SDN功能实现(七)---修改OVS源码实现ACK机制(控制器-交换机用户态-交换机内核态通信)
一:功能介绍
回顾毕业论文中的一个功能模块,个人觉得还是有一定的价值,进行博客分享,可供大家参考,也算是对研究了3年的SDN领域的最后一次知识分享吧,希望有更多的人在SDN领域作出贡献,分享自己的学习经历.
此外,需要说明本文源于自己的毕业论文,所以本人论文不存在抄袭.......
(一)系统部分架构说明
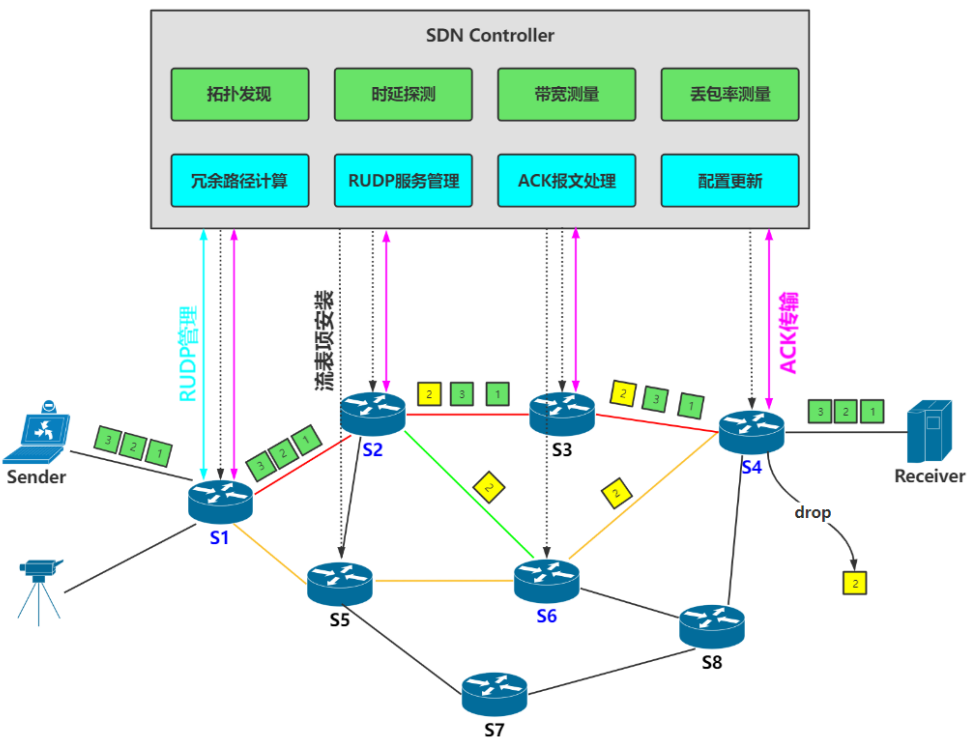
(二)ACK机制
补充:RUDP数据报文字段如下图,通过对FrontDPID和PacketNumber字段数据的获取,用于支持ACK机制的实现.
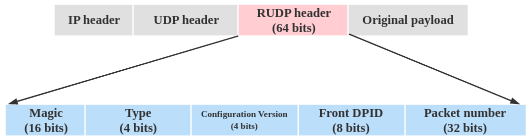
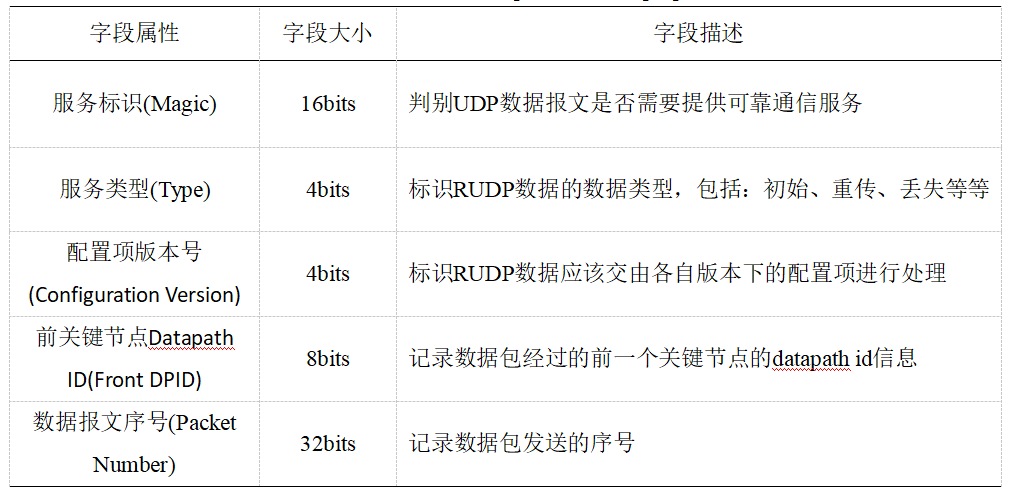
其中各个字段属性如下:
在系统实现中,关键节点交换机(如S4)使用了数据缓存队列缓存所有需要可靠传输服务的RUDP数据包,同时通过开启内核线程实现定时检测队列,如果有新的数据达到,则对最新的数据的包序号进行ACK转发,从内核态通过Generic Netlink机制上传至用户态,用户态通过openflow协议传输至控制器,控制器通过获取的包序号和前一个关键节点交换机(S2)信息,将ACK报文通过OpenFlow协议转发至S2交换机用户空间,S2同样通过Generic Netlink转发至内核态,通过对ACK数据解析,S2获取得到S4中包接收的顺序,因此可以释放数据队列中已经确认的ACK序号前面的所有数据空间,对于丢失的数据,同样通过ACK可以实现重传和转发.
本文主要介绍ACK报文在两个交换机的内核态-用户态-控制器-用户态-内核态之间的转发过程.
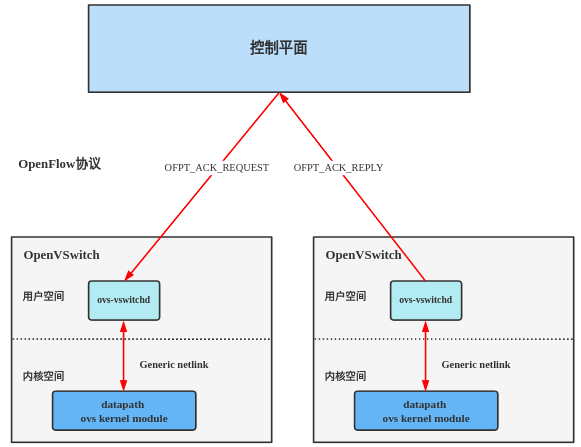
其中Generic Netlink学习,可以看前面转载的几篇博客!!!
二:扩展OpenFlow协议,实现控制器和交换机用户态通信
(一)Ryu源码修改
1.修改ofproto/ofproto_v1_3.py,声明新的OpenFlow消息类型
OFPT_GET_ASYNC_REQUEST = 26 # Controller/switch message OFPT_GET_ASYNC_REPLY = 27 # Controller/switch message OFPT_SET_ASYNC = 28 # Controller/switch message OFPT_METER_MOD = 29 # Controller/switch message
#与前面的消息类型编码不一致(唯一即可) OFPT_ACK_REQUEST = 32 # Symmetric message OFPT_ACK_REPLY = 33 # Symmetric message
2.修改ofproto/ofproto_v1_3_parser.py,实现对新的ACK消息支持
@_register_parser @_set_msg_type(ofproto.OFPT_ACK_REQUEST) class OFPACKRequest(MsgBase): def __init__(self, datapath, data=None): super(OFPACKRequest, self).__init__(datapath) self.data = data @classmethod def parser(cls, datapath, version, msg_type, msg_len, xid, buf): msg = super(OFPACKRequest, cls).parser(datapath, version, msg_type, msg_len, xid, buf) msg.data = msg.buf[ofproto.OFP_HEADER_SIZE:] return msg def _serialize_body(self): if self.data is not None: self.buf += self.data @_register_parser @_set_msg_type(ofproto.OFPT_ACK_REPLY) class OFPACKReply(MsgBase): def __init__(self, datapath, data=None): super(OFPACKReply, self).__init__(datapath) self.data = data @classmethod def parser(cls, datapath, version, msg_type, msg_len, xid, buf): msg = super(OFPACKReply, cls).parser(datapath, version, msg_type, msg_len, xid, buf) msg.data = msg.buf[ofproto.OFP_HEADER_SIZE:] return msg def _serialize_body(self): assert self.data is not None self.buf += self.data
3.完成1,2步骤后记得进行Ryu源码的重新编译!步骤在前面的SDN实现中
4.实现Ryu App应用对新的ACK消息进行转发
from ryu.base import app_manager from ryu.controller import ofp_event from ryu.controller.handler import CONFIG_DISPATCHER, MAIN_DISPATCHER from ryu.controller.handler import MAIN_DISPATCHER,CONFIG_DISPATCHER,DEAD_DISPATCHER,HANDSHAKE_DISPATCHER #只是表示datapath数据路径的状态 from ryu.controller.handler import set_ev_cls from ryu.ofproto import ofproto_v1_3 from ryu.lib.packet import packet from ryu.lib.packet import ethernet from ryu.lib.packet import ether_types from ryu.lib.packet import udp from ryu.lib.packet import ipv4 from struct import pack RUDP_MAGIC = 38217 class RudpTrans(app_manager.RyuApp): OFP_VERSIONS = [ofproto_v1_3.OFP_VERSION] def __init__(self, *args, **kwargs): super(RudpTrans, self).__init__(*args, **kwargs) self.mac_to_port = {} self.datapaths = {} self.initFlag = False @set_ev_cls(ofp_event.EventOFPSwitchFeatures, CONFIG_DISPATCHER) def switch_features_handler(self, ev): datapath = ev.msg.datapath self.datapaths[datapath.id] = datapath ofproto = datapath.ofproto parser = datapath.ofproto_parser # install table-miss flow entry # # We specify NO BUFFER to max_len of the output action due to # OVS bug. At this moment, if we specify a lesser number, e.g., # 128, OVS will send Packet-In with invalid buffer_id and # truncated packet data. In that case, we cannot output packets # correctly. The bug has been fixed in OVS v2.1.0. match = parser.OFPMatch() actions = [parser.OFPActionOutput(ofproto.OFPP_CONTROLLER, ofproto.OFPCML_NO_BUFFER)] self.add_flow(datapath, 0, match, actions) def add_flow(self, datapath, priority, match, actions, buffer_id=None): ofproto = datapath.ofproto parser = datapath.ofproto_parser inst = [parser.OFPInstructionActions(ofproto.OFPIT_APPLY_ACTIONS, actions)] if buffer_id: mod = parser.OFPFlowMod(datapath=datapath, buffer_id=buffer_id, priority=priority, match=match, instructions=inst) else: mod = parser.OFPFlowMod(datapath=datapath, priority=priority, match=match, instructions=inst) datapath.send_msg(mod) def _send_ack_request(self,dp_id,hash_id,packet_number,type_id): """ 发送echo_time报文到datapath """ print("===============_send_ack_request========start============") print("front dpid / hash id / packet number / type id : ",dp_id, hash_id, packet_number, type_id) datapath = self.datapaths.get(dp_id,None) if datapath == None: return parser = datapath.ofproto_parser print("========%d"%packet_number); ack_req = parser.OFPACKRequest(datapath,data=pack("BBBI",dp_id,hash_id,type_id,packet_number)) datapath.send_msg(ack_req) print("==========_send_ack_request=========end=====") @set_ev_cls(ofp_event.EventOFPACKReply,[MAIN_DISPATCHER,CONFIG_DISPATCHER,HANDSHAKE_DISPATCHER]) def ack_reply_handler(self,ev): """ 处理ACK响应报文,获取控制器到交换机的链路往返时延 """ print("==================OFPT_ACK_REPLY============start===========") print(ev.msg.data) info = ev.msg.data front_dpid = int.from_bytes(info[0:1],'little') hash_id = int.from_bytes(info[1:2],'little') packet_id = int.from_bytes(info[2:6],'little') type_id = int.from_bytes(info[6:7],'little') self._send_ack_request(front_dpid,hash_id,packet_id,type_id) print("==================OFPT_ACK_REPLY===========end============")
(二)OVS源码修改,实现对新的OpenFlow消息支持
1.修改include/openvswitch/ofp-msgs.h下的enum ofptype和enum ofpraw枚举类型
enum ofptype { OFPTYPE_HELLO, /* OFPRAW_OFPT_HELLO. */ OFPTYPE_ERROR, /* OFPRAW_OFPT_ERROR. ...... OFPTYPE_ACK_REQUEST, /* OFPRAW_OFPT_ACK_REQUEST */ OFPTYPE_ACK_REPLY, /* OFPRAW_OFPT_ACK_REPLY */ ...... }
注意:注释对应了下面ofpraw枚举的名称
enum ofpraw { ...... /* OFPT 1.1-1.3 (32): uint8_t[]. */ OFPRAW_OFPT_ACK_REQUEST, /* OFPT 1.1-1.3 (33): uint8_t[]. */ OFPRAW_OFPT_ACK_REPLY, ...... }
注意:序号需要保持与Ryu中的消息序号一致!!!
2.修改在ofproto/ofproto.c文件中handle_flow函数下的handle_single_part_openflow方法,处理自定义的类型
static enum ofperr handle_single_part_openflow(struct ofconn *ofconn, const struct ofp_header *oh, enum ofptype type) OVS_EXCLUDED(ofproto_mutex) { switch (type) { /* OpenFlow requests. */ ...... case OFPTYPE_ACK_REQUEST: // VLOG_INFO("--------------------OFPTYPE_ACK_REQUEST--------------------"); return handle_ack_request(ofconn,oh); ...... case OFPTYPE_ACK_REPLY: return 0; ...... }
同样在该文件中实现handle_ack_request方法:
static enum ofperr handle_ack_request(struct ofconn *ofconn, const struct ofp_header *oh) { //不同的是,获取数据,发送消息给内核 // VLOG_INFO("----handle_ack_request-------start----"); if(!ack_init) return OFPERR_OFPAFC_INIT; if(!ack_oh || ack_oh != oh) ack_oh = oh; struct ofpbuf rq_buf = ofpbuf_const_initializer(oh, ntohs(oh->length)); //rq_buf.data是我们的数据,但是前面8个字节是结构体ofp_header,所以我们获取真正的数据需要跳过这8个字节数据 char *data = rq_buf.data; // uint32_t packetid = ack_parse_packet_number(data+8,rq_buf.size-8); uint8_t front_dpid = *(uint8_t *)(data + 8); uint8_t hash_id = *(uint8_t *)(data + 9); uint8_t typeid = *(uint8_t *)(data + 10); uint32_t packetid = *(uint32_t *)(data + 12); //存在对齐问题,所以间隔2
//通过以上操作,可以获取并解析出控制器转发的ACK消息数据 // VLOG_INFO("--handle_ack_request---front dpid:%u--hash id:%u--packet id:%u- type:%u-------",front_dpid,hash_id,packetid,typeid); dpif_netlink_ack_reply(false,front_dpid,hash_id,packetid,typeid); return 0; }
其中dpif_netlink_ack_reply方案用于将解析的数据通过Generic Netlink转发至内核态,将在下一章中进行详细介绍!
三:实现交换机内核态与用户态通信
(一)用户态主动与内核态通信
1.在内核态进行新的Generic Netlink套接字注册
(1)在datapath/linux/compat/include/linux/openvswitch.h中进行类型声明
/* ACK. */ #define OVS_ACK_FAMILY "ovs_ack" #define OVS_ACK_VERSION 0x1 enum ovs_ack_cmd { OVS_ACK_CMD_UNSPEC, OVS_ACK_CMD_ECHO, //用户发给内核,该命令将由内核进行处理 OVS_ACK_CMD_SET, //用戶发送给内核,进行设置 OVS_ACK_CMD_REPLY, //由内核发送响应给用户态,该命令将由用户态进行处理 __OVS_ACK_CMD_MAX, }; #define OVS_ACK_CMD_MAX (__OVS_ACK_CMD_MAX - 1) enum ovs_ack_attr { OVS_ACK_ATTR_UNSPEC = 0, OVS_ACK_ATTR_INIT, //flag标识初始化 OVS_ACK_ATTR_VID, //8bits无符号整型 OVS_ACK_ATTR_OUTPUT, //16bits无符号整型 OVS_ACK_ATTR_TURNOUT, //16bits无符号整型 OVS_ACK_ATTR_QUEUE_SIZE, //16bits无符号整型 OVS_ACK_ATTR_TIME_INTERVAL, //16bits无符合整型 OVS_ACK_ATTR_DEVSTATUS, //8bits无符号整型 OVS_ACK_ATTR_HASH_ID, //8bits无符号整型 OVS_ACK_ATTR_TYPE, //8bits无符号整型 OVS_ACK_ATTR_NUMBER, //32bits无符号整型 __OVS_ACK_ATTR_MAX, }; #define OVS_ACK_ATTR_MAX (__OVS_ACK_ATTR_MAX - 1)
其中红色的字段与本次的ACK机制有关,其他的是关于其他功能的,这里不需要关心.
另外需要补充,datapath/linux/compat/include/linux/openvswitch.h在编译过程中会自动生成一个include/odp-netlink.h文件,我们在用户空间中使用这个头文件即可.
(2)在datapath/datapath.c中进行实现
Ⅰ.为模块添加Generic Netlink family信息
module_init(dp_init); module_exit(dp_cleanup); MODULE_DESCRIPTION("Open vSwitch switching datapath"); MODULE_LICENSE("GPL"); MODULE_VERSION(VERSION); MODULE_ALIAS_GENL_FAMILY(OVS_DATAPATH_FAMILY); MODULE_ALIAS_GENL_FAMILY(OVS_VPORT_FAMILY); MODULE_ALIAS_GENL_FAMILY(OVS_FLOW_FAMILY); MODULE_ALIAS_GENL_FAMILY(OVS_PACKET_FAMILY); MODULE_ALIAS_GENL_FAMILY(OVS_ACK_FAMILY); MODULE_ALIAS_GENL_FAMILY(OVS_METER_FAMILY); MODULE_ALIAS_GENL_FAMILY(OVS_CT_LIMIT_FAMILY);
Ⅱ.定义策略、操作集和family
static const struct nla_policy ack_policy[OVS_ACK_ATTR_MAX + 1] = { [OVS_ACK_ATTR_INIT] = {.type = NLA_FLAG}, [OVS_ACK_ATTR_VID] = {.type = NLA_U8}, [OVS_ACK_ATTR_HASH_ID] = {.type = NLA_U8}, [OVS_ACK_ATTR_NUMBER] = {.type = NLA_U32}, [OVS_ACK_ATTR_TYPE] = {.type = NLA_U8}, [OVS_ACK_ATTR_OUTPUT] = {.type = NLA_U16}, [OVS_ACK_ATTR_TURNOUT] = {.type = NLA_U16}, [OVS_ACK_ATTR_QUEUE_SIZE] = {.type = NLA_U16}, [OVS_ACK_ATTR_TIME_INTERVAL] = {.type = NLA_U16}, [OVS_ACK_ATTR_DEVSTATUS] = {.type = NLA_U8}, }; //其他的为默认,NLA_UNSPEC表示类型和长度未知 static const struct genl_ops dp_ack_genl_ops[] = { { .cmd = OVS_ACK_CMD_ECHO, .doit = ovs_ack_cmd_execute, .policy = ack_policy, .flags = 0, }, { .cmd = OVS_ACK_CMD_SET, .doit = ovs_ack_cmd_set, .policy = ack_policy, .flags = 0, }, }; static struct genl_family dp_ack_genl_family __ro_after_init = { .id = 0, //内核自动生成ID,我们后面通过name去查询ID .hdrsize = sizeof(struct ovs_header), .name = OVS_ACK_FAMILY, .version = OVS_ACK_VERSION, .maxattr = OVS_ACK_ATTR_MAX, .netnsok = true, .parallel_ops = true, .ops = dp_ack_genl_ops, .n_ops = ARRAY_SIZE(dp_ack_genl_ops), .module = THIS_MODULE, };
对于多余的删去,不要即可,保留红色的就行。
Ⅲ.实现对用户态下发的数据获取功能,即前面的ovs_ack_cmd_execute函数
static int ovs_ack_cmd_execute(struct sk_buff *skb, struct genl_info *info) { // pr_info("--------------ovs_ack_cmd_execute-------------------------\n"); // struct sk_buff *user_skb = NULL; /* to be queued to userspace */ struct ovs_header *ovs_header = info->userhdr; struct nlattr **a = info->attrs; uint32_t number = 0; uint8_t typeid = 0; uint8_t Dpid = 0; uint8_t hashId = 0; if (a[OVS_ACK_ATTR_INIT]){ // pr_info("--------------OVS_ACK_ATTR_INIT-------------------------\n"); // ovs_ack_genl_request(number,info); }else if(a[OVS_ACK_ATTR_NUMBER] && a[OVS_ACK_ATTR_TYPE]){ //----获取得到需要的信息,根据需求进行下一步定制即可 Dpid = nla_get_u8(info->attrs[OVS_ACK_ATTR_VID]); hashId = nla_get_u8(info->attrs[OVS_ACK_ATTR_HASH_ID]); number = nla_get_u32(info->attrs[OVS_ACK_ATTR_NUMBER]); typeid = nla_get_u8(info->attrs[OVS_ACK_ATTR_TYPE]); pr_info("--------------OVS_ACK_ATTR_NUMBER--%u--%u---%u-------%u-------%u----\n",Dpid,hashId,number,typeid,now_t()); if(typeid == 0 || rudp_dev[Dpid][hashId].lastPktFlag < number) { //ack确认回送 rudp_dev[Dpid][hashId].lastPktFlag = number; }else if(typeid >= 1 && typeid <= 5) { //数据包丢失 丢失(链路无故障)重发,延迟(链路可能故障)重发+转发 pr_info("--------------ChecklossPacketAndTurn pkt loss-----------"); ChecklossPacketAndTurn(Dpid,hashId,number,typeid); } //test 开始进行处理数据,比如定时器计时 // testRudpTimer(number); }else{ pr_info("--------------no type-------------------------\n"); } return 0; }
2.在用户态通过Generic Netlink套接字下发数据给内核态
接着二(二)中的dpif_netlink_ack_reply方法解析函数下发消息至内核态
(1)在lib/dpif-netlink.h中进行函数声明
int dpif_netlink_ack_reply(bool init,uint8_t front_dpid,uint8_t hash_id,uint32_t number,uint8_t type_id);
注意在本文件中包含了#include "odp-netlink.h"头文件,如果没有加上即可
(2)在lib/dpif-netlink.c中进行实现
Ⅰ.声明使用的family
* Initialized by dpif_netlink_init(). */ static int ovs_datapath_family; static int ovs_vport_family; static int ovs_flow_family; static int ovs_packet_family; static int ovs_ack_family; static int ovs_meter_family; static int ovs_ct_limit_family;
Ⅱ.实现Generic Netlink通信
int dpif_netlink_ack_reply(bool init,uint8_t front_dpid,uint8_t hash_id,uint32_t number,uint8_t type_id) { if (ovs_ack_family < 0) { return EOPNOTSUPP; } struct ofpbuf *request = ofpbuf_new(NL_DUMP_BUFSIZE); nl_msg_put_genlmsghdr(request, 0, ovs_ack_family, NLM_F_REQUEST | NLM_F_ECHO, OVS_ACK_CMD_ECHO, OVS_ACK_VERSION); struct ovs_header *ovs_header; ovs_header = ofpbuf_put_uninit(request, sizeof *ovs_header); ovs_header->dp_ifindex = 0; if (init) { nl_msg_put_flag(request, OVS_ACK_ATTR_INIT); }else{ nl_msg_put_u8(request, OVS_ACK_ATTR_VID, front_dpid); nl_msg_put_u8(request, OVS_ACK_ATTR_HASH_ID, hash_id); nl_msg_put_u32(request, OVS_ACK_ATTR_NUMBER, number); nl_msg_put_u8(request, OVS_ACK_ATTR_TYPE, type_id); } int err = nl_transact(NETLINK_GENERIC, request, NULL); ofpbuf_delete(request); return err; }
(二)内核态主动发送消息到用户空间
由于内核态->用户态与用户态->内核态通信是异步操作,并且通过源码分析,发现通过扩展原有dp_packet_genl_family更为简单,所以选取对dp_packet_genl_family进行修改(之前也想过在用户态ovs-vswitchd进程中通过开启新的线程进行检测内核发送的消息,但是感觉效率没有ovs内部源码写的好,所以复用原有套接字,进行二次修改).若是大家有更好的扩展方案,请分享出来.
前提理解:在内核态中接收到数据包后,若是无法在匹配到流表项,则需要上传至用户态中进行查询;该过程通过datapath/datapath.c中的queue_userspace_packet实现.通过OVS_PACKET_FAMILY套接字实现.因此在此基础上实现通信
1.在datapath/linux/compat/include/linux/openvswitch.h中进行消息扩展
/* Packet transfer. */ #define OVS_PACKET_FAMILY "ovs_packet" #define OVS_PACKET_VERSION 0x1 enum ovs_packet_cmd { OVS_PACKET_CMD_UNSPEC, /* Kernel-to-user notifications. */ OVS_PACKET_CMD_MISS, /* Flow table miss. */ OVS_PACKET_CMD_ACTION, /* OVS_ACTION_ATTR_USERSPACE action. */ /* Userspace commands. */ OVS_PACKET_CMD_EXECUTE, /* Apply actions to a packet. */ /* Extern Kernel-to-user notification */ OVS_PACKET_CMD_ACK }; /** * enum ovs_packet_attr - attributes for %OVS_PACKET_* commands. * @OVS_PACKET_ATTR_PACKET: Present for all notifications. Contains the entire * packet as received, from the start of the Ethernet header onward. For * %OVS_PACKET_CMD_ACTION, %OVS_PACKET_ATTR_PACKET reflects changes made by * actions preceding %OVS_ACTION_ATTR_USERSPACE, but %OVS_PACKET_ATTR_KEY is * the flow key extracted from the packet as originally received. * @OVS_PACKET_ATTR_KEY: Present for all notifications. Contains the flow key * extracted from the packet as nested %OVS_KEY_ATTR_* attributes. This allows * userspace to adapt its flow setup strategy by comparing its notion of the * flow key against the kernel's. When used with %OVS_PACKET_CMD_EXECUTE, only * metadata key fields (e.g. priority, skb mark) are honored. All the packet * header fields are parsed from the packet instead. * @OVS_PACKET_ATTR_ACTIONS: Contains actions for the packet. Used * for %OVS_PACKET_CMD_EXECUTE. It has nested %OVS_ACTION_ATTR_* attributes. * Also used in upcall when %OVS_ACTION_ATTR_USERSPACE has optional * %OVS_USERSPACE_ATTR_ACTIONS attribute. * @OVS_PACKET_ATTR_USERDATA: Present for an %OVS_PACKET_CMD_ACTION * notification if the %OVS_ACTION_ATTR_USERSPACE action specified an * %OVS_USERSPACE_ATTR_USERDATA attribute, with the same length and content * specified there. * @OVS_PACKET_ATTR_EGRESS_TUN_KEY: Present for an %OVS_PACKET_CMD_ACTION * notification if the %OVS_ACTION_ATTR_USERSPACE action specified an * %OVS_USERSPACE_ATTR_EGRESS_TUN_PORT attribute, which is sent only if the * output port is actually a tunnel port. Contains the output tunnel key * extracted from the packet as nested %OVS_TUNNEL_KEY_ATTR_* attributes. * @OVS_PACKET_ATTR_MRU: Present for an %OVS_PACKET_CMD_ACTION and * @OVS_PACKET_ATTR_LEN: Packet size before truncation. * %OVS_PACKET_ATTR_USERSPACE action specify the Maximum received fragment * size. * * These attributes follow the &struct ovs_header within the Generic Netlink * payload for %OVS_PACKET_* commands. */ enum ovs_packet_attr { OVS_PACKET_ATTR_UNSPEC, OVS_PACKET_ATTR_PACKET, /* Packet data. */ OVS_PACKET_ATTR_KEY, /* Nested OVS_KEY_ATTR_* attributes. */ OVS_PACKET_ATTR_ACTIONS, /* Nested OVS_ACTION_ATTR_* attributes. */ OVS_PACKET_ATTR_USERDATA, /* OVS_ACTION_ATTR_USERSPACE arg. */ OVS_PACKET_ATTR_EGRESS_TUN_KEY, /* Nested OVS_TUNNEL_KEY_ATTR_* attributes. */ OVS_PACKET_ATTR_UNUSED1, OVS_PACKET_ATTR_UNUSED2, OVS_PACKET_ATTR_PROBE, /* Packet operation is a feature probe, error logging should be suppressed. */ OVS_PACKET_ATTR_MRU, /* Maximum received IP fragment size. */ OVS_PACKET_ATTR_LEN, /* Packet size before truncation. */ /* extern ack */ OVS_PACKET_ATTR_FD, /* front dpid*/ OVS_PACKET_ATTR_HASH_ID, /* ack ip hash id */ OVS_PACKET_ATTR_ACK, /* packet number,4bytes*/ OVS_PACKET_ATTR_TYPE_ID, /* packet ack type */ __OVS_PACKET_ATTR_MAX }; #define OVS_PACKET_ATTR_MAX (__OVS_PACKET_ATTR_MAX - 1)
添加红色字段即可.
2.在datapath/datapath.c中实现内核发送ACK数据至用户空间
在本系统中将RUDP数据包放入了数据队列中,通过dev_id与hash_id索引了通信双方(src_ip,dst_ip)的数据缓存队列,通过定时获取检测数据队列回送ACK报文。(当然可以按照思想实现自己的功能)
Ⅰ.开启线程,进行数据队列数据包检测
//线程启动函数 int ack_thread_func(void *data) { bool devs[DEV_NUMBER] = {0}; bool hashids[QUEUE_HASH_NUMBER] = {0}; int dev_nums = 0,hashid_nums = 0, eleIdx; struct PacketInfo *pi = NULL; int i,j,k; uint8_t src,dst; // uint8_t i; uint16_t num,startIdx, cnt = 0; init_ack_timer(); for(;;) { if(kthread_should_stop()) { break; } //获取ack队列数据 dev_nums = Rudp_Get_devIds(devs); // pr_info("--------dev_nums--------------%d---",dev_nums); // pr_info("---dev_nums: %d %d %d %d----",devs[1],devs[2],devs[6],devs[7]); for(i=0;i<DEV_NUMBER;i++) { if(devs[i]) { // pr_info("--------dev id------%d--\n",i); hashid_nums = Rudp_Get_QueueSizes(i,hashids); // pr_info("--------hashid_nums--------------%d---",hashid_nums); for(j = 0; j < QUEUE_HASH_NUMBER; j++) { // pr_info("----------rudp_dev[%d][%d].dev_status--%d---",i,j,rudp_dev[i][j].dev_status); // pr_info("-----------test 1---------------"); if(hashids[j]) { //----------------------------!!!!未处理,未移除队列数据导致一直添加数据 if(rudp_dev[i][j].dev_status == 0 || Rudp_Queue_getTopEle(i,j) == NULL) { //不进行ack回送 continue; } src = j >> 4; dst = j & 0x0f; // pr_info("-----------test 2---------------"); //开始获取队列尾部元素,进入计时器中 eleIdx = Rudp_Queue_getRearIdx(i,j); // pr_info("-----------test 3---------------"); //对于状态2,3都需要就行ACK回送,丢失处理和过期处理 if(rudp_dev[i][j].dev_status != 1) { //1.处理丢失数据响应 check_loss_ack(i,j); // pr_info("--------hashid_%d---------src:%d-----dst:%d---",j,src,dst); if(Rudp_Queue_GetLossQueueStatus(i,j) && (num = Rudp_Queue_GetLossQueueNumber(i,j))) { // pr_info("-----------loss queue number:%d----",num); startIdx = (src - 1) * LOSS_QUEUE_LEN; for(k = 0,cnt=0; k < LOSS_QUEUE_LEN && cnt != num; k++) { if(rudp_dev[i][dst].queue[startIdx + k].packet_id) cnt++; do_send_loss_ack(i,dst,startIdx+k); // add_ack_timer(MIN_TIME_INTERVAL,i,dst,startIdx+k,do_cirNode_call); } } //2.处理正常数据响应 // pr_info("--------eleIdx--------------%d---",eleIdx); if(eleIdx == -1) { //还未插入数据,队列中无数据 break; } // pr_info("-----------test 4---------------"); if(Rudp_Queue_GettimerIdx(i,j) == eleIdx) { //已经存在定时器中了,不需要反复添加 break; } // pr_info("-----------test 5---------------"); do_send_recv_ack(i,j,eleIdx); //回送ACK //注意:状态3不需要进行转发,直接释放即可 if(rudp_dev[i][j].dev_status == 3) { do_free_devStatus(i,j,eleIdx); } } //对于状态1,2都需要就行过期检测! if(rudp_dev[i][j].dev_status != 3) add_ack_timer(Rudp_Queue_GettimeInt(i,j)+2,i,j,eleIdx,do_ackCheck_call); //设置过期时间为(时延+2)*6 // timer_entry_t *add_ack_timer(uint32_t msec,uint8_t dev_id, uint16_t hash_id, uint32_t queue_idx, timer_handler_ptr callback) // pr_info("--------add_ack_timer-----------------"); } } } } //检查过期事件 expire_ack_timer(); // pr_info("-------ack_thread_func-----%d---%d---\n",ack_packet_number++,ack_sleep_interval++); msleep(1); } return 0; }
在内核datapath初始化时,开启线程:
static struct task_struct *ack_task;
static int __init dp_init(void) { int err; BUILD_BUG_ON(sizeof(struct ovs_skb_cb) > FIELD_SIZEOF(struct sk_buff, cb)); pr_info("Open vSwitch switching datapath %s\n", VERSION); ovs_nsh_init(); err = action_fifos_init(); if (err) goto error; err = ovs_internal_dev_rtnl_link_register(); if (err) goto error_action_fifos_exit; err = ovs_flow_init(); if (err) goto error_unreg_rtnl_link; err = ovs_vport_init(); if (err) goto error_flow_exit; err = register_pernet_device(&ovs_net_ops); if (err) goto error_vport_exit; err = compat_init(); if (err) goto error_netns_exit; err = register_netdevice_notifier(&ovs_dp_device_notifier); if (err) goto error_compat_exit; err = ovs_netdev_init(); if (err) goto error_unreg_notifier; err = dp_register_genl(); if (err < 0) goto error_unreg_netdev; //创建线程 ack_task = kthread_create(ack_thread_func, NULL, "ack_task"); if(IS_ERR(ack_task)) { printk("Unable to start kernel thread.\n"); ack_task = NULL; goto error_unreg_netdev; } wake_up_process(ack_task); return 0; error_unreg_netdev: ovs_netdev_exit(); error_unreg_notifier: unregister_netdevice_notifier(&ovs_dp_device_notifier); error_compat_exit: compat_exit(); error_netns_exit: unregister_pernet_device(&ovs_net_ops); error_vport_exit: ovs_vport_exit(); error_flow_exit: ovs_flow_exit(); error_unreg_rtnl_link: ovs_internal_dev_rtnl_link_unregister(); error_action_fifos_exit: action_fifos_exit(); error: ovs_nsh_cleanup(); return err; } static void dp_cleanup(void) { int i = 0; pr_info("----------dp_clean-----------------"); if(ack_task && ack_task != NULL) { kthread_stop(ack_task); ack_task = NULL; } //free resources for(i=0;i<DEV_NUMBER;i++) { Rudp_Device_free(i); } dp_unregister_genl(ARRAY_SIZE(dp_genl_families)); ovs_netdev_exit(); unregister_netdevice_notifier(&ovs_dp_device_notifier); compat_exit(); unregister_pernet_device(&ovs_net_ops); rcu_barrier(); ovs_vport_exit(); ovs_flow_exit(); ovs_internal_dev_rtnl_link_unregister(); action_fifos_exit(); ovs_nsh_cleanup(); } module_init(dp_init); module_exit(dp_cleanup);
以上函数不需要过多关注,只需要知道通过do_send_recv_ack方法进行ACK上传即可。
Ⅱ.do_send_recv_ack为上传ACK报文做准备,包括从数据缓存队列获取skb数据,解析portid等等
int do_send_recv_ack(uint8_t dev_id,uint16_t hash_id,uint16_t queue_idx) //状态2(1):只需要回送确认ACK-->两种ACK类型(包括确认ACK、丢失ACK) { uint32_t pkt_id,portid; uint8_t type_id, frontDpid; struct sk_buff *skb; char* data = NULL; // pr_info("---------------do_send_recv_ack start------------"); //1.从数据缓存队列中获取最新的数据包信息 pkt_id = rudp_dev[dev_id][hash_id].queue[queue_idx].packet_id; type_id = rudp_dev[dev_id][hash_id].queue[queue_idx].type_id; frontDpid = rudp_dev[dev_id][hash_id].queue[queue_idx].frontDp_id; skb = rudp_dev[dev_id][hash_id].queue[queue_idx].data; pr_info("---------------do_send_recv_ack dev_id:%d frontDpid:%d-----",dev_id,frontDpid); if(skb == NULL) { // pr_info("---------wait-----------"); return -1; } //2.解析skb数据,获取packet number struct udphdr *udp_header = (struct udphdr *)skb_transport_header(skb); data = (char *)((char *)udp_header + 8); u32 packetid = MyProto_head_get_packetid((const struct MyProtoHead *)data); //3.通过skb数据获取vport和datapath信息 const struct vport *p = OVS_CB(skb)->input_vport; struct datapath *dp = p->dp; if(p==NULL || dp == NULL) { // pr_info("-------do_send_recv_ack err-----"); return -2; } //4.获取与用户空间通信的portid portid = ovs_vport_find_upcall_portid(p, skb); pr_info("---------------do_send_recv_ack dev_id:%d frontDpid:%d-----pktid:%d-----pktId:%d--typeid:%d",dev_id,frontDpid,pkt_id,packetid,type_id); //5.发送确认ACK到用户空间 send_ack_userspace_packet(dp, portid, frontDpid, hash_id, pkt_id, type_id); // pr_info("---------------do_send_recv_ack end------------"); return 0; }
Ⅲ.send_ack_userspace_packet方法通过generic netlink发送ACK报文到用户空间
static int send_ack_userspace_packet(struct datapath *dp, u32 portid, u8 frontDpid, u8 hashid, u32 packetid, u8 typeid) { struct ovs_header *upcall; struct sk_buff *user_skb = NULL; /* to be queued to userspace */ size_t len; int err, dp_ifindex; dp_ifindex = get_dpifindex(dp); if (!dp_ifindex){ // pr_info("---send_ack_userspace_packet !dp_if---"); return -ENODEV; } pr_info("------------send_ack_userspace_packet------start-------"); pr_info("----send_ack_userspace_packet--datapath:%p-%u--------_%u-----------%u-----------typeid:%u",dp,frontDpid,hashid,packetid,typeid); //1.分配空间,构造新的user_skb数据,存放上传的ACK数据 len = NLMSG_ALIGN(sizeof(struct ovs_header)) + nla_total_size(sizeof(u8)) + nla_total_size(sizeof(u8)) + nla_total_size(sizeof(u8)) + nla_total_size(sizeof(u32)); user_skb = genlmsg_new(len, GFP_ATOMIC); if (!user_skb) { err = -ENOMEM; pr_info("---send_ack_userspace_packet !user_skb---"); goto out; } //2.通过OVS_PACKET_CMD_ACK命令类型进行通信 upcall = genlmsg_put(user_skb, 0, 0, &dp_packet_genl_family, 0, OVS_PACKET_CMD_ACK); upcall->dp_ifindex = dp_ifindex; //3.进行ACK数据填充 /* Add OVS_PACKET_ATTR_FD */ if (nla_put_u8(user_skb, OVS_PACKET_ATTR_FD, frontDpid)) { err = -ENOBUFS; pr_info("---send_ack_userspace_packet !frontDpid---"); goto out; } /* Add OVS_PACKET_ATTR_HASH_ID */ if(nla_put_u8(user_skb,OVS_PACKET_ATTR_HASH_ID, hashid)){ err = -ENOBUFS; pr_info("---send_ack_userspace_packet !hashid---"); goto out; } /* Add OVS_PACKET_ATTR_TYPE_ID */ if(nla_put_u8(user_skb,OVS_PACKET_ATTR_TYPE_ID, typeid)){ err = -ENOBUFS; // pr_info("---send_ack_userspace_packet !typeid---"); goto out; } /* Add OVS_PACKET_ATTR_ACK */ if (nla_put_u32(user_skb, OVS_PACKET_ATTR_ACK, packetid)) { err = -ENOBUFS; // pr_info("---send_ack_userspace_packet !packetid---"); goto out; } //4.更新数据信息,单播上传至用户空间 ((struct nlmsghdr *) user_skb->data)->nlmsg_len = user_skb->len; if(ovs_dp_get_net(dp) == NULL){ pr_info("-----send_ack_userspace_packet ovs_dp_get_net(dp) err-----------"); } err = genlmsg_unicast(ovs_dp_get_net(dp), user_skb, portid); user_skb = NULL; out: // kfree_skb(user_skb); pr_info("------------send_ack_userspace_packet------end-------"); return err; }
因为接收ACK通过OVS_ACK_CMD_ECHO实现,并且在内部进行了policy检测,所以我们在这里OVS_PACKET_CMD_ACK中只是进行上传,不需要进行检测,所以不用修改family和policy。
3.用户态对内核上传的ACK数据进行解析
通过源码分析,用户态通过ofproto/ofproto-dpif-upcall.c中的recv_upcalls方法对内核传输的OVS_PACKET数据包进行获取,recv_upcalls方法调用dpif_recv函数,在dpif_recv内部通过回调函数dpif->dpif_class->recv(实际被初始化为dpif_netlink_recv),调用dpif_netlink_recv__方法,在内部通过parse_odp_packet方法解析数据包,以上方法在lib/dpif-netlink.c中实现,而本文需要通过扩展的OpenFlow消息,上传ACK信息至控制器,因此需要在ofproto模块下获取返回的数据,所以定义了一个新的数据结构,改变以上函数参数列表,通过传参(指针),返回ACK信息。
Ⅰ.在lib/dpif.h中扩展新的数据结构dpif_ack,用于保存ACK数据
struct dpif_ack { bool ack_flag; uint8_t front_dpid; uint32_t packet_id; uint8_t hash_id; uint8_t type_id; };
Ⅱ.从recv_upcalls到parse_odp_packet,按序修改传参和实现
1)recv_upcalls修改:
static size_t recv_upcalls(struct handler *handler) { struct udpif *udpif = handler->udpif; uint64_t recv_stubs[UPCALL_MAX_BATCH][512 / 8]; struct ofpbuf recv_bufs[UPCALL_MAX_BATCH]; struct dpif_upcall dupcalls[UPCALL_MAX_BATCH]; struct upcall upcalls[UPCALL_MAX_BATCH]; struct flow flows[UPCALL_MAX_BATCH]; size_t n_upcalls, i; // VLOG_INFO("-------------recv_upcalls--------------"); n_upcalls = 0; while (n_upcalls < UPCALL_MAX_BATCH) { struct ofpbuf *recv_buf = &recv_bufs[n_upcalls]; struct dpif_upcall *dupcall = &dupcalls[n_upcalls]; struct upcall *upcall = &upcalls[n_upcalls]; struct flow *flow = &flows[n_upcalls]; unsigned int mru; int error; struct dpif_ack dack; dack.ack_flag = false; ofpbuf_use_stub(recv_buf, recv_stubs[n_upcalls], sizeof recv_stubs[n_upcalls]); if (dpif_recv(udpif->dpif, handler->handler_id, dupcall, recv_buf, &dack)) { //----------!!!!!-------开始调用dpif_recv--->dpif_netlink_recv-->epoll-->nl_sock_recv-->parse_odp_packet ofpbuf_uninit(recv_buf); break; } // VLOG_INFO("--------ack info---%d--%u--%u--",dack.ack_flag,dack.front_dpid,dack.packet_id); if(dack.ack_flag) { //处理发送数据给控制器 // VLOG_INFO("--------ack info---%u--%u--",dack.front_dpid,dack.packet_id); handle_ack_reply(dack.front_dpid,dack.hash_id,dack.packet_id,dack.type_id); //重点:回送ACK到控制器,后面单独分析 goto cleanup; } upcall->fitness = odp_flow_key_to_flow(dupcall->key, dupcall->key_len, flow); if (upcall->fitness == ODP_FIT_ERROR) { goto free_dupcall; } if (dupcall->mru) { mru = nl_attr_get_u16(dupcall->mru); } else { mru = 0; } error = upcall_receive(upcall, udpif->backer, &dupcall->packet, dupcall->type, dupcall->userdata, flow, mru, &dupcall->ufid, PMD_ID_NULL); if (error) { if (error == ENODEV) { /* Received packet on datapath port for which we couldn't * associate an ofproto. This can happen if a port is removed * while traffic is being received. Print a rate-limited * message in case it happens frequently. */ dpif_flow_put(udpif->dpif, DPIF_FP_CREATE, dupcall->key, dupcall->key_len, NULL, 0, NULL, 0, &dupcall->ufid, PMD_ID_NULL, NULL); VLOG_INFO_RL(&rl, "received packet on unassociated datapath " "port %"PRIu32, flow->in_port.odp_port); } goto free_dupcall; } upcall->key = dupcall->key; upcall->key_len = dupcall->key_len; upcall->ufid = &dupcall->ufid; upcall->out_tun_key = dupcall->out_tun_key; upcall->actions = dupcall->actions; pkt_metadata_from_flow(&dupcall->packet.md, flow); flow_extract(&dupcall->packet, flow); error = process_upcall(udpif, upcall, &upcall->odp_actions, &upcall->wc); if (error) { goto cleanup; } n_upcalls++; continue; cleanup: upcall_uninit(upcall); free_dupcall: dp_packet_uninit(&dupcall->packet); ofpbuf_uninit(recv_buf); } if (n_upcalls) { handle_upcalls(handler->udpif, upcalls, n_upcalls); //---------在dpif_netlink_recv之后调用handle_upcalls for (i = 0; i < n_upcalls; i++) { dp_packet_uninit(&dupcalls[i].packet); ofpbuf_uninit(&recv_bufs[i]); upcall_uninit(&upcalls[i]); } } return n_upcalls; }
2)修改dpif_recv方法,包括lib/dpif.h函数声明:
lib/dpif.h函数声明修改
int dpif_recv(struct dpif *, uint32_t handler_id, struct dpif_upcall *, struct ofpbuf *, struct dpif_ack *);
lib/dpif.c函数实现
int dpif_recv(struct dpif *dpif, uint32_t handler_id, struct dpif_upcall *upcall, struct ofpbuf *buf, struct dpif_ack *dack) { int error = EAGAIN; if (dpif->dpif_class->recv) { error = dpif->dpif_class->recv(dpif, handler_id, upcall, buf, dack); if (!error) { dpif_print_packet(dpif, upcall); } else if (error != EAGAIN) { log_operation(dpif, "recv", error); } } return error; }
该回调函数为dpif_netlink_recv,同时我们需要先修改dpif->dpif_class的回调指针,位于lib/dpif-provider.h下:
/* Datapath interface class structure, to be defined by each implementation of * a datapath interface. * * These functions return 0 if successful or a positive errno value on failure, * except where otherwise noted. * * These functions are expected to execute synchronously, that is, to block as * necessary to obtain a result. Thus, they may not return EAGAIN or * EWOULDBLOCK or EINPROGRESS. We may relax this requirement in the future if * and when we encounter performance problems. */ struct dpif_class { /* Type of dpif in this class, e.g. "system", "netdev", etc. * * One of the providers should supply a "system" type, since this is * the type assumed if no type is specified when opening a dpif. */ const char *type; /* Called when the dpif provider is registered, typically at program * startup. Returning an error from this function will prevent any * datapath with this class from being created. * * This function may be set to null if a datapath class needs no * initialization at registration time. */ int (*init)(void); /* Enumerates the names of all known created datapaths (of class * 'dpif_class'), if possible, into 'all_dps'. The caller has already * initialized 'all_dps' and other dpif classes might already have added * names to it. * * This is used by the vswitch at startup, so that it can delete any * datapaths that are not configured. * * Some kinds of datapaths might not be practically enumerable, in which * case this function may be a null pointer. */ int (*enumerate)(struct sset *all_dps, const struct dpif_class *dpif_class); /* Returns the type to pass to netdev_open() when a dpif of class * 'dpif_class' has a port of type 'type', for a few special cases * when a netdev type differs from a port type. For example, when * using the userspace datapath, a port of type "internal" needs to * be opened as "tap". * * Returns either 'type' itself or a string literal, which must not * be freed. */ const char *(*port_open_type)(const struct dpif_class *dpif_class, const char *type); /* Attempts to open an existing dpif called 'name', if 'create' is false, * or to open an existing dpif or create a new one, if 'create' is true. * * 'dpif_class' is the class of dpif to open. * * If successful, stores a pointer to the new dpif in '*dpifp', which must * have class 'dpif_class'. On failure there are no requirements on what * is stored in '*dpifp'. */ int (*open)(const struct dpif_class *dpif_class, const char *name, bool create, struct dpif **dpifp); /* Closes 'dpif' and frees associated memory. */ void (*close)(struct dpif *dpif); /* Attempts to destroy the dpif underlying 'dpif'. * * If successful, 'dpif' will not be used again except as an argument for * the 'close' member function. */ int (*destroy)(struct dpif *dpif); /* Performs periodic work needed by 'dpif', if any is necessary. * Returns true if need to revalidate. */ bool (*run)(struct dpif *dpif); /* Arranges for poll_block() to wake up if the "run" member function needs * to be called for 'dpif'. */ void (*wait)(struct dpif *dpif); /* Retrieves statistics for 'dpif' into 'stats'. */ int (*get_stats)(const struct dpif *dpif, struct dpif_dp_stats *stats); /* Adds 'netdev' as a new port in 'dpif'. If '*port_no' is not * ODPP_NONE, attempts to use that as the port's port number. * * If port is successfully added, sets '*port_no' to the new port's * port number. Returns EBUSY if caller attempted to choose a port * number, and it was in use. */ int (*port_add)(struct dpif *dpif, struct netdev *netdev, odp_port_t *port_no); /* Removes port numbered 'port_no' from 'dpif'. */ int (*port_del)(struct dpif *dpif, odp_port_t port_no); /* Refreshes configuration of 'dpif's port. The implementation might * postpone applying the changes until run() is called. */ int (*port_set_config)(struct dpif *dpif, odp_port_t port_no, const struct smap *cfg); /* Queries 'dpif' for a port with the given 'port_no' or 'devname'. * If 'port' is not null, stores information about the port into * '*port' if successful. * * If the port doesn't exist, the provider must return ENODEV. Other * error numbers means that something wrong happened and will be * treated differently by upper layers. * * If 'port' is not null, the caller takes ownership of data in * 'port' and must free it with dpif_port_destroy() when it is no * longer needed. */ int (*port_query_by_number)(const struct dpif *dpif, odp_port_t port_no, struct dpif_port *port); int (*port_query_by_name)(const struct dpif *dpif, const char *devname, struct dpif_port *port); /* Returns the Netlink PID value to supply in OVS_ACTION_ATTR_USERSPACE * actions as the OVS_USERSPACE_ATTR_PID attribute's value, for use in * flows whose packets arrived on port 'port_no'. * * A 'port_no' of UINT32_MAX should be treated as a special case. The * implementation should return a reserved PID, not allocated to any port, * that the client may use for special purposes. * * The return value only needs to be meaningful when DPIF_UC_ACTION has * been enabled in the 'dpif''s listen mask, and it is allowed to change * when DPIF_UC_ACTION is disabled and then re-enabled. * * A dpif provider that doesn't have meaningful Netlink PIDs can use NULL * for this function. This is equivalent to always returning 0. */ uint32_t (*port_get_pid)(const struct dpif *dpif, odp_port_t port_no); /* Attempts to begin dumping the ports in a dpif. On success, returns 0 * and initializes '*statep' with any data needed for iteration. On * failure, returns a positive errno value. */ int (*port_dump_start)(const struct dpif *dpif, void **statep); /* Attempts to retrieve another port from 'dpif' for 'state', which was * initialized by a successful call to the 'port_dump_start' function for * 'dpif'. On success, stores a new dpif_port into 'port' and returns 0. * Returns EOF if the end of the port table has been reached, or a positive * errno value on error. This function will not be called again once it * returns nonzero once for a given iteration (but the 'port_dump_done' * function will be called afterward). * * The dpif provider retains ownership of the data stored in 'port'. It * must remain valid until at least the next call to 'port_dump_next' or * 'port_dump_done' for 'state'. */ int (*port_dump_next)(const struct dpif *dpif, void *state, struct dpif_port *port); /* Releases resources from 'dpif' for 'state', which was initialized by a * successful call to the 'port_dump_start' function for 'dpif'. */ int (*port_dump_done)(const struct dpif *dpif, void *state); /* Polls for changes in the set of ports in 'dpif'. If the set of ports in * 'dpif' has changed, then this function should do one of the * following: * * - Preferably: store the name of the device that was added to or deleted * from 'dpif' in '*devnamep' and return 0. The caller is responsible * for freeing '*devnamep' (with free()) when it no longer needs it. * * - Alternatively: return ENOBUFS, without indicating the device that was * added or deleted. * * Occasional 'false positives', in which the function returns 0 while * indicating a device that was not actually added or deleted or returns * ENOBUFS without any change, are acceptable. * * If the set of ports in 'dpif' has not changed, returns EAGAIN. May also * return other positive errno values to indicate that something has gone * wrong. */ int (*port_poll)(const struct dpif *dpif, char **devnamep); /* Arranges for the poll loop to wake up when 'port_poll' will return a * value other than EAGAIN. */ void (*port_poll_wait)(const struct dpif *dpif); /* Deletes all flows from 'dpif' and clears all of its queues of received * packets. */ int (*flow_flush)(struct dpif *dpif); /* Flow dumping interface. * * This is the back-end for the flow dumping interface described in * dpif.h. Please read the comments there first, because this code * closely follows it. * * 'flow_dump_create' and 'flow_dump_thread_create' must always return an * initialized and usable data structure and defer error return until * flow_dump_destroy(). This hasn't been a problem for the dpifs that * exist so far. * * 'flow_dump_create' and 'flow_dump_thread_create' must initialize the * structures that they return with dpif_flow_dump_init() and * dpif_flow_dump_thread_init(), respectively. * * If 'terse' is true, then only UID and statistics will * be returned in the dump. Otherwise, all fields will be returned. * * If 'types' isn't null, dumps only the flows of the passed types. */ struct dpif_flow_dump *(*flow_dump_create)( const struct dpif *dpif, bool terse, struct dpif_flow_dump_types *types); int (*flow_dump_destroy)(struct dpif_flow_dump *dump); struct dpif_flow_dump_thread *(*flow_dump_thread_create)( struct dpif_flow_dump *dump); void (*flow_dump_thread_destroy)(struct dpif_flow_dump_thread *thread); int (*flow_dump_next)(struct dpif_flow_dump_thread *thread, struct dpif_flow *flows, int max_flows); /* Executes each of the 'n_ops' operations in 'ops' on 'dpif', in the order * in which they are specified, placing each operation's results in the * "output" members documented in comments and the 'error' member of each * dpif_op. The offload_type argument tells the provider if 'ops' should * be submitted to to a netdev (only offload) or to the kernel datapath * (never offload) or to both (offload if possible; software fallback). */ void (*operate)(struct dpif *dpif, struct dpif_op **ops, size_t n_ops, enum dpif_offload_type offload_type); /* Enables or disables receiving packets with dpif_recv() for 'dpif'. * Turning packet receive off and then back on is allowed to change Netlink * PID assignments (see ->port_get_pid()). The client is responsible for * updating flows as necessary if it does this. */ int (*recv_set)(struct dpif *dpif, bool enable); /* Refreshes the poll loops and Netlink sockets associated to each port, * when the number of upcall handlers (upcall receiving thread) is changed * to 'n_handlers' and receiving packets for 'dpif' is enabled by * recv_set(). * * Since multiple upcall handlers can read upcalls simultaneously from * 'dpif', each port can have multiple Netlink sockets, one per upcall * handler. So, handlers_set() is responsible for the following tasks: * * When receiving upcall is enabled, extends or creates the * configuration to support: * * - 'n_handlers' Netlink sockets for each port. * * - 'n_handlers' poll loops, one for each upcall handler. * * - registering the Netlink sockets for the same upcall handler to * the corresponding poll loop. * */ int (*handlers_set)(struct dpif *dpif, uint32_t n_handlers); /* Pass custom configuration options to the datapath. The implementation * might postpone applying the changes until run() is called. */ int (*set_config)(struct dpif *dpif, const struct smap *other_config); /* Translates OpenFlow queue ID 'queue_id' (in host byte order) into a * priority value used for setting packet priority. */ int (*queue_to_priority)(const struct dpif *dpif, uint32_t queue_id, uint32_t *priority); /* Polls for an upcall from 'dpif' for an upcall handler. Since there * can be multiple poll loops (see ->handlers_set()), 'handler_id' is * needed as index to identify the corresponding poll loop. If * successful, stores the upcall into '*upcall', using 'buf' for * storage. Should only be called if 'recv_set' has been used to enable * receiving packets from 'dpif'. * * The implementation should point 'upcall->key' and 'upcall->userdata' * (if any) into data in the caller-provided 'buf'. The implementation may * also use 'buf' for storing the data of 'upcall->packet'. If necessary * to make room, the implementation may reallocate the data in 'buf'. * * The caller owns the data of 'upcall->packet' and may modify it. If * packet's headroom is exhausted as it is manipulated, 'upcall->packet' * will be reallocated. This requires the data of 'upcall->packet' to be * released with ofpbuf_uninit() before 'upcall' is destroyed. However, * when an error is returned, the 'upcall->packet' may be uninitialized * and should not be released. * * This function must not block. If no upcall is pending when it is * called, it should return EAGAIN without blocking. */ int (*recv)(struct dpif *dpif, uint32_t handler_id, struct dpif_upcall *upcall, struct ofpbuf *buf, struct dpif_ack *dack); /* Arranges for the poll loop for an upcall handler to wake up when 'dpif' * has a message queued to be received with the recv member functions. * Since there can be multiple poll loops (see ->handlers_set()), * 'handler_id' is needed as index to identify the corresponding poll loop. * */ void (*recv_wait)(struct dpif *dpif, uint32_t handler_id); /* Throws away any queued upcalls that 'dpif' currently has ready to * return. */ void (*recv_purge)(struct dpif *dpif); /* When 'dpif' is about to purge the datapath, the higher layer may want * to be notified so that it could try reacting accordingly (e.g. grabbing * all flow stats before they are gone). * * Registers an upcall callback function with 'dpif'. This is only used * if 'dpif' needs to notify the purging of datapath. 'aux' is passed to * the callback on invocation. */ void (*register_dp_purge_cb)(struct dpif *, dp_purge_callback *, void *aux); /* For datapaths that run in userspace (i.e. dpif-netdev), threads polling * for incoming packets can directly call upcall functions instead of * offloading packet processing to separate handler threads. Datapaths * that directly call upcall functions should use the functions below to * to register an upcall function and enable / disable upcalls. * * Registers an upcall callback function with 'dpif'. This is only used * if 'dpif' directly executes upcall functions. 'aux' is passed to the * callback on invocation. */ void (*register_upcall_cb)(struct dpif *, upcall_callback *, void *aux); /* Enables upcalls if 'dpif' directly executes upcall functions. */ void (*enable_upcall)(struct dpif *); /* Disables upcalls if 'dpif' directly executes upcall functions. */ void (*disable_upcall)(struct dpif *); /* Get datapath version. Caller is responsible for freeing the string * returned. */ char *(*get_datapath_version)(void); /* Conntrack entry dumping interface. * * These functions are used by ct-dpif.c to provide a datapath-agnostic * dumping interface to the connection trackers provided by the * datapaths. * * ct_dump_start() should put in '*state' a pointer to a newly allocated * stucture that will be passed by the caller to ct_dump_next() and * ct_dump_done(). If 'zone' is not NULL, only the entries in '*zone' * should be dumped. * * ct_dump_next() should fill 'entry' with information from a connection * and prepare to dump the next one on a subsequest invocation. * * ct_dump_done() should perform any cleanup necessary (including * deallocating the 'state' structure, if applicable). */ int (*ct_dump_start)(struct dpif *, struct ct_dpif_dump_state **state, const uint16_t *zone, int *); int (*ct_dump_next)(struct dpif *, struct ct_dpif_dump_state *state, struct ct_dpif_entry *entry); int (*ct_dump_done)(struct dpif *, struct ct_dpif_dump_state *state); /* Flushes the connection tracking tables. The arguments have the * following behavior: * * - If both 'zone' and 'tuple' are NULL, flush all the conntrack * entries. * - If 'zone' is not NULL, and 'tuple' is NULL, flush all the * conntrack entries in '*zone'. * - If 'tuple' is not NULL, flush the conntrack entry specified by * 'tuple' in '*zone'. If 'zone' is NULL, use the default zone * (zone 0). */ int (*ct_flush)(struct dpif *, const uint16_t *zone, const struct ct_dpif_tuple *tuple); /* Set max connections allowed. */ int (*ct_set_maxconns)(struct dpif *, uint32_t maxconns); /* Get max connections allowed. */ int (*ct_get_maxconns)(struct dpif *, uint32_t *maxconns); /* Get number of connections tracked. */ int (*ct_get_nconns)(struct dpif *, uint32_t *nconns); /* Connection tracking per zone limit */ /* Per zone conntrack limit sets the maximum allowed connections in zones * to provide resource isolation. If a per zone limit for a particular * zone is not available in the datapath, it defaults to the default * per zone limit. Initially, the default per zone limit is * unlimited (0). */ /* Sets the max connections allowed per zone according to 'zone_limits', * a list of 'struct ct_dpif_zone_limit' entries (the 'count' member * is not used when setting limits). If 'default_limit' is not NULL, * modifies the default limit to '*default_limit'. */ int (*ct_set_limits)(struct dpif *, const uint32_t *default_limit, const struct ovs_list *zone_limits); /* Looks up the default per zone limit and stores that in * 'default_limit'. Look up the per zone limits for all zones in * the 'zone_limits_in' list of 'struct ct_dpif_zone_limit' entries * (the 'limit' and 'count' members are not used), and stores the * reply that includes the zone, the per zone limit, and the number * of connections in the zone into 'zone_limits_out' list. */ int (*ct_get_limits)(struct dpif *, uint32_t *default_limit, const struct ovs_list *zone_limits_in, struct ovs_list *zone_limits_out); /* Deletes per zone limit of all zones specified in 'zone_limits', a * list of 'struct ct_dpif_zone_limit' entries. */ int (*ct_del_limits)(struct dpif *, const struct ovs_list *zone_limits); /* Meters */ /* Queries 'dpif' for supported meter features. * NULL pointer means no meter features are supported. */ void (*meter_get_features)(const struct dpif *, struct ofputil_meter_features *); /* Adds or modifies the meter in 'dpif' with the given 'meter_id' * and the configuration in 'config'. * * The meter id specified through 'config->meter_id' is ignored. */ int (*meter_set)(struct dpif *, ofproto_meter_id meter_id, struct ofputil_meter_config *); /* Queries 'dpif' for meter stats with the given 'meter_id'. Stores * maximum of 'n_bands' meter statistics, returning the number of band * stats returned in 'stats->n_bands' if successful. */ int (*meter_get)(const struct dpif *, ofproto_meter_id meter_id, struct ofputil_meter_stats *, uint16_t n_bands); /* Removes meter 'meter_id' from 'dpif'. Stores meter and band statistics * (for maximum of 'n_bands', returning the number of band stats returned * in 'stats->n_bands' if successful. 'stats' may be passed in as NULL if * no stats are needed, in which case 'n_bands' must be passed in as * zero. */ int (*meter_del)(struct dpif *, ofproto_meter_id meter_id, struct ofputil_meter_stats *, uint16_t n_bands); };
3)修改dpif_netlink_recv方法与dpif_netlink_recv__方法:位于lib/dpif-netlink.c下
static int dpif_netlink_recv__(struct dpif_netlink *dpif, uint32_t handler_id, struct dpif_upcall *upcall, struct ofpbuf *buf, struct dpif_ack *dack) OVS_REQ_RDLOCK(dpif->upcall_lock) { struct dpif_handler *handler; int read_tries = 0; if (!dpif->handlers || handler_id >= dpif->n_handlers) { return EAGAIN; } handler = &dpif->handlers[handler_id]; if (handler->event_offset >= handler->n_events) { int retval; handler->event_offset = handler->n_events = 0; do { retval = epoll_wait(handler->epoll_fd, handler->epoll_events, dpif->uc_array_size, 0); } while (retval < 0 && errno == EINTR); if (retval < 0) { static struct vlog_rate_limit rl = VLOG_RATE_LIMIT_INIT(1, 1); VLOG_WARN_RL(&rl, "epoll_wait failed (%s)", ovs_strerror(errno)); } else if (retval > 0) { handler->n_events = retval; } } while (handler->event_offset < handler->n_events) { int idx = handler->epoll_events[handler->event_offset].data.u32; struct dpif_channel *ch = &dpif->channels[idx]; handler->event_offset++; for (;;) { int dp_ifindex; int error; if (++read_tries > 50) { return EAGAIN; } //通过netlink接收数据 error = nl_sock_recv(ch->sock, buf, NULL, false); if (error == ENOBUFS) { /* ENOBUFS typically means that we've received so many * packets that the buffer overflowed. Try again * immediately because there's almost certainly a packet * waiting for us. */ report_loss(dpif, ch, idx, handler_id); continue; } ch->last_poll = time_msec(); if (error) { if (error == EAGAIN) { break; } return error; } //对数据进行解析 error = parse_odp_packet(dpif, buf, upcall, &dp_ifindex, dack); if (!error && dp_ifindex == dpif->dp_ifindex) { return 0; } else if (error) { return error; } } } return EAGAIN; } #endif static int dpif_netlink_recv(struct dpif *dpif_, uint32_t handler_id, struct dpif_upcall *upcall, struct ofpbuf *buf, struct dpif_ack *dack) { struct dpif_netlink *dpif = dpif_netlink_cast(dpif_); int error; fat_rwlock_rdlock(&dpif->upcall_lock); #ifdef _WIN32 error = dpif_netlink_recv_windows(dpif, handler_id, upcall, buf); #else error = dpif_netlink_recv__(dpif, handler_id, upcall, buf, dack); #endif fat_rwlock_unlock(&dpif->upcall_lock); return error; }
4)修改parse_odp_packet方法,实现对OVS_PACKET_CMD_ACK的解析,位于lib/dpif-netlink.c
static int parse_odp_packet(const struct dpif_netlink *dpif, struct ofpbuf *buf, struct dpif_upcall *upcall, int *dp_ifindex, struct dpif_ack *dack) { static const struct nl_policy ovs_packet_policy[] = { /* Always present. 由于ack不需要,所以修改了,添加上.optional*/ [OVS_PACKET_ATTR_PACKET] = { .type = NL_A_UNSPEC, .min_len = ETH_HEADER_LEN, .optional = true }, [OVS_PACKET_ATTR_KEY] = { .type = NL_A_NESTED, .optional = true}, /* OVS_PACKET_CMD_ACTION only. */ [OVS_PACKET_ATTR_USERDATA] = { .type = NL_A_UNSPEC, .optional = true }, [OVS_PACKET_ATTR_EGRESS_TUN_KEY] = { .type = NL_A_NESTED, .optional = true }, [OVS_PACKET_ATTR_ACTIONS] = { .type = NL_A_NESTED, .optional = true }, [OVS_PACKET_ATTR_MRU] = { .type = NL_A_U16, .optional = true }, /* OVS_PACKET_CMD_ACK only. */ [OVS_PACKET_ATTR_FD] = {.type = NL_A_U8, .optional = true }, [OVS_PACKET_ATTR_HASH_ID] = {.type = NL_A_U8, .optional = true }, [OVS_PACKET_ATTR_TYPE_ID] = {.type = NL_A_U8, .optional = true }, [OVS_PACKET_ATTR_ACK] = {.type = NL_A_U32, .optional = true } }; struct ofpbuf b = ofpbuf_const_initializer(buf->data, buf->size); struct nlmsghdr *nlmsg = ofpbuf_try_pull(&b, sizeof *nlmsg); struct genlmsghdr *genl = ofpbuf_try_pull(&b, sizeof *genl); int i; struct ovs_header *ovs_header = ofpbuf_try_pull(&b, sizeof *ovs_header); struct nlattr *a[ARRAY_SIZE(ovs_packet_policy)]; if (!nlmsg || !genl || !ovs_header || nlmsg->nlmsg_type != ovs_packet_family || !nl_policy_parse(&b, 0, ovs_packet_policy, a, ARRAY_SIZE(ovs_packet_policy))) { return EINVAL; } // VLOG_INFO("-----------parse_odp_packet------------"); if (genl->cmd == OVS_PACKET_CMD_ACK) { //-----parse ack info----- struct nlattr *fd_nla = a[OVS_PACKET_ATTR_FD]; struct nlattr *hashid_nla = a[OVS_PACKET_ATTR_HASH_ID]; struct nlattr *typeid_nla = a[OVS_PACKET_ATTR_TYPE_ID]; struct nlattr *pid_nla = a[OVS_PACKET_ATTR_ACK]; uint8_t frontDpid = *(uint8_t *)NLA_DATA(fd_nla); uint8_t hashId = *(uint8_t *)NLA_DATA(hashid_nla); uint8_t typeId = *(uint8_t *)NLA_DATA(typeid_nla); uint32_t packetId = *(uint32_t *)NLA_DATA(pid_nla); // VLOG_INFO("------------ovs_packet_cmd_ack--------devid:-%u--------------hashId:%u------pktid:-%u------------typeid:%u-----\n", // frontDpid,hashId,packetId,typeId); dack->ack_flag = 1; dack->front_dpid = frontDpid; dack->packet_id = packetId; dack->hash_id = hashId; dack->type_id = typeId; *dp_ifindex = ovs_header->dp_ifindex; //注意,这里需要提前获取dp_ifindex,在dpif_netlink_recv__中会进行判断的 return 0; } int type = (genl->cmd == OVS_PACKET_CMD_MISS ? DPIF_UC_MISS : genl->cmd == OVS_PACKET_CMD_ACTION ? DPIF_UC_ACTION : -1); if (type < 0) { return EINVAL; } /* (Re)set ALL fields of '*upcall' on successful return. */ upcall->type = type; upcall->key = CONST_CAST(struct nlattr *, nl_attr_get(a[OVS_PACKET_ATTR_KEY])); upcall->key_len = nl_attr_get_size(a[OVS_PACKET_ATTR_KEY]); dpif_flow_hash(&dpif->dpif, upcall->key, upcall->key_len, &upcall->ufid); upcall->userdata = a[OVS_PACKET_ATTR_USERDATA]; upcall->out_tun_key = a[OVS_PACKET_ATTR_EGRESS_TUN_KEY]; upcall->actions = a[OVS_PACKET_ATTR_ACTIONS]; upcall->mru = a[OVS_PACKET_ATTR_MRU]; /* Allow overwriting the netlink attribute header without reallocating. */ dp_packet_use_stub(&upcall->packet, CONST_CAST(struct nlattr *, nl_attr_get(a[OVS_PACKET_ATTR_PACKET])) - 1, nl_attr_get_size(a[OVS_PACKET_ATTR_PACKET]) + sizeof(struct nlattr)); dp_packet_set_data(&upcall->packet, (char *)dp_packet_data(&upcall->packet) + sizeof(struct nlattr)); dp_packet_set_size(&upcall->packet, nl_attr_get_size(a[OVS_PACKET_ATTR_PACKET])); if (nl_attr_find__(upcall->key, upcall->key_len, OVS_KEY_ATTR_ETHERNET)) { /* Ethernet frame */ upcall->packet.packet_type = htonl(PT_ETH); } else { /* Non-Ethernet packet. Get the Ethertype from the NL attributes */ ovs_be16 ethertype = 0; const struct nlattr *et_nla = nl_attr_find__(upcall->key, upcall->key_len, OVS_KEY_ATTR_ETHERTYPE); if (et_nla) { ethertype = nl_attr_get_be16(et_nla); } upcall->packet.packet_type = PACKET_TYPE_BE(OFPHTN_ETHERTYPE, ntohs(ethertype)); dp_packet_set_l3(&upcall->packet, dp_packet_data(&upcall->packet)); } *dp_ifindex = ovs_header->dp_ifindex; // VLOG_INFO("-----parse_odp_packet-----------dp_ifindex----%d\n",*dp_ifindex); return 0; }
至此,用户态获取了内核上传的ACK信息,下面将三(二)3Ⅱ1)中的handle_ack_reply
方法进行解析,看如何实现发送至控制器
4.用户态上传ACK到控制器中,通过handle_ack_reply方法
Ⅰ.在ofproto/ofproto.h中进行声明
int handle_ack_reply(uint8_t front_dpid,uint8_t hash_id, uint32_t packet_id, uint8_t type_id);
Ⅱ.在ofproto/ofproto.c中进行实现,通过封装数据到ofpbuf中,通过ovs内部方法ofconn_send_reply实现上传数据到控制器,控制器按照格式进行解析即可
//上传ack机制需要的数据给控制器 int handle_ack_reply(uint8_t front_dpid,uint8_t hash_id, uint32_t packet_id, uint8_t type_id) { if(!ack_ofconn) return OFPERR_OFPAFC_BAD_CONN; // VLOG_INFO("--------handle_ack_reply----------"); // if(!ack_oh) // return OFPERR_OFPAFC_BAD_OHREQ; // struct ofpbuf *reply = ofpraw_alloc_reply(OFPRAW_OFPT_ACK_REPLY, // ack_oh, rq_buf.size+sizeof(tv)); // char test[10] = "66666"; struct ofpbuf *reply = ofpraw_alloc_xid(OFPRAW_OFPT_ACK_REPLY,OFP13_VERSION,htonl(0),32*sizeof(char)); void *dst = ofpbuf_put_uninit(reply, sizeof(uint8_t) + sizeof(uint8_t) + sizeof(uint32_t) + sizeof(uint8_t)); // uint32_t net_packet_id = htonl(packet_id); //封装数据 memcpy(dst,&front_dpid,sizeof(uint8_t)); //1 byte, not need htonl memcpy(dst+sizeof(uint8_t),&hash_id,sizeof(uint8_t)); //1 byte, not need htonl memcpy(dst+sizeof(uint8_t)+sizeof(uint8_t),&packet_id,sizeof(uint32_t)); memcpy(dst+sizeof(uint8_t)+sizeof(uint8_t)+sizeof(uint32_t),&type_id,sizeof(uint8_t)); //1 byte, not need htonl ofconn_send_reply(ack_ofconn,reply); return 0; }
Ⅲ.补充,不同于其它上传方法,如handle_features_request(struct ofconn *ofconn, const struct ofp_header *oh),我们的传参中不包含ofconn信息,所以本文设计了全局变量ack_ofconn保存ofconn信息
1)在ofproto/ofproto.c中声明全局变量
//保存ack机制需要的全局变量 int ack_init = 0; struct ofconn *ack_ofconn = NULL; struct ofp_header *ack_oh = NULL;
其中ack_oh在前文的handle_ack_request中被赋值,其实该变量在ACK机制中无用,不用管;ack_init同样不需要管,直接=1即可。
2)ack_ofconn变量的赋值,在handle_openflow中被赋值
static void handle_openflow(struct ofconn *ofconn, const struct ovs_list *msgs) OVS_EXCLUDED(ofproto_mutex) { if(!ack_ofconn || ack_ofconn != ofconn) { ack_ofconn = ofconn; } COVERAGE_INC(ofproto_recv_openflow); //VLOG_INFO("-------------handle_openflow-------------"); struct ofpbuf *msg = ofpbuf_from_list(ovs_list_front(msgs)); //VLOG_INFO("-------------handle_openflow------1-------"); enum ofptype type; enum ofperr error = ofptype_decode(&type, msg->data); //VLOG_INFO("-------------handle_openflow------2-------"); if (!error) { //VLOG_INFO("-------------handle_openflow------3-------"); if (type == OFPTYPE_TABLE_FEATURES_STATS_REQUEST) { handle_table_features_request(ofconn, msgs); } else if (type == OFPTYPE_FLOW_MONITOR_STATS_REQUEST) { handle_flow_monitor_request(ofconn, msgs); } else if (!ovs_list_is_short(msgs)) { error = OFPERR_OFPBRC_BAD_STAT; } else { error = handle_single_part_openflow(ofconn, msg->data, type); } } if (error) { ofconn_send_error(ofconn, msg->data, error); } }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号