第三次作业
作业①:
要求:爬取中国气象网(http://www.weather.com.cn) 的图片。分别使用单线程和多线程的方式爬取。
代码:1.单线程运行:
from bs4 import BeautifulSoup from bs4 import UnicodeDammit import urllib.request def imageSpider(start_url): try: urls = [] req = urllib.request.Request(start_url,headers=headers) data = urllib.request.urlopen(req) data = data.read() dammit = UnicodeDammit(data,["utf-8","gbk"]) data = dammit.unicode_markup soup = BeautifulSoup(data,"lxml") images = soup.select("img") for image in images: try: src = image["src"] url = urllib.request.urljoin(start_url,src) if url not in urls: urls.append(url) print(url) download(url) except Exception as errrrrrrrrrrrrrrrrrrror: print(errrrrrrrrrrrrrrrrrrror) except Exception as errrrrrrrrrrrrrrrrrrror: print(errrrrrrrrrrrrrrrrrrror) def download(url): global count try: count = count + 1 if(url[len(url)-4] == "."): ext = url[len(url)-4:]
#ext = url[len(url)-4] else: ext = "" req = urllib.request.Request(url,headers=headers) data = urllib.request.urlopen(req,timeout=100) data = data.read() fobj = open("images\\" + str(count) + ext,"wb") fobj.write(data) fobj.close() print("downloaded" + str(count) + ext) except Exception as errrrrrrrrrrrrrrrrrrror: print(errrrrrrrrrrrrrrrrrrror) start_url = "http://weather.com.cn/weather/101280601.shtml" headers={"User-Agent":"Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre"} count = 0 imageSpider(start_url)
结果:

...?这是什么东西?
仔细检查之后发现是我之前抄书都抄错了,把
ext = url[len(url)-4:]
抄成了
ext = url[len(url)-4]
修正后正常输出:
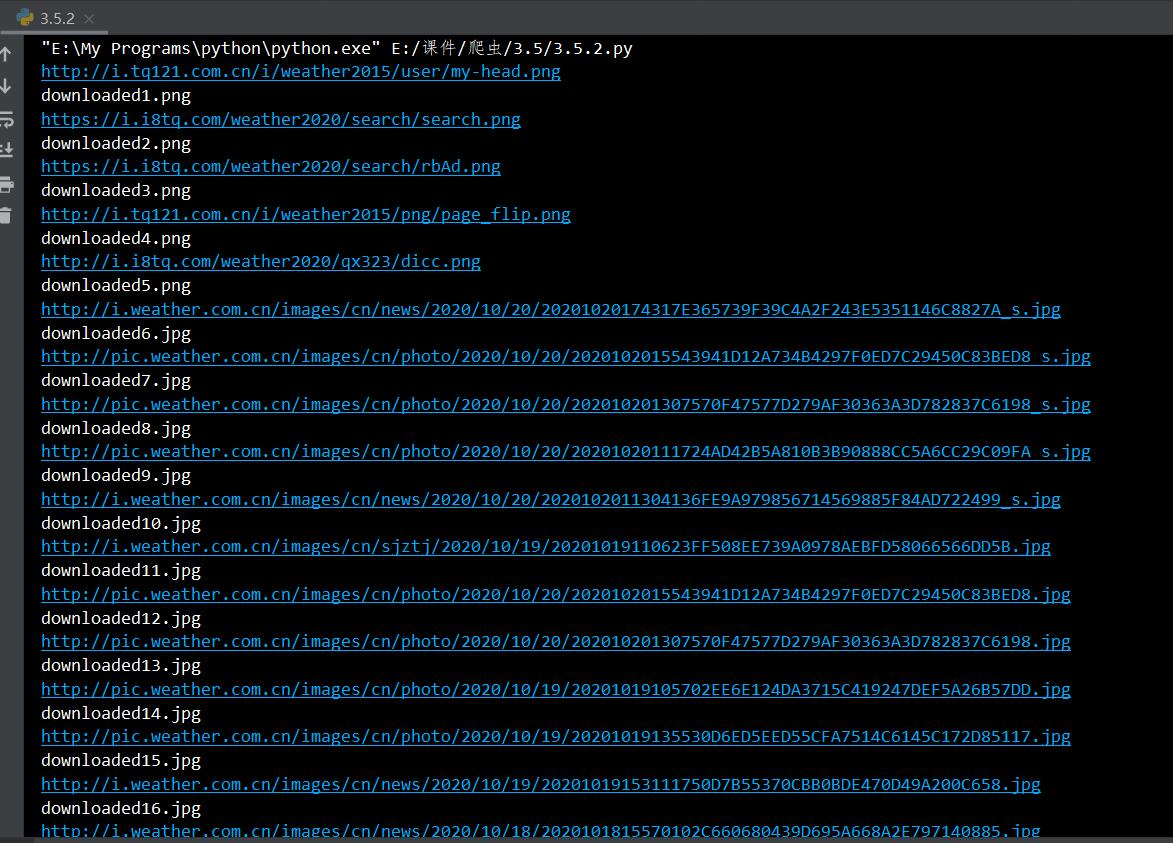
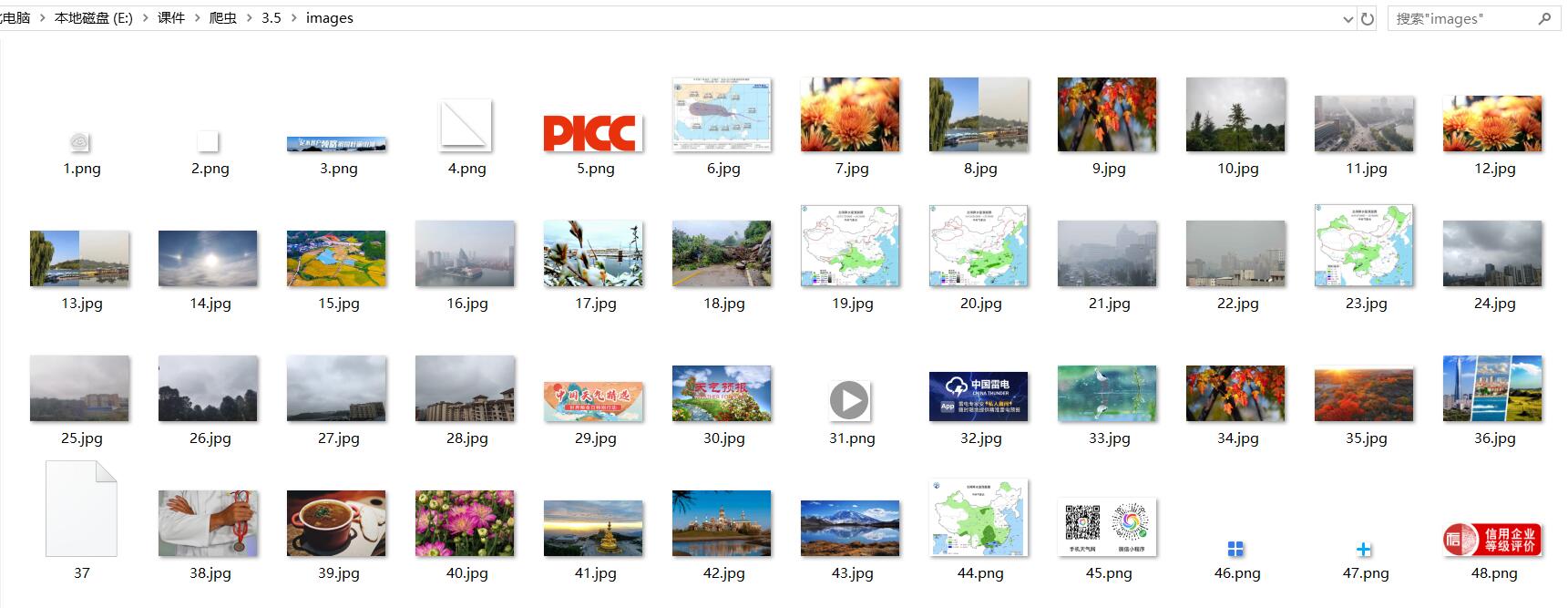
代码2.多线程运行:
from bs4 import BeautifulSoup from bs4 import UnicodeDammit import urllib.request import threading def imageSpider(start_url): global thread global count try: urls = [] req = urllib.request.Request(start_url, headers=headers) data = urllib.request.urlopen(req) data = data.read() dammit = UnicodeDammit(data, ["utf-8", "gbk"]) data = dammit.unicode_markup soup = BeautifulSoup(data, "html.parser") images1 = soup.select("img") for image in images1: try: src = image["src"] url = urllib.request.urljoin(start_url, src) if url not in urls: urls.append(url) print(url) count = count + 1 T = threading.Thread(target=download, args=(url, count)) T.setDaemon(False) T.start() thread.append(T) except Exception as errrrrrrrrrrrrrrrrrrror: print(errrrrrrrrrrrrrrrrrrror) except Exception as errrrrrrrrrrrrrrrrrrror: print(errrrrrrrrrrrrrrrrrrror) def download(url, count): try: count=count+1 if (url[len(url) - 4] == "."): ext = url[len(url) - 4:] else: ext = "" req = urllib.request.Request(url, headers=headers) data = urllib.request.urlopen(req, timeout=100) data = data.read() fobj = open("images2\\" + str(count) + ext, "wb") fobj.write(data) fobj.close() print("downloaded " + str(count) + ext) except Exception as errrrrrrrrrrrrrrrrrrror: print(errrrrrrrrrrrrrrrrrrror) start_url = "http://weather.com.cn/weather/101280601.shtml" headers = {"User-Agent":"Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre"} count = 0 thread = [] imageSpider(start_url) for t in thread: t.join() print("the End")
结果:
看起来很正常,很多线程......嗯?
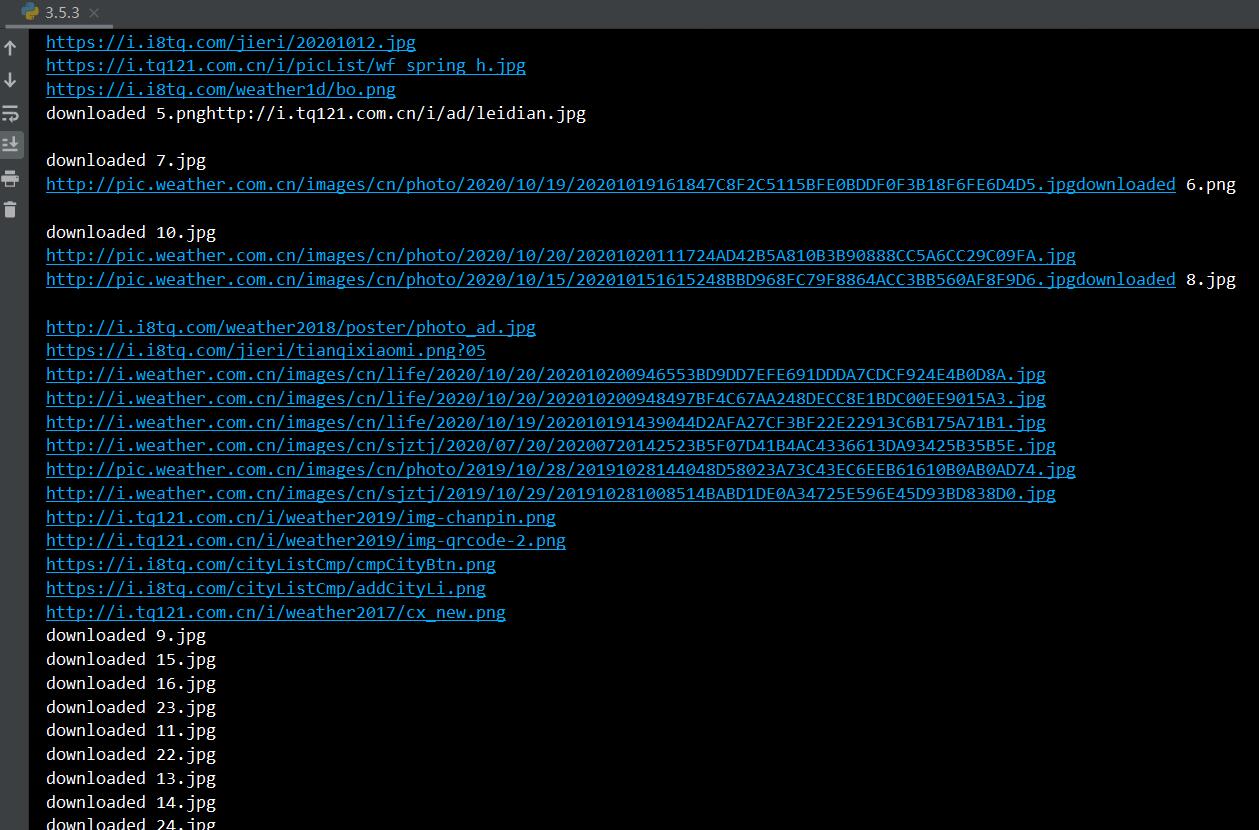
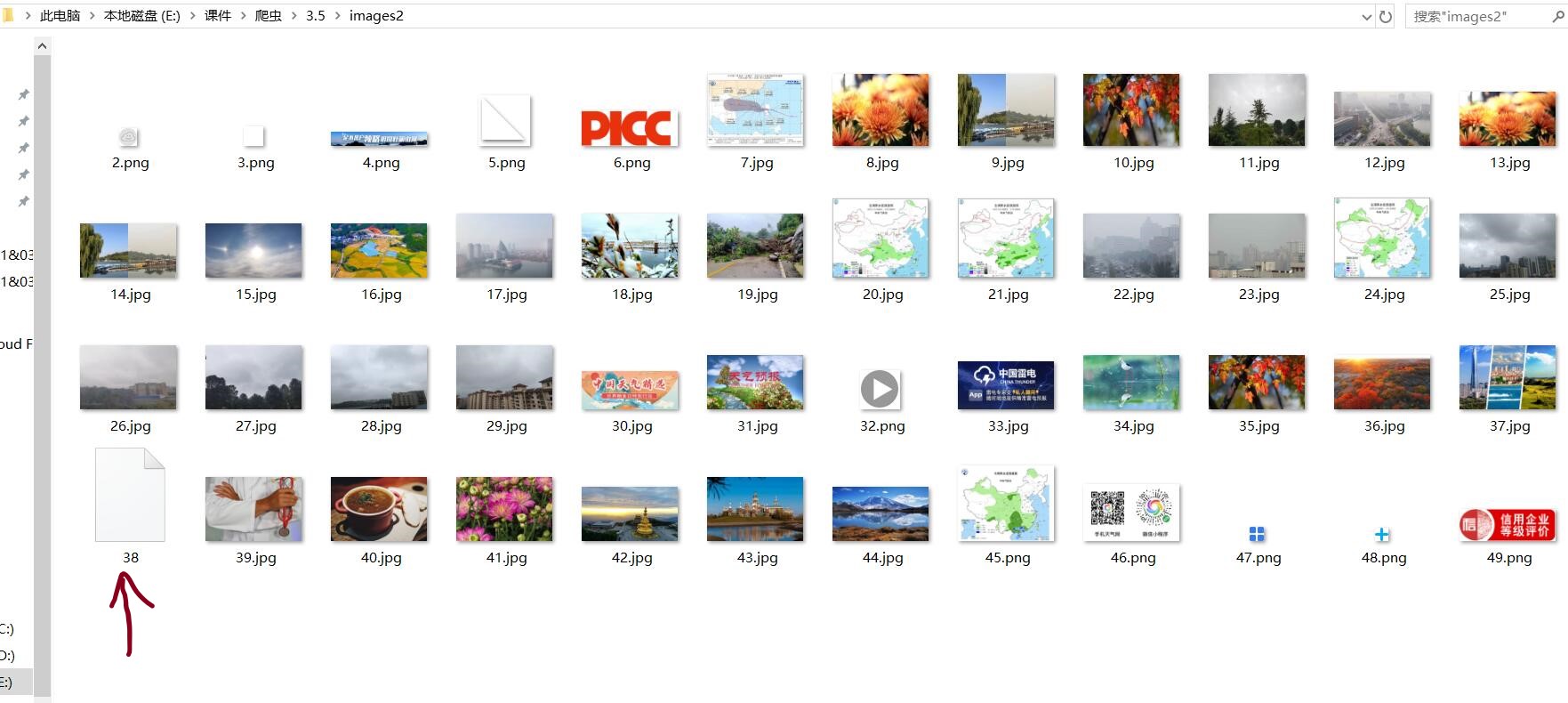
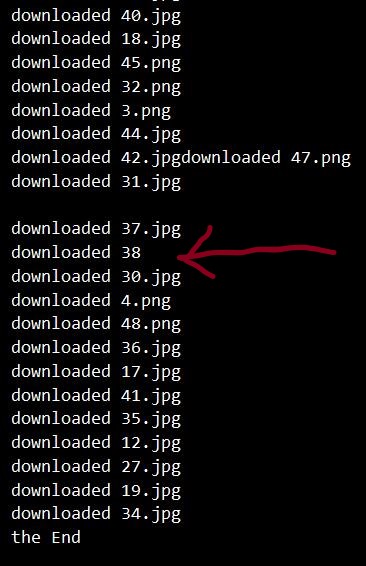
仔细检查后发现,多线程运行时有小概率会出现代码被跳过的情况,导致甚至有图片没有加上后缀名。
总结:再次尝试了多线程运行,虽然没有加上time()来测速,但毫无疑问多线程会更快一些。
只是这个连线程内代码都能被跳过的机制,在弄明白之前我实在有点不敢用......
作业②
-
要求:使用scrapy框架复现作业①。
- 代码:
- MySpider.py:
-
import scrapy from items import WeatherPhotoItem from scrapy.selector import Selector class Spider_weatherphoto(scrapy.Spider): name = "weatherspider" start_urls=["http://www.weather.com.cn/"] def parse(self, response): try: data = response.body.decode() selector = Selector(text=data) s=selector.xpath("//img/@src").extract() for e in s: item=WeatherPhotoItem() item["pic"] = [e] yield item except Exception as err: print(err)pinelines.py:
-
import os import urllib class GetpicturePipeline: cnt = 1 urlstream = [] def process_item(self, item, spider): GetpicturePipeline.cnt += 1 try: if not os.path.exists('images3'): os.mkdirs('images3') if item['url'] not in GetpicturePipeline.urlstream: data = urllib.request.urlopen(item['url']).read() with open('images3/' + str(GetpicturePipeline.cnt) + '.jpg', "wb") as f: f.write(data) except Exception as err: print(err) return itemitems.py:
-
import scrapy class WeatherPhotoItem(scrapy.Item): pic= scrapy.Field() pass
结果:
![]()
- 总结:第一次尝试了scrapy框架和xpath,实事求是的讲xpath是一个更为优秀的查找信息的语言,但在定位上会麻烦一些...
-
作业③:
-
要求:使用scrapy框架爬取股票相关信息。
- 代码:
- items.py:
-
import scrapy class GetstockItem(scrapy.Item): index = scrapy.Field() code = scrapy.Field() name = scrapy.Field() latestPrice = scrapy.Field() seeSawedRange = scrapy.Field() seeSawedPrice = scrapy.Field() highest = scrapy.Field() lowest = scrapy.Field() today = scrapy.Field() yesterday = scrapy.Field() passpipelines.py
-
import prettytable as pt class GetstockPipeline: tb = pt.PrettyTable(["序号", "股票代码", "股票名称", "最新报价", "涨跌幅", "涨跌额", "最高", "最低", "今开", "昨收"]) def process_item(self, item, spider): self.tb.add_row( [item["index"], item["code"], item["name"], item["latestPrice"], item["seeSawedRange"], item["seeSawedPrice"],item["highest"], item["lowest"], item["today"],item["yesterday"]]) return item -
MySpider.py
-
import scrapy import re from getstock.pipelines import GetstockPipeline from getstock.items import GetstockItem
class MySpider(scrapy.Spider): name = "mySpider" def start_requests(self): url = 'http://19.push2.eastmoney.com/api/qt/clist/get?cb=jQuery112403324490377009397_1602209502288&pn=1&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&fid=f3&fs=m:0+t:6,m:0+t:13,m:0+t:80,m:1+t:2,m:1+t:23&fields=f12,f14,f2,f3,f4,f5,f6,f7,f15,f16,f17,f18&_=1602209502289' yield scrapy.Request(url=url, callback=self.parse) def parse(self,response): try: r = response.body.decode() pat = '\[(.*?)\]' data = re.compile(pat, re.S).findall(r) datas = data[0].split("},{") datas[0] = datas[0].replace('{', '') datas[-1] = datas[-1].replace('}', '') for i in range(len(datas)): item = GetstockItem() item["index"] = i+1 item["code"] = datas[i].split(",")[6].split(":")[1] item["name"] = datas[i].split(",")[7].split(":")[1] item["latestPrice"] = datas[i].split(",")[0].split(":")[1] item["seeSawedRange"] = datas[i].split(",")[1].split(":")[1] item["seeSawedPrice"] = datas[i].split(",")[2].split(":")[1] item["highest"] = datas[i].split(",")[8].split(":")[1] item["lowest"] = datas[i].split(",")[9].split(":")[1] item["today"] = datas[i].split(",")[10].split(":")[1] item["yesterday"] = datas[i].split(",")[11].split(":")[1] yield item print(GetstockPipeline.tb) except Exception as err: print(err)总结:
- 这次实验进一步增强了我对scrapy框架的理解,并尝试使用了一个更为优秀的第三方库以排版输出结果,主体部分还是参考了之前上一次优秀作业的代码,创新度较少。
-

 浙公网安备 33010602011771号
浙公网安备 33010602011771号