Druid 专题

16. Druid中的maxIdle为什么是没用的?
maxIdle是Druid为了方便DBCP用户迁移而增加的,maxIdle是一个混乱的概念。连接池只应该有maxPoolSize和minPoolSize,druid只保留了maxActive和minIdle,分别相当于maxPoolSize和minPoolSize。
24. 如果DruidDataSource在init的时候失败了,不再使用,是否需要close
是的,如果DruidDataSource不再使用,必须调用close来释放资源,释放的资源包括关闭Create和Destory线程。
33. 如何设置为让连接池知道数据库已经断开了,并且自动测试连接查询
加入以下配置:
<!-- 用来检测连接是否有效的sql,要求是一个查询语句,常用select 'x'。如果validationQuery为null,testOnBorrow、testOnReturn、testWhileIdle都不会起作用。 --> <property name="validationQuery" value="SELECT 1" /> <property name="testOnBorrow" value="false" /> <property name="testOnReturn" value="false" /> <property name="testWhileIdle" value="true" />
https://github.com/alibaba/druid/wiki/%E5%B8%B8%E8%A7%81%E9%97%AE%E9%A2%98
数据源配置:
#datasource #Introductions: https://github.com/alibaba/druid/wiki/DruidDataSource%E9%85%8D%E7%BD%AE%E5%B1%9E%E6%80%A7%E5%88%97%E8%A1%A8 #https://github.com/alibaba/druid/wiki/%E9%85%8D%E7%BD%AE_DruidDataSource%E5%8F%82%E8%80%83%E9%85%8D%E7%BD%AE #初始化时建立物理连接的个数。初始化发生在显式调用init方法,或者第一次getConnection时 default:0 spring.datasource.druid.initial-size=2 #最大连接池数量。default=8+ spring.datasource.druid.max-active=20 #最小连接池数量。maxIdle已经废弃 spring.datasource.druid.min-idle=10 #获取连接时最大等待时间,单位毫秒。配置了maxWait之后,缺省启用公平锁,并发效率会有所下降,如果需要可以通过配置useUnfairLock属性为true使用非公平锁 spring.datasource.druid.max-wait=60000 #是否缓存preparedStatement,也就是PSCache。PSCache对支持游标的数据库性能提升巨大,比如说oracle。在mysql下建议关闭。default=false spring.datasource.druid.pool-prepared-statements=false #要启用PSCache,必须配置大于0,当大于0时,poolPreparedStatements自动触发修改为true。在Druid中,会存在Oracle下PSCache占用内存过多的问题,可以把这个数据配置大一些,比如100.default=-1 spring.datasource.druid.max-pool-prepared-statement-per-connection-size=-1 #用来检测连接是否有效的sql,要求是一个查询语句,常用select 'x'。如果validationQuery为null,testOnBorrow,testOnBorrow,testOnReturn,testWhileIdle都不会起作用。这个可以不配置 #spring.datasource.druid.validation-query=select 'x' #单位:秒,检测连接是否有效的超时时间。底层调用jdbc Statement对象的void. setQueryTImeout(int seconds)方法,mysql实现的不是很合理,不建议在mysql下配置此参数 #spring.datasource.druid.validation-query-timeout=60 #申请连接时执行validationQuery检测连接是否有效,做了这个配置会降低性能。default=true spring.datasource.druid.test-on-borrow=false #归还连接时执行validationQuery检测连接是否有效,做了这个配置会降低性能。default=false spring.datasource.druid.test-on-return=false #建议配置为true,不影响性能,并且保证安全性。申请连接的时候检测,如果空闲时间大于timeBetweenEvictionRunsMillis,执行validationQuery检测连接是否有效。default=false spring.datasource.druid.test-while-idle=true #连接池中的minIdle数据以内的连接,空闲时间超过minEvictableIdleTimeMillis,则会执行keepAlive操作。default=false spring.datasource.druid.keep-alive=true #配置间隔多久才进行一次检测,检测需要关闭的空闲连接,单位是毫秒 default=1分钟 #有两个含义: # (1)Destroy线程会检测连接的间隔时间,如果连接空闲时间大于等于minEvictableIdleTimeMillis则关闭物理连接 # (2)testWhileIdle的判断依据,详细看testWhileIdle属性的说明 spring.datasource.druid.time-between-eviction-runs-millis=60000 #池中的连接保持空闲而不被驱逐的最小时间,单位是毫秒 spring.datasource.druid.min-evictable-idle-time-millis=300000 #合并多个DruidDataSource的监控数据 spring.datasource.druid.use-global-data-source-stat=true #spring.datasource.druid.filters=#配置多个英文逗号分隔 # 配置StatFilter spring.datasource.druid.filter.stat.enabled=true spring.datasource.druid.filter.stat.db-type=mysql spring.datasource.druid.filter.stat.log-slow-sql=true spring.datasource.druid.filter.stat.slow-sql-millis=2000 spring.datasource.druid.filter.stat.merge-sql=true # 配置WallFilter spring.datasource.druid.filter.wall.enabled=true spring.datasource.druid.filter.wall.db-type=mysql spring.datasource.druid.filter.wall.config.delete-allow=false spring.datasource.druid.filter.wall.config.drop-table-allow=false spring.datasource.druid.filter.wall.config.create-table-allow=false spring.datasource.druid.filter.wall.config.alter-table-allow=false spring.datasource.druid.filter.wall.config.truncate-allow=false
零、类图&流程预览
本文会通过getConnection作为入口,探索在druid里,一个连接的生命周期。大体流程被划分成了以下几个主流程:
主流程1:获取连接流程
首先从入口来看看它在获取连接时做了哪些操作: 点击前往原文 https://mp.weixin.qq.com/s/p2JqgLu5qWgEpd9hfVrYuQ
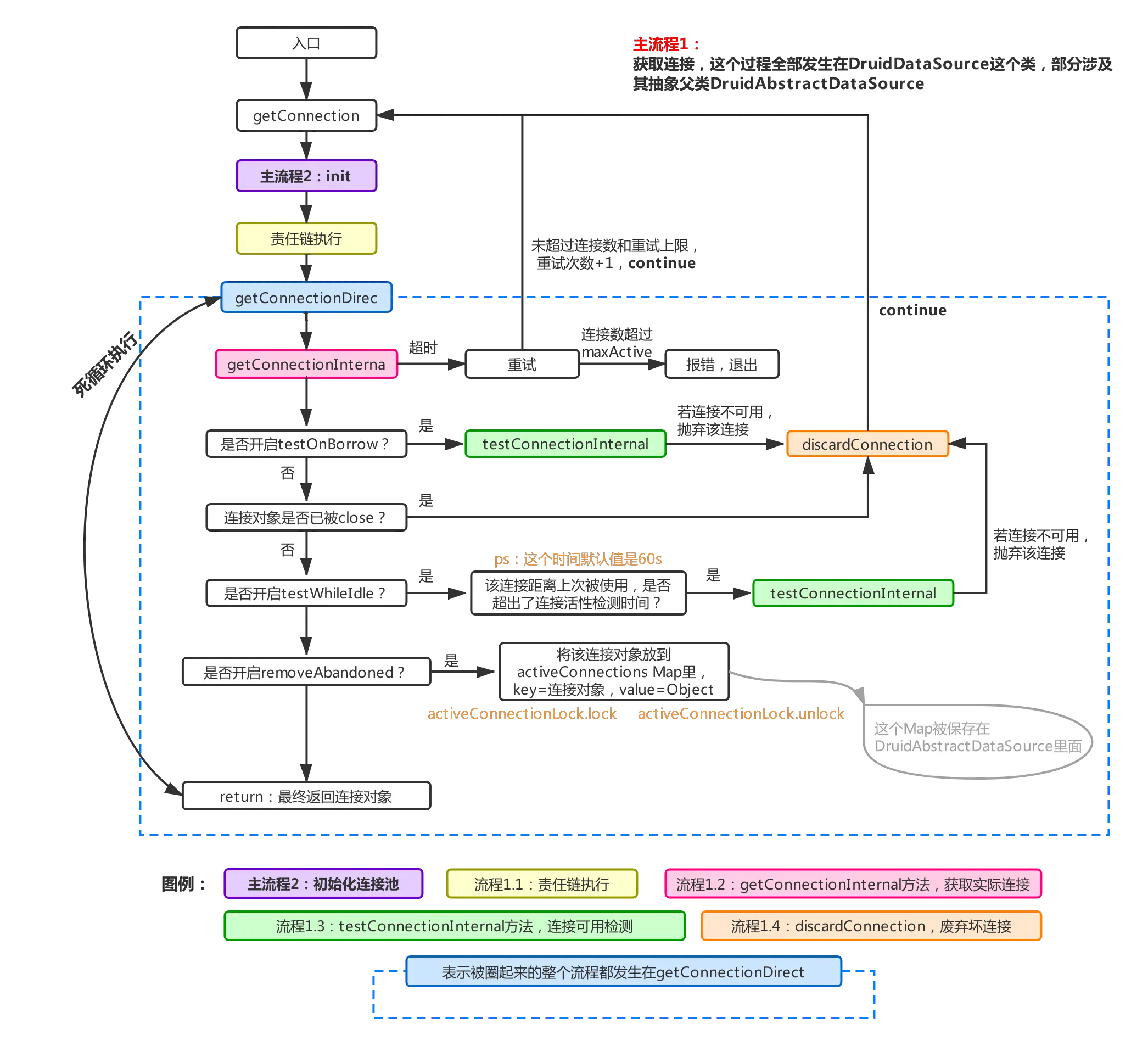
上述为获取连接时的流程图,首先会调用init进行连接池的初始化,然后运行责任链上的每一个filter,最终执行getConnectionDirect获取真正的连接对象,如果开启了testOnBorrow,则每次都会去测试连接是否可用(这也是官方不建议设置testOnBorrow为true的原因,影响性能,这里的测试是指测试mysql服务端的长连接是否断开,一般mysql服务端长连保活时间是8h,被使用一次则刷新一次使用时间,若一个连接距离上次被使用超过了保活时间,那么再次使用时将无法与mysql服务端通信)。
如果testOnBorrow没有被置为true,则会进行testWhileIdle的检查(这一项官方建议设置为true,缺省值也是true),检查时会判断当前连接对象距离上次被使用的时间是否超过规定检查的时间,若超过,则进行检查一次,这个检查时间通过timeBetweenEvictionRunsMillis来控制,默认60s。
每个连接对象会记录下上次被使用的时间,用当前时间减去上一次的使用时间得出闲置时间,闲置时间再跟timeBetweenEvictionRunsMillis比较,超过这个时间就做一次连接可用性检查,这个相比testOnBorrow每次都检查来说,性能会提升很多,用的时候无需关注该值,因为缺省值是true,经测试如果将该值设置为false,testOnBorrow也设置为false,数据库服务端长连保活时间改为60s,60s内不使用连接,超过60s后使用将会报连接错误。
若使用testConnectionInternal方法测试长连接结果为false,则证明该连接已被服务端断开或者有其他的网络原因导致该连接不可用,则会触发discardConnection进行连接回收(对应流程1.4,因为丢弃了一个连接,因此该方法会唤醒主流程3进行检查是否需要新建连接)。整个流程运行在一个死循环内,直到取到可用连接或者超过重试上限报错退出(在连接没有超过连接池上限的话,最多重试一次(重试次数默认重试1次,可以通过notFullTimeoutRetryCount属性来控制),所以取连接这里一旦发生等待,在连接池没有满的情况下,最大等待 2 × maxWait 的时间 ←这个有待验证)。
特别说明①
为了保证性能,不建议将testOnBorrow设置为true,或者说牵扯到长连接可用检测的那几项配置使用druid默认的配置就可以保证性能是最好的,如上所说,默认长连接检查是60s一次,所以不启用testOnBorrow的情况下要想保证万无一失,自己要确认下所连的那个mysql服务端的长连接保活时间(虽然默认是8h,但是dba可能给测试环境设置的时间远小于这个时间,所以如果这个时间小于60s,就需要手动设置timeBetweenEvictionRunsMillis了,如果mysql服务端长连接时间是8h或者更长,则用默认值即可。
特别说明②
为了防止不必要的扩容,在mysql服务端长连接够用的情况下,对于一些qps较高的服务、网关业务,建议把池子的最小闲置连接数minIdle和最大连接数maxActive设置成一样的,且按照需要调大,且开启keepAlive进行连接活性检查(参考流程4.1),这样就不会后期发生动态新建连接的情况(建连还是个比较重的操作,所以不如一开始就申请好所有需要的连接,个人意见,仅供参考),但是像管理后台这种,长期qps非常低,但是有的时候需要用管理后台做一些巨大的操作(比如导数据什么的)导致需要的连接暴增,且管理后台不会特别要求性能,就适合将minIdle的值设置的比maxActive小,这样不会造成不必要的连接浪费,也不会在需要暴增连接的时候无法动态扩增连接。
主流程2:初始化连接池
通过上面的流程图可以看到,在获取一个连接的时候首先会检查连接池是否已经初始化完毕(通过inited来控制,bool类型,未初始化为flase,初始化完毕为true,这个判断过程在init方法内完成),若没有初始化,则调用init进行初始化(图主流程1中的紫色部分),下面来看看init方法里又做了哪些操作:
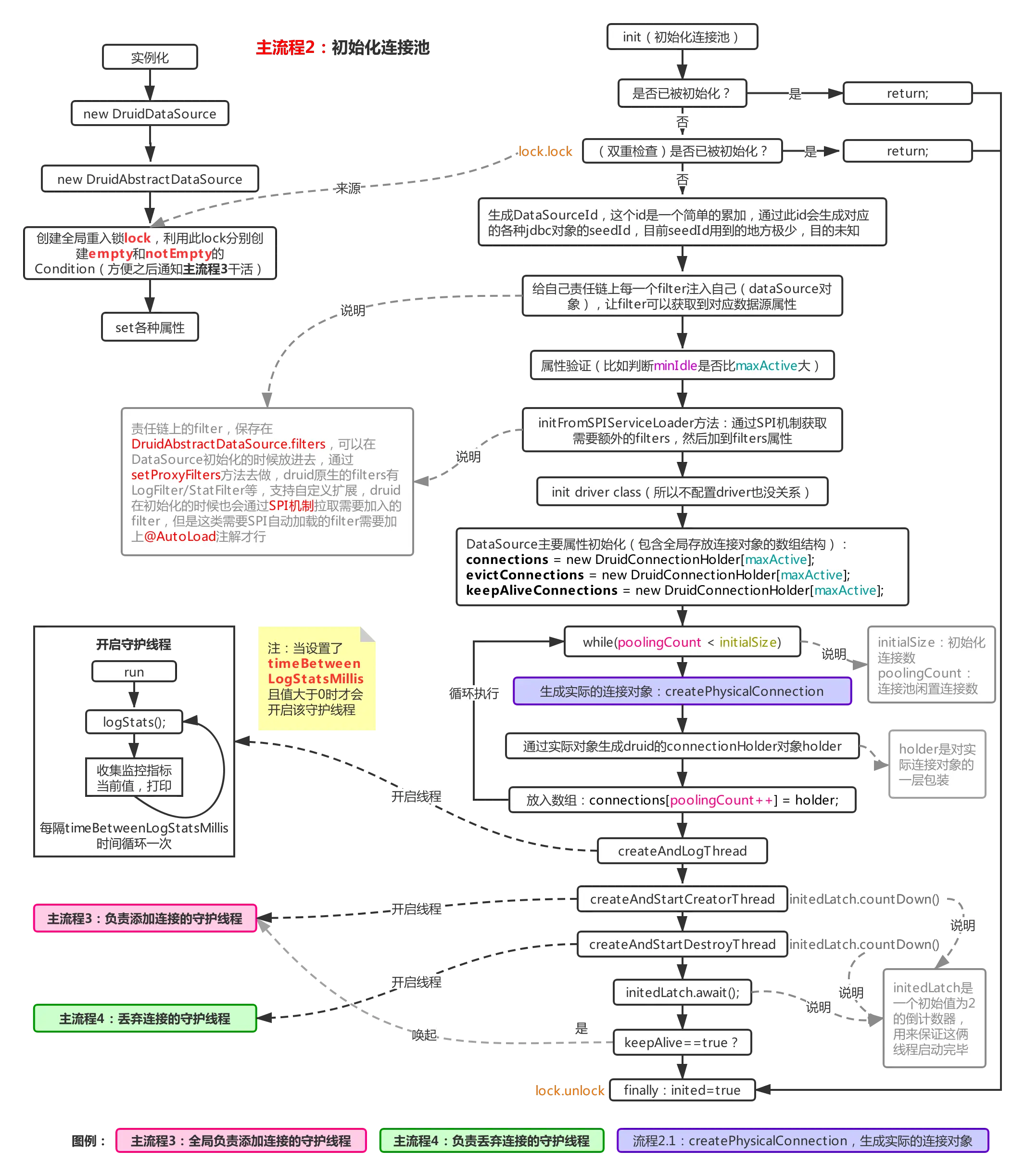
可以看到,实例化的时候会初始化全局的重入锁lock,在初始化过程中包括后续的连接池操作都会利用该锁保证线程安全,初始化连接池的时候首先会进行双重检查是否已经初始化过,若没有,则进行连接池的初始化,这时候还会通过SPI机制额外加载责任链上的filter。
但是这类filter需要在类上加上@AutoLoad注解。然后初始化了三个数组,容积都为maxActive,首先connections就是用来存放池子里连接对象的,evictConnections用来存放每次检查需要抛弃的连接(结合流程4.1理解),keepAliveConnections用于存放需要连接检查的存活连接(同样结合流程4.1理解),然后生成初始化数(initialSize)个连接,放进connections,然后生成两个必须的守护线程,用来添加连接进池以及从池子里摘除不需要的连接,这俩过程较复杂,因此拆出来单说(主流程3和主流程4)。
特别说明①
从流程上看如果一开始实例化的时候不对连接池进行初始化(这个初始化是指对池子本身的初始化,并非单纯的指druid对象属性的初始化),那么在第一次调用getConnection时就会走上图那么多逻辑,尤其是耗时较久的建立连接操作,被重复执行了很多次,导致第一次getConnection时耗时过久,如果你的程序并发量很大,那么第一次获取连接时就会因为初始化流程而发生排队,所以建议在实例化连接池后对其进行预热,通过调用init方法或者getConnection方法都可以。
特别说明②
在构建全局重入锁的时候,利用lock对象生成了俩Condition,对这俩Condition解释如下:
当连接池连接够用时,利用empty阻塞添加连接的守护线程(主流程3),当连接池连接不够用时,获取连接的那个线程(这里记为业务线程A)就会阻塞在notEmpty上,且唤起阻塞在empty上的添加连接的守护线程,走完添加连接的流程,走完后会重新唤起阻塞在notEmpty上的业务线程A,业务线程A就会继续尝试获取连接。
三、流程1.1:责任链
WARN:这块东西结合源码看更容易理解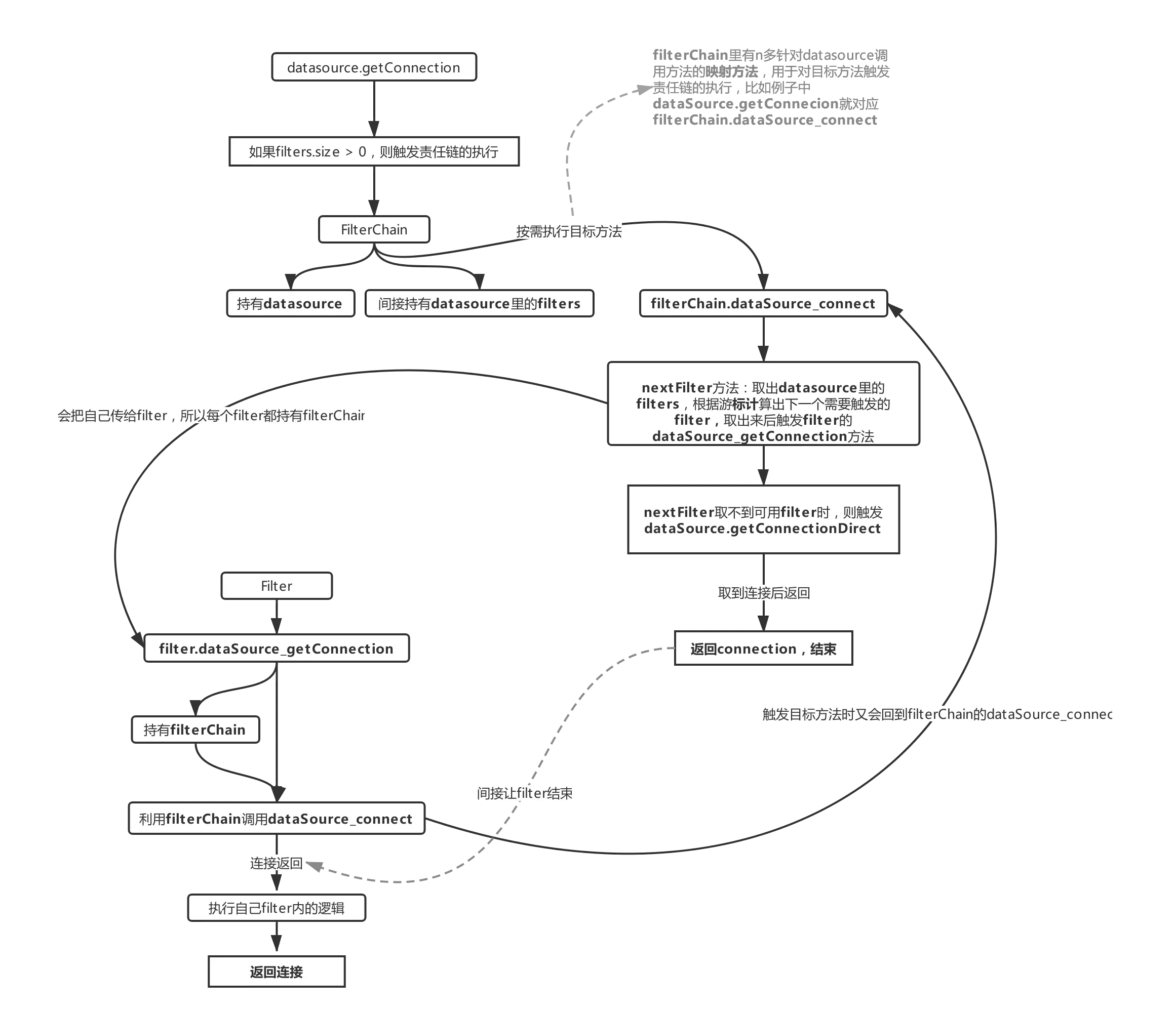
这里对应流程1里获取连接时需要执行的责任链,每个DruidAbstractDataSource里都包含filters属性,filters是对Druid里Filters接口的实现,里面有很多对应着连接池里的映射方法,比如例子中dataSource的getConnection方法在触发的时候就会利用FilterChain把每个filter里的dataSource_getConnection给执行一遍,这里也要说明下FilterChain,通过流程1.1可以看出来,datasource是利用FilterChain来触发各个filter的执行的,FilterChain里也有一堆datasource里的映射方法,比如上图里的dataSource_connect,这个方法会把datasource里的filters全部执行一遍直到nextFilter取不到值,才会触发dataSource.getConnectionDirect,这个结合代码会比较容易理解。
四、流程1.2:从池中获取连接的流程
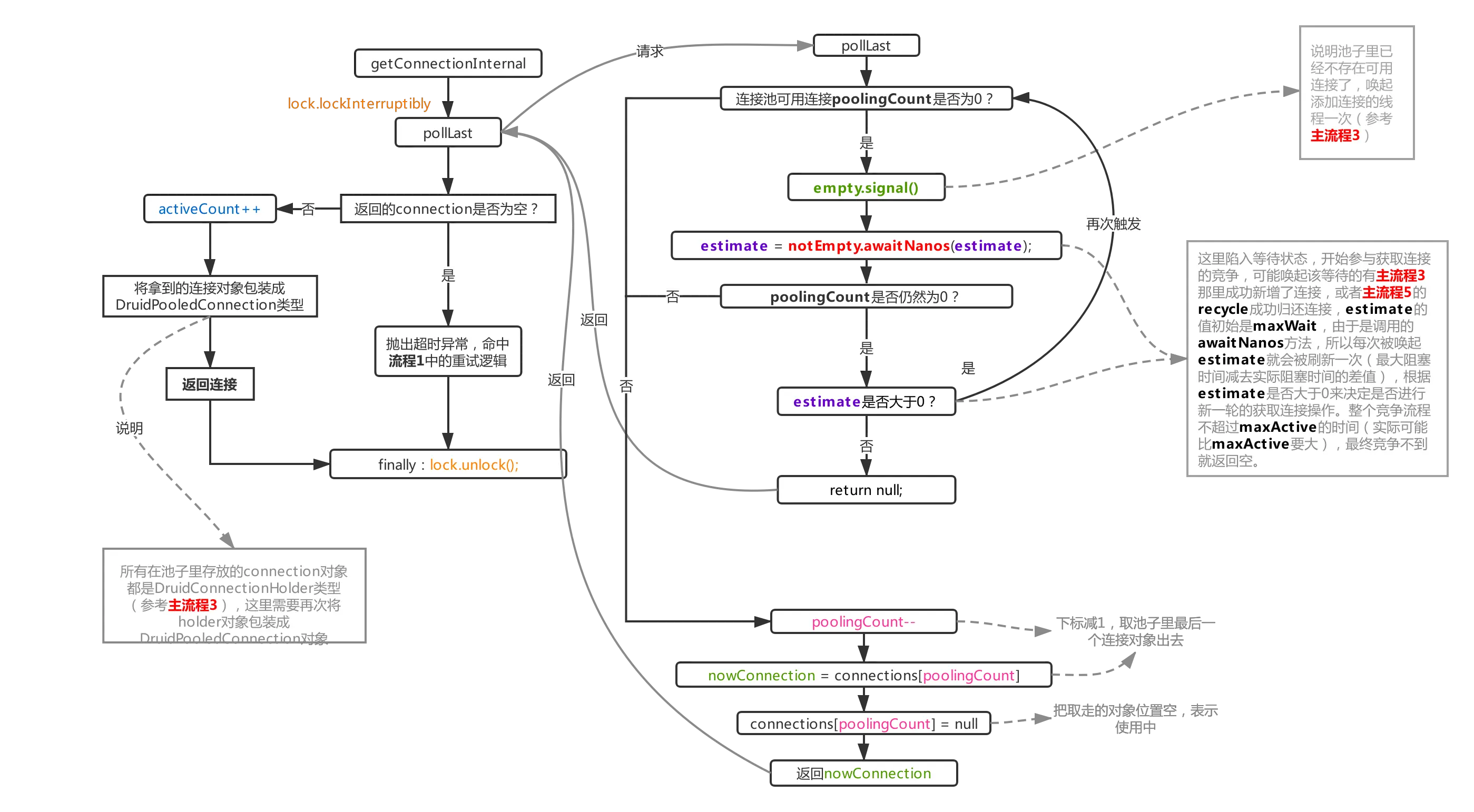
通过getConnectionInternal方法从池子里获取真正的连接对象,druid支持两种方式新增连接,一种是通过开启不同的守护线程通过await、signal通信实现(本文启用的方式,也是默认的方式),另一种是直接通过线程池异步新增,这个方式通过在初始化druid时传入asyncInit=true,再把一个线程池对象赋值给createScheduler,就成功启用了这种模式,没仔细研究这种方式,所以本文的流程图和代码块都会规避这个模式。
上面的流程很简单,连接足够时就直接poolingCount-1,数组取值,返回,activeCount+1,整体复杂度为O(1),关键还是看取不到连接时的做法,取不到连接时,druid会先唤起新增连接的守护线程新增连接,然后陷入等待状态,然后唤醒该等待的点有两处,一个是用完了连接recycle(主流程5)进池子后触发,另外一个就是新增连接的守护线程成功新增了一个连接后触发,await被唤起后继续加入锁竞争,然后往下走如果发现池子里的连接数仍然是0(说明在唤醒后参与锁竞争里刚被放进来的连接又被别的线程拿去了),则继续下一次的await,这里采用的是awaitNanos方法,初始值是maxWait,然后下次被刷新后就是maxWait减去上次阻塞花费的实际时间,每次await的时间会逐步减少,直到归零,整体时间是约等于maxWait的,但实际比maxActive要大,因为程序本身存在耗时以及被唤醒后又要参与锁竞争导致也存在一定的耗时。
如果最终都没办法拿到连接则返回null出去,紧接着触发主流程1中的重试逻辑。
druid如何防止在获取不到连接时阻塞过多的业务线程?
通过上面的流程图和流程描述,如果非常极端的情况,池子里的连接完全不够用时,会阻塞过多的业务线程,甚至会阻塞超过maxWait这么久,有没有一种措施是可以在连接不够用的时候控制阻塞线程的个数,超过这个限制后直接报错,而不是陷入等待呢?
druid其实支持这种策略的,在maxWaitThreadCount属性为默认值(-1)的情况下不启用,如果maxWaitThreadCount配置大于0,表示启用,这是druid做的一种丢弃措施,如果你不希望在池子里的连接完全不够用导阻塞的业务线程过多,就可以考虑配置该项,这个属性的意思是说在连接不够用时最多让多少个业务线程发生阻塞,流程1.2的图里没有体现这个开关的用途,可以在代码里查看,每次在pollLast方法里陷入等待前会把属性notEmptyWaitThreadCount进行累加,阻塞结束后会递减,由此可见notEmptyWaitThreadCount就是表示当前等待可用连接时阻塞的业务线程的总个数,而getConnectionInternal在每次调用pollLast前都会判断这样一段代码:
`if (maxWaitThreadCount > 0 && notEmptyWaitThreadCount >= maxWaitThreadCount) {
connectErrorCountUpdater.incrementAndGet(this);
throw new SQLException("maxWaitThreadCount " + maxWaitThreadCount + ", current wait Thread count "
+ lock.getQueueLength()); //直接抛异常,而不是陷入等待状态阻塞业务线程
}
复制代码`
可以看到,如果配置了maxWaitThreadCount所限制的等待线程个数,那么会直接判断当前陷入等待的业务线程是否超过了maxWaitThreadCount,一旦超过甚至不触发pollLast的调用(防止新增等待线程),直接抛错。
一般情况下不需要启用该项,一定要启用建议考虑好maxWaitThreadCount的取值,一般来说发生大量等待说明代码里存在不合理的地方:比如典型的连接池基本配置不合理,高qps的系统里maxActive配置过小;比如借出去的连接没有及时close归还;比如存在慢查询或者慢事务导致连接借出时间过久。这些要比配置maxWaitThreadCount更值得优先考虑,当然配置这个做一个极限保护也是没问题的,只是要结合实际情况考虑好取值。
五、流程1.3:连接可用性测试
①init-checker
讲这块的东西之前,先来了解下如何初始化检测连接用的checker,整个流程参考下图:
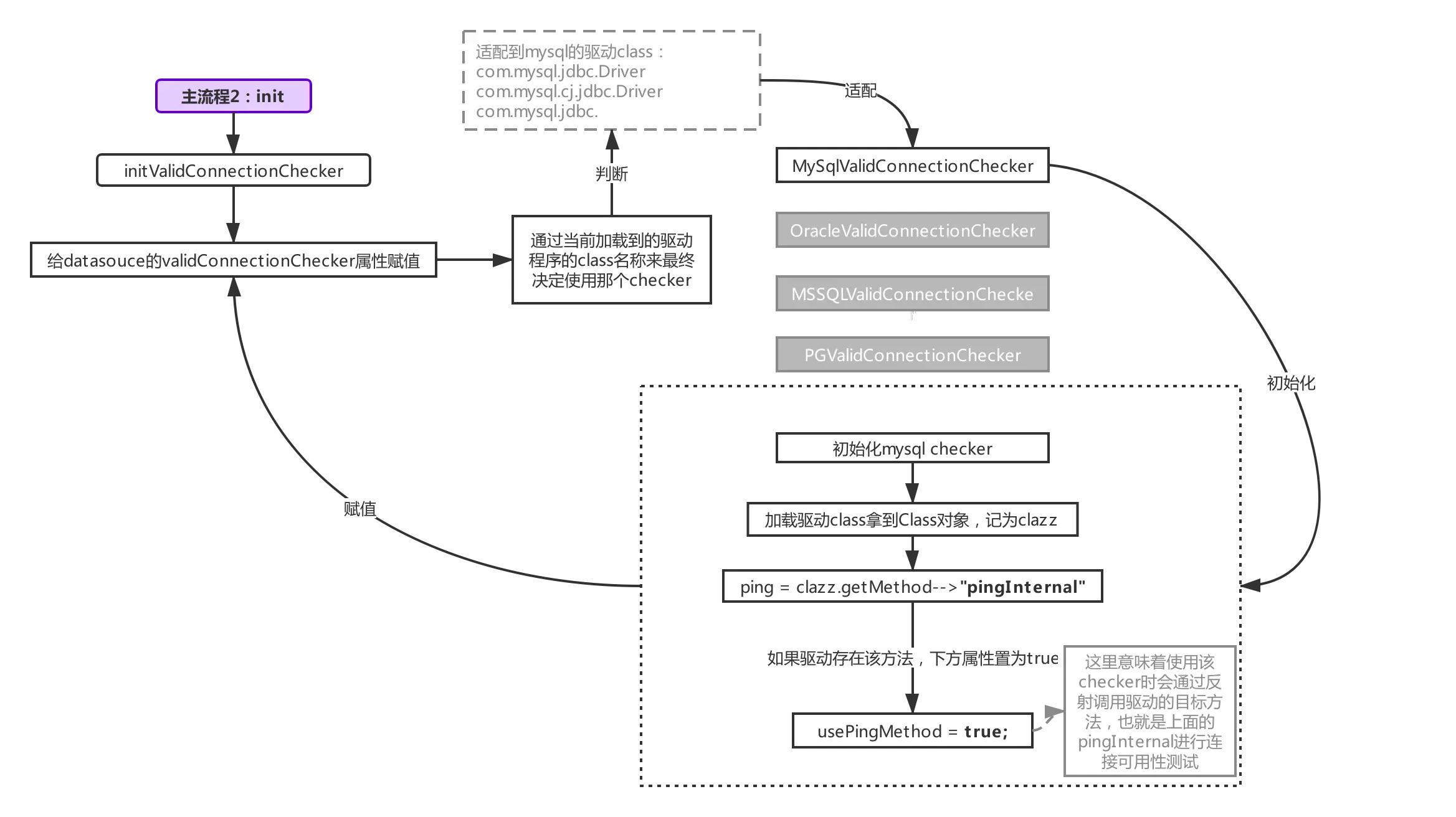
初始化checker发生在init阶段(限于篇幅,没有在主流程2(init阶段)里体现出来,只需要记住初始化checker也是发生在init阶段就好),druid支持多种数据库的连接源,所以checker针对不同的驱动程序都做了适配,所以才看到图中checker有不同的实现,我们根据加载到的驱动类名匹配不同的数据库checker,上图匹配至mysql的checker,checker的初始化里做了一件事情,就是判断驱动内是否有ping方法(jdbc4开始支持,mysql-connector-java早在3.x的版本就有ping方法的实现了),如果有,则把usePingMethod置为true,用于后续启用checker时做判断用(下面会讲,这里置为true,则通过反射的方式调用驱动程序的ping方法,如果为false,则触发普通的SELECT 1查询检测,SELECT 1就是我们非常熟悉的那个东西啦,新建statement,然后执行SELECT 1,然后再判断连接是否可用)。
②testConnectionInternal
然后回到本节探讨的方法:流程1.3对应的testConnectionInternal
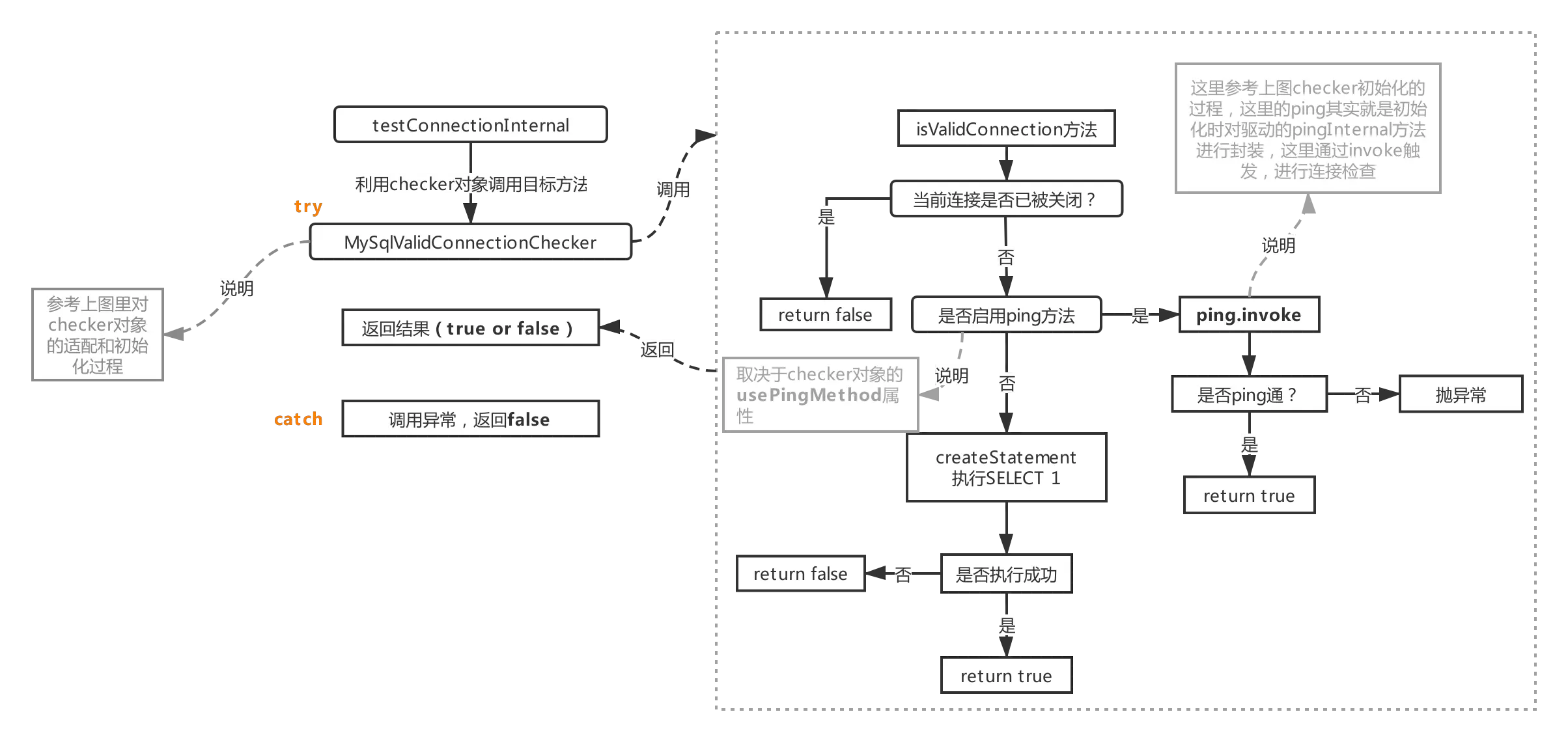
这个方法会利用主流程2(init阶段)里初始化好的checker对象(流程参考init-checker)里的isValidConnection方法,如果启用ping,则该方法会利用invoke触发驱动程序里的ping方法,如果不启用ping,就采用SELECT 1方式(从init-checker里可以看出启不启用取决于加载到的驱动程序里是否存在相应的方法)。
六、流程1.4:抛弃连接
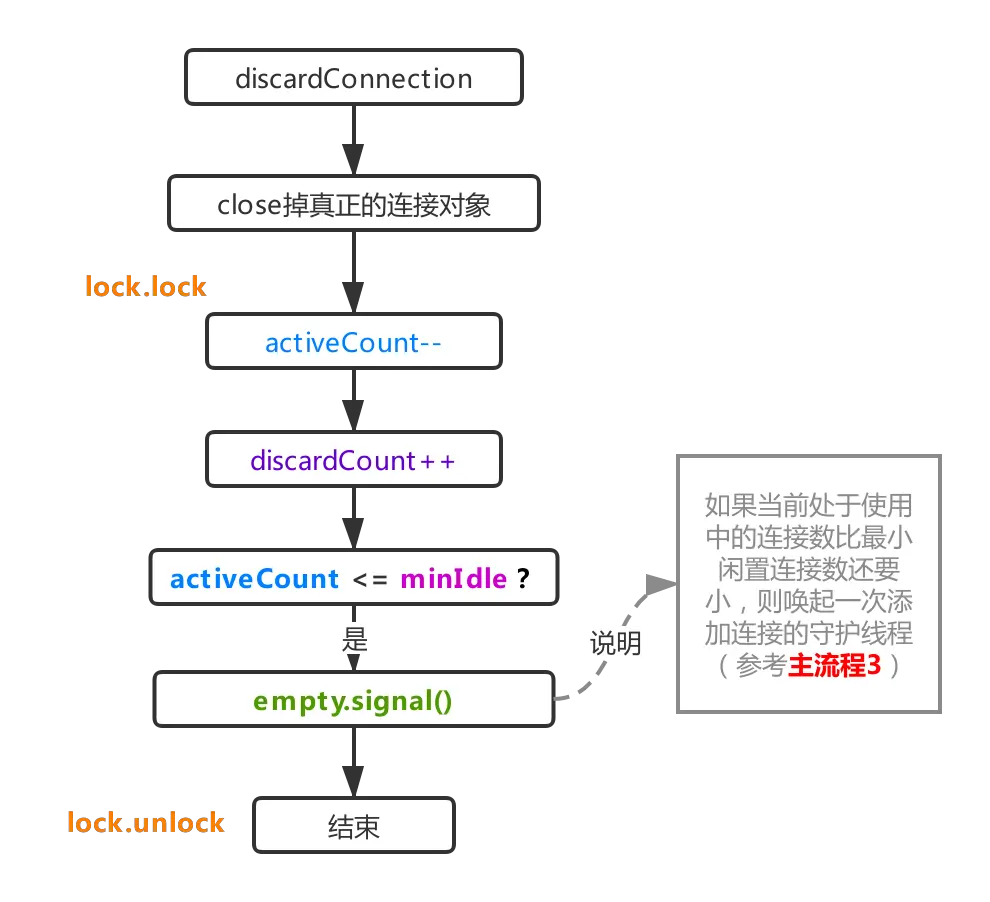
经过流程1.3返回的测试结果,如果发现连接不可用,则直接触发抛弃连接逻辑,这个过程非常简单,如上图所示,由流程1.2获取到该连接时累加上去的activeCount,在本流程里会再次减一,表示被取出来的连接不可用,并不能active状态。其次这里的close是拿着驱动那个连接对象进行close,正常情况下一个连接对象会被druid封装成DruidPooledConnection对象,内部持有的conn就是真正的驱动Connection对象,上图中的关闭连接就是获取的该对象进行close,如果使用包装类DruidPooledConnection进行close,则代表回收连接对象(recycle,参考主流程5)。
七、主流程3:添加连接的守护线程
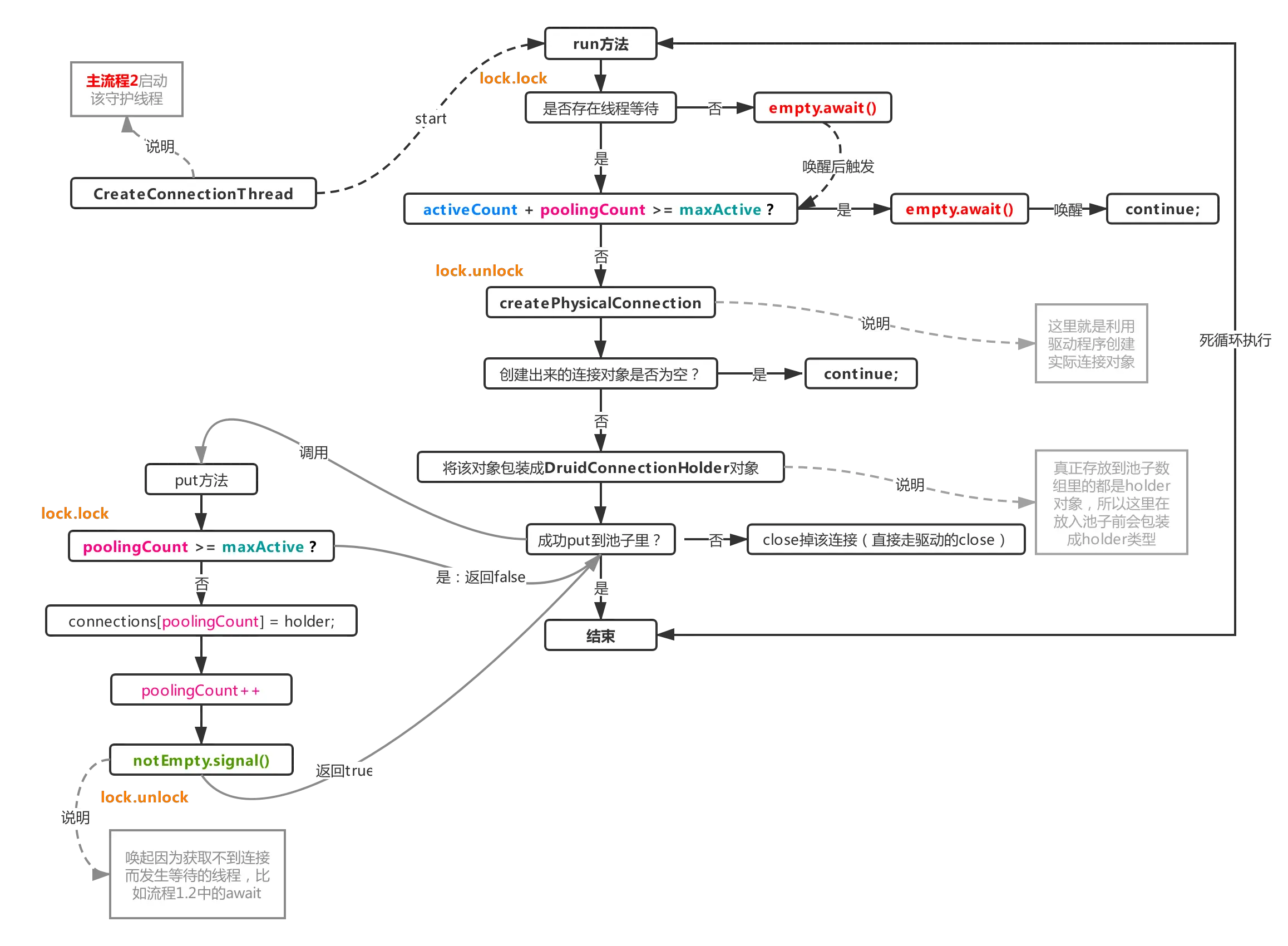
在主流程2(init初始化阶段)时就开启了该流程,该流程独立运行,大部分时间处于等待状态,不会抢占cpu,但是当连接不够用时,就会被唤起追加连接,成功创建连接后将会唤醒其他正在等待获取可用连接的线程,比如:
结合流程1.2来看,当连接不够用时,会通过empty.signal唤醒该线程进行补充连接(阻塞在empty上的线程只有主流程3的单线程),然后通过notEmpty阻塞自己,当该线程补充连接成功后,又会对阻塞在notEmpty上的线程进行唤醒,让其进入锁竞争状态,简单理解就是一个生产-消费模型。这里有一些细节,比如池子里的连接使用中(activeCount)加上池子里剩余连接数(poolingCount)就是指当前一共生成了多少个连接,这个数不能比maxActive还大,如果比maxActive还大,则再次陷入等待。而在往池子里put连接时,则判断poolingCount是否大于maxActive来决定最终是否入池。
八、主流程4:抛弃连接的守护线程
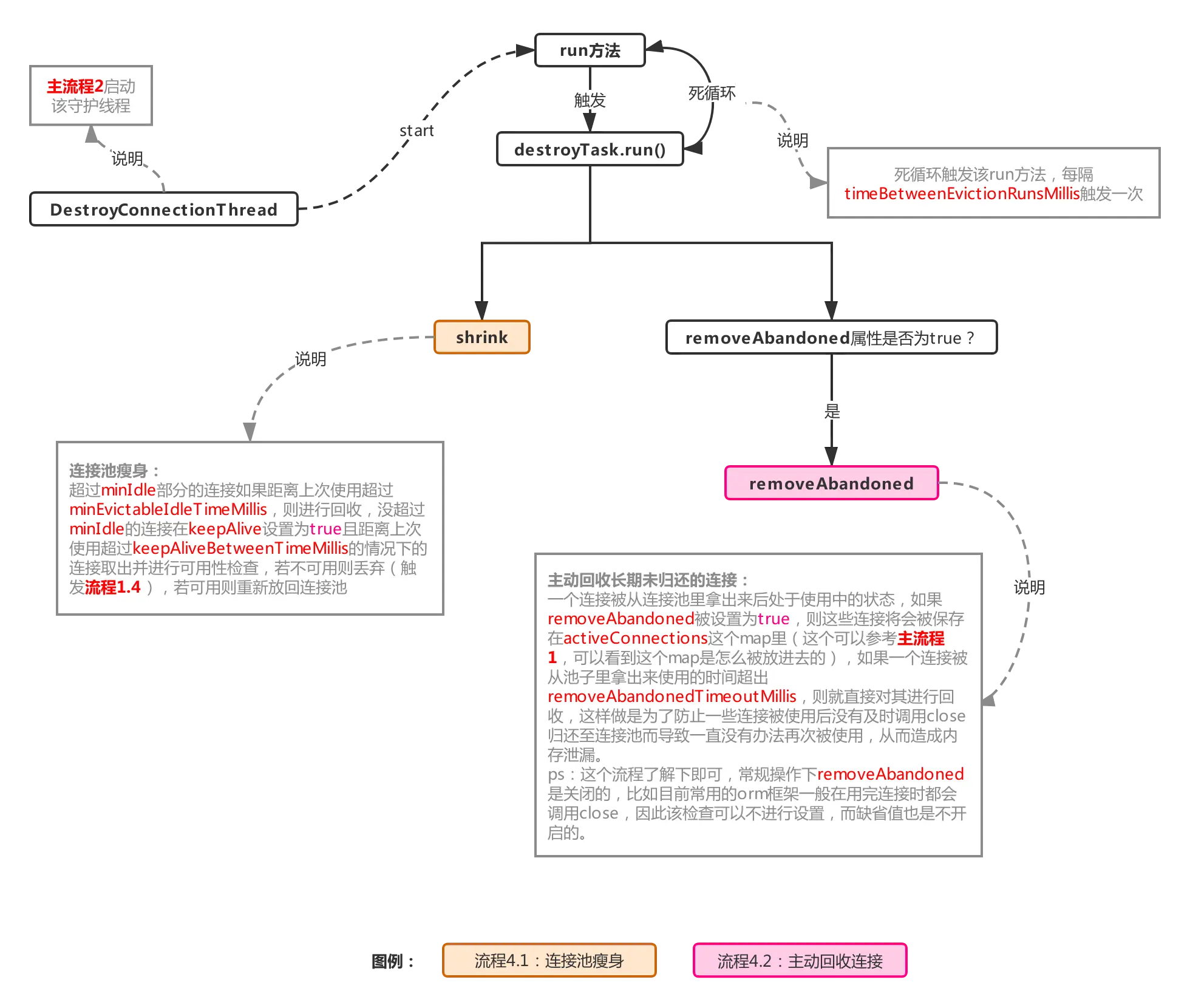
流程4.1:连接池瘦身,检查连接是否可用以及丢弃多余连接
整个过程如下:
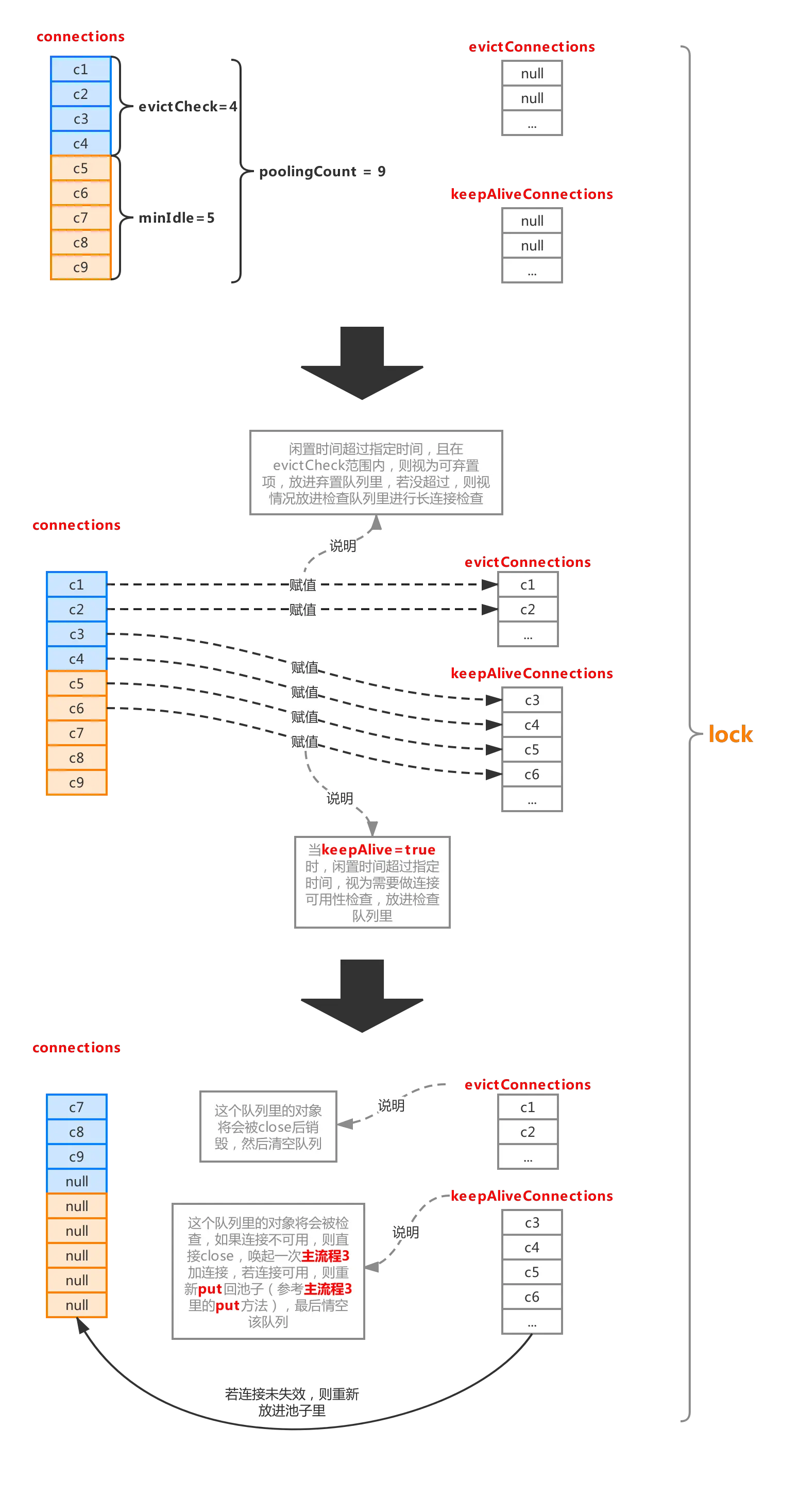
整个流程分成图中主要的几步,首先利用poolingCount减去minIdle计算出需要做丢弃检查的连接对象区间,意味着这个区间的对象有被丢弃的可能,具体要不要放进丢弃队列evictConnections,要判断两个属性:
minEvictableIdleTimeMillis:最小检查间隙,缺省值30min,官方解释:一个连接在池中最小生存的时间(结合检查区间来看,闲置时间超过这个时间,才会被丢弃)。
maxEvictableIdleTimeMillis:最大检查间隙,缺省值7h,官方解释:一个连接在池中最大生存的时间(无视检查区间,只要闲置时间超过这个时间,就一定会被丢弃)。
如果当前连接对象闲置时间超过minEvictableIdleTimeMillis且下标在evictCheck区间内,则加入丢弃队列evictConnections,如果闲置时间超过maxEvictableIdleTimeMillis,则直接放入evictConnections(一般情况下会命中第一个判断条件,除非一个连接不在检查区间,且闲置时间超过maxEvictableIdleTimeMillis)。
如果连接对象不在evictCheck区间内,且keepAlive属性为true,则判断该对象闲置时间是否超出keepAliveBetweenTimeMillis(缺省值60s),若超出,则意味着该连接需要进行连接可用性检查,则将该对象放入keepAliveConnections队列。
两个队列赋值完成后,则池子会进行一次压缩,没有涉及到的连接对象会被压缩到队首。
然后就是处理evictConnections和keepAliveConnections两个队列了,evictConnections里的对象会被close最后释放掉,keepAliveConnections里面的对象将会其进行检测(流程参考流程1.3的isValidConnection),碰到不可用的连接会调用discard(流程1.4)抛弃掉,可用的连接会再次被放进连接池。
整个流程可以看出,连接闲置后,也并非一下子就减少到minIdle的,如果之前产生一堆的连接(不超过maxActive),突然闲置了下来,则至少需要花minEvictableIdleTimeMillis的时间才可以被移出连接池,如果一个连接闲置时间超过maxEvictableIdleTimeMillis则必定被回收,所以极端情况下(比如一个连接池从初始化后就没有再被使用过),连接池里并不会一直保持minIdle个连接,而是一个都没有,生产环境下这是非常不常见的,默认的maxEvictableIdleTimeMillis都有7h,除非是极度冷门的系统才会出现这种情况,而开启keepAlive也不会推翻这个规则,keepAlive的优先级是低于maxEvictableIdleTimeMillis的,keepAlive只是保证了那些检查中不需要被移出连接池的连接在指定检测时间内去检测其连接活性,从而决定是否放入池子或者直接discard。
流程4.2:主动回收连接,防止内存泄漏
过程如下:
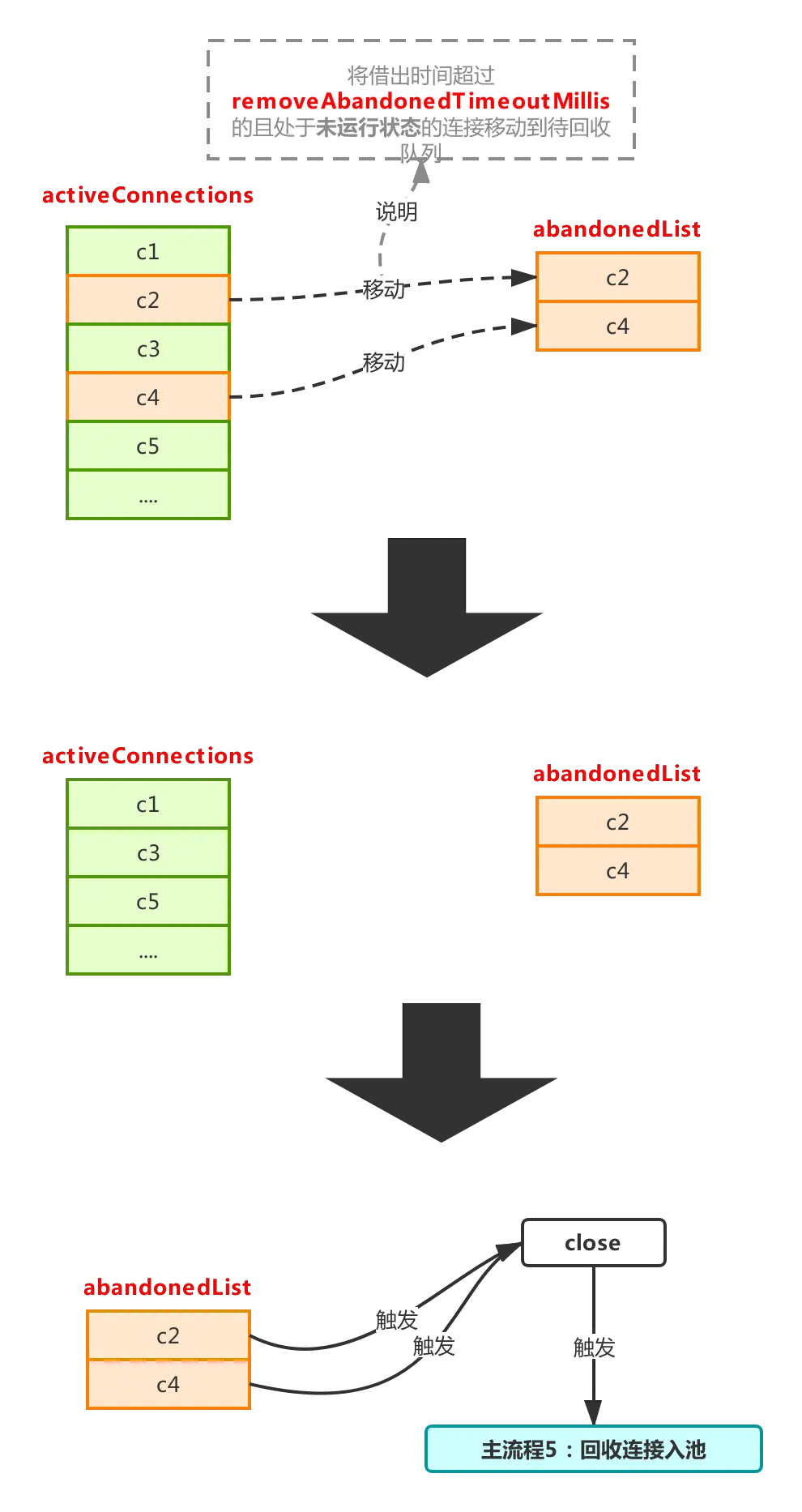
这个流程在removeAbandoned设置为true的情况下才会触发,用于回收那些拿出去的使用长期未归还(归还:调用close方法触发主流程5)的连接。
先来看看activeConnections是什么,activeConnections用来保存当前从池子里被借出去的连接,这个可以通过主流程1看出来,每次调用getConnection时,如果开启removeAbandoned,则会把连接对象放到activeConnections,然后如果长期不调用close,那么这个被借出去的连接将永远无法被重新放回池子,这是一件很麻烦的事情,这将存在内存泄漏的风险,因为不close,意味着池子会不断产生新的连接放进connections,不符合连接池预期(连接池出发点是尽可能少的创建连接),然后之前被借出去的连接对象还有一直无法被回收的风险,存在内存泄漏的风险,因此为了解决这个问题,就有了这个流程,流程整体很简单,就是将现在借出去还没有归还的连接,做一次判断,符合条件的将会被放进abandonedList进行连接回收(这个list里的连接对象里的abandoned将会被置为true,标记已被该流程处理过,防止主流程5再次处理)。
这个如果在实践中能保证每次都可以正常close,完全不用设置removeAbandoned=true,目前如果使用了类似mybatis、spring等开源框架,框架内部是一定会close的,所以此项是不建议设置的,视情况而定。
九、主流程5:回收连接
这个流程通常是靠连接包装类DruidPooledConnection的close方法触发的,目标方法为recycle,流程图如下:
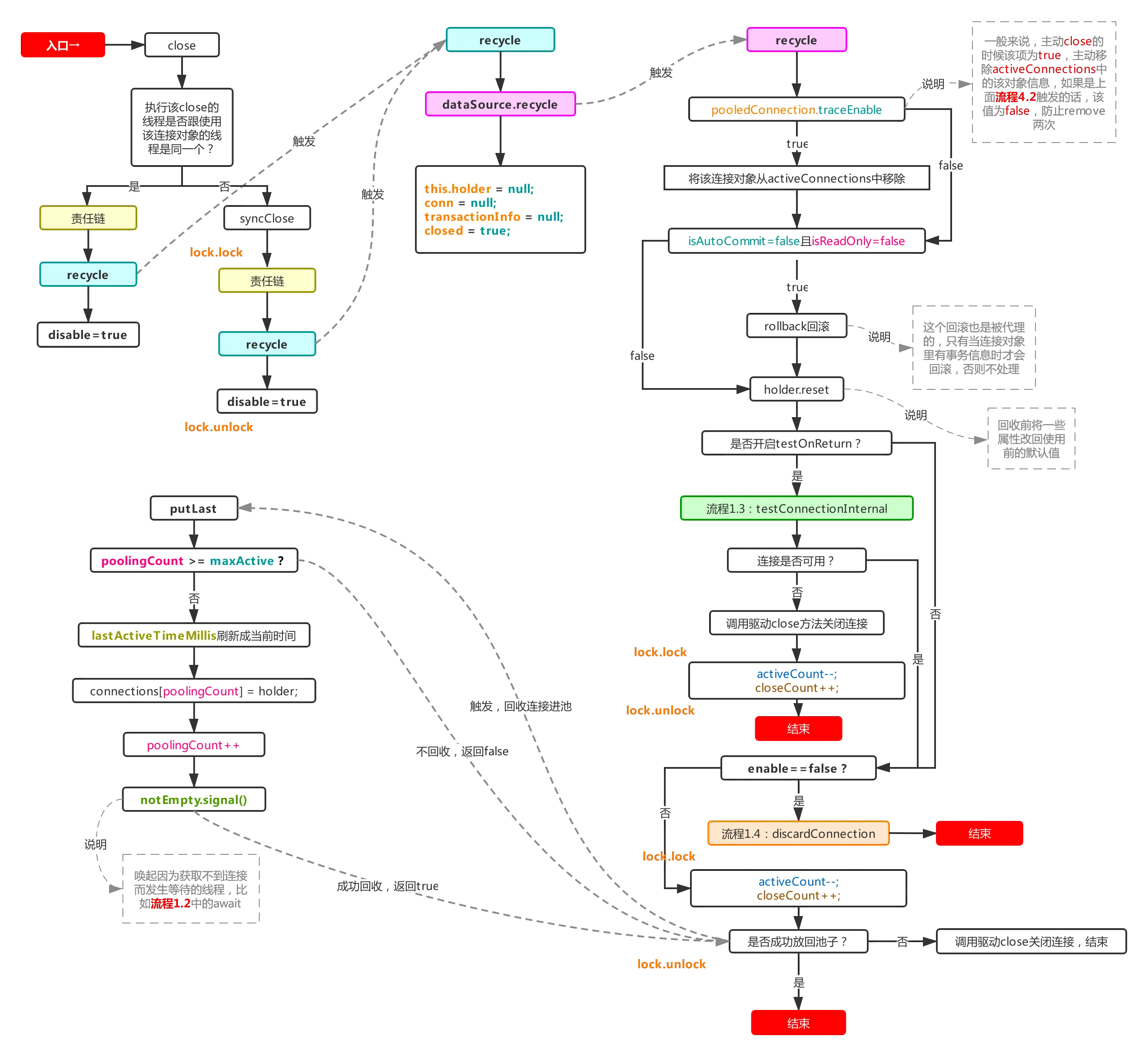
这也是非常重要的一个流程,连接用完要归还,就是利用该流程完成归还的动作,利用druid对外包装的Connecion包装类DruidPooledConnection的close方法触发,该方法会通过自己内部的close或者syncClose方法来间接触发dataSource对象的recycle方法,从而达到回收的目的。
最终的recycle方法:
①如果removeAbandoned被设置为true,则通过traceEnable判断是否需要从activeConnections移除该连接对象,防止流程4.2再次检测到该连接对象,当然如果是流程4.2主动触发的该流程,那么意味着流程4.2里已经remove过该对象了,traceEnable会被置为false,本流程就不再触发remove了(这个流程都是在removeAbandoned=true的情况下进行的,在主流程1里连接被放进activeConnections时traceEnable被置为true,而在removeAbandoned=false的情况下traceEnable恒等于false)。
②如果回收过程中发现存在有未处理完的事务,则触发回滚(比较有可能触发这一条的是流程4.2里强制归还连接,也有可能是单纯使用连接,开启事务却没有提交事务就直接close的情况),然后利用holder.reset进行恢复连接对象里一些属性的默认值,除此之外,holder对象还会把由它产生的statement对象放到自己的一个arraylist里面,reset方法会循环着关闭内部未关闭的statement对象,最后清空list,当然,statement对象自己也会记录下其产生的所有的resultSet对象,然后关闭statement时同样也会循环关闭内部未关闭的resultSet对象,这是连接池做的一种保护措施,防止用户拿着连接对象做完一些操作没有对打开的资源关闭。
③判断是否开启testOnReturn,这个跟testOnBorrow一样,官方默认不开启,也不建议开启,影响性能,理由参考主流程1里针对testOnBorrow的解释。
④直接放回池子(当前connections的尾部),然后需要注意的是putLast方法和put方法的不同之处,putLast会把lastActiveTimeMillis置为当前时间,也就是说不管一个连接被借出去过久,只要归还了,最后活跃时间就是当前时间,这就会有造成某种特殊异常情况的发生(非常极端,几乎不会触发,可以选择不看):
如果不开启testOnBorrow和testOnReturn,并且keepAlive设置为false,那么长连接可用测试的间隔依据就是利用当前时间减去上次活跃时间(lastActiveTimeMillis)得出闲置时间,然后再利用闲置时间跟timeBetweenEvictionRunsMillis(默认60s)进行对比,超过才进行长连接可用测试。那么如果一个mysql服务端的长连接保活时间被人为调整为60s,然后timeBetweenEvictionRunsMillis被设置为59s,这个设置是非常合理的,保证了测试间隔小于长连接实际保活时间,然后如果这时一个连接被拿出去后一直过了61s才被close回收,该连接对象的lastActiveTimeMillis被刷为当前时间,如果在59s内再次拿到该连接对象,就会绕过连接检查直接报连接不可用的错误。
十、结束
到这里针对druid连接池的初始化以及其内部一个连接从生产到消亡的整个流程就已经整理完了,主要是列出其运行流程以及一些主要的监控数据都是如何产生的,没有涉及到的是一个sql的执行,因为这个基本上就跟使用原生驱动程序差不多,只是druid又包装了一层Statement等,用于完成一些自己的操作。
https://segmentfault.com/a/1190000039711193
com.alibaba.druid.pool.DruidAbstractDataSource#testConnectionInternal(com.alibaba.druid.pool.DruidConnectionHolder, java.sql.Connection)
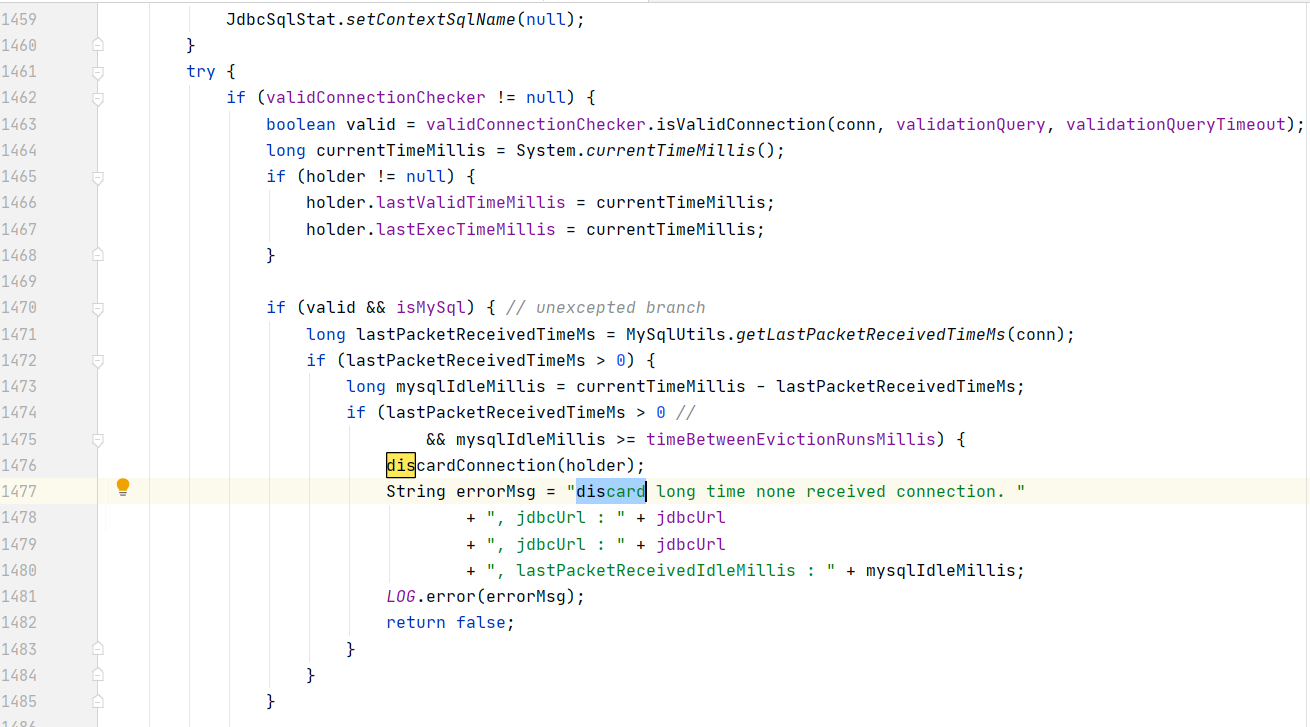
com.alibaba.druid.pool.DruidDataSource#initCheck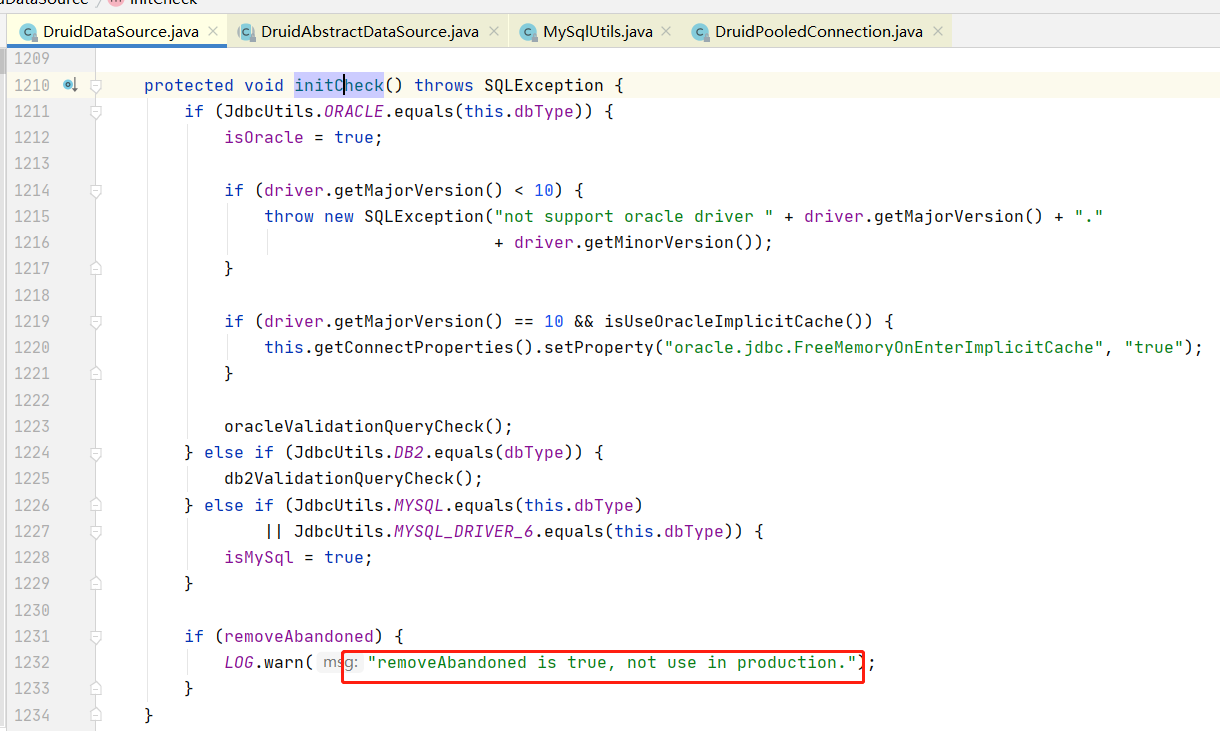
removeAbandoned="true"
removeAbandonedTimeout="60"
logAbandoned="true"
有时粗心的程序编写者在从连接池中获取连接使用后忘记了连接的关闭,这样连池的连接就会逐渐达到maxActive直至连接池无法提供服务。
现代连接池一般提供一种“智能”的检查,但设置了removeAbandoned="true"时,当连接池连接数到达(getNumIdle() < 2) and (getNumActive() > getMaxActive() - 3) [空闲的连接小于2并且活动的连接大于(最大连接-3)] 时便会启动连接回收,那种活动时间超过removeAbandonedTimeout="60"的连接将会被回收,同时如果logAbandoned="true"设置为true,程序在回收连接的同时会打印日志。
removeAbandoned是连接池的高级功能,理论上这中配置不应该出现在实际的生产环境,因为有时应用程序执行长事务,可能这种情况下,会被连接池误回收,该种配置一般在程序测试阶段,为了定位连接泄漏的具体代码位置,被开启。生产环境中连接的关闭应该靠程序自己保证。
com.alibaba.druid.pool.DruidDataSource#discardConnection(java.sql.Connection) /** * 抛弃连接,不进行回收,而是抛弃 * * @param realConnection * @deprecated */ public void discardConnection(Connection realConnection) { JdbcUtils.close(realConnection); lock.lock(); try { activeCount--; discardCount++; if (activeCount <= minIdle) { emptySignal(); } } finally { lock.unlock(); } }
com.alibaba.druid.pool.DruidDataSource#removeAbandoned public int removeAbandoned() { int removeCount = 0; long currrentNanos = System.nanoTime(); List<DruidPooledConnection> abandonedList = new ArrayList<DruidPooledConnection>(); activeConnectionLock.lock(); try { Iterator<DruidPooledConnection> iter = activeConnections.keySet().iterator(); for (; iter.hasNext();) { DruidPooledConnection pooledConnection = iter.next(); if (pooledConnection.isRunning()) { continue; } long timeMillis = (currrentNanos - pooledConnection.getConnectedTimeNano()) / (1000 * 1000); if (timeMillis >= removeAbandonedTimeoutMillis) { iter.remove(); pooledConnection.setTraceEnable(false); abandonedList.add(pooledConnection); } } } finally { activeConnectionLock.unlock(); } if (abandonedList.size() > 0) { for (DruidPooledConnection pooledConnection : abandonedList) { final ReentrantLock lock = pooledConnection.lock; lock.lock(); try { if (pooledConnection.isDisable()) { continue; } } finally { lock.unlock(); } JdbcUtils.close(pooledConnection); pooledConnection.abandond(); removeAbandonedCount++; removeCount++; if (isLogAbandoned()) { StringBuilder buf = new StringBuilder(); buf.append("abandon connection, owner thread: "); buf.append(pooledConnection.getOwnerThread().getName()); buf.append(", connected at : "); buf.append(pooledConnection.getConnectedTimeMillis()); buf.append(", open stackTrace\n"); StackTraceElement[] trace = pooledConnection.getConnectStackTrace(); for (int i = 0; i < trace.length; i++) { buf.append("\tat "); buf.append(trace[i].toString()); buf.append("\n"); } buf.append("ownerThread current state is " + pooledConnection.getOwnerThread().getState() + ", current stackTrace\n"); trace = pooledConnection.getOwnerThread().getStackTrace(); for (int i = 0; i < trace.length; i++) { buf.append("\tat "); buf.append(trace[i].toString()); buf.append("\n"); } LOG.error(buf.toString()); } } } return removeCount; }
4. SQL合并配置
当你程序中存在没有参数化的sql执行时,sql统计的效果会不好。比如:
select * from t where id = 1 select * from t where id = 2 select * from t where id = 3
在统计中,显示为3条sql,这不是我们希望要的效果。StatFilter提供合并的功能,能够将这3个SQL合并为如下的SQL
select * from t where id = ?
配置StatFilter的mergeSql属性
<bean id="stat-filter" class="com.alibaba.druid.filter.stat.StatFilter">
<property name="mergeSql" value="true" />
</bean>
https://github.com/alibaba/druid/wiki/%E9%85%8D%E7%BD%AE_StatFilter
spring.datasource.druid.filters=config,stat,wall,log4j 配置监控统计拦截的filters,去掉后监控界面SQL无法进行统计,’wall’用于防火墙
WebStatFilter用于采集web-jdbc关联监控的数据。【只是提供一个展示界面,及展示界面本身按一定维度统计的数据】
用来展示已经统计到的监控数据
https://github.com/alibaba/druid/wiki/%E9%85%8D%E7%BD%AE_%E9%85%8D%E7%BD%AEWebStatFilter
监控配置【展示一些Filter已经存放的数据】,主要决定怎么展示
# WebStatFilter配置,说明请参考Druid Wiki,配置_配置WebStatFilter spring.datasource.druid.web-stat-filter.enabled= #是否启用StatFilter默认值false spring.datasource.druid.web-stat-filter.url-pattern= spring.datasource.druid.web-stat-filter.exclusions= spring.datasource.druid.web-stat-filter.session-stat-enable= spring.datasource.druid.web-stat-filter.session-stat-max-count= spring.datasource.druid.web-stat-filter.principal-session-name= spring.datasource.druid.web-stat-filter.principal-cookie-name= spring.datasource.druid.web-stat-filter.profile-enable= # StatViewServlet配置,说明请参考Druid Wiki,配置_StatViewServlet配置 spring.datasource.druid.stat-view-servlet.enabled= #是否启用StatViewServlet(监控页面)默认值为false(考虑到安全问题默认并未启动,如需启用建议设置密码或白名单以保障安全) spring.datasource.druid.stat-view-servlet.url-pattern= spring.datasource.druid.stat-view-servlet.reset-enable= spring.datasource.druid.stat-view-servlet.login-username= spring.datasource.druid.stat-view-servlet.login-password= spring.datasource.druid.stat-view-servlet.allow= spring.datasource.druid.stat-view-servlet.deny= # Spring监控配置,说明请参考Druid Github Wiki,配置_Druid和Spring关联监控配置 spring.datasource.druid.aop-patterns= # Spring监控AOP切入点,如x.y.z.service.*,配置多个英文逗号分隔
如何配置 Filter
你可以通过 spring.datasource.druid.filters=stat,wall,log4j ... 的方式来启用相应的内置Filter,不过这些Filter都是默认配置。如果默认配置不能满足你的需求,你可以放弃这种方式,通过配置文件来配置Filter,下面是例子。
# 配置StatFilter spring.datasource.druid.filter.stat.enabled=true spring.datasource.druid.filter.stat.db-type=h2 spring.datasource.druid.filter.stat.log-slow-sql=true spring.datasource.druid.filter.stat.slow-sql-millis=2000 # 配置WallFilter spring.datasource.druid.filter.wall.enabled=true spring.datasource.druid.filter.wall.db-type=h2 spring.datasource.druid.filter.wall.config.delete-allow=false spring.datasource.druid.filter.wall.config.drop-table-allow=false
# 其他 Filter 配置不再演示
目前为以下 Filter 提供了配置支持,请参考文档或者根据IDE提示(spring.datasource.druid.filter.*)进行配置。
- StatFilter
- WallFilter
- ConfigFilter
- EncodingConvertFilter
- Slf4jLogFilter
- Log4jFilter
- Log4j2Filter
- CommonsLogFilter
要想使自定义 Filter 配置生效需要将对应 Filter 的 enabled 设置为 true ,Druid Spring Boot Starter 默认禁用 StatFilter,你也可以将其 enabled 设置为 true 来启用它。
https://github.com/alibaba/druid/tree/master/druid-spring-boot-starter
http://120.26.192.168/druid/datasource.html
如果你用druid,看监控数据库,NotEmptyWaitCount数量多,或者可以考虑加大连接池的MaxActive数量。
数据库处理不过来导致execute queryTimeout了
有一个Druid连接池的错误,错误信息是这样的“The last packet successfully received from the server was 3,984,663 milliseconds ago. The last packet sent successfully to the server was 37 milliseconds ago.”,连接池缺省配置的testWhileIdle,按理来说不应该发生这样的错误。阿里应用一直没问题,但是外部的用户偶尔零星反馈过来,多年来都是如此,我一直很担心。
最近几天有一个阿里云的用户遇到这样的问题,直接通过阿里云客服找过来支持,经过多次在对方生产环境测试验证,终于找到原因,是用法的问题,不是Druid的问题,确认了这个之后,多年的担心可放下了。
问题是这样的,申请连接后间隔长时间再createStatememt执行Sql,而testWhileIdle只在getConnectin()时发挥作用。
代码示例如下:
Connection conn = druidDataSource.getConnection();
// 这里做耗时很长的事情,比如一个Hive大任务,跑数个小时
Statement stmt = conn.createStatement();
stmt.execute(); // 这里抛错
Druid内置提供了四种LogFilter(Log4jFilter、Log4j2Filter、CommonsLogFilter、Slf4jLogFilter),用于输出JDBC执行的日志。这些Filter都是Filter-Chain扩展机制中的Filter,所以配置方式可以参考这里:Filter配置
1. 别名映射
在druid-xxx.jar!/META-INF/druid-filter.properties文件中描述了这四种Filter的别名
druid.filters.log4j=com.alibaba.druid.filter.logging.Log4jFilter druid.filters.log4j2=com.alibaba.druid.filter.logging.Log4j2Filter druid.filters.slf4j=com.alibaba.druid.filter.logging.Slf4jLogFilter druid.filters.commonlogging=com.alibaba.druid.filter.logging.CommonsLogFilter druid.filters.commonLogging=com.alibaba.druid.filter.logging.CommonsLogFilter
他们的别名分别是log4j、log4j2、slf4j、commonlogging和commonLogging。其中commonlogging和commonLogging只是大小写不同。
<bean id="dataSource" class="com.alibaba.druid.pool.DruidDataSource" init-method="init" destroy-method="close"> ... ... <property name="filters" value="stat,log4j" /> </bean>
2. loggerName配置
LogFilter都是缺省使用四种不同的Logger执行输出,看实现代码:
public abstract class LogFilter { protected String dataSourceLoggerName = "druid.sql.DataSource"; protected String connectionLoggerName = "druid.sql.Connection"; protected String statementLoggerName = "druid.sql.Statement"; protected String resultSetLoggerName = "druid.sql.ResultSet"; }
你可以根据你的需要修改,在log4j.properties文件上做配置时,注意配置使用相关的logger。
2. 配置输出日志
缺省输入的日志信息全面,但是内容比较多,有时候我们需要定制化配置日志输出。
<bean id="log-filter" class="com.alibaba.druid.filter.logging.Log4jFilter"> <property name="resultSetLogEnabled" value="false" /> </bean> <bean id="dataSource" class="com.alibaba.druid.pool.DruidDataSource" init-method="init" destroy-method="close"> ... <property name="proxyFilters"> <list> <ref bean="log-filter"/> </list> </property> </bean>
| 参数 | 说明 |
| dataSourceLogEnabled | 所有DataSource相关的日志 |
| connectionLogEnabled | 所有连接相关的日志 |
| connectionLogErrorEnabled | 所有连接上发生异常的日志 |
| statementLogEnabled | 所有Statement相关的日志 |
| statementLogErrorEnabled | 所有Statement发生异常的日志 |
| resultSetLogEnabled | |
| resultSetLogErrorEnabled | |
| connectionConnectBeforeLogEnabled | |
| connectionConnectAfterLogEnabled | |
| connectionCommitAfterLogEnabled | |
| connectionRollbackAfterLogEnabled | |
| connectionCloseAfterLogEnabled | |
| statementCreateAfterLogEnabled | |
| statementPrepareAfterLogEnabled | |
| statementPrepareCallAfterLogEnabled | |
| statementExecuteAfterLogEnabled | |
| statementExecuteQueryAfterLogEnabled | |
| statementExecuteUpdateAfterLogEnabled | |
| statementExecuteBatchAfterLogEnabled | |
| statementCloseAfterLogEnabled | |
| statementParameterSetLogEnabled | |
| resultSetNextAfterLogEnabled | |
| resultSetOpenAfterLogEnabled | |
| resultSetCloseAfterLogEnabled |
4. log4j.properties配置
如果你使用log4j,可以通过log4j.properties文件配置日志输出选项,例如:
log4j.logger.druid.sql=warn,stdout log4j.logger.druid.sql.DataSource=warn,stdout log4j.logger.druid.sql.Connection=warn,stdout log4j.logger.druid.sql.Statement=warn,stdout log4j.logger.druid.sql.ResultSet=warn,stdout
5. 输出可执行的SQL
Java启动参数配置方式
-Ddruid.log.stmt.executableSql=true
logFilter参数直接配置
<bean id="log-filter" class="com.alibaba.druid.filter.logging.Log4jFilter"> <property name="statementExecutableSqlLogEnable" value="true" /> </bean>
https://github.com/alibaba/druid/wiki/%E9%85%8D%E7%BD%AE_LogFilter
MySql+Mybatis+Druid:sql injection violation, multi-statement not allow
做一个批量update的操作 ,sqlmap如下:
<update id="updateBatch" parameterType="java.util.List"> <foreach collection="list" item="item" index="index" open="" close="" separator=";"> update device_bd_token <set> access_token=#{item.accessToken} </set> where device_id = #{item.deviceId} </foreach> </update>
刚开始以为是连接数据库的url上没有加上支持批量的参数,然后就改了下:
jdbc.url=jdbc:mysql://192.168.11.107:3306/alarm_db?allowMultiQueries=true&useUnicode=true&characterEncoding=UTF-8
结果还是同样的错误!但是在命令行直接执行又是没问题的,这就很奇怪了!
仔细看日志,好像是Druid的WallFilter.check()抛出来的,那就是说是Druid在做预编译的时候,给抛出的异常,还没有到mysql的服务器。
最终的解决办法是这样的:
<bean id="dataSourceOne" class="com.alibaba.druid.pool.DruidDataSource" destroy-method="close"> <property name="proxyFilters"> <list> <ref bean="stat-filter" /> <ref bean="wall-filter"/> </list> </property> </bean>
<bean id="wall-filter" class="com.alibaba.druid.wall.WallFilter"> <property name="config" ref="wall-config" /> </bean> <bean id="wall-config" class="com.alibaba.druid.wall.WallConfig"> <property name="multiStatementAllow" value="true" /> </bean>
配置一个multiStatementAllow参数就可以了。
看下源码的处理:




也就是说,只要把config的multiStatementAllow设置为true就可以避免出现这样的错误了!
Druid配置的时候还有一个大坑就是,不要同时配置filters和proxyFilters,filter都是内置的,想通过proxyFilters来定制的话,就不要配置filters。
DruidDataSource继承了DruidAbstractDataSource,
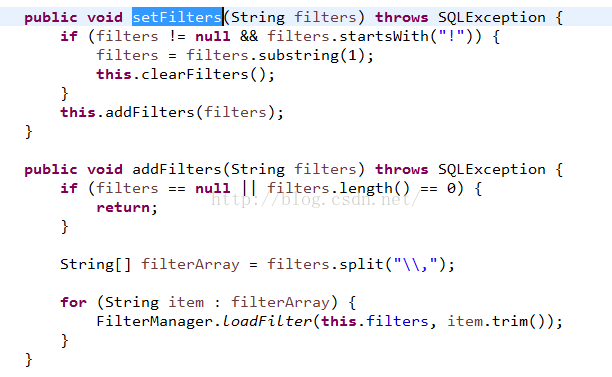

可以看出来,既可以配置filters,也可以配置proxyFilters,不同的是,filters是字符串别名,proxyFilters是类。
我们继续看一下这些字符串的值应该是啥样的:


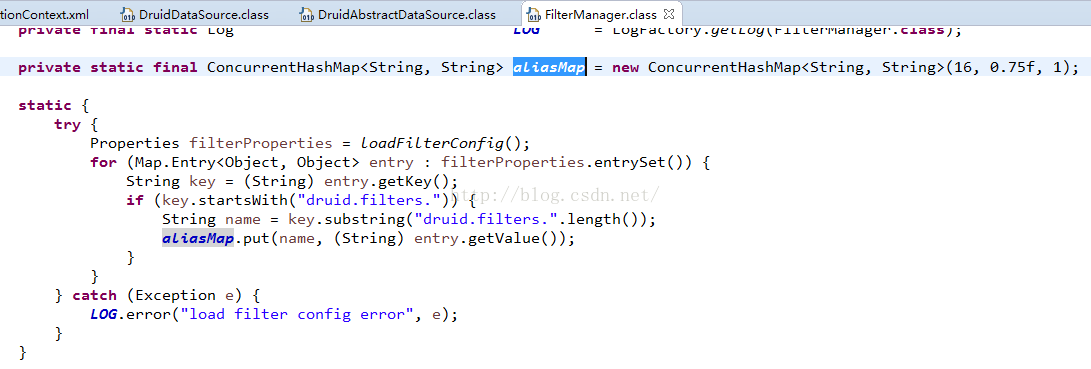
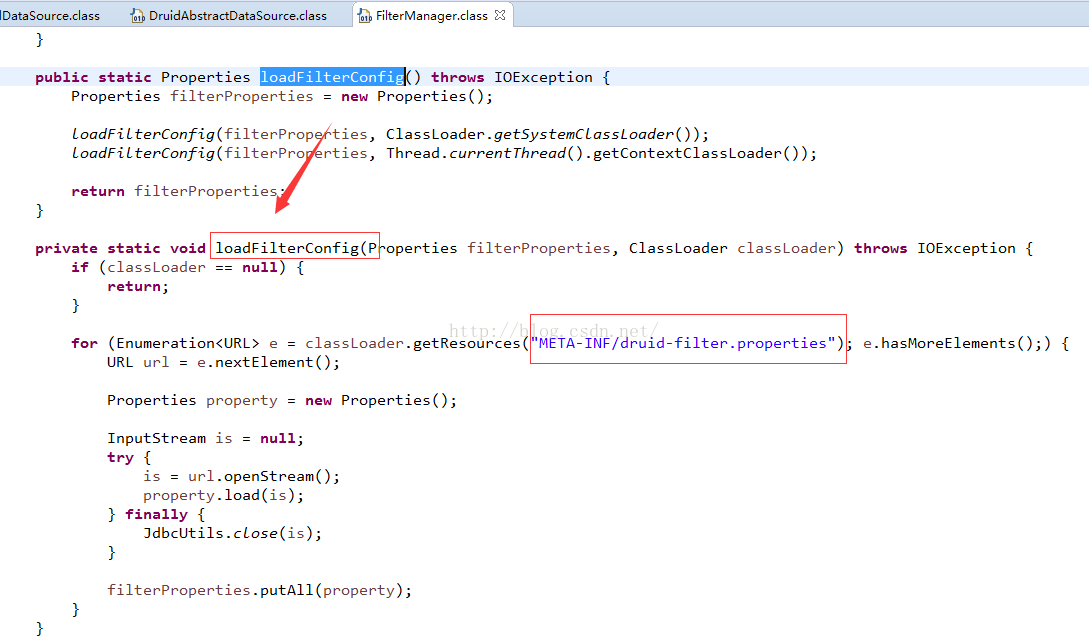
原来在这里:

这就是druid内置的所有的filter了,去掉前缀druid.filters就是别名了。
[ERROR] session ip change too many (WebSessionStat.java:266)的原因及不完整解决办法
最近将项目放到公网,结果反复刷新页面后,出现了大量的[ERROR] session ip change too many (WebSessionStat.java:266)错误,如下图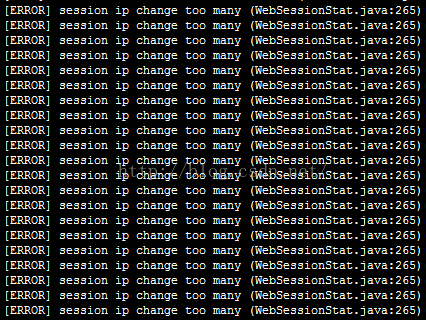
仔细查找,原来是alibaba druid提示的,具体来说,是druid监控session时,记录访问IP提示的。
如果只想看解决方法,对原因无兴趣,请直接跳到本文末尾,下面是产生的原因。
首先打开druid的源代码,找到com.alibaba.druid.support.http.stat.WebSessionStat类,可以看到输出错误的源代码
public void addRemoteAddress(String ip) { if (remoteAddresses == null) { this.remoteAddresses = ip; return; } if (remoteAddresses.contains(ip)) { return; } if (remoteAddresses.length() > 256) { LOG.error("session ip change too many"); return; } remoteAddresses += ';' + ip; }
很明显,是由于每次访问的ip不一样,然后remoteAddresses += ';' + ip;多次累加,导致remoteAddresses超过了256位长度。可是为什么同一个session每次ip会不一样,ip又是怎么获取的,这需要继续跟踪源代码。
跟踪源代码可以看到com.alibaba.druid.util.DruidWebUtils的public static String getRemoteAddr(HttpServletRequest request)方法中,是这么获取IP的:
package com.alibaba.druid.util; import javax.servlet.GenericServlet; import javax.servlet.ServletContext; import javax.servlet.http.HttpServletRequest; public class DruidWebUtils { public static String getRemoteAddr(HttpServletRequest request) { String ip = request.getHeader("x-forwarded-for"); if (ip == null || ip.length() == 0 || "unknown".equalsIgnoreCase(ip)) { ip = request.getHeader("Proxy-Client-IP"); } if (ip == null || ip.length() == 0 || "unknown".equalsIgnoreCase(ip)) { ip = request.getHeader("WL-Proxy-Client-IP"); } if (ip == null || ip.length() == 0 || "unknown".equalsIgnoreCase(ip)) { ip = request.getRemoteAddr(); } return ip; }
可以看到,druid获得ip的方法是request.getHeader("x-forwarded-for");,这个方法会获取到ip:port,而国内由于公网IP极其匮乏,导致绝大部分人上网都是通过地址映射以后来上网,这就导致了每次请求的ip、端口都可能不一样,那么自然会被WebSessionStat.addRemoteAddress()方法累加到remoteAddresses,导致remoteAddresses越来越长,最终超过256位长度,触发LOG.error("session ip change too many");语句。
知道原因,下面就是修改方法:
方法一:关闭druid的session监控。
在web.xml配置druid的地方,将sessionStatEnable设为false即可,如下: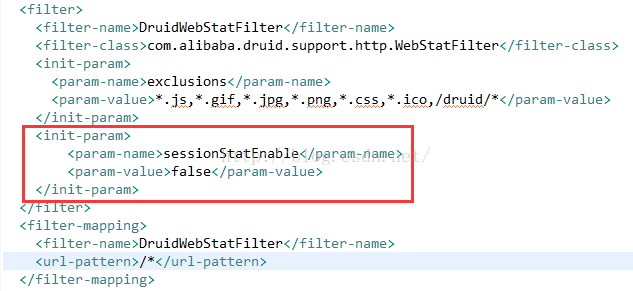
方法二:修改druid的源码。
下载或反编译druid的源码,将LOG.error("session ip change too many");注释掉,或者将if条件长度改大即可。
方法三:等。等阿里巴巴官方修改相关代码。
参考文献:http://www.oschina.net/question/579092_243246
---------------------
作者:zhu19774279
来源:CSDN
原文:https://blog.csdn.net/zhu19774279/article/details/50392813
版权声明:本文为博主原创文章,转载请附上博文链接!
配置WebStatFilter
WebStatFilter用于采集web-jdbc关联监控的数据。
web.xml配置
<filter> <filter-name>DruidWebStatFilter</filter-name> <filter-class>com.alibaba.druid.support.http.WebStatFilter</filter-class> <init-param> <param-name>exclusions</param-name> <param-value>*.js,*.gif,*.jpg,*.png,*.css,*.ico,/druid/*</param-value> </init-param> </filter> <filter-mapping> <filter-name>DruidWebStatFilter</filter-name> <url-pattern>/*</url-pattern> </filter-mapping>
exclusions配置
经常需要排除一些不必要的url,比如*.js,/jslib/*等等。配置在init-param中。比如:
<init-param> <param-name>exclusions</param-name> <param-value>*.js,*.gif,*.jpg,*.png,*.css,*.ico,/druid/*</param-value> </init-param>
sessionStatMaxCount配置
缺省sessionStatMaxCount是1000个。你可以按需要进行配置,比如:
<init-param> <param-name>sessionStatMaxCount</param-name> <param-value>1000</param-value> </init-param>
sessionStatEnable配置
你可以关闭session统计功能,比如:
<init-param> <param-name>sessionStatEnable</param-name> <param-value>false</param-value> </init-param>
principalSessionName配置
你可以配置principalSessionName,使得druid能够知道当前的session的用户是谁。比如:
<init-param> <param-name>principalSessionName</param-name> <param-value>xxx.user</param-value> </init-param>
根据需要,把其中的xxx.user修改为你user信息保存在session中的sessionName。
注意:如果你session中保存的是非string类型的对象,需要重载toString方法。
principalCookieName
如果你的user信息保存在cookie中,你可以配置principalCookieName,使得druid知道当前的user是谁
<init-param> <param-name>principalCookieName</param-name> <param-value>xxx.user</param-value> </init-param>
根据需要,把其中的xxx.user修改为你user信息保存在cookie中的cookieName
profileEnable
druid 0.2.7版本开始支持profile,配置profileEnable能够监控单个url调用的sql列表。
<init-param> <param-name>profileEnable</param-name> <param-value>true</param-value> </init-param>
结果展示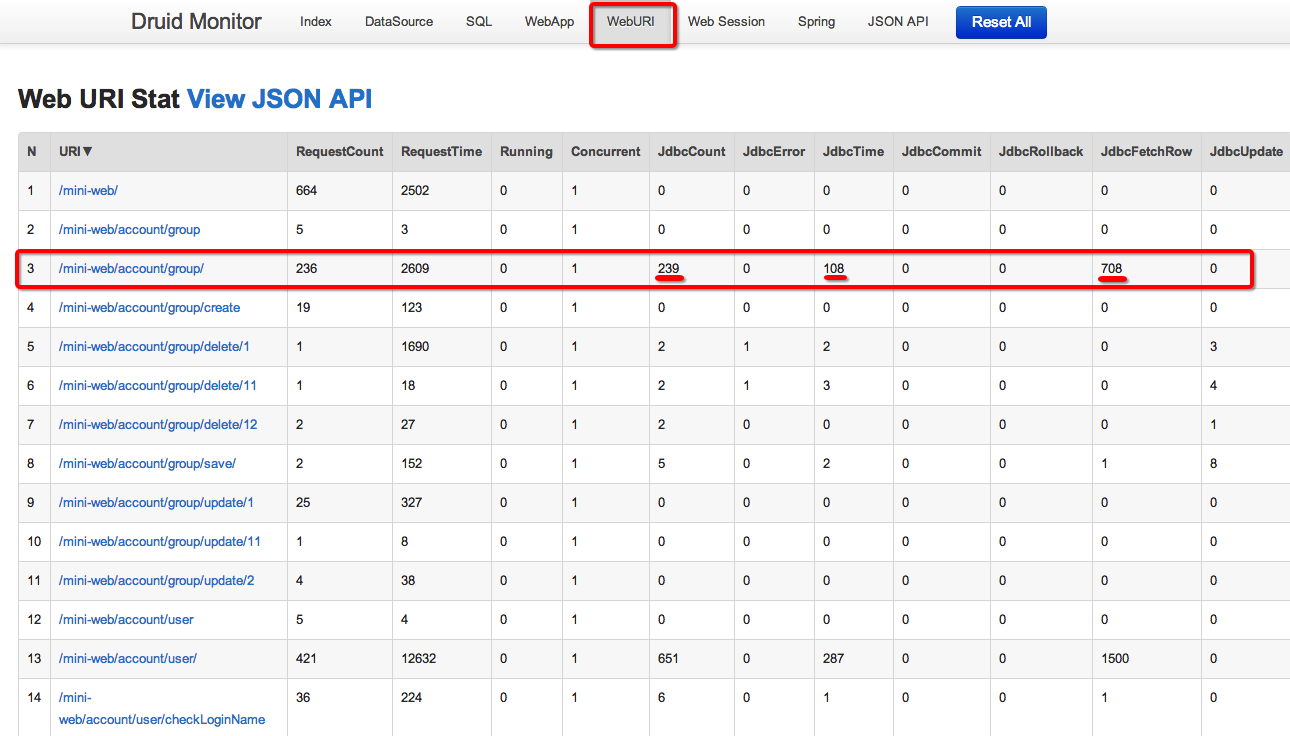
https://github.com/alibaba/druid/wiki/%E9%85%8D%E7%BD%AE_%E9%85%8D%E7%BD%AEWebStatFilter
DruidDataSource配置兼容DBCP,但个别配置的语意有所区别。
| 配置 | 缺省值 | 说明 |
|---|---|---|
| name | 配置这个属性的意义在于,如果存在多个数据源,监控的时候可以通过名字来区分开来。如果没有配置,将会生成一个名字,格式是:"DataSource-" + System.identityHashCode(this). 另外配置此属性至少在1.0.5版本中是不起作用的,强行设置name会出错。详情-点此处。 | |
| url | 连接数据库的url,不同数据库不一样。例如: mysql : jdbc:mysql://10.20.153.104:3306/druid2 oracle : jdbc:oracle:thin:@10.20.149.85:1521:ocnauto |
|
| username | 连接数据库的用户名 | |
| password | 连接数据库的密码。如果你不希望密码直接写在配置文件中,可以使用ConfigFilter。详细看这里 | |
| driverClassName | 根据url自动识别 | 这一项可配可不配,如果不配置druid会根据url自动识别dbType,然后选择相应的driverClassName |
| initialSize | 0 | 初始化时建立物理连接的个数。初始化发生在显示调用init方法,或者第一次getConnection时 |
| maxActive | 8 | 最大连接池数量 |
| maxIdle | 8 | 已经不再使用,配置了也没效果 |
| minIdle | 最小连接池数量 | |
| maxWait | 获取连接时最大等待时间,单位毫秒。配置了maxWait之后,缺省启用公平锁,并发效率会有所下降,如果需要可以通过配置useUnfairLock属性为true使用非公平锁。 | |
| poolPreparedStatements | false | 是否缓存preparedStatement,也就是PSCache。PSCache对支持游标的数据库性能提升巨大,比如说oracle。在mysql下建议关闭。 |
| maxPoolPreparedStatementPerConnectionSize | -1 | 要启用PSCache,必须配置大于0,当大于0时,poolPreparedStatements自动触发修改为true。在Druid中,不会存在Oracle下PSCache占用内存过多的问题,可以把这个数值配置大一些,比如说100 |
| validationQuery | 用来检测连接是否有效的sql,要求是一个查询语句,常用select 'x'。如果validationQuery为null,testOnBorrow、testOnReturn、testWhileIdle都不会起作用。 | |
| validationQueryTimeout | 单位:秒,检测连接是否有效的超时时间。底层调用jdbc Statement对象的void setQueryTimeout(int seconds)方法 | |
| testOnBorrow | true | 申请连接时执行validationQuery检测连接是否有效,做了这个配置会降低性能。 |
| testOnReturn | false | 归还连接时执行validationQuery检测连接是否有效,做了这个配置会降低性能。 |
| testWhileIdle | false | 建议配置为true,不影响性能,并且保证安全性。申请连接的时候检测,如果空闲时间大于timeBetweenEvictionRunsMillis,执行validationQuery检测连接是否有效。 |
| keepAlive | false (1.0.28) |
连接池中的minIdle数量以内的连接,空闲时间超过minEvictableIdleTimeMillis,则会执行keepAlive操作。 |
| timeBetweenEvictionRunsMillis | 1分钟(1.0.14) | 有两个含义: 1) Destroy线程会检测连接的间隔时间,如果连接空闲时间大于等于minEvictableIdleTimeMillis则关闭物理连接。 2) testWhileIdle的判断依据,详细看testWhileIdle属性的说明 |
| numTestsPerEvictionRun | 30分钟(1.0.14) | 不再使用,一个DruidDataSource只支持一个EvictionRun |
| minEvictableIdleTimeMillis | 连接保持空闲而不被驱逐的最小时间 | |
| connectionInitSqls | 物理连接初始化的时候执行的sql | |
| exceptionSorter | 根据dbType自动识别 | 当数据库抛出一些不可恢复的异常时,抛弃连接 |
| filters | 属性类型是字符串,通过别名的方式配置扩展插件,常用的插件有: 监控统计用的filter:stat 日志用的filter:log4j 防御sql注入的filter:wall |
|
| proxyFilters | 类型是List<com.alibaba.druid.filter.Filter>,如果同时配置了filters和proxyFilters,是组合关系,并非替换关系 |
如果表格无法完全展示,请查看图片:
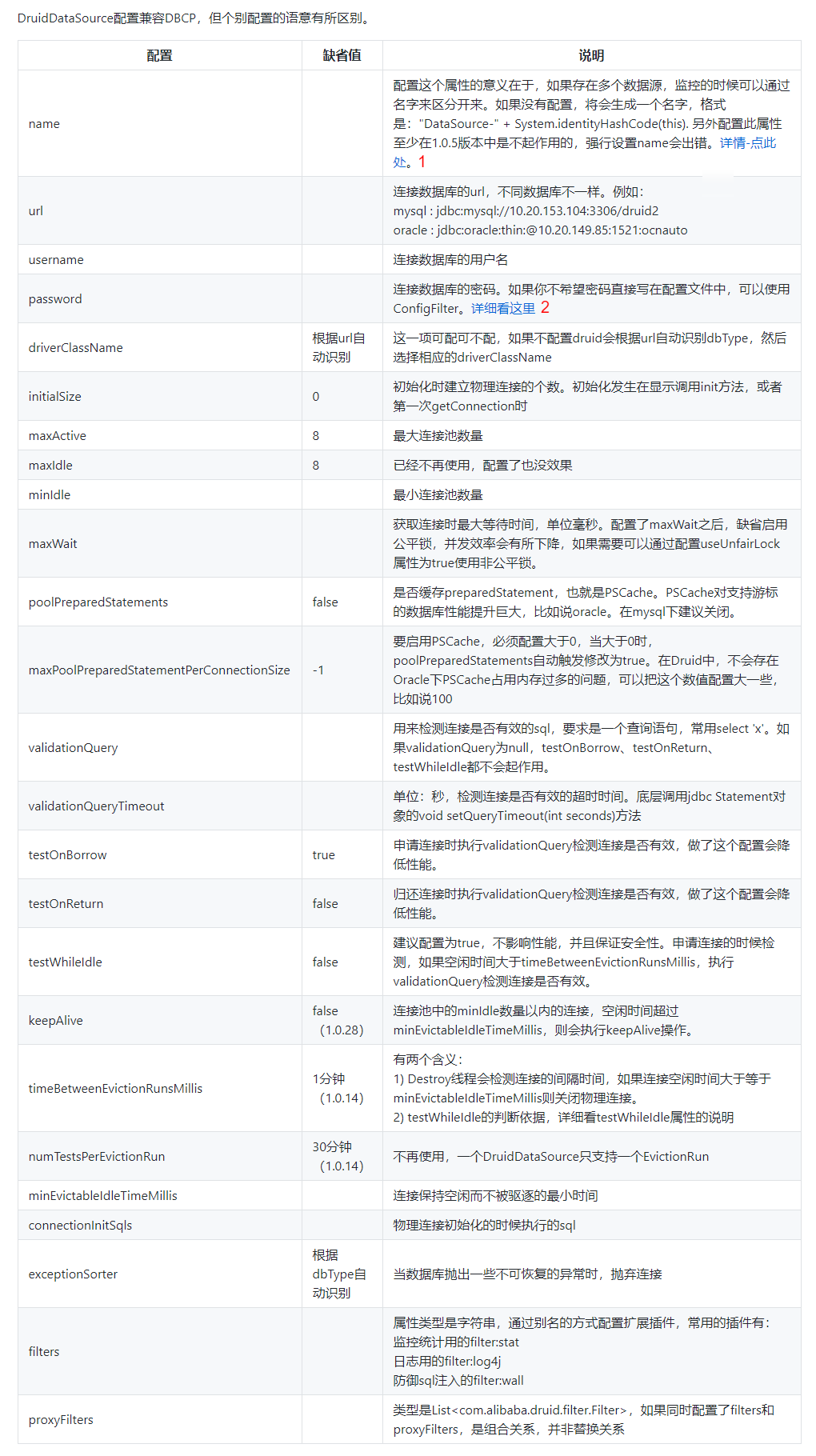
https://github.com/alibaba/druid/wiki/DruidDataSource%E9%85%8D%E7%BD%AE%E5%B1%9E%E6%80%A7%E5%88%97%E8%A1%A8

 浙公网安备 33010602011771号
浙公网安备 33010602011771号