python编程小知识
python基础小知识
字符串
r保持字符串
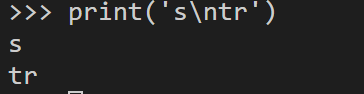
# 此时\n会转义为换行符
print('s\ntr')
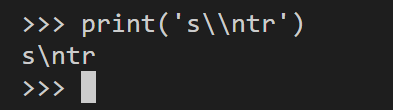
# 第1种防止转义
print('s\\ntr')
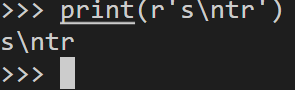
# 第2种防止转义
print(r's\ntr')
\符号
作为转义字符
# 此时\n会转义为换行符
print('s\ntr')
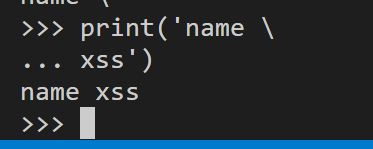
作为续行字符
print('name \
xss')
*复制字符串
print('new'*2)

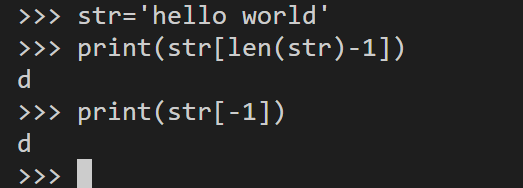
字符串索引
字符串支持从前到后0-len(str)进行遍历,也支持从[-1, -(len(str))]进行反向遍历
str='hello world'
print(str[len(str)-1])
print(str[-1])
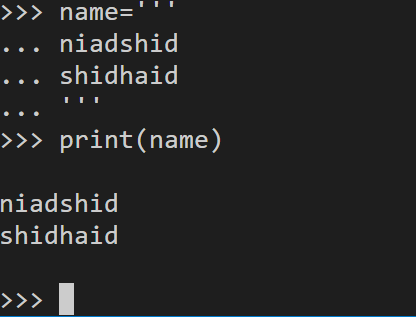
'''3引号
'''3引号可以用来实现一个字符串跨多行
name='''
niadshid
shidhaid
'''
\r回车符号
\r回车符号,会将后面的字符覆盖前面的,字符可以用来实现进度条
print('hello\rworld') # 输出world

字符串内建函数
str='aces'
str.capitalize() # 字符串第1个转换为大小,输出为Aces
str.swapcase() # 将字符串中字母的大小颠倒
str.title() # 将字符串标题化
center(width, fillchar) # 返回一个指定宽度居中的字符串,填充字符为fillchar,默认是空格
count(str, begin, end) # 计算字符str在字符串范围内[begin, end]内的数量
endwith(suffix, begin, end) # 查看字符串范围内是否以suffix结尾
startswith(substr, begin, end) # 查看字符串是否以substr开头
expandtabs(tabsize=8) # 将tab转为空格
find(str, begin, end) # 查找字符,如果找到则返回索引,否则返回-1
index(str, begin, end) # 查找字符,如果找不到会抛出异常
isalnum() # 是否字母和数字
isalpha() # 是否是字母
isdigit() # 是否是数字
islower() # 是否都是小写
isnumeric() # 是否只包含数字
isspace() # 是否是空格
istitle() # 字符串是否是标题化的
str.join(seq) # 以str为字符连接序列中的元素
stripe # 去掉两侧空格
lstrip(str) # 截掉左边空格或者指定字符
rstipe() # 截掉右边空格或者指定字符
max(str) # 返回字符串中最大的
min(str) # 返回字符串中最小的
str.replace(old, new, times) # 将str中old字符串替换为new字符串,最多替换times次
rfind() # 从右侧找
split(str, num) # 以分隔符截取字符串,num指定分割次数,所以会分割num+1个字符串
splitlines(True) # 表示包含换行符,将每行划分为一个列表
splitlines(False) # 默认就是不包含换行符的,将每行划分为一个列表
列表
同样也可以正反向索引,截取列表,列表是可变的
更新列表
list1.append('name') # 增加一个元素
del list1[2] # 删除列表中第3个元素
列表基础操作
列表基础操作支持+,*,in
for x in list1: print(x, end=' ')
列表嵌套
x=[[1,2,3],[4,5,6]]
x[0][1]
集合
集合被一个{}围绕,可以使用set()创建一个空集合,集合会自动去除重复元素
支持对集合取&交集、|并集、-差集、^两集合中同时不存在的元素
nset=set()
字典
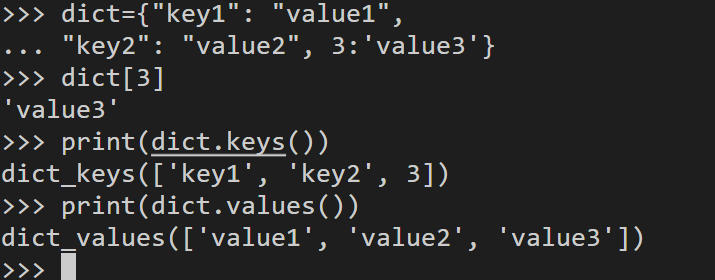
字典与列表的区别是,字典是通过键值进行索引,列表通过偏移进行索引,典型的字典如
dict={"key1": "value1",
"key2": "value2", 3:'value3'}
print(dict[3]) # 输出value3
print(dict.keys()) # 输出所有的key
print(dict.values()) # 输出所有的值
运算符
is运算符
is和==的运算符的区别是,is判断的变量引用的对象是否是同一个,==只是判断值是否相同
a=[1, 2, 3]
b=a
print(b is a) # 返回 true
b=a[:]
print(b is a) # 此时b是一个新的对象,返回False
# 对于可变类型(如列表),b = a[:]会创建一个新的对象,b和a是不同的对象。
函数装饰器decorator
函数装饰器,必须返回一个可用的打包函数对象
普通方式
print('hello')
def happy(func):
def wrapper():
print('appache')
func()
return wrapper
@happy
def hi():
print('name')
hi()
print(hi.__name__) # 输出的是wrapper, 此时重写了函数名
更标准的方式
from functools import wraps
print('hello')
def happy(func):
@wraps(func) # 解决重写函数名问题
def wrapper():
print('appache')
func()
return wrapper
@happy
def hi():
print('name')
hi()
print(hi.__name__) # 输出的是wrapper

 浙公网安备 33010602011771号
浙公网安备 33010602011771号