

CNN与视觉
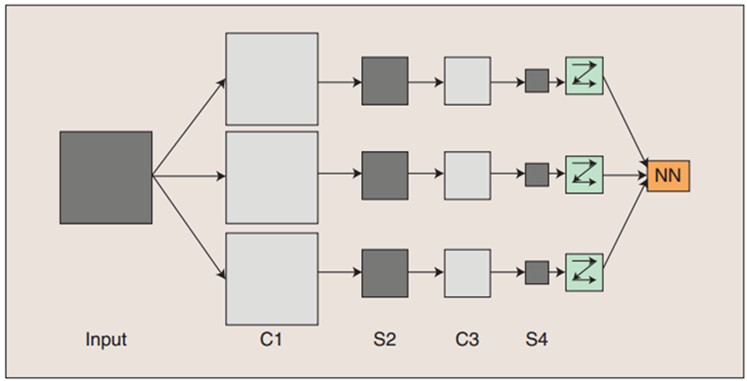
图片出至:https://blog.csdn.net/dcxhun3/article/details/46878999
cnn由三部分构成,卷积、激活、池化。(如同卷饼一样)
卷积:cnn中的基础操作,使用的是2d卷积。kernel只能在xy上滑动位移无法跨越通道。公式如下:
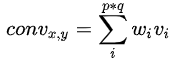
w为kernel权重v为像素亮度。说白了就是卷积核3*3对应原图像第一个3*3区块卷积就是对应位置相乘后总体加和。
5x5的图像不填充情况用3x3的核卷积,出来的结果是(5-3+1) 3x3的图像,我们暂时定义这个卷积后的图像大小为mxm。用脑子模拟一下。(把摸具按在面上,按一次拿起来往下按直到饼都被按了)
多个卷积核:使用多个同时扫描,特征图就会增加维度。
步长:步长如果是n,输出就是m/n。
padding:卷积后图像维度是缩减了,在图像周围填充0保证和原图大小一样。
激活:卷积后加入偏置b,并引入非线性激活函数(火烤)。
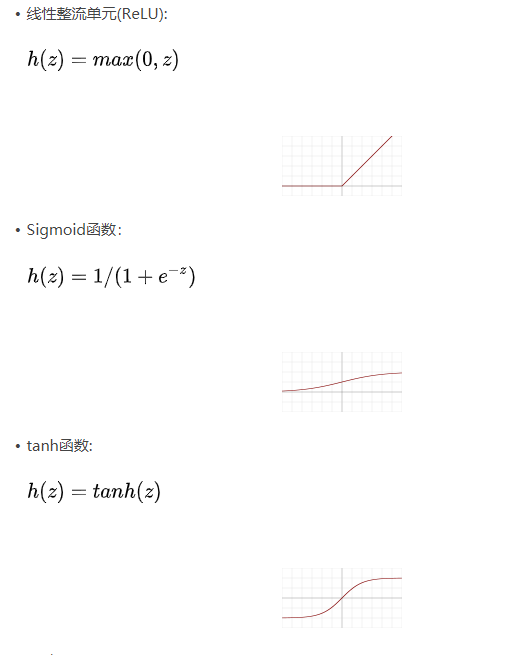
池化:是一种降采样操作,主要目标是降低feature map的特征空间,因为图像细节不利于高层特征的抽取。(涂酱料)
最大池化就是取最大值,l2池化取均方值,池化操作不是必须的,但是可以降低计算成本。
全连接:当用于分类的时候,最后一层需要增加一个全连接网络,输出的计算方式是:
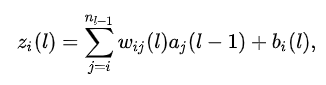
到这里位置,我们可以用一个做饼的过程来描述卷积的过程,首先我们要把面饼展开,用摸具在上面按出形状(卷积)。之后我们把饼用火烤,有些地方要火大一些有些地方要生一些,但是总体不能差太多(激活)。饼出来了我们不想让饼看着黑一块白一块就要网上刷酱料,让饼模糊起来。(池化)
之后要讲一下如何反向传播梯度,这里有个不错的博客可以参考:https://www.cnblogs.com/pinard/p/6422831.html
首先是DNN如何反向传播梯度:
我们前向传播已经会算了(不会的可以查一下),aL为前向传播L层的输出。那么损失就是:
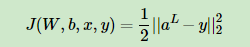
||s||2为s的L2范数,我们希望能最小化这个式子。
第L层有:
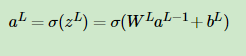
损失函数带入得到:
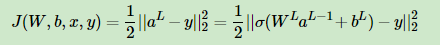
求解w,b的梯度值:
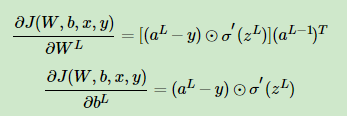
那个圈中一个点的是哈达玛积。
其中zl为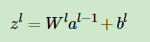
第l层的损失为:
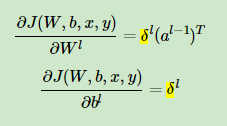
CNN的特点:通过感受野减少了神经网络巡的参数。
nn.Conv2d(in_channels=3,out_channels=96,kernel_size=11,stride=4,padding=2)
in_channels=3:表示的是输入的通道数
out_channels=96:表示的是输出的通道数
kernel_size=12:表示卷积核的大小是12x12的
stride=4:表示的是步长为4,
padding=2:表示的是填充值的大小为2,也就是上面的P, P=2
N=(W-F+2P)/S+1 N为输出大小 =( 输入大小-卷积核大小+2倍填充值大小)/ 步长 +1
这个可以这么理解,如一个5x5大小的输入,你用一个3x3的卷积核,那么输出3x3在上面框一圈,如果每次能走1也就能向右或者向下走个2步长。5-3+1 = 3 输出就是3x3.
这么走太简单了而且越走越小。所以我们还要加一个padding,
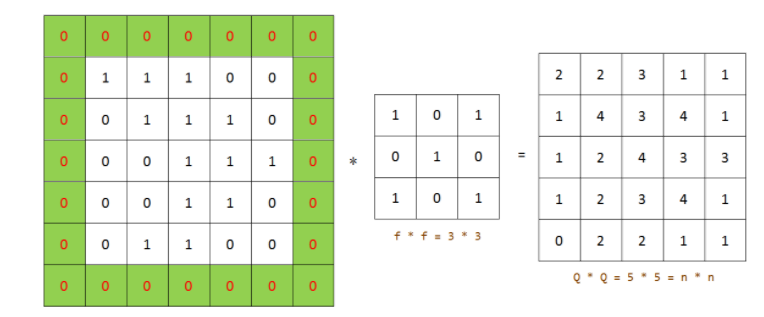
如果想要输入输出相同, padding = (过滤器-1)/2 所以过滤器多是奇数。
加上了stride,感受野一次要走stride步,计算起来就是上面的那个公式了。
输出大小 =( 输入大小-卷积核大小+2倍填充值大小)/ 步长 +1
输出大小 = 输入的大小,减去第一个卷积核的长度,加上填充值上下填充的长度,然后将这些除以步长。最后加上1是初始感受野位置的1.很清楚。
参考:https://zhuanlan.zhihu.com/p/62760780
我们从这个NetV1来进行具体分析一下:
ef NetV1(): state_shape, action_dim = [80, 80, 4], 2 actions = Input([action_dim]) state = Input(state_shape) x = Conv2D(32, kernel_size=8, strides=4, padding="same")(state) x = Activation("relu")(x) x = MaxPool2D(pool_size=2)(x) x = Conv2D(64, kernel_size=4, strides=2, padding="same")(x) #padding = x = Activation('relu')(x) x = Conv2D(64, kernel_size=3, strides=1, padding="same")(x) x = Activation('relu')(x) x = Flatten()(x) x = Dense(512)(x) x = Activation('relu')(x) out1 = Dense(action_dim)(x) out2 = Dot(-1)([actions, out1]) model = keras.Model([state, actions], out2) optimizer = keras.optimizers.Adam(1e-6) # optimizer = keras.optimizers.SGD(lr=1e-5, decay=1e-6, momentum=0.9, nesterov=True) loss = keras.losses.mse model.compile(optimizer=optimizer, loss=loss) model.summary() return model
padding="valid" 不进行填充,不满了就舍弃。
padding=“same” 用0进行填充
maxpool 最大池化层,压缩数据和参数的量,减小过拟合。默认应该都是2x2 步长为2 也就是压缩一半的大小。
dense 全连接层,参数为神经元节点数。
input 用来实例化一个keras张量
dot keras layer的dot ,用来
model.compile 告诉模型优化器和损失的评判标准
model.summary 输出模型的参数情况

 浙公网安备 33010602011771号
浙公网安备 33010602011771号