机器学习(Machine Learning)- 吴恩达(Andrew Ng) 学习笔记(十二)
Support Vector Machines 支持向量机
支持向量机是监督学习算法的一种,在学习复杂的非线性方程时提供了一种更为清晰、更为强大的学习方式。
Optimization objective
Alternative view of logistic regression
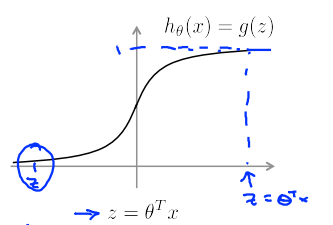
先介绍一下逻辑回归
\(h_\theta(x) = \frac{1}{1 + e^{-\theta^Tx}}\)
- If \(y = 1\), we want \(h_\theta(x) \approx 1\), \(\theta^Tx >> 0\)
- If \(y = 0\), we want \(h_\theta(x) \approx 0\), \(\theta^Tx << 0\)
Cost of example: \(-(y\ logh_\theta(x) + (1-y)log(1-h_\theta(x)))\) = \(-ylog\frac{1}{1+e^{-\theta^Tx}} - (1-y)log(1-\frac{1}{1+e^{-\theta^Tx}}))\) 每个样本都对总的代价函数有影响,下图为具体关系。
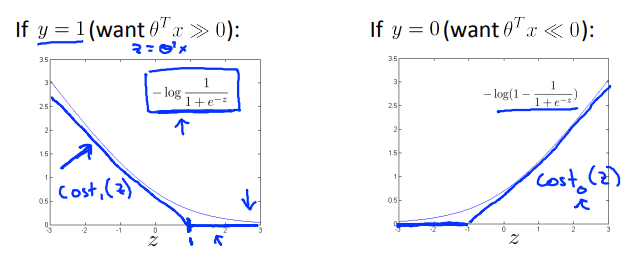
扩展:从代价函数开始修改,实现支持向量机。
如图所示,在左边的图中取\(z = 1\)点,画出要用的代价函数(看起来和逻辑回归的曲线有点相似,但它的是直线),新画的线将作为\(y = 1\)的前提下的代价函数,记为\(cost_1(z)\)。\(y = 0\)的情况类似,记为\(cost_0(z)\)。
Support vector machine
Logistic regression:
Support vector machine:
区别:
-
SVM去掉了常数(对最值的选取无影响)
-
通过参数来决定更关心第一项的优化还是第二项的优化。
逻辑回归中:\(A + \lambda B\),如果给定\(\lambda\)是一个非常大的值,意味着B有更大的权重;
SVM中:\(CA+B\),通过将C设定为一个很小的值,等同于给B比A更大的权重。
-
SVM的假设函数:
\[h_\theta(x) \left\{ \begin{aligned} 1 && if \ \theta^Tx \ge 0 \\ 0 && otherwise \end{aligned} \right. \]
Large Margin Intuition
Support Vector Machine
下图是支持向量机模型的代价函数,左边是用于正样本的关于\(𝑧\)的代价函数\(cos𝑡_1(𝑧)\),右边是用于负样本的关于\(𝑧\)的代价函数\(cos𝑡_0(𝑧)\)。
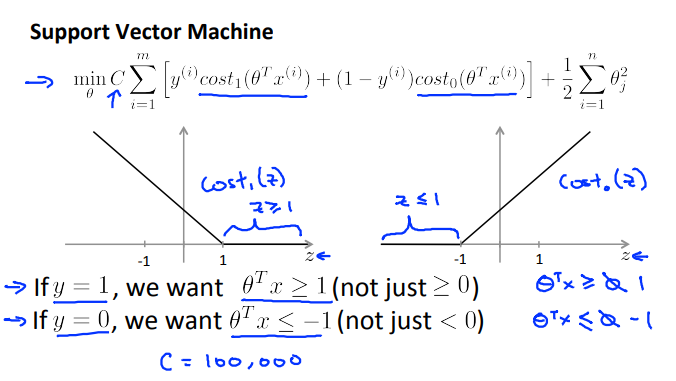
那么,最小化这些代价函数的必要条件是什么呢?
-
如果\(𝑦 = 1\),则只有在\(𝑧 \ge 1\)时,代价函数\(cos𝑡_1(𝑧)\)才等于\(0\)。即对于一个正样本,我们希望\(\theta^𝑇𝑥 \ge 1\)。
-
如果\(𝑦 = 0\),则只有在\(𝑧 \le −1\)时,代价函数\(cos𝑡_0(𝑧)\)才等于\(0\)。即对于一个负样本,我们希望\(\theta^𝑇𝑥 \le -1\)。
事实上,对于一个正样本\(𝑦 = 1\),仅仅要求\(\theta^𝑇𝑥 \ge 0\),就能将该样本恰当分出。因为如果\(\theta^𝑇𝑥>0\)的话,模型代价函数值为0。同样,对于一个负样本,则仅需\(\theta^Tx \le 0\)就会将负例正确分离。
但是支持向量机的要求更高,它不仅要求能正确分开输入的样本,即不仅要求\(\theta^Tx \gt 0\),而且要比\(0\)值大很多,如\(\theta^Tx \ge 1\)。对于负样本,也要求比\(0\)小很多,如\(\theta^Tx \le-1\),这就相当于在支持向量机中嵌入了一个额外的安全因子,或者说安全的间距因子。
那么,在支持向量机中,这个因子会导致什么结果?接下来会考虑一个特例:将这个常数\(𝐶\)设置成一个非常大的值,如\(C = 100000\),观察支持向量机会给出什么结果。
SVM Decision Boundary
如果\(𝐶\)非常大,则最小化代价函数的时候,我们将会很希望找到一个使第一项为\(0\)的最优解。因此,让我们尝试在代价项的第一项为\(0\)的情形下理解该优化问题。
- 当训练样本标签\(y = 1\)时,想令第一项为\(0\),则需要找到一个\(\Theta\),使\(\Theta^Tx \ge 1\)。
- 当训练样本标签\(y = 0\)时,想令第一项为\(0\),则需要找到一个\(\Theta\),使\(\Theta^Tx \le -1\)。
由上可得,当最小化关于变量\(\Theta\)的函数时,会得到十分有趣的决策边界,具体如下。
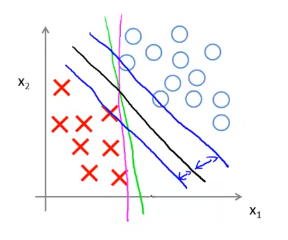
Linearly separable case: 线性可分离的情况
下图所示的数据集同时存在正负样本,是线性可分的,有多种分法。SVM最终会选择黑色的那个,相较于粉色和绿色,它在分离正负样本上显得更好。因为他有最大的间距。
画出两条额外的蓝线,可以看出黑色的决策界和训练样本之间有更大的最短距离,而粉线和绿线离样本就非常近,在分离样本时表现就比黑线差。
这个间距就叫做支持向量机的间距,也是支持向量机具有鲁棒性的原因,因为他努力用一个最大间距来分离样本。由此支持向量机有时也被称为大间距分类器。
Large margin classifier in presence of outlines
我们将这个大间距分类器中的正则化因子常数\(𝐶\)设置的非常大,因此对下图所示的一个数据集,也许
我们将选择黑线这样的决策界,从而最大间距地分离开正样本和负样本。
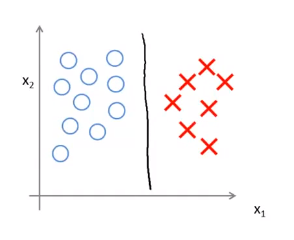
事实上,支持向量机现在要比这个大间距分类器所体现得更成熟,尤其是当你使用大间距分类器的时候,你的学习算法会受异常点的影响。比如我们加入一个额外的正样本,如图所示。此时,为了将样本用最大间距分开,也许我最终会得到一条粉色的决策界。但是仅仅基于一个异常值,仅仅基于一个样本,就将我的决策界从这条黑线变到这条粉线,这实在是不明智的。
而如果正则化参数\(𝐶\)设置的非常大(事实上这正是支持向量机将会做的),它会将决策界从黑线变到了粉线,但是如果\(𝐶\)设置的小一点,则你最终会得到这条黑线。
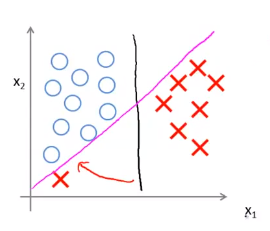
如果数据不是线性可分的,在下图正样本堆中有些负样本,或者在负样本堆中有些正样本,则支持向量机也会将它们恰当分开。
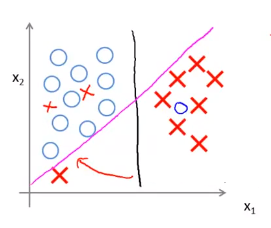
这里\(C\)的作用类似于\(\frac{1}{\lambda}\)(\(\lambda\)是正则化参数)。上述只是𝐶非常大的情形(或者等价地 \(\lambda\) 非常小的情形)最终会得到类似粉线这样的决策界。但是实际上应用支持向量机的时候,当\(𝐶\)不是非常大的时候,它可以忽略掉一些异常点的影响,得到更好的决策界。甚至当数据不是线性可分的时候,支持向量机也可以给出好的结果。
The mathematics behind large margin classification (optional)
SVM大边界分类背后的数学
Vector Inner Product
\(u = \left[ \begin{matrix} u_0 \\ u_1 \end{matrix} \right]\),\(v = \left[ \begin{matrix} v_0 \\ v_1 \end{matrix} \right]\)。
\(||u|| = \sqrt{u_1^2+u_2^2}\):向量\(u\)的长度。
\(p\):\(v\)在\(u\)上的投影。
\(u^Tv = p||u|| = u_1v_1+u_2v_2 = v^Tu\):两向量的内积。
SVM Decosion Boundary
公式:
简化::假设\(\theta_0 = 0\),$ n = 2$。
--> \(min_\theta\frac{1}{2}\sum_{j=1}^n\theta_j^2 = \frac{1}{2}(\theta_1^2+\theta_2^2) = \frac{1}{2}(\sqrt{\theta_1^2+\theta_2^2})^2 = \frac{1}{2}||\theta||^2\)。
记\(\theta = \left[ \begin{matrix} \theta_1 \\ \theta_2 \end{matrix} \right]\),知\(\theta^Tx^{(i)} = p^{(i)}||\theta|| = \theta_1x_1^{(i)}+\theta_2x_2^{(i)}\)。
问题:考虑如下样本,支持向量机会做出什么样的选择?
-
如下图左所示,此时不是一个好的选择,因为它间距很小,决策界离训练样本很近。
具体来看,参数\(\theta\)是和决策界正交的,\(\theta_0 = 0\)意味着\(\theta\)对应的决策界过原点\((0,0)\)。从正负样本中各选出一个样本来,记为\(x_1\)和\(x_2\),将其分别投影到\(\theta\)上,并将其与决策边界的距离记为\(p^{(1)}\)和\(p^{(2)}\),可以发现\(p^{(1)}\)和\(p^{(2)}\)都很小。因此在考察优化目标函数时,对于正样本,需要\(p^{(1)} ||\theta|| \ge 1\),\(p^{(1)}\)很小,则需要\(||\theta||\)很大;类似的,对于负样本而言,\(p^{(2)}\)很小,则需要\(||\theta||\)很大。
但我们的目标是希望参数\(\theta\)的范数是小的,所以此时的决策边界不是一个好的选择。
-
如下图右所示,选择的边界是中间那条垂直的直线,对应\(\theta\)的方向是水平的。
继续选取一正一负两样本\(x^{(1)}\)和\(x^{(2)}\),做出在\(\theta\)上的投影到决策边界的举例\(p^{(1)}\)和\(p^{(2)}\)。此时的\(p^{(1)}\)和\(p^{(2)}\)要大一些了。
对于同样的约束\(p^{(1)}||\theta|| \gt 1\),由于\(p^{(1)}\)变大,\(\theta\)就可变小很多。
-
综上,想令\(\theta\)变小,从而令\(\theta^2\)变小,支持向量机就会选右侧的决策界。
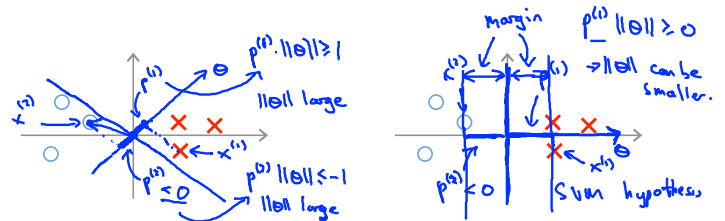
总结:SVM通过极大化\(p^{(i)}\)的值达到最小化目标函数的目的。
备注:上述推导使用了简化假设参数\(\theta_0 = 0\),这意味着我们让决策界通过原点。若\(\theta_0\)不为0,即决策界不通过原点,此时是上述推导的一个推广,结论同样成立,
Kernels I 核函数
Non-linear Decision Boundary
回顾我们之前讨论过的使用高阶多项式模型来解决无法用直线进行分隔的分类问题,为了获得下图所示的判断边界,我们的模型可能是\(\theta_0+\theta_1x_1+\theta_2x_2+\theta_3x_1x_2+\theta_4x_1^2+\theta_5x_2^2+\ldots\ge0\)的形式,可以用一系列新的特征\(f\)来代替模型中的每一项,如\(f_1 = x_1\),\(f_2 = x_2\),\(f_3 = x_1x_2\),\(f_4 = x_1^2\),\(f_5 = x_2^2\),得到\(h_\theta(x) = \theta_1f_1+\theta_2f_2+\ldots+\theta_nf_n\)。
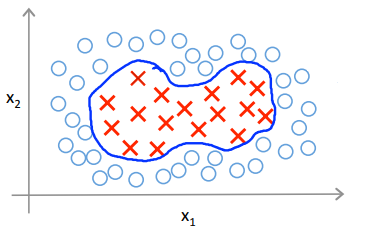
除了对原有特征进行组合外,有无更好的方法来构造\(f_1\),\(f_2\),\(f_3\)?
Kernel
Given \(x\), compute new feature depending on proximity to landmarks \(l^{(1)},l^{(2)},l^{(3)}\).
给定训练实例\(x\),利用预选的特征点 \(l^{(1)},l^{(2)},l^{(3)}\)的近似程度来选取新的特征\(f_1,f_2,f_3\)。
例如:
- \(f_1 = similarity(x, l^{(1)}) = exp(-\frac{||x-l^{(1)}||^2}{2\sigma^2})\)
- \(f_2 = similarity(x, l^{(2)}) = exp(-\frac{||x-l^{(2)}||^2}{2\sigma^2})\)
- \(f_3 = similarity(x, l^{(3)}) = exp(-\frac{||x-l^{(2)}||^2}{2\sigma^2})\)
其中\(similarity(x, l^{(i)})\)称为核函数,在此例中是一个高斯核函数。(与正态分布无实际上的关系,只是看起来像而已)
Kernels and Similarity
\(f_1 = similarity(x, l^{(1)}) = exp(-\frac{||x-l^{(1)}||^2}{2\sigma^2}) = exp(-\frac{\sum^n_{j=1}(x_j-l_j^{(1)})^2}{2\sigma^2})\)
特征点\(l^{(i)}\)的作用是什么?
- If \(x \approx l^{(1)}\) 如果\(x\)与标记点非常近,则\(f_1 \approx exp(\frac{0^2}{2\sigma^2}) = exp(0) = 1\)
- If \(x\) is far from \(l^{(1)}\) 如果\(x\)与标记点很远,则\(f_1 = exp(-\frac{(large \ number)^2}{2\sigma^2}) \approx 0\)
- \(f_2\)、\(f_3\)同理。
总结:给定一个训练实例\(x\),我们就能基于之前给的标记点,计算出三个新的特征变量。
Example
已知\(l^{(1)} = \left[ \begin{matrix} 3 \\ 5 \end{matrix} \right]\),\(f_1 = exp(-\frac{||x-l^{(1)}||^2}{2\sigma^2})\),\(\sigma\)值为\(1,0.5,3\)时的3D曲面图和等值线图如下所示。
3D曲面图的纵坐标为\(f_i\)的值,两个横坐标为\(x_1\)和\(x_2\)。
等值线图的横纵坐标分别为\(x_1\)和\(x_2\)。
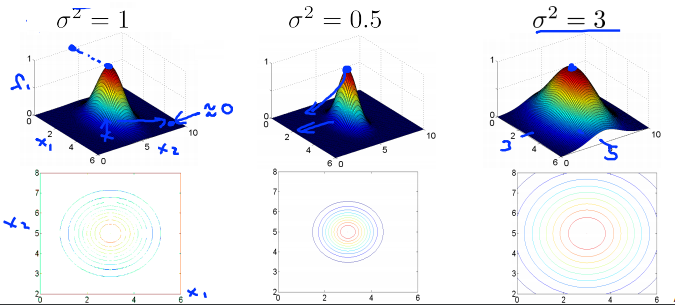
将\(\sigma\)的值进行改变,会发现核函数看起来还是相似的。
- 在减小\(\sigma\)值时,凸起的宽度变窄了,等值线图也收缩了一些,特征值降到\(0\)的速度会变得很快。
- 增大\(\sigma\)值,特征值减小的速度变慢了、
预测函数:\(h_\theta(x) = \theta_0 + \theta_1f_1 + \theta_2f_2 + \theta_3f_3\),Predict "1" when \(h_\theta(x) \ge 0\).
例子:假设得到的预测函数的参数为\(\theta_0 = -0.5\),\(\theta_1 = \theta_2 = 1\),\(\theta_3 = 0\)。
- \(l^{(1)}\)点处\(f_1 \approx 1\),\(f_2 \approx 0\),\(f_3 \approx 0\)。此时\(h_\theta(x) = 0.5 \gt 0\),预测此点\(y = 1\)。
- \(l^{(2)}\)点处\(f_1 \approx 0\),\(f_2 \approx 0\),\(f_3 \approx 0\)。此时\(h_\theta(x) = -0.5 \lt 0\),预测此点\(y = 0\)。
Kernels II
Choosing the landmarks 选取标记点
根据训练集的选取标记点,每个标记点与样本点的位置都精确对应。
SVM with Kernels
Given \((x^{(1)},y^{(1)})\),\((x^{(2)},y^{(2)})\),\(\dots\),\((x^{(n)},y^{(n)})\)。
Choose \(l^{(1)} = x^{(1)}\),\(l^{(2)} = x^{(2)}\),\(\dots\),\(l^{(m)} = x^{(m)}\)。
给定\(m\)个训练样本,选取与\(m\)个样本精确一致的位置作为标记点。
Given example \(x\):
For training example \((x^{(i)},y^{(i)})\):
将它们都写为向量形式:\(f = \left[ \begin{matrix} f_0 \\ f_1 \\ f_2 \\ \vdots \\ f_m \end{matrix} \right]\),\(f_0 = 1\);\(x^{(i)} \in R^{(n+1)}\) --> \(f^{(i)} = \left[ \begin{matrix} f_0^{(i)} \\ f_1^{(i)} \\ f_2^{(i)} \\ \vdots \\ f_m^{(i)} \end{matrix} \right]\)。
Hypothesos:
Given \(x\), compute features \(f \in R^{m+1}\). Predict \(y = 1\) if \(\theta^Tf \ge 0\).
其中$\theta^Tf = \theta_0f_0 + \theta_1f_1 + \dots + \theta_mf_m $.
这样知道参数\(\theta\)后就能做出预测了。
Training:
如何求解\(\theta\)?
对代价函数进行修改\(\theta^Tx^{(i)}\),变为\(\theta^Tf^{(i)}\),\(\sum_{j=1}^m\theta_j^2\)可被重写为\(\theta^T\theta\)(忽略\(\theta_0\)这一项的时候)。
大多数支持向量机在实现的时候,其实是用$$\theta^TM\theta$$替换掉\(\theta^T\theta\),其中\(M\)是根据我们选择的核函数而不同的一个矩阵。这是参数向量\(\theta\)的变尺度版本,这种变化和核函数相关,这样做可以适应超大的训练集。
其他:
理论上讲,我们也可以在逻辑回归中使用核函数,但是上面使用\(𝑀\)来简化计算的方法不适用于逻辑回归,因此计算将非常耗费时间。
在此,我们不介绍最小化支持向量机的代价函数的方法,你可以使用现有的软件包(如liblinear,libsvm等)。在使用这些软件包最小化我们的代价函数之前,我们通常需要编写核函数,并且如果我们使用高斯核函数,那么在使用之前进行特征缩放是非常必要的。
另外,支持向量机也可以不使用核函数,不使用核函数又称为线性核函数(linear kernel),当我们不采用非常复杂的函数,或者我们的训练集特征非常多而实例非常少的时候,可以采用这种不带核函数的支持向量机。
下面是支持向量机的两个参数\(𝐶\)和\(\sigma\)的影响:
\(𝐶\) = \(\frac{1 }{\lambda}\)
- Large \(C\): Lower bias, high variance. \(𝐶\) 较大时,相当于\(\lambda\)较小,可能会导致过拟合,高方差。
- Small \(C\): Higher bias, low variance. \(𝐶\) 较小时,相当于\(\lambda\)较大,可能会导致低拟合,高偏差。
- Large \(\sigma^2\): Features \(f_i\) vary more smoothly. High bias, lower variance. \(\sigma\)大时,特征值\(f_i\)会更平滑,导致低方差,高偏差。
- Small \(\sigma^2\): Features \(f_i\) vary less smoothly. Lower bias, higher variance. \(\sigma\)小时,特征值\(f_i\)会更粗糙,导致低偏差,高方差。
Using an SVM
Use SVM software package (e.g. liblinear, libsvm, ...) to solve for parameters \(\theta\). 用软件包来求解参数\(\theta\)。
Need to specify: 虽然直接调用别人写好的软件,但还是要做的
- Choice of parameter \(C\). 参数\(C\)的选择
- Choice of kernel (similarity function): 选择内核参数或想要使用的相似函数
E.g. No kernel ("linear kernel") Predict "\(y = 1\)" if \(\theta^Tx \ge 0\).
这个函数不需要内核参数(也称为线性核函数)。如果有大量特征值\(n\),训练的样本数\(m\)却很小,因为没有足够的数据而不会去拟合一个非常复杂的非线性函数(防止过拟合),若想得到一个判定边界,选择拟合一个线性函数是个不错的选择。可以决定不适用内核参数或一些被叫做线性内核函数的等价物。
Guessian kernel:
\(f_i = exp(-\frac{||x-l^{(i)}||^2}{2\sigma^2})\), where \(l^{(i)} = x^{(i)}\). No need to choose \(\sigma^2\).
对于内核函数的第二个选择是可以构建一个高斯内核函数。如果选择这个,需要选择的另一个参数\(\sigma^2\)。
当特征值\(n\)的值很小,训练集\(m\)的值很大(如\(n = 2\),训练集很大),要用内核函数去拟合一个更加复杂的非线性判定边界时,高斯内核函数是一个不错的选择。
Kernel (similarity) functions:
自己动手实现的高斯内核函数:
function f = kernel (x1, x2)
f = exp(-(x1 - x2) * (x1 - x2) / (2 * sigma * sigma))
return
Note: Do perform feature scaling before using the Gaussian kernel.
注意:在使用高斯内核函数之前将这些特征变量的大小按比例归一化。
Other choices of kernel
Note: Not all similarity functions \(similarity(x, l)\) make valid kernels. (Need to satisfy technical condition called "Mercer's Theorem" to make sure SVM packages' optimizations run correctly, and do not diverge).
注意:不是你提出来的所有核函数都是有效的。
无论是线性核函数,高斯核函数还是其它一些核函数,他们都需要满足一个技术条件,叫做“莫塞尔定理”。原因为不论是支持向量机算法还是SVM的实现函数,都有许多熟练的数值优化技巧,为了有效的求解参数\(\theta\),在最初的设想里,这些决策都用以将我们的注意力限制在可以满足莫塞尔定理的核函数上。这个定理所做的是确保所有的SVM包、软件包能够用打雷的优化方法并很快得到参数\(\theta\)。
Many off-the-shelf kernels avaliable: 其他可以现成使用的核函数
-
Polynomial kernel 多项式核函数,实际上有两个参数:要加上什么样的参数和多项式的次数。
\(x\)和\(l\)之间的相似值可定义为 \(k(x, l) = (x^Tl + constant)^{degree}\),如:\((x^Tl)^2\)、\((x^Tl)^3\)、\((x^Tl + 1)^3\)、\((x^Tl + 5)^4\)…… -
More esoteric: String kernel, chi-square kernel, histogram intersection kernel, ...
更深奥的:字符串核函数(输入数据是文本字符串或其他类型的字符串时有可能会用到),卡方核函数,直方相交核函数...
Multi-class classification
考虑一个多分类问题,你有\(K\)个类别,\(y \in \{1,2,3,...,K\}\),输出的是一些在你的多个类别间恰当的判定边界。下图所示的分类问题中,有4个类别。
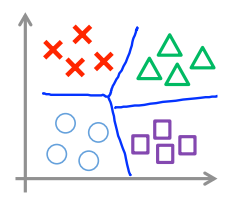
Many SVM packages already have build-in multi-class classification functionality. 许多SVM包已经建立了多分类函数
Otherwise, use one-vs.-all method. (Train \(K\) SVMs, one to distinguish \(y = i\) from the rest, for \(i = 1,2,...,K\)), get \(\theta^{(1)}\), \(\theta^{(2)}\),..., \(\theta^{(k)}\). Pick class \(i\) with largest \((\theta^{(i)})^Tx\). 否则,可以使用一对多方法(训练\(K\)个支持向量机),得到\(\theta\),从中选出最优解。
Logistic regression vs. SVMs
$n = $ number of features (\(x \in R^{(n + 1)}\)), $m = $ number of training examples.
-
If \(n\) is large (relative to \(m\)): Use
logistic regression, orSVM without a kernel ("linear kernel"). -
If \(n\) is small, \(m\) is intermediate: Use
SVM with Gaussian kernel. -
If \(n\) is small, \(m\) is large:
Create/add more features, then uselogistic regressionorSVM without a kernel. -
Neural network likely to work well for most of thesr settings, but may be slower to train.
