DS01-线性表
0.PTA得分截图

1.本周学习总结
1.1 总结线性表内容
思维导图

线性表总结
线性表是一种最为简单的线性结构。
线性结构的基本特征
线性结构是一个数据元素的有序(次序)集。
集合中必存在唯一的一个“第一元素”
集合中必存在唯一的一个“最后元素”
除最后元素外,均有“唯一后继”
除第一元素外,均有“唯一前驱”
线性表的存储结构及实现
单链表(线性表的链接存储方式):
顺序表 ———→ 静态存储分配 ———→ 事先确定容量
链表 ———→ 动态存储分配 ———→ 运行时分配空间
存储思想:用一组任意(连续、不连续、零散分布)的存储单元存放线性表的元素
顺序表

结构体定义
在定义一个线性表的顺序储存类型时,需要一个数组来储存线性表的所有元素以及一个整型变量来储存线性表的长度,假定数组用data[MaxSize]表示,长度整型变量用length表示
typedef struct
{
ElemType data[MaxSize];
int length;
}List;
顺序表基本运算
| 顺序表插入数据ListInsert(&L,i,e) |
| 顺序表删除数据ListDelete(&L,i) |
| 顺序表查找元素LocateElem(&L,e) |
结构体定义
在链表中,假定每一个结点类型用LinkList表示,则它包括储存元素的数据域用data表示,还包括存储后继元素位置的指针域用next表示
typedef struct LNode
{
ElemType data;
struct LNode *next;//指向后继结点
}Link,*Linklist; //Link为结构体变量,LinkList为结构体指针
链表基本运算
| 头插法建链表CreateList(L,a,n) |
| 尾插法建链表CreateList(L,a,n) |
| 链表插入数据LinkList(&L,e) |
插入算法的平均时间复杂度为O(L.length)
| 链表删除数据ListDelete(&L,e) |
删除算法的平均时间复杂度为O(L.length)
| 计算链表长度LinkList(LinkList h) |
| 倒置链表remove_LinkList(LinkList h) |
| 冒泡排序法bubblesort_LinkList(LinkList h) |
| 插入数据LinkList(&L,e) |
| 删除数据LinkList(&L,e) |
| 有序表合并 |
curptr = L1;
ptrL1 = L1->next;
ptrL2 = L2->next;
L1->next = NULL;
while (ptrL1 && ptrL2)
{
if (ptrL1->data < ptrL2->data)
{
ptr = new LNode;
ptr->data = ptrL1->data;
ptr->next = NULL;
curptr->next = ptr;
curptr = ptr;
ptrL1 = ptrL1->next;
}
else if (ptrL1->data == ptrL2->data)
{
if (ptrL1->next != NULL)
ptrL1 = ptrL1->next;
else
ptrL2 = ptrL2->next;
}
else
{
ptr = new LNode;
ptr->data = ptrL2->data;
ptr->next = NULL;
curptr->next = ptr;
curptr =ptr;
ptrL2 = ptrL2->next;
}
}
while (ptrL2)
{
ptr = new LNode;
ptr->data = ptrL2->data;
ptr->next = NULL;
curptr->next = ptr;
curptr = ptr;
ptrL2 = ptrL2->next;
}
while (ptrL1)
{
ptr = new LNode;
ptr->data = ptrL1->data;
ptr->next = NULL;
curptr->next = ptr;
curptr = ptr;
ptrL1 = ptrL1->next;
}
}
####<span style="color:orange">循环链表、双链表结构特点</span>
####<span style="color:green">循环链表</span>
<table>
<tr>
<td bgcolor=#FF4500>定义循环链表</td>
</tr>
</table>
typedef struct CLNode
{
LElemType data;
struct CLNode * next;
CLNode(LElemType Data=inf,CLNode *Next=NULL)
{
data=Data;
next=Next;
}
}CLNode , *CLinkList ;
<table>
<tr>
<td bgcolor=#FF4500>头插法创建循环链表</td>
</tr>
</table>
void head_creatlist_circle(list *&l)
{
list *s;
l = (list *)malloc(sizeof(list));
l->next = l;
int x;
printf("请输入数据:\n");
scanf("%d",&x);
while(x != 0)
{
s = (list *)malloc(sizeof(list));
s->data = x;
s->next = l->next ;
l->next = s;
scanf("%d",&x);
}
}
<table>
<tr>
<td bgcolor=#FF4500>尾插法创建循环链表</td>
</tr>
</table>
void tail_creatlist_circle(list *&l)
{
list r,s;
l = (list *)malloc(sizeof(list));
r = l;
int x;
printf("请输入数据:\n");
scanf("%d",&x);
while(x != 0)
{
s = (list *)malloc(sizeof(list));
s->data = x;
r->next = s;
r = s;
scanf("%d",&x);
}
r->next = l;
}
循环链表:是一种头尾相接的链表。其特点是最后一个结点的指针域指向链表的头结点,整个链表的指针域链接成一个环。
特点是: 从循环链表的任意一个结点出发都可以找到链表中的其它结点,使得表处理更加方便灵活。
其示意图如下图所示
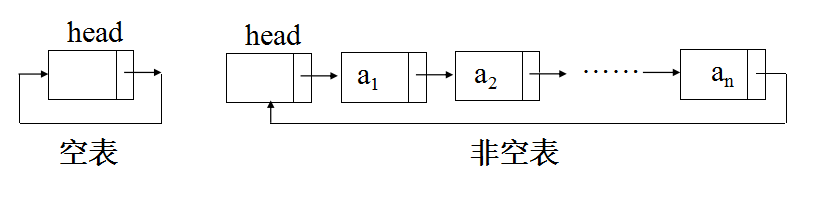
循环链表的操作:
对于单循环链表,除链表的合并外,其它的操作和单线性链表基本上一致,仅仅需要在单线性链表操作算法基础上作以下简单修改:
(1) 判断是否是空链表:head->next==head ;
(2) 判断是否是表尾结点:p->next==head ;
####<span style="color:green">双链表</span>
<table>
<tr>
<td bgcolor=#FF4500>定义双链表</td>
</tr>
</table>
typedef struct LNode
{
int data;
struct LNode *prior;
struct LNode *next;
}Link, *LinkList;
<table>
<tr>
<td bgcolor=#FF4500>创建双链表</td>
</tr>
</table>
DLink * createLink(DLink *head)
{
DLink p,q;
int n;
head=p=(DLink *)malloc(sizeof(DLink));
head->rlink=NULL;
scanf("%d",&n);
while(n!=-1)
{//以输入-1作为输入数据的结束
q=(DLink *)malloc(sizeof(DLink));
p->llink=q;
q->rlink=p;
p=p->llink;
p->data=n;
scanf("%d",&n);
}
return head;
}
双向链表(Double Linked List) :指的是构成链表的每个结点中设立两个指针域:一个指向其直接前趋的指针域prior,一个指向其直接后继的指针域next。这样形成的链表中有两个方向不同的链,故称为双向链表。
如下图所示:

双向链表的特点有:
双向链表结构具有对称性,设p指向双向链表中的某一结点,则其对称性可用(p->prior)->next=p=(p->next)->prior;描述
结点p的存储位置存放在其直接前趋结点p->prior的直接后继指针域中,同时也存放在其直接后继结点p->next的直接前趋指针域中。
####<span style="color:orange">顺序储存结构的优缺点</span>
####<span style="color:green">优点</span>
- 逻辑相邻,物理相邻
- 无须为表示表中元素之间的顺序关系增加额外的储存空间
- 可随机存取任一元素
- 储存空间使用紧凑
####<span style="color:green">缺点</span>
- 插入、删除操作需要移动大量的元素
- 预先分配空间需按最大空间分配,利用不充分
- 表容量难以扩充
##1.2.谈谈你对线性表的认识及学习体会。
我觉得学习的线性表还有单链表就像上学期所学习的数组与链表,顺序表是结构体里面有个数组还有个数组长度。顺序表操作还有理解起来相对容易些,而单链表就难度大了很多,特别是在做PTA时候,有时候没有考虑到空指针的情况,然后还老是找不出来,一旦对空指针进行操作程序就崩溃了,所以做题时候还是得拿着纸拿着笔在那画线,还要考虑充分,不然有时候下一个节点为空之类的没考虑到又去进行操作这类似的情况,还有删除元素插入元素等等,感觉写代码就是写bug。虽然在一些操作上顺序表是比链表时间复杂度上来的多,但我觉得还是顺序表看起来好理解 。可能是数组先入为主吧,大多情况下,更偏爱于用顺序表来做。数据结构这本书,不但需要我们学习新的内容,而且对我们在某些算法上的优化也有很大的要求,上个学期,我们可能不会注重程序运行过长带来的后果,而用链表写代码,加大了数据的量,也就对一些程序的时间复杂度有了更重的要求,这个阶段,我们不但要写出程序,还要尽可能的写出最优程序,尽量的将时间复杂度和空间复杂度降到能力范围之内的最低。但是因为在家上网课的原因,自觉性也是降低了很多,自己的代码能力也有所降低,要想办法的弥补、挽回啊...
#2.PTA实验作业
##2.1.题目1:链表倒数第m个数
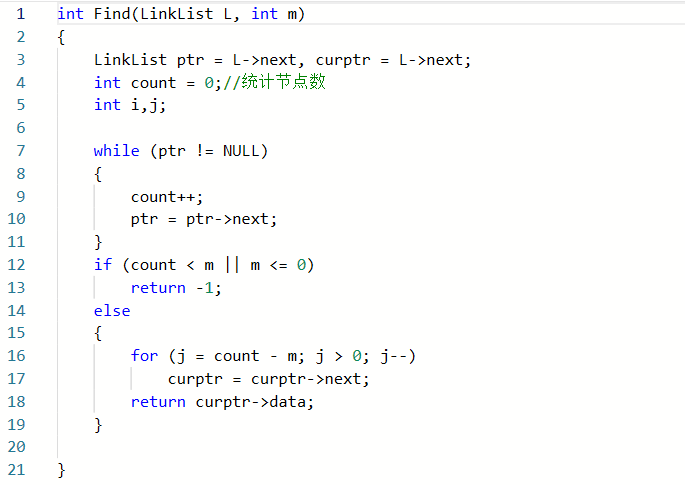
###2.1.1代码截图
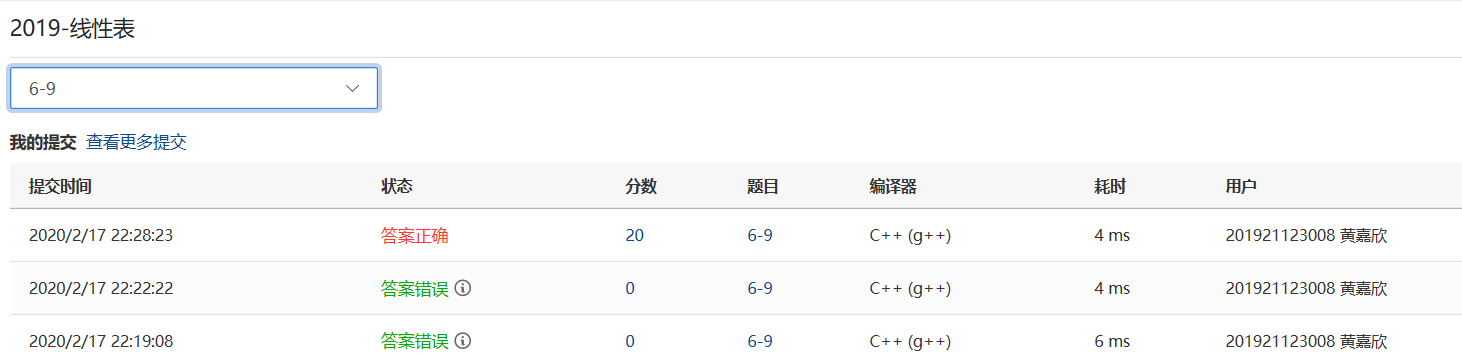
###2.1.2本题PTA提交列表说明
- Q1:一开始位置无效的测试点过不去 没搞懂什么意思,以为是链表为空或者是m为负数 ,可我也加了这些条件后还是错的
- A1:当时只考虑上述两种情况,忘记了当m的大小超过链表的总结点个数也是无效位置,所有增加了计算链表长度的代码进行提交。
- Q2:curptr作为一个代替头结点的存在,让它等于L,进入else分支开始移动,没有考虑到第一个空结点不能算进count-m中,而导致错误。
- A2:令curptr=L->next,为第一个有结点的数据
##2.2.题目2:有序链表合并
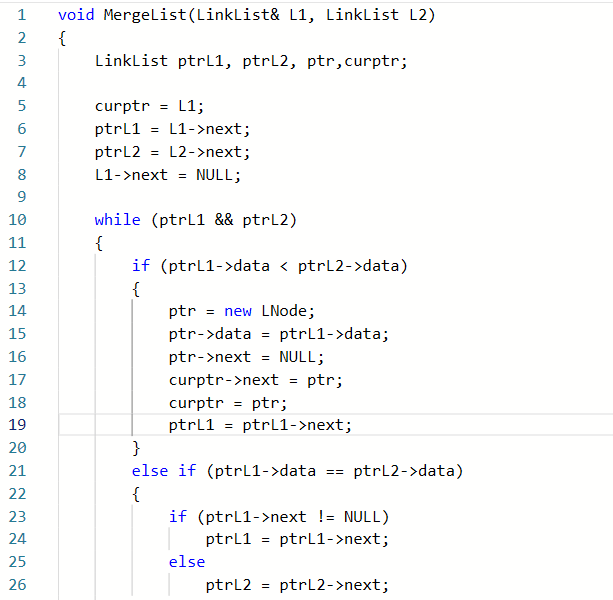
###2.2.1代码截图
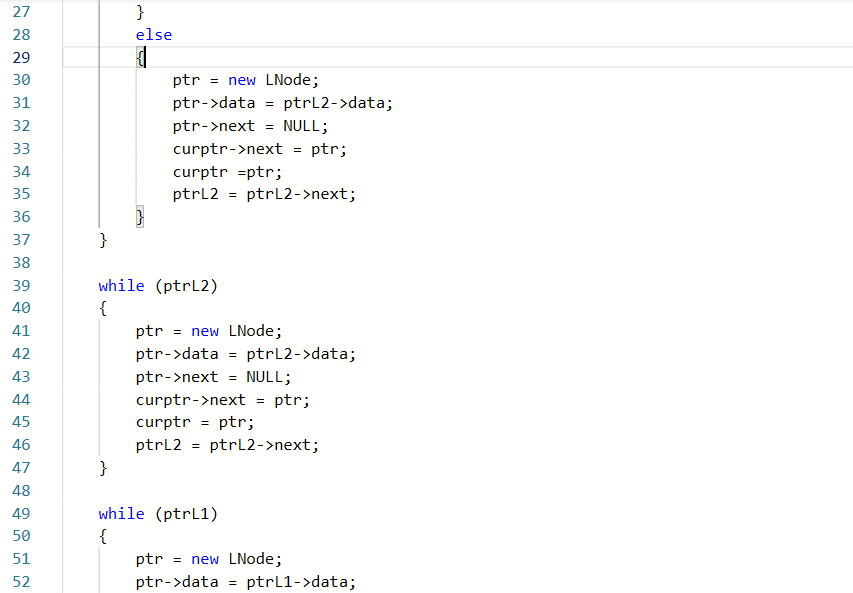

###2.2.2本题PTA提交列表说明
- Q1:起初是直接在L1上进行修改的,本来也没考虑太多,想着既然是要合并到L1,就直接修改L1,导致一开始有部分错误,后面还有死循环这种好久没出现的问题。
- A1:刚开始不是用的上面代码截图的方法,代码内容太复杂了,调试了很久也没看出什么,然后想到上学期学数组的时候,将两个数组合并,用的一种方法将时间复杂度降低,就开始重新写代码
- Q2:重复数据那一个测试点还是没有办法过,指针我也只移动了一个,想着可以把那个重复的数据放进新建的链表中,可是没想到提交还是没过
- A2:就去向大佬请教,也看了很久没看出什么,然后就突然想如果是重复数据,移动的指针刚好就是尾指针呢,有了这个想法之后就把判断相等的那段代码加上if-else判断尾指针,如果是尾指针就移动另一个,这样去提交,误打误撞就正确了。
##2.3.题目3:一元多项式的乘法与加法运算
###2.3.1代码截图
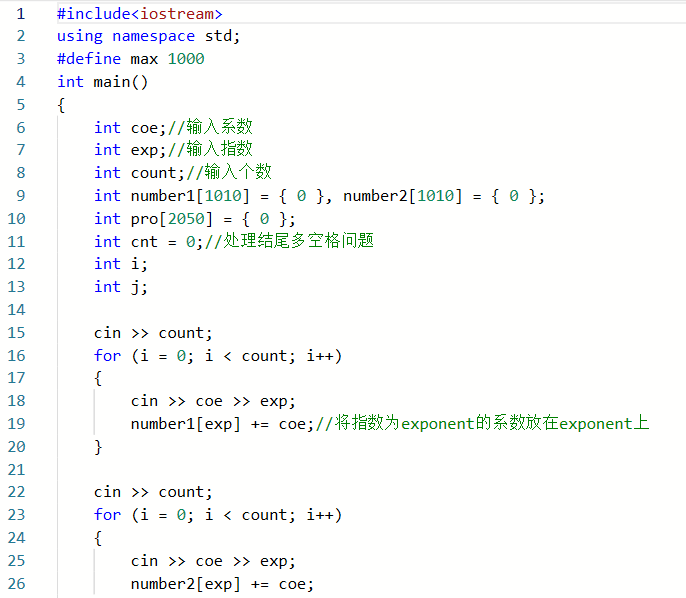


###2.3.2本题PTA提交列表说明
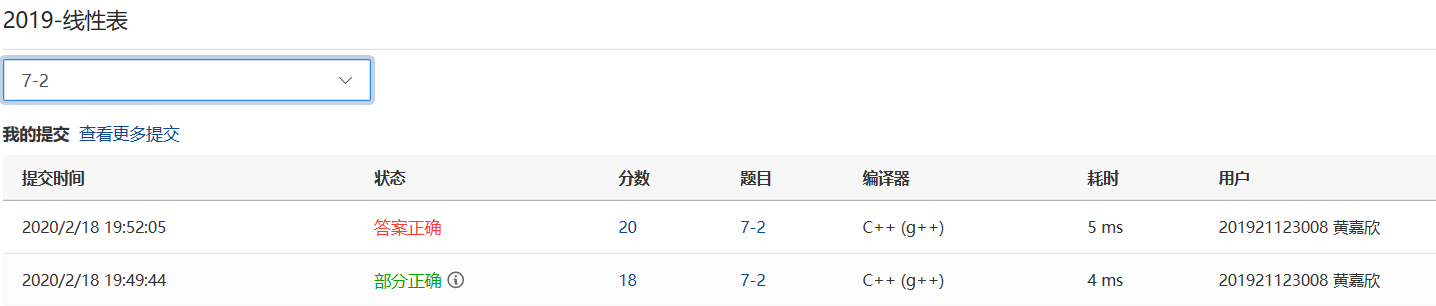
- Q1:部分正确是我在VS上调试了好久才将样例运行下来是正确答案,系数和指数取上限的测试点过不了,这道题目我是用数组做的,我问的同学他们都是用链表做的,噶我就很无奈了只能继续调试了
- A1:一元多项式的乘法指数要进行相加,上限都是MAXSIZE的话,指数的最大是2*MAXSIZE,把输出由MAXSIZE-1改成了2*MZASIZE-1去提交
- Q2:提交之后还是过不了,整个人都懵了,傻了,没有办法之下,我去百度了我这种做法看看我和别人有什么不同
- A2:数组的做法让我对最后一个数组元素过分敏感,指数是可以取到MAXSIZE的,所以数组范围要扩大,把相应的-1去掉就可以通过了。
#3.阅读代码
##3.1 题目及解题代码
<table>
<tr>
<td bgcolor=#FF4500>两数相加</td>
</tr>
</table>
/**
- Definition for singly-linked list.
- struct ListNode {
- int val;
- ListNode *next;
- ListNode(int x) : val(x), next(NULL) {}
- };
/
class Solution {
public:
ListNode addTwoNumbers(ListNode* l1, ListNode* l2) {
int len1=1;//记录l1的长度
int len2=1;//记录l2的长度
ListNode* p=l1;
ListNode* q=l2;
while(p->next!=NULL)//获取l1的长度
{
len1++;
p=p->next;
}
while(q->next!=NULL)//获取l2的长度
{
len2++;
q=q->next;
}
if(len1>len2)//l1较长,在l2末尾补零
{
for(int i=1;i<=len1-len2;i++)
{
q->next=new ListNode(0);
q=q->next;
}
}
else//l2较长,在l1末尾补零
{
for(int i=1;i<=len2-len1;i++)
{
p->next=new ListNode(0);
p=p->next;
}
}
p=l1;
q=l2;
bool count=false;//记录进位
ListNode* l3=new ListNode(-1);//存放结果的链表
ListNode* w=l3;//l3的移动指针
int i=0;//记录相加结果
while(p!=NULL&&q!=NULL)
{
i=count+p->val+q->val;
w->next=new ListNode(i%10);
count=i>=10?true:false;
w=w->next;
p=p->next;
q=q->next;
}
if(count)//若最后还有进位
{
w->next=new ListNode(1);
w=w->next;
}
return l3->next;
}
};
###3.1.1 该题的设计思路
- 获取两个链表所对应的长度
- 在较短的链表末尾补零
- 对齐相加考虑进位
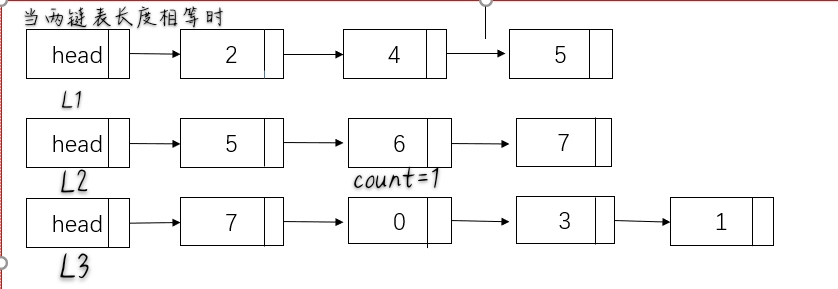
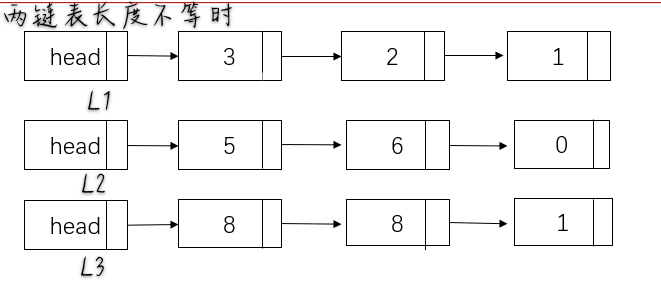
<span style="color:orange">时间复杂度O(max(len1,len2))</span>
<span style="color:orange">空间复杂度O(max(len1,len2))</span>
###3.1.2 该题的伪代码
ListNode* addTwoNumbers(ListNode* L1, ListNode* L2)
{
定义结构体指针p代替L1进行遍历操作
定义结构体指针q代替L2进行遍历操作
定义结构体指针w作为L3的移动指针
定义链表L3存放相加结构
定义整型变量len1=1来记录L1的长度
定义整型变量len2=1来记录L2的长度
定义bool型变量count=false记录进位
while p do
len1累加
p指向下一个结点
end
while q do
len2累加
q指向下一个结点
end
if(len1 > len2) then
L1较长,在L2末尾补零
else then
L2较长,在L1末尾补零
p,q指针重新指到头结点
while(p!=NULL&&q!=NULL) do
int i=count + p->val + q->val
w->next 指向一个新结点内容为i%10
if(i > 10) then
count为true
else then
count为false
end if
p,q,w指针向后移动
end
if(count) then
w->next 指向一个新结点内容为1
把w移动到w->next
return L3;
}
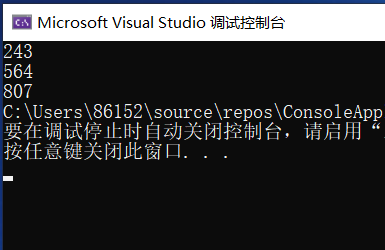
###3.1.3 运行结果
###3.1.4分析该题目解题优势及难点
- 这道题目解答的点睛之笔在于较短链表末尾补零的操作,如果想到这种解法题目也是迎刃而解,如果没想到应该也是会卡壳很久的吧,对于我自己来说,我肯定是要卡一个小时甚至更多的,这道题目可能不是更重的去抓对链表的应用,结合了链表的简单操作实现末尾补零的神操作。
- 难点之一就是怎么让链表中的各个结点齐位相加,所以这既是题目的难点也是该题的两点;还有一点难点就是进位,解题代码的进位灵活的运用了相加取余的做法,还有就是最高位运算相加之后还要在对count进行是否为1的判断,这里是很容易漏掉的!!!
##3.2 题目及解题代码
<table>
<tr>
<td bgcolor=#FF4500>旋转链表</td>
</tr>
</table>
struct ListNode* rotateRight(struct ListNode* head, int k)
{
if(head==0) return 0;
short length=1;
struct ListNode* tmp=head;
while(tmp->next!=0){
tmp=tmp->next;
length++;
}
tmp->next=head;
k=length-k%length;
while(k--) tmp=tmp->next;
head=tmp->next;
tmp->next=0;
return head;
}
###3.2.1 该题的设计思路
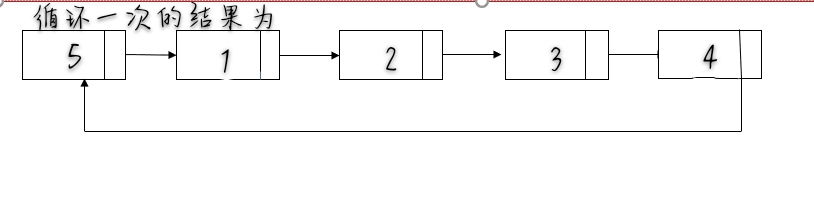
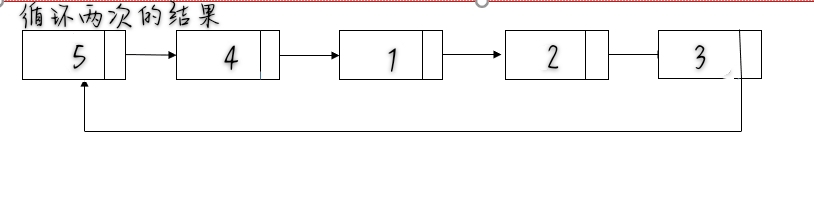
- 找到旧的尾部并将其与链表头相连 tmp->next=head;,整个链表闭合成环,同时计算出链表的长度 length。
- 找到新的尾部,第 (length - k % length - 1) 个节点 ,新的链表头是第 (length - k % length) 个节点。
- 断开环 ,并返回新的链表头head。
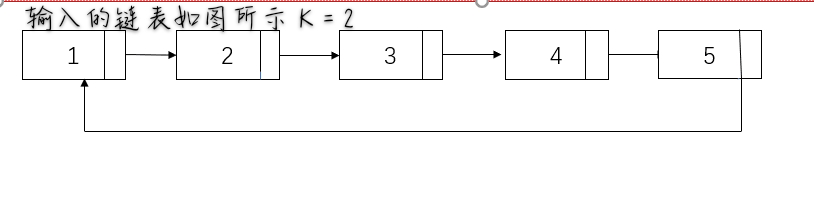
<span style="color:orange">时间复杂度O(length)</span>
<span style="color:orange">空间复杂度O(1)</span>
###3.2.2 该题的伪代码
定义一个整型变量length=0存放链表head的长度
定义结构体指针temp代替head遍历链表
while(temp->next!=0) do
temp指针向后移动
length自增计算链表长度
end
temp的后继指针指向Head形成一个循环链表
重新计算K=length - K % length让temp移动到新的头结点处
while(k--)
temp向后移动
head指向temp的后继结点
temp的后继结点赋值为0,断开循环链表
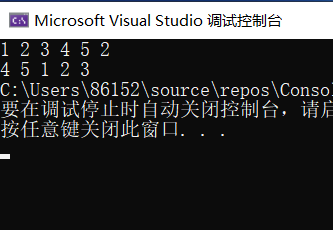
###3.2.3 运行结果
###3.2.4分析该题目解题优势及难点
- 解题代码开辟新思路在原链表上构建循环链表,对于链表来说,将链表每个节点向右移动 k 个位置,其实就是将链表串起来改变链表的头结点,这个解题思路非常之巧妙,可以说是很难想到,运用此方法的前提是要对链表极其的熟练,这道题目就可以看出链表的实用性,用平常最喜欢的数组是不可以做到这种的简便做法,目前只有链表可以,链表是个好东西呀!!!
- 难点:如果想不到简便做法,可能会采取两层循环的方式,外层循环是K,里层循环是链表,这样整个题目的时间复杂度就要提升O(k*length),效率会大打折扣,一旦数据过大,就是面临运行超时的问题,所以由此可见一个好的算法多么的重要,上学期学习C语言,我们很少去注意自己的代码运行花费的时候,觉得过了就好了,到了这个学习我们就要格外的注意了,暴风雨来了....
 浙公网安备 33010602011771号
浙公网安备 33010602011771号