第二次作业
作业①:
要求:在中国气象网(http://www.weather.com.cn)给定城市集的7日天气预报,并保存在数据库。
代码:
from bs4 import BeautifulSoup
from bs4 import UnicodeDammit
import urllib.request
import sqlite3
class WeatherDB:
def openDB(self):
self.con=sqlite3.connect("weathers.db")
self.cursor=self.con.cursor()
try:
self.cursor.execute("create table weathers (wCity varchar(16),wDate varchar(16),wWeather varchar(64),wTemp varchar(32),constraint pk_weather primary key (wCity,wDate))")
except:
self.cursor.execute("delete from weathers")
def closeDB(self):
self.con.commit()
self.con.close()
def insert(self, city, date, weather, temp):
try:
self.cursor.execute("insert into weathers (wCity,wDate,wWeather,wTemp) values (?,?,?,?)",
(city, date, weather, temp))
except Exception as err:
print(err)
def show(self):
self.cursor.execute("select * from weathers")
rows = self.cursor.fetchall()
print("%-16s%-16s%-32s%-16s" % ("city", "date", "weather", "temp"))
for row in rows:
print("%-16s%-16s%-32s%-16s" % (row[0], row[1], row[2], row[3]))
class WeatherForecast:
def __init__(self):
self.headers = {
"User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre"}
self.cityCode = {"北京": "101010100", "上海": "101020100", "广州": "101280101", "深圳": "101280601"}
def forecastCity(self, city):
if city not in self.cityCode.keys():
print(city + " code cannot be found")
return
url = "http://www.weather.com.cn/weather/" + self.cityCode[city] + ".shtml"
try:
req = urllib.request.Request(url, headers=self.headers)
data = urllib.request.urlopen(req)
data = data.read()
dammit = UnicodeDammit(data, ["utf-8", "gbk"])
data = dammit.unicode_markup
soup = BeautifulSoup(data, "lxml")
lis = soup.select("ul[class='t clearfix'] li")
for li in lis:
try:
date = li.select('h1')[0].text
weather = li.select('p[class="wea"]')[0].text
temp = li.select('p[class="tem"] span')[0].text + "/" + li.select('p[class="tem"] i')[0].text
print(city, date, weather, temp)
self.db.insert(city, date, weather, temp)
except Exception as err:
print(err)
except Exception as err:
print(err)
def process(self, cities):
self.db = WeatherDB()
self.db.openDB()
for city in cities:
self.forecastCity(city)
# self.db.show()
self.db.closeDB()
ws = WeatherForecast()
ws.process(["北京", "上海", "广州", "深圳"])
print("completed")
结果:

心得体会:
这次实验主要是实现书本代码复现,顺便学习了将爬取结果存入.db数据库内。
另外有一个极其有趣的地方:和同学交流时发现这个代码在白天晚上爬取的效果不同?于是我试了一下:
这是白天爬取:
这是晚上爬取:
破案了,他们每天傍晚会把今天的天气预测拿掉所以会list out of range...
作业②
要求:用requests和BeautifulSoup库方法定向爬取股票相关信息。
代码:
import pandas as pd
import time
def getHtml(cmd):#用get方法访问服务器并提取页面数据
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 "
"(KHTML, like Gecko) Chrome/86.0.4240.75 Safari/537.36"
}
url = "http://nufm.dfcfw.com/EM_Finance2014NumericApplication/JS.aspx?"\
"cb=jQuery112406115645482397511_1542356447436&type=CT"\
"&token=4f1862fc3b5e77c150a2b985b12db0fd&sty=FCOIATC"\
"&js""=(%7Bdata%3A%5B(x)%5D%2CrecordsFiltered%3A(tot)%7D)"\
"&cmd={cmd}&st=" \
"(ChangePercent)&sr=-1&p=1&ps=500&_={present_time}"
present_time = int(round(time.time() * 1000)) #增加一个当前时间
r = requests.get(url.format(cmd=cmd, present_time=present_time), headers=headers)
html = r.content.decode()
return html
def getOnePageStock(cmd):#获取单个页面股票数据
data = getHtml(cmd)
coloums = ['代码', '名称', '最新价格', '涨跌额', '涨跌幅', '成交量', '成交额', '振幅', '最高', '最低','今开', '昨收', '今开']
datas = data.split('["')[1].split('"]')[0].split('","')
dic_data = len(datas)
items = []
for i in range(dic_data):
item = dict(zip(coloums, datas[i].split(',')[1:13]))#做出一个字典
items.append(item)
return items
def main():
cmd = {
"上证指数":"C.1",
"深圳指数":"C.5",
"沪深A股":"C._A",
"上证A股":"C.2",
"深圳A股":"C._SZAME",
"新股":"C.BK05011",
"中小板":"C.13",
"创业板":"C.80"
}
for i in cmd.keys():
stocks = getOnePageStock(cmd[i])
df = pd.DataFrame(stocks)
try:
fp=open("Stock/"+i+".xls", "w")
df.to_excel("Stock/"+i+".xls")
except Exception as e:
print(e)
finally:
fp.close()
print("已保存"+i+".xls")
main()```
##结果:
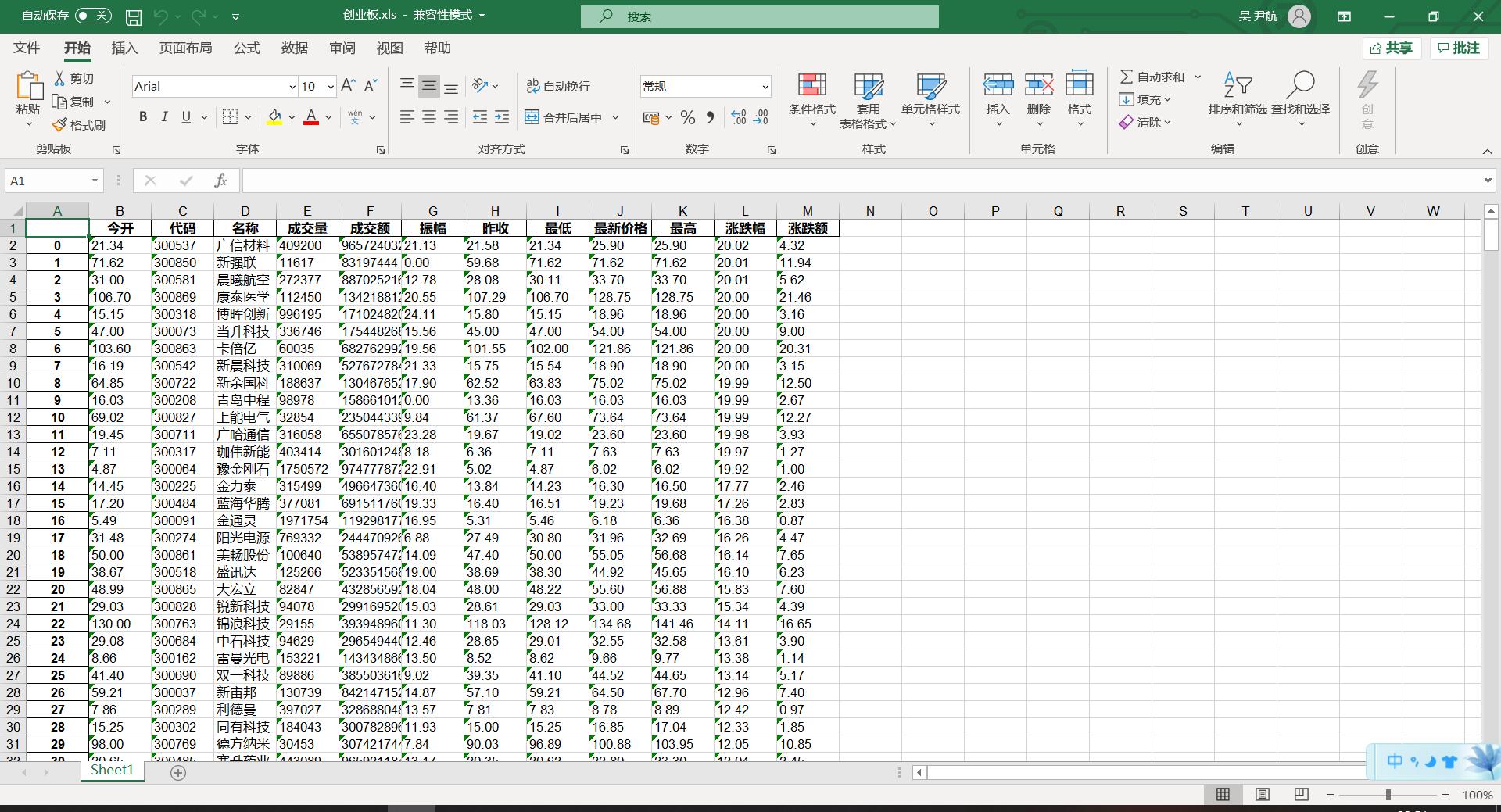
##心得体会:
虽然好像是要求BS库,但我还是在参考交流了同学的意见后把那篇专栏实例的代码修改到了可运行的水平。
学习了如何处理json和动态网页,难度尚可。
#作业③:
##要求:根据自选3位数+学号后3位选取股票,获取印股票信息。抓包方法同作②。
##代码:
```import requests
import re
import time
def getHtml(num):
url = "https://30.push2.eastmoney.com/api/qt/clist/get?cb=jQuery1124004229850317009731_1585637567592&pn=sh"+str(num)+"&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&fid=f3&fs=m:0+t:5&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f26,f22,f33,f11,f62,f128,f136,f115,f152&_=1585637567593"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 "
"(KHTML, like Gecko) Chrome/86.0.4240.75 Safari/537.36"
}
present_time = int(round(time.time() * 1000)) #增加一个当前时间
r = requests.get(url.format(num=num, present_time=present_time), headers=headers)
html = r.content.decode()
return html
def getItems(num):
data = getHtml(num)
datas = re.compile(r"{\"f.*\"}", re.S).findall(data) #用正则表达式处理目标数据
item = eval(datas[0])
return item
def Get_My_Stock(num):
choicestock = getItems(num)
choicestock.field_names = ["代码", "名称", "今开", "最高", "最低"]
choicestock.add_row([choicestock['f57'], choicestock['f58'], choicestock['f46'], choicestock['f44'], choicestock['f45']])#这是股票所需数据在json串中对应变量
print(choicestock)
num = '002131'
Get_My_Stock(num)```
##结果:
(选择002+131)

##心得体会:
对实验2进行了一些修改。
我的代码不支持对2的数据库进行查找只能提前自选,之后可能参考其他同学加以改进。
 浙公网安备 33010602011771号
浙公网安备 33010602011771号