常用RDD
只作为我个人笔记,没有过多解释
Transfor
map
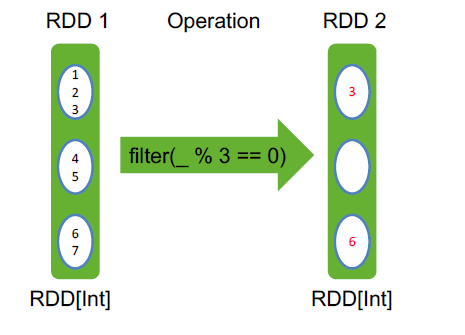
filter filter之后,依然有三个分区,第二个分区为空,但不会消失
flatMap
reduceByKey
groupByKey()
sortByKey()
val pets = sc.parallelize( List((“cat”, 1), (“dog”, 1), (“cat”, 2)) ) pets.reduceByKey(_ + _) // => {(cat, 3), (dog, 1)} pets.groupByKey() // => {(cat, Seq(1, 2)), (dog, Seq(1)} pets.sortByKey() // => {(cat, 1), (cat, 2), (dog, 1)}
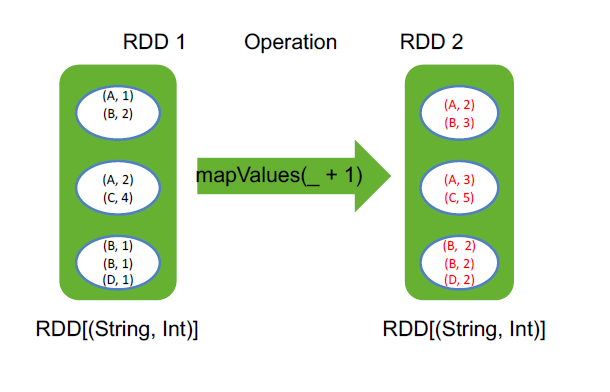
mapValues(_ + 1) mapvalues是忽略掉key,只把value进行操作
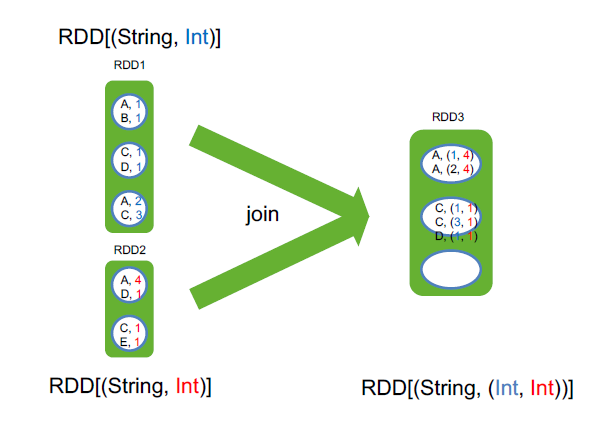
join RDD[(String, Int)].join(RDD[(String, Long)]) => RDD[(String, (Int, Long))]
join这两个rdd的value类型可以不一样,至于分区是根据hash来指定的
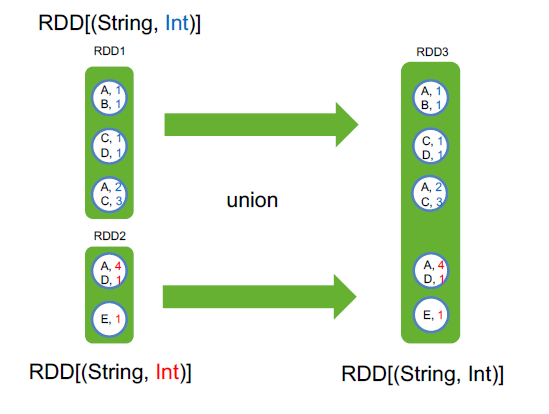
union
cogroup

用 cogroup 实现 join


sample() 从数据集中采样
cartesian() 求笛卡尔积
pipe() 传入一个外部程序
coalesce(口莱斯) 合并一个RDD的分区
rdd4 = rdd1 ++ rdd2 ++ rdd3
rdd4.coalesce(3)
rdd4.coalesce(3,true)
repartition 合并分区 rdd3.repartition(10)
并不是真的将分区合并,而是让一个task处理多个分区,如1k、10k、100k、1m、10m这五种文件,一共10w个,在hdfs上会有10w个block,取数据的时候会有10w个分区,同样有10w个task,这并不合适,如果能将这些分区合并,比如有10个task,每个task读1w个文件,速度会快很多,这个时候,有两种合并方式,coalesce和repartition
coalesce优点是简单粗暴,合并分区速度很快,缺点是很可能每个task所处理的数据不均匀。如果文件天生是比较均匀的,那coalesce合适
repartition优点是合并很均匀,用的是归并排序,缺点是计算开销比较大
举例,repartition合并的方法,10w个文件如何均匀的分成3个分区?
将每个文件均匀分成3分份,然后每一个分区从每个文件中拿一份
zip 将两个RDD的元素一一映射,合在一起
Action
collect()
take(2)
count()
reduce
foreach(println)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号