树,二叉树,查找算法总结
树,二叉树,查找算法总结
1.思维导图
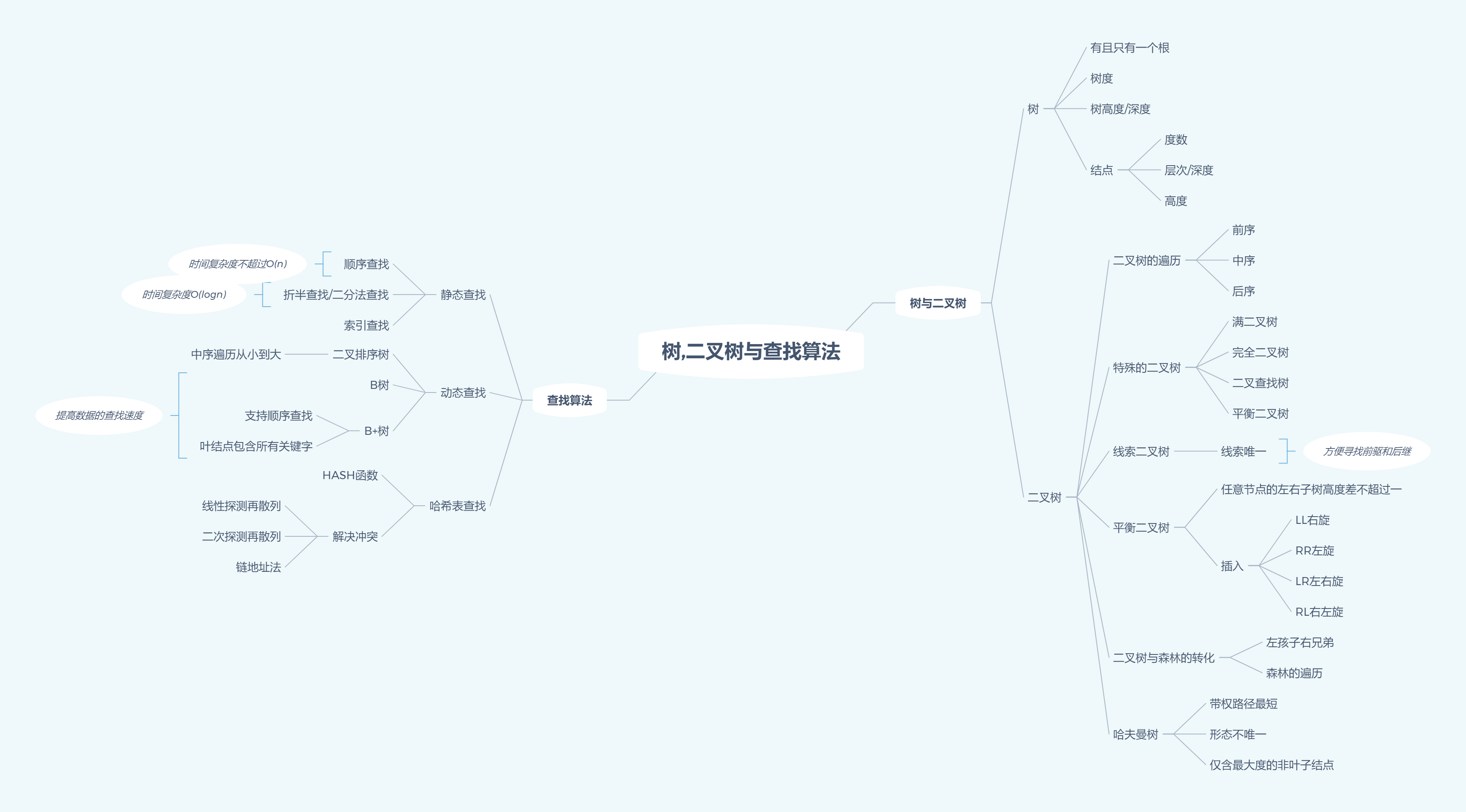
2.重要概念的笔记
节点的度:节点拥有子树数称为节点的度。(也就是该节点拥有的子节点数)度为0的节点称为非终端节点或分支节点,除根节点外,分支节点也称为内部节点,树的度是树内各节点度的最大值。
节点的层次与深度:节点的层次(Level)从根开始定义,根为第一层,根的孩子为第二层。若A节点在第l层,则其子树的根就在第l+1层(即A节点的子节点)。其双亲在同一层的节点互为堂兄弟。树中节点的最大层次称为树的深度(Depth)或高度。 、
满二叉树: 所有分支节点都存在左子树和右子树,并且所有叶子都在同一层上,这样的二叉树称为满二叉树。
完全二叉树:对于一个有n个节点的二叉树按层序编号,如果编号为i(1 ≤ i ≤ n)的节点与同样深度的满二叉树中编号为i的节点在二叉树中位置完全相同则该二叉树称为完全二叉树。
二叉树的性质
性质1:在二叉树的第i层上至多有2∧i-1个结点(i>=1)。
性质2:深度为k的二叉树至多有2∧k -1个结点(k>=1)。
性质3:对任何一棵二叉树T,如果其终端结点数为n0,度为2的结点数为n2,则n0=n2+1。
性质4:具有n个结点的完全二叉树的深度为[log2n]+1 ([x]表示不大于x的最大整数。
哈希表的构造:
除留余数法:
h(k)=m%p(p为素数,p<=m)
哈希冲突的解决方法:
-
拉链法:所有有冲突的元素在一条链表上。指针需要额外的空间,故当结点规模较小时,开放定址法较为节省空间,而若将节省的指针空间用来扩大散列表的规模,可使装填因子变小,这又减少了开放定址法中的冲突,从而提高平均查找速度。
-
开放定址法:
线性探测法: 冲突发生时,顺序查看表中下一单元,直到找出一个空单元或查遍全表。
二次探查法: 冲突发生时,在表的左右进行跳跃式探测,比较灵活
3.疑难问题及解决方案
1.对哈希表查找不成功的理解
我认为查找不成功指通过取余进行一次搜索不能得到结果的情况,然而通过测试答案发现并非如此。
通过查阅相关资料及课本,得知:查找不成功的平均长度指哈希表中查找不到待查的元素,最后找到空位置的探测次数的平均值。
2.对与B树以及B+树,不懂得他们存在的意义,他们相较于二叉树相比,有什么好处?
通过查找各种资料,了解到一些计算机的相关知识。
要考虑磁盘IO的影响,它相对于内存来说是很慢的。数据库索引是存储在磁盘上的,当数据量大时,就不能把整个索引全部加载到内存了,只能逐一加载每一个磁盘页(对应索引树的节点)。所以我们要减少IO次数,对于树来说,IO次数就是树的高度,而“矮胖”就是b树的特征之一,它的每个节点最多包含m个孩子,m称为b树的阶,m的大小取决于磁盘页的大小。
那么B+树呢?
由于B树遍历整个树的过程和二叉树本质上是一样的,B树相对二叉树虽然提高了磁盘IO性能,但并没有解决遍历元素效率低下的问题。 并且, 每个节点中既要存索引信息,又要存其对应的数据 , 每次读到内存中的树的信息就会不太够 。
故引入B+树,在课堂中了解到,B+树可以将所有信息都存储在了叶子节点里面 ,这样的话想遍历所有数据信息只需要顺序遍历叶子节点就可以了,方便高效。
同时,通过查阅相关资料了解到B+树的另一些好处:
-
B+树的磁盘读写代价更低
B+的内部结点并没有指向关键字具体信息的指针。因此其内部结点相对B树更小。如果把所有同一内部结点的关键字存放在同一盘块中,那么盘块所能容纳的关键字数量也越多。一次性读入内存中的需要查找的关键字也就越多。相对来说IO读写次数也就降低了。
-
B+树的数据信息遍历更加方便
B+树只要遍历叶子节点就可以实现整棵树的遍历,而B树不支持这样的操作(或者说效率太低),而且 在数据库中基于范围的查询是非常频繁的,所以数据库索引基本采用B+树
-
B+树的查询效率更加稳定
由于非终结点并不是最终指向文件内容的结点,而只是叶子结点中关键字的索引。所以任何关键字的找必须走一条从根结点到叶子结点的路。所有关键字查询的路径长度相同,导致每一个数据的查询效率相当。
