Hadoop基础---MapReduce实现
一:MapReduce思想
(一)MapReduce解决的问题
1.如何实现将代码分发到集群中节点中,并且如何运行起来
2.将代码分发到哪些指定机器中运行
3.实时监控节点运行情况
4.结果如何汇总
总之:将我们简单的业务逻辑很方便的扩展到海量数据环境下的进行分布式运算
(二)MapReduce基本概念和程序编写逻辑
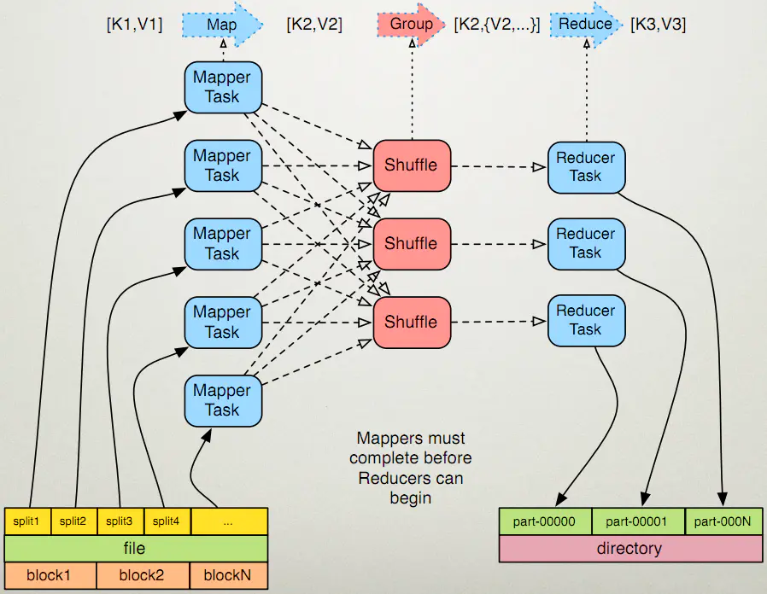
MapReduce的程序执行流程分为两个阶段:Mapper阶段和Reducer阶段
其中Mapper阶段包括:

1>指定输入文件的路径,并将输入文件在逻辑上切分成若干个split数据片。随后对输入切片按照一定的规则解析成键值对<k1,v1>,其中k1就是我们常说的起始偏移量,v1就是行文本的内容。 2>调用自己编写的map函数,将输入的键值对<k1,v1>转化成键值对<k2,v2>,其中每一个键值对<k1,v1>都会调用一次map函数。 3>对输出的键值对<k2,v2>进行分区、排序、分组,其中分组就是相同的key的value放到同一个集合当中。 4>(可选)对分组后的数据进行本地归并处理(combiner)。
其中Reducer阶段包括:
5>对多个Mapper任务的输出,按照不同的分区,通过网络拷贝到不同的Reducer节点上进行处理,随后对多个Mapper任务的输出进行合并,排序。 6>调用自己编写的reduce函数,将输入的键值对<k2,v2s>转化成键值对<k3,v3>
7>将Reducer任务的输出保存到指定的文件中。
二:WordCount程序实现
(一)map程序编写
package cn.hadoop.mr.wc; import java.io.IOException; import org.apache.commons.lang.StringUtils; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; //4个泛型中,前两个是指定mapper输入数据的类型,后两个是mapper输出结果数据的类型 //map和reduce的数据输入输出都是以<k,v>键值对的形式封装的 //默认情况下,mapper的数据输入中,key是要处理的文本中一行的起始偏移量,value则是该行的内容 public class WCMapper extends Mapper<LongWritable, Text, Text, LongWritable>{ @Override //自定义数据类型在网络编码中不会出现多余数据,提高网络传输效率。提高集群数据通信能力 protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, LongWritable>.Context context) throws IOException, InterruptedException { //获取这一行的内容 String lineval = value.toString(); //将这一行的文本按分隔符进行切分 String words[] = StringUtils.split(lineval, " "); //遍历数组,转换为输出模式的<k,v>形式 for(String word:words) { //输出数据写入上下文中 context.write(new Text(word), new LongWritable(1)); } //实际上不是写入一个<k,v>就发送给集群节点,而是将key相同的一类的数据遍历完成后,从缓存中发送出去 //结果传送形式是<k,<v1,v2,v3,...,vn>>,这里的实际形式是<k,<1,1,1,1,1,....,1>> } }
(二)Reduce程序编写
package cn.hadoop.mr.wc; import java.io.IOException; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; public class WCReducer extends Reducer<Text, LongWritable, Text, LongWritable>{ @Override protected void reduce(Text key, Iterable<LongWritable> values, Reducer<Text, LongWritable, Text, LongWritable>.Context context) throws IOException, InterruptedException { long count = 0; //遍历values,统计每个key出现的总次数 for(LongWritable value:values) { count+=value.get(); } //输出这一个单词的统计结果 context.write(key, new LongWritable(count)); } }
(三)生成job,将map和reduce提交给集群
package cn.hadoop.mr.wc; import java.io.IOException; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class WCRunner { public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { Configuration conf = new Configuration(); Job wcjob = Job.getInstance(conf); //设置整个job所用的那些类在那些jar包中 wcjob.setJarByClass(WCRunner.class); //设置job使用的mapper和reducer的类 wcjob.setMapperClass(WCMapper.class); wcjob.setReducerClass(WCReducer.class); //设置map和reduce的输出类 wcjob.setOutputKeyClass(Text.class); wcjob.setOutputValueClass(LongWritable.class); //这里可以单独设置map的输出数据k,v类型。如果和上面类型不同,则下面则有用 wcjob.setMapOutputKeyClass(Text.class); wcjob.setMapOutputValueClass(LongWritable.class); //指定要处理的输入数据存放的路径 FileInputFormat.setInputPaths(wcjob, new Path("/wc/input/")); //指定输出结构存放路径 FileOutputFormat.setOutputPath(wcjob, new Path("/wc/output")); //将job提交给集群运行 wcjob.waitForCompletion(true); //传参是:是否显示程序运行状态及进度 } }
(四)补充
要运行map和reduce程序,还需要导入share文件夹中的mapreduce文件夹下的jar包
(五)导出jar包
(六)实验测试
1.实验数据


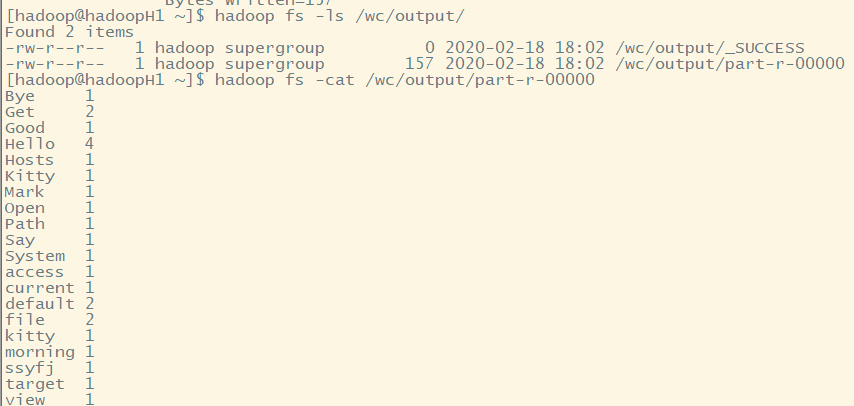
Hello kitty Hello Mark Bye Kitty Good morning Say Hello System Path Hosts file Open file Hello ssyfj Get access Get default
2.上传到hdfs系统中
创建文件输入目录
hadoop fs -mkdir -p /wc/input/
上传到文件输入目录
hadoop fs -put wcdata.txt /wc/input/
注意:不要创建结果输出目录,不然会报错
3.调用程序进行数据分析
hadoop jar wc.jar cn.hadoop.mr.wc.WCRunner
wc.jar是我们导出的jar包,cn.hadoop.mr.wc.WCRunner是我们运行的主类
4.查看结果
三:Hadoop本地测试
(一)在项目中引入hdfs、mapreduce、yarn的jar包(包括lib依赖库下的jar包)
(二)解决Exception in thread "main" java.lang.NullPointerException问题(下面两种方法)
1.在主类WCRunner的main方法中开头添加
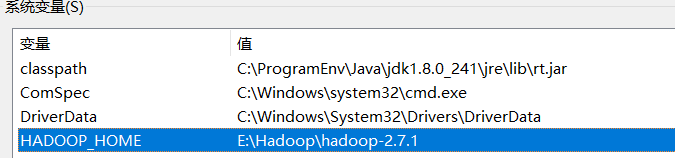
System.setProperty("hadoop.home.dir", "E:\\Hadoop\\hadoop-2.7.1");
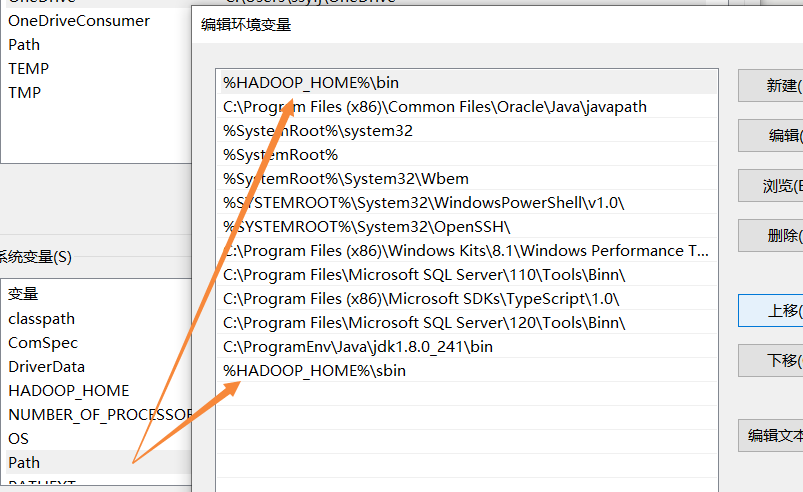
2.添加环境变量
(三)获取下列文件到Hadoop主目录下的bin目录下
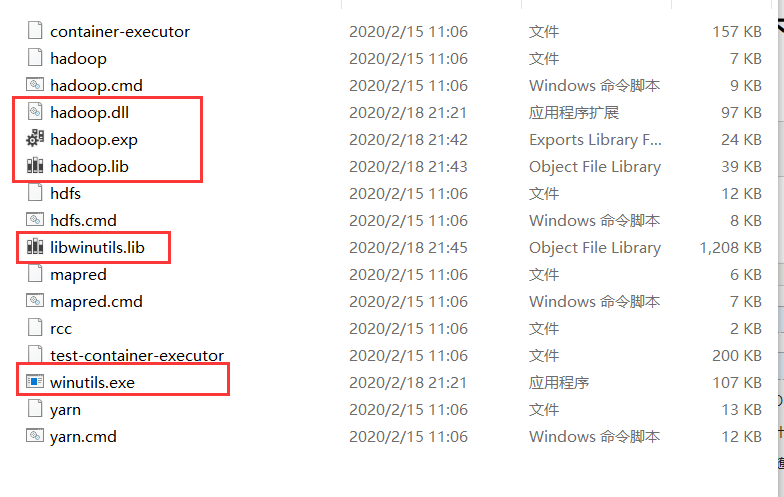
下载地址:https://github.com/steveloughran/winutils/tree/master/hadoop-2.7.1
(四)将该bin目录下的所有文件导入到C:\Windows\System32目录下
(五)结果查看

(六)解决Eclipse运行Hadoop,日志不显示问题
一般出现下面情况:然后不会出现MapReduce进度信息。
log4j:WARN No appenders could be found for logger (org.apache.hadoop.util.Shell). log4j:WARN Please initialize the log4j system properly. log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for more info.
这种情况一般是由于log4j这个日志信息打印模块的配置信息没有给出造成的,可以在项目的src目录下,新建一个文件,命名为“log4j.properties”,填入以下信息:
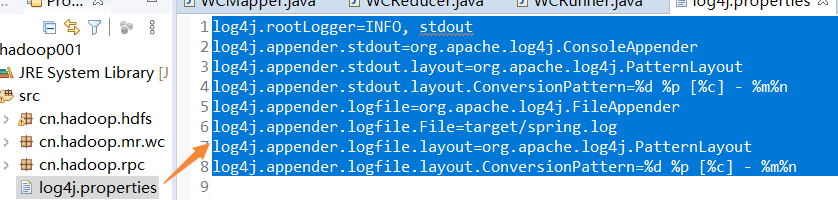
log4j.rootLogger=INFO, stdout log4j.appender.stdout=org.apache.log4j.ConsoleAppender log4j.appender.stdout.layout=org.apache.log4j.PatternLayout log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n log4j.appender.logfile=org.apache.log4j.FileAppender log4j.appender.logfile.File=target/spring.log log4j.appender.logfile.layout=org.apache.log4j.PatternLayout log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n

 浙公网安备 33010602011771号
浙公网安备 33010602011771号