第六次作业
一、作业内容
作业①:
要求:
用requests和BeautifulSoup库方法爬取豆瓣电影Top250数据。
每部电影的图片,采用多线程的方法爬取,图片名字为电影名
了解正则的使用方法
候选网站:豆瓣电影:https://movie.douban.com/top250
代码:
from bs4 import BeautifulSoup
from bs4 import UnicodeDammit
import urllib.request
import threading
def imageSpider(start_url):
global thread
global count
try:
urls = []
req = urllib.request.Request(start_url, headers=headers)
data = urllib.request.urlopen(req)
data = data.read()
dammit = UnicodeDammit(data, ["utf-8", "gbk"])
data = dammit.unicode_markup
soup = BeautifulSoup(data, "html.parser")
list = soup.select('ol[class="grid_view"] li')
for li in list:
rank=li.select('div[class="pic"] em[class=""]')[0].text.replace("em",'').replace("\n",'')
fn=li.select('div[class="info"] div a span ')[0].text.replace("span",'').replace("\n",'')
info_l=li.select('div[class="bd"] p')[0].text.replace("p",'').replace("\n",'').replace(" ",'')
info_f =li.select('div[class="bd"] br')[0].text.replace("br",'').replace("\n",'').replace(" ",'')
comment=li.select('div[class="bd"] div[class="star"] span[class="rating_num"]')[0].text.replace("span",'').replace("\n",'').replace(" ",'')#评价信息
audi=li.select('div[class="star"] span')[3].text.replace("span",'').replace("\n",'').replace(" ",'')
print(rank,fn,info_l,info_f,comment,audi)
images1 = soup.select("img")
for image in images1:
try:
src = image["src"]
url = urllib.request.urljoin(start_url, src)
if url not in urls:
urls.append(url)
print(url)
count = count + 1
T = threading.Thread(target=download, args=(url, count))
T.setDaemon(False)
T.start()
thread.append(T)
except Exception as err:
print(err)
except Exception as err:
print(err)
def download(url, count):
try:
count=count+1
if (url[len(url) - 4] == "."):
ext = url[len(url) - 4:]
else:
ext = ""
req = urllib.request.Request(url, headers=headers)
data = urllib.request.urlopen(req, timeout=100)
data = data.read()
fobj = open("photo\\" + str(count) + ext, "wb")
fobj.write(data)
fobj.close()
print("downloaded " + str(count) + ext)
except Exception as err:
print(err)
start_url = "https://movie.douban.com/top250"
headers = {"User-Agent":"Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre"}
count = 0
thread = []
imageSpider(start_url)
for t in thread:
t.join()
print("the End")
结果:
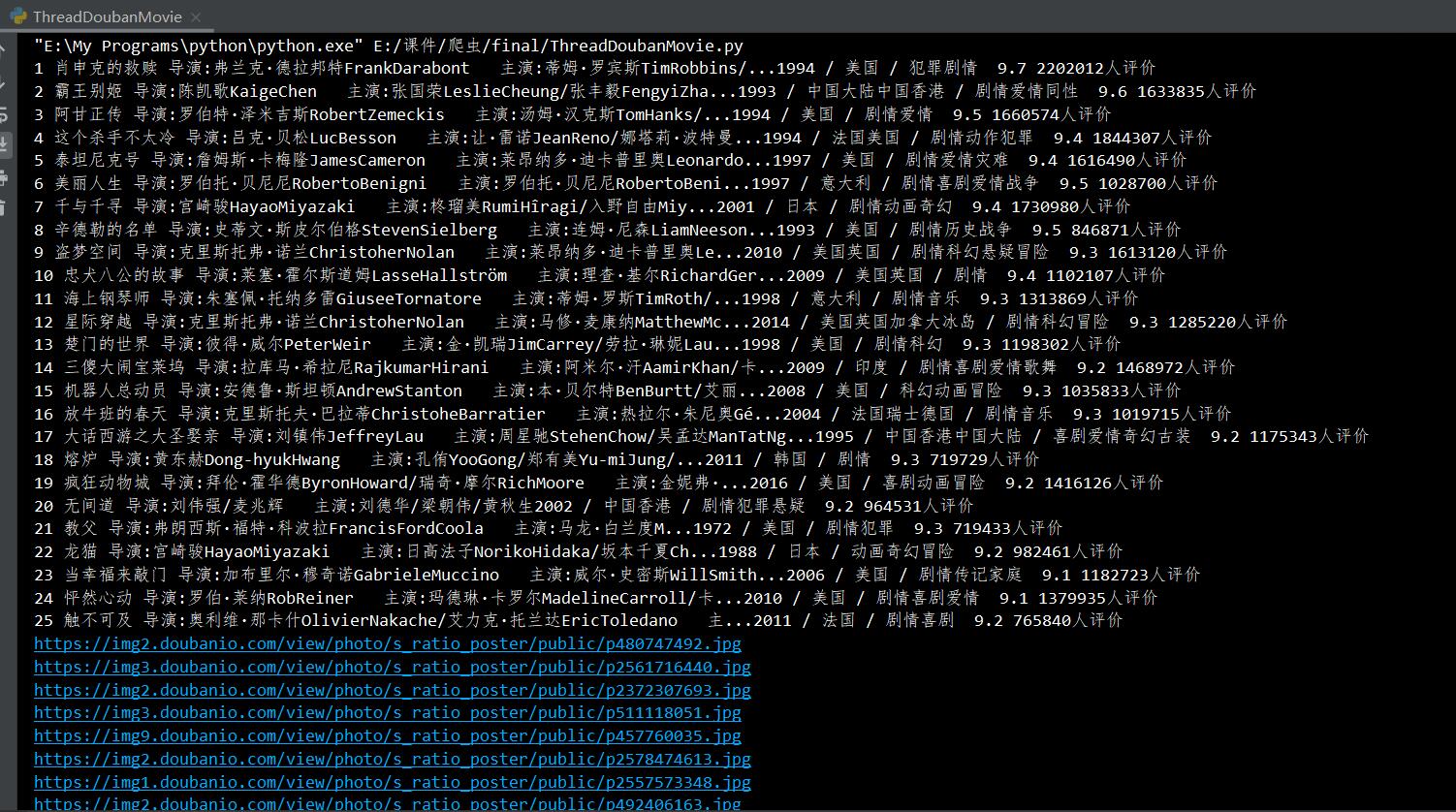
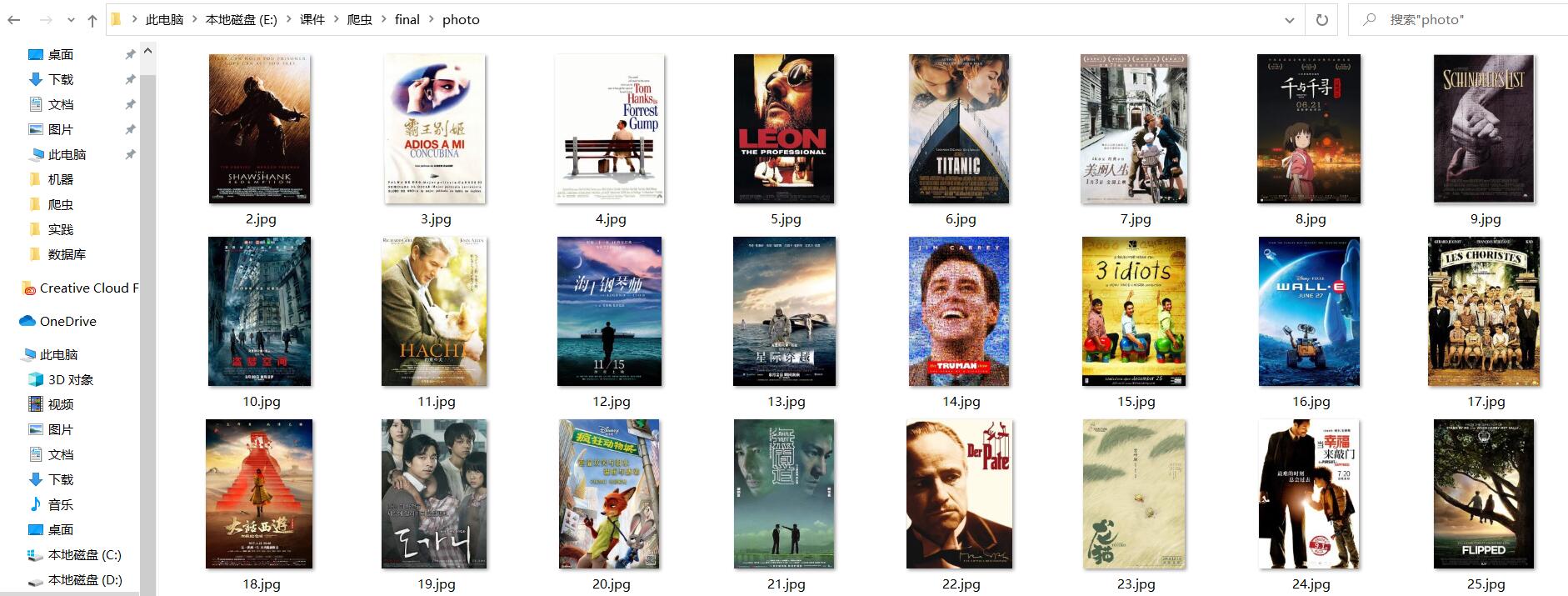
心得:
这次作业主要是回顾上半学期的bs和request库爬虫,相比于之前我主要是在静态网页定位上有所遗忘,进行了重新学习。
作业②:
要求:
熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;Scrapy+Xpath+MySQL数据库存储技术路线爬取科软排名信息
爬取科软学校排名,并获取学校的详细链接,进入下载学校Logo存储、获取官网Url、院校信息等内容。
候选网站:https://www.shanghairanking.cn/rankings/bcur/2020
代码:
items.py:
import scrapy
class UniversityrankingItem(scrapy.Item):
sNo=scrapy.Field()
schoolName=scrapy.Field()
city=scrapy.Field()
officalUrl=scrapy.Field()
info=scrapy.Field()
pipelines.py
import sqlite3
class UniversityrankingPipeline:
class SpiderPipeline:
def open_spider(self, MySpider):
self.con = sqlite3.connect("University.db")
self.cursor = self.con.cursor()
try:
self.cursor.execute("drop table University")
except:
pass
sql = "create table University(sNo int,schoolName varchar(32),city varchar(16),officalUrl varchar(64),"\
"info text,);"
self.cursor.execute(sql)
#self.cursor.execute("delete from University")
def close_spider(self, MySpider):
if self.opened: self.con.commit()
self.con.close()
self.opened = False
print("closed")
def process_item(self, item, spider):
try:
print(item["sNo"])
print(item["schoolName"])
print(item["city"])
print(item["officalUrl"])
print(item["info"])
print()
self.cursor.execute("insert into University(sNo,schoolName,city,officalUrl,info) "
"values(?,?,?,?,?)",
(sNo, schoolName, city, officalUrl, info))
except Exception as err:
print(err)
return item
结果:
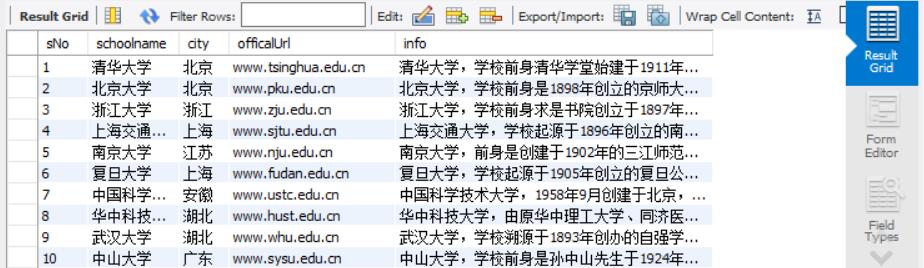
由于一直没能实现将图片存入数据库中,我最后放弃了这一想法,只存储了排名、校名、城市、官网、信息五项。
感想:
结果到最后还是没能用上pymysql啊......
这一题仿照了原来的架构,在xpath上有所遗忘,但总体完成,还是比较清晰的。
作业③:
要求:
熟练掌握 Selenium 查找HTML元素、爬取Ajax网页数据、等待HTML元素加载、网页跳转等内容。
使用Selenium框架+ MySQL数据库存储技术模拟登录慕课网,并获取学生自己账户中已学课程的信息并保存在MYSQL中。
其中模拟登录账号环节需要录制gif图。
候选网站: 中国mooc网:https://www.icourse163.org
代码:
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import sqlite3
import time
class MOOC:
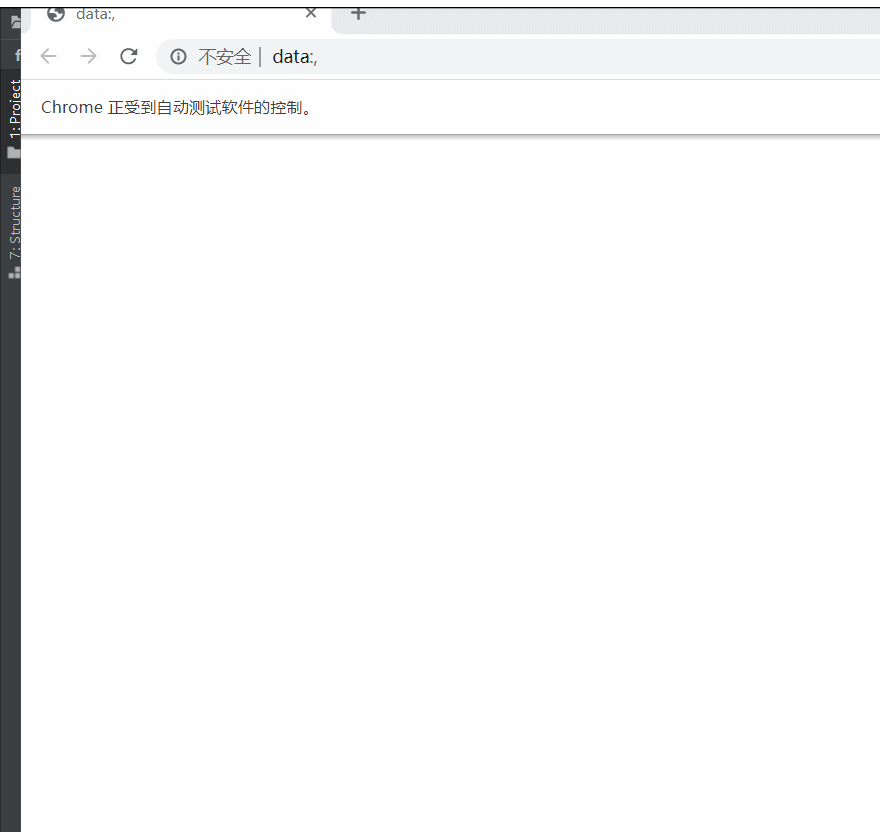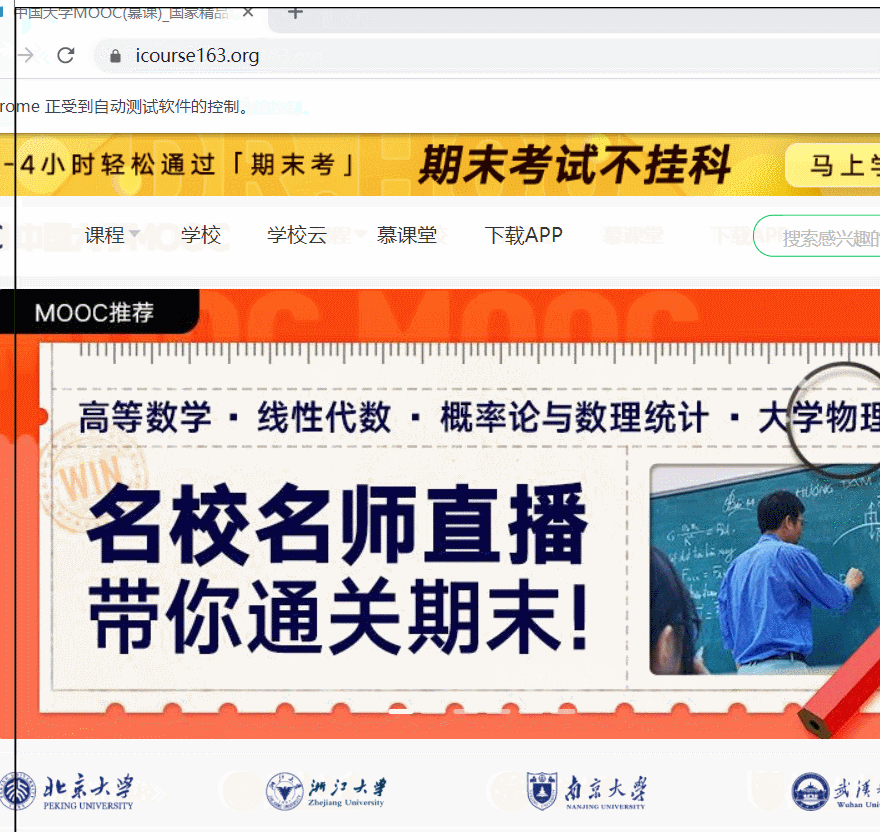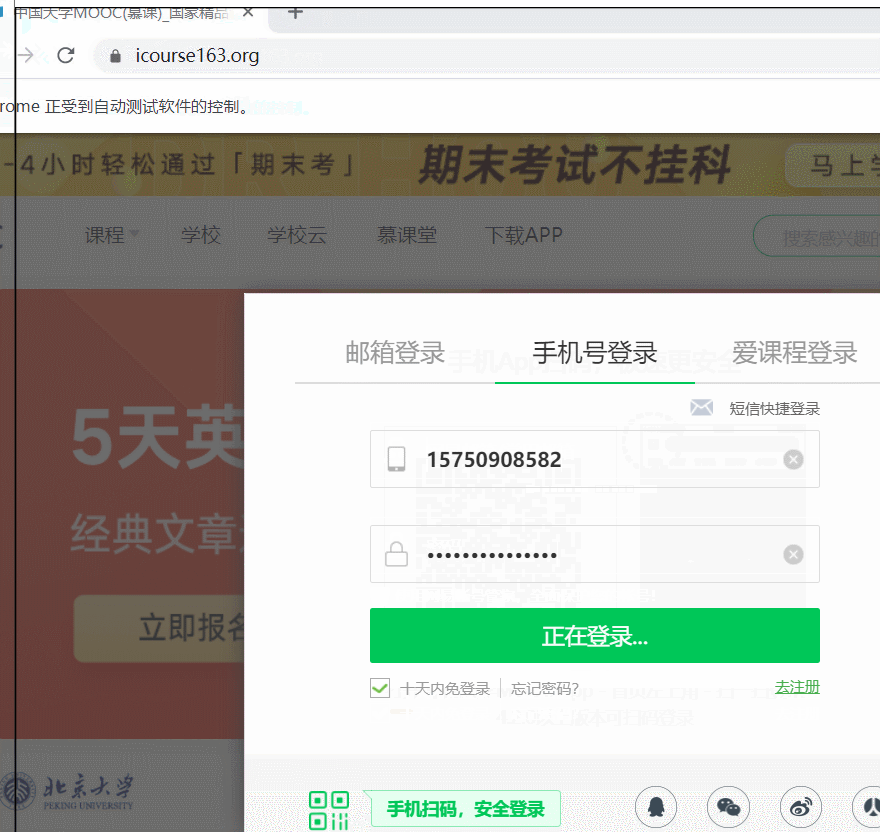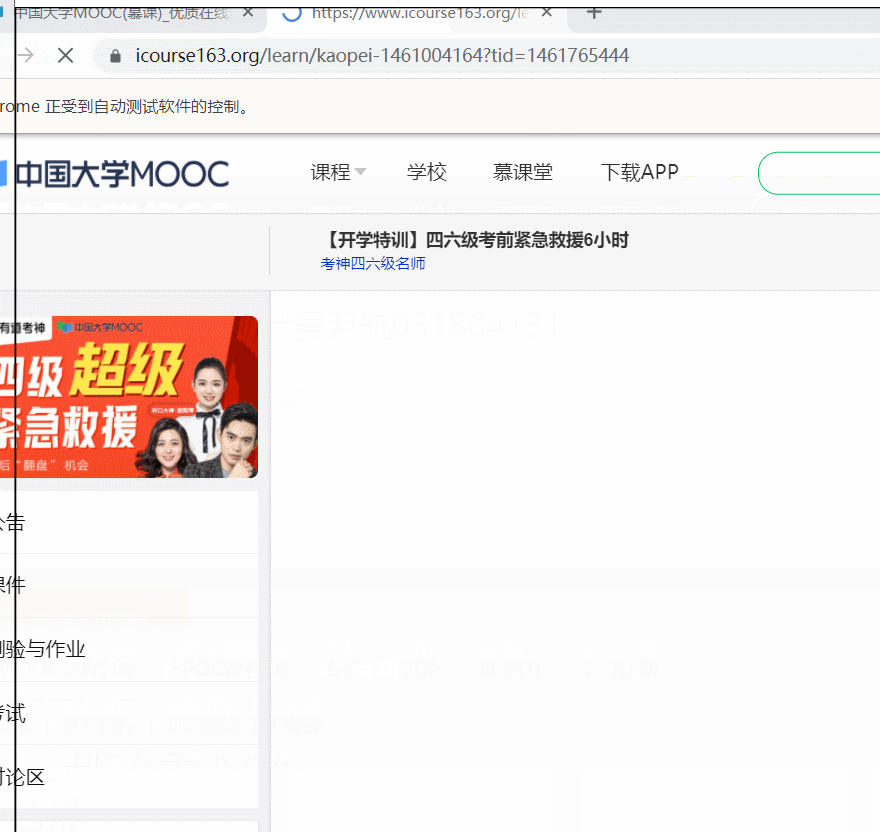
def Load_in(self):
time.sleep(1)
user = self.driver.find_element_by_xpath('//*[@id="j-topnav"]/div')
user.click()
time.sleep(1)
way = self.driver.find_element_by_xpath('//div[@class="ux-login-set-scan-code_ft"]/span')
way.click()
time.sleep(1)
telephone = self.driver.find_element_by_xpath('//ul[@class="ux-tabs-underline_hd"]/li[2]')
telephone.click()
time.sleep(1)
frame = self.driver.find_element_by_xpath(
"/html/body/div[13]/div[2]/div/div/div/div/div/div[1]/div/div[1]/div[2]/div[2]/div/iframe")
self.driver.switch_to.frame(frame)
self.driver.find_element_by_xpath('//input[@type="tel"]').send_keys('15750908582')
time.sleep(1)
self.driver.find_element_by_xpath('//input[@class="j-inputtext dlemail"]').send_keys('wuyinhang817000')
time.sleep(1)
load_in = self.driver.find_element_by_xpath('//*[@id="submitBtn"]')
load_in.click()
def MyClass(self):
time.sleep(1)
myclass = self.driver.find_element_by_xpath('//*[@id="j-indexNav-bar"]/div/div/div/div/div[7]/div[3]/div')
myclass.click()
self.all_spider()
def all_spider(self):
time.sleep(1)
self.spider()
time.sleep(1)
try:
self.driver.find_element_by_xpath(
'//ul[@class="ux-pager"]/li[@class="ux-pager_btn ux-pager_btn__next"]/a[@class="th-bk-disable-gh"]')
except Exception:
self.driver.find_element_by_xpath(
'//ul[@class="ux-pager"]/li[@class="ux-pager_btn ux-pager_btn__next"]/a[@class="th-bk-main-gh"]').click()
self.all_spider()
def spider(self):
id = 0
time.sleep(1)
lis = self.driver.find_elements_by_xpath('//div[@class="course-card-wrapper"]')
for li in lis:
time.sleep(1)
li.click()
window = self.driver.window_handles
self.driver.switch_to.window(window[1])
time.sleep(1)
window = self.driver.window_handles
self.driver.switch_to.window(window[2])
time.sleep(1)
id += 1
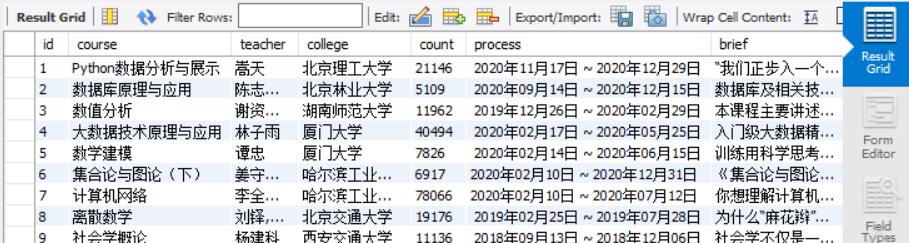
course = self.driver.find_element_by_xpath(
'//*[@id="g-body"]/div[1]/div/div[3]/div/div[1]/div[1]/span[1]').text
teacher = self.driver.find_element_by_xpath('//*[@id="j-teacher"]//h3[@class="f-fc3"]').text
collage = self.driver.find_element_by_xpath('//*[@id="j-teacher"]/div/a/img').get_attribute('alt')
process = self.driver.find_element_by_xpath('//*[@id="course-enroll-info"]/div/div[1]/div[2]/div[1]').text
count = self.driver.find_element_by_xpath('//*[@id="course-enroll-info"]/div/div[2]/div[1]/span').text
brief = self.driver.find_element_by_xpath('//*[@id="j-rectxt2"]').text
self.cursor.execute("insert into mooc(id, course, teacher, collage, count, process, brief) "
"values( ?,?,?,?,?,?,?)",
(id, course, teacher, collage, count, process, brief))
time.sleep(1)
self.driver.close()
self.driver.switch_to.window(window[1])
time.sleep(1)
self.driver.close()
self.driver.switch_to.window(window[0])
def start(self):
self.con = sqlite3.connect("mooc.db")
self.cursor = self.con.cursor()
try:
self.cursor.execute("drop table mooc")
except:
pass
sql = 'create table mooc(id int,course varchar(32),teacher varchar(16),collage varchar(32),count varchar(64),' \
'process varchar(64),brief text);'
self.cursor.execute(sql)
#self.cursor.execute("delete from mooc")
def stop(self):
try:
self.con.commit()
self.con.close()
except Exception as err:
print(err)
def executespider(self, url):
chrome_options = Options()
self.driver = webdriver.Chrome(chrome_options=chrome_options)
self.driver.get(url)
self.start()
self.Load_in()
self.MyClass()
self.stop()
def main():
url = 'https://www.icourse163.org/'
spider = MOOC()
spider.executespider(url)
if __name__ == '__main__':
main()
结果:
心得:
使用了上次的selenium框架,这次成功的完成了模拟登录账号,删掉了选择界面。
有时会爬到一半报错:selenium.common.exceptions.WebDriverException: Message: chrome not reachable
有时正常,尚在研究之中。
写在最后:
一学期的学习就这样结束了。本人并不是特别聪明的类型,作业做得马马虎虎,每次做作业都深刻的体会到了人和人的差距......
但还是要感谢吴老师、陈助教以及班里的各位大佬的帮助,大家对我相当宽容,给了我很多帮助,让我受益良多。
对于一门课、一种技术而言,兴趣不一定和成果成严格正比,但一定存在正相关。
愿我们以后还能把兴趣挥洒在每一个角落。再次感谢!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号