kafka和zookeeper
1.Kafka入门教程
1.1 消息队列(Message Queue)
Message Queue消息传送系统提供传送服务。消息传送依赖于大量支持组件,这些组件负责处理连接服务、消息的路由和传送、持久性、安全性以及日志记录。消息服务器可以使用一个或多个代理实例。
JMS(Java Messaging Service)是Java平台上有关面向消息中间件(MOM)的技术规范,它便于消息系统中的Java应用程序进行消息交换,并且通过提供标准的产生、发送、接收消息的接口简化企业应用的开发,翻译为Java消息服务。
1.2 MQ消息模型

KafkaMQ消息模型图1-1
1.3 MQ消息队列分类
消息队列分类:点对点和发布/订阅两种:
1、点对点:
消息生产者生产消息发送到queue中,然后消息消费者从queue中取出并且消费消息。
消息被消费以后,queue中不再有存储,所以消息消费者不可能消费到已经被消费的消息。Queue支持存在多个消费者,但是对一个消息而言,只会有一个消费者可以消费。
2、发布/订阅:
消息生产者(发布)将消息发布到topic中,同时有多个消息消费者(订阅)消费该消息。和点对点方式不同,发布到topic的消息会被所有订阅者消费。
1.4 MQ消息队列对比
1、RabbitMQ:支持的协议多,非常重量级消息队列,对路由(Routing),负载均衡(Loadbalance)或者数据持久化都有很好的支持。
2、ZeroMQ:号称最快的消息队列系统,尤其针对大吞吐量的需求场景,擅长的高级/复杂的队列,但是技术也复杂,并且只提供非持久性的队列。
3、ActiveMQ:Apache下的一个子项,类似ZeroMQ,能够以代理人和点对点的技术实现队列。
4、Redis:是一个key-Value的NOSql数据库,但也支持MQ功能,数据量较小,性能优于RabbitMQ,数据超过10K就慢的无法忍受。
1.5 Kafka简介
Kafka是分布式发布-订阅消息系统,它最初由 LinkedIn 公司开发,使用 Scala语言编写,之后成为 Apache 项目的一部分。在Kafka集群中,没有“中心主节点”的概念,集群中所有的服务器都是对等的,因此,可以在不做任何配置的更改的情况下实现服务器的的添加与删除,同样的消息的生产者和消费者也能够做到随意重启和机器的上下线。

Kafka消息系统生产者和消费者部署关系图1-2

Kafka消息系统架构图1-3
1.6 Kafka术语介绍
1、消息生产者:即:Producer,是消息的产生的源头,负责生成消息并发送到Kafka
服务器上。
2、消息消费者:即:Consumer,是消息的使用方,负责消费Kafka服务器上的消息。
3、主题:即:Topic,由用户定义并配置在Kafka服务器,用于建立生产者和消息者之间的订阅关系:生产者发送消息到指定的Topic下,消息者从这个Topic下消费消息。
4、消息分区:即:Partition,一个Topic下面会分为很多分区,例如:“kafka-test”这个Topic下可以分为6个分区,分别由两台服务器提供,那么通常可以配置为让每台服务器提供3个分区,假如服务器ID分别为0、1,则所有的分区为0-0、0-1、0-2和1-0、1-1、1-2。Topic物理上的分组,一个 topic可以分为多个 partition,每个 partition 是一个有序的队列。partition中的每条消息都会被分配一个有序的 id(offset)。
5、Broker:即Kafka的服务器,用户存储消息,Kafa集群中的一台或多台服务器统称为 broker。
6、消费者分组:Group,用于归组同类消费者,在Kafka中,多个消费者可以共同消息一个Topic下的消息,每个消费者消费其中的部分消息,这些消费者就组成了一个分组,拥有同一个分组名称,通常也被称为消费者集群。
7、Offset:消息存储在Kafka的Broker上,消费者拉取消息数据的过程中需要知道消息在文件中的偏移量,这个偏移量就是所谓的Offset。
1.7 Kafka中Broker
1、Broker:即Kafka的服务器,用户存储消息,Kafa集群中的一台或多台服务器统称为 broker。
2、Message在Broker中通Log追加的方式进行持久化存储。并进行分区(patitions)。
3、为了减少磁盘写入的次数,broker会将消息暂时buffer起来,当消息的个数(或尺寸)达到一定阀值时,再flush到磁盘,这样减少了磁盘IO调用的次数。
4、Broker没有副本机制,一旦broker宕机,该broker的消息将都不可用。Message消息是有多份的。
5、Broker不保存订阅者的状态,由订阅者自己保存。
6、无状态导致消息的删除成为难题(可能删除的消息正在被订阅),kafka采用基于时间的SLA(服务水平保证),消息保存一定时间(通常为7天)后会被删除。
7、消息订阅者可以rewind back到任意位置重新进行消费,当订阅者故障时,可以选择最小的offset(id)进行重新读取消费消息。
1.8 Kafka的Message组成
1、Message消息:是通信的基本单位,每个 producer 可以向一个 topic(主题)发布一些消息。
2、Kafka中的Message是以topic为基本单位组织的,不同的topic之间是相互独立的。每个topic又可以分成几个不同的partition(每个topic有几个partition是在创建topic时指定的),每个partition存储一部分Message。
3、partition中的每条Message包含了以下三个属性:
offset 即:消息唯一标识:对应类型:long
MessageSize 对应类型:int32
data 是message的具体内容。
1.9 Kafka的Partitions分区
1、Kafka基于文件存储.通过分区,可以将日志内容分散到多个server上,来避免文件尺寸达到单机磁盘的上限,每个partiton都会被当前server(kafka实例)保存。
2、可以将一个topic切分多任意多个partitions,来消息保存/消费的效率。
3、越多的partitions意味着可以容纳更多的consumer,有效提升并发消费的能力。
1.10 Kafka的Consumers
1、消息和数据消费者,订阅 topics并处理其发布的消息的过程叫做 consumers。
2、在 kafka中,我们可以认为一个group是一个“订阅者”,一个Topic中的每个partions,只会被一个“订阅者”中的一个consumer消费,不过一个 consumer可以消费多个partitions中的消息(消费者数据小于Partions的数量时)。注意:kafka的设计原理决定,对于一个topic,同一个group中不能有多于partitions个数的consumer同时消费,否则将意味着某些consumer将无法得到消息。
3、一个partition中的消息只会被group中的一个consumer消息。每个group中consumer消息消费互相独立。
1.11 Kafka的持久化
1、一个Topic可以认为是一类消息,每个topic将被分成多partition(区),每个partition在存储层面是append log文件。任何发布到此partition的消息都会被直接追加到log文件的尾部,每条消息在文件中的位置称为offset(偏移量),partition是以文件的形式存储在文件系统中。
2、Logs文件根据broker中的配置要求,保留一定时间后删除来释放磁盘空间。

Kafka消息分区Partition图1-4
Partition:
Topic物理上的分组,一个 topic可以分为多个 partition,每个 partition 是一个有序的队列。partition中的每条消息都会被分配一个有序的 id(offset)。
3、为数据文件建索引:稀疏存储,每隔一定字节的数据建立一条索引。下图为一个partition的索引示意图:

Kafka消息分区Partition索引图1-5
1.12 Kafka的分布式实现:
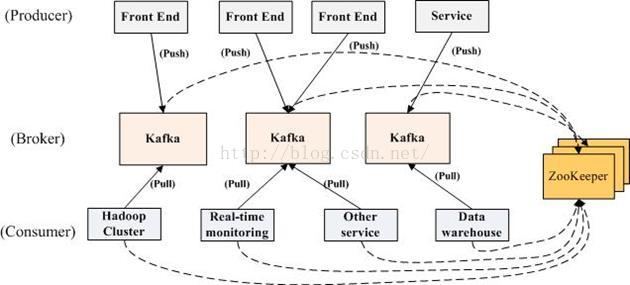
Kafka分布式关系图1-6

Kafka生产环境关系图1-7
1.13 Kafka的通讯协议:
1、Kafka的Producer、Broker和Consumer之间采用的是一套自行设计基于TCP层的协议,根据业务需求定制,而非实现一套类似ProtocolBuffer的通用协议。
2、基本数据类型:(Kafka是基于Scala语言实现的,类型也是Scala中的数据类型)
定长数据类型:int8,int16,int32和int64,对应到Java中就是byte, short, int和long。
变长数据类型:bytes和string。变长的数据类型由两部分组成,分别是一个有符号整数N(表示内容的长度)和N个字节的内容。其中,N为-1表示内容为null。bytes的长度由int32表示,string的长度由int16表示。
数组:数组由两部分组成,分别是一个由int32类型的数字表示的数组长度N和N个元素。
3、Kafka通讯的基本单位是Request/Response。
4、基本结构:
RequestOrResponse => MessageSize(RequestMessage | ResponseMessage)
| 名称 | 类型 | 描术 |
|---|---|---|
| MessageSize | int32 | 表示RequestMessage或者ResponseMessage的长度 |
| RequestMessageResponseMessage | — |
5、通讯过程:
客户端打开与服务器端的Socket
往Socket写入一个int32的数字(数字表示这次发送的Request有多少字节)
服务器端先读出一个int32的整数从而获取这次Request的大小
然后读取对应字节数的数据从而得到Request的具体内容
服务器端处理了请求后,也用同样的方式来发送响应。
6、RequestMessage结构:
RequestMessage => ApiKey ApiVersionCorrelationId ClientId Request
| 名称 | 类型 | 描术 |
|---|---|---|
| ApiKey | int16 | 表示这次请求的API编号 |
| ApiVersion | int16 | 表示请求的API的版本,有了版本后就可以做到后向兼容 |
| CorrelationId | int32 | 由客户端指定的一个数字唯一标示这次请求的id,服务器端在处理完请求后也会把同样的CorrelationId写到Response中,这样客户端就能把某个请求和响应对应起来了。 |
| ClientId | string | 客户端指定的用来描述客户端的字符串,会被用来记录日志和监控,它唯一标示一个客户端。 |
| Request | — | Request的具体内容。 |
7、ResponseMessage结构:
ResponseMessage => CorrelationId Response
| 名称 | 类型 | 描术 |
|---|---|---|
| CorrelationId | int32 | 对应Request的CorrelationId。 |
| Response | — | 对应Request的Response,不同的Request的Response的字段是不一样的。 |
Kafka采用是经典的Reactor(同步IO)模式,也就是1个Acceptor响应客户端的连接请求,N个Processor来读取数据,这种模式可以构建出高性能的服务器。
8、Message结构:
Message:Producer生产的消息,键-值对
Message => Crc MagicByte Attributes KeyValue
| 名称 | 类型 | 描术 |
|---|---|---|
| CRC | int32 | 表示这条消息(不包括CRC字段本身)的校验码。 |
| MagicByte | int8 | 表示消息格式的版本,用来做后向兼容,目前值为0。 |
| Attributes | int8 | 表示这条消息的元数据,目前最低两位用来表示压缩格式。 |
| Key | bytes | 表示这条消息的Key,可以为null。 |
| Value | bytes | 表示这条消息的Value。Kafka支持消息嵌套,也就是把一条消息作为Value放到另外一条消息里面。 |
9、MessageSet结构:
MessageSet:用来组合多条Message,它在每条Message的基础上加上了Offset和MessageSize
MessageSet => [Offset MessageSize Message]
| 名称 | 类型 | 描术 |
|---|---|---|
| Offset | int64 | 它用来作为log中的序列号,Producer在生产消息的时候还不知道具体的值是什么,可以随便填个数字进去。 |
| MessageSize | int32 | 表示这条Message的大小。 |
| Message | - | 表示这条Message的具体内容,其格式见上一小节。 |
10、 Request/Respone和Message/MessageSet的关系:
Request/Response是通讯层的结构,和网络的7层模型对比的话,它类似于TCP层。
Message/MessageSet定义的是业务层的结构,类似于网络7层模型中的HTTP层。Message/MessageSet只是Request/Response的payload中的一种数据结构。
备注:Kafka的通讯协议中不含Schema,格式也比较简单,这样设计的好处是协议自身的Overhead小,再加上把多条Message放在一起做压缩,提高压缩比率,从而在网络上传输的数据量会少一些。
1.14 数据传输的事务定义:
1、at most once:最多一次,这个和JMS中”非持久化”消息类似.发送一次,无论成败,将不会重发。
at most once:消费者fetch消息,然后保存offset,然后处理消息;当client保存offset之后,但是在消息处理过程中出现了异常,导致部分消息未能继续处理.那么此后”未处理”的消息将不能被fetch到,这就是“atmost once”。
2、at least once:消息至少发送一次,如果消息未能接受成功,可能会重发,直到接收成功。
at least once:消费者fetch消息,然后处理消息,然后保存offset.如果消息处理成功之后,但是在保存offset阶段zookeeper异常导致保存操作未能执行成功,这就导致接下来再次fetch时可能获得上次已经处理过的消息,这就是“atleast once”,原因offset没有及时的提交给zookeeper,zookeeper恢复正常还是之前offset状态。
3、exactly once:消息只会发送一次。
exactly once: kafka中并没有严格的去实现(基于2阶段提交,事务),我们认为这种策略在kafka中是没有必要的。
注:通常情况下“at-least-once”是我们首选。(相比at most once而言,重复接收数据总比丢失数据要好)。
2.简单命令介绍
启动命令:./kafka-server-start.sh -daemon /Users/huangweixing/software/kafka_2.12-2.1.0/config/server.properties
创建topic命令:./kafka-topics.sh --create --topic test0 --replication-factor 1 --partitions 1 --zookeeper localhost:2181
查看kafka中topic情况:./kafka-topics.sh --list --zookeeper 127.0.0.1:2181
查看对应topic详细描述信息:./kafka-topics.sh --describe --zookeeper 127.0.0.1:2181 --topic test0
topic信息修改:kafka-topics.sh --zookeeper 127.0.0.1:2181 --alter --topic test0 --partitions 3 ## Kafka分区数量只允许增加,不允许减少
————————————————
版权声明:本文为CSDN博主「没那个条件」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/hweixing123/article/details/86536641
3.kafka配置
1. 生产端的配置文件 producer.properties
# Licensed to the Apache Software Foundation (ASF) under one or more
# contributor license agreements. See the NOTICE file distributed with
# this work for additional information regarding copyright ownership.
# The ASF licenses this file to You under the Apache License, Version 2.0
# (the "License"); you may not use this file except in compliance with
# the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# see org.apache.kafka.clients.producer.ProducerConfig for more details
############################# Producer Basics #############################
# list of brokers used for bootstrapping knowledge about the rest of the cluster
# format: host1:port1,host2:port2 ...
bootstrap.servers=localhost:9092
# specify the compression codec for all data generated: none, gzip, snappy, lz4, zstd
compression.type=none
# name of the partitioner class for partitioning events; default partition spreads data randomly
#partitioner.class=
#broker必须在该时间范围之内给出反馈,否则失败。
#在向producer发送ack之前,broker允许等待的最大时间 ,如果超时,
#broker将会向producer发送一个error ACK.意味着上一次消息因为某种原因
#未能成功(比如follower未能同步成功)
#request.timeout.ms=
# how long `KafkaProducer.send` and `KafkaProducer.partitionsFor` will block for
#max.block.ms=
# the producer will wait for up to the given delay to allow other records to be sent so that the sends can be batched together
#linger.ms=
# the maximum size of a request in bytes
#max.request.size=
# the default batch size in bytes when batching multiple records sent to a partition
#batch.size=
# the total bytes of memory the producer can use to buffer records waiting to be sent to the server
#buffer.memory=
2. 消费端的配置文件 consumer.properties:
# Licensed to the Apache Software Foundation (ASF) under one or more
# contributor license agreements. See the NOTICE file distributed with
# this work for additional information regarding copyright ownership.
# The ASF licenses this file to You under the Apache License, Version 2.0
# (the "License"); you may not use this file except in compliance with
# the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# see org.apache.kafka.clients.consumer.ConsumerConfig for more details
# list of brokers used for bootstrapping knowledge about the rest of the cluster
# format: host1:port1,host2:port2 ...
bootstrap.servers=localhost:9092
#指定消费
group.id=test-consumer-group
# 如果zookeeper没有offset值或offset值超出范围。
#那么就给个初始的offset。有smallest、largest、
#anything可选,分别表示给当前最小的offset、
#当前最大的offset、抛异常。默认larges
#auto.offset.reset=
3.服务端的配置文件 server.properties
# Licensed to the Apache Software Foundation (ASF) under one or more
# contributor license agreements. See the NOTICE file distributed with
# this work for additional information regarding copyright ownership.
# The ASF licenses this file to You under the Apache License, Version 2.0
# (the "License"); you may not use this file except in compliance with
# the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# see kafka.server.KafkaConfig for additional details and defaults
############################# Server Basics #############################
#broker的全局唯一编号,不能重复
broker.id=0
############################# Socket Server Settings #############################
# The address the socket server listens on. It will get the value returned from
# java.net.InetAddress.getCanonicalHostName() if not configured.
# FORMAT:
# listeners = listener_name://host_name:port
# EXAMPLE:
# listeners = PLAINTEXT://your.host.name:9092
#listeners=PLAINTEXT://:9092
# Hostname and port the broker will advertise to producers and consumers. If not set,
# it uses the value for "listeners" if configured. Otherwise, it will use the value
# returned from java.net.InetAddress.getCanonicalHostName().
#advertised.listeners=PLAINTEXT://your.host.name:9092
# Maps listener names to security protocols, the default is for them to be the same. See the config documentation for more details
#listener.security.protocol.map=PLAINTEXT:PLAINTEXT,SSL:SSL,SASL_PLAINTEXT:SASL_PLAINTEXT,SASL_SSL:SASL_SSL
#处理网络请求的线程数量,也就是接收消息的线程数。
#接收线程会将接收到的消息放到内存中,然后再从内存中写入磁盘。
num.network.threads=3
#消息从内存中写入磁盘是时候使用的线程数量。
#用来处理磁盘IO的线程数量
num.io.threads=8
#发送套接字的缓冲区大小
socket.send.buffer.bytes=102400
#接受套接字的缓冲区大小
socket.receive.buffer.bytes=102400
#请求套接字的缓冲区大小
socket.request.max.bytes=104857600
############################# Log Basics #############################
#kafka运行日志存放的路径
log.dirs=/tmp/kafka-logs
#topic在当前broker上的分片个数
num.partitions=1
#我们知道segment文件默认会被保留7天的时间,超时的话就
#会被清理,那么清理这件事情就需要有一些线程来做。这里就是
#用来设置恢复和清理data下数据的线程数量
num.recovery.threads.per.data.dir=1
############################# Internal Topic Settings #############################
# The replication factor for the group metadata internal topics "__consumer_offsets" and "__transaction_state"
# For anything other than development testing, a value greater than 1 is recommended for to ensure availability such as 3.
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
############################# Log Flush Policy #############################
# Messages are immediately written to the filesystem but by default we only fsync() to sync
# the OS cache lazily. The following configurations control the flush of data to disk.
# There are a few important trade-offs here:
# 1. Durability: Unflushed data may be lost if you are not using replication.
# 2. Latency: Very large flush intervals may lead to latency spikes when the flush does occur as there will be a lot of data to flush.
# 3. Throughput: The flush is generally the most expensive operation, and a small flush interval may lead to excessive seeks.
# The settings below allow one to configure the flush policy to flush data after a period of time or
# every N messages (or both). This can be done globally and overridden on a per-topic basis.
# The number of messages to accept before forcing a flush of data to disk
#log.flush.interval.messages=10000
# The maximum amount of time a message can sit in a log before we force a flush
#log.flush.interval.ms=1000
############################# Log Retention Policy #############################
# The following configurations control the disposal of log segments. The policy can
# be set to delete segments after a period of time, or after a given size has accumulated.
# A segment will be deleted whenever *either* of these criteria are met. Deletion always happens
# from the end of the log.
#segment文件保留的最长时间,默认保留7天(168小时),
#超时将被删除,也就是说7天之前的数据将被清理掉。
log.retention.hours=168
# A size-based retention policy for logs. Segments are pruned from the log unless the remaining
# segments drop below log.retention.bytes. Functions independently of log.retention.hours.
#log.retention.bytes=1073741824
#日志文件中每个segment的大小,默认为1G
log.segment.bytes=1073741824
#上面的参数设置了每一个segment文件的大小是1G,那么
#就需要有一个东西去定期检查segment文件有没有达到1G,
#多长时间去检查一次,就需要设置一个周期性检查文件大小
#的时间(单位是毫秒)。
log.retention.check.interval.ms=300000
############################# Zookeeper #############################
# Zookeeper connection string (see zookeeper docs for details).
# This is a comma separated host:port pairs, each corresponding to a zk
# server. e.g. "127.0.0.1:3000,127.0.0.1:3001,127.0.0.1:3002".
# You can also append an optional chroot string to the urls to specify the
# root directory for all kafka znodes.
zookeeper.connect=localhost:2181
# Timeout in ms for connecting to zookeeper
zookeeper.connection.timeout.ms=6000
############################# Group Coordinator Settings #############################
# The following configuration specifies the time, in milliseconds, that the GroupCoordinator will delay the initial consumer rebalance.
# The rebalance will be further delayed by the value of group.initial.rebalance.delay.ms as new members join the group, up to a maximum of max.poll.interval.ms.
# The default value for this is 3 seconds.
# We override this to 0 here as it makes for a better out-of-the-box experience for development and testing.
# However, in production environments the default value of 3 seconds is more suitable as this will help to avoid unnecessary, and potentially expensive, rebalances during application startup.
group.initial.rebalance.delay.ms=0
4.java kafka
引入依赖
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
bootstrap.yml
spring:
cloud:
config:
label: paas-service-message-converged-service
profile: DEV
discovery:
enabled: true
service-id: baseServices-config-server
# stream:
# kafka:
# binder:
# brokers: 10.17.173.199:9092
# zkNodes: 10.17.173.199:2181
kafka:
# 指定kafka server的地址,集群配多个,中间,逗号隔开
bootstrap-servers: 10.17.162.121:9092
producer:
# 写入失败时,重试次数。当leader节点失效,一个repli节点会替代成为leader节点,此时可能出现写入失败,
# 当retris为0时,produce不会重复。retirs重发,此时repli节点完全成为leader节点,不会产生消息丢失。
retries: 0
# 每次批量发送消息的数量,produce积累到一定数据,一次发送
# batch-size: 16384
# produce积累数据一次发送,缓存大小达到buffer.memory就发送数据
# buffer-memory: 33554432
acks: 1
# 指定消息key和消息体的编解码方式
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.apache.kafka.common.serialization.StringSerializer
consumer:
# 指定默认消费者group id --> 由于在kafka中,同一组中的consumer不会读取到同一个消息,依靠groud.id设置组名
group-id: group${random.uuid}
# smallest和latest才有效,如果smallest重新0开始读取,如果是latest从logfile的offset读取。消息推送只需要实时的消息,因此使用latest
auto-offset-reset: latest
# enable.auto.commit:true --> 设置自动提交offset
enable-auto-commit: true
#如果'enable.auto.commit'为true,则消费者偏移自动提交给Kafka的频率(以毫秒为单位),默认值为5000。
auto-commit-interval: 100
# 指定消息key和消息体的编解码方式
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
application:
name: paas-service-message-converged-service
main:
allow-bean-definition-overriding: true
eureka:
instance:
hostname: ${spring.cloud.client.ip-address}
prefer-ip-address: true
instanceId: ${eureka.instance.hostname}:${spring.application.name}:${server.port}
client:
serviceUrl:
defaultZone: http://portal-dev:portal-dev@10.17.162.120:8761/eureka/
kafka发送消息
package com.midea.mideacloud.paasservice.rest;
import com.alibaba.fastjson.JSONArray;
import com.midea.management.util.UserUtils;
import com.midea.mideacloud.paascommon.utils.TemplateUtil;
import com.midea.mideacloud.paasservice.common.utils.NumberUtil;
import com.midea.mideacloud.paasservice.domain.MessageAtomicRouters;
import com.midea.mideacloud.paasservice.domain.api.MessageReceiverFeign;
import com.midea.mideacloud.paasservice.domain.api.UserInfoFeign;
import com.midea.mideacloud.paasservice.domain.dto.*;
import com.midea.mideacloud.paasservice.service.IMessageInfoConvergedService;
import com.midea.mideacloud.paasservice.service.websocket.helper.WebSocketMessageRedisHelper;
import com.mideaframework.core.web.JsonResponse;
import com.mideaframework.core.web.RestDoing;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.BeanUtils;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.web.bind.annotation.*;
import javax.servlet.http.HttpServletRequest;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
import static com.midea.mideacloud.paasservice.common.constants.WebSocketConstants.Kafka.WEBSOCKET_TO_CLIENT_KAFKA_TOPIC;
import static com.midea.mideacloud.paasservice.common.constants.WebSocketConstants.Redis.REDIS_WEBSOCKET_MSG_PREFIX;
@RestController
public class MessageInfoRest {
private Logger logger = LoggerFactory.getLogger(MessageInfoRest.class);
@Autowired
private IMessageInfoConvergedService iMessageInfoConvergedService;
@Autowired
private KafkaTemplate<String,Object> kafkaTemplate;
@Autowired
private UserInfoFeign userInfoFeign;
@Autowired
private WebSocketMessageRedisHelper webSocketMessageRedisHelper;
@Autowired
private RedisTemplate redisTemplate;
@Autowired
private MessageReceiverFeign messageReceiverFeign;
@RequestMapping(value = MessageAtomicRouters.ROUTER_MESSAGES_SEND_MESSAGE,method = RequestMethod.POST)
public JsonResponse send(@RequestBody Body body, HttpServletRequest request){
if(body == null){
logger.info("body参数为空");
return JsonResponse.fail("500","body参数为空");
}
RestDoing doing = jsonResponse -> {
//通过传过来的类型,去获取模板对象,拼接对应的回复内容
int type = body.getType();
List<String> data = body.getData();
String[] strings = data.toArray(new String[data.size()]);
JsonResponse<MessageTemplateDto> messageTemplateDtoJsonResponse = iMessageInfoConvergedService.getTemplate(type);
if(null == messageTemplateDtoJsonResponse || !messageTemplateDtoJsonResponse.judgeSuccess()){
logger.error("获取信息模板失败",messageTemplateDtoJsonResponse);
}
MessageTemplateDto template = messageTemplateDtoJsonResponse.getData();
logger.info("模板对象"+template);
//根据类型拼接内容模板
MessageInfoDto messageInfoDto = new MessageInfoDto();
//工单或者应用部署类型,要拼接标题模板
if(0 == type || 3 == type || 4 == type){
messageInfoDto.setTitle(TemplateUtil.getTitle(template.getName(),body.getTitle()));
}else {
messageInfoDto.setTitle(template.getName());
}
messageInfoDto.setContent(TemplateUtil.getContent(type,template.getTypeTemplate(), strings));
messageInfoDto.setType(type);
messageInfoDto.setUrl(TemplateUtil.getUrl(type,template.getUrlTemplate(),body.getId()));
Integer messageId = (Integer) iMessageInfoConvergedService.saveMessageInfo(messageInfoDto).getData();
messageInfoDto.setId(messageId);
//把id插入中间表
List<Integer> userIds = body.getUserIds();
List<MessageReceiverDto> MessageReceiverDtos = new ArrayList<>();
for (int i = 0; i < userIds.size(); i++) {
MessageReceiverDto messageReceiverDto = new MessageReceiverDto();
messageReceiverDto.setMessageId(messageId);
Integer userId = NumberUtil.valueOf(userIds.get(i));
messageReceiverDto.setUserId(userId);
messageReceiverDto.setStatus(0);
MessageReceiverDtos.add(messageReceiverDto);
}
//通过用户id集合获取用户对象集合
List<UserInfoDto> userInfos = userInfoFeign.findByUserCodeList((ArrayList<Integer>) userIds).getData();
logger.info("用户对象集合打印"+userInfos);
//插入接收表,返回对应的对象集合
List<MessageReceiverDto> messageReceiverDtoList = messageReceiverFeign.insertRelation(MessageReceiverDtos).getData();
//封装推送消息
List<Object> list = new ArrayList<>();
for (int i = 0; i < userIds.size(); i++) {
MessageInfoDto temp = new MessageInfoDto();
BeanUtils.copyProperties(messageInfoDto, temp);
Integer userId = NumberUtil.valueOf(userIds.get(i));
//根据userId获取用户user对象
temp.setUserId(userId);
UserInfoDto userInfo = null;
try {
userInfo = userInfos.get(i);
} catch (Exception e) {
e.printStackTrace();
logger.info("消息发送,用户获取失败");
}
temp.setUserCode(userInfo.getUserCode());
temp.setUserName(userInfo.getUserName());
Integer messageReceiverId = messageReceiverDtoList.get(i).getId();
temp.setMessageReceiverId(messageReceiverId.toString());
list.add(temp);
}
logger.info("推送消息集合打印"+list);
JSONArray kafkaMsgArray = new JSONArray(list);
//将当前消息存入redis中,key为messageId,标记状态为未发送
Map mapToRedis = webSocketMessageRedisHelper.buildMapForBatchSaveToRedis(kafkaMsgArray);
redisTemplate.opsForHash().putAll(REDIS_WEBSOCKET_MSG_PREFIX, mapToRedis);
//将消息推送至kafka
kafkaTemplate.send(WEBSOCKET_TO_CLIENT_KAFKA_TOPIC, kafkaMsgArray.toJSONString());
};
return doing.go(request, logger);
}
}
kafka监听
package com.midea.mideacloud.paasservice.mq.kafka;
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONArray;
import com.midea.mideacloud.paasservice.cache.websocket.SocketManager;
import com.midea.mideacloud.paasservice.service.websocket.WebSocketService;
import lombok.extern.slf4j.Slf4j;
import org.apache.commons.lang.StringUtils;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.stereotype.Component;
import org.springframework.web.socket.WebSocketSession;
import java.io.IOException;
import static com.midea.mideacloud.paasservice.common.constants.WebSocketConstants.Kafka.WEBSOCKET_CLOSE_KAFKA_TOPIC;
import static com.midea.mideacloud.paasservice.common.constants.WebSocketConstants.Kafka.WEBSOCKET_TO_CLIENT_KAFKA_TOPIC;
/**
* <p>Kafka消费者:监听WebSocket推送消息</p>
* @author ex_shibb1
* @date 2019/11/13 14:58
*/
@Slf4j
@Component
public class WebSocketMessageKafkaConsumer {
@Autowired
private WebSocketService webSocketService;
@KafkaListener(topics = WEBSOCKET_TO_CLIENT_KAFKA_TOPIC)
public void onMessage(String message){
log.info("监听到一条{}主题的消息 : {}", WEBSOCKET_TO_CLIENT_KAFKA_TOPIC, message);
if (StringUtils.isBlank(message)) {
return;
}
JSONArray kafkaMsgArray = JSON.parseArray(message);
webSocketService.batchSendMsg(kafkaMsgArray);
}
@Deprecated
@KafkaListener(topics = WEBSOCKET_CLOSE_KAFKA_TOPIC)
public void onClose(String userCode){
log.info("监听到一条{}主题的消息 : {}", WEBSOCKET_CLOSE_KAFKA_TOPIC, userCode);
if (StringUtils.isBlank(userCode)) {
return;
}
WebSocketSession webSocketSession = SocketManager.get(userCode);
if (null == webSocketSession) {
//尝试remove一下
SocketManager.remove(userCode);
log.warn(userCode + "连接不存在,无需断开");
return;
}
try {
webSocketSession.close();
SocketManager.remove(userCode);
} catch (IOException e) {
log.error(userCode + "的WebSocket断开连接异常", e);
return;
}
log.info(userCode + "连接断开成功");
}
}
2.kafka manage
一.kafka-manager简介
kafka-manager是目前最受欢迎的kafka集群管理工具,最早由雅虎开源,用户可以在Web界面执行一些简单的集群管理操作。具体支持以下内容:
- 管理多个集群
- 轻松检查群集状态(主题,消费者,偏移,代理,副本分发,分区分发)
- 运行首选副本选举
- 使用选项生成分区分配以选择要使用的代理
- 运行分区重新分配(基于生成的分配)
- 使用可选主题配置创建主题(0.8.1.1具有与0.8.2+不同的配置)
- 删除主题(仅支持0.8.2+并记住在代理配置中设置delete.topic.enable = true)
- 主题列表现在指示标记为删除的主题(仅支持0.8.2+)
- 批量生成多个主题的分区分配,并可选择要使用的代理
- 批量运行重新分配多个主题的分区
- 将分区添加到现有主题
- 更新现有主题的配置
kafka-manager 项目地址:https://github.com/yahoo/kafka-manager
二.kafka-manager安装
1.下载安装包
使用Git或者直接从Releases中下载,这里我们下载 1.3.3.18 版本:https://github.com/yahoo/kafka-manager/releases

[admin@node21 software]$ wget https://github.com/yahoo/kafka-manager/archive/1.3.3.18.zip
2.解压安装包
[ ](javascript:void(0)😉
](javascript:void(0)😉
[admin@node21 software]$ mv 1.3.3.18.zip kafka-manager-1.3.3.18.zip
[admin@node21 software]$ unzip kafka-manager-1.3.3.18.zip -d /opt/module/
[admin@node21 software]$ cd /opt/module/
[admin@node21 module]$ ll
drwxr-xr-x 9 admin admin 268 May 27 00:33 jdk1.8
drwxr-xr-x 7 admin admin 122 Jun 14 11:44 kafka_2.11-1.1.0
drwxrwxr-x 9 admin admin 189 Jul 7 04:44 kafka-manager-1.3.3.18
drwxr-xr-x 11 admin admin 4096 May 29 10:14 zookeeper-3.4.12
[admin@node21 module]$ ls kafka-manager-1.3.3.18/
app build.sbt conf img LICENCE project public README.md sbt src target test
[](javascript:void(0)😉
3.sbt编译
1)yum安装sbt(因为kafka-manager需要sbt编译)
[admin@node21 ~]$ curl https://bintray.com/sbt/rpm/rpm > bintray-sbt-rpm.repo
[admin@node21 ~]$ sudo mv bintray-sbt-rpm.repo /etc/yum.repos.d/
[admin@node21 ~]$ sudo yum install sbt
修改仓库地址:(sbt 默认下载库文件很慢, 还时不时被打断),我们可以在用户目录下创建 touch ~/.sbt/repositories, 填上阿里云的镜像 # vi ~/.sbt/repositories
[](javascript:void(0)😉
[repositories]
local
aliyun: http://maven.aliyun.com/nexus/content/groups/public/
typesafe: http://repo.typesafe.com/typesafe/ivy-releases/, [organization]/[module]/(scala_[scalaVersion]/)(sbt_[sbtVersion]/)[revision]/[type]s/[artifact](-[classifier]).[ext], bootOnly
sonatype-oss-releases
maven-central
sonatype-oss-snapshots
[](javascript:void(0)😉
验证:检查sbt是否安装成功,查看命令输出,发现已经成功可以从maven.aliyun.com/nexus下载到依赖即表示成功
[admin@node21 ~]$ sbt-version
2)编译kafka-manager
[admin@node21 kafka-manager-1.3.3.18]$ ./sbt clean dist
看到打印这个消息 Getting org.scala-sbt sbt 0.13.9 (this may take some time)... 就慢慢等吧,可以到~/.sbt/boot/update.log 查看sbt更新日志。sbt更新好,就开始下载各种jar包,最后看到:Your package is ready in /opt/module/kafka-manager-1.3.3.18/target/universal/kafka-manager-1.3.3.18.zip 证明编译好了。

4.安装
环境准备:Java 8+ kafka集群搭建参考:CentOS7.5搭建Kafka2.11-1.1.0集群
重新解压编译好的kafka-manager-1.3.3.18.zip
[admin@node21 kafka-manager-1.3.3.18]$ ls
bin conf lib README.md share
修改配置文件
[](javascript:void(0)😉
[admin@node21 kafka-manager-1.3.3.18]$ pwd
/opt/module/kafka-manager-1.3.3.18
[admin@node21 kafka-manager-1.3.3.18]$ ls conf/
application.conf consumer.properties logback.xml logger.xml routes
[admin@node21 kafka-manager-1.3.3.18]$ sudo vi conf/application.conf
修改kafka-manager.zkhosts列表为自己的zk节点
kafka-manager.zkhosts="node21:2181,node22:2181,node23:2181"
[](javascript:void(0)😉

5.启动服务
启动zk集群,kafka集群,再启动kafka-manager服务。
bin/kafka-manager 默认的端口是9000,可通过 -Dhttp.port,指定端口; -Dconfig.file=conf/application.conf指定配置文件:
[admin@node21 kafka-manager-1.3.3.18]$ nohup bin/kafka-manager -Dconfig.file=conf/application.conf -Dhttp.port=8080 &
jps查看进程

6.编写服务启动脚本
chmod +x kafka-manager.sh
nohup /opt/module/kafka-manager-1.3.3.18/bin/kafka-manager -Dconfig.file=/opt/module/kafka-manager-1.3.3.18/conf/application.conf -Dhttp.port=8888 >/opt/module/kafka-ma
nager-1.3.3.18/kafka-manager.log 2>&1 &
WebUI查看:http://node21:8888/ 出现如下界面则启动成功。

三.kafka-manager配置
1.新建Cluster
点击【Cluster】>【Add Cluster】打开如下添加集群配置界面:输入集群的名字(如Kafka-Cluster-1)和 Zookeeper 服务器地址(如localhost:2181),选择最接近的Kafka版本

其他broker的配置可以根据自己需要进行配置,默认情况下,点击【保存】时,会提示几个默认值为1的配置错误,需要配置为>=2的值。提示如下。

新建完成后,保存运行界面如下:



四.kafka-manager管理
1.新建主题
Topic---Create

2.查看主题
Topic---list

3.kafka-manage配置
3.1.application.conf
# Copyright 2015 Yahoo Inc. Licensed under the Apache License, Version 2.0
# See accompanying LICENSE file.
# This is the main configuration file for the application.
# ~~~~~
# Secret key
# ~~~~~
# The secret key is used to secure cryptographics functions.
# If you deploy your application to several instances be sure to use the same key!
play.crypto.secret="^<csmm5Fx4d=r2HEX8pelM3iBkFVv?k[mc;IZE<_Qoq8EkX_/7@Zt6dP05Pzea3U"
play.crypto.secret=${?APPLICATION_SECRET}
play.http.session.maxAge="1h"
# The application languages
# ~~~~~
play.i18n.langs=["en"]
play.http.requestHandler = "play.http.DefaultHttpRequestHandler"
play.http.context = "/"
play.application.loader=loader.KafkaManagerLoader
# 修改kafka-manager.zkhosts列表为自己的zk节点
kafka-manager.zkhosts="10.17.162.229:2181,10.17.162.230:2181,10.17.162.231:2181"
kafka-manager.zkhosts=${?ZK_HOSTS}
pinned-dispatcher.type="PinnedDispatcher"
pinned-dispatcher.executor="thread-pool-executor"
application.features=["KMClusterManagerFeature","KMTopicManagerFeature","KMPreferredReplicaElectionFeature","KMReassignPartitionsFeature"]
akka {
loggers = ["akka.event.slf4j.Slf4jLogger"]
loglevel = "INFO"
}
akka.logger-startup-timeout = 60s
basicAuthentication.enabled=true
basicAuthentication.enabled=${?KAFKA_MANAGER_AUTH_ENABLED}
basicAuthentication.ldap.enabled=false
basicAuthentication.ldap.enabled=${?KAFKA_MANAGER_LDAP_ENABLED}
basicAuthentication.ldap.server=""
basicAuthentication.ldap.server=${?KAFKA_MANAGER_LDAP_SERVER}
basicAuthentication.ldap.port=389
basicAuthentication.ldap.port=${?KAFKA_MANAGER_LDAP_PORT}
basicAuthentication.ldap.username=""
basicAuthentication.ldap.username=${?KAFKA_MANAGER_LDAP_USERNAME}
basicAuthentication.ldap.password=""
basicAuthentication.ldap.password=${?KAFKA_MANAGER_LDAP_PASSWORD}
basicAuthentication.ldap.search-base-dn=""
basicAuthentication.ldap.search-base-dn=${?KAFKA_MANAGER_LDAP_SEARCH_BASE_DN}
basicAuthentication.ldap.search-filter="(uid=$capturedLogin$)"
basicAuthentication.ldap.search-filter=${?KAFKA_MANAGER_LDAP_SEARCH_FILTER}
basicAuthentication.ldap.connection-pool-size=10
basicAuthentication.ldap.connection-pool-size=${?KAFKA_MANAGER_LDAP_CONNECTION_POOL_SIZE}
basicAuthentication.ldap.ssl=false
basicAuthentication.ldap.ssl=${?KAFKA_MANAGER_LDAP_SSL}
basicAuthentication.username="admin"
basicAuthentication.username=${?KAFKA_MANAGER_USERNAME}
basicAuthentication.password="password"
basicAuthentication.password=${?KAFKA_MANAGER_PASSWORD}
basicAuthentication.realm="Kafka-Manager"
basicAuthentication.excluded=["/api/health"] # ping the health of your instance without authentification
kafka-manager.consumer.properties.file=${?CONSUMER_PROPERTIES_FILE}
3.2.consumer.propertis
security.protocol=PLAINTEXT
key.deserializer=org.apache.kafka.common.serialization.ByteArrayDeserializer
value.deserializer=org.apache.kafka.common.serialization.ByteArrayDeserializer
3.zookeeper
下载地址:http://mirrors.hust.edu.cn/apache/zookeeper/ ,↓
下载最新版:

点击下载:

下载好后解压到自己想存放的位置,当前我的文件解压到了D盘(D:\zookeeper-3.5.4-beta),选择解压到当前文件即可。。。
解压后目录结构:
- bin目录
zk的可执行脚本目录,包括zk服务进程,zk客户端,等脚本。其中,.sh是Linux环境下的脚本,.cmd是Windows环境下的脚本。 - conf目录
配置文件目录。zoo_sample.cfg为样例配置文件,需要修改为自己的名称,一般为zoo.cfg。log4j.properties为日志配置文件。 - lib
zk依赖的包。 - contrib目录
一些用于操作zk的工具包。 - recipes目录
zk某些用法的代码示例
zookeeper 支持的运行平台:

ZooKeeper的安装包括单机模式安装,以及集群模式安装。
单机模式较简单,是指只部署一个zk进程,客户端直接与该zk进程进行通信。
在开发测试环境下,通过来说没有较多的物理资源,因此我们常使用单机模式。当然在单台物理机上也可以部署集群模式,但这会增加单台物理机的资源消耗。故在开发环境中,我们一般使用单机模式。
但是要注意,生产环境下不可用单机模式,这是由于无论从系统可靠性还是读写性能,单机模式都不能满足生产的需求。
1、单机模式:
然后找到文件夹下面的 conf 配置文件中的 zoo_sample.cfg 设置一下配置文件就可以启动:
but 这里需要更改一下 .cfg 文件名 zookeeper 启动脚本默认是寻找 zoo.cfg 文件。。。。之所以 得修改文件名
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
dataDir=D:\\zookeeper-3.5.4-beta\\data
dataLogDir=D:\\zookeeper-3.5.4-beta\\log
# the port at which the clients will connect
admin.serverPort=8082
clientPort=2181
# the maximum number of client connections.
# increase this if you need to handle more clients
#maxClientCnxns=60
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
#autopurge.purgeInterval=1
修改内容:
增加了:admin.serverPort=8082 #不然会出现端口被占用的情况,因为默认是和Apache.Tomcat使用的8080端口
修改了:dataDir=D:\\zookeeper-3.5.4-beta\\data #保存数据的目录
dataLogDir=D:\\zookeeper-3.5.4-beta\\log #保存日志的目录
-
tickTime:这个时间是作为 Zookeeper 服务器之间或客户端与服务器之间维持心跳的时间间隔,也就是每个 tickTime 时间就会发送一个心跳。
-
dataDir:顾名思义就是 Zookeeper 保存数据的目录,默认情况下,Zookeeper 将写数据的日志文件也保存在这个目录里。
-
dataLogDir:顾名思义就是 Zookeeper 保存日志文件的目录
-
clientPort:这个端口就是客户端连接 Zookeeper 服务器的端口,Zookeeper 会监听这个端口,接受客户端的访问请求。
使用文本编辑器打开zkServer.cmd或者zkServer.sh文件,可以看到其会调用zkEnv.cmd或者zkEnv.sh脚本。zkEnv脚本的作用是设置zk运行的一些环境变量,例如配置文件的位置和名称等。
当这些配置项配置好后,你现在就可以启动 Zookeeper 了,启动后要检查 Zookeeper 是否已经在服务,可以通过 netstat – ano 命令查看是否有你配置的 clientPort 端口号在监听服务
通过 cmd 命令模式进入 Zookeeper 的 bin 目录:# D:\zookeeper-3.5.4-beta\bin>zkServer.cmd
现在 zookeeper server 端已经启动:然后我们来连接一下这个服务端
通过 cmd 命令模式进入 Zookeeper 的 bin 目录运行:# D:\zookeeper-3.5.4-beta\bin>zkCli.cmd
2 、集群模式:
单机模式的zk进程虽然便于开发与测试,但并不适合在生产环境使用。在生产环境下,我们需要使用集群模式来对zk进行部署。
注意:
在集群模式下,建议至少部署3个zk进程,或者部署奇数个zk进程。如果只部署2个zk进程,当其中一个zk进程挂掉后,剩下的一个进程并不能构成一个quorum的大多数。因此,部署2个进程甚至比单机模式更不可靠,因为2个进程其中一个不可用的可能性比一个进程不可用的可能性还大。
- 在集群模式下,所有的zk进程可以使用相同的配置文件(是指各个zk进程部署在不同的机器上面),例如如下配置:
只需要在我们配置好的zoo.cfg文件中进行更改:
tickTime=2000
dataDir=/home/myname/zookeeper
clientPort=2181
initLimit=5
syncLimit=2
server.1=192.168.229.160:2888:3888
server.2=192.168.229.161:2888:3888
server.3=192.168.229.162:2888:3888
-
initLimit
ZooKeeper集群模式下包含多个zk进程,其中一个进程为leader,余下的进程为follower。
当follower最初与leader建立连接时,它们之间会传输相当多的数据,尤其是follower的数据落后leader很多。initLimit配置follower与leader之间建立连接后进行同步的最长时间。 -
syncLimit
配置follower和leader之间发送消息,请求和应答的最大时间长度。 -
tickTime
tickTime则是上述两个超时配置的基本单位,例如对于initLimit,其配置值为5,说明其超时时间为 2000ms * 5 = 10秒。 -
server.id=host:port1:port2
其中id为一个数字,表示zk进程的id,这个id也是dataDir目录下myid文件的内容。
host是该zk进程所在的IP地址,port1表示follower和leader交换消息所使用的端口,port2表示选举leader所使用的端口。 -
dataDir
其配置的含义跟单机模式下的含义类似,不同的是集群模式下还有一个myid文件。myid文件的内容只有一行,且内容只能为1 - 255之间的数字,这个数字亦即上面介绍server.id中的id,表示zk进程的id。 -
initLimit
ZooKeeper集群模式下包含多个zk进程,其中一个进程为leader,余下的进程为follower。
当follower最初与leader建立连接时,它们之间会传输相当多的数据,尤其是follower的数据落后leader很多。initLimit配置follower与leader之间建立连接后进行同步的最长时间。 -
syncLimit
配置follower和leader之间发送消息,请求和应答的最大时间长度。 -
tickTime
tickTime则是上述两个超时配置的基本单位,例如对于initLimit,其配置值为5,说明其超时时间为 2000ms * 5 = 10秒。 -
server.id=host:port1:port2
其中id为一个数字,表示zk进程的id,这个id也是dataDir目录下myid文件的内容。
host是该zk进程所在的IP地址,port1表示follower和leader交换消息所使用的端口,port2表示选举leader所使用的端口。 -
dataDir
其配置的含义跟单机模式下的含义类似,不同的是集群模式下还有一个myid文件。myid文件的内容只有一行,且内容只能为1 - 255之间的数字,这个数字亦即上面介绍server.id中的id,表示zk进程的id。
注意
如果仅为了测试部署集群模式而在同一台机器上部署zk进程,server.id=host:port1:port2配置中的port参数必须不同。但是,为了减少机器宕机的风险,强烈建议在部署集群模式时,将zk进程部署不同的物理机器上面。
我们打算在三台不同的机器 192.168.229.160,192.168.229.161,192.168.229.162上各部署一个zk进程,以构成一个zk集群。 三个zk进程均使用相同的 zoo.cfg 配置:
tickTime=2000
dataDir=/home/myname/zookeeper
clientPort=2181
initLimit=5
syncLimit=2
server.1=192.168.229.160:2888:3888
server.2=192.168.229.161:2888:3888
server.3=192.168.229.162:2888:3888
在三台机器dataDir目录( /home/myname/zookeeper 目录)下,分别生成一个myid文件,其内容分别为1,2,3。然后分别在这三台机器上启动zk进程,这样我们便将zk集群启动了起来:
可以使用以下命令来连接一个zk集群:
zkCli -server IP:端口,IP:端口,IP:端口
客户端连接进程(连接上哪台机器的zk进程是随机的),客户端已成功连接上zk集群。
3.zookeeper配置
3.1 zoo.cfg
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
dataDir=/apps/data/zookeeper
# the port at which the clients will connect
clientPort=2181
server.1=10.17.162.229:2888:3888
server.2=10.17.162.230:2888:3888
server.3=10.17.162.231:2888:3888
# the maximum number of client connections.
# increase this if you need to handle more clients
#maxClientCnxns=60
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
#autopurge.purgeInterval=1
本文教程参考:kafka:https://blog.csdn.net/dapeng1995/article/details/81536862,
kafka-manage:https://www.cnblogs.com/frankdeng/p/9584870.html,
zookeeper:https://blog.csdn.net/weixin_41558061/article/details/80597174

 浙公网安备 33010602011771号
浙公网安备 33010602011771号