机器学习(Machine Learning)- 吴恩达(Andrew Ng) 学习笔记(十五)
Anomaly detection 异常检测
Problem motivation
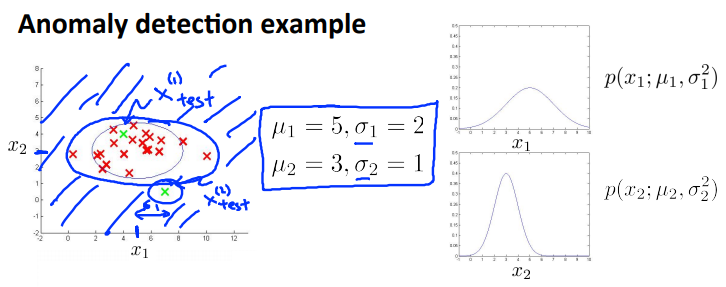
Anomaly detection example 异常检测的例子
Aircraft engine features: \(x_1\) = heat generated, \(x_2\) = vibration intensity, ...
以飞机发动机功能为例,在做质量检测时可以测量的飞机发动机功能,如:热量,振动强度……
Dataset:\(\{x^{(1)},x^{(2)},\dots,x^{(m)}\}\)
获取相关特征的数据集,绘制图像如图所示。
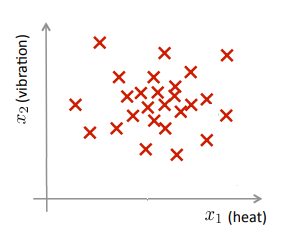
由上,我们可定义异常检测如下:
假设得到一个新的飞机引擎从生产线上做出,其特征为\(x_{test}\),我们希望知道这个新的飞机引擎是否有某种异常。
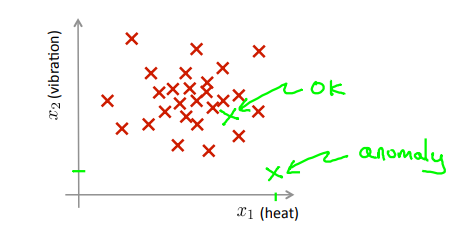
Density estimation 密度估算
Dataset:\(\{x^{(1)},x^{(2)},\dots,x^{(m)}\}\). Is \(x_{test}\) anomalous?
有数据集,如何判断\(x_{test}\)是否异常?
对给定的训练集,对数据建立一个模型\(p(x)\),即对特征变量\(x\)的分布概率建模,接下来对新的特征变量进行检验,其中\(\epsilon\)为阈值:
- 若\(p(x_{test}) \lt \epsilon\),则将其标记为异常。
- 若\(p(x_{test}) \ge \epsilon\),则将其标记为正常。
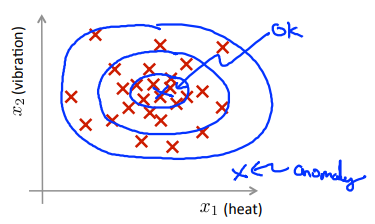
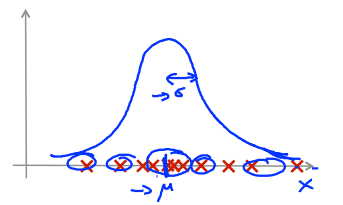
总结:在中心区域的点有很大的概率是正常的,离中心稍微远一点的点概率会小一些,更远的地方的点概率将会更小,再远的将成为异常点。
Anomaly detection example 异常检测的例子
- Fraud detection: 诈骗检测
- \(x^{(i)}\) = features of user \(i\)'s activities. 用户的第\(i\)个活动特征
- Model \(p(x)\) from data. 数据的模型\(p(x)\)
- Identify unusual users by checking which have \(p(x) \lt \epsilon\). 通过\(p(x)\)检测用户是否正常
- Manufacturing 工业生产领域(如:飞机引擎等)
- Monitoring computers in a data center. 数据中心的计算机监控
- \(x^{(i)}\) = features of machine \(i\), 机器的第\(i\)个特征
- \(x_1\) = memory use of machine \(i\), 内存消耗
- \(x_2\) = number of disk accesses/sec, 硬盘访问量
- \(x_3\) = CPU load, CPU负载
- \(x_4\) = CPU load/network traffic, CPU负载与网络流量的比值
- \(\dots\)
Gaussian distribution
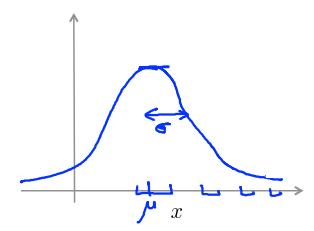
Gaussian (Normal) distribution 高斯(正态)分布
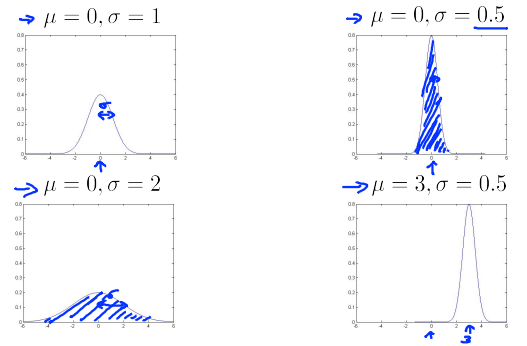
参数:\(\mu\)为期望,控制曲线中心;\(\sigma\)为标准差,控制曲线宽度。
公式:
图形:
Gaussian distribution example
Parameter estimation 参数估计
什么是参数估计问题?
Dataset: \(\{x^{(1)},x^{(2)},\dots,x^{(m)}\}\),\(x^{(i)} \in R\).
有\(m\)个样本,它们都是实数,在下图中标记出了整个数据集,图中的横轴是\(x\)轴,其取值分布广泛。猜测这些样本来自一个高斯分布的总体,每一个样本\(x_i\)服从高斯分布,即\(x^{(i)}\) ~ \(N(\mu,\sigma^2)\),但不知道具体的\(\mu\)和\(\sigma\)的值。
参数估计问题就是给定数据集,估算出\(\mu\)和\(\sigma\)的值。根据\(x^{(i)}\)的分布情况画出蓝色的曲线如图所示。
计算\(\mu\)和\(\sigma\)的标准公式:
Algorithm
Anomaly detection algorithm
-
Choose features \(x_i\) that you think might be indicative of anomalous examples. 选特征
-
Fit parameters \(\mu_1,\dots,\mu_n,\sigma_1^2,\dots,\sigma_n^2\). 拟合参数
-
Give new example \(x\), compute \(p(x)\):
\[p(x) = \prod_{j=1}^np(x_j;\mu_j,\sigma_j^2) = \prod^n_{j=1}\frac{1}{\sqrt{2\pi}\sigma_j}exp(-\frac{(x_j-\mu_j)^2}{2\sigma_j^2}) \]Anomaly if \(p(x) \lt \epsilon\). 计算\(p(x)\)并判断是否异常
Anomaly detection example
-
两个特征的训练集以及特征的分布情况。
-
三维图表示的密度估计函数,\(z\)轴为根据两个特征值所估计的\(p(x)\)值。
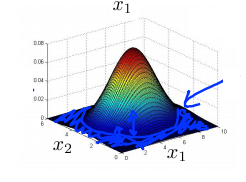
我们选择一个\(\epsilon\),将\(𝑝(𝑥) = \epsilon\)作为我们的判定边界,当\(𝑝(𝑥) \gt \epsilon\)时预测数据为正常数据,
否则为异常。
Developing and evaluating an anomaly detection system
开发与评价一个异常检测系统
The importance of real-number evaluation
When developing a learning algorithm (choosing features, ect.), making decisions is much easier if we have a way of evaluating our learning algorithm.
当你尝试为特定应用开发学习算法时,你需要做出很多选择,如选择特征值。假如我们有一种评估学习算法的方法,那么决策将会容易很多。
Assume we have some labeled data, of anomalous and non-anomalous examples. (\(y = 0\) if normal, \(y = 1\) if anomalous).
Training set: \(x^{(1)},x^{(2)},\dots,x^{(m)}\) (assume normal examples/not anomalous)
Cross validation set: \((x_{cv}^{(1)},y_{cv}^{(1)}),\dots(x_{cv}^{(m_{cv})},y_{cv}^{(m_{cv})}))\)
Test set: \((x_{test}^{(1)},y_{test}^{(1)}),\dots,(x_{test}^{(m_{test})},y_{test}^{(m_{test})})\)
假设我们有一些带标签的数据,标签为异常和非异常两种(\(y = 0\)为正常,\(y = 1\)为异常)。有对应的训练集、交叉验证集和测试集。
Aircraft engines motivating example
10000 good (normal) engines, 20 flawed engines (anomalous)
样本有10000正常的引擎和20有缺陷的引擎。
-
分法1:(推荐)
Training set: 6000 good engines
CV: 2000 good engines (\(y = 0\)), 10 anomalous (\(y = 1\))
Test: 2000 good engines (\(y = 0\)), 10 anomalous (\(y = 1\))
-
分法2:(交叉验证集和测试集使用了相同的样本,不推荐)
Training set: 6000 good engines
CV: 4000 good engines (\(y = 0\)), 10 anomalous (\(y = 1\))
Test: 4000 good engines (\(y = 0\)), 10 anomalous (\(y = 1\))
Algorithm evaluation
异常检测算法是一个非监督学习算法,意味着我们无法根据结果变量\(y\)的值来告诉我们数据是否真的是异常的。我们需要另一种方法来帮助检验算法是否有效。当我们开发一个异常检测系统时,我们从带标记(异常或正常)的数据着手,我们从其中选择一部分正常数据用于构建训练集,然后用剩下的正常数据和异常数据混合的数据构成交叉检验集和测试集。
具体的评价方法:
-
Fit model \(p(x)\) on training set \(\{x^{(1)},\dots,x^{(m)} \}\) 根据训练集数据,我们估计特征的平均值和方差并构建\(p(x)\)函数。
-
On a cross validation/test example \(x\), predict \(y = \left\{\begin{aligned} 1 && if\ p(x) \lt \epsilon\ (anomaly) \\ 0 && if\ p(x) \ge \epsilon\ \ \ (normal) \end{aligned} \right.\).
对交叉检验集/测试集,我们尝试使用不同的\(\epsilon\)值作为阀值,并预测数据是否异常,根据\(F_1\)值或者查准率与召回率的比例来选择\(\epsilon\)。
-
Possible evaluation metrics: 可能的评估指标
-
True positive, false positive, false negative, true negative
-
Precision/Recall 查准率/召回率
-
\(F_1\) -score \(F_1\)积分
Can also use cross validation set to choose parameter \(\epsilon\).
选出\(\epsilon\)后,针对测试集进行预测,计算异常检验系统的\(F_1\)值,或者查准率与召回率之比。
-
Anomaly detection vs. supervised learning
异常检测与监督学习的对比
| Anomaly detection | supervised learning |
|---|---|
| Very small number of positive examples (\(y = 1\)) (0-20 is common); large number of negative (\(y = 0\)) examples. | Large number of positive and negative examples |
| Many different "type" of anomalies. Hard for any algorithm to learn from positive examples what the anomalies look like; future anomalies may look nothing like any of the anomalous examples we've seen so far. | Enough positive examples for algorithm to get a sense of what positive examples are like, future positive examples likely to be similar to ones in training set. |
例子
| Anomaly detection | supervised learning |
|---|---|
| Fraud detection | Email spam classification |
| Manufacturing (e.g. aircraft engines) | Weather prediction (sunny/raint/est). |
| Monitoring machines in a data center | Cancer classification |
总结:
正例足够多就用监督学习,不够就用错误检测。
Choosing what features to use
对于异常检测算法,使用特征是至关重要的,下面谈谈如何选择特征。
Non-gaussian features
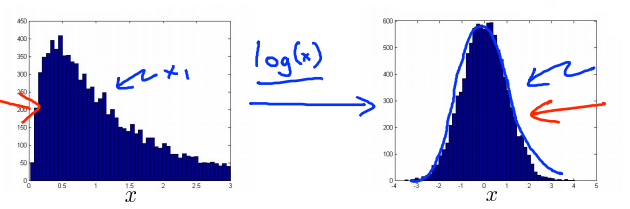
在异常检测算法中我们做的事情之一就是使用正态(高斯)分布来对特征向量建模,但是有些数据并不太符合高斯分布,虽然算法也常常可以正常运行,但效果不好。
可以采用参数修改的方法对数据进行转换,使其看起来更像高斯分布。如:使用对数函数,\(x = log(x + c)\),其中\(c\)为非负常数;使用指数函数,\(x = x^c\),其中\(0 \lt c \lt 1\)。
Error analysis for anomaly detection
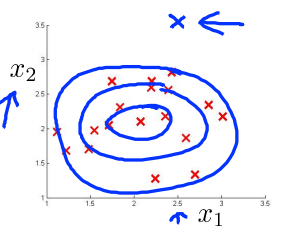
一个常见的问题是一些异常的数据可能也会有较高的\(p(x)\)值,因而被算法认为是正常的。这种情况下误差分析能够帮助我们,我们可以分析那些被算法错误预测为正常的数据,观察能否找出一些问题。我们可能能从问题中发现我们需要增加一些新的特征,增加这些新特征后获得的新算法能够帮助我们更好地进行异常检测。
例如下图中,\(x\)为异常样例,当只有一个特征值\(x_1\)时会区分错误,加一个特征值\(x_2\)后就可以正确区分。
Monitoring computers in a data center
我们也可以通过将一些相关的特征进行组合,来获得一些新的更好的特征(异常数据的该特征值异常地大或小)。
例如,在检测数据中心的计算机状况的例子中,我们可以用CPU负载与网络通信量的比例作为一个新的特征,如果该值异常地大,便有可能意味着该服务器是陷入了一些问题中。
总结:
- 如何选择特征,以及对特征进行一些小小的转换,让数据更像正态分布,然后再把数据输入异常检测算法。
- 建立特征时,进行的误差分析的方法,来捕捉各种异常的可能。
Multivariate Gaussian distribution
Motivating example: Monitoring machines in a data center
Multivariate Gaussian (Normal) distribution
在一般的高斯分布模型中,我们计算\(p(x)\)的方法是:通过分别计算每个特征对应的几率然后将其累乘起来。
在多元高斯分布模型中,我们将构建特征的协方差矩阵,用所有的特征一起来计算\(p(x)\)。
其中\(\mu\)相当于每个正态分布的对称轴,是一个一维向量;\(\Sigma\)是协方差矩阵。
Multivariate Gaussian (Normal) examples
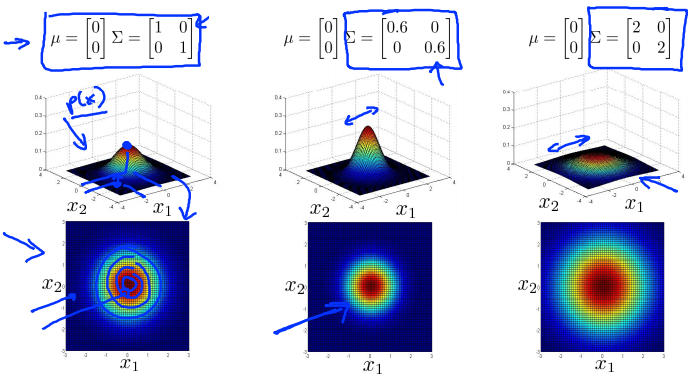
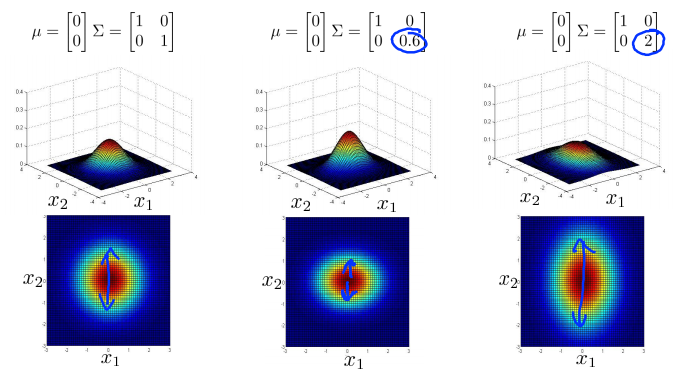
- 普通的高斯分布,中心取\(\left[ \begin{matrix} 0 \\ 0 \end{matrix} \right]\),\(\Sigma\)取单位矩阵,作为对照。此时面的高度为\(p(x)\)的值,在\(x_1 = x_2 = 0\)时取最大值。下面的图是用等高线画的图,颜色越深表示值越大。
- 缩小\(\Sigma\),因为面以下的区域要等于1(概率分布的积分必须等于1),所以鼓包的宽度会减小,高度会增加一点。
- 相对地,增加\(\Sigma\)时,会得到一个更宽更扁的高斯分布。
- 分别减小和增加\(\Sigma\)第一个特征变量\(x_1\)的方差,同时保持第二个特征变量\(x_2\)的方差不变,会减小和增加第一个特征变量的变化范围。
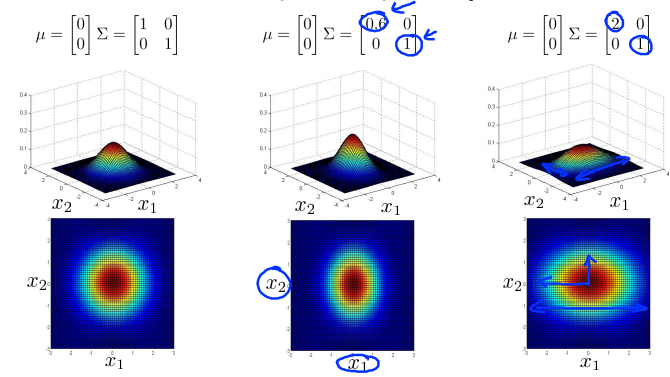
- 类似地,保持\(\Sigma\)第一个特征变量\(x_1\)的方差不变,分别增大和减小第二个特征变量\(x_2\)的方差,会分别增大和减小第二个特征变量的变化范围。
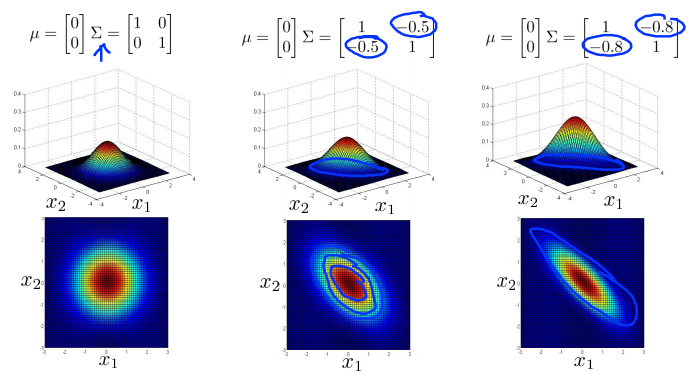
- 保持\(\Sigma\)对角线上的元素不变,增加副对角线上的元素,即增加两者之间的正相关性,会得到一个更加窄和高的沿着\(x = y\)这条线的分布。
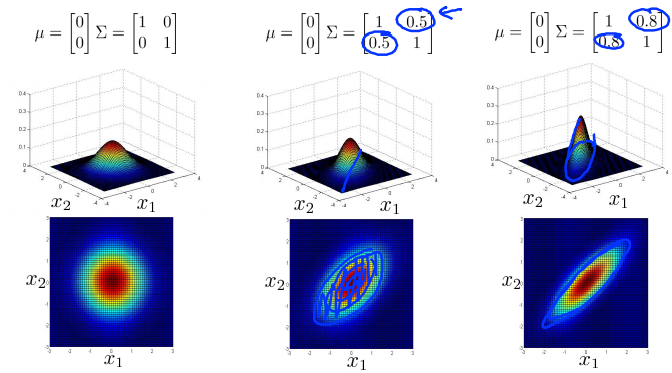
- 相对地,减小副对角线上的元素,即增加两者之间的负相关性,会得到一个沿着\(x = -y\)这条线的分布。
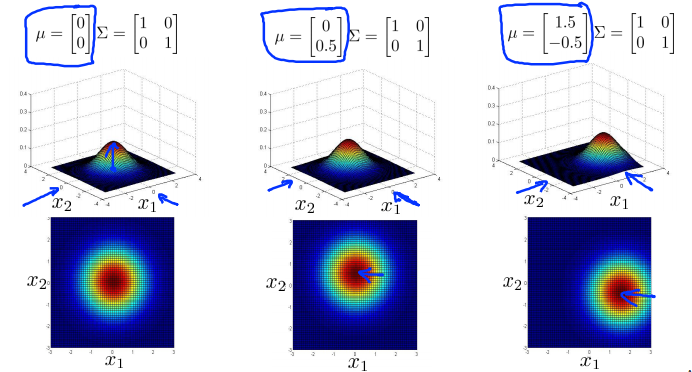
- 改变平均参数\(\mu\),会改变分布的峰值(中心)。
Anomaly detection using the multivariate Gaussian distribution
Multivariate Gaussian (Normal) distribution
Parameter \(\mu\),\(\Sigma\)
Parameter fitting:
Given training set \(\{x^{(1)},x^{(2)},\dots,x^{(m)} \}\)
\(\mu = \frac{1}{m}\sum^m_{i=1}x^{(i)}\), \(\Sigma = \frac{1}{m}\sum^m_{i=1}(x^{(i) - \mu})(x^{(i)} - \mu)^T\).
Anomaly detection with the multivariate Gaussian
使用多元高斯分布的异常检测
- Fit model \(p(x)\) by setting \(\mu = \frac{1}{m}\sum^m_{i=1}x^{(i)}\), \(\Sigma = \frac{1}{m}\sum^m_{i=1}(x^{(i) - \mu})(x^{(i)} - \mu)^T\). 拟合模型\(p(x)\)。
- Given a new example \(x\), compute \(p(x;\mu,\Sigma) = \frac{1}{{(2\pi)}^{\frac{n}{2}}|\Sigma|^{\frac{1}{2}}}exp(-\frac{1}{2}(x-\mu)^T\Sigma^{-1}(x-\mu))\).Flag an anomaly if \(p(x) \lt \epsilon\). 对于新给出的样例,计算\(p(x)\)的值,如果\(p(x) \lt \epsilon\),则对其进行标记。
Relationship to original model
Original model: \(p(x) = p(x_1;\mu_1,\sigma_1^2) \times p(x_2;\mu_2,\sigma_2^2) \times \dots \times p(x_n;\mu_n,\sigma_n^2)\).
Corresponds to multivariate Gaussian: \(p(x;\mu,\Sigma) = \frac{1}{{(2\pi)}^{\frac{n}{2}}|\Sigma|^{\frac{1}{2}}}exp(-\frac{1}{2}(x-\mu)^T\Sigma^{-1}(x-\mu))\) where \(\Sigma = \left[ \begin{matrix} \sigma_1^2 & 0 & \dots & 0 \\ 0 & \sigma_2^2 & \dots & 0 \\ \dots & \dots & \dots & \dots \\ 0 & 0 & \dots & \sigma_n^2 \end{matrix} \right]\).
| Original model | Multivariate Gaussian |
|---|---|
| Manually create features to capture anomalies where \(x_1\),\(x_2\) take unusual combinations of values | Automatically captures correlations between features |
| Computationally cheaper (alternatively, scales better to large) | Computationally more expensive |
| OK even if \(m\) (training set size) is small | Must have \(m \gt n\) or else \(\Sigma\) is non-invertible |
传统高斯分布与多元高斯分布的关系:当多元高斯分布的协方差为对角矩阵时,就是传统高斯分布。
| 原高斯分布模型 | 多元高斯分布模型 |
|---|---|
| 不能捕捉特征值之间的相关性,但可以通过将特征值之间进行组合的方法来解决 | 自动捕捉特征值之间的相关性 |
| 计算代价低,能适应大规模的特征 | 计算代价高 |
| 训练集较小时也能使用 | 必须要有\(m \gt n\)(通常需要\(m \gt 10n\)),或者协方差矩阵不可逆(特征值冗余也会导致协方差矩阵不可逆) |
总结:一般来说,原高斯分布模型用得更多一些,如果有两个特征相关,可以尝试创建一个新特征来描述它俩的关系,实在不行或者如上表右边的情况,才用多元高斯分布模型。
