
线性回归-(最小二乘法解方程组,拟合)
一.线性回归(损失函数为最小二乘法)
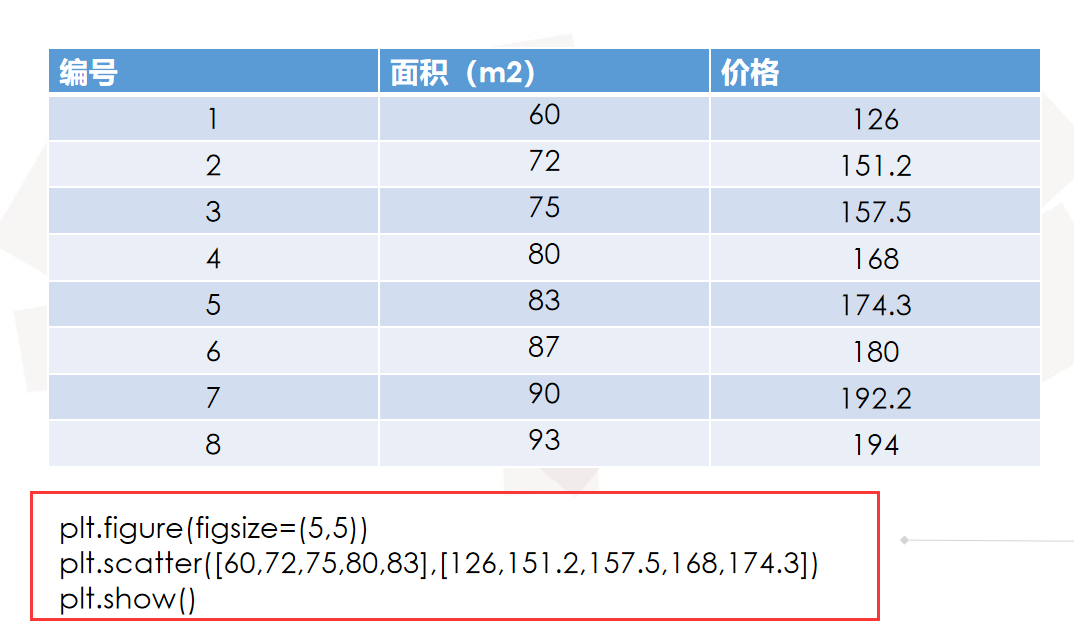

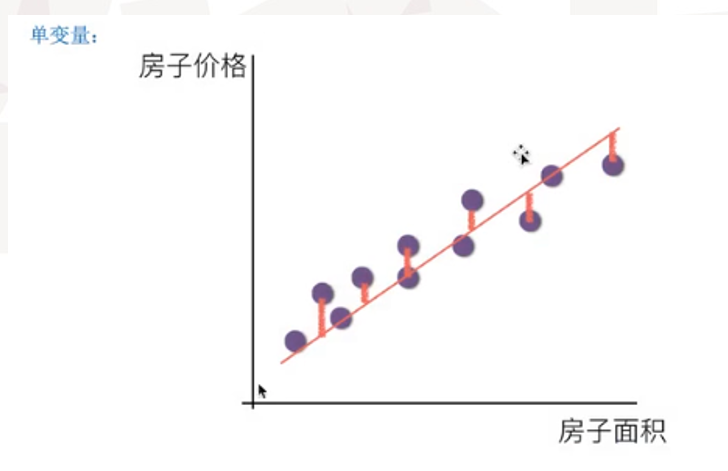
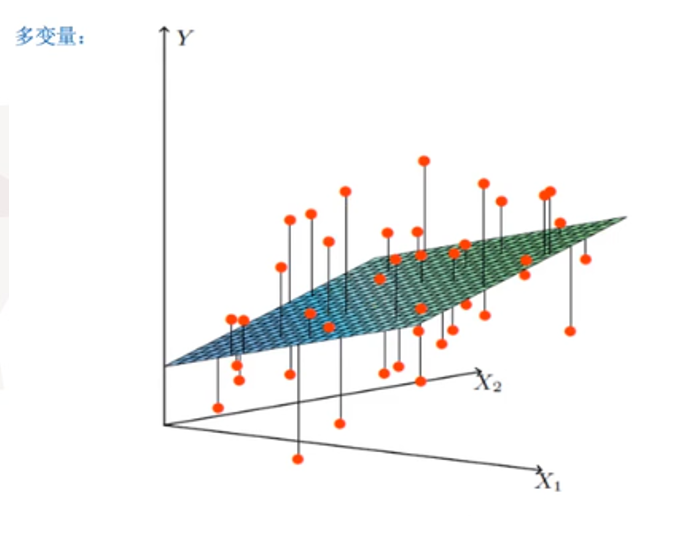


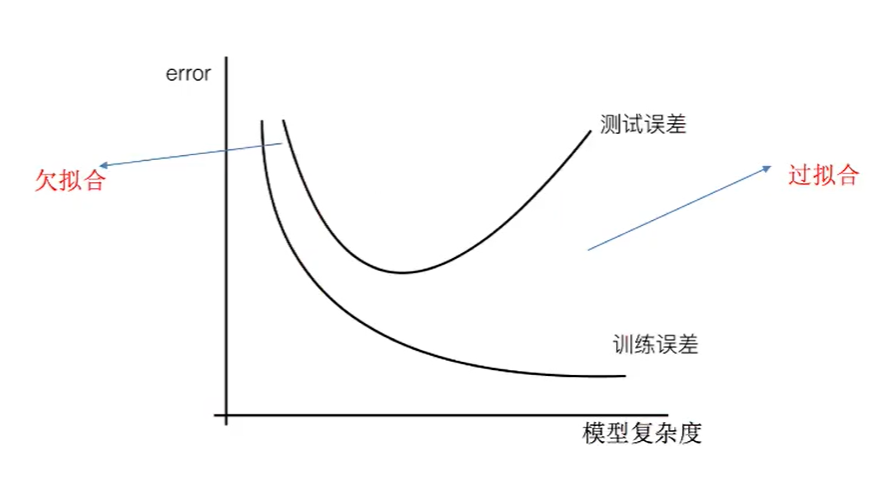
如何去求模型中的权重w,使得损失loss最小? (目的是找到最小损失对应的w值)



sklearn 回归性能评估API:
sklearn.metrics.mean_squared_error




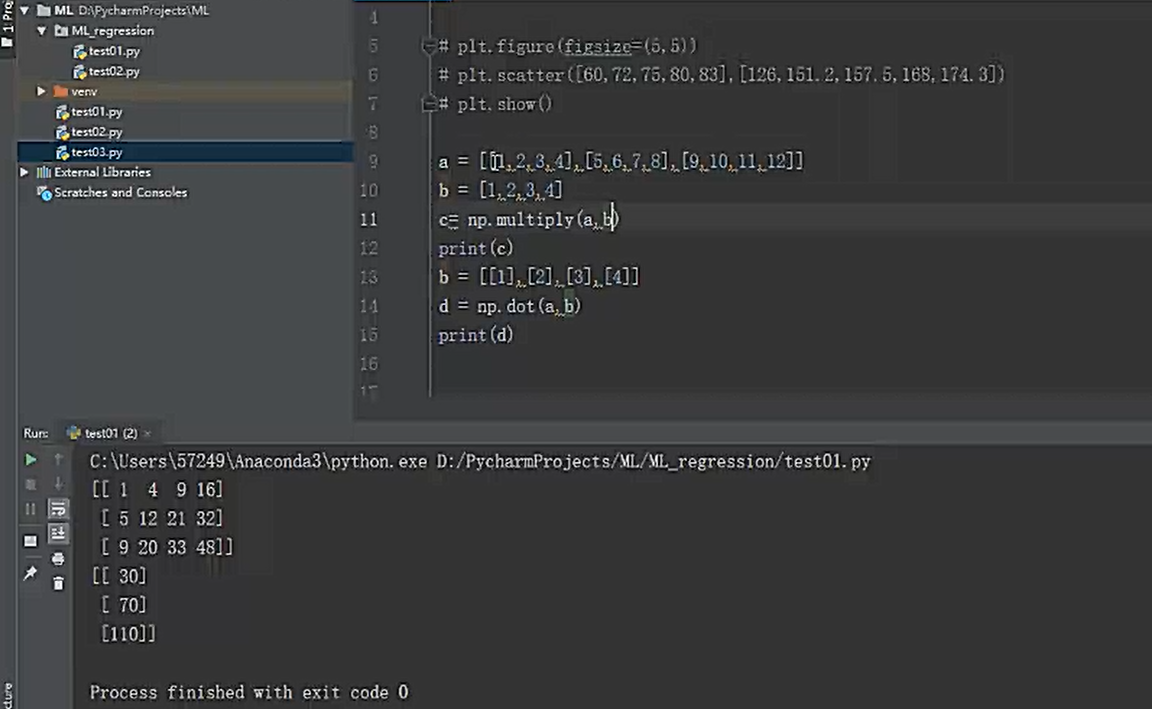
数组相乘与矩阵相乘的演示:
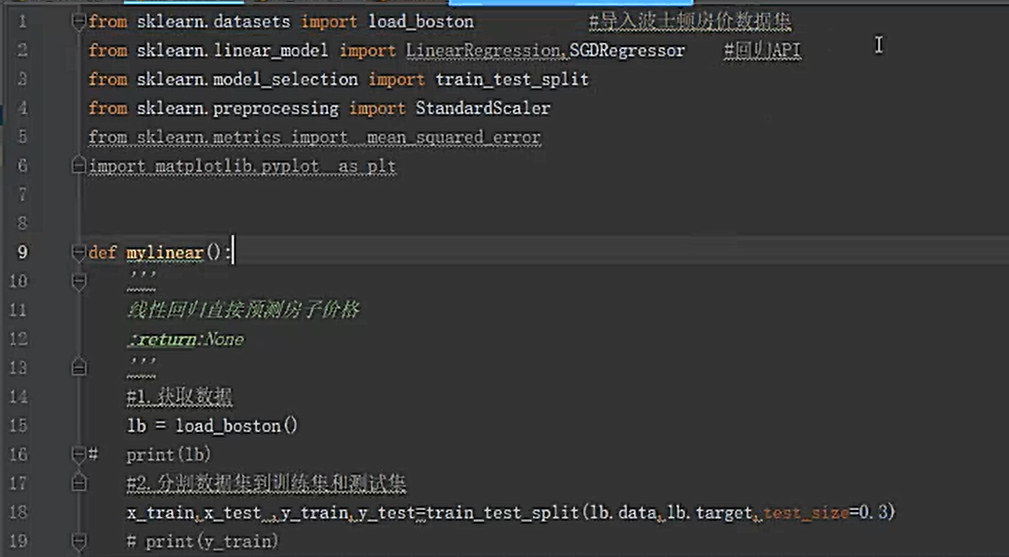
波士顿房价预测



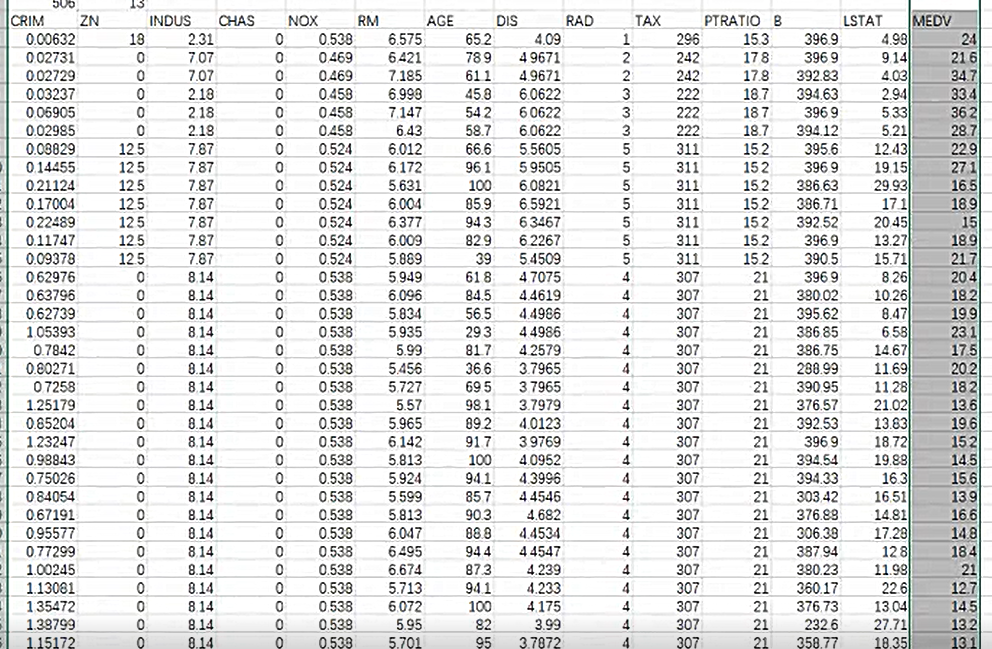
作业:自主编写线性回归算法 ,数据可以自己造,或者从网上获取。
#运用线性回归算法预测波士顿房价
from sklearn.datasets import load_boston
from sklearn.linear_model import LinearRegression
import matplotlib.pyplot as plt
data = load_boston()
data_all = data['data']
x = data_all[:, 5:6]
y = data['target']
model_LR = LinearRegression()
model_LR.fit(x,y)
pre = model_LR.predict(x)
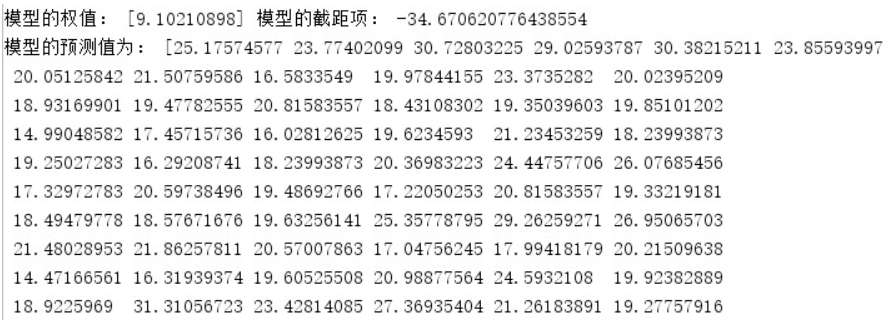
print('模型的权值:',model_LR.coef_,'模型的截距项:',model_LR.intercept_)
print('模型的预测值为:',pre)
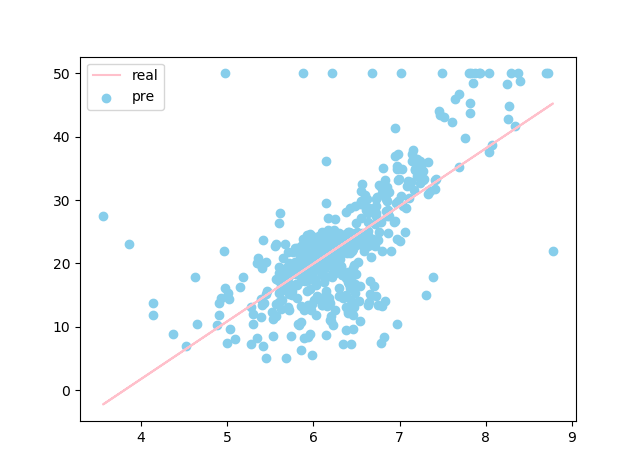
#使用可视化的方式对比拟合出的线性回归方程与真实房价的分布情况
plt.scatter(x,y,c='skyblue') #真实房价的分布(散点图)
plt.plot(x,pre,c='pink') #拟合出的线性回归方程
plt.legend(['real','pre'])
plt.show()
运行结果:
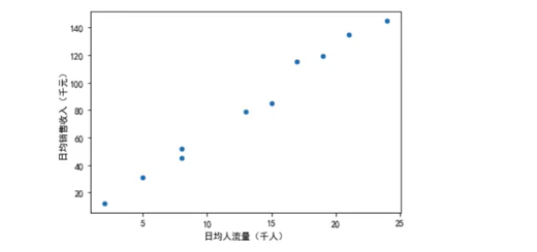
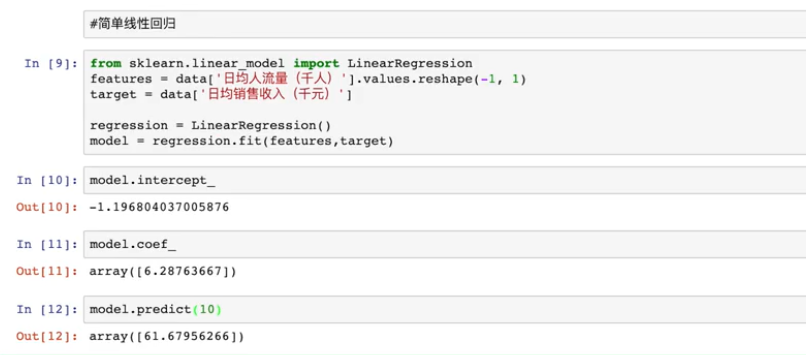
例2: 简单的线性回归
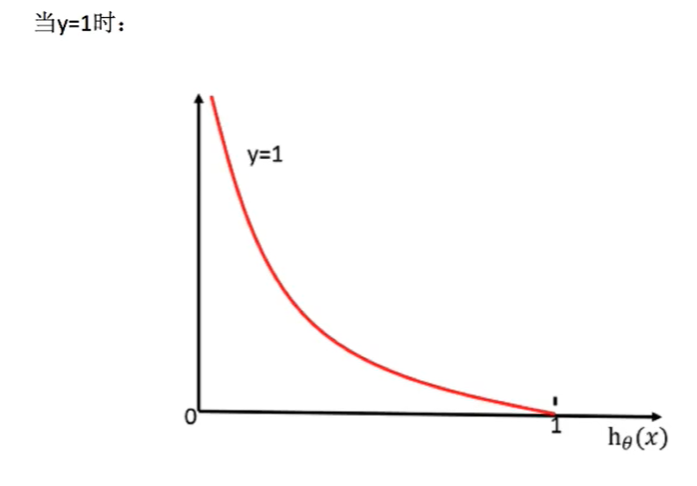
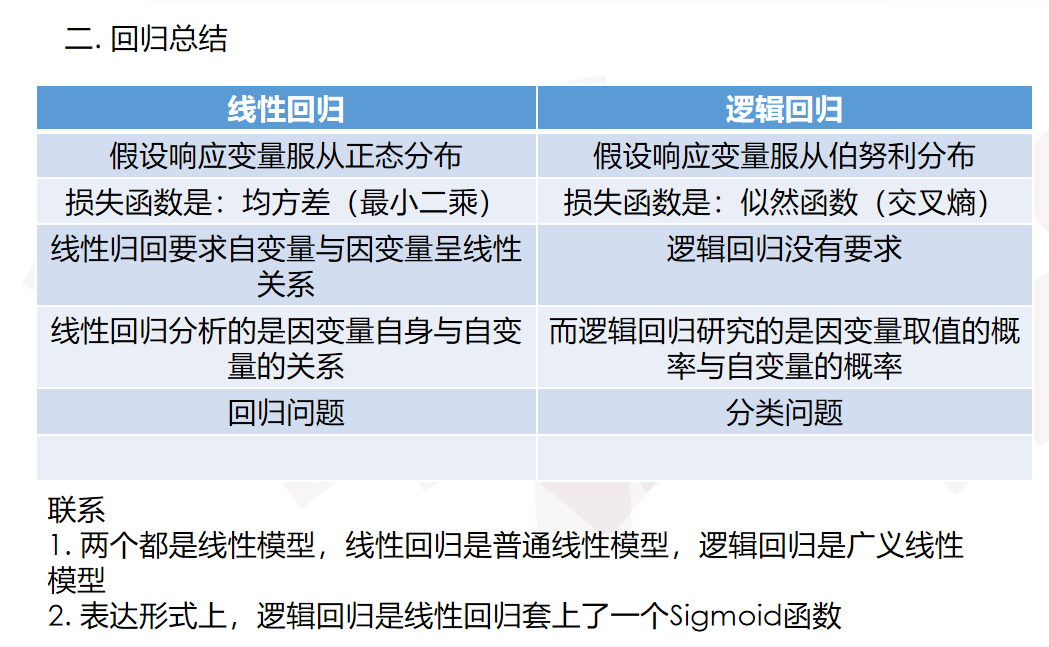
二.逻辑回归(损失函数似然函数)




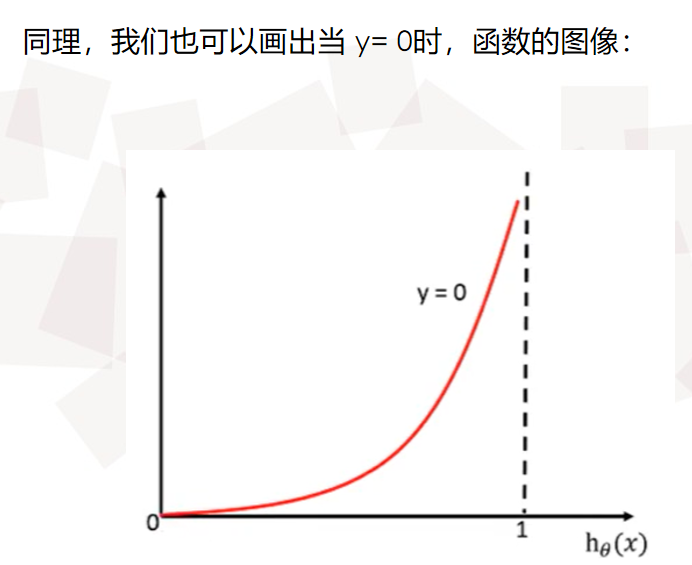
sklearn 逻辑回归API
sklearn,linear_modle.LogisticRegressionI
作业:逻辑回归实践
我这次选择的实践是,利用逻辑回归 依据各种属性数据预测乳腺癌的患病情况。
数据应用的是UCI的 威斯康星州(诊断)数据 ,并给它添加了标签。(一共570条数据)。
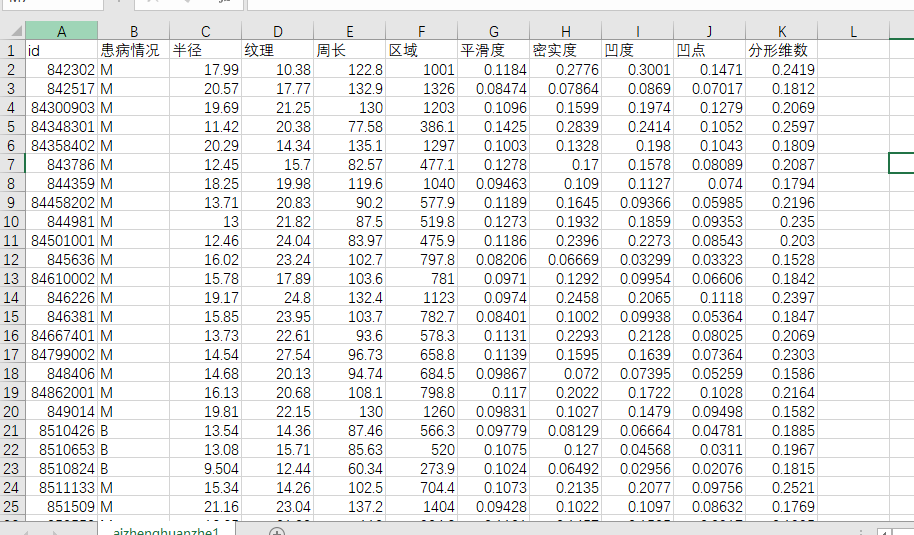
其属性信息为:
1)ID号
2)诊断(M =恶性,B =良性)
3-32)
为每个细胞核计算十个实值特征:
a)半径(中心到周长上各点的距离的平均值)
b)纹理(灰度值的标准偏差)
c)周长
d)面积
e)光滑度(半径长度的局部变化)
f)紧凑度(周长^ 2 /面积-1.0)
g)凹度(轮廓凹部的严重程度)
h )凹点(轮廓的凹入部分的数量)
i)对称性
j)分形维数(“海岸线近似”-1)
实验代码:
from sklearn.model_selection import train_test_split # 划分数据集
from sklearn.linear_model import LogisticRegression # 逻辑回归
from sklearn.metrics import classification_report
from sklearn.preprocessing import StandardScaler # 标准化处理
#导入基础的库
import pandas as pd
data = pd.read_csv(r'D:\shujvji\aizhenghuanzhe1.csv', encoding='utf-8') #读取csv数据
#data.head(3)
x_data = data.iloc[:, 2:10]
y_data = data.iloc[:, 1]
x_train, x_test, y_train, y_test = train_test_split(x_data, y_data, test_size=0.3) #划分测试集占整体30%
#进行标准化处理
std = StandardScaler()
x_train = std.fit_transform(x_train)
x_test = std.transform(x_test)
#建模
mylg = LogisticRegression() #应用逻辑回归算法
mylg.fit(x_train, y_train) #用逻辑回归构建模型
print('模型参数:\n', mylg.coef_) #其结果代表θ,以矩阵方式呈现
mylg_predict = mylg.predict(x_test) #预测
target_names = ['M', 'B']
print('准确率:\n', mylg.score(x_test, y_test))
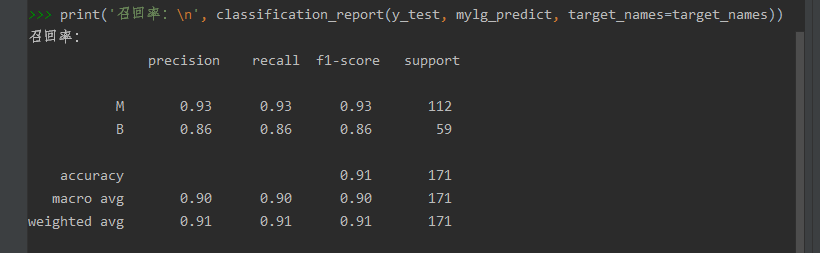
print('召回率:\n', classification_report(y_test, mylg_predict, target_names=target_names))
模型参数:

模型准确率:

召回率和预测精度:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号