
一周一个中间件-kafka角色篇(节点数据如何同步)
前言
Apache Kafka 最早是由 LinkedIn 开源出来的分布式消息系统,现在是Apache旗下的一个子项目,并且已经成为开源领域应用最广泛的消息系统之一。尤其是做日志中间件。
- Kafka是一个分布式系统,
背景
我们公司迁移ActiveMQ消息中间件,为了减少资源开支,引入Kafka这种高性能高吞吐高并发的消息组件,相同的数据消息,kafka所需要的的资源开支更少,性能更高,减少公司的开支。
知识准备
- broker
即代表的一个kafka的server服务器。
- topic
kafka下的消息逻辑概念,可以看成众多的消息的集合。
- partition分区
一个topic先可以多个分区,不同的分区可以分别部署在broker中。
- Replica副本
同一个分区的不同副本保存相同的数据,副本之间是一主多从,Leader和Follower角色。Leader副本负责读写请求,Folower只与Leader副本消息同步。Leader副本出现故障后,则从Follower副本中选举Leader副本对外提供服务。可以通过提高副本数量,可以提高容灾能力。
- controller leader控制器组件
kafka的核心组件,由一个Broker担任,行使其管理和协调的职责。它的主要作用是在 Apache ZooKeeper 的帮助下管理和协调整个 Kafka 集群。(追踪集群中的其他Broker,处理新加入的和失败的Broker节点、Rebalance分区、分配新的分区leader,创建、删除主题的功能)
- partition leader
因为一个分区会有多个副本,所以要选举出来谁作为分区的leader来对外提供服务。
集群见的角色分配
controller leader选举
上面我们有讲到controller leader的作用,既然作用如何之大,所有的broker节点都想要去当,那么leader是如何选举出来呢,这里离不开zookeeper的作用,当kafka集群开始启动时,broker会尝试向zk创建临时节点 /controller,一旦创建成功,那么这个broker就会成功leader,其他的broker就会监听这个zk的临时节点,一旦这个节点被删除,就会尝试重新创建节点,来争抢leader角色。
同时为了防止发生脑裂的问题,比如当第一个leader出现网络波动,无法与zk链接,zk的临时节点就会消失,导致重新选举leader,但是第一个leader没有失望,也不知道自己已经丢失了leader的角色,集群中出现了二个leader在发号施令。kafka为了解决这种脑裂问题,在每次节点创建时都会增加epoch number数字,每次出现重新选举都会创建一个新的,递增的数字,当二个leader发号施令时,其他的broker节点知道当前最大的epoch number,就会忽略比他小的数字。
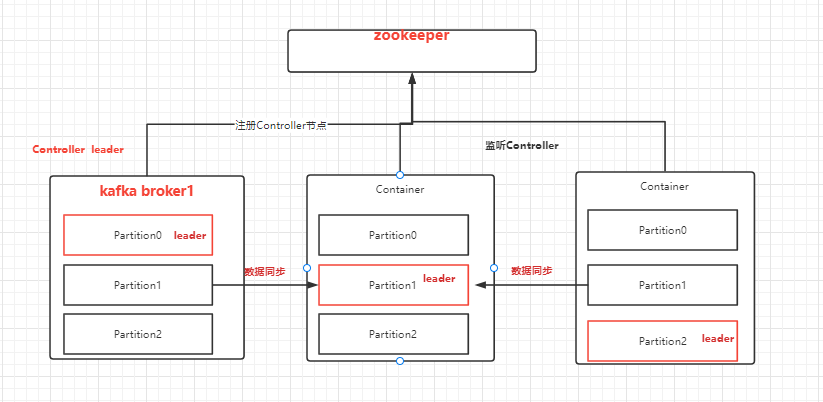
上面我们有讲到controller leader的作用,其中有一个很重要的作用就是为分区选举leader。
-
一旦有broker节点出现宕机,zk的元数据节点/Brokers/ids/下的临时节点就会被删除,zk的watch机制就会通知controller leader,他就会重新进行Rebalance分区.指定那个副本作为新的分区leader,然后通知其他副本去同步消息。
-
一旦有broker新节点出现,zk的元数据节点/Brokers/ids/下就会创建新的临时节点,zk的watch机制就会通知controller leader,他就会重新执行Rebalance分区,使leader和副本均匀分布在broker节点中,保障集群的负载均衡和集群的高可用。
当Controller监控到Broker加入,它将使用zk上的BrokerID来查看该Broker上是否存在分区,如果存在,新的Broker上面的follower分区同步现有leader分区的消息。为了保证负载均衡,Controller会将新加入的Broker上的follower分区选举为leader分区。如果没有就会触发分区leader重新选举,让分区leader均匀分布在broker中,因为客户端只和分区leader进行交互,leader均匀分布在broker中,可以达到集群的负载均衡。也会将副本尽量不和leader放置在同一个broker中,避免同时挂掉,提高集群的高可用性。
partition leader
上面有讲到partition分区的概念,这是kafka中一个消息组topic下分别设立多个分区,每个分区负责不同的数据,方便消息的水平扩展。只要的你的分片数量都多,理论上这个topic下的消息可以无限大。而且一个partition下会有多个相同的partition,来保证当前分区的数据不会丢失。但是到底哪个partition来负责与客户端进行交互呢?答案就是在众多partition中设立leader和follower角色。分区leader角色来与客户端进行交互数据,然后由follower副本来想leader同步消息数据。

在partition leader在与生产者进行交互时,会有一个疑问,是发送消息给leader成功,就ack返回成功?还是需要partition所有的节点全部数据同步了,才算ack返回成功?针对这种情况,kafka有一个ack设置参数,该参数分别对应-1 0 1.
- 0 时,当生产者发送消息给leader时,不管有没有接收到,直接默认ack成功。这种是效率最快,但是也是最不安全的,因为可能leader分区已经死亡,但是生产者不知情,可能会造成数据丢失。
- 1 (默认)时,生产者发送leader消息,确保leader成功保存改消息数据,但是不管follower分区有没有同步数据,直接返回成功,这种情况是比较高效和安全的。因为leader保存消息,follower分区会向其同步数据。但是如果出现这样情况,刚刚leader保存完数据,返回ack确认,leader分区就挂掉了,follower分区没有来得及同步数据,那么该消息数据就会丢失。
- -1 时,需要等到leader保存完数据,并且follower分区全部同步完数据,才返回ack确认,这种情况是最安全的,但是效率也是最低的。
有个问题,如果选择了-1,但是某一个follower分区有问题,一直无法同步成功,那么是不是生产者一直拿不到ack确认?那岂不造成生产事故?
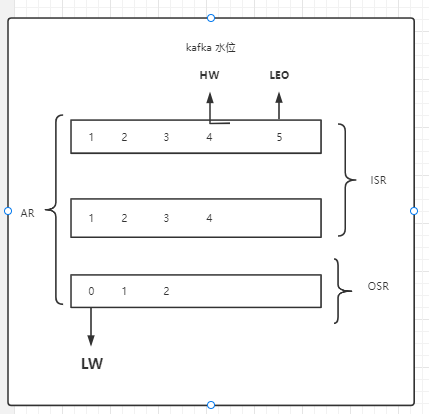
ISR、OSR、AR、LW、HW、LEO
* ISR (IN-SYNC replicas) 指符合副本的概念的follower分区
* OSR (OUT-SYNC replicas) 指不符合副本概念的follower分区
* AR = ISR + OSR 指所有存活的分区
* LW (LOW water) 低水位 指在AR broker节点中所有拥有的最小的logStartOffset值
* HW (High water) 高水位 指在AR节点中可以对外提供的offset。
* LEO (log end offset) 当前broker节点的最新的一个offset节点。
解决上诉的问题,需要大家熟悉上面几个专用名词ISR、OSR、AR、LW、HW、LEO。
副本与副本之间也不是完全一样,他们之间也是有阶级之间的区分,kafka需要识别出那些是有效地follower分区,那些是可能无效的follower分区。所以他创建的三个集合。以下的说话都是在某个partition概念下去阐述的。
AR集合是该分区所有存活的分区节点。以leader的数据作为标尺,如果其余副本与leader数据相差的offset在合理区间内,那么这个副本就是有效副本,因为我们会允许leader与follower之间存在一定的数据差距,因为总归是leader先保存完数据,follower才去pull数据,所以一定会存在数据差距。所以将这些数据作为ISR(IN-SYNC replicas)寓意在同步范围内的副本集合,但是如果有副本与leader的数据相差的offset超出的合理区间内,那么这个副本就是无效副本,就将这些副本归类于OSR(out-sync replicas)寓意不在同步范围内的副本集合。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号