
Mysql面试题汇总
1. SQL标准
SQL是Structured Query Language的缩写,属于声明性语言,SQL有两个重要的标准,分别是 SQL92 和 SQL99,它们分别代表了 92 年和 99 年颁布的SQL 标准。
2. 常见的 SQL 分为哪几类?
1. DDL (Data Definition Language)- 操作数据库和表。
2. DML(Data Manipulation Language) - 对表中的数据进行增删改。
3. DQL(Data Query Language)- 查询表中的数据。
4. DCL (Data Control Language) - 定义访问权限和创建用户。
3. 数据库的范式是什么?
第一范式 (1st NF): 列都是不可再分, 确保每一列的原子性。
第二范式 (2nd NF):行可以唯一区分,主键约束。
第三范式 (3rd NF):表的非主属性不能依赖与其他表的非主属性 外键约束
巴德斯克范式(BCNF):每个表只有一个候选键,要求主键列互不依赖,前提必须遵循3NF。
第四范式:用来消除多值依赖。
第五范式(完美范式):用来处理消除所有的业务冗余,以独立的表来表达每一个业务需求。
范式是一级一级依赖的,第二范式建立在第一范式上,第三范式建立第一第二范式上 。
反范式化模型
不满足范式的模型,就是反范式模型。
范式的优点:
1. 范式化的数据库更新起来更加快。
2. 范式化之后,只有很少的重复数据,只需要修改更少的数据。
3. 范式化的表更小,可以在内存中执行。
4. 很少的冗余数据,在查询的时候需要更少的distinct或者group by语句。
范式的缺点:
1. 范式化的表,在查询的时候经常需要很多的关联,因为单独一个表内不存在冗余和重复数据。这导致,稍微复杂一些的查询语句在查询范式的schema上都可能需要较多次的关联。这会增加让查询的代价,也可能使一些索引策略无效。因为范式化将列存放在不同的表中,而这些列在一个表中本可以属于同一个索引。
反范式的优点:
1. 可以避免关联,因为所有的数据几乎都可以在一张表上显示;
2. 可以设计有效的索引;
反范式的缺点:
表格内的冗余较多,删除数据时候会造成表有些有用的信息丢失。
所以在设计数据库时,要注意混用范式化和反范式化
4. MyISAM和InnoDB的区别有哪些?
1. InnoDB支持事务, MyISAM不支持。
2. InnoDB支持行级锁, MyISAM支持表级锁。
3. InnoDB支持多版本并发控制(MVVC), MyISAM不支持。
4. InnoDB支持外键, MyISAM不支持。
5. MyISAM支持全文索引, InnoDB部分版本不支持(但可以使用Sphinx插件)。
5. Mysql ACID四大特性
1. 原子性(Atomicity):原子性是指事务包含的所有操作要么全部成功,要么全部失败回滚。失败回滚的操作事务,将不能对事物有任何影响。
2. 一致性(Consistency):一致性是指事务必须使数据库从一个一致性状态变换到另一个一致性状态,也就是说一个事务执行之前和执行之后都必须处于一致性状态。
3. 隔离性(Isolation):隔离性是指当多个用户并发访问数据库时,比如同时访问一张表,数据库每一个用户开启的事务,不能被其他事务所做的操作干扰,多个并发事务之间,应当相互隔离。
4. 持久性(Durability):持久性是指事务的操作,一旦提交,对于数据库中数据的改变是永久性的,即使数据库发生故障也不能丢失已提交事务所完成的改变。
6. drop、delete与truncate的区别
SQL中的drop、delete、truncate都表示删除,但是三者有一些差别delete和truncate只删除表的数据不删除表的结构速度, 一般来说: drop > truncate > delete。
delete语句是dml,这个操作会放到rollback segement中, 事务提交之后才生效。如果有相应的trigger,执行的时候将被触发. truncate,drop是ddl, 操作立即生效,原数据不放到rollbacksegment中,不能回滚. 操作不触发。
7. 什么是MYSQL回表查询
8. 什么是索引下推?
1. 索引下推(index condition pushdown )简称ICP,在Mysql5.6的版本上推出,用于优化查询。
2. 在不使用ICP的情况下,在使用非主键索引(又叫普通索引或者二级索引)进行查询时,存储引擎通过索引检索到数据,然后返回给MySQL服务器,服务器然后判断数据是否符合条件 。
3. 在使用ICP的情况下,如果存在某些被索引的列的判断条件时,MySQL服务器将这一部分判断条件传递给存储引擎,然后由存储引擎通过判断索引是否符合MySQL服务器传递的条件,只有当索引符合条件时才会将数据检索出来返回给MySQL服务器 。
4. 索引条件下推优化可以减少存储引擎查询基础表的次数,也可以减少MySQL服务器从存储引擎接收数据的次数。
9. MySQL的MRR 是什么?
MRR(Multi-Range Read Optimization)是是Mysql5.6优化器的一个新特性,优化器可以将随机 IO 转化为顺序 IO, 以降低查询过程中IO开销的一种手段,这对IO-bound(I/O密集型)类型的SQL语句性能带来极大的提升,适用于range ref eq_ref类型的查询。
10. 什么是聚簇索引和非聚簇索引
聚簇索引:将数据存储与索引放到了一块,找到索引也就找到了数据。
Innodb中在聚簇索引之上创建的索引称之为辅助索引(二级索引),辅助索引访问数据总是需要二次查找,非聚簇索引都是辅助索引,像复合索引、前缀索引、唯一索引,辅助索引叶子节点存储的不再是行的物理位置,而是主键值,因为Innodb中只有唯一的主键。
非聚簇索引:将数据存储于索引分开结构,索引结构的叶子节点指向了数据的对应行,Myisam存储引擎通过key_buffer把索引先缓存到内存中,当需要访问数据时(通过索引访问数据),在内存中直接搜索索引,然后通过索引找到磁盘相应数据,这也就是为什么索引不在key buffer命中时,速度慢的原因。
11. Mysql数据库及表容量有限制吗?
具体可以查看官方文档:https://dev.mysql.com/doc/mysql-reslimits-excerpt/5.6/en/table-size-limit.html
12. MysqL自动提交机制
Mysql有一个自动提交机制(AutoCommit),在默认情况下是开启的,MysqL在执行一句DML语句将缺省地开始一个新的事务,这个就叫做自动提交的。在开启自动提交当情况下,比如当执行了insert into test values(1)语句,Mysql默认会帮你开启事务,并且在这条插入语句执行完成之后,默认帮你提交事务。
自动执行(AutoCommit)与提交类型(Completion)
使用事务有两种方式,分别为隐式事务和显式事务。隐式事务实际上就是自动提交,有些数据库比如Oracle 默认不自动提交,需要手写
Commit。在MySQL中自动提交(autocommit)在支持事务(transaction)的引擎中,若autocommit = true, 则不需要commit的情况下直接提交语句形成永久性修改,Mysql默认打开autocommit, 也可以通过配置设置。
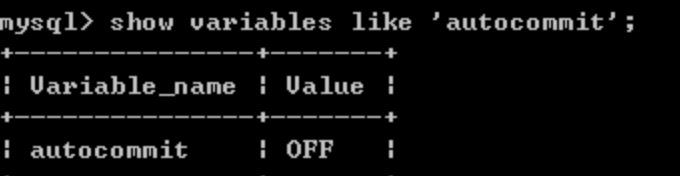
查看自动提交设置:
show variables like '%auto%';
关闭方式有两种:
控制台命令执行:set autocommit = 0 # 1.开启 0.关闭 直接在配置文件加入:autocommit=0 #直接在Mysql配置文件修改
这篇写的挺好的:https://blog.csdn.net/wx145/article/details/82740737
autocommit是否开启会对innodb性能有一定的影响。如果关闭了autocommit,不要忘了commit。
13. Mysql如何加锁
锁定表:lock tables,对应的解锁unlock tables。
锁定行:select ... from ... where ... for update,for update 仅适用于InnoDB存储引擎,而且必须在事务区块(begin/commit)中才能生效。for update只能对id字段一定是主键或者唯一索引使用,否则就升级为表锁,如果未获取到数据的时候,mysql不进行锁 (no lock)。这篇文章对for update有详细说明:https://www.cnblogs.com/smallfa/p/12068678.html
select …… for update会对行记录加上X锁,其他事务不能对已锁定的行记录加上任何锁。
select …… lock in share mode会对行记录加上S锁,其他事务可以对锁定航加S锁,但加X锁会被阻塞。
14. datetime和timestamp的区别
占用空间
datetime:8字节,以 8 个字节储存,不会进行时区的检索。
timestamp: 4字节,以utc存储,的格式储存, 它会自动检索当前时区并进行转换。注意一点timestamp的时间范围最多存储到2038年。
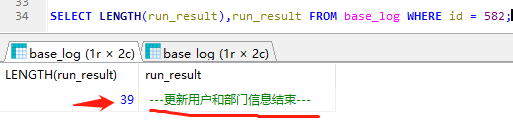
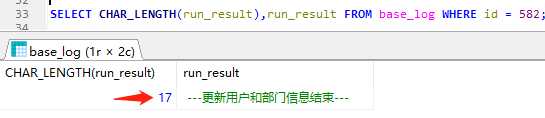
15. LENGTH和CHAR_LENGTH的区别
length(): 是计算字段的长度一个汉字是算三个字符,一个数字或字母算一个字符。
char_length():不管汉字还是数字或者是字母都算是一个字符。
长连接:长连接是指连接成功后,如果客户端持续有请求,则一直使用同一个连接。长连接连接成功后如果长期闲置不操作,mysql会8小时后(可以使用参数wait_timeout控制的)主动断开该连接。
短连接:短连接则是指每次执行完很少的几次查询就断开连接,下次查询再重新建立一个。
17. 查看sql语句执行过程
查看profiling 是否开启,开启它可以让 MySQL 收集在 SQL 执行时所使用的资源情况,命令如下:
select @@profiling;
profiling=0 代表关闭,我们需要把 profiling 打开,即设置为 1:
set profiling=1;
然后执行一条sql语句
SELECT * FROM table WHERE creator_id = 4777
查看当前会话所产生的所有 profiles:
show profile;
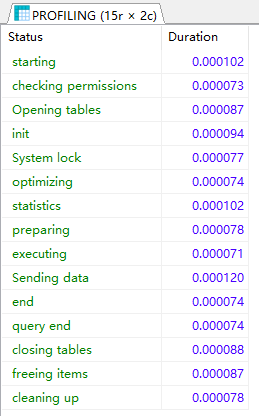
18. DDL语句可以回滚吗
不可以,DDL直接触发隐式提交,任何事务回滚的前提是没有commit,隐式提交直接给你commit了,所以后续的rollback(回滚)一点意义都没有。
19. text类型容量有多大
之前一直以为text容量很大,所以很多时候在存储大量数据时候会选择text类型,也忽视了text容量具体多少,直到有一次线上出现一个问题,线上日志接口在保存提交数据的时候,由于提交的内容数据量巨大超过text容量而导致报错。如下错误提示
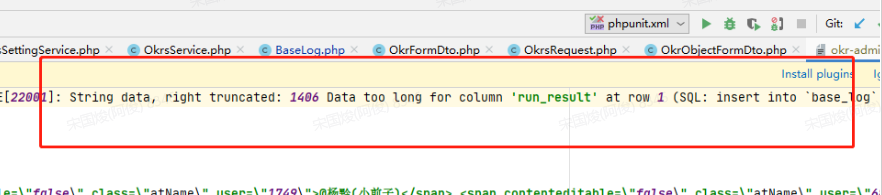
查询后知道text的容量大小是最多可以存储65535字节。所以以后在保存大容量数据的时候,例如小说这样的数据也要考虑选择合适的字段类型(mediumtext和longtext)或者其他方案(比如云存储)。
下面列出各个字符串类型容量大小:参考https://www.runoob.com/mysql/mysql-data-types.html
| 类型 | 大小 | 说明 |
|---|---|---|
| TINYTEXT | 0-255 byte | 短文本字符串 |
| BLOB | 0-65535 byte | 二进制形式的长文本数据 |
| TEXT | 0-65535 byte | 长文本数据 |
| MEDIUMBLOB | 0-16777215 byte | 二进制形式的中等长度文本数据 |
| MEDIUMTEXT | 0-16777215 bytes | 中等长度文本数据 |
| LONGBLOB | 0-4294967295 bytes | 二进制形式的极大文本数据 |
| LONGTEXT | 0-4294967295 bytes | 极大文本数据 |
20. utf8和utf8mb4的区别
相信很多人用到编码格式为utf8mb4时候,是因为遇到emoji表情(这样的😂表情)时候插入字段编码类型为UTF-8时候报错,在mysql中UTF-8编码最多只支持3个字节,而emoji表情以及一些特殊的中文字符则需要4个字节才能存储, 因此才会报错。
线上实际报错:
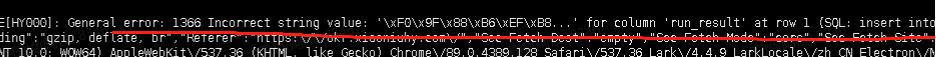
线上表结构
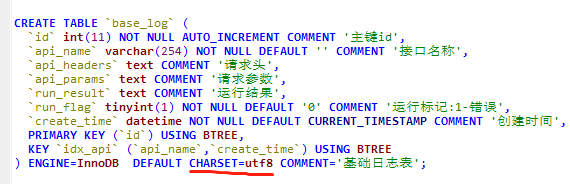
通过修改表编码类型或者字段编码类型修改为utf8mb4类型。
修改语句
1. 修改具体字段编码
ALTER TABLE base_log MODIFY COLUMN run_result TEXT CHARACTER SET utf8mb4 COMMENT '运行结果';
2. 修改整张表编码
ALTER TABLE base_log CONVERT TO CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci;
修改之后如下:
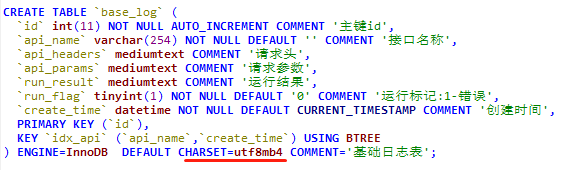
当然在创建数据库时候,可以设置utf8mb4编码,以后每张表默认就是utf8mb4编码格式。
使用 SHOW CREATE database 数据库名查看
CREATE DATABASE `db` /*!40100 DEFAULT CHARACTER SET utf8mb4 */
21. mysql中的行锁有哪几种
1. 记录锁(Record Lock):
单个行记录上的锁,记录锁就是为某行记录加锁,列必须为唯一索引列或主键列,否则加的锁就会变成临键锁,查询语句必须为精准匹配 = ,不能为 >、<、like等,否则也会退化成临键锁。
2. 间隙锁(Gap Lock):
锁定一个范围,但不包括记录本身。间隙锁基于非唯一索引,它锁定一段范围内的索引记录。比如查询字段区间为1-5,即1-5内的记录行都会被锁住,2、3、4 的数据行的会被阻塞,但是 1 和 5 两条记录行并不会被锁住。
3. 临键锁(Next-Key Lock):
临键锁可以理解为一种特殊的间隙锁,上面说过了通过临建锁可以解决幻读的问题。 每个数据行上的非唯一索引列上都会存在一把临键锁,当某个事务持有该数据行的临键锁时,会锁住一段左开右闭区间的数据。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号