 工作进程可以共享任何 TCP 连接。 在本例子中,共享的是 HTTP 服务器。
http.createServer((req, res) => {
res.writeHead(200);
res.end('你好世界\n');
}).listen(8000);
console.log(`工作进程 ${process.pid} 已启动`);
}
进程间通信
进程间通信的原理:
父进程在实际创建子进程之前,会创建IPC通道并监听它,然后才真正的创建出子进程。此过
程中会通过环境变量(NODE_CHANNEL_FD)告诉子进程这个IPC通道的文件描述符。子进
程在启动的过程中,根据文件描述符连接这个IPC通道,从而完成父子进程之间的连接。
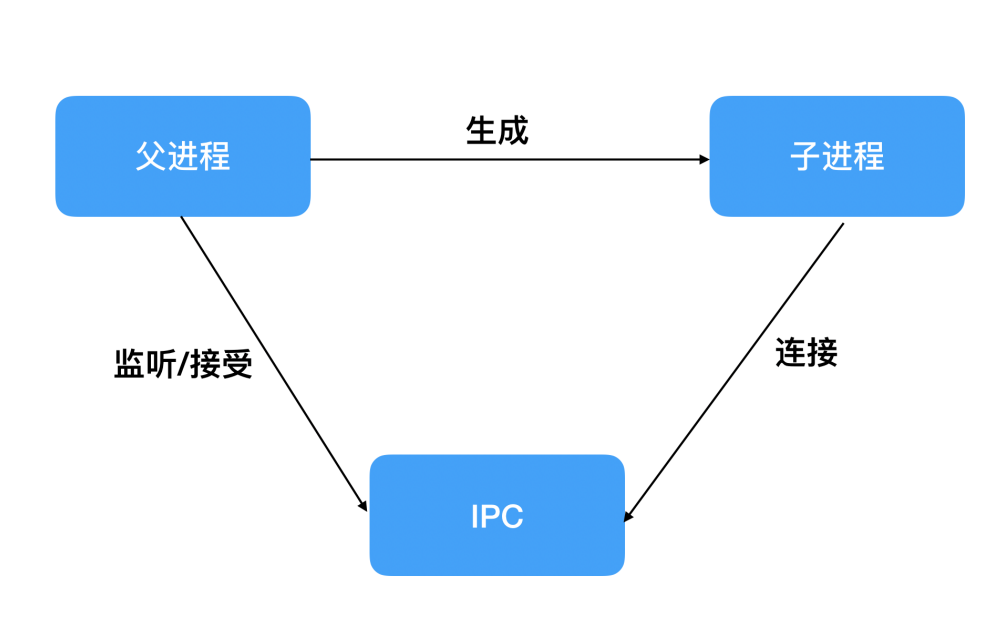
代码示例:
子进程——计算出结果后,进入监听,等待父进程的通知,再将结果发送给父进程
父进程——计算出结果后,进入监听,等待子进程的结果
主程序:
const http = require('http')
const {fork} = require('child_process')
const server = http.createServer((req, res) => {
if (req.url === '/compute') {
res.writeHead(200, {'content-type': 'application/json;charset=UTF-8'})
//fork子进程
const work = fork('work.js')
work.send('发送给子进程的信息')
work.on('message', data => {
res.end('父进程接收子进程的消息:' + data)
})
}
})
server.listen(3000, () => {
console.log('listen sucess')
})
work.js
process.title = '计算' let sum = 0; for(let i = 0;i<100;i++){ sum += i } process.on('message',(data)=>{ console.log('接收父进程的消息:'+data) process.send(sum) })
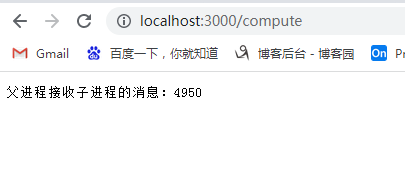
运行结果:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号