今日内容概要
- GIL全局解释器锁
- 验证GIL的存在
- 死锁现象
- 进程池与线程池
- 协程
- IO模型
- 前端
- BS架构
- HTTP协议
GIL全局解释器锁
'''
1.python解释器有很多,比如Cpython,Jpython,pyputhon,默认使用的是Cpython
2.Cpython中GIL全局解释器也是一把互斥锁,用于阻止同一个进程下多个线程同时运行(python多线程无法使用多核优势)
3.GIL存在Cpython解释器中,原因在于Cpython解释器的内存管理不是线程安全的
4.内存管理 ---> 垃圾回收机制
引用计数,标记清除,分代回收
'''
特性:1.GIL是Cpython的
2.python同一个进程下多线程无法使用多核优势(不能并行但可以并发)
3.同一个进程内多个线程想要运行必须抢GIL锁
4.所有解释型语言几乎都无法实现同个进程下多个线程同时运行
验证GIL的存在
from threading import Thread
import time
m = 100
def index():
global m
num = m
# time.sleep(1)
num -= 1
m = num
for i in range(100):
t = Thread(target=index)
t.start()
time.sleep(3)
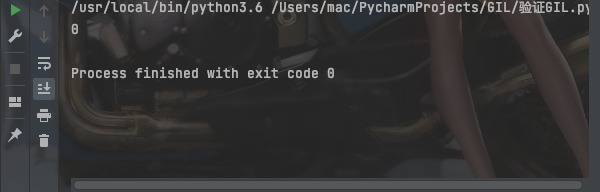
print(m)
'''
同个进程下多个线程虽然因为GIL的原因不会出现并行效果,但是如果线程内有IO操作还是会造成数据错乱,这个时候就需要额外添加互斥锁
'''
![image]()
死锁现象
from threading import Thread, Lock
import time
import os
print(os.cpu_count()) # 查看本机可使用内核数
a = Lock()
b = Lock()
class MyClass(Thread):
def run(self):
self.index()
self.rain()
def index(self):
a.acquire()
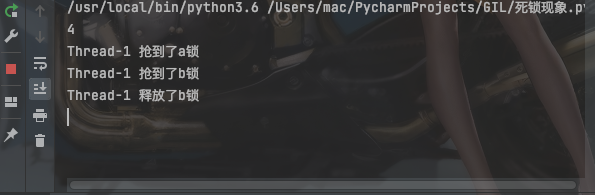
print('%s 抢到了a锁' % self.name) # 相当于线程名称
b.acquire()
print('%s 抢到了b锁' % self.name)
time.sleep(1)
b.release()
print('%s 释放了b锁' % self.name)
a.acquire()
print('%s 释放了a锁' % self.name)
def rain(self):
b.acquire()
print('%s 抢到了b锁' % self.name)
a.acquire()
print('%s 抢到了a锁' % self.name)
a.acquire()
print('%s 释放了a锁' % self.name)
b.release()
print('%s 释放了b锁' % self.name)
for i in range(10):
obj = MyClass()
obj.start()
'''锁不能轻易使用,容易产生死锁现象'''
![image]()
进程池与线程池
进程池:提前开设了固定个数的进程,之后反复调用这些进程完成工作(后续不再开设新的)
线程池:提前开设了固定个数的线程,之后反复调用这些线程完成工作(后续不再开设新的)
在保证计算机硬件不崩溃的前提下开设多进程和多线程,降低程序的运行效率,保证计算机硬件安全
进程池线程池基本使用
from concurrent.futures import ProcessPoolExecutor, ThreadPoolExecutor
import time
import os
# 创建进程池与线程池
# pool = ThreadPoolExecutor(5) # 可以自定义线程数 也可以使用默认
pool = ProcessPoolExecutor(5)
# 定义一个任务
def index(n):
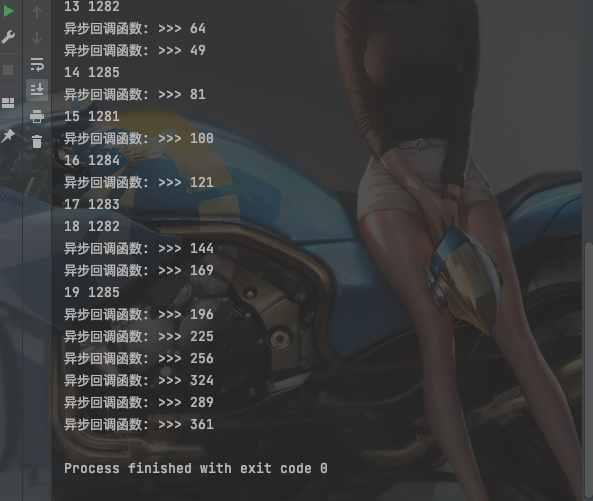
print(n, os.getpid())
time.sleep(1)
return '>>> %s' % n ** 2
# 定义一个异步回调函数:异步提交完有结果自动调用该函数
def call_back(a):
print('异步回调函数: %s' % a.result())
# 朝线程中提交任务
l_list = []
for i in range(20):
res = pool.submit(index, i).add_done_callback(call_back) # 异步提交
# print(res.result()) # 获取任务的执行结果 同步提交
# l_list.append(res)
# pool.shutdown() # 等待线程池中所有的任务执行完毕 获取各自任务结果
# for i in l_list:
# print(i.result()) # 获取任务执行的结果 同步
![image]()
协程
进程:资源单位
线程:工作单位
线程:程序员单方面意淫出来的 ---> 单线程下实现并发
CPU被剥夺的条件:1.程序长时间占用
2. 程序进入IO操作
欺骗CPU行为:单线程下我们如果能够自己检测IO操作并且自己实现代码层面的切换,那么
对于CPU而言我们这个程序就没有IO操作,CPU会尽可能的被占用
第三方gevent模块:能够自主监测IO行为并切换
from gevent import monkey;monkey.patch_all() # 固定代码格式加上之后才能检测所有的IO行为
from gevent import spawn
import time
def play(name):
print('%s play 1' % name)
time.sleep(5)
print('%s play 2' % name)
def eat(name):
print('%s eat 1' % name)
time.sleep(3)
print('%s eat 2' % name)
start = time.time()
# play('jason') # 正常的同步调用
# eat('jason') # 正常的同步调用
g1 = spawn(play, 'jason') # 异步提交
g2 = spawn(eat, 'jason') # 异步提交
g1.join()
g2.join() # 等待被监测的任务运行完毕
print('主', time.time() - start) # 单线程下实现并发,提升效率
IO模型
IO模型主要基于网络IO(linux系统)
基本关键字:同步(synchronous)
异步(asynchronous)
阻塞(blocking)
非阻塞(non-blocking)
研究方向:blocking IO 阻塞IO
nonblocking IO 非阻塞IO
IO multiplexing IO多路复用
signal driven IO 信号驱动IO
asynchronous IO 异步IO
由于signal driven IO(信号驱动IO)在实际中并不常用,所以主要介绍其余四种IO Model
四种IO模型简介
1.阻塞IO
最为常见的一种IO模型 有两个等待的阶段(wait for data、copy data)
2.非阻塞IO
系统调用阶段变为了非阻塞(轮训),有一个等待的阶段(copy data)
轮训的阶段是比较消耗资源的
3.多路复用IO
利用select或者epoll来监管多个程序,一旦某个程序需要的数据存在于内存中了 那么立刻通知该程序去取即可
4.异步IO
只需要发起一次系统调用,之后无需频繁发送,有结果并准备好之后会通过异步回调机制反馈给调用者
前端
前端:任何于操作系统打交道的界面称为前端
后端:不直接于用户打交道,而是控制核心逻辑的运行,各种编程语言编写的代码
前端三剑客:HTML 网页的骨架
CSS 网页的样式
JS 网页的动态效果
BS架构
在编写TCP服务端时候,针对客户选择可以子写客户端代码,也可以是浏览器当客户端(bs架构本质也是cs架构)
自己编写的服务端发送的数据浏览器不识别,原因是每个人服务端数据格式千差万别,浏览器无法自动识别,没有按照浏览器固定的格式发送
'''
浏览器可以访问很多服务端,如何做到无障碍与这么多不同程序员开发的软件实现数据交互
1.浏览器自身功能强大 自动识别并切换(太过消耗资源)
2.大家统一一个与浏览器交互的数据方式(统一思想)
'''
HTTP协议
协议:大家商量好一个共同认可的结果
HTTP协议:规定了浏览器与服务端之间数据交互方式及其他事项,如果我们开发的时候不遵循
该协议,那么浏览器就无法识别我们的网站,网站就需要自己编写一个客户端
四大特性:1.基于请求响应
服务端永远不会主动给客户端发消息,必须是客户端先发请求
如果想让服务端主动给客户端发送消息可以采用其他网络协议
2.基于TCP、IP作用于应用层之上的协议
应用层(HTTP),传输层,网络层,数据链路层,物理链接层
3.无状态
不保存客户端的状态信息
4.无连接/短连接
两者请求响应之后立刻断绝关系
数据格式:1.请求格式
请求首行(网络请求的方法)
请求头(一堆k:v键值对)
(换行符 不能省略)
请求体(并不是所有的请求方法都有)
2.响应格式
响应首行(响应状态码)
响应头(一堆k:v键值对)
(换行符 不能省略)
响应体(即将交给浏览器的数据)
相应状态码:用数字来表示一串中文意思
1XX:服务端已经接受到了数据正在处理 你可以继续发送数据也可以等待
2XX:200 OK请求成功 服务端返回了相应的数据
3XX:重定向(原本想访问A页面 但是自动跳转到了B页面)
4XX:403没有权限访问 404请求资源不存在
5XX:服务器内部错误
'''公司还会自定义状态码,一般以10000开头'''
HTML前戏
import socket
server = socket.socket()
server.bind(('127.0.0.1', 8081))
server.listen()
while True:
sock, addr = server.accept()
while True:
data = sock.recv(1024)
if len(data) == 0:
continue
print(data)
# 遵循HTTP相应格式
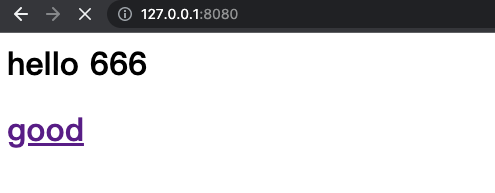
sock.send(b'HTTP/1.1 200 OK\r\n\r\n')
sock.send(b'<h1>hello 666<h1>')
sock.send(b'<a href="https://www.jd.com">good<a>')
# with open(r'data.txt', 'rb') as f:
# data = f.read()
# sock.send(data)
![image]()
![image]()


 浙公网安备 33010602011771号
浙公网安备 33010602011771号