🍖纯手撸Web框架与主流框架
引入
由上一篇 HTTP 协议的介绍我们知道, 想要浏览器能访问到服务端的数据就必须按照 HTTP 协议来收发数据, 那么接下来我们就开始为所要发送的消息加上相应状态行, 实现一个合格的Web框架
- 先摆上请求数据格式好做对比
# 请求首行
b'GET / HTTP/1.1\r\n
# 请求头 (下面都是,一大堆的K:V键值对)
Host: 127.0.0.1:8080\r\n
Connection: keep-alive\r\n
Cache-Control: max-age=0\r\n
Upgrade-Insecure-Requests: 1\r\n
User-Agent: Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3823.400 QQBrowser/10.7.4307.400\r\n
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8\r\n
Accept-Encoding: gzip, deflate, br\r\n
Accept-Language: zh-CN,zh;q=0.9\r\n
Cookie: csrftoken=WCzjKvmjOSdJbYKs0uIfPtiFfLl04FENb6p9CjypP7ZObcUpydaQPLZN0qPOVqwj\r\n
# 换行
\r\n'
# 请求体
b''
一.初代版本
1.根据 URL 中不同的路径返回不同的内容
import socket
server = socket.socket() # 默认就是TCP协议
server.bind(('127.0.0.1',8080))
server.listen(5)
while True:
conn, addr = server.accept() # 三次四次挥手
data = conn.recv(1024)
res = data.decode('utf8')
conn.send(b'HTTP/1.1 200 OK\r\n\r\n') # 请求首行,请求头,空行
path = res.split(' ')[1] # 字符串切割获取地址
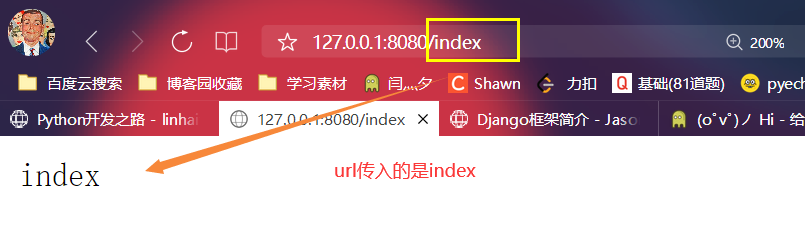
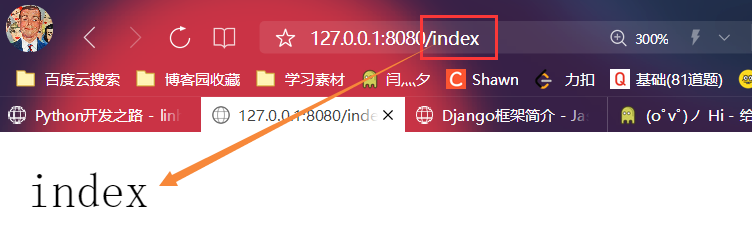
if path == '/index': # 判断地址
# conn.send(b'index') # 1.如果判断成功则发送请求体
with open(r'fh.html','rb') as f: # 2.或者打开文件一内容作为请求体发送
data = f.read()
conn.send(data)
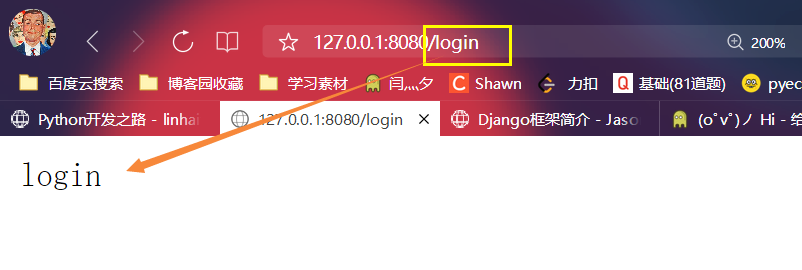
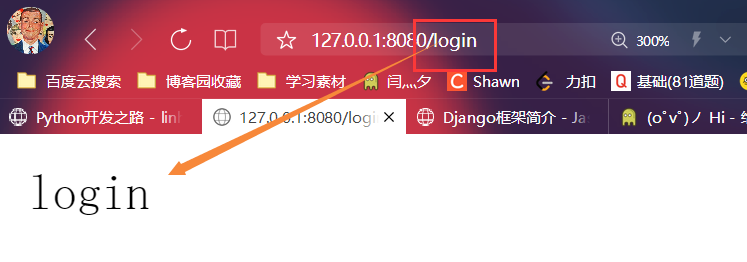
elif path == '/login': # 1.如果判断为login
conn.send(b'login') # 2.就发送b'login'的请求体
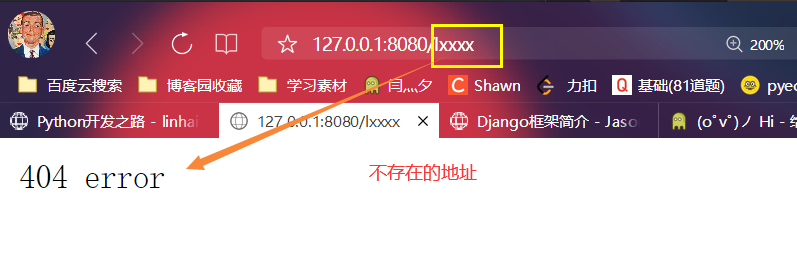
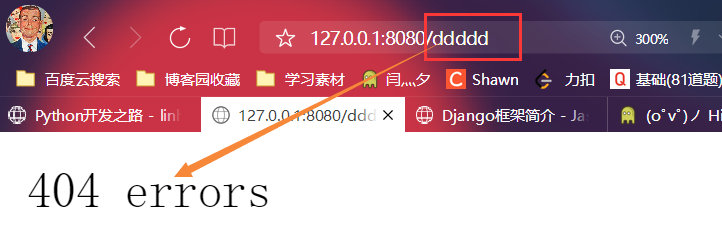
else:
conn.send(b'404 error') # 没匹配到则返回404
conn.close()
2.测试一下
3.存在的问题
- 如果网址路径很多, 服务端代码就会因为 if...else... 变得非常重复
- 并且手动的处理 HTTP 数据格式过于繁琐
二.基于 wsgiref 模块
1.wsgiref 模块的作用
- swgiref模块帮助我们封装了socket 代码
- 帮我们处理 http 格式的数据
2.便利之处
- 请求来的时候帮助你自动拆分http格式数据并封装成非常方便处理的数据格式(类似于字典)
- 响应走的时候帮你将数据再打包成符合http格式的数据
3.实现代码
from wsgiref.simple_server import make_server
# 以函数形式定义功能,扩展方便
def index_func(request):
return 'index'
def login_func(request):
return 'login'
def error(request):
return '404 errors'
# 地址与功能的对应关系
urls = [
('/index',index_func),
('/login',login_func)
]
def run_server(request,response):
"""
:param request:请求相关的所有数据,一个类似字典的形式,"PATH_INFO"正好就是我们要找的地址
:param response:响应相关的所有数据
:return:
"""
response('200 OK',[]) # 响应首行, 响应头
current_path = request.get("PATH_INFO") # 找到路径
func = None # 定义一个变量, 存储匹配到的函数名
for url in urls:
if current_path == url[0]:
func = url[1] # 如果匹配到了则将函数名赋值给func
break # 匹配之后立刻结束循环
if func: # 然后判断一下func是否被赋值了(也就是是否匹配到了)
data = func(request) # 执行函数拿到结果,request可有可无,但放进去以后好扩展
else:
data = error(request)
return [data.encode('utf-8')]
if __name__ == '__main__':
server = make_server('127.0.0.1', 8080, run_server) # 一旦被访问将会交给run_server处理
server.serve_forever() # 启动服务端并一直运行
- 查看效果
三.分文件盛放代码
随着业务越来越多, 功能越来越多, 将所有代码放在同一个文件会带来很多不必要的麻烦, 于是就需要我们分文件放置相关的代码
1.views.py : 只放功能代码
def index_func(request):
return 'index'
def login_func(request):
return 'login'
def error(request):
return '404 errors'
def xxx(request):
pass
2.urls.py : 存放路径与功能的对应关系
from views import *
urls = [
('/index',index_func),
('/login',login_func)
]
3.run.py : 只放请求与相应处理代码
from wsgiref.simple_server import make_server
from urls import urls
from views import *
def run_server(request,response):
"""
:param request:请求相关的所有数据,一个类似字典的形式,"PATH_INFO"正好就是我们要找的地址
:param response:响应相关的所有数据
:return:
"""
response('200 OK',[]) # 响应首行, 响应头
current_path = request.get("PATH_INFO") # 找到路径
func = None # 定义一个变量, 存储匹配到的函数名
for url in urls:
if current_path == url[0]:
func = url[1] # 如果匹配到了则将函数名赋值给func
break # 匹配之后立刻结束循环
if func: # 然后判断一下func是否被赋值了(也就是是否匹配到了)
data = func(request) # 执行函数拿到结果,request可有可无,但放进去以后好扩展
else:
data = error(request)
return [data.encode('utf-8')]
if __name__ == '__main__':
server = make_server('127.0.0.1', 8080, run_server) # 一旦被访问将会交给run_server处理
server.serve_forever() # 启动服务端并一直运行
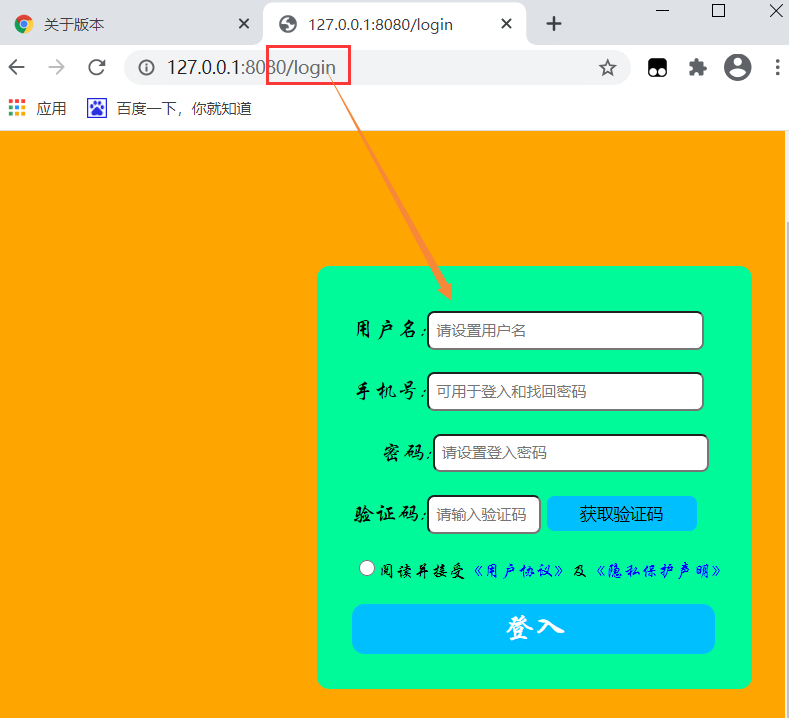
四.返回HTML静态网页
静态网页 : 数据都是写死的, 固定不变的
解决了不同URL返回不同内容的问题, 但是我不想仅仅返回几个字符串, 我想给浏览器返回完整的HTML内容, 对此我们只需要通过 open 打开 HTML文件将内容读出来再发送给浏览器就行了
- 修改 view.py 文件
def index_func(request):
return 'index'
def login_func(request):
with open(r"./login.html", "r", encoding="utf-8")as f:
res = f.read() #打开文件读出内容,再返回文件内容
return res
def error(request):
return '404 errors'
五.返回动态页面
动态页面 : 数据来源于后端 (代码或者数据库)
1.示例1 : 访问网址展示当前时间
- 由后端生成时间不能改展示到HTML页面中
# view.py 文件
def index_func(request):
return 'index'
def login_func(request):
from datetime import datetime
now_time = datetime.now().strftime("%Y-%m-%d %X")
with open(r"./login.html", "r", encoding="utf-8")as f:
res = f.read().replace("datetime1",now_time)
return res
def error(request):
return '404 errors'
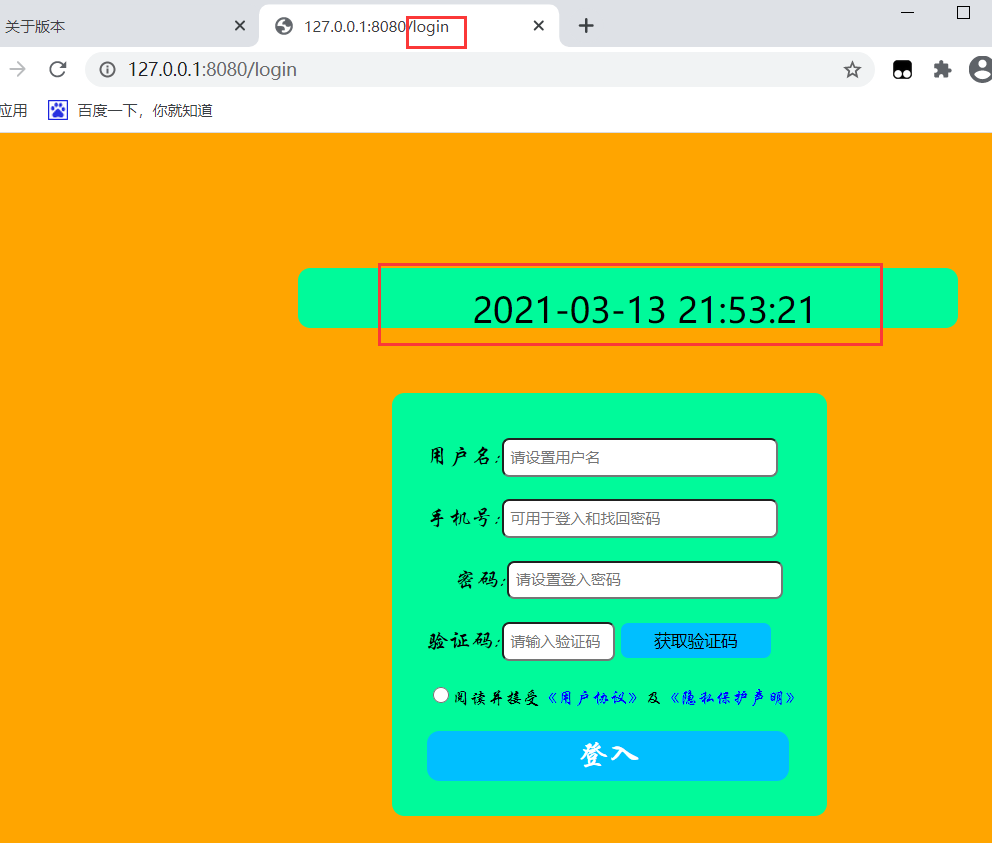
2.示例二 : 从数据库中拿到数据
上面我们需要手动的 replace 更换 HTML 文件里的代码, 下面我们使用 jinja2 来优化 replace
1.jinja模块介绍
-
jinja2 模块的作用 : jiaja2的原理就是字符串替换,我们只要在HTML页面中遵循 jinja2 的语法规则写上,其内部就会按照指定的语法进行相应的替换,从而达到动态的返回内容.
-
jinja2 模板语法
// 定义变量, 双花括号
{{ user_list }}
// for 循环, 花括号 + 百分号
{% for user_dict in user_list %}
{{ user_dict.id }} # 支持Python操作对象的方式取值
{% endfor %}
- 下载 jinja2 模块
# pip3 install jinja2
豆瓣源 : http://pypi.douban.com/simple/
清华源: https://pypi.tuna.tsinghua.edu.cn/simple
使用方法 : pip install -i https://pypi.tuna.tsinghua.edu.cn/simple jinja2
ps : 该模块是flask框架必备的模块 所以下载flask也会自动下载该模块
2.在数据库中创建一张表来做准备
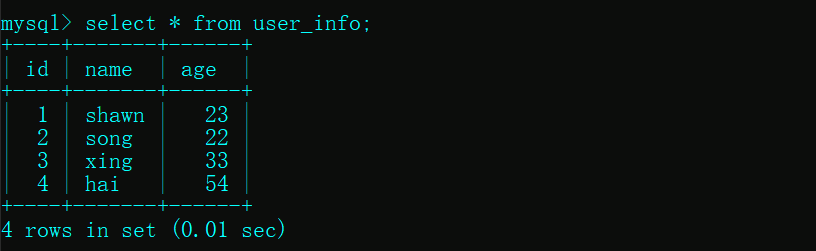
- view.py 文件
def index_func(request):
return 'index'
def login_func(request):
from datetime import datetime
now_time = datetime.now().strftime("%Y-%m-%d %X")
with open(r"./login.html", "r", encoding="utf-8")as f:
res = f.read().replace("datetime1",now_time)
return res
# 从数据库获取数据
def get_db_func(request):
from jinja2 import Template
import pymysql
conn = pymysql.connect(host='127.0.0.1',
port=3306,
user='root',
password='123',
db='db1111',
charset='utf8',
autocommit=True)
cursor = conn.cursor(cursor=pymysql.cursors.DictCursor)
sql = 'select * from user_info'
rows = cursor.execute(sql)
user_list = cursor.fetchall() # [{},{},{}] 格式
with open(r'get_db.html','r',encoding='utf-8')as f:
data = f.read() # 字符串
temp = Template(data)
# 将user_list传给HTML页面, 在页面中使用data_list调用
res = temp.render(data_list=user_list)
return res
def error(request):
return '404 errors'
- urls.py 文件
from views import *
urls = [
('/index', index_func),
('/login', login_func),
('/get_db',get_db_func) # 添加一个新功能
]
-
run.py 文件不需要变动
-
get_db.html 文件
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
<script src="https://cdn.bootcdn.net/ajax/libs/jquery/3.4.1/jquery.min.js"></script>
<link href="https://cdn.bootcdn.net/ajax/libs/twitter-bootstrap/3.4.1/css/bootstrap.min.css" rel="stylesheet">
<script src="https://cdn.bootcdn.net/ajax/libs/twitter-bootstrap/3.4.1/js/bootstrap.min.js"></script>
</head>
<body>
<div class="container">
<div class="row">
<h2 class="text-center">用户信息表</h2>
<table class="table table-hover table-striped table-bordered">
<thead>
<tr>
<th>ID</th>
<th>name</th>
<th>age</th>
</tr>
</thead>
<tbody>
{% for user_dict in data_list %} {# 🔰从列表中循环取出字典 #}
<tr>
<td>{{ user_dict.id }}</td> {# 🔰以类似Python中字典的方式取值 #}
<td>{{ user_dict.name }}</td>
<td>{{ user_dict.age }}</td>
</tr>
{% endfor %}
</tbody>
</table>
</div>
</div>
</body>
</html>
- 效果
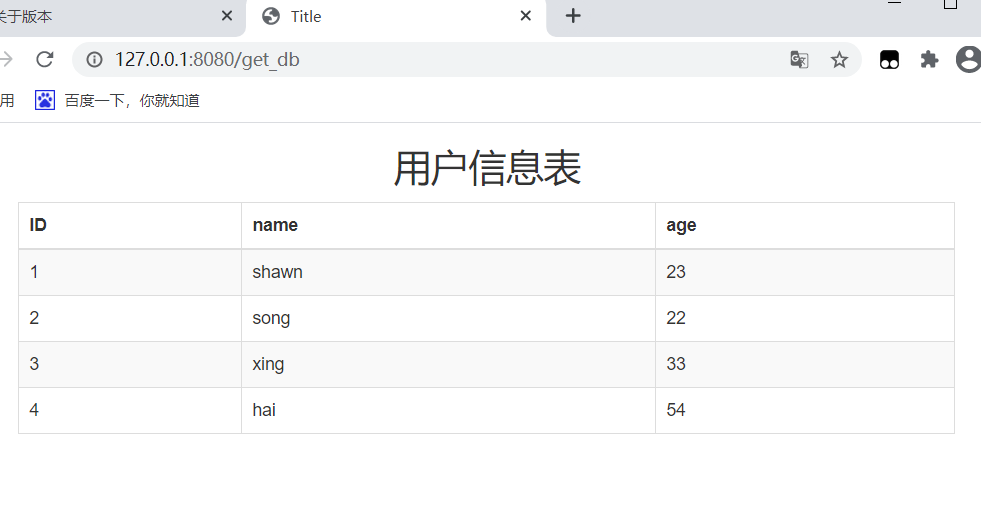
- 数据库添加一条记录, 页面刷新
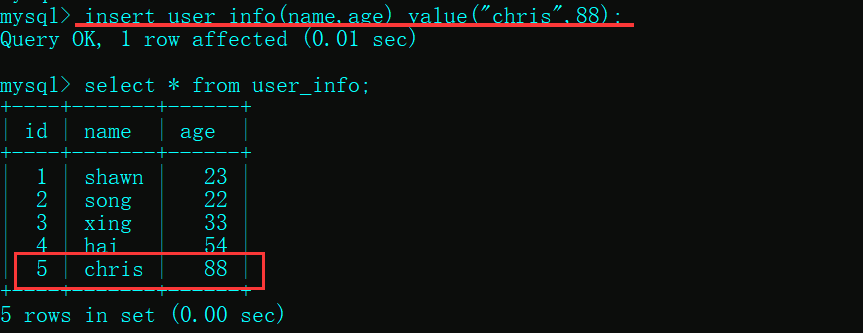
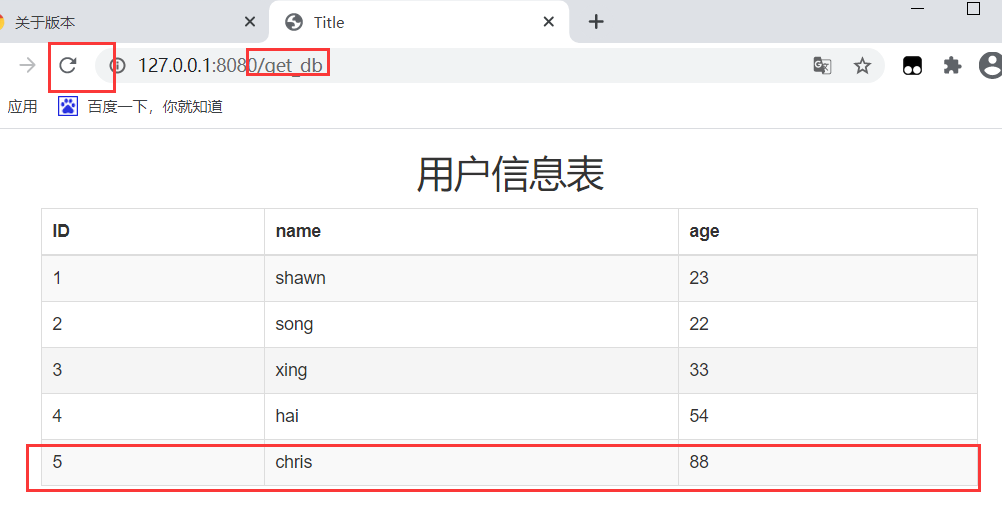
以上就实现了从数据库获取数据的动态页面
六.总结
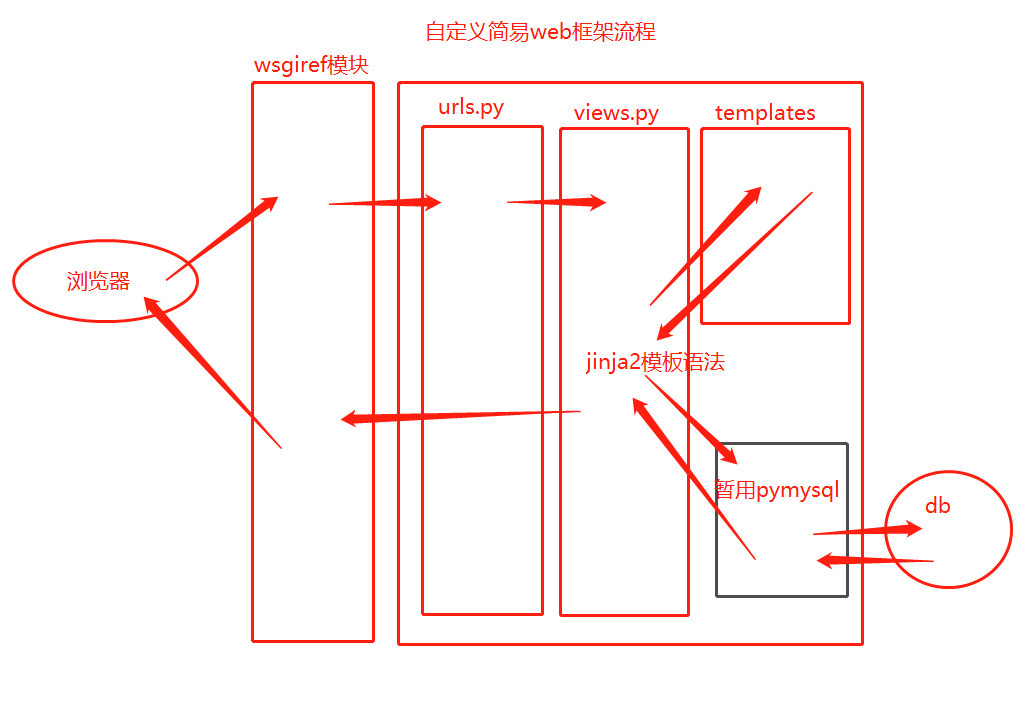
1.自定义版本的Web框架流程图
// 浏览器客户端
// wsgiref模块
请求来: 处理浏览器请求, 解析浏览器http格式的数据, 封装成大字典(PATH_INFO中存放的用访问资源的路径)
响应去: 将数据打包成符合http格式 再返回给浏览器
// 后端
"urls.py": 找用处输入的路径有没有与视图函数的对应关系. 如果有则取到views.py找对应的视图函数.
"views.py":
功能1(静态): 视图函数找templates中的html文件, 返回给wsgiref做HTTP格式的封包处理, 再返回给浏览器.
功能2(动态): 视图函数通过pymysql链接数据库, 通过jinja2模板语法将数据库中取出的数据在tmpelates文件夹下的html文件做一个数据的动态渲染, 最后返回给wsgiref做HTTP格式的封包处理, 再返回给浏览器.
功能3(动态): 也可以通过jinja2模板语法对tmpelates文件夹下的html文件进行数据的动态渲染, 渲染完毕, 再经过wsgiref做HTTP格式的封包处理, 再返回给浏览器.
"templates": html文件
// 数据库
2.步骤总结
-
手写 Web 框架
-
wsgiref 模块
1.封装了socket代码
2.处理了http数据格式
- 根据不同功能拆分不同文件
"urls.py" : 路由与视图函数对应关系
"views.py" : 视图函数
"templates" : 模板文件夹(存放HTML文件)
1.第一步添加路由与视图函数的对应关系
2.去views中书写功能代码
3.如果需要使用到html则去模板文件夹中操作
- jinja2 模板语法
// 定义变量, 双花括号
{{ user_list }}
// for 循环, 花括号 + 百分号
{% for user_dict in user_list %}
{{ user_dict.id }} # 支持Python操作对象的方式取值
{% endfor %}
- 流程图
七.主流 web 框架
1.三大主流 web 框架
- django 框架
特点 : 大而全,自带的功能组件非常多!类似于航空母舰
不足 : 有时候过于笨重
- flask 框架
特点 : 小而精 自带的功能特别特别特别的少, 类似于游骑兵, 但第三方的模块特别特别特别的多,如果将flask第三方的模块加起来完全可以盖过django
不足 : 比较依赖于第三方的开发者
ps : 三行代码就可以启动一个 flask 后端服务
- tornado 框架
异步非阻塞 速度非常的快 快到可以开发游戏服务器
- Sanic 框架
- FastAPI 框架
- .....
2.Web框架三部分
- A : socket 部分
- B : 路由与视图匹配部分
- C : 模板语法部分
3.三种主流框架三部分的使用情况
- Django
A : 用的是别人的 (wsgiref模块)
B : 用的是自己的
C : 用的是自己的 (没有jinja2好用 但是也很方便)
- flask
A : 用的是别人的 (werkzeug(内部还是wsgiref模块))
B : 自己写的
C : 用的别人的 (jinja2)
- tornado
A,B,C都是自己写的

 浙公网安备 33010602011771号
浙公网安备 33010602011771号