Xgboost小结与调参
1、Xgboost对GBDT的优化
- 算法层面
1.XGB增加了正则项,能够防止过拟合。正则项为树模型复杂度,通过叶子节点数量和叶节点的值定义树模型复杂度。
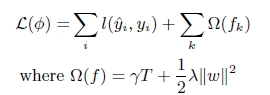
T为叶子节点的数量,这T个叶子节点的值,组成了T维向量ω。
2.XGB损失函数是误差部分是二阶泰勒展开,GBDT 是一阶泰勒展开。因此损失函数近似的更精准。
3. XGB对每颗子树增加一个参数,使得每颗子树的权重降低,防止过拟合,这个参数叫shrinkage,对特征进行降采样,灵感来源于随机森林,除了能降低计算量外,还能防止过拟合。
4.采用百分位数法,计算特征的最佳分裂点。在寻找最佳分割点时,考虑传统的枚举每个特征的所有可能分割点的贪心法效率太低,xgboost实现了一种近似的算法。大致的思想是根据百分位法列举几个可能成为分割点的候选者,然后从候选者中根据上面求分割点的公式计算找出最佳的分割点。
5.增加处理缺失值的方案(通过枚举所有缺失值在当前节点是进入左子树,还是进入右子树更优来决定一个处理缺失值默认的方向)。
6.交叉验证,early stop,当预测结果已经很好的时候可以提前停止建树,加快训练速度。
7.Shrinkage,你可以是几个回归树的叶子节点之和为预测值,也可以是加权,比如第一棵树预测值为3.3,label为4.0,第二棵树才学0.7,….再后面的树还学个鬼,所以给他打个折扣,比如3折,那么第二棵树训练的残差为4.0-3.3*0.3=3.01,这就可以发挥了啦,以此类推,作用是啥,防止过拟合,如果对于“伪残差”学习,那更像梯度下降里面的学习率;
8.支持并行化,这是XGB的闪光点,虽然树与树之间是串行关系,但是同层级节点可并行。具体的对于某个节点,节点内选择最佳分裂点,候选分裂点计算增益用多线程并行。训练速度快。
- 系统层面
1.对每个特征进行分块(block)并排序,使得在寻找最佳分裂点的时候能够并行化计算。这是xgboost比一般GBDT更快的一个重要原因。
2.通过设置合理的block的大小,充分利用了CPU缓存进行读取加速(cache-aware access)。使得数据读取的速度更快。因为太小的block的尺寸使得多线程中每个线程负载太小降低了并行效率。太大的block尺寸会导致CPU的缓存获取miss掉。
3.out-of-core 通过将block压缩(block compressoin)并存储到硬盘上,并且通过将block分区到多个硬盘上(block Sharding)实现了更大的IO 读写速度,因此,因为加入了硬盘存储block读写的部分不仅仅使得xgboost处理大数据量的能力有所提升,并且通过提高IO的吞吐量使得xgboost相比一般实利用这种技术实现大数据计算的框架更快。
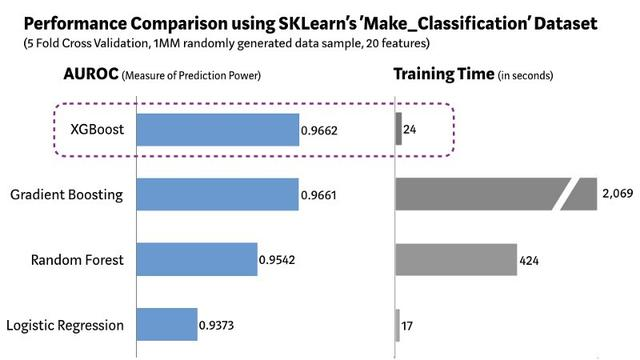
2、Xgboost训练时长
(图片来自 机器之心)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号