

SparkSQL程序设计
1、创建Spark Session
val spark = SparkSession.builder . master("local") .appName("spark session example") .getOrCreate()
注:下面的 spark 都指的是 sparkSession
2、将RDD隐式转换为DataFrame
import spark.implicits._
spark中包含 sparkContext和 sqlContext两个对象
sparkContext 是操作 RDD 的
sqlContext 是操作 sql 的
4、将数据源转换为 DataSet/DataFrame
1、RDD
通过反射
通过自定义 schema 方式 2、通过使用 SparkSql 内置数据源直接读取 JSON、parquet、jdbc、orc、csv、text 文件,创建 DS/DF
hive 里用 orc 多
impla 里用 parquet 多
5、对4反射方式进行解释
同时,红色字体处表示 import spark.implicits._ 排上用场

6、对4中通过自定义 schema 方式显式的注入 schema 来生产 DF
这个 schema 由StructType 构成,StructType 由StructFiledName,StructType,是否为空,这三部分组成
mode(SaveMode.override) 指的是,将数据写成文件时,如果存在这个目录,则覆盖掉

7、对4中,直接从数据源读取数据,转换成 DF 进行解释
这些数据源,内部本身就包含了数据的 schema,所以可以直接读取文件成一个 DF
2是1的简写,区别是,如果是内部数据源,用2,如果是外部数据源,用1
3是直接通过 sql 的方式去创建成表,然后通过 select 的方式去查找,然而编程的时候不是用这样的写法,由其他 sql 写法
json 和 parquet 两者方式一样

8、读取 JDBC 数据,产生 DF

9、通过读取 text 来生成 DF
注意1与2的不同!

10、引用外部数据源的方法
去下面网址,进入 DataSource,查找外部数据源的使用
spark-packages.org
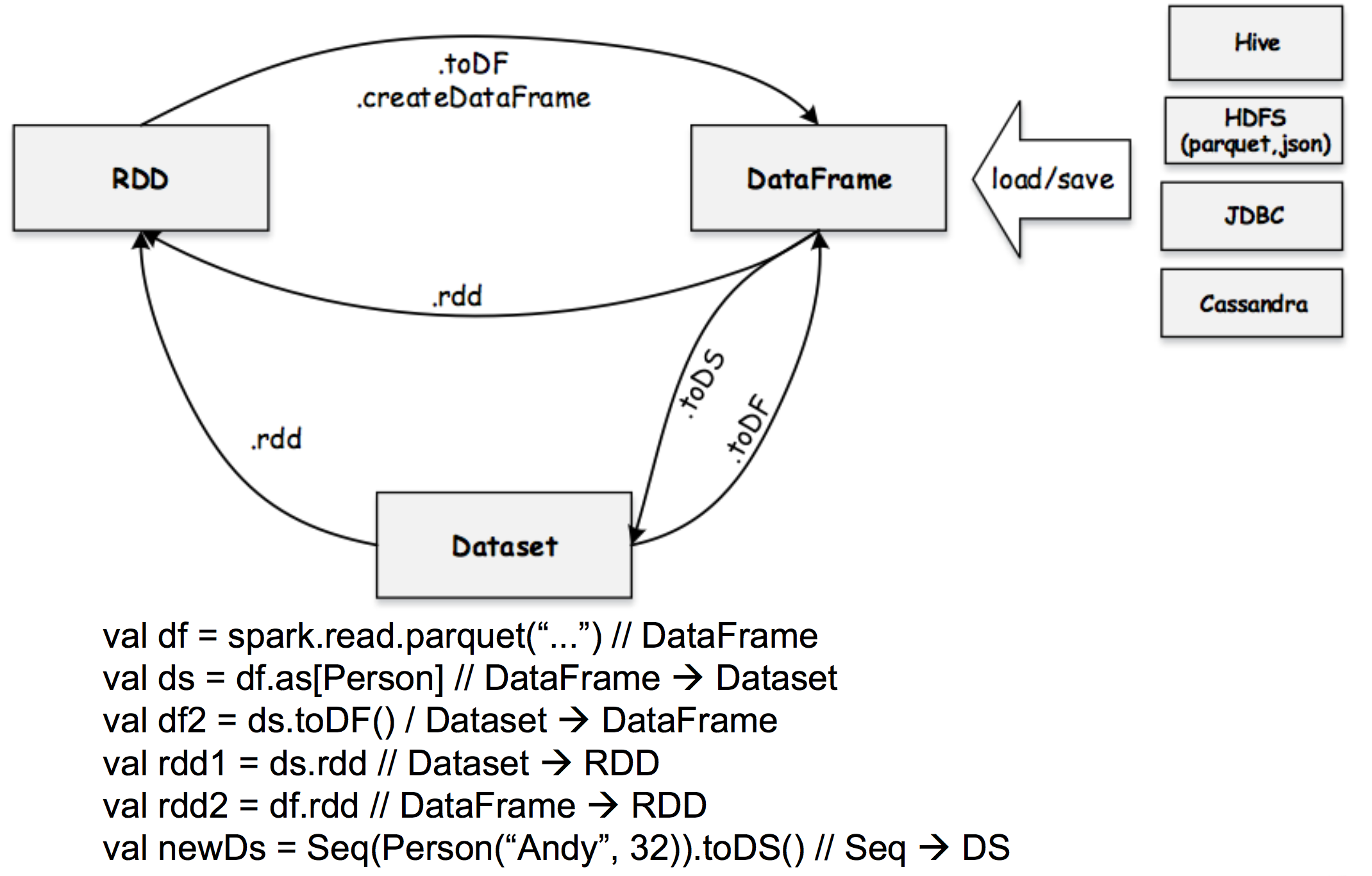
11、RDD、DF、DS 之间的关系
首先从 DataSource 那里获取数据,生成 DF,
DF 通过.rdd 生成 RDD
DF 通过.toDS 或者 .as 生成 DS
DF和 DS 都可以转换成 RDD ,需要注意的是从 DF 转换成 RDD 格式是 Row 对象,并不是它原始对象,DS 转换成 RDD 格式可以是原始的对象
还可以把一个 Scala 集合转化成 DS,跟把 Scala 集合转化成 RDD 一样
图有点老,在 spark2.1中,RDD.toDS 方法已经有了
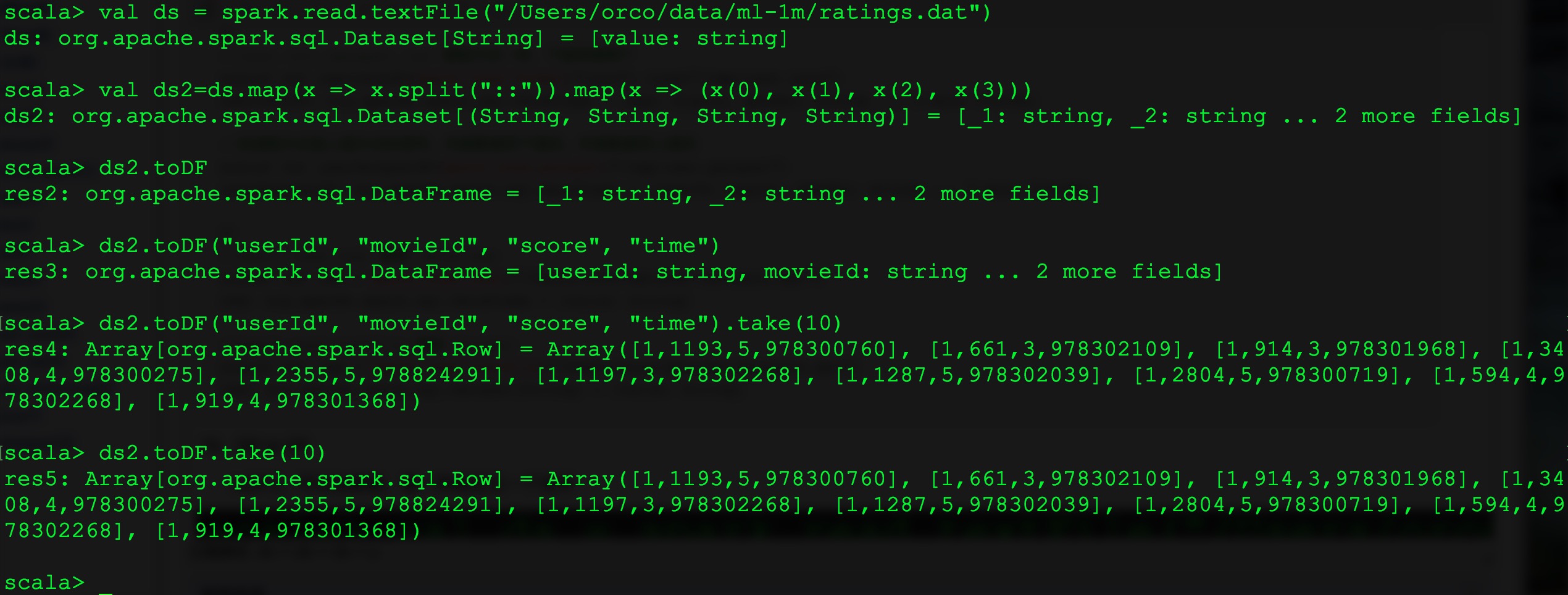
12、加载文件
1: scala> val usersRdd=sc.textFile("/Users/orco/data/ml-1m/users.dat") usersRdd: org.apache.spark.rdd.RDD[String] = /Users/orco/data/ml-1m/users.dat MapPartitionsRDD[1] at textFile at <console>:24 2: //json、orc、parquet、csv 读取方式一样,下面举例两个 scala> val userJsonDF=spark.read.format("json").load("/tmp/user.json") userJsonDF: org.apache.spark.sql.DataFrame = [age: bigint, gender: string ... 3 more fields] //该读取方式是上面方式的简写,内部数据用下面的,外部数据用上面的 scala> val userParquetDF=spark.read.parquet("/tmp/user.parquet") userParquetDF: org.apache.spark.sql.DataFrame = [userID: bigint, gender: string ... 3 more fields] 3: //spark.read.text 返回 DataFrame scala> val rdd = spark.read.text("/Users/orco/data/ml-1m/users.dat") rdd: org.apache.spark.sql.DataFrame = [value: string] //spark.read.textFile 返回 DataSet scala> val rdd = spark.read.textFile("/Users/orco/data/ml-1m/users.dat") rdd: org.apache.spark.sql.Dataset[String] = [value: string]
13、DS to DF
toDF(),可以加参数,每一列给定义一个名字
14、练习
1. json 数据 {"age":"45","gender":"M","occupation":"7","userID":"4","zipcode":"02460"}{"age":"1","gend er":"F","occupation":"10","userID":"1","zipcode":"48067"} 2. 读取数据 scala> val userDF = spark.read.json("/tmp/user.json") userDF: org.apache.spark.sql.DataFrame = [age: string, gender: string, occupation: string, userID: string, zipcode: string] 3. 生成Json数据 scala> userDF.limit(5).write.mode("overwrite").json("/tmp/user2.json") 4. 查看数据 scala> userDF.show(4) 或者(DF.toJSON 生成一个 DS) scala> userDF.limit(2).toJSON.foreach(x =>println(x)) {"age":"1","gender":"F","occupation":"10","userID":"1","zipcode":"48067"} {"age":"56","gender":"M","occupation":"16","userID":"2","zipcode":"70072"} 或者 scala> userDF.printSchema root |-- age: string (nullable = true) |-- gender: string (nullable = true) |-- occupation: string (nullable = true) |-- userID: string (nullable = true) |-- zipcode: string (nullable = true) 5. 修改 DF/DS 元信息 userDF.toDF("a","b","c","d","e") userDS.toDF("a","b","c","d","e") 或者 val userDs = spark.read.textFile("ml-1m/users.dat").map(_.split("::")) val userDf = userDs.map(x => (x(0).toLong, x(1).toString, x(2).toInt, x(3).toInt, x(4))).toDF("userId", "gender", "age", "occ", "timestamp") 或者 //增加新列“age2” userDf.withColumn(”age2",col(”age")+1) 6. Action 算子,如 collect、first、take、head 等
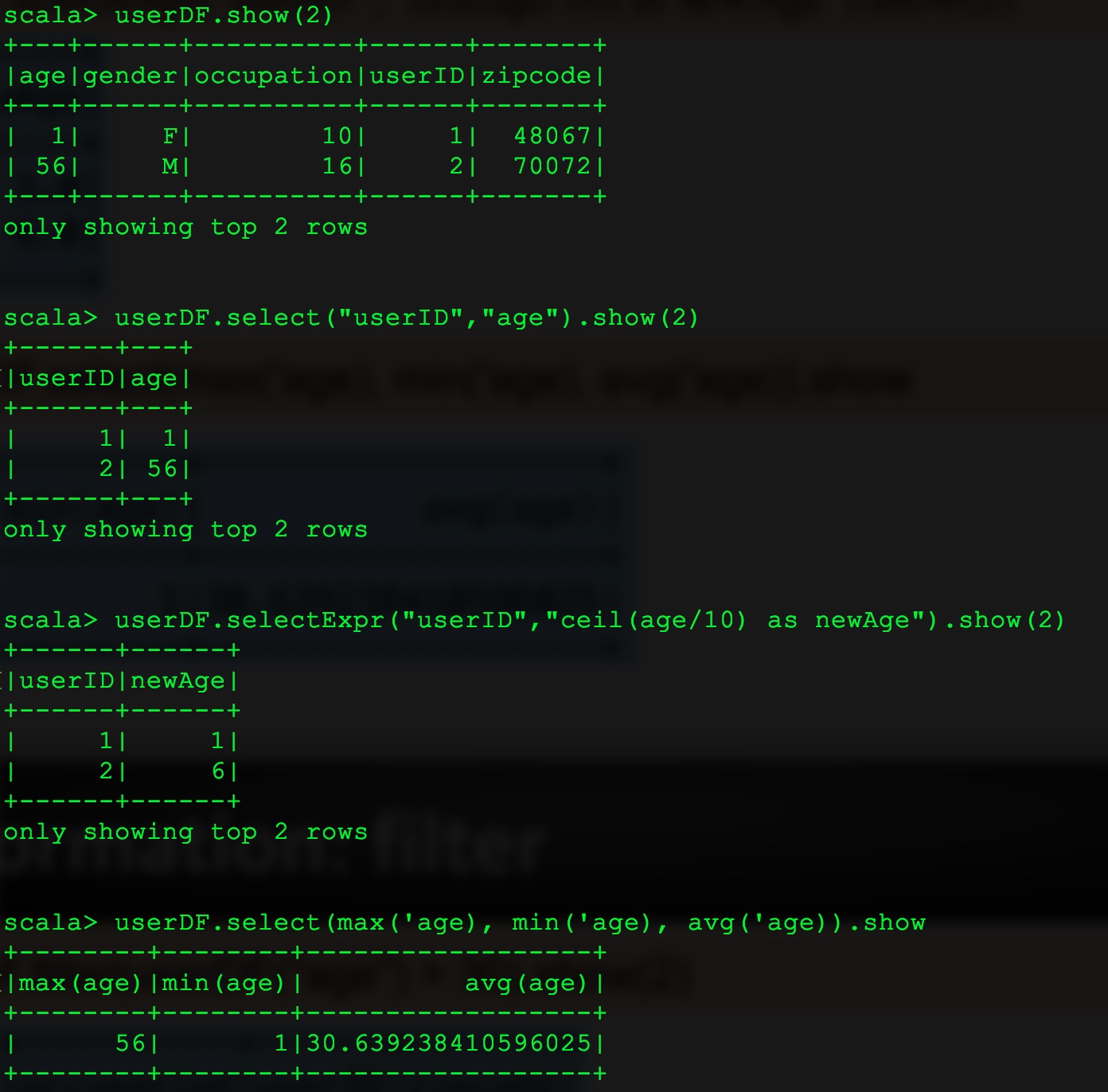
15、单独列举出来,select 算子
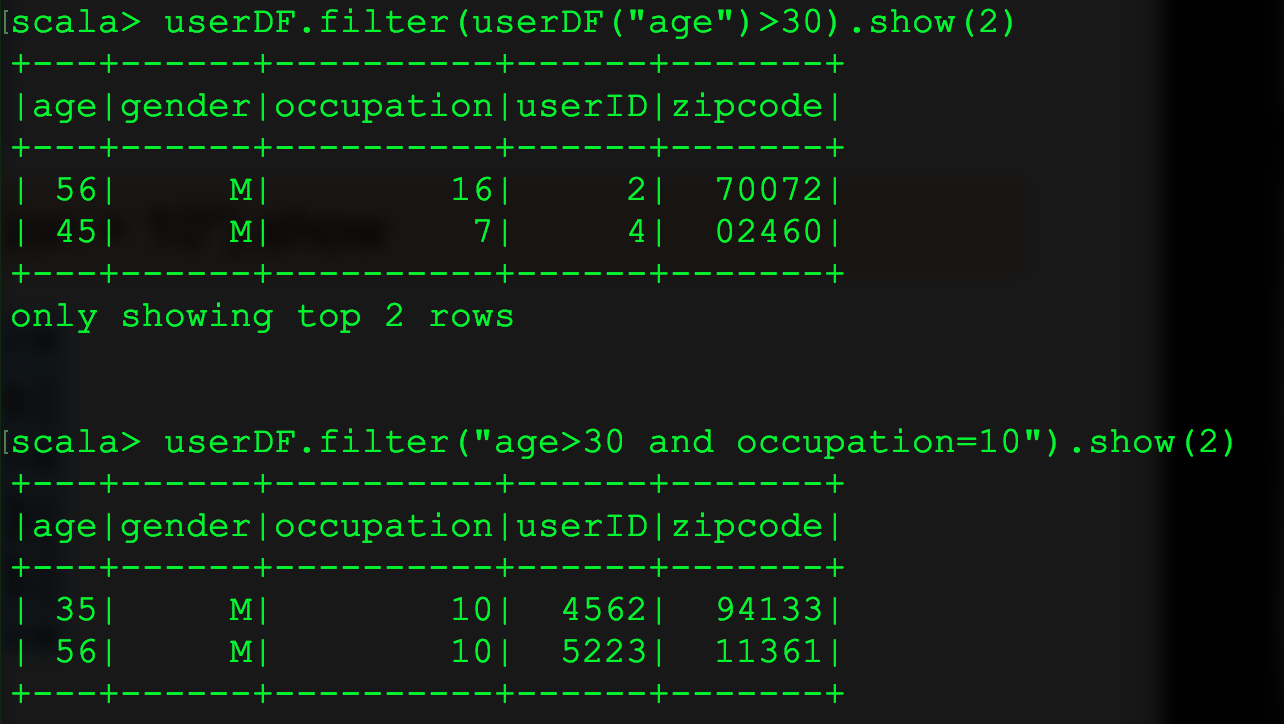
16、filter 的两种使用
17、混用 select filter,无先后顺序
userDF.select("userID", "age").filter("age > 30").show(2)
userDF.filter("age > 30").select("userID", "age").show(2)
18、groupBy
scala> userDF.groupBy("age").count().show()
+---+-----+
|age|count|
+---+-----+
| 50| 496|
| 25| 2096|
| 56| 380|
| 1| 222|
| 35| 1193|
| 18| 1103|
| 45| 550|
+---+-----+
scala> userDF.groupBy("age").agg(count("gender")).show()
+---+-------------+
|age|count(gender)|
+---+-------------+
| 50| 496|
| 25| 2096|
| 56| 380|
| 1| 222|
| 35| 1193|
| 18| 1103|
| 45| 550|
+---+-------------+
scala> userDF.groupBy("age").agg(countDistinct("gender")).show()
+---+----------------------+
|age|count(DISTINCT gender)|
+---+----------------------+
| 50| 2|
| 25| 2|
| 56| 2|
| 1| 2|
| 35| 2|
| 18| 2|
| 45| 2|
+---+----------------------+
scala>
19、groupBy,agg 另一种写法
可用的聚集函数:
`avg`, `max`, `min`, `sum`, `count`
scala> userDF.groupBy("age").agg("gender"->"count","occupation"->"count").show()
+---+-------------+-----------------+
|age|count(gender)|count(occupation)|
+---+-------------+-----------------+
| 50| 496| 496|
| 25| 2096| 2096|
| 56| 380| 380|
| 1| 222| 222|
| 35| 1193| 1193|
| 18| 1103| 1103|
| 45| 550| 550|
+---+-------------+-----------------+
20、join

当 join 的列名不一样的时候用下面的方式,同时可以指定连接方式,如 inner

21、DF 创建临时表
不论是临时表还是全局表,application 关闭后,都会删除,如果想一直有效,那就用 saveAsTable 的方式存起来
userDataFrame.createOrReplaceTempView("users")
val groupedUsers = spark.sql("select gender, age, count(*) as n from users group by gender, age")
groupedUsers.show()

22、SparkSQL 的万能思路
第一步:得到DataFrame或Dataset val ds = ... 第二步:注册成临时表 ds.registerTempTable("xxx") 第三步:用SQL计算 spark.sql ("SELECT ...")

 浙公网安备 33010602011771号
浙公网安备 33010602011771号