RabbitMq篇
RabbitMq是使用Erlang语言开发的开源消息队列系统,基于AMQP协议来实现。
1、特点
-
可靠性:RabbitMq使用一些机制来保证可靠性,如持久化、传输确认及发布确认等。
-
灵活的路由:在消息进入队列之前,通过交换器来路由消息。对于典型的路由功能,RabbitMq己经提供了一些内置的交换器来实现。针对更复杂的路由功能,可以将多个 交换器绑定在一起,也可以通过插件机制来实现自己的交换器。
-
扩展性:多个RabbitMq节点可以组成一个集群,也可以根据实际业务情况动态地扩展 集群中节点。
-
高可用性:队列可以在集群中的机器上设置镜像,使得在部分节点出现问题的情况下队 列仍然可用。
-
多种协议:RabbitMq除了原生支持AMQP协议,还支持STOMP,MQTT等多种消息 中间件协议。
-
多语言客户端:RabbitMq几乎支持所有常用语言,比如Java、Python、Ruby、PHP、C#、JavaScript等。
-
管理界面:RabbitMq提供了一个易用的用户界面,使得用户可以监控和管理消息、集 群中的节点等。
-
令插件机制:RabbitMq提供了许多插件 ,以实现从多方面进行扩展,当然也可以编写自 己的插件。
2、基本的概念模型
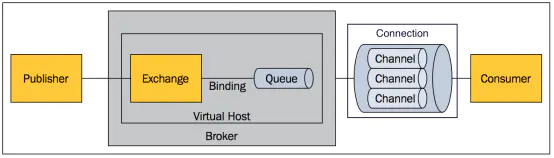
-
Message消息:消息是不具名的,它由消息头和消息体组成。消息体是不透明的,而消息头则由一系列的可选属性组成,这些属性包括routing-key(路由键)、priority(相对于其他消息的优先权)、delivery-mode(指出该消息可能需要持久性存储)等。
-
Publisher消息的生产者:也是一个向交换器发布消息的客户端应用程序。
-
Exchange交换器:用来接收生产者发送的消息并将这些消息路由给服务器中的队列。
-
Binding绑定:用于消息队列和交换器之间的关联。一个绑定就是基于路由键将交换器和消息队列连接起来的路由规则,所以可以将交换器理解成一个由绑定构成的路由表。
-
Queue消息队列:用来保存消息直到发送给消费者。它是消息的容器,也是消息的终点。一个消息可投入一个或多个队列。消息一直在队列里面,等待消费者连接到这个队列将其取走
-
Connection网络连接:比如一个TCP连接。
-
Channel信道:多路复用连接中的一条独立的双向数据流通道。信道是建立在真实的TCP连接内地虚拟连接,AMQP 命令都是通过信道发出去的,不管是发布消息、订阅队列还是接收消息,这些动作都是通过信道完成。因为对于操作系统来说建立和销毁 TCP 都是非常昂贵的开销,所以引入了信道的概念,以复用一条 TCP 连接。
-
Virtual Host虚拟主机:表示一批交换器、消息队列和相关对象。虚拟主机是共享相同的身份认证和加密环境的独立服务器域。每个 vhost 本质上就是一个 mini 版的 RabbitMq服务器,拥有自己的队列、交换器、绑定和权限机制。vhost 是 AMQP 概念的基础,必须在连接时指定,RabbitMq默认的vhost是
/。 -
Broker:表示消息队列服务器实体。
3、六种工作模式
3.1、simple简单模式
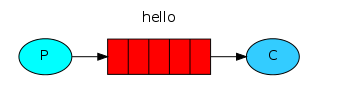
最简单的一对一模式,一个生产者,一个消费者。
3.2、work工作模式(资源的竞争)
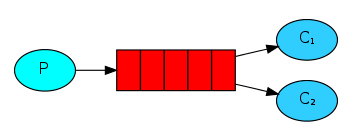
一对多模式,一个生产者,多个消费者,一个队列。一个消息只能被一个消费者消费。
消息分发机制:
-
轮询分发:在消费之前就会把消息均等分成几份,然后把这几份消息一次性的发给消费者,让消费者消费 ,加入有10个消息,2个消费者,那么就是消息队列把消息平均分成两份,把5个消息发给一个消费者,另外5个消息发给另外5个消费者。
-
公平分发:只要有消费者空闲,就会给这个消费者发送消息。
3.3、publish/subscribe发布订阅(共享资源)
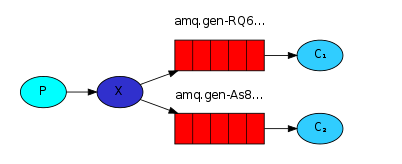
生产者把消息发送到交换机之后,交换机将消息转发到每个与它绑定的队列中。消费者监听自己队列里的消息并消费。把交换机的路由模式设置为广播(fanout)模式。
3.4、routing路由模式
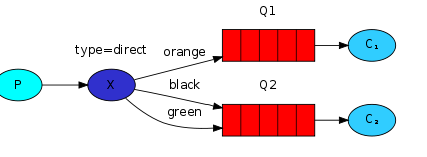
生产者将消息发送给交换机,由交换机根据routing_key分发到不同的消息队列,然后消费者同样根据routing_key来消费对应队列上的消息。把交换机的路由模式设置为定向(direct)模式。
3.5、topic主题模式(路由模式的一种)
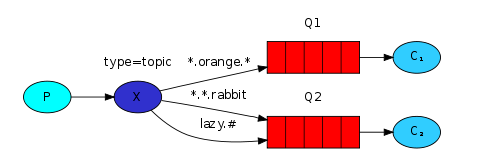
主题模式应该算是路由模式的一种,也是通过routing_key来分发,只不过是routing_key支持了正则表达式,更加灵活。把交换机的路由模式设置为(topic)模式。
-
*#代表通配符。 -
*代表一个单词,#代表零个或多个单词。
3.6、RPC远程过程调用

RPC即客户端远程调用服务端的方法 ,使用MQ可以实现RPC的异步调用,基于Direct交换机实现,流程如下:
-
客户端既是生产者也是消费者(生产了消息,消费了消息),向RPC请求队列发送RPC调用消息,同时监听RPC响应队列。
-
服务端监听RPC请求队列的消息,收到消息后执行服务端的方法,得到方法返回的结果。
-
服务端将RPC方法的结果发送到RPC响应队列。
-
客户端(RPC调用方)监听RPC响应队列,接收到RPC调用结果。
4、问题及解决方案
4.1、消息丢失
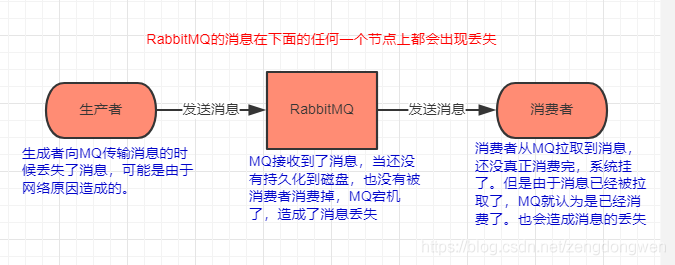
4.1.1、生产者没有成功把消息发送到MQ
-
丢失的原因:因为网络传输的不稳定性,当生产者在向MQ发送消息的过程中,MQ没有成功接收到消息,但是生产者却以为MQ成功接收到了消息,不会再次重复发送该消息,从而导致消息的丢失。
-
解决办法: 有两个解决办法:事务机制和confirm机制,最常用的是confirm机制。
4.1.1.1、事务机制
伪代码:
// 开启事务
channel.txSelect;
try {
// 这里发送消息
} catch (Exception e) {
channel.txRollback;
// 这里再次重发这条消息
}
// 提交事务
channel.txCommit;
4.1.1.2、confirm机制
RabbitMq可以开启 confirm 模式,在生产者那里设置开启 confirm 模式之后,生产者每次写的消息都会分配一个唯一的 id,如果消息成功写入 RabbitMq中,RabbitMq会给生产者回传一个 ack 消息,告诉你说这个消息 ok 了。如果 RabbitMq没能处理这个消息,会回调你的一个 nack 接口,告诉你这个消息接收失败,生产者可以发送。而且你可以结合这个机制自己在内存里维护每个消息 id 的状态,如果超过一定时间还没接收到这个消息的回调,那么可以重发。
4.1.2、RabbitMq接收到消息之后丢失了消息
-
丢失的原因:RabbitMq接收到生产者发送过来的消息,是存在内存中的,如果没有被消费完,此时RabbitMq宕机了,那么再次启动的时候,原来内存中的那些消息都丢失了。
-
解决办法:开启RabbitMq的持久化。当生产者把消息成功写入RabbitMq之后,RabbitMq就把消息持久化到磁盘。结合上面的说到的confirm机制,只有当消息成功持久化磁盘之后,才会回调生产者的接口返回ack消息,否则都算失败,生产者会重新发送。存入磁盘的消息不会丢失,就算RabbitMq挂掉了,重启之后,他会读取磁盘中的消息,不会导致消息的丢失。
持久化的配置:
-
第一点是创建 queue 的时候将其设置为持久化,这样就可以保证 RabbitMq持久化 queue 的元数据,但是它是不会持久化 queue 里的数据的。
-
第二个是发送消息的时候将消息的
deliveryMode设置为 2,就是将消息设置为持久化的,此时 RabbitMq就会将消息持久化到磁盘上去。
4.1.3、消费者弄丢了消息
-
丢失的原因:如果RabbitMq成功的把消息发送给了消费者,那么RabbitMq的ack机制会自动的返回成功,表明发送消息成功,下次就不会发送这个消息。但如果就在此时,消费者还没处理完该消息,然后宕机了,那么这个消息就丢失了。
-
解决的办法:简单来说,就是必须关闭 RabbitMq的自动
ack,可以通过一个 api 来调用就行,然后每次在自己代码里确保处理完的时候,再在程序里ack一把。这样的话,如果你还没处理完,不就没有ack了?那 RabbitMq就认为你还没处理完,这个时候 RabbitMq会把这个消费分配给别的 consumer 去处理,消息是不会丢的。
4.2、重复消费
-
原因:正常情况下,消费者在消费消息的时候,消费完毕后,会发送一个确认消息给消息队列,消息队列就知道该消息被消费了,就会将该消息从消息队列中删除;但是因为网络传输等等故障,确认信息没有传送到消息队列,导致消息队列不知道自己已经消费过该消息了,再次将消息分发给其他的消费者。
-
解决方法:保证消息的唯一性,就算是多次传输,不要让消息的多次消费带来影响;保证消息等幂性;
-
在消息生产时,MQ内部针对每条生产者发送的消息生成一个inner-msg-id,作为去重和幂等的依据(消息投递失败并重传),避免重复的消息进入队列;
-
在消息消费时,要求消息体中必须要有一个bizId(对于同一业务全局唯一,如支付ID、订单ID、帖子ID等)作为去重和幂等的依据,避免同一条消息被重复消费。
-
本文来自博客园,作者:是老胡啊,转载请注明原文链接:https://www.cnblogs.com/solar-9527/p/15909146.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号