机器学习(Machine Learning)- 吴恩达(Andrew Ng) 学习笔记(八)
Neural Networks: Representation 神经网络
Non-linear hypotheses 非线性分类器
为什么要研究神经网络?先看几个机器学习问题的例子。
1. 考虑这个监督学习分类的问题,我们已经有了对应的训练集。
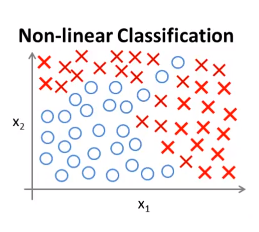
如果利用逻辑回归算法来解决这个问题,首先要构造一个包含很多非线性项的逻辑回归函数。如:\(g(\Theta_0 + \Theta_1x_1 + \Theta_2x_2 + \Theta_3x_1x_2 + \Theta_4x_1^2x_2 + \Theta_5x_1^3x_2 + \Theta_6x_1x_2^2 + \ldots)\)。当多项式项数足够多时我们可能会得到一个分开正样本和负样本的分界线。
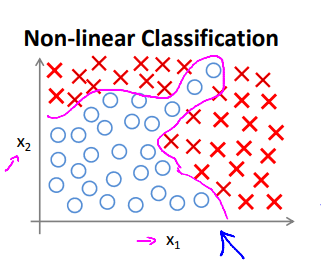
当只有两项时,这种方法确实可以得到不错的结果,因为你可以把\(x_1、x_2\)的组合都包含到多项式中。
2. 但是许多复杂的机器学习问题涉及的项数往往多于两项。当特征项数n很大时,除了存在运算量过大的问题外,找出附加项来建立一些分类器也是很困难的。
Neurons and the brain
【神经网络的背景知识】
神经网络逐渐兴起于二十世纪八九十年代应用得非常广泛,但由于各种原因在90年代的后期应用减少了,但是最近神经网络又东山再起,其中一个原因是神经网络是计算量有些偏大的算法。然而大概由于近些年计算机的运行速度变快才足以真正运行起大规模的神经网络。如今的神经网络,对于许多应用来说是最先进的技术。
The "one learning algorithm" hypothesis
思想:通过假设大脑做所有这些不同事情的方法不需要上千个不同的程序去实现,相反的,大脑处理的方法只需要一个单一的学习算法就可以了。
神经重接实验:
- 将视神经的信号传到听觉皮层上,听觉皮层将学会“看”。
- 将视神经的信号传到躯体感觉皮层上,躯体感觉皮层将学会“看”。
推断:如果人体有同一块脑组织可以处理光、声或触觉信号,那么也许存在一种学习算法可以同时处理视觉、听觉和触觉,而不是需要运行上千个不同的程序或者上千个不同的算法来做这些大脑所完成的成千上万的美好事情。也许我们需要做的就是找出一些近似的或实际的大脑学习算法,然后实现它。大脑通过自学掌握如何处理这些不同类型的数据。
Model representation I
我们在运用神经网络时该如何表示我们的假设或模型?
Neuron in the brain
神经网络是在模仿大脑中的神经元或者神经网络时发明的。因此,要解释如何表示模型假设,我们先来看单个神经元在大脑中是什么样的。
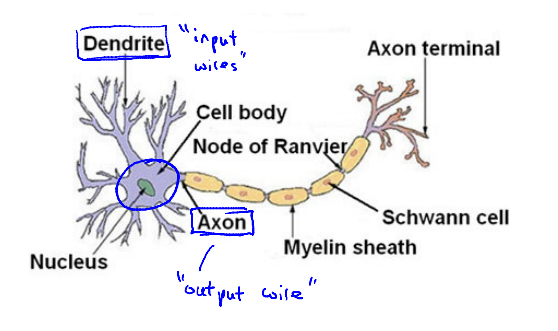
简而言之,神经元是一个计算单元,它从输入神经(input)接受一定数目的信息,并做一些计算,然后将结果通过它的轴突(output)传送到其它结点或者大脑中的其它神经元。
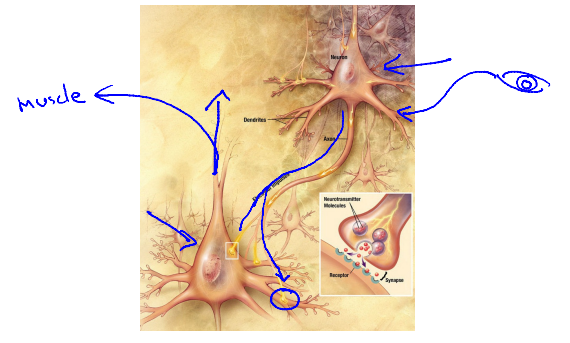
神经元利用微弱的电流进行沟通,这些弱电流也称作动作电位。如果神经元想要传递一个消息,它就会通过它的轴突发送一段微弱电流给其它神经元。接收电流的神经元通过接收消息做一些计算,它可能反过来将在轴突上的自己的消息传给其它神经元。(这也是我们感觉和肌肉运转的原理)
Neuron model: Logistic unit 神经元模型:逻辑单元
下图是一个简单的模拟神经元的模型。
我们将神经元模拟成一个逻辑单元,下图中的黄色圆圈可以想象为一个类似神经元的东西。我们通过它的输入神经(树突)传递给它一些信息,然后神经元做一些运算,并通过它的输出神经(轴突)输出计算结果。
通常只绘制\(x_1,x_2,x_3\)节点,有时会增加额外的\(x_0\)节点(偏置单位/偏置神经元),因\(x_0 \equiv 1\)所以对例子无用时可省略。
其中\(h_\Theta(x) = \frac{1}{1 + e^{-\Theta^Tx}}\),通常\(x\)和\(\Theta\)是我们的参数向量,即\(x = \left[ \begin{matrix} x_0 \\ x_1 \\ x_2 \\x_3 \end{matrix} \right]\),\(\Theta = \left[ \begin{matrix} \Theta_0 \\ \Theta_1 \\ \Theta_2 \\ \Theta_3 \end{matrix} \right]\)。

Neural Network
神经网络就是不同神经元组合在一起的集合。
\(x_0,\ldots,x_3\)是输入单元,\(a_0,\ldots,a_3\)是神经元,最后一层的节点输出假设函数\(h(x)\)的计算结果。
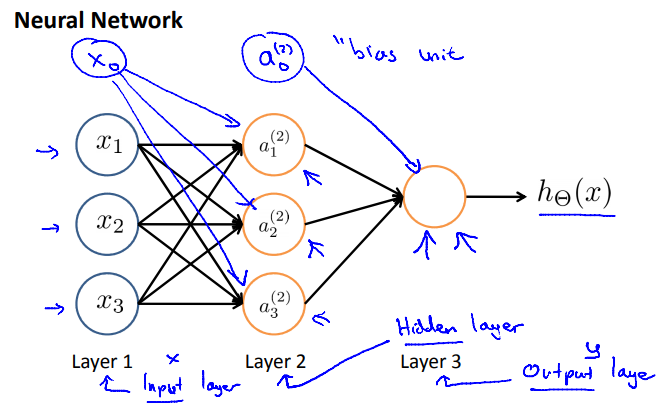
术语:网络中的第一层称为输入层,最后一层称为输出层,中间的称为隐藏层。
符号表示:
- \(a_i^{(j)}\) = “activation” of unit \(i\) in layer \(j\). 第\(j\)层的第\(i\)个神经元或单元的“激活函数”,"激活函数"是一个具体神经元,它读入计算并输出值。
- \(\Theta^{(j)}\) = matrix of weights controlling function mapping from layer \(j\) to layer \(j + 1\). 从第\(j\)层映射到第\(j + 1\)层的权重矩阵。
以上图为例,激活函数和输出分别为:
If network has \(s_j\) units in layer \(j\), \(s_{j+1}\) units in layer \(j + 1\), then \(\Theta^{(j)}\) will be of dimension \(s_{j+1} \times (s_j + 1)\). 如果第\(j\)层有\(s_j\)个单元,\(j+1\)层有\(s_{j+1}\)个单元,则\(\Theta^{(j)}\)是\(s_{j+1} \times (s_j + 1)\)维的。(因为需考虑\(x_0\)结点)如:
Model representation II
- 如何高效的进行计算以及向量化的实现方法。
- 为什么这样表示神经网络是一个好的方法及它们怎样帮助我们学习复杂的非线性假设。
Forward propagation: Vectorized implementation
在上节的激活函数中,我们定义\(z_1^{(2)}\)、\(z_2^{(2)}\)、\(z_3^{(2)}\)为:
则它们都是\(x_0\)、\(x_1\)、\(x_2\)、\(x_3\)的加权线性组合,将进入一个特定的神经元。
记\(X = \left[ \begin{matrix} x_0 \\ x_1 \\ x_2 \\ x_3 \end{matrix} \right]\),\(z^{(2)} = \left[ \begin{matrix} z_1^{(2)} \\ z_2^{(2)} \\ z_3^{(3)} \end{matrix} \right]\),令\(z^{(2)} = \Theta^{(1)}x\),\(a^{(2)} = g(z^{(2)})\),因\(a_0^{(2)} = 1\),
则\(z^{(3)} = \Theta^{(2)}a^{(2)}\),\(h_{\Theta}(x) = a^{(3)} = g(z^{(3)})\)。
这个计算\(X\)的过程也称为Forward propagation(向前传播)。
Neural Network learning its own features
神经网络所做的就像逻辑回归,但是它不是使用\(x_1\)、\(x_2\)、\(x_3\)作为输入特征,而是用\(a_1\)、\(a_2\)、\(a_3\)作为新的输入特征。

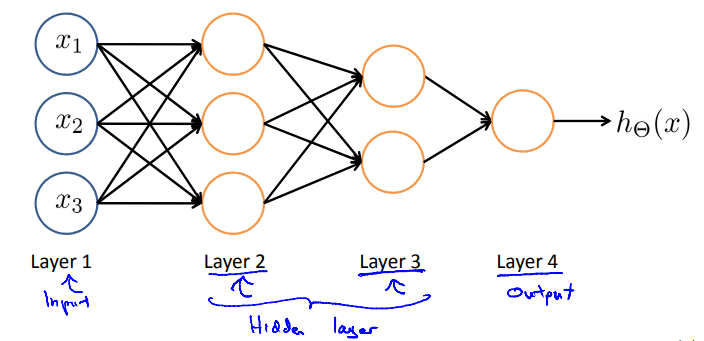
Other network architectures 其它神经网络的架构
神经网络中神经元相连接的方式称为神经网络的架构。
下图所示的例子中,第二层有三个隐藏单元,它们根据输入层计算一个复杂的函数,然后第三层将第二层训练出的特征项作为输入,并在第三层计算一些更复杂的函数。这样在你达到输出层(即第四层)之前,就可以利用第三层训练出更复杂的特征项作为输入,以此得到非常有趣的非线性假设。
Examples and intuitions I
Simple example: AND
\(x_1,x_2 \in \{0,1\}\), \(y = x_1\) AND \(x_2\).
-
搭建神经网络
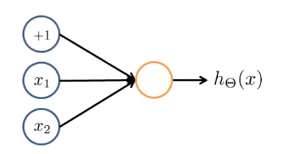
-
分配权重/参数
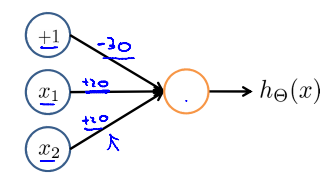
-
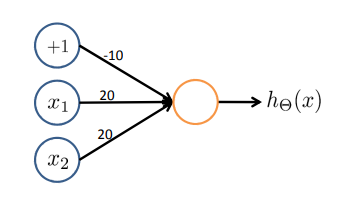
写出表达式:\(h_{\Theta}(x) = g(-30 + 20x_1 + 20x_2)\)
-
观察结果

Example: OR function
Examples and intuitions II
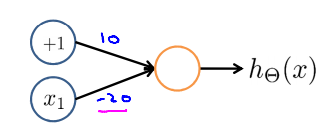
Negation
\(h_{\Theta}(x) = g(10 - 20x_1)\)
Putting it together: \(x_1\) XNOR \(x_2\)
- 三种操作的汇总:

- XNOR操作的解释:\(x_1\) XNOR \(x_2\) = NOT(\(x_1\) XOR \(x_2\) )
- 实现

Neural Network intuition
When you have multiple layers you have relatively simple function of the inputs of the second layer. But the third layer I can build on that to complete even more complex functions, and then the layer after that can compute even more complex functions.
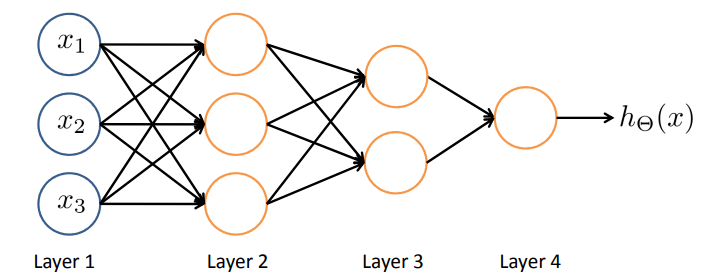
当有多层时,第二层输入的功能就相对简单了。 但是我可以在此基础上建立第三层来计算更加复杂的函数,然后再下一层又可以计算出再复杂一些的函数。
Multiclass Classification 多分类
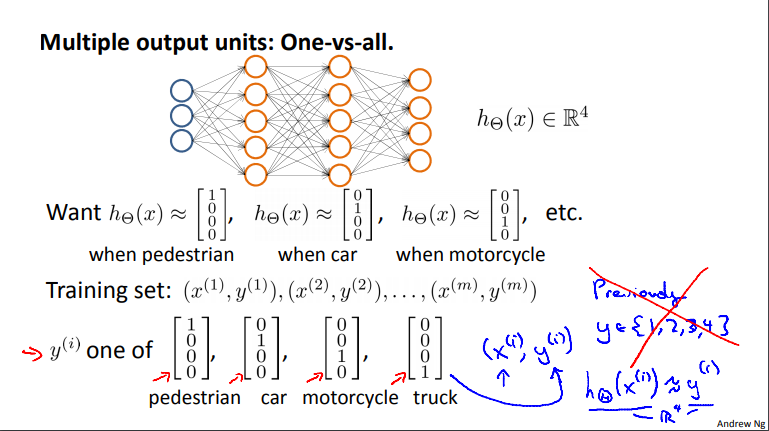
Multiple output units: One-vs-all. 多输出单位:一对多模型
问题:识别图片上是一个行人,一辆汽车,还是一辆摩托车,还是一辆卡车。
思路:建立一个具有四个输出单元的神经网络。
比较:这和我们介绍逻辑回归时讨论的一对多方法其实是一样的,只不过现在我们有四个逻辑回归分类器,而我们需要对四个分类器中每一个都分别进行识别分类。
建模:图示为神经网络结构。
- 因为此时神经网络的输出是一个四维向量,所以输出需要用一个向量来表示。我们用第一个元素表示图上是不是一个行人,第二个元素表示图上是不是一辆汽车,以此类推。因此,当图上是一个行人时我们希望输出\(\left[ \begin{matrix} 1 \\ 0 \\ 0 \\ 0 \end{matrix} \right]\),是一辆汽车时希望输出\(\left[ \begin{matrix} 0 \\ 1 \\ 0 \\ 0 \end{matrix} \right]\),……。
- 之前我们把\(y\)写作一个整数,用1,2,3,4来表示。但在这个例子中,当我们要表征一个具有行人、汽车、摩托车和卡车这样四个不同图片作为元素的训练集时,我们要用\(\left[ \begin{matrix} 1 \\ 0 \\ 0 \\ 0 \end{matrix} \right]\)、\(\left[ \begin{matrix} 0 \\ 1 \\ 0 \\ 0 \end{matrix} \right]\),……来表示。
- 我们的训练样本要用\((x^{(i)},y^{(i)})\)来表示,其中\(x^{(i)}\)表示我们已知的四种物体图像中的一个,而\(y^{(i)}\)是这四个向量中的某一个。我们希望通过找到某种方法,让我们的神经网络输出某个值,因此\(h(x) \approx y\)。
Review
测验:
-
Which of the following statements are true? Check all that apply.
-
Consider the following neural network which takes two binary-valued inputs \(x_1, x_2 \in \{0, 1\}\) and outputs \(h_\Theta(x)\). Which of the following logical functions does it (approximately) compute?
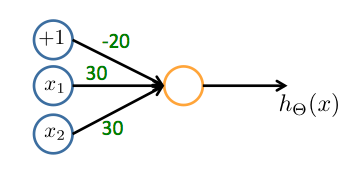
-
Consider the neural network given below. Which of the following equations correctly computes the activation \(a_1^{(3)}\)? Note: \(g(z)\) is the sigmoid activation function.
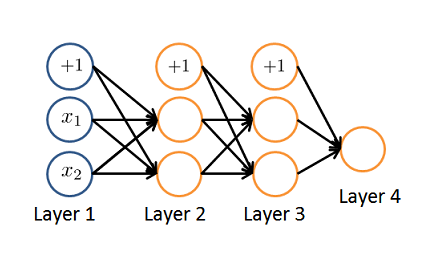
-
You have the following neural network:
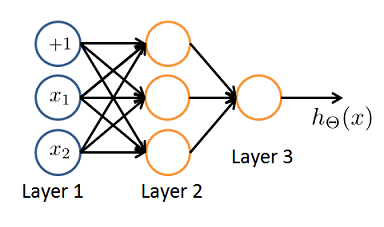
You'd like to compute the activations of the hidden layer \(a^{(2)} \in R^3\). One way to do so is the following Octave code:

You want to have a vectorized implementation of this (i.e., one that does not use for loops). Which of the following implementations correctly compute \(a^{(2)}\)? Check all that apply.
-
You are using the neural network pictured below and have learned the parameters \(\Theta^{(1)} = \left[ \begin{matrix} 1 & 2.1 & 1.3 \\ 1 & 0.6 & -1.2 \end{matrix} \right]\) (used to compute \(a^{(2)}\) and \(\Theta^{(2)} = \left[ \begin{matrix} 1 & 4.5 & 3.1 \end{matrix} \right]\) (used to compute \(a^{(3)}\) as a function of \(a^{(2)}\). Suppose you swap the parameters for the first hidden layer between its two units so \(\Theta^{(1)} = \left[ \begin{matrix} 1 & 0.6 & -1.2 \\ 1 & 2.1 & 1.3 \end{matrix} \right]\) and also swap the output layer so \(\Theta^{(2)} = \left[ \begin{matrix} 1 & 3.1 & 4.5 \end{matrix} \right]\). How will this change the value of the output \(h_\Theta(x)\)?

编程:
-
lrCostFunction.m
J = 1 / m * ( -y' * log(sigmoid( X * theta )) - (1 - y)' * log(1 - sigmoid( X * theta ))) + lambda / (2 * m) * (theta' * theta - theta(1)^2); grad = 1 / m * (X' * (sigmoid(X * theta) - y)); temp = theta; temp(1) = 0; grad = grad + lambda / m * temp; -
oneVsAll.m
initial_theta = zeros(n + 1, 1); options = optimset('GradObj', 'on', 'MaxIter', 50); for c = 1:num_labels all_theta(c, :) = fmincg (@(t)(lrCostFunction(t, X, (y == c), lambda)), initial_theta, options); end -
predictOneVsAll.m
A = sigmoid(X * all_theta'); [value, index] = max(A, [], 2); p = index; -
predict.m
a1 = [ones(m, 1) X]; z2 = a1 * Theta1'; a2 = sigmoid(z2); a2 = [ones(size(z2, 1), 1) a2]; z3 = a2 * Theta2'; a3 = sigmoid(z3); [value, index] = max(a3, [], 2); p = index;
