Hadoop 伪分布式环境搭建,基本操作,Java调用api
伪分布式快速搭建
首先打开vmware,新建3台虚拟机,使用xshell连接并将键入指令发送给所有会话
1.关闭防火墙 systemctl stop firewalld systemctl disable firewalld

2.关闭SELinux
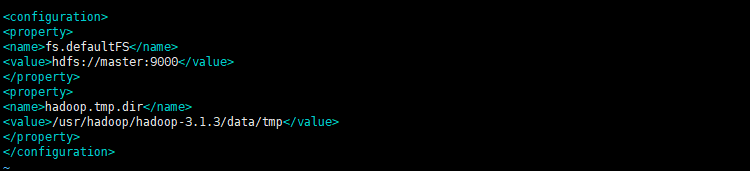
3.创建相关文件夹 mkdir -p /opt/install mkdir -p /opt/software
4.安装JDK 使用FileZilla上传到/opt/install cd /opt/install tar -zxvf jdk-8u11-linux-x64.tar.gz -C /opt/software/ cd /opt/software mv jdk1.8.0_11 jdk1.8 vim /ect/profile
JAVA_HOME=/opt/software/jdk1.8 CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar PATH=$JAVA_HOME/bin:$PATH

5.修改主机名,在Hadoop中,要求主机名中不能出现_和- cd /etc/hostname 主机名最好是字母或者数字,但是不能全部是数字,数字最好不作为开头。例如: hadoop01 或者 slave1 保存退出,并且重新生效 source /etc/hostname
6.将主机名和IP进行映射 vim /etc/hosts 添加映射,例如: 192.168.171.129 slave1 保存退出

7.重启 reboot
8.配置免密登陆 生成公私钥 ssh-keygen 配置免密 ssh-copy-id root@slave1 密码:123456; 测试一下是否免密: ssh slave1
9.上传Hadoop
10.解压Hadoop tar -xvf hadoop-2.7.1_64bit.tar.gz -C /opt/software
11.进入Hadoop的安装路径 cd /opt/software/hadoop-2.7.1 cd etc/Hadoop
12.编辑hadoop-env.sh vim hadoop-env.sh 修改 export JAVA_HOME=/opt/software/jdk1.8 export HADOOP_CONF_DIR=/home/software/hadoop-2.7.1/etc/hadoop 保存退出,重新生效 source hadoop-env.sh


13.编辑core-site.xml vim core-site.xml 添加: <!-- 指定文件系统 --> <property> <name>fs.defaultFS</name> <value>hdfs://master:9000</value> </property> <!-- 指定HDFS的数据存储位置 -->
<property> <name>hadoop.tmp.dir</name> <value>/usr/hadoop/hadoop-3.1.3/data/tmp</value> </property>
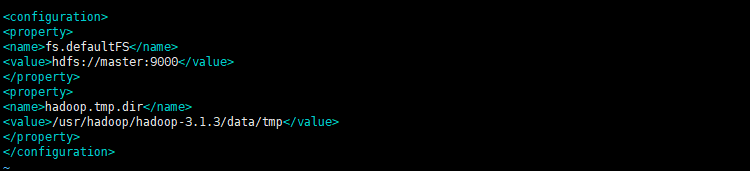
14.编辑hdfs-site.xml,伪分布式的副本数量一定要为1 vim hdfs-site.xml 添加: <!-- 指定HDFS中的副本数量 --> <property> <name>dfs.replication</name> <value>1</value> </property>

15.编辑mapred-site.xml cp mapred-site.xml.template mapred-site.xml vim mapred-site.xml 添加: <!-- 将MapReduce配置成基于YARN的系统 --> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property>

16.编辑yarn-site.xml vim yarn-site.xml 添加: <!-- 指定YARN中ResourceManager的地址 --> <property> <name>yarn.resourcemanager.hostname</name> <value>master</value> </property> <!-- 指定NodeManager中数据获取的方式 --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property>

17.编辑workers文件(在老版本的hadoop中为编辑slaves文件) vim workers添加当前的主机名,例如: slave1

18.配置环境变量 vim /etc/profile 添加: export HADOOP_HOME=/opt/software/hadoop-2.7.1 export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin 保存退出之后,重新生效: source /etc/profile

19.第一次启动Hadoop之前需要进行一次格式化 hadoop namenode -format command not found --- 环境变量 如果出现其他错误,查看core-site.xml和hdfs-site.xml
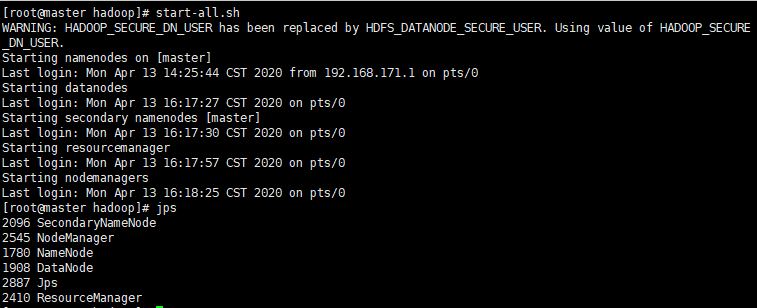
启动Hadoop start-all.sh 如果启动成功,利用jps查看,会出现以下6个进程: Jps NameNode --- 50070 DataNode --- 50075 SecondaryNameNode --- 50090 ResourceManager --- 8088 NodeManager
如果是命令找不到,则表示环境变量配置错误或者是没有source 如果少了NameNode或者DataNode: a.coere-site.xml或者hdfs-site.xml配置错误 b.多次格式化 - 删除/home/software/hadoop-2.7.1/tmp重新格式化重新启动 如果少了ResourceManager或者NodeManager: 查看yarn-site.xml
启动 Hadoop 集群(方便后续的测试) sbin/start-dfs.sh sbin/start-yarn.sh -help:输出这个命令参数 hadoop fs -help rm -ls: 显示目录信息 hadoop fs -ls / -mkdir:在 hdfs 上创建目录 hadoop fs -mkdir -p /user/warehouse/test -moveFromLocal 从本地剪切粘贴到 hdfs touch test.txt hadoop fs -moveFromLocal ./test.txt /user/warehouse/test --appendToFile :追加一个文件到已经存在的文件末尾 touch ximen.txt vi ximen.txt 输入 hello hadoop hadoop fs -appendToFile ximen.txt /user/warehouse/test/test.txt -cat :显示文件内容 hadoop fs -cat /user/warehouse/test/test.txt -tail:显示一个文件的末尾 hadoop fs -tail /user/warehouse/test/test.txt -chgrp 、-chmod、-chown:linux 文件系统中的用法一样,修改文件所属权限 hadoop fs -chmod 666 /user/warehouse/test/test.txt hadoop fs -chown blb:blb /user/warehouse/test/test.txt -copyFromLocal:从本地文件系统中拷贝文件到 hdfs 路径去 hadoop fs -copyFromLocal README.txt /user/warehouse/test -copyToLocal:从 hdfs 拷贝到本地 hadoop fs -copyToLocal /user/warehouse/test/test.txt ./test.txt -cp :从 hdfs 的一个路径拷贝到 hdfs 的另一个路径 hadoop fs -cp /user/warehouse/test/test.txt /test.txt -mv:在 hdfs 目录中移动文件 hadoop fs -mv /test2.txt /user/warehouse/test/ -get:等同于 copyToLocal,就是从 hdfs 下载文件到本地 hadoop fs -get /user/warehouse/test/jinlian2.txt ./ -getmerge :合并下载多个文件,比如 hdfs 的目录 /aaa/下有多个文件:log.1, log.2,log.3,... hadoop fs -getmerge /user/warehouse/test/* ./zaiyiqi.txt -put:等同于 copyFromLocal hadoop fs -put ./zaiyiqi.txt /user/warehouse/test/ -rm:删除文件或文件夹 hadoop fs -rm /user/warehouse/test/jinlian2.txt -rmdir:删除空目录 hadoop fs -mkdir /test hadoop fs -rmdir /test -df :统计文件系统的可用空间信息 hadoop fs -df -h / -du 统计文件夹的大小信息 hadoop fs -du -s -h /user/warehouse/test
package com.blb.hdfs; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IOUtils; import org.junit.Test; import java.io.*; import java.net.URI; public class HDFS_Study { // 上传 @Test public void put() throws IOException, InterruptedException { // Configuration表示对环境的配置 Configuration conf = new Configuration(); // 之前在XXX-site.xml中的配置都可以写在这儿 // 代码中的配置优先于配置文件中内容 conf.set("dfs.replication", "1"); // conf.set("dfs.blocksize", "5562856"); // 连接HDFS FileSystem fs = FileSystem.get( URI.create("hdfs://192.168.10.131:9000"), conf, "root"); // 指定在HDFS上的存储位置 OutputStream out = fs.create(new Path("/a.txt")); // 指定要上传的文件 FileInputStream in = new FileInputStream("D:\\Demo.txt"); // 读取文件,然后利用输出流写出 IOUtils.copyBytes(in, out, conf); // 关流 in.close(); out.close(); } // 下载 @Test public void get() throws IOException { Configuration conf = new Configuration(); FileSystem fs = FileSystem.get( URI.create("hdfs://192.168.10.131:9000"), conf); // 指定要下载的文件 InputStream in = fs.open(new Path("/a.txt")); FileOutputStream out = new FileOutputStream("C:\\a.txt"); IOUtils.copyBytes(in, out, conf); in.close(); out.close(); } // 删除 @Test public void delete() throws IOException, InterruptedException { Configuration conf = new Configuration(); FileSystem fs = FileSystem.get( URI.create("hdfs://192.168.10.131:9000"), conf, "root"); // 删除 fs.delete(new Path("/a.txt"), true); } }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号