


JBoltAI 的 AI 识图能力解析:视觉模型的工程化应用实践
JBoltAI 的 AI 识图能力解析:视觉模型的工程化应用实践
一、技术定位:视觉理解能力的工程化封装
JBoltAI 的 AI 识图能力是对 AI 视觉模型核心能力的系统性封装,聚焦于解决图像内容的语义解析与结构化处理需求。其技术本质是通过计算机视觉算法(如 CNN、Transformer 架构模型)对图像像素信息进行特征提取,结合深度学习训练形成的视觉理解能力,实现从像素到语义的跨层级映射。该能力并非单一模型的独立应用,而是整合了目标检测、光学字符识别(OCR)、图像分割、语义分析等多模块技术的综合解决方案。
二、核心功能:多模态视觉信息的解析与交互
- 基础视觉识别能力
可精准识别图像中的常见物体(如自然景物、交通工具、生活用品等),通过预训练模型对万级类别物体进行分类,支持自定义数据集的迁移学习。例如,在工业质检场景中可识别零部件缺陷,在安防场景中可识别违禁物品。
同时,具备文本与图表分析能力,可处理印刷体、手写体文本(支持多语言混合场景),解析图表类型(折线图、柱状图等)并提取趋势数据,还原文档布局结构(如段落层级、表格行列)。 - 视觉代理与工具协同
作为 "视觉代理",该能力可通过预设规则或实时推理,动态调用外部工具完成复杂任务。例如,在识别到图像中的数学公式后,自动触发计算器工具完成运算;检测到发票图像时,联动财税系统进行数据核验。这种 "识别 - 推理 - 执行" 的闭环机制,使其成为连接视觉感知与业务流程的关键枢纽。
三、技术特性:精准定位与结构化输出
- 空间定位技术
支持生成物体边界框(Bounding Box)、关键点坐标(如人体姿态节点、机械部件基准点)。通过锚框回归算法与非极大值抑制(NMS)技术,可在复杂场景中分离重叠物体,实现多目标同时定位。 - 结构化数据生成
针对扫描数据(如发票、表格、档案),可输出 JSON/XML 格式的结构化数据,包含字段名称、坐标位置、置信度等元信息。以发票处理为例,可自动提取发票号码、金额、日期、购销方信息等字段,并按业务规则生成标准化数据结构,减少人工录入误差。
四、实战案例:从技术演示到场景落地
视频通过三组代码演示展现技术落地能力:
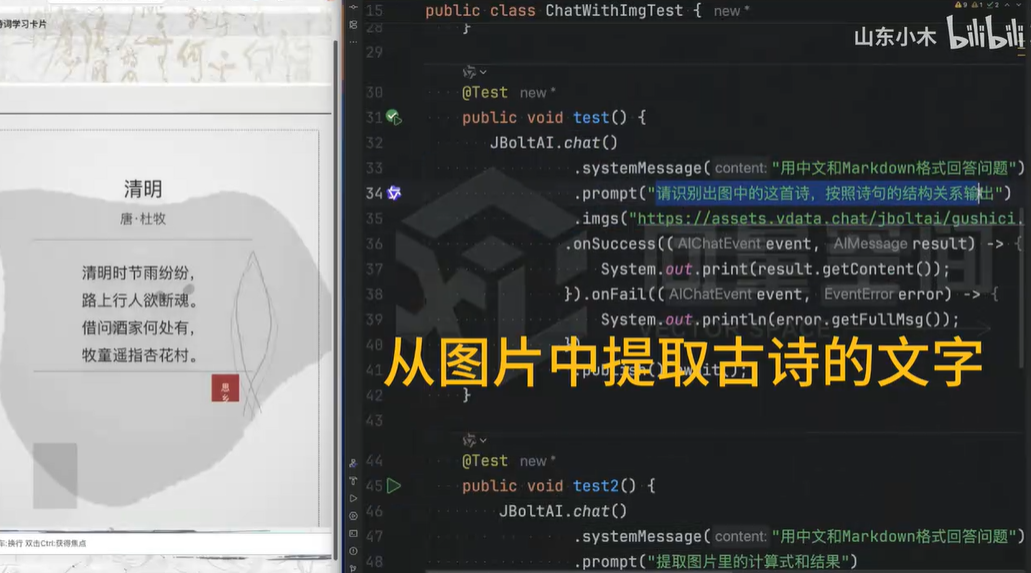
- 古诗文字提取
输入古籍书页图像,通过 OCR 技术识别繁体汉字,结合自然语言处理(NLP)模块校正识别误差,最终输出带标点的文本内容。该功能可应用于古籍数字化、手写笔记电子化等场景,降低文字转录成本。
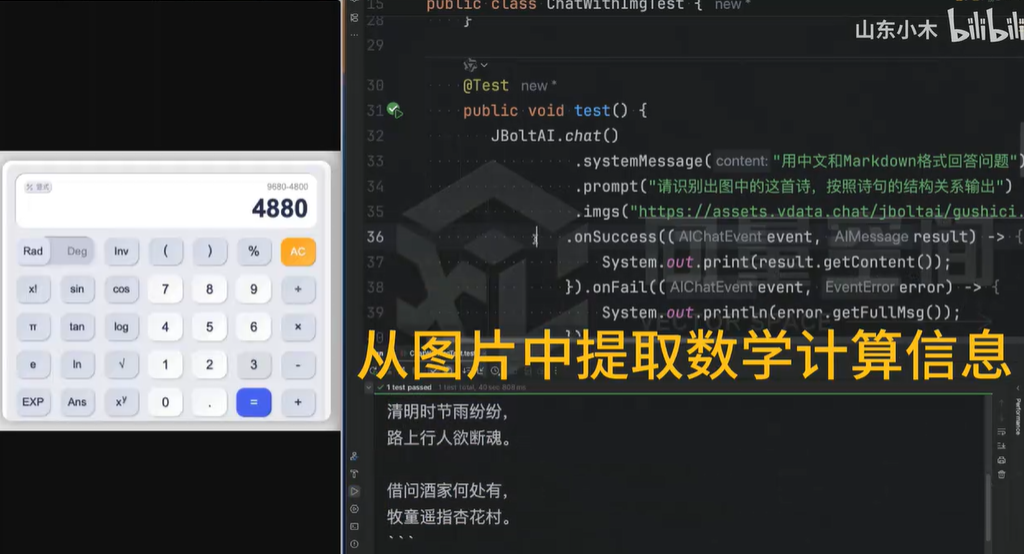
- 数学计算信息解析
识别包含数学算式的图片(如试卷、报表),提取数字与运算符并生成计算表达式,同时统计物体种类数量(如图片中不同形状的几何图形计数)。该能力可辅助教育领域自动批改作业,或在零售场景中统计货架商品品类。
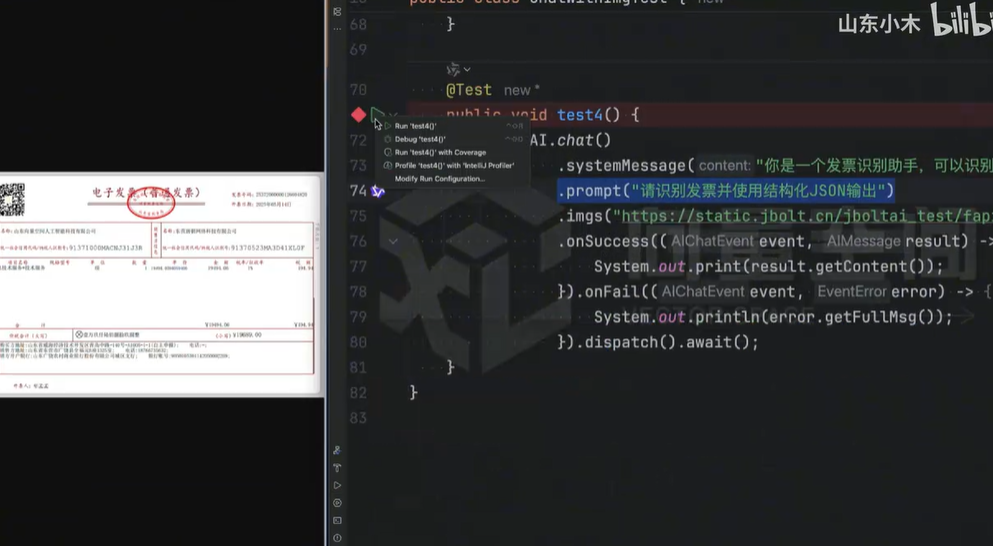
- 发票结构化处理
针对增值税发票扫描件,通过版面分析定位字段区域,结合模板匹配与深度学习模型识别具体内容,输出包含发票要素的结构化数据。该方案可接入企业财务系统,实现报销流程自动化,提升票据处理效率。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号