
强化学习相关
马尔可夫过程是研究离散事件动态系统状态空间的重要方法,它的数学基础是随机过程理论。
马尔可夫过程:https://zhuanlan.zhihu.com/p/22653871
维纳过程:独立增量的过程X(t),其增量的分布服从高斯分布。称为维纳过程。维纳过程是一种特殊的马尔可夫过程。
马尔可夫过程,简单说就是一个智能体(Agent)采取行动(Action)从而改变自己的状态(State)获得奖励(Reward)与环境(Environment)发生交互的循环过程。策略完全取决于当前状态。
马尔可夫问题的求解:目标是让当前的策略使得未来的回报最大化,求解过程分为“预测”和“行动”。我们可以用公式描述动作的价值,强化学习方法实质是研究贝尔曼方程的近似解。
研究一下flappybird的强化学习代码。
我们在研究代码之前需要搞清楚输入输出都是什么。
首先,强化学习有5个元素:环境,代理,状态,激励函数(reward),动作。
代理(智能体)(Agent):智能体的结构可以是一个神经网络,可以是一个简单的算法,智能体的输入通常是状态State,输出通常是策略Policy。
动作(Actions):动作空间。比如小人玩游戏,只有上下左右可移动,那Actions就是上、下、左、右。
状态(State):就是智能体的输入
奖励(Reward):进入某个状态时,能带来正奖励或者负奖励。
环境(Environment):接收action,返回state和reward。
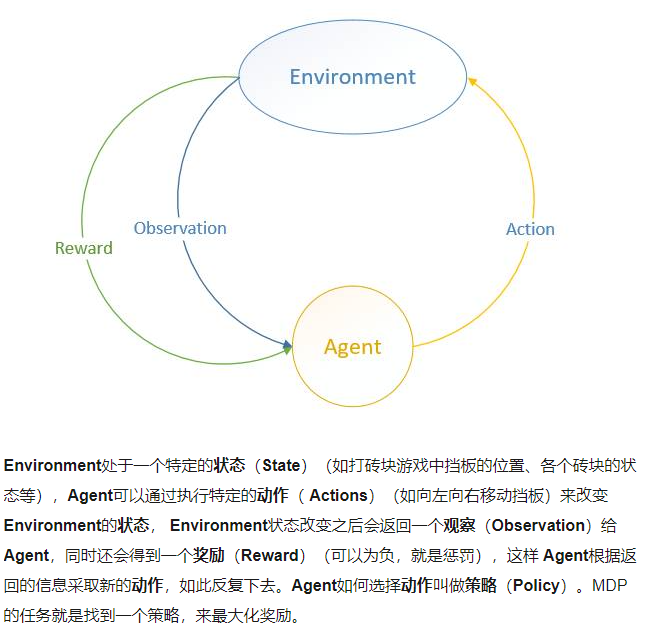
对于游戏来说
输入:一个action,决定小鸟上飞还是降落。 输出:State reward terminal,分别代表80x80x4帧的图像、(0.1,1,-1)之中的某一个值、0和-1代表是否游戏结束。
对于玩家这个智能体来说:
玩家是个神经网络,输入:训练数据state当前状态也是上个输出的第一项,这个训练数据的标签是y。
如果把游戏玩死了y就是当前的reward,如果游戏还在进行y就是现在reward加上下次的价值Q。
首先先安装环境,cv2(opencv2)这个没有安装,这里可以安装
https://www.lfd.uci.edu/~gohlke/pythonlibs/#opencv
下载好之后
pip install C:\Users\Administrator\Downloads\opencv_python-4.4.0-cp38-cp38-win_amd64.whl
numpy也没有?之前安装过啊,pycharm找不到。要在settings中设置project interpreter中将anaconda下的python选中才能读取anaconda的包。这里注意是anaconda下的python不是里面env一类文件夹的python。
pygame也没有,继续下载。pip直接下载不到,需要下载3.8版本(对应python的)离线包然后离线下载。
好了已经跑起来了,鸟可以自己在训练了。我们从代码的入口进行跟踪一遍。
if __name__ == '__main__': train()
走到train
def train(): net, call_function, count = get_net(net_version=0) agent = keras.backend.function(net.input[0], net.layers[-2].output) #实例化一个keras函数 产生动作的代理 data = GameMemory(agent, count, flag=FLAG) # flag in ["train", "explore", "display"] 训练过程随机动作较多 net.fit(data.next_data(), epochs=EPOCHS, initial_epoch=data.count, steps_per_epoch=STEPS_PER_EPOCH, callbacks=call_function)
代理产生动作,环境根据动作反馈该动作执行后的环境状态以及reward。这里设置飞过中心线的奖励是1,靠近中心线但是没碰到中心线是0.1。
我们拆解一下这几个模块看一下都是干什么的。首先看agent.py,第一个函数
def convert(img): img = cv2.cvtColor(cv2.resize(img, IMAGE_SHAPE), cv2.COLOR_BGR2GRAY) #这里指转换成灰度图片,IMAGE_SHAPE = (80, 80)
ret, img = cv2.threshold(img, 1, 255, cv2.THRESH_BINARY)
return np.array(img)
1.cv2.cvtColor(p1,p2) 是颜色空间转换函数,p1是需要转换的图片,p2是转换成何种格式。
2.cv2.resize(img, IMAGE_SHAPE) 将图片转换成宽/高为IMAGE_SHAPE.这里是80*80.
3.cv2.threshold (源图片, 阈值, 填充色, 阈值类型) 这个函数多用于二值化处理,即选取一个阈值然后变成非黑即白的图像。img为处理好的图像
最后将这个图像以数组形式返回。总而言之,这个convert的功能是将一个图片进行灰度、二值化的处理后返回。
Memory类
class Memory: def __init__(self): self.time_step = 4 self.max_length = 50000 self.head, self.next = self.time_step, 0 self.memory = np.empty(self.max_length, dtype=[("image", np.float, IMAGE_SHAPE), ("art", np.float, [4])]) def memory_append(self, image, art): self.memory["image"][self.next % self.max_length] = image self.memory["art"][self.next % self.max_length] = art self.next = self.next + 1 self.head += 1 if self.next > self.max_length else 0
np.empty 根据给的维度和类型创建一个空数组(实际不是空的还是有很小很小的值的)
类的功能是每4帧记录一下image和art。
GameMemory类,是上面Memory类的子类,explore应该代表探索次数,pre_step_epoch为每次训练的迭代次数。flag是训练过程的随机动作,["train", "explore", "display"] 中的一个。
这三个是什么东西?分别是对应开发探索和表演。
探索(exploration): 不去选择最优解,而是随机选择
开发(exploitation):选择最优解
马尔科夫决策: 马尔科夫决策过程指你接下来的所有状态和决策只取决于你当前的状态和决策。比如你下象棋,你走第四步时,影响你决策和接下来状态的只有第三步。
agent = keras.backend.function(net.input[0], net.layers[-2].output) agent就是func
count = get_net(net_version=0) count应该是某h5模型文件中的参数(?)
class GameMemory(Memory): def __init__(self, func, count, flag="explore"): self.count = count self.func = func self.flag = flag self.explore = 3000000 self.observer = 10000 self.image_shape = (80, 80) self.pre_step_epoch = 10000 super().__init__()
之后是GameMemory中的其他函数:
def show(self): for _ in self.next_data(): yield _
然后是里面最大的函数next_data 分成两段来解析
def next_data(self): # 参数设置 epsilon = 0.001 if self.flag in ["explore", "display"] else 0.1 #根据flag的模式选择epsilon参数 init_epsilon, final_epsilon = 0.1, 0.001 #初始epsilon和最终的epsilon的数目 action_dim = 2 # # 初始化 num = 40 if self.flag in ["explore", "train"] else 1 game = Game(num) # game为环境 #这里创建game对象 这里的num为fps action = np.array([1, 0]) image, reward, terminal = game.frame_step(action) #这个frame step用来返回当前的image reward和terminal 一会在下面展开 image = convert(image) #这里从image做一些基本处理 for _ in range(4): #记录4次 self.memory_append(image, [*action, reward, terminal]) epsilon -= (init_epsilon - final_epsilon) / self.explore * self.count * self.pre_step_epoch #埃普西隆衰减 epsilon = np.clip(epsilon, a_max=init_epsilon, a_min=final_epsilon) #np clip 将所有的数限定在max和min中
这里我们进入去看一下frame_step里面的内容:
def frame_step(self, actions): # pygame.event.pump() self.state[0] = self.player.y < 0 # 小鸟到达边缘游戏结束,state第一个标志位为游戏结束标志 state = self.control.notify(actions) # 根据动作更新state self.state = np.logical_or(self.state, state) #返回逻辑后的bool值 if state[1]: # state第二个标志位表示是否刷新新的管道 pipe = PipeElement(self.width + 10, offset=self.base.y) self.control.attach(pipe) reward = self.restart() if self.state[0] else 0.1 # 游戏输出状态,没有分数增加或者游戏未结束则未0.1 terminal = reward < 0 reward = max(reward, int(state[-1])) if not terminal else reward # state第三个标志位表示分数是否增加 self.draw() # 绘制游戏界面 self.display.update() self.clock.tick(self.fps) image_data = convert_data(self.display.get_surface()) return image_data, reward, int(terminal)
logical or返回逻辑后的布尔值,我们可能还是没有弄清楚这个state具体是什么样子的,其实它是在register返回定义的,register返回了一个control一个state,代码如下:
def register(self): """ 游戏各元素如何更新依赖Control类控制,游戏开始加入BASE, 两个PIPE,Player和计分板,后两个较特殊在构造时增加 state [False, False, False] 表示游戏没有结束,无新管道加入,分数没有增加 :return: """ control = Control(self.player, self.scoreboard) control.attach(self.base) pipe = PipeElement(self.width, offset=self.base.y) control.attach(pipe) pipe = PipeElement(self.width * 1.5, offset=self.base.y) control.attach(pipe) state = np.array([False, False, False]) # 状态,控制是否结束游戏,是否有新元素加入,分数 return control, state
可以看到state表示游戏是否结束、是否有新管道和分数是否增加。control的属性有玩家、计分板、观察帧数。
class Control:
def __init__(self, player, scoreboard):
self.player = player
self.scoreboard = scoreboard
self.max_observe = 4
self.observes = []
到这里为止control、state的内容已经清楚了,register函数用来返回这两个值也清楚了。之后我们回到上面那个frame_step的代码,有关于管道的信息:
if state[1]: # state第二个标志位表示是否刷新新的管道 pipe = PipeElement(self.width + 10, offset=self.base.y) self.control.attach(pipe)
这里我们正好延展看一下pipe里面是什么:
class PipeElement: def __init__(self, x, offset): self.down = Element("assets/sprites/pipe-green.png", x) #下面的图片和元素 offset_y = int(0.2*offset) + np.random.randint(2, 10) * 10 + 100 #设置y的高度 self.down.move(0, offset_y) #下面柱子进行移动 self.up = Element("assets/sprites/pipe-green.png", x, rotate=True) #上面的图片和元素 offset_y = offset_y - self.up.image.get_height() - 100 #同理 self.up.move(0, offset_y) self.speed = -4 #柱子移动的速度(因为是鸟不动柱子动) def update(self, player): #update 表示每次更新一下柱子信息包括 self.up.move(self.speed, 0) # 移动 #上下移动 self.down.move(self.speed, 0) detach = 0 < self.up.x < 5 # 是否到达左边界 #碰撞判定和得分判定 flag = check_crash(player, self.down) or check_crash(player, self.up) player_mid_pos = player.x + player.image.get_width()/2 #鸟的位置 pipe_mid_pos = self.up.x + self.up.image.get_width()/2 score = False if pipe_mid_pos <= player_mid_pos < pipe_mid_pos + 4: #只要不碰撞到pip则算存活 就得分 score = True return np.array([flag, detach, score]) #返回是【是否碰撞到了鸟、柱子是否要出左侧边界、是否通过】
这些是游戏的基本元素了。我们重新回到frame_step中去,就剩下这么几行代码了(代码来自framestep函数)
reward = self.restart() if self.state[0] else 0.1 # 游戏输出状态,没有分数增加或者游戏未结束则未0.1 terminal = reward < 0 reward = max(reward, int(state[-1])) if not terminal else reward # state第三个标志位表示分数是否增加 self.draw() # 绘制游戏界面 self.display.update() #将绘制的东西希纳是在屏幕上 self.clock.tick(self.fps) #控制帧率为fps image_data = convert_data(self.display.get_surface()) #获取当前显示的surface对象后进行图像处理,然后获得了image data return image_data, reward, int(terminal)
我们的目的是获得reward和terminal。可以看到reward的值为如果游戏结束了那么为restart的返回值,是-1.同时把所有元素进行重新初始化,否则化说明游戏正在继续,则为0.1
如果游戏重启了那么terminal就是true了,因为它代表了游戏是否结束。
reward返回的值就是分数是否增加,现在我们已经有了image_data, reward, int(terminal)。取int值后true会变成1,false则会变成0.
我们一路向上返回、封装起来,就返回到上面next_data函数中。next data函数前面已经给出了一半,下面是剩下一半的代码:
try: while True: # 获取动作 if random.random() < epsilon: #如果一个随机动作小于epsilon 重点!下面解释 action_ind = np.random.randint(0, action_dim) #产生一个随机动作 else: #根据经验产生一个“贪婪动作” idx = (self.next - np.arange(1, self.time_step+1)) % self.max_length state = self.memory["image"][idx] state = np.transpose(state[np.newaxis, :, :], [0, 2, 3, 1]) #transpose是转置 action_ind = self.func(state).argmax(-1).astype("int")[0] # 智能体产生动作 epsilon -= (init_epsilon - final_epsilon) / self.explore epsilon = np.clip(epsilon, a_max=init_epsilon, a_min=final_epsilon) count += 1 action = game.get_event(action_ind) # 游戏中事件触发 image, reward, terminal = game.frame_step(action) # 环境的激励 image = convert(image) # 80*80 self.memory_append(image, [*action, reward, terminal]) data = self.batch_data() if data is not None: yield data except GameOver: print("\n{}> game close <{}".format("="*10, "="*10))
这个随机的动作是为什么?
首先,当Q表或Q网络被随机初始化时,其预测最初也是随机的。如果我们选择具有最高Q值的动作,则该动作也将是随机的,这时 Agent执行的动作是随机的。随着Q函数的收敛,返回更一致的Q值,探索量将减少,此时这些一致的Q值叫做开发(Exploitation)。但是这些探索是“贪心”的,它发现第一个有效策略后停止收敛,很有可能我们只是找到了一个局部最优解。
对于上述问题,一个简单而有效的解决方案是 ε(epsilon)-greedy exploration —— 以概率 ε选择一个随机动作,否则选择具有最高Q值“贪婪”动作。DeepMind 实际上将 ε随时间从1减少到0.1,一 开始,系统完全随机移动,最大限度地探索状态空间,然后稳定的利用开发率。
argmax(-1) 这里:https://www.freesion.com/article/9764605635/
拿到了image(当前的图像)reward(当前的奖励)以及terminal(游戏是否终止)后将他们存入到memory中,data就是我们训练用的数据了,通过batch data函数抽取数据。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号