
从零学习node爬虫
node爬虫
node爬虫入门
批量爬取网站图片
实现步骤
- 发送
http请求获取整个网页内容 - 通过
cheerio库对网页内容进行分析 - 提取
img标签的src属性 - 使用
download库对图片进行批量下载
发送http请求
- 爬取目标网址 http://www.itheima.com/teacher.html#ajavaee
- 使用 http 模块请求网站地址
- 发送请求并获取详情获取网站源代码
// 批量爬取 http://www.itheima.com/teacher.html#ajavaee 网站中的老师图片
let http = require('http')
// 创建一个请求,此时不会真正的去发送请求
let request = http.request('http://www.itheima.com/teacher.html#ajavaee', res => {
// 异步响应数据
let chunsk = []
// 监听 data 事件,获取传递过来的数据片段并且拼接数据
res.on('data', c => chunsk.push(c))
// 监听end事件,数据获取完毕后触发
res.on('end',()=>{
// 使用一个Buffer来处理获取到的数据,并且按照 utf-8 处理解析字符串
console.log(Buffer.concat(chunsk).toString('utf-8'));
})
})
// 发送请求
request.end()
cheerio库简介
cheerio 可以在服务端像使用 jQuery 一样来解析 html,使用它可以非常简单的帮助我们解析通过 http 获取到html 字符串
安装
npm install cheerio --save
实例demo
const cheerio = require('cheerio');
const $ = cheerio.load('<h2 class="title">Hello world</h2>');
$('h2.title').text('Hello there!');
$('h2').addClass('welcome');
$.html();
//=> <html><head></head><body><h2 class="title welcome">Hello there!</h2></body></html>
使用cheerio解析html,获取图片中的src属性值
首先要将网址的域名作为一个常量抽离出来
const HOST = 'http://www.itheima.com/'
let cheerio = require('cheerio') // 引入 cheerio 解析 html
然后将获取到的网站代码用cheerio的load方法解析获取一个 $, 使用 $ 获取图片
// 监听end事件,数据获取完毕后触发
res.on('end', () => {
// 使用一个Buffer来处理获取到的数据,并且按照 utf-8 处理解析字符串
const HTMLStr = Buffer.concat(chunsk).toString('utf-8')
// 使用 cheerio 接收html字符串
const $ = cheerio.load(HTMLStr);
// 分析页面结构获取一个图片元素伪数组
// 使用 map 获取处理数组,获取所有 img 标签中的 src 属性值
let imgs = Array.prototype.map.call($('.maincon .clears li .main_pic img'), item => {
return HOST + $(item).attr('src')
})
console.log(imgs);
})
使用download批量下载图片
安装
npm install download --save
官方实例demo
const fs = require('fs');
const download = require('download');
(async () => {
await download('http://unicorn.com/foo.jpg', 'dist');
fs.writeFileSync('dist/foo.jpg', await download('http://unicorn.com/foo.jpg'));
download('unicorn.com/foo.jpg').pipe(fs.createWriteStream('dist/foo.jpg'));
await Promise.all([
'unicorn.com/foo.jpg',
'cats.com/dancing.gif'
].map(url => download(url, 'dist')));
})();
使用 Promise.all 批量下载我们获取到的图片
注意:请求的路径中不能包含中文,如果有中文需要用一个全局方法 encodeURL来对路径进行 base64 转义
let download = require('download')
// 使用 map 获取处理数组,获取所有 img 标签中的 src 属性值
let imgs = Array.prototype.map.call($('.maincon .clears li .main_pic img'), item => {
return encodeURI(HOST + $(item).attr('src'))
})
// 批量下载图片到 dist 文件夹中
Promise.all(imgs.map(url => download(url, 'dist'))).then(()=>{
console.log('图片获取成功');
})
encodeURL 方法
encodeURI() 函数可把字符串作为 URI 进行编码
console.log(encodeURI('http://百度.com')); // => http://%E7%99%BE%E5%BA%A6.com
http发送请求(伪造header)
使用http发送post请求时有时候需要携带header请求头才可以正常请求
http请求的第二个参数可以设置请求方式和请求头
- method 设置请求方法,不设置默认是 get
- headers 是一个对象,里面设置请求的头信息,需要用引号括起来
let http = require('https')
let request = http.request('https://weibo.com/ajax/statuses/hot_band', {
method: "get",
headers: {
"authority": "weibo.com",
"method": "GET",
"path": "/ajax/statuses/hot_band",
"scheme": "https",
"accept": "application/json, text/plain, */*",
"accept-encoding": "gzip, deflate, br",
"accept-language": "zh-CN,zh;q=0.9",
"cookie": "SUBP=0033WrSXqPxfM725Ws9jqgMF55529P9D9WWjZa3-O7Xh0ilHzUjr5bGu5JpX5KMhUgL.Fo-fS05XSKq7Sh52dJLoIpxqgCH8SC-RxF-4SEH8SCHFSE-4x5tt; SINAGLOBAL=8655939215617.323.1616200012427; UM_distinctid=178632914c4a0e-0c5c35f55fe3f8-3c634203-100200-178632914c58b9; ALF=1650518966; SSOLoginState=1618982966; SCF=AmdR3wyLr9BHJPHz43JVNdyeUIoju-GE2ECLznLbRe_e7p1bSHxE0b_cwSvRBWwBZoKQE3xnKfVDzl6BqldWTOI.; SUB=_2A25Ne8hnDeRhGeNL7FIV9SjMzzyIHXVu8L6vrDV8PUNbmtANLWTmkW9NSPtXpCiVfjEDU4GIDRCh1uRuK0D2il7X; wvr=6; wb_view_log_5570456040=1366*7681; _s_tentry=login.sina.com.cn; Apache=345608834203.7789.1618982971783; UOR=login.sina.com.cn,service.weibo.com,www.baidu.com; ULV=1618982971818:3:1:1:345608834203.7789.1618982971783:1616571340254; webim_unReadCount=%7B%22time%22%3A1618982990208%2C%22dm_pub_total%22%3A5%2C%22chat_group_client%22%3A0%2C%22chat_group_notice%22%3A0%2C%22allcountNum%22%3A79%2C%22msgbox%22%3A0%7D; XSRF-TOKEN=D6EqZZsYP2IFHxXs47IJQFlv; WBPSESS=chY5fvV0VYzufsU9gfOV8Hvaow8rhToTA9H35uW2CRhBnav2CB7tH6LS37WchRB6yzq7wkApy7JK43mOrl0mUIjfeWrk6RUnplJcpt-6DmKq8OqV1UGcwxm394UGfafg",
"referer": "https://weibo.com/hot/search",
"sec-fetch-dest": "empty",
"sec-fetch-mode": "cors",
"sec-fetch-site": "same-origin",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.135 Safari/537.36",
"x-requested-with": "XMLHttpRequest",
"x-xsrf-token": "D6EqZZsYP2IFHxXs47IJQFlv"
}
}, res => {
// 异步响应数据
let chunsk = []
// 监听 data 事件,获取传递过来的数据片段并且拼接数据
res.on('data', c => chunsk.push(c))
res.on('end', () => {
console.log(Buffer.concat(chunsk).toString('utf-8'));
})
})
request.end()
封装爬虫基础库
为了方便开发,考虑代码规范,建议使用 typescript 进行封装
准备环境
-
首先全局安装
typeScriptnpm install typescript -g -
使用
tsc初始化项目tsc --init初始化完成后自动创建一个
tsconfig.json文件,这个文件是typescript的配置文件 -
有了这个配置文件后可以吧我们编写的
ts代码编译成js代码,但是只有这个文件还不够,需要进一步配置才可以ts 的配置如下
{ "compilerOptions": { "target": "es2015", // 希望编译后的js是哪个版本,es2015表示es6 "module": "commonjs", // commonjs可以使用模块语法 "outDir": "./bin", // 编译后的代码输出录 "rootDir": "./src", // 从哪个入口开始编译代码 "strict": true, // 是否开启严格模式 "esModuleInterop": true, "skipLibCheck": true, "forceConsistentCasingInFileNames": true }, "include": [ "src/**/*" // 限制 ts 从哪个文件夹下编译,防止去编译别的文件夹下的文件 ], "exclude": [ "node_modules", // 设置要忽略哪些文件不用编译 "**/*.spec.ts" ] }
hello ts
在 src 目录下新建 hellots.ts
console.log('hello ts');
然后在项目根目录执行 tsc 命令开始编译,编译成功后会自动生成 bin 文件夹,bin 文件夹下有一个 hellots.js 文件,文件内容就是编译后的结果
"use strict";
console.log('hello ts');
创建一个祖宗类的基本功能
实现一个爬虫祖宗类
这个类接收一个对象,里面包含url,method,header
子类继承这个祖宗类,传入url自动开爬
class Spider {
constructor(options) {
}
}
设置接口
在 src 目录下新建 interfaceOptions/spiderOptions.ts 文件,这个文件用来设置这个祖宗类的参数字段类型和是否必填
// 导出接口参数字段
export default interface spiderOptions {
url: String, // url必填
method?: String, // 请求方式,非必填
Header?: Object // 请求头信息,非必填
}
导入接口并实现基础请求功能
// 导入请求模块
const http = require('https')
// 导入参数接口,用来限制接口类型
import spiderOptions from './interfaceOptions/spiderOptions'
// 实现一个爬虫祖宗类
// 这个类接收一个对象,里面包含url,method,header
// 子类继承这个祖宗类,传入url自动开爬
class Spider {
// 初始化参数值
options: spiderOptions
// 设置options参数的字段及类型;设置 method 默认值为 get
constructor(options: spiderOptions = { url: '', method: 'get' }) {
this.options = options
this.start()
}
// 设置爬取方法
start() {
// 创建请求
let requset = http.request(this.options.url, (res: any) => {
let chunks: any = []
res.on('data', (c: any) => chunks.push(c))
res.on('end', () => {
console.log(Buffer.concat(chunks).toString('utf-8'));
})
})
// 发送请求
requset.end()
}
}
// 导出祖宗类
export default Spider
ts环境下使用require时的坑
在使用 require 导入 https 时会有一个报错,这是因为我们是在 ts 的开发环境下编码,需要在开发环境依赖中添加@types/node包,打开命令提示工具执行以下这个命令即可
npm i --save-dev @types/node
新建测试文件查看功能是否正常
新建 src/test.ts 文件,导入 Spider 类,传入我们要爬取的 url 地址,查看功能是否正常
import Spider from './Spider'
new Spider({
url: 'https://www.jianshu.com/p/c8b86b09daf0'
})
切记编写好 ts 文件后我们不能直接运行,需要把ts文件编译成 js 文件才可以执行,在项目根目录下执行 tsc 开始编译代码,然后在 bin 文件夹下自动生成对应的 js 文件
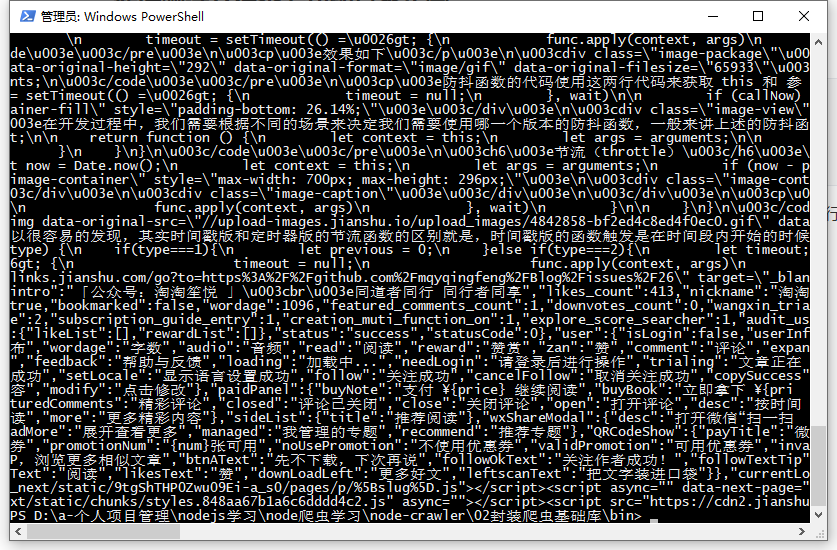
然后在 bin 目录下执行 node test.js,可以看到页面代码可以成功获取到
selenium基础使用
selenium简介
Selenium 是一个 Web 的自动化测试工具,类型像我们玩游戏用的按键精灵,它支持所
有主流的浏览器(包括 PhantomJS 这些无界面的浏览器)。
Selenium 可以根据我们的指令,让浏览器自动加载页面,获取需要的数据,甚至页面截屏,或者判断网站上某些动作是否发生。
selenium-webdriver下载
首先在 npm 官网搜索 selenium
https://www.npmjs.com/search?q=selenium
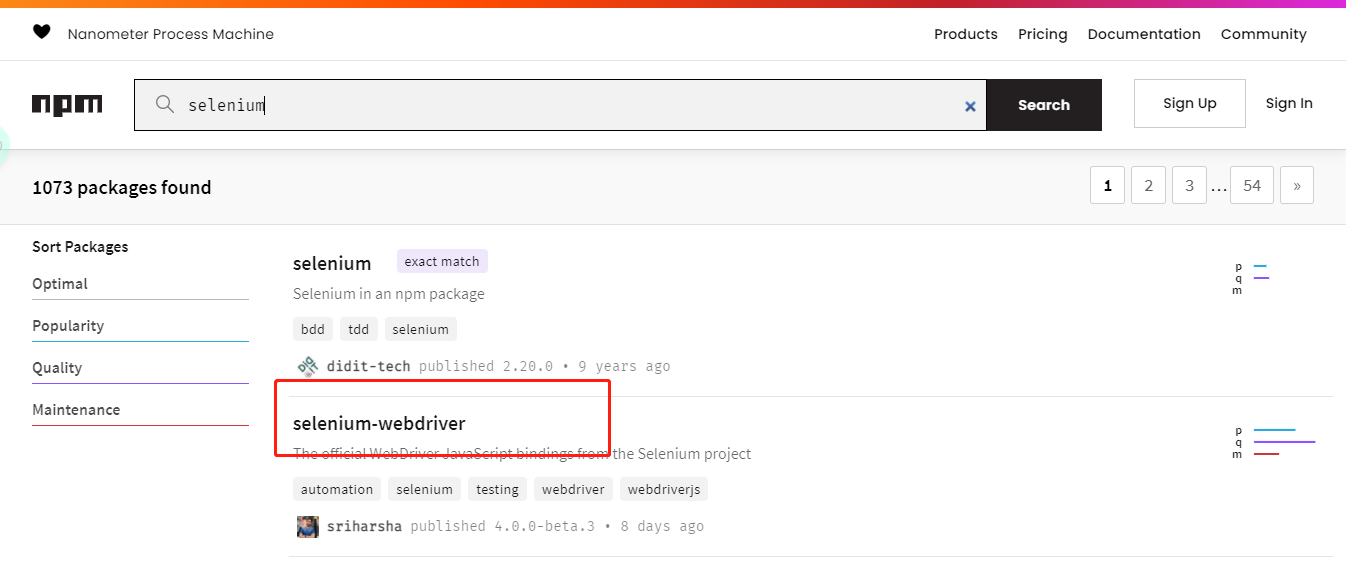
选择第二个点击进来,这里我们选择 Chrome 浏览器
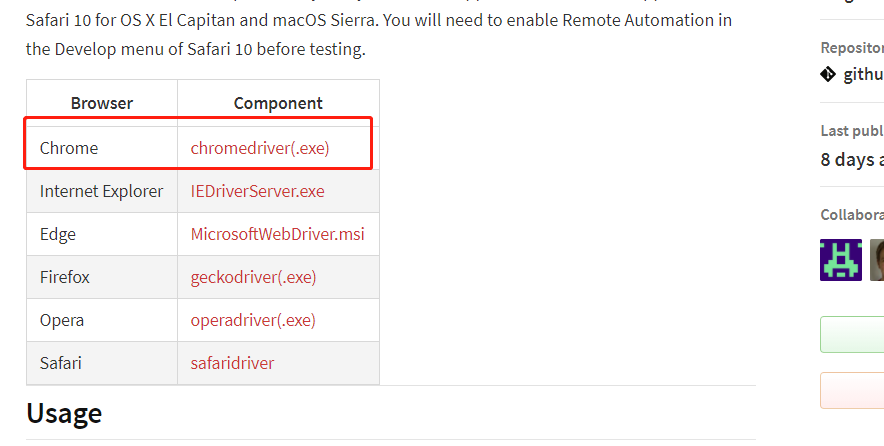
点击 chromedriver(.ext)会进入到一个好多版本的下载页面,此时不要着急,我们先查看我们浏览器的版本,去下载对应的版本。 这时打开 Chrome 浏览器的设置页面,查看我们浏览器的版本号
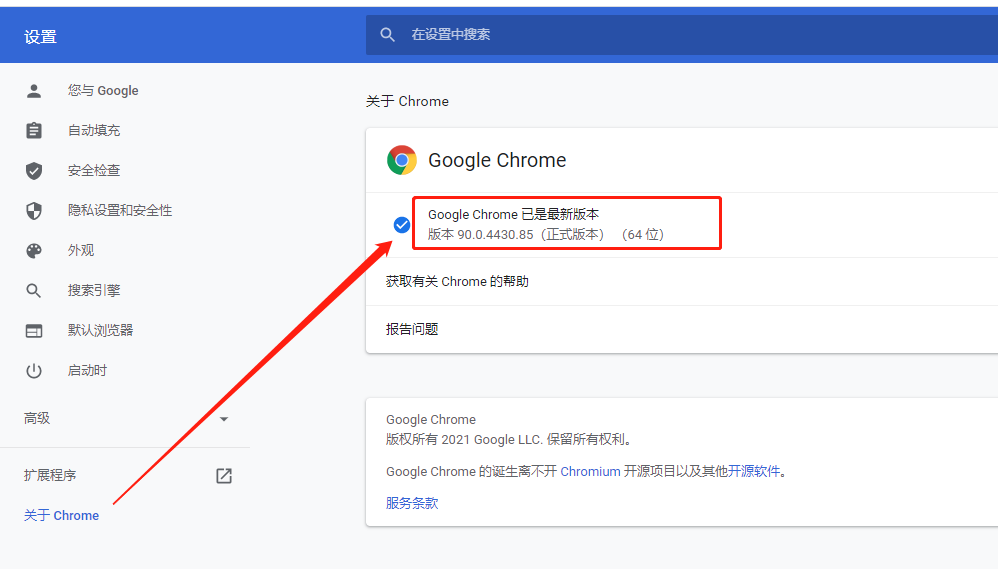
然后在刚才打开的页面选择对应的版本,这里我的浏览器版本是 90.0.4430.85,那么我们要找的版本是至少精确到 4430 的版本
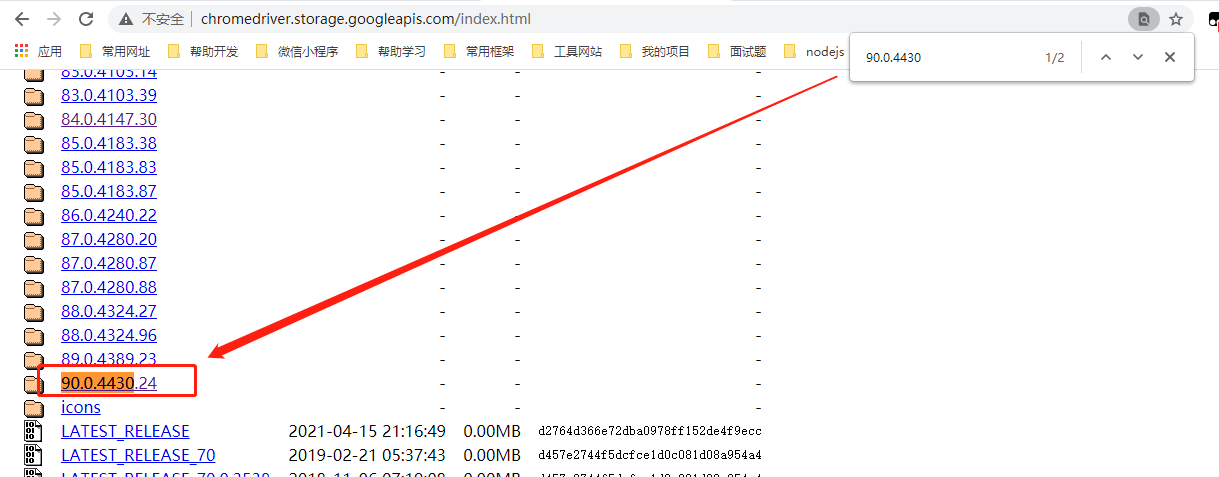
找到之后点击进来选择对应的平台压缩包进行下载
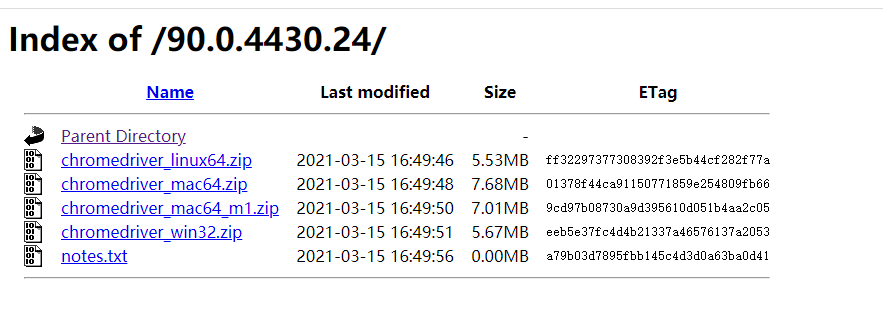
选择下载目录是我们项目的根目录
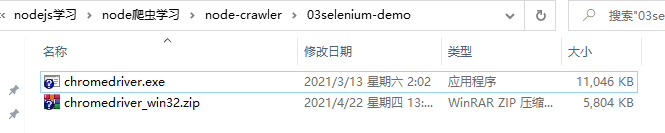
下载好之后解压出来可以看到一个 exe 文件,这个文件我们要通过写代码的方式来运行它
使用selenium实现自动打开百度并搜索
首先根据官方介绍安装依赖包
npm install selenium-webdriver
新建 hello-selenium.js
// 从 selenium-webdriver 包中导入相关依赖
const {
Builder,
By,
Key,
until
} = require('selenium-webdriver');
// 声明一个自执行方法
(async function example() {
// 实例化 Chrome 浏览器
let driver = await new Builder().forBrowser('chrome').build();
try {
// 访问百度
await driver.get('https://www.baidu.com');
// 打开百度后找到搜索框的id,百度搜索框的id是 kw,并输入哔哩哔哩,然后回车开始查询
await driver.findElement(By.id('kw')).sendKeys('哔哩哔哩', Key.RETURN);
// 等待1秒后验证网站标题是否为:哔哩哔哩_百度搜索
await driver.wait(until.titleIs('哔哩哔哩_百度搜索'), 1000);
} finally {
// 退出浏览器,开发阶段不用退出
// await driver.quit();
}
})();
selenium API
https://www.selenium.dev/selenium/docs/api/javascript/index.html
设置无头浏览器
无头浏览器表示不打开新窗口,在后台默默爬取
let chrome = require('selenium-webdriver/chrome');
let {Builder,By} = require('selenium-webdriver');
let driver = new Builder()
.forBrowser('chrome')
.setChromeOptions(new chrome.Options().headless())
.build();
关于 chrome 浏览器的更多设置,请查看 API 文档
自动打开浏览器输入关键字进行查询
下面代码实现了自动打开拉钩官网,选择上海站并搜索前端
// 从 selenium-webdriver 包中导入相关依赖
const {
Builder,
By,
Key,
until
} = require('selenium-webdriver');
// 声明一个自执行方法
(async function example() {
// 实例化 Chrome 浏览器
let driver = await new Builder().forBrowser('chrome').build();
// 打开拉钩官网
await driver.get('https://www.lagou.com/');
// 勾选上海站
await driver.findElement(By.css("div#changeCityBox ul.clearfix li:nth-child(2)")).click()
// 搜索前端并回车
await driver.findElement(By.id('search_input')).sendKeys('前端', Key.RETURN);
})();
获取拉钩网站的第一页职位信息并保存到数组中
使用 driver.findElements 可以获取到批量元素
然后循环每个职位元素,分析每个信息的结构,获取元素中的文字
// 搜索前端并回车
await driver.findElement(By.id('search_input')).sendKeys('前端', Key.RETURN);
// 获取到职位列表集合
let items = await driver.findElements(By.css("div#s_position_list>ul.item_con_list li"))
// 存放职位信息
let jobList = []
// 遍历每个职位,获取职位的详细信息
for (let i = 0; i < items.length; i++) {
let item = items[i]
// 获取职位名称
let jobName = await item.findElement(By.css(".position>.p_top>a>h3")).getText()
// 获取工作地址
let jobAddress = await item.findElement(By.css(".position>.p_top>a>span>em")).getText()
// 获取职位链接
let positionLink = await item.findElement(By.css(".position>.p_top>a")).getAttribute('href')
// 获取职位发布时间
let formatTime = await item.findElement(By.css(".position>.p_top>.format-time")).getText()
// 职位薪资
let money = await item.findElement(By.css(".position>.p_bot>.li_b_l>.money")).getText()
// 职位要求
let requirement = await item.findElement(By.css(".position>.p_bot>.li_b_l")).getText()
// 由于要求没有标签包裹,所以需要替换一下
requirement = requirement.replace(money, "")
// 获取工作内容
let jobContent = await item.findElement(By.css("div.list_item_bot>.li_b_l")).getText()
// 获取公司福利
let jobwelfare = await item.findElement(By.css("div.list_item_bot>.li_b_r")).getText()
// 获取公司名称
let companyname = await item.findElement(By.css("div.company>div.company_name>a")).getText()
// 获取公司网址
let companylink = await item.findElement(By.css("div.company>div.company_name>a")).getAttribute('href')
// 获取公司规模
let industry = await item.findElement(By.css("div.company>.industry")).getText()
jobList.push({
jobName,
jobAddress,
positionLink,
formatTime,
money,
requirement,
jobContent,
jobwelfare,
companyname,
companylink,
industry
})
}
console.log(jobList);
运行结果

分页爬取信息思路
- 首先将爬取网站信息的方法提取出来
- 声明一个当前页码和最大页码
- 首先先爬取第一页的数据,如果当前页爬取成功后,让当前页码 ++
- 如果当前页码小于等于最大页码,则说明没有爬完,应该点击下一页,递归调用爬取方法
常见错误分析
这个错误是由于页面数据还有加载出来,我们的爬虫就去根据我们编写的 css 结构去获取数据而导致的
StaleElementReferenceError: stale element reference: element is not attached to the page document

解决这种错误我们采用一个 while 循环来重复调用爬取接口,在每次循环后我们定义一个 netError 变量,默认是一个 true,表示我们这次循环没有错误发生, 然后用一个 try catch 来包裹住爬取的方法,如果发生错误会进入到 catch 中,此时设置 notError 为 false,然后在 finally 方法中去判断这个变量,finally 方法是除了 try catch 之外的另外一个方法,这个方法无论对错都会执行,所以在 finally 方法中判断 notError 是否为 true ,如果为 true 表示本次请求没有错误,则 break 退出 while 循环,否则进行 while 循环判断页面数据是否加载成功
分页爬取拉钩网站数据的完整代码
const fs = require('fs')
// 从 selenium-webdriver 包中导入相关依赖
const {
Builder,
By,
Key,
until
} = require('selenium-webdriver');
// 存放职位信息
let jobList = []
// 定义初始页码
let currentTag = 1;
// 定义最大页码
let maxTag;
// 实例化 Chrome 浏览器
let driver = new Builder().forBrowser('chrome').build();
// 声明一个自执行方法
(async function example() {
// 打开拉钩官网
await driver.get('https://www.lagou.com/');
// 勾选上海站
await driver.findElement(By.css("div#changeCityBox ul.clearfix li:nth-child(2)")).click()
// 搜索前端并回车
await driver.findElement(By.id('search_input')).sendKeys('前端', Key.RETURN);
// 获取最大页码
maxTag = await driver.findElement(By.css("div.page-number>.totalNum")).getText()
// 执行爬取方法
start()
})();
// 将爬取方法抽离出来
async function start() {
// 只有正确时才打印
console.log(`------当前正在获取第${currentTag}页的数据,共${maxTag}页------`);
while (true) {
// 每次进来先声明本次循环没有错误,没有错误则会退出 while 循环,不会陷入死循环
let netError = true
try {
// 获取到职位列表集合
let items = await driver.findElements(By.css("div#s_position_list>ul.item_con_list li"))
// 遍历每个职位,获取职位的详细信息
for (let i = 0; i < items.length; i++) {
let item = items[i]
// 获取职位名称
let jobName = await item.findElement(By.css(".position>.p_top>a>h3")).getText()
// 获取工作地址
let jobAddress = await item.findElement(By.css(".position>.p_top>a>span>em")).getText()
// 获取职位链接
let positionLink = await item.findElement(By.css(".position>.p_top>a")).getAttribute('href')
// 获取职位发布时间
let formatTime = await item.findElement(By.css(".position>.p_top>.format-time")).getText()
// 职位薪资
let money = await item.findElement(By.css(".position>.p_bot>.li_b_l>.money")).getText()
// 职位要求
let requirement = await item.findElement(By.css(".position>.p_bot>.li_b_l")).getText()
// 由于要求没有标签包裹,所以需要替换一下
requirement = requirement.replace(money, "")
// 获取工作内容
let jobContent = await item.findElement(By.css("div.list_item_bot>.li_b_l")).getText()
// 获取公司福利
let jobwelfare = await item.findElement(By.css("div.list_item_bot>.li_b_r")).getText()
// 获取公司名称
let companyname = await item.findElement(By.css("div.company>div.company_name>a")).getText()
// 获取公司网址
let companylink = await item.findElement(By.css("div.company>div.company_name>a")).getAttribute('href')
// 获取公司规模
let industry = await item.findElement(By.css("div.company>.industry")).getText()
jobList.push({
jobName,
jobAddress,
positionLink,
formatTime,
money,
requirement,
jobContent,
jobwelfare,
companyname,
companylink,
industry
})
}
// 爬取完第一页后让当前页码加1
currentTag++
// 如果当亲的页码小于等于最大页码,则说明没有爬取结束继续爬下一页数据
if (currentTag <= 3) {
// 执行点击下一页的操作
await driver.findElement(By.css(".item_con_pager>.pager_container>.pager_next")).click()
// 递归执行爬取方法
await start()
} else {
fs.writeFile('./bin/joblist.txt', JSON.stringify(jobList), (err, data) => {
// 保存爬取到的数据信息到TXT文件中
console.log('数据获取完毕');
})
}
} catch (error) {
// 如果有错误,则让循环状态变成 false ,继续下一次循环
if (error) netError = false
} finally {
// finally 表示无论对错都会执行
// 每次循环的时候就来判断对错,如果没有错误则 break 退出 while 循环
if (netError) break;
}
}
}
将数据保存到 xlsx 文件中
node-xlsx
node-xlsx 可以将一个二维数组转成 buffer 类型数据的第三方依赖包,将生成的buffer数据写入到 xlsx 文件中即可获得一个有数据的 xlsx 文件
安装
npm install node-xlsx --save
使用
注意:写入的数据必须是一个二维数组,二维数组里面的第一个元素为 xlsx 文件的表头
import xlsx from 'node-xlsx';
// Or var xlsx = require('node-xlsx').default;
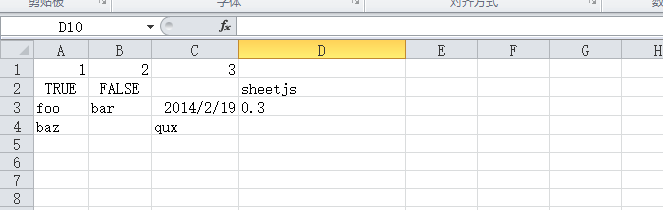
const data = [[1, 2, 3], [true, false, null, 'sheetjs'], ['foo', 'bar', new Date('2014-02-19T14:30Z'), '0.3'], ['baz', null, 'qux']];
var buffer = xlsx.build([{name: "mySheetName", data: data}]); // Returns a buffer
设置列宽
列宽 10 表示一列可以展示 5 个汉字,10个英文字母,超出的部分将会被遮挡住
import xlsx from 'node-xlsx';
// Or var xlsx = require('node-xlsx').default;
const data = [[1, 2, 3], [true, false, null, 'sheetjs'], ['foo', 'bar', new Date('2014-02-19T14:30Z'), '0.3'], ['baz', null, 'qux']]
const options = {'!cols': [{ wch: 6 }, { wch: 7 }, { wch: 10 }, { wch: 20 } ]};
var buffer = xlsx.build([{name: "mySheetName", data: data}], options); // Returns a buffer
将 buffer 写到 xlsx 文件中
var xlsx = require('node-xlsx').default;
var fs = require('fs')
// 要写入的数据
const data = [[1, 2, 3], [true, false, null, 'sheetjs'], ['foo', 'bar', new Date('2014-02-19T14:30Z'), '0.3'], ['baz', null, 'qux']]
// 设置每列的宽度
const options = {'!cols': [{ wch: 6 }, { wch: 7 }, { wch: 10 }, { wch: 20 } ]};
// 生成 buffer 数据
var buffer = xlsx.build([{name: "mySheetName", data: data}], options);
// 写入数据
fs.writeFile('./bin/test.xlsx',buffer,(err,res)=>{
if(err) return console.log('写入失败');
console.log('写入成功');
})

打开 test.xlsx 文件查看文件内容
改造爬取拉钩网的案例
写一个公共的生成 xlsx 的方法,这个方法接收我们爬取到的数据,然后将数据处理后存入 xlsx 文件中,方便我们查看
提取公共的生成 xlsx 方法
新建 utli/node-create-excel.js 文件,导出一个方法,这个方法接收一个一维数组
const xlsx = require('node-xlsx').default;
const fs = require('fs')
const path = require('path')
// 接收一个数组
// 将数组转成二维数组
// 使用 node-xlsx 将二维数组转成文件流
// 将文件流写入excel中
module.exports = function (joblist) {
// 1.将一维数组转成二维数组
let twoDList = [];
joblist.forEach(item => twoDList.push(Object.values(item)))
// 2.设置excel表头
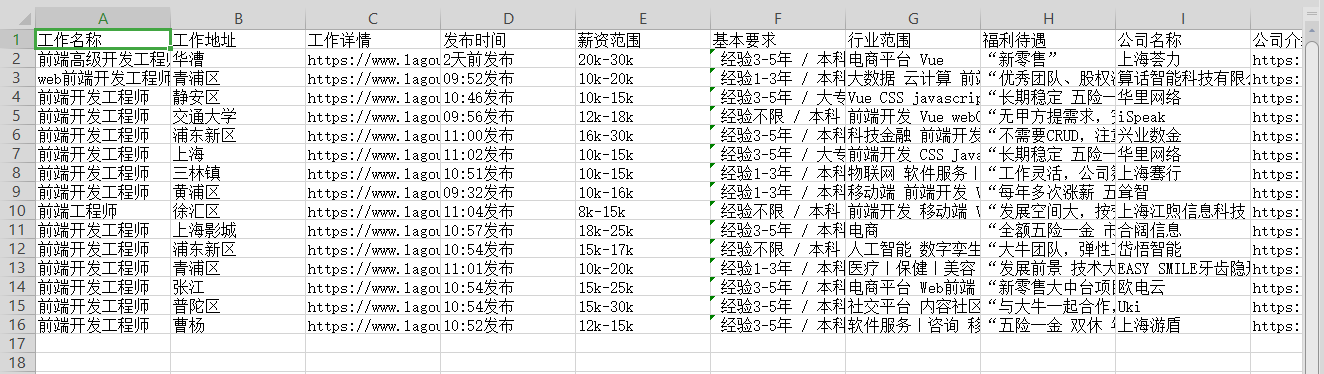
let xlsxTitle = [
'工作名称', '工作地址', '工作详情', '发布时间', '薪资范围', '基本要求',
'行业范围', '福利待遇', '公司名称', '公司介绍', '公司规模'
]
// 3.将表头插入二维数据中
twoDList.unshift(xlsxTitle)
// 4.设置列宽
let excelTitleWidht = {
'!cols': [{
wch: 16
}, {
wch: 16
}, {
wch: 16
}, {
wch: 16
}, {
wch: 16
}, {
wch: 16
}, {
wch: 16
}, {
wch: 16
}, {
wch: 16
}, {
wch: 16
}, {
wch: 16
}]
};
// 5.生成文件流
let excelBuffer = xlsx.build([{
name: "mySheetName",
data: twoDList
}], excelTitleWidht);
console.log(twoDList);
// 6.写入文件流
fs.writeFile(path.join(__dirname, "../bin/joblist.xlsx"), excelBuffer, (err, res) => {
if (err) return console.log(err);
console.log('文件写入成功')
})
}
爬取到数据后调用方法生成xlsx
在代码顶部导入方法
// 将获取到的数据存到excel中
const writeExcel = require('./util/node-create-excel')
修改原有代码,将原本写到 txt 文件的方法替换成调用生成 xlsx 方法。这里为了方便测试,只让爬虫获取第一页的数据,可根据实例需求获取前几页的数据或者所有页数据
// 如果当亲的页码小于等于最大页码,则说明没有爬取结束继续爬下一页数据
if (currentTag <= 1) {
// 执行点击下一页的操作
await driver.findElement(By.css(".item_con_pager>.pager_container>.pager_next")).click()
// 递归执行爬取方法
await start()
} else {
// 保存爬取到的数据信息到TXT文件中
// fs.writeFile('./bin/joblist.txt', JSON.stringify(jobList), (err, data) => {
// console.log('数据获取完毕');
// })
writeExcel(jobList)
}
执行代码查看运行效果

打开文件查看获取到的数据
完。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号