

pro1:
安装最新的pip 软件
解决方法:右键点击以管理员身份运行
pip installl --upgrade pip
pro2: range()我想直接打印发现结果是:range()既不能返回dtype 又不能返回shape(),它的类型是对象

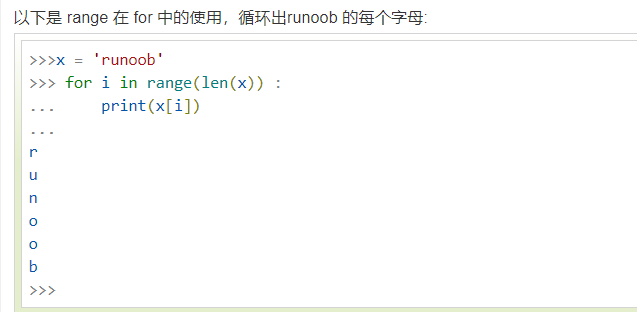
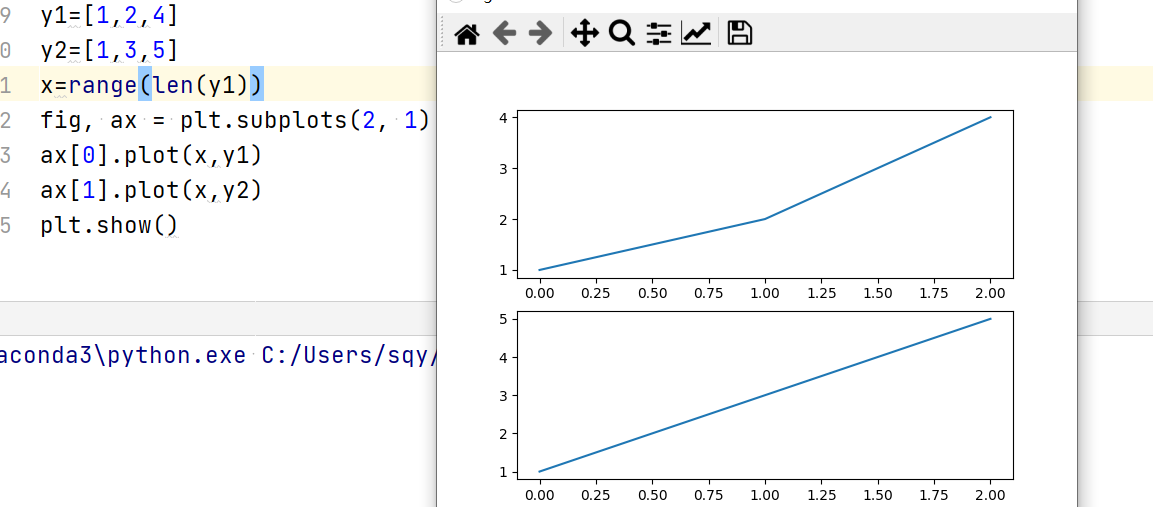
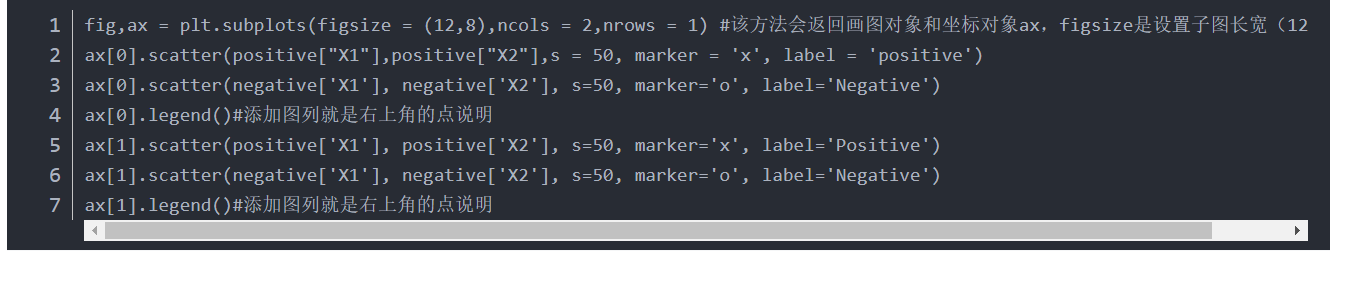
pro3:调用plt.subplot()时,ax可以用切片法分别在不同图中绘制
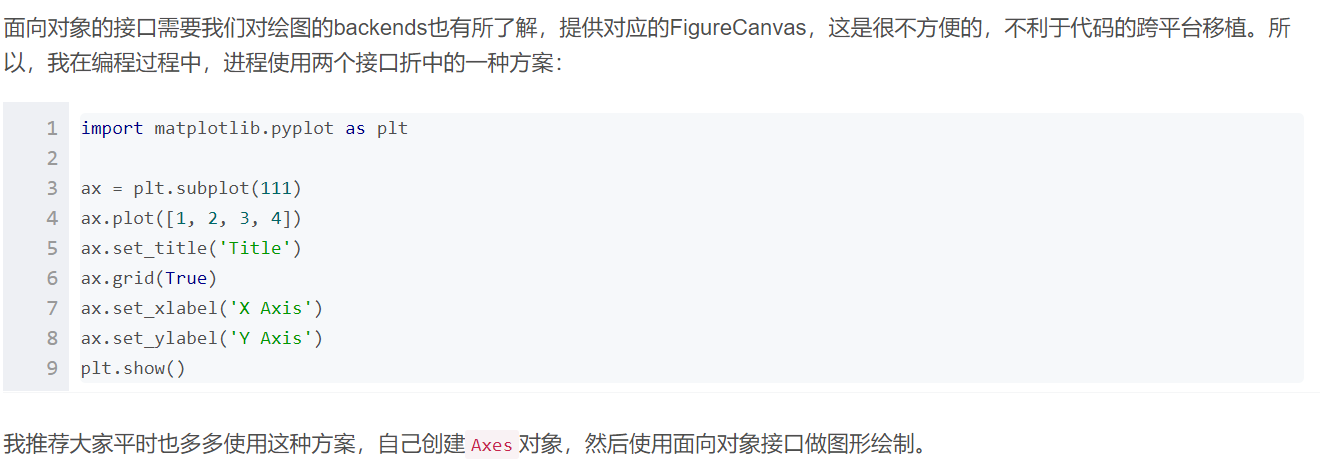
4.pro4:pyplot API和面对对象编程API:
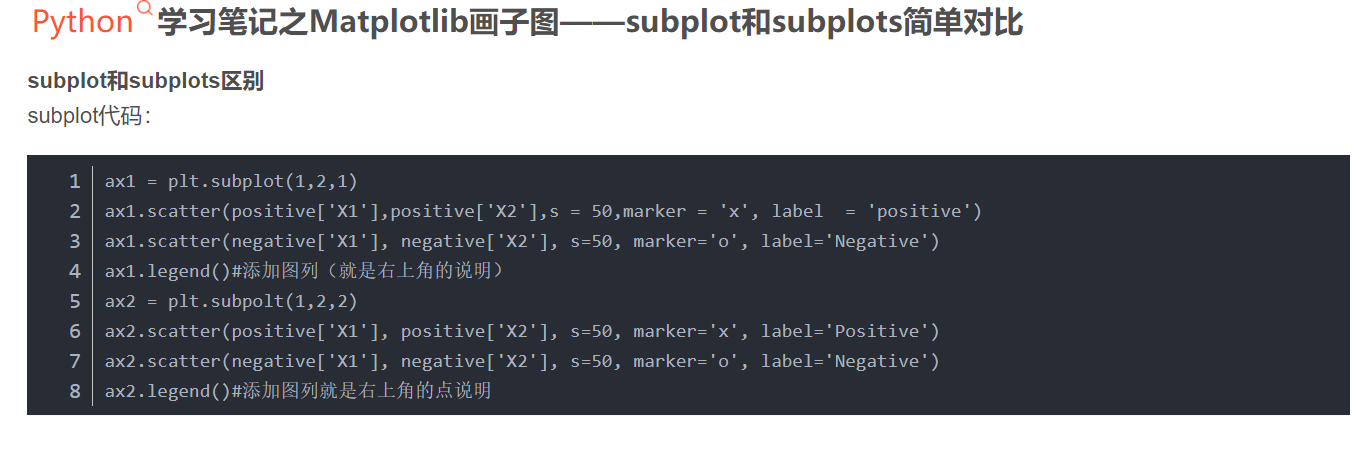
5.
fig,ax=plt.subplots(111) 报错
AxesSubplot‘ object has no property ‘figsize‘,原因是拼写错误,必须是subplots而不是subplot
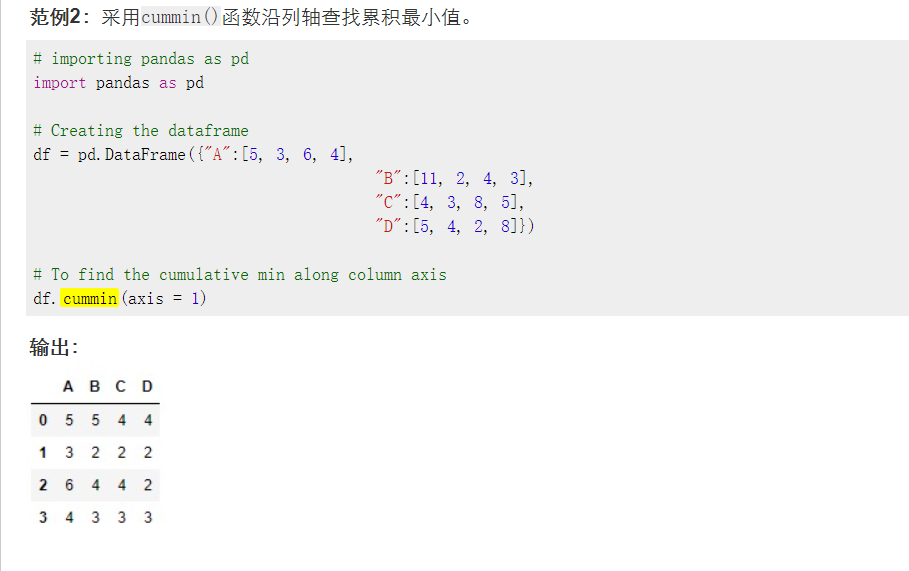
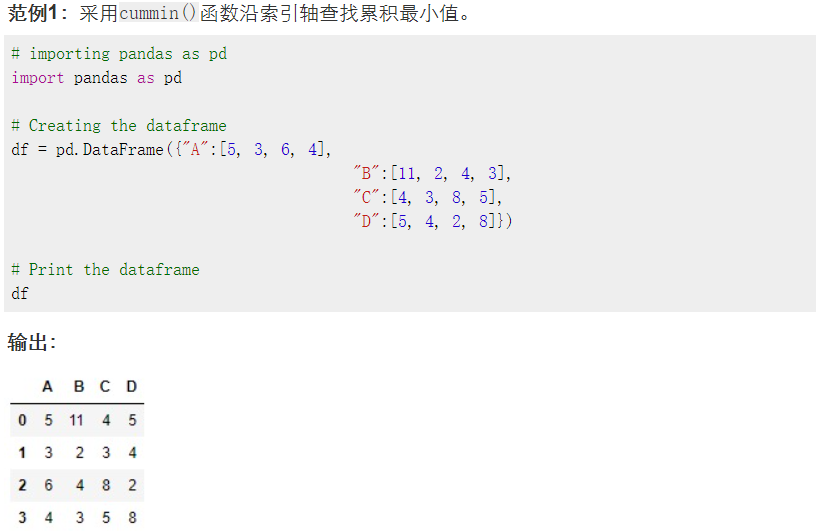
5.cummin()的使用:

axis=1 表示按column方向比较,axis=0表示按index方向比较
6.python 中shape函数
返回数据的长度shape[0]返回行数,shape[1]返回列数
7.matlab 中多行注释:
选中要注释的文本,按ctrl +r 进行多行注释
选中已经注释的文本,按ctrl+t取消多行注释
8.flat()函数在数组(ndarray)的用处


还有一种是array.tolist(),将数组转换成列表
使用flat不行,就尝试一下array.flatten()
9.在jupyter lab中如何合并和拆分单元格
q 
10.数组切片

11. 如何查看帮助文档?

12.什么是基类?


13.dataframe可以和二维数组进行转换
14.type()和dtype()和astype()的区别:
type()返回数据结构类型(list,dict,numpy,ndarray),用法为type(变量名)

dtype返回数据元素的类型(int,float),用法为 array.dtype
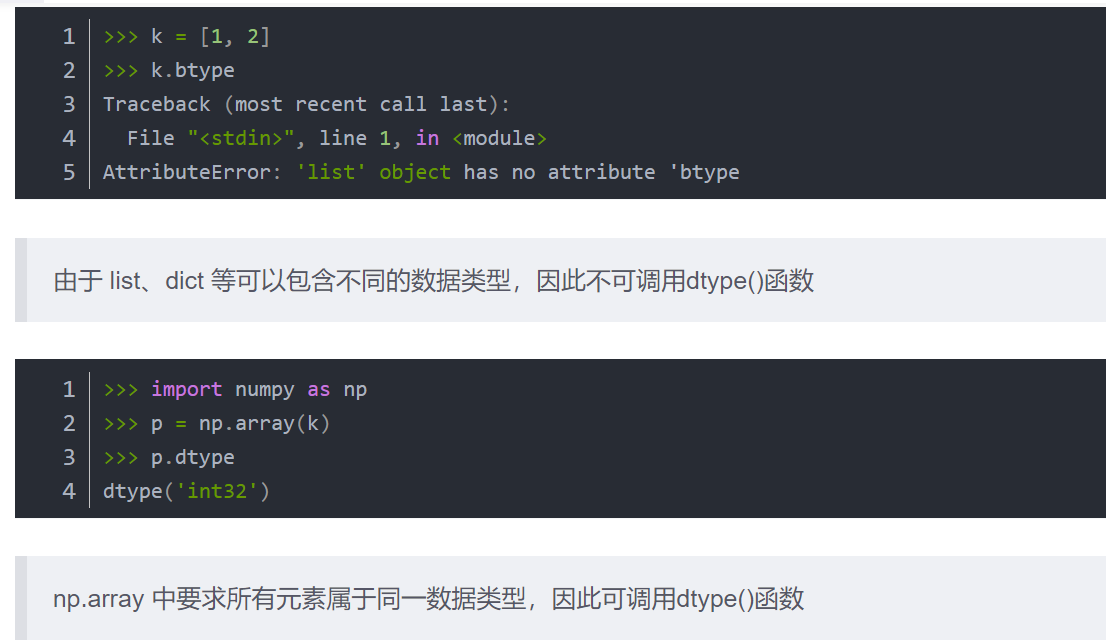
astype()用来改变np.array中所有数据元素的数据类型,用法为astype(int)/ astype(float)

15.shape官方python文档
shape : tuple of ints
The elements of the shape tuple give the lengths of the
corresponding array dimensions
一定是整数类型,返回的整型元组元素是相关的数组维度的长度
输入的参数是数组类型或者数组形式的列表

用法为:array.shape或者np.shape(array)

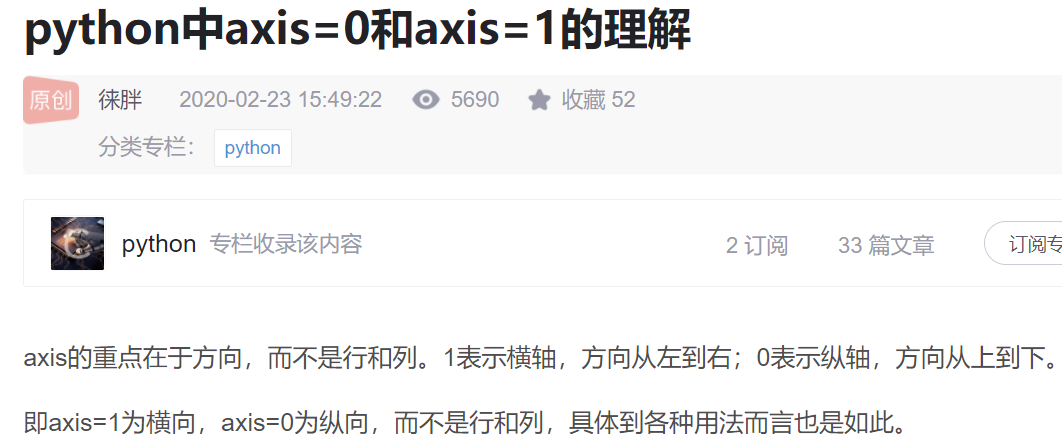
16.关于axis=0和axis=1的最终版理解
17. Python中的*args和**kwargs
在Python中的代码中经常会见到这两个词 args 和 kwargs,前面通常还会加上一个或者两个星号。其实这只是编程人员约定的变量名字,args 是 arguments 的缩写,表示位置参数;kwargs 是 keyword arguments 的缩写,表示关键字参数。这其实就是 Python 中可变参数的两种形式,并且 *args 必须放在 **kwargs 的前面,因为位置参数在关键字参数的前面
*args就是就是传递一个可变参数列表给函数实参,这个参数列表的数目未知
第一个参数是必须要传入的参数,所以使用了第一个形参,而后面三个参数则作为可变参数列表传入了实参,并且是作为元组tuple来使用的:
def test_args(first, *args):
print('Required argument: ', first)
print(type(args))
for v in args:
print ('Optional argument: ', v)
test_args(1, 2, 3, 4)
Required argument: 1 <class 'tuple'> Optional argument: 2 Optional argument: 3 Optional argument: 4
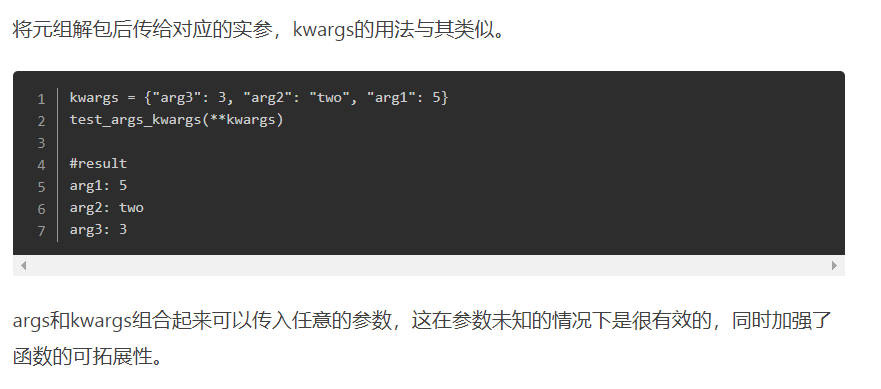
**kwargs
而**kwargs则是将一个可变的关键字参数的字典传给函数实参,同样参数列表长度可以为0或为其他值。下面这段代码演示了如何使用kwargs
def test_kwargs(first, *args, **kwargs): print('Required argument: ', first) print(type(kwargs)) for v in args: print ('Optional argument (args): ', v) for k, v in kwargs.items(): print ('Optional argument %s (kwargs): %s' % (k, v)) test_kwargs(1, 2, 3, 4, k1=5, k2=6)
正如前面所说的,args类型是一个tuple,而kwargs则是一个字典dict,并且args只能位于kwargs的前面。代码的运行结果如下
Required argument: 1
<class 'dict'>
Optional argument (args): 2
Optional argument (args): 3
Optional argument (args): 4
Optional argument k2 (kwargs): 6
Optional argument k1 (kwargs): 5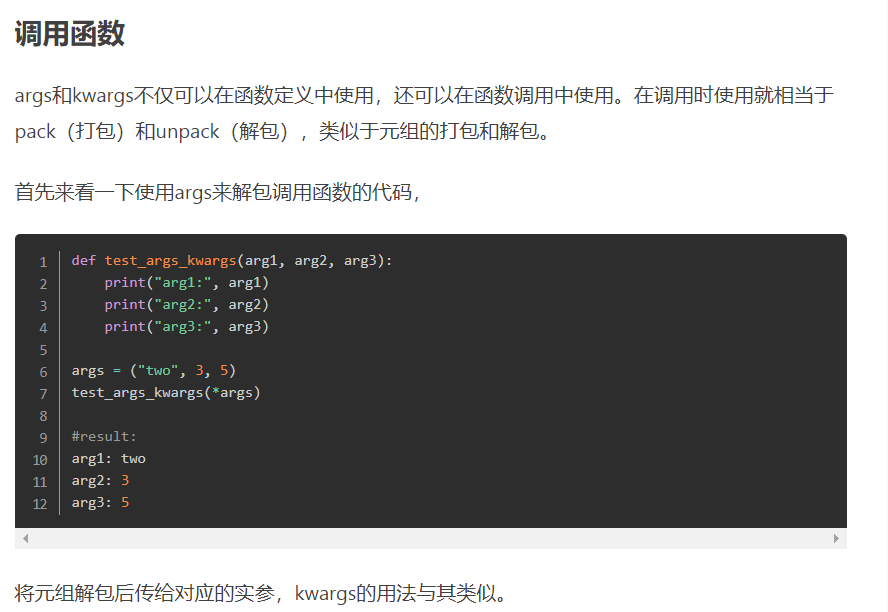
18.pandas 里的describe()函数是对每一列数据统计
data.describe() #对每一列数据进行统计,包括计数,均值,std,各个分位数等。
19.loc与iloc
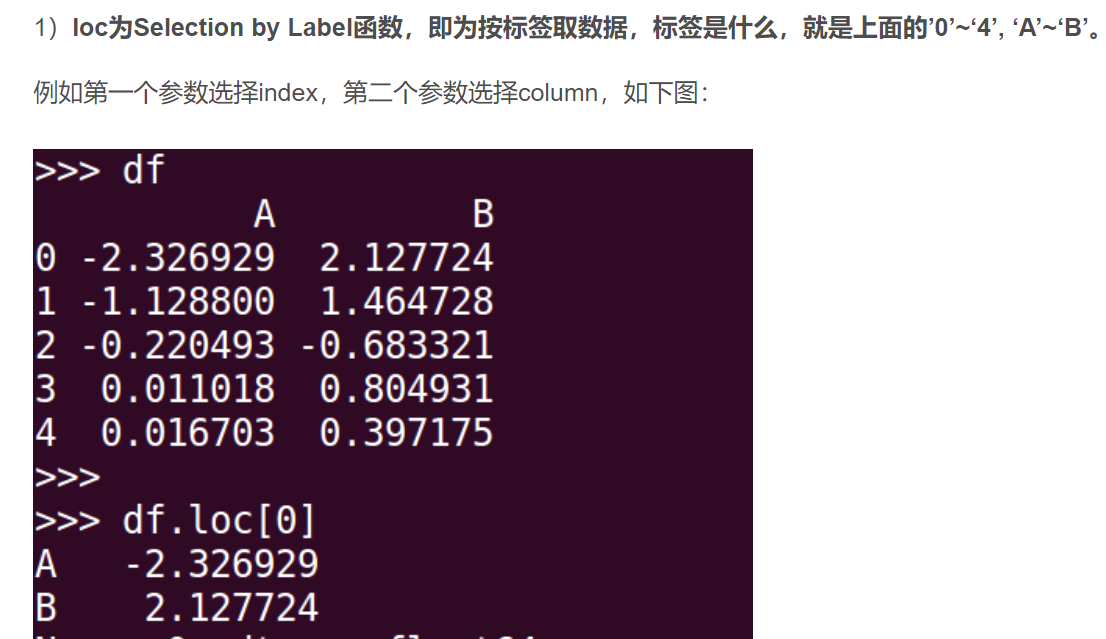
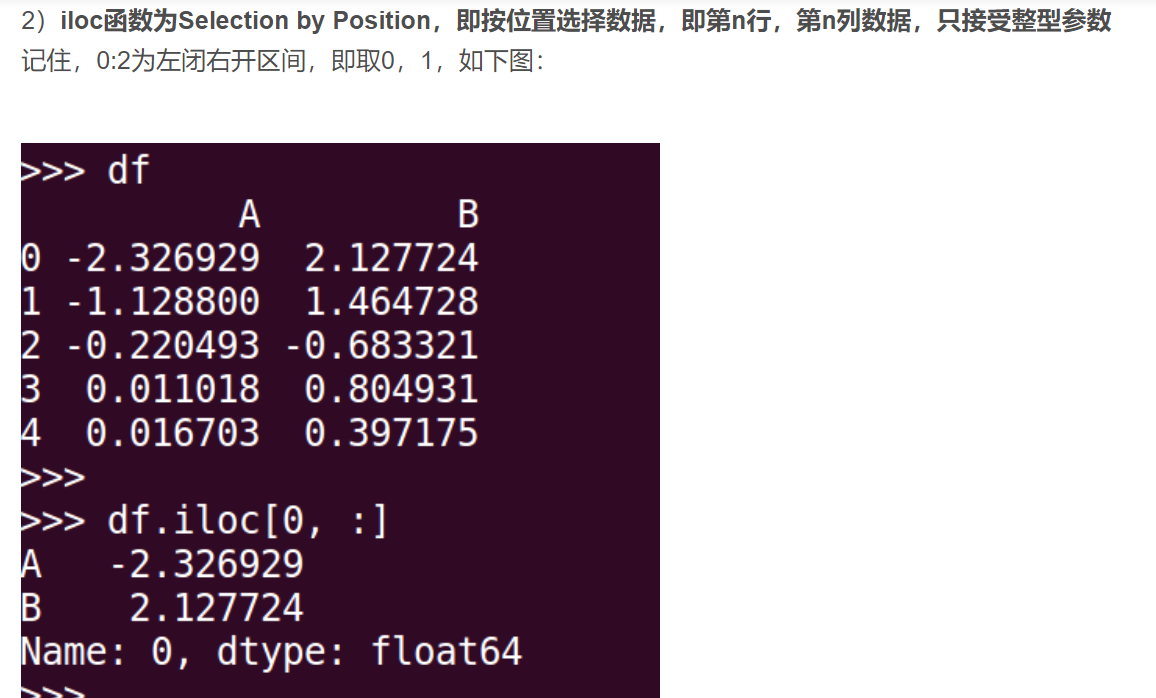
20.直接取出训练集中的列名

先将数组类型的数据转换为DataFrame,然后调用里面的属性columns和利用tolist()进行转换
21.
1.auc roc
AUC(area under the curve)是ROC曲线下的面积,所以,在理解AUC之前,要先了解ROC是什么。而ROC的计算又需要借助混淆矩阵
混淆矩阵
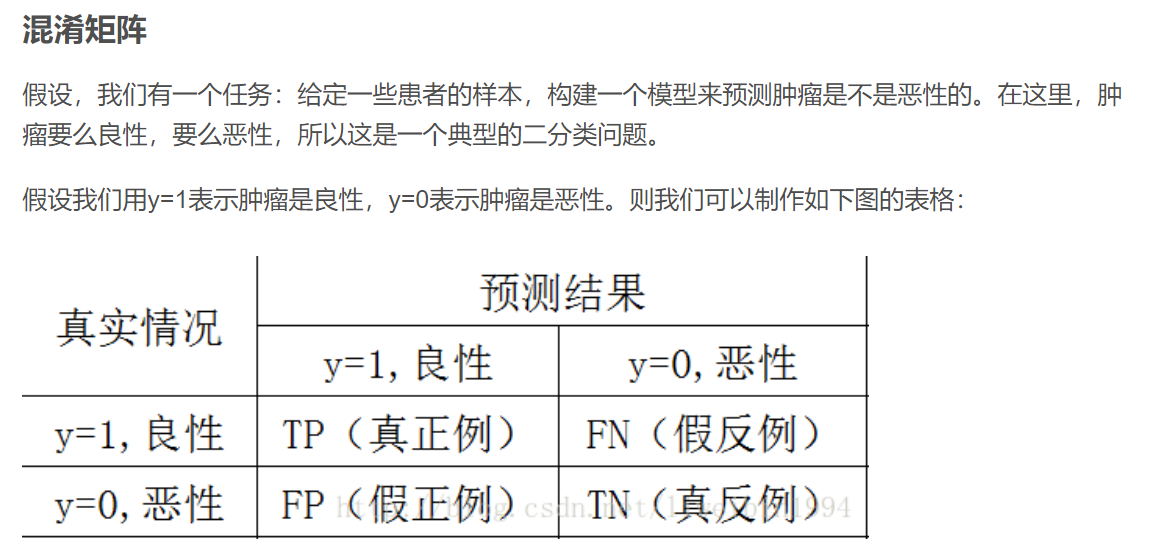
个人理解:正例反例是二分类中相对概念,是根据预测结果定义的一个为正一个为反。而真假则是根据标签判定预测结果的正确与否,标签一致的为真,不一致的为假

正例和反例数量不同时,auc评价不受影响,而召回率受影响很大。
22.删除DataFrame中的某些列(即某些特征)并按行进行合并

23.只有序列才有value_counts()这个函数,用来查看数据出现的次数,查看数据的分布情况,而DataFrame里的某一列取出来就是一个序列
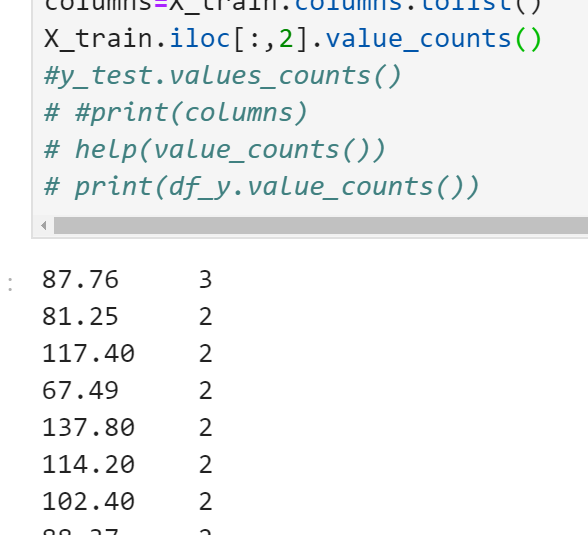
23.切片法切的是index而序列的ndex已经有了,所以不是从0开始,而是看前面的序号
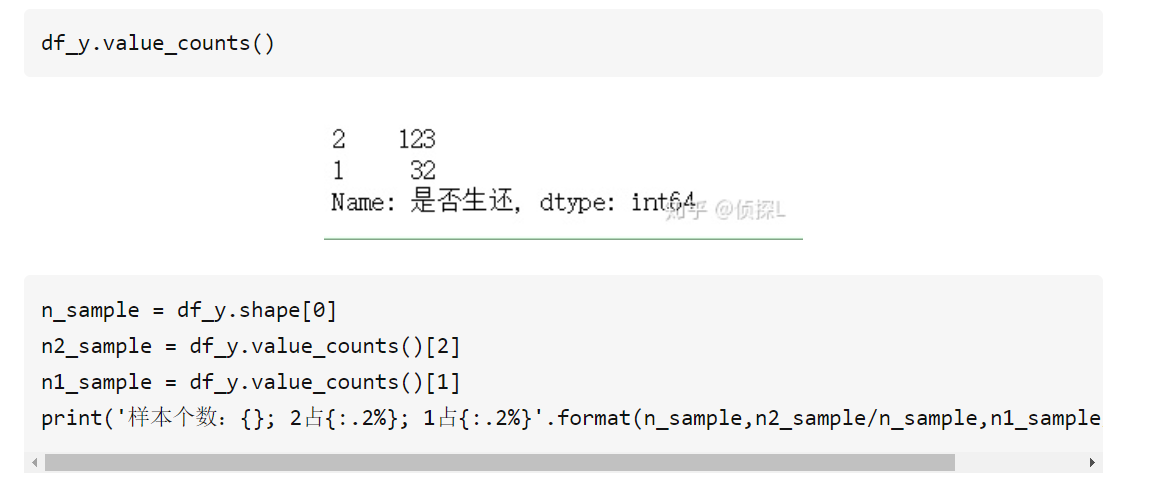
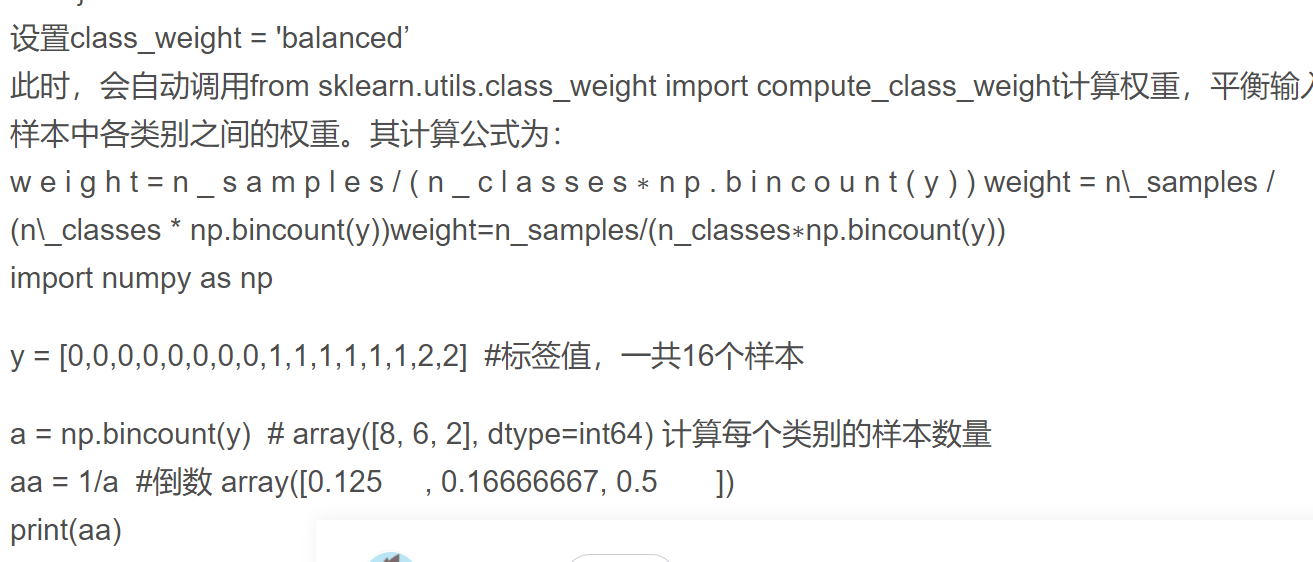
24.数据不均衡问题

不平衡程度相同(即正负样本比例类似)的两个问题,解决的难易程度也可能不同,因为问题难易程度还取决于我们所拥有数据有多大。比如在预测微博互动数的问题中,虽然数据不平衡,但每个档位的数据量都很大——最少的类别也有几万个样本,这样的问题通常比较容易解决;而在癌症诊断的场景中,因为患癌症的人本来就很少,所以数据不但不平衡,样本数还非常少,这样的问题就非常棘手。综上,可以把问题根据难度从小到大排个序:大数据+分布均衡<大数据+分布不均衡<小数据+数据均衡<小数据+数据不均衡。说明:对于小数据集,机器学习的方法是比较棘手的。对于需要解决的问题,拿到数据后,首先统计可用训练数据有多大,然后再观察数据分布情况。经验表明,训练数据中每个类别有5000个以上样本,其实也要相对于特征而言,来判断样本数目是不是足够,数据量是足够的,正负样本差一个数量级以内是可以接受的,不太需要考虑数据不平衡问题(完全是经验,没有理论依据,仅供参考)。
随机采样最大的优点是简单,但缺点也很明显。过采样后的数据集中会反复出现一些样本,训练出来的模型会有一定的过拟合;而欠采样的缺点显而易见,那就是最终的训练集丢失了数据,模型只学到了总体模式的一部分
三、如何选择
解决数据不平衡问题的方法有很多,上面只是一些最常用的方法,而最常用的方法也有这么多种,如何根据实际问题选择合适的方法呢?接下来谈谈一些我的经验。
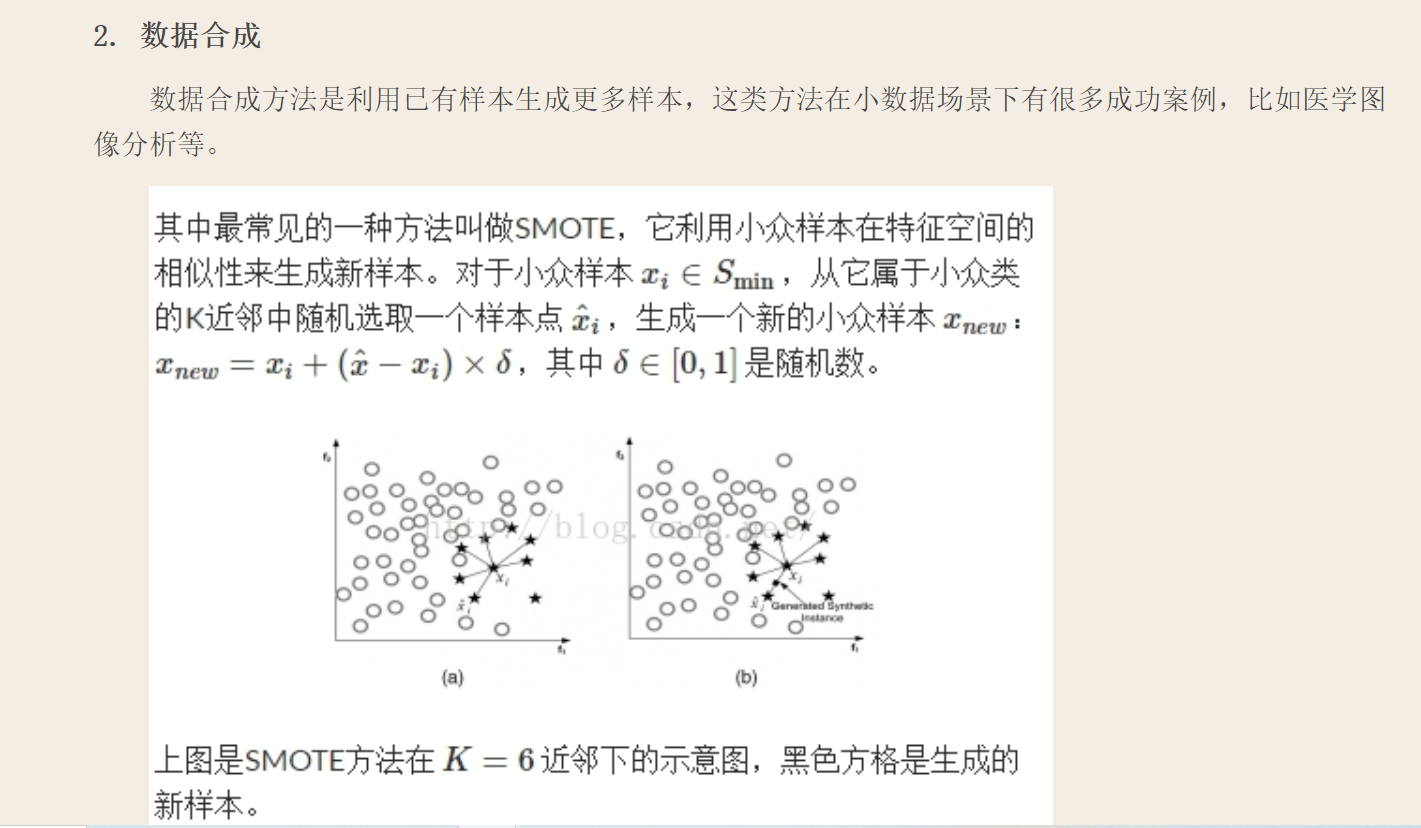
1、在正负样本都非常之少的情况下,应该采用数据合成的方式;
2、在负样本足够多,正样本非常之少且比例及其悬殊的情况下,应该考虑一分类方法;
3、在正负样本都足够多且比例不是特别悬殊的情况下,应该考虑采样或者加权的方法。
4、采样和加权在数学上是等价的,但实际应用中效果却有差别。尤其是采样了诸如Random Forest等分类方法,训练过程会对训练集进行随机采样。在这种情况下,如果计算资源允许过采样往往要比加权好一些。
5、另外,虽然过采样和欠采样都可以使数据集变得平衡,并且在数据足够多的情况下等价,但两者也是有区别的。实际应用中,我的经验是如果计算资源足够且小众类样本足够多的情况下使用过采样,否则使用欠采样,因为过采样会增加训练集的大小进而增加训练时间,同时小的训练集非常容易产生过拟合。
6、对于欠采样,如果计算资源相对较多且有良好的并行环境,应该选择Ensemble方法。
但这些都只能解决分类中的数据不均衡问题(标签是离散数据)
而解决回归问题中的数据不均衡问题(标签是连续的)
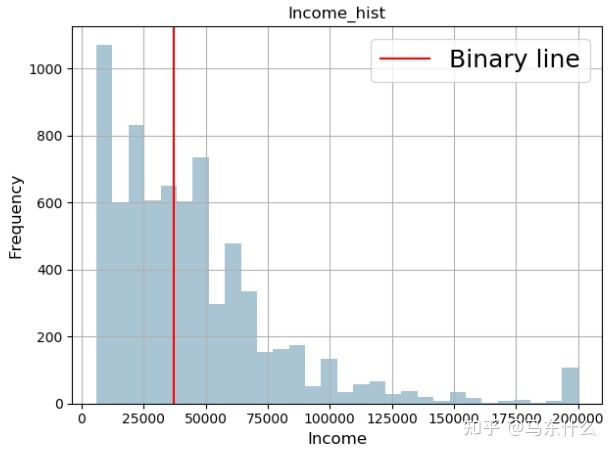
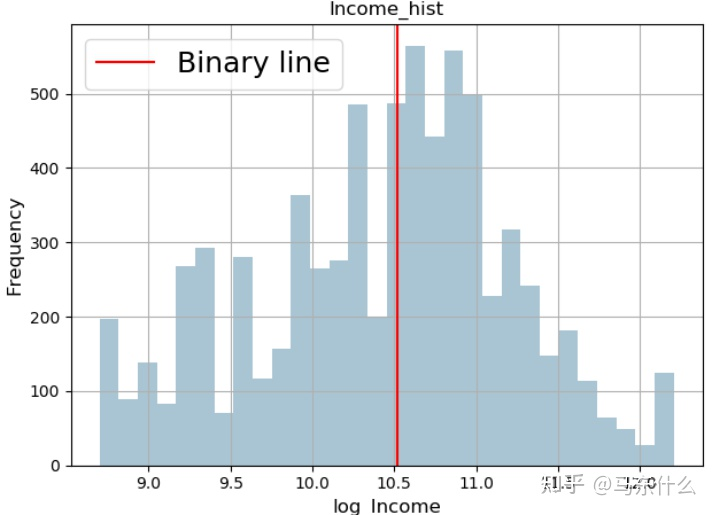
通常通过对标签进行log变换和反变换:我们将所有的样本都向高密度区间拉近了,从而大大缓解了回归不均衡的问题;
进行对数变换之后,我们将所有的样本都向高密度区间拉近了,从而大大缓解了回归不均衡的问题;
25.

26.如何获取列表的下标

27.python实现box-cox变换
'''box-cox变换'''
## Import necessary modules
from scipy.special import boxcox1p
from scipy.stats import boxcox_normmax
import seaborn as sns
import matplotlib.pyplot as plt
def fixing_skewness(df):
"""
This function takes in a dataframe and return fixed skewed dataframe
"""
# 得到所有非类别型变量
numeric_feats = df.dtypes[df.dtypes != "object"].index
# 计算所有非类别型特征的偏态并排序
skewed_feats = df[numeric_feats].apply(lambda x: x.skew()).sort_values(ascending=False)
# 对偏态大于0.5的进行修正,大于0是右偏,小于0是左偏
high_skew = skewed_feats[abs(skewed_feats) > 0.5]
skewed_features = high_skew.index
# 修正
for feat in skewed_features:
# 这里是+1是保证数据非负,否则会弹出错误,没有其他含义,不会影响对偏态的修正
df[feat] = boxcox1p(df[feat], boxcox_normmax(df[feat] + 1))
fig,axes=plt.subplots(len(columns_name),1)
plt.rcParams['font.sans-serif']=['SimHei'] #显示中文标签
plt.rcParams['axes.unicode_minus']=False #解决负号“-”显示为方块的问题
for item in columns_name:
idx=columns_name.index(item)
sns.distplot(X_resampled[item],ax=axes[idx])
fig,axes=plt.subplots(len(columns_name),1)
fixing_skewness(X_resampled)
for item in columns_name:
idx=columns_name.index(item)
sns.distplot(X_resampled[item],ax=axes[idx])
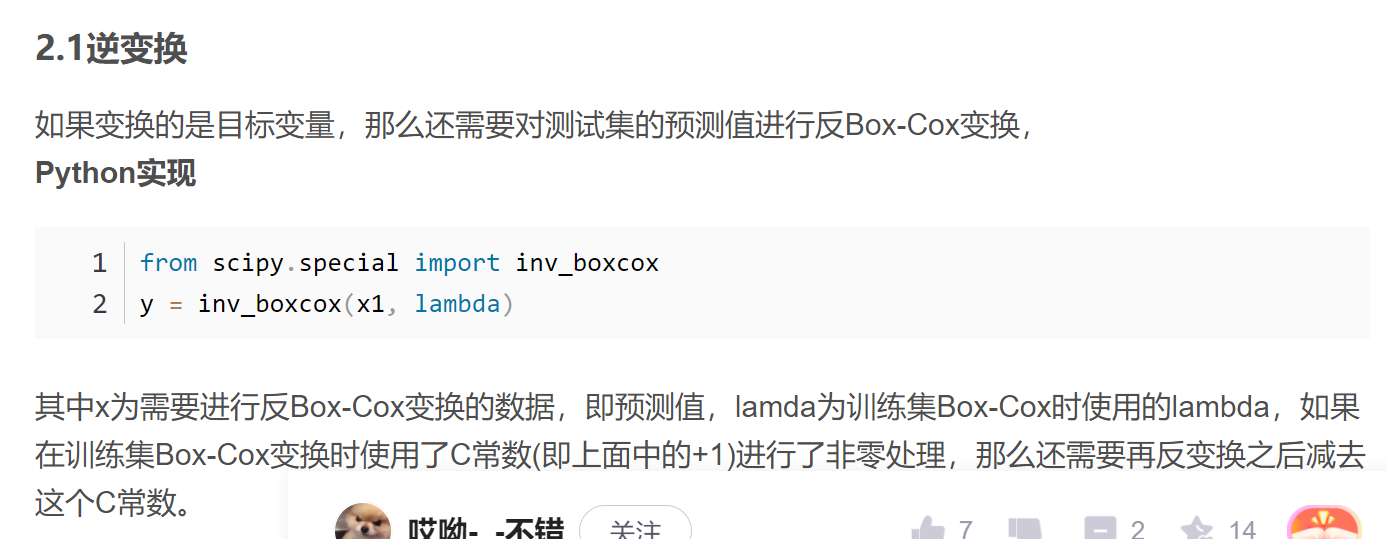
1 from scipy.special import inv_boxcox 2 y = inv_boxcox(x1, lambda)
28.对数组中某列数据进行按从小到大排序
import numpy as np
u = np.unique(data, axis=0) # or np.unique(data, axis=0).tolist()
29.异常值检测
异常点检测的目的是找出数据集中和大多数数据不同的数据,常用的异常点检测算法一般分为三类。
第一类是基于统计学的方法来处理异常数据,这种方法一般会构建一个概率分布模型,并计算对象符合该模型的概率,把具有低概率的对象视为异常点。比如特征工程中的RobustScaler方法,在做数据特征值缩放的时候,它会利用数据特征的分位数分布,将数据根据分位数划分为多段,只取中间段来做缩放,比如只取25%分位数到75%分位数的数据做缩放。这样减小了异常数据的影响。
第二类是基于聚类的方法来做异常点检测。这个很好理解,由于大部分聚类算法是基于数据特征的分布来做的,通常如果我们聚类后发现某些聚类簇的数据样本量比其他簇少很多,而且这个簇里数据的特征均值分布之类的值和其他簇也差异很大,这些簇里的样本点大部分时候都是异常点。比如我之前讲到的BIRCH聚类算法原理和DBSCAN密度聚类算法都可以在聚类的同时做异常点的检测。
第三类是基于专门的异常点检测算法来做。这些算法不像聚类算法,检测异常点只是一个赠品,它们的目的就是专门检测异常点的,这类算法的代表是One Class SVM和Isolation Forest.
30.把dataframe里的某个数值的下标找出来,并把这一行数据提出来
1 X_outlier=X['峰值电压时间(分钟)']>=15.0 2 print(X_outlier.values) 3 result=[] 4 X_lst=list(X_outlier.values) 5 for i in range(len(X_lst)): 6 if X_lst[i]==True: 7 result.append(i) 8 print(result) 9 for item in result: 10 print(X.iloc[item,:])
31.plt.scatter 参数如下:
其中散点的形状参数marker如下:
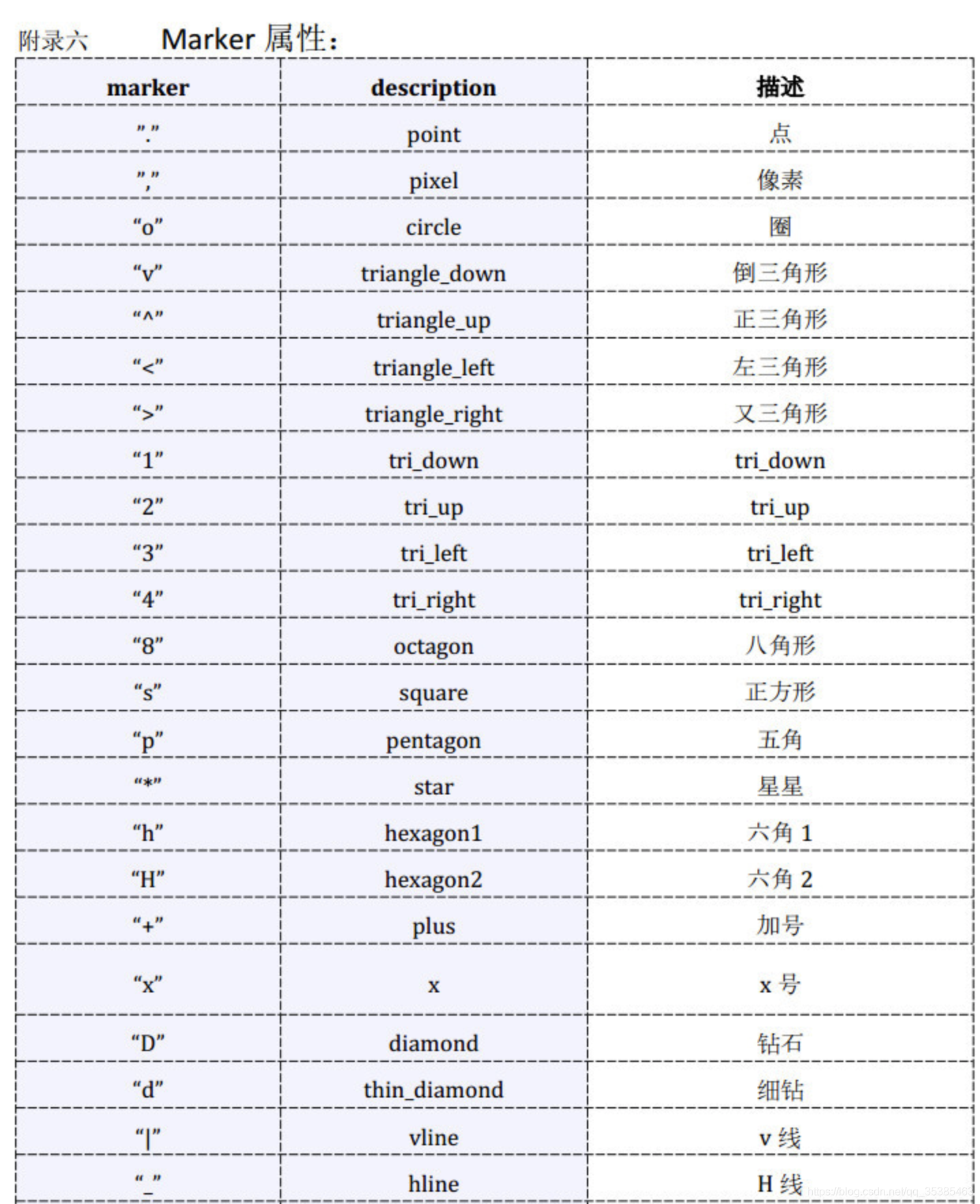
其中颜色参数c如下

32.各种检验中p-value
p-value>0.05或0.01就是需要被消除的特征
33.怎样获取列名
columns_name=list(X.columns)
34.int64index()还是Rangeindex()都是不可打印现实的类型,需要在前面在前面加一个 list()就可以把它打印展示出来
35.np.dot()函数
一维数组是内积运算,二维数组是矩阵积运算
https://www.cnblogs.com/luhuan/p/7925790.html
36.python 之MSE、RMSE、MAE、标准差、方差
https://blog.csdn.net/llx1026/article/details/77752121
1 target = [1.5, 2.1, 3.3, -4.7, -2.3, 0.75] 2 prediction = [0.5, 1.5, 2.1, -2.2, 0.1, -0.5] 3 4 5 error = [] 6 for i in range(len(target)): 7 error.append(target[i] - prediction[i]) 8 9 10 print("Errors: ", error) 11 print(error) 12 13 14 15 16 17 18 squaredError = [] 19 absError = [] 20 for val in error: 21 squaredError.append(val * val)#target-prediction之差平方 22 absError.append(abs(val))#误差绝对值 23 24 25 print("Square Error: ", squaredError) 26 print("Absolute Value of Error: ", absError) 27 28 29 30 31 print("MSE = ", sum(squaredError) / len(squaredError))#均方误差MSE 32 33 34 35 36 from math import sqrt 37 print("RMSE = ", sqrt(sum(squaredError) / len(squaredError)))#均方根误差RMSE 38 print("MAE = ", sum(absError) / len(absError))#平均绝对误差MAE 39 40 41 targetDeviation = [] 42 targetMean = sum(target) / len(target)#target平均值 43 for val in target: 44 targetDeviation.append((val - targetMean) * (val - targetMean)) 45 print("Target Variance = ", sum(targetDeviation) / len(targetDeviation))#方差 46 47 48 print("Target Standard Deviation = ", sqrt(sum(targetDeviation) / len(targetDeviation)))#标准差
37.python查找模块说明性文档:
一:在解释器输入如下指令
**1.help(模块名)
**2.模块名._doc_
二:在终端(Terminal)中输入
**3.python -m pydoc 模块名
38.终端退出当前交互界面:
按q
39.randint
randint(a, b) method of random.Random instance
Return random integer in range [a, b], including both end points.
#randint(a,b)返回[a,b]之间的随机整数,包括两端的断点
40.int()
向下取整,即只保留小数的整数部分
41.
a.reshape(-1,1)
将数组a转换为一列的格式
a.reshape(1,-1)
将数组a转换为一行的格式
a.reshape(-1,)
将数组a转换为一串
42.
pyhton中产生随机数
1.产生(0,1)之间的随机浮点数:
(1)random.random(),不需要任何参数,利用round(a,2)函数来保留指定精度的小数
(2)random.rand(m),产生m个(0,1)之间的随机浮点数
2.产生[a,b]的随机整数:random.randint(a,b)
3.产生制定范围与数量的随机浮点数:没有现成的库函数可以调用,需要自己编写
1 '''生成指定范围,指定数量的随机浮点数 2 np.random.rand(num)只能生成num个(0,1)之间的随机浮点数, 3 其中,l为下限,h为上限,num为要生成的浮点数的数量 4 ''' 5 import numpy as np 6 def randfloat(num, l, h): 7 if l > h: 8 return None 9 else: 10 a = h - l 11 b = h - a 12 out = (np.random.rand(num) * a + b).tolist() 13 #out = np.array(out) 14 return out 15 c=randfloat(15,0.2,0.8) 16 result=[] 17 for item in c: 18 result.append(round(item,2)) 19 print(result)
4.从列表中选出不重复的三位随机数:
1 import numpy as np 2 lst = [1,2,3,9999,0,888] 3 print("原始列表元素为: ") 4 print(lst) 5 while len(lst)>1: 6 index = list(range(len(lst))) 7 np.random.shuffle(index) 8 x1=lst[index[0]] 9 x2=lst[index[1]] 10 x3=lst[index[2]] 11 lst.remove(x1) 12 lst.remove(x2) 13 lst.remove(x3) 14 print("本次删除的元素为: ") 15 print(x1,x2,x3) 16 print("剩余元素为: ") 17 print(lst)
42.python中两个列表不能直接相乘或相减
43. 读取csv文件时,默认使用c引擎读取,所以用python就可能报错,可以加入一行语句:'engine=''python'
44.替换数组中的整列
1 a = np.array(SOH_HAT.values).reshape(-1,) 2 b = np.delete(teX1.values,5,axis=1) 3 c = np.insert(b, 5, values=a, axis=1)
需要先删除指定列的元素再插入对应的值(数组),可能问题就是如果数组是dataframe转化过来的,那么操作后可能各列的名字会消失不见
之前尝试过直接替换操作,行不通,还是要先删除再插入
45.把列表转换为字符串
1 a=['1','2','3','5','6'] 2 ",".join(a)
'1,2,3,5,6'
本意是以指定符号链接的字符串
46.定义全局变量
有时候并行的两个函数,想要在第二个函数里使用第一个函数的变量,那就首先先定义一下函数变量,然后在每一个调用变量前都先使用 global 变量名 进行声明

 浙公网安备 33010602011771号
浙公网安备 33010602011771号