不同聚类算法对比
参考 : https://blog.csdn.net/abc200941410128/article/details/78541273?locationNum=1&fps=1
聚类算法的目的就是将相似的数据对象划分为一类或者簇,使得在同一个簇内的数据对象尽可能相似,不同簇中的数据对象尽可能不相似。
常见的聚类方法有如下几种:
1.划分聚类(KMeans);
2.层次聚类;
3.密度聚类(DBSCAN);
4.模型聚类;
5.谱聚类
1.层次聚类
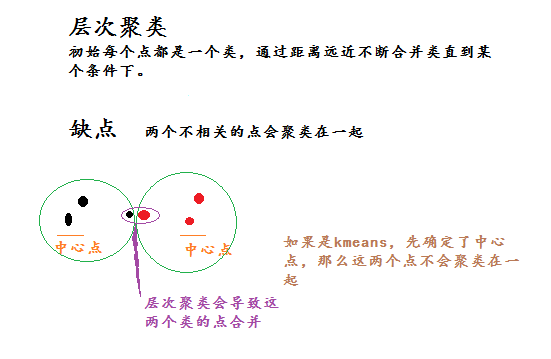
层次聚类主要有两种类型:合并的层次聚类和分裂的层次聚类。前者是一种自底向上的层次聚类算法,从最底层开始,每一次通过合并最相似的聚类来形成上一层次中的聚类,整个当全部数据点都合并到一个聚类的时候停止或者达到某个终止条件而结束,大部分层次聚类都是采用这种方法处理。后者是采用自顶向下的方法,从一个包含全部数据点的聚类开始,然后把根节点分裂为一些子聚类,每个子聚类再递归地继续往下分裂,直到出现只包含一个数据点的单节点聚类出现,即每个聚类中仅包含一个数据点。
优点:可解释性好(如当需要创建一种分类法时);还有些研究表明这些算法能产生高质量的聚类,也会应用在上面说的先取K比较大的K-means后的合并阶段;还有对于K-means不能解决的非球形族就可以解决了。
缺点:时间复杂度高啊,o(m^3),改进后的算法也有o(m^2lgm),m为点的个数;贪心算法的缺点,一步错步步错。
BIRCH算法:
适合样本量较大的数据集;
适合类别数比较多的数据集;
不适合特征维数较高的数据集。
2.划分聚类
优点:对于大型数据集也是简单高效、时间复杂度、空间复杂度低。
缺点:最重要是数据集大时结果容易局部最优;需要预先设定K值,对最先的K个点选取很敏感;对噪声和离群值非常敏感;只用于numerical类型数据;不能解决非凸(non-convex)数据。
常见算法及改进:
k-means对初始质心的选取很敏感,所以有了k-means++、intelligent k-means、genetic k-means。
k-means对噪声和离群值非常敏感,所以有了k-medoids和k-medians。
k-means只用于numerical类型数据,不适用于categorical类型数据,所以有了k-modes。
k-means不能解决非凸(non-convex)数据,所以有了kernel k-means
2.1 k-means++
k-means++的基本思想是:初始的聚类中心之间的相互距离要尽可能的远。算法步骤如下:
1.从输入的数据点集合中随机选择一个点作为第一个聚类中心;
2.对于数据集中的每一个点x,计算它与最近聚类中心(指已选择的聚类中心)的距离D(x);
3.选择一个新的数据点作为新的聚类中心,选择的原则是:D(x)较大的点,被选取作为聚类中心的概率较大;
4.重复2和3直到k个聚类中心被选出来;
5.利用这k个初始的聚类中心来运行标准的k-means算法。
关于k-means++ 的详细过程,可参考 https://www.cnblogs.com/wang2825/articles/8696830.html
2.2 k-modes
K-modes算法可以看做是k-means算法在非数值属性集合上的版本。算法步骤如下:
1.随机确定k个聚类中心C1,C2...Ck,Ci是长度为M的向量,Ci=[C1,C2,...,Ci];
2.对于样本Xj (j=1,2,...,N),分别比较其与k个中心之间的距离(这里的距离为不同属性值的个数,假如x1=[1,2,1,3],C1=[1,2,3,4]x1=[1,2,1,3],C1=[1,2,3,4],那么X1与C1之间的距离为2)
3.将Xj划分到距离最小的簇,在全部的样本都被划分完毕之后,重新确定簇中心,向量Ci中的每一个分量都更新为簇i中的众数,如{[a,1] [a,2] [b,1] [a,1] [c,3]}的簇中心为[a,1];
4.重复步骤二和三,直到总距离(各个簇中样本与各自簇中心距离之和)不再降低,返回最后的聚类结果。
3.密度聚类
DBSCAN算法流程:
1.从任一对象点p开始;
2.寻找并合并核心p对象直接密度可达(eps)的对象;
3.如果p是一个核心点,则找到了一个聚类,如果p是一个边界点(即从p没有密度可达的点)则寻找下一个对象点;
4.重复2、3,直到所有点都被处理。
优点:
1. 速度快,复杂度log(N)*N^2;
2. 对噪声不敏感;能发现任意形状的聚类。
缺点:
1.参数难以控制,对聚类效果影响大,也可以说是参数敏感;
即:因为DBSCAN使用簇的基于密度的定义,因此它是相对抗噪音的,并且能处理任意形状和大小的簇。但是如果簇的密度变化很大,例如ABCD四个簇,AB的密度大大大于CD,而且AB附近噪音的密度与簇CD的密度相当,这是当MinPs较大时,无法识别簇CD,簇CD和AB附近的噪音都被认为是噪音;当MinPs较小时,能识别簇CD,但AB跟其周围的噪音被识别为一个簇。
2.DBSCAN用固定参数识别聚类,但当聚类的稀疏程度不同时,相同的判定标准可能会破坏聚类的自然结构较稀的聚类会被划分为多个类或密度较大且离得较近的类会被合并成一个聚类。
层次聚类和密度聚类共同的缺点:
4.模型聚类
高斯混合模型(GMM)和K-means对比:
相似点:
两者的分类受初始值影响;两者可能限于局部最优解;两者类别的个数都要靠猜测。
不同点:
k-means属于硬分类,明确给出分类结果,GMM属于软分类,给出属于每个类的概率值;
k-means计算距离采用欧式距离,GMM采用马氏距离;
GMM模型可以给出聚类分组的概率。
5.谱聚类
谱聚类的适用性比k-means好,不仅仅适用于凸数据集;
谱聚类根据数据间的相似度矩阵进行聚类,因此对稀疏数据的聚类比较有效。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号