python常用模块
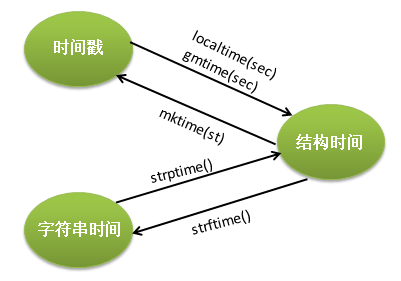
1.time
import time # 导入time模块
1) time()
获取当前时间的时间戳
tmp = time.time() print(tmp) # 1531456199.5435042
2) localtime()/gmtime()
本地时间(东八区)/GMT时间
获取当前时间的struct_time格式时间
time.localtime(sec)
tmp = time.localtime() print(type(tmp)) # <class 'time.struct_time'> print(tmp) # time.struct_time(tm_year=2018, tm_mon=7, tm_mday=13, tm_hour=12, tm_min=45, tm_sec=38, tm_wday=4, tm_yday=194, tm_isdst=0)
struct_time中的数据依次是:年、月、日、时、分钟、秒、周几、一年中的第几天、是否是夏令时(0:是,1:不是)
3)strftime()
struct_time转化为字符串,
time.strftime(format,[struct_time|tuple])
tmp = time.localtime() # struct_time print(time.strftime('%Y-%m-%d %H:%M:%S',tmp)) # 2018-07-13 13:03:53 tmp=(2018,7,13,12,30,51,4,194,0) # tuple print(time.strftime('%Y-%m-%d %H:%M:%S',tmp)) # 2018-07-13 12:30:51
4) strptime()
字符串格式转换为struct_time
time.strptime(str,format)
tmp = time.strptime('2018-06-06 18:01:02', '%Y-%m-%d %H:%M:%S') print(tmp) # time.struct_time(tm_year=2018, tm_mon=6, tm_mday=6, tm_hour=18, tm_min=1, tm_sec=2, tm_wday=2, tm_yday=157, tm_isdst=-1)
5) mktime()
将struct_time转换为时间戳
time.mktime(struct_time)
tmp = time.strptime('2018-06-06 18:01:02', '%Y-%m-%d %H:%M:%S') a = time.mktime(tmp) print(a) # 1528279262.0 a = time.mktime(time.localtime()) print(a) # 1531461481.0
2.random
import random #加载random模块
1) ramdom()
生成(0-1)中的随机数
tmp = random.random() print(tmp) # 0.8526857923098596
2)randint(m,n)
生成[m-n]中的随机数
tmp = random.randint(1,10) print(tmp) # 10
3)randrange(m[,n])
生成[m,n)中的随机数
tmp = random.randrange(2) print(tmp) # 0,1 tmp = random.randrange(0,2) print(tmp) # 0,1
4)shuffle(list)
将列表中的元素随机输出
list1 = [1,2,3,4] random.shuffle(list1) print(list1) # [4, 2, 3, 1]
5)choice([str|list])
随机生成 字符串/列表 中的单个 字符/元素
# 随机生成字符串中的单个字符 tmp = random.choice('hello') print(tmp) # 'h' ,'e',... # 随机生成列表中的元素 tmp = random.choice(['123','a','c']) print(tmp) # '123','a' ...
随机生成5个字符,包括数字,大写字母,小写字母


def ram_num(): code='' for i in range(5): add=str(random.choice([chr(random.randrange(97,123)),random.randrange(10),chr(random.randrange(65,91))])) code+=add print(code) ram_num() # Xaw6l,31dy9,r4sLw
#!/bin/env python import random import string def ram_num(): code = '' for i in range(5): add = random.choice(string.digits+string.ascii_letters) code += add print(code) ram_num()
3.os
os.getcwd() # 获取当前工作目录,即当前python脚本工作的目录路径 os.chdir("dirname") # 改变当前脚本工作目录;相当于shell下cd os.curdir # 返回当前目录字符串名: ('.') os.pardir # 获取当前目录的父目录字符串名:('..') os.makedirs('dirname1/dirname2') #可生成多层递归目录 os.removedirs('dirname1') # 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推 os.mkdir('dirname') # 生成单级目录;相当于shell中mkdir dirname os.rmdir('dirname') # 删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname os.listdir('dirname') # 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印 f = open('pathtofile','a') #windows 下创建文件 os.mknod("pathtofile") # linux下创建文件 os.remove() # 删除一个文件 os.rename("oldname","newname") # 重命名文件/目录 os.stat('path/filename') # 获取文件/目录信息 info=os.stat('testfile.txt') print(info) # os.stat_result(st_mode=33206, st_ino=44191571343580618, st_dev=1350904164, st_nlink=1, st_uid=0, st_gid=0, st_size=9, st_atime=1531467733, st_mtime=1531467733, st_ctime=1531467733) atime=info.st_atime os.sep 输出操作系统特定的路径分隔符,win下为"\",Linux下为"/" sw=os.sep print('E:%skk%sstudy1' %(sw,sw)) os.linesep 输出当前平台使用的行终止符,win下为"\t\n",Linux下为"\n" os.pathsep 输出用于分割文件路径的字符串 print(os.pathsep) # ; os.name 输出字符串指示当前使用平台。win->'nt'; Linux->'posix' print(os.name) # nt os.system("bash command") 运行shell命令,直接显示 os.environ 获取系统环境变量 os.path.abspath('相对路径') print(os.path.abspath('./baozi.py')) os.path.dirname('文件路径名称') print(os.path.dirname(r'E:\kk\study1\baozi.py')) os.path.join('path1',"path2","path3") # 执行结果path1\path2\path3 print(os.path.join("E:\home", "me", "mywork")) # E:\home\me\mywork
>>> os.listdir('/tmp/walker')
['c', 'f3', 'a', 'b', 'f2', 'f1']
>>> for dir_path,dirs,files in os.walk('/tmp/walker'):
... for file_names in files:
... file_names
...
'f3'
'f2'
'f1'
>>> for dir_path,dirs,files in os.walk('/tmp/walker'):
... for dir_names in dirs:
... dir_names
...
'c'
'a'
'b'
4.sys
sys.platform # linux2,win32 sys.path # 返回模块的搜索路径 sys.argv[1:2] # argv[0]是脚本名称,argv[1]是第一个参数,argv[1:2]是1-2
#!/bin/env python import sys length = len(sys.argv) if length != 3: print("Usage: %s first_name last_name" %sys.argv[0]) else: fname = sys.argv[1] lname = sys.argv[2] fullname = fname + lname print('你的全名是:%s' %fullname) print(sys.argv) # ['test5.py', 'slito', 'bo'] # python test5.py slito bo
5.logging
log模块级别由高到低依次为: critical -> error -> warning -> info -> debug,默认是warnning,warnning级别以下不显示信息。
logging.debug("debug message") logging.info("info message") logging.warning("warnning message") logging.error("error message") logging.critical("critical message") ''' WARNING:root:warnning message ERROR:root:error message CRITICAL:root:critical message '''
1.设置logging.basicConfig后,可以自定义日志输出级别,日志格式,日志输出目的
logging.basicConfig(level=logging.DEBUG, format='%(asctime)s %(filename)s[line:%(lineno)d] %(levelname)s %(message)s', datefmt='%a,%d %b %Y %H:%M:%S', filename='test0713.log', filemode='a' ) logging.debug("debug message1") logging.info("info message1") logging.warning("warnning message1") logging.error("error message1") logging.critical("critical message1")
查看test0713.log内容:
Fri,13 Jul 2018 17:05:06 other.py[line:10] DEBUG debug message1 Fri,13 Jul 2018 17:05:06 other.py[line:11] INFO info message1 Fri,13 Jul 2018 17:05:06 other.py[line:12] WARNING warnning message1 Fri,13 Jul 2018 17:05:06 other.py[line:13] ERROR error message1 Fri,13 Jul 2018 17:05:06 other.py[line:14] CRITICAL critical message1
level:设置rootlogger 的日志级别
format:指定handler使用的日志显示格式。
datefmt:指定日期时间格式。
filename:日志会被存储在指定的文件中。
filemode:文件打开方式,在指定了filename时使用这个参数,默认值为“a”还可指定为“w”。
format参数中可能用到的格式化串:
%(name)s Logger的名字
%(levelno)s 数字形式的日志级别
%(levelname)s 文本形式的日志级别
%(pathname)s 调用日志输出函数的模块的完整路径名,可能没有
%(filename)s 调用日志输出函数的模块的文件名
%(module)s 调用日志输出函数的模块名
%(funcName)s 调用日志输出函数的函数名
%(lineno)d 调用日志输出函数的语句所在的代码行
%(created)f 当前时间,用UNIX标准的表示时间的浮 点数表示
%(relativeCreated)d 输出日志信息时的,自Logger创建以 来的毫秒数
%(asctime)s 字符串形式的当前时间。默认格式是 “2003-07-08 16:49:45,896”。逗号后面的是毫秒
%(thread)d 线程ID。可能没有
%(threadName)s 线程名。可能没有
%(process)d 进程ID。可能没有
%(message)s用户输出的消息
2.创建格式化后的logging模块,返回一个logger。使用logger生成日志信息。
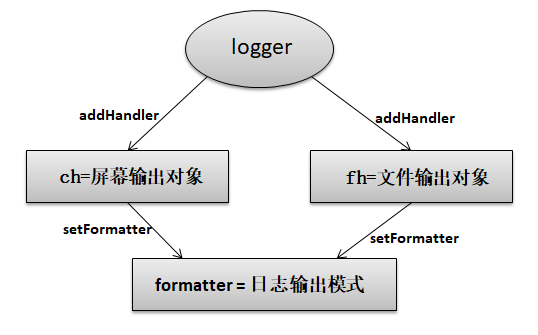
def logger(log_type): #创建logger对象及日志级别 logger = logging.getLogger(log_type) logger.setLevel(setting.LOG_LEVEL) #创建终端输出及日志级别 ch = logging.StreamHandler() ch.setLevel(setting.LOG_LEVEL) #创建文件对象和日志级别 log_file = "%s/log/%s" %(setting.BASE_DIR,setting.LOG_TYPES[log_type]) fh = logging.FileHandler(log_file) fh.setLevel(setting.LOG_LEVEL) #创建日志格式 formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s') #给ch和fh设置日志格式 ch.setFormatter(formatter) fh.setFormatter(formatter) #添加ch和fh logger.addHandler(ch) logger.addHandler(fh) return logger # logger函数目的是定义一个logger对象,这个对象可以打印相关信息 # a=logger('transaction') # a.info('test file')
6.configparser
1).生成配置文件
import configparser config=configparser.ConfigParser() # 第一种赋值 config['DEFAULT'] = { 'Name':'zhangbo', 'id':'2' } # 第二种赋值 config['ller']={} config['ller']['nb'] = 'yes' # 第三种赋值 config['slito'] = {} slitobo = config['slito'] slitobo['next'] = 'ok' # 写入文件 with open('example.ini','w') as f: config.write(f)
执行结果
[DEFAULT] name = zhangbo id = 2 [ller] nb = yes [slito] next = ok
2).读取配置文件
import configparser config=configparser.ConfigParser() config.read('example.ini',encoding='utf-8')
3).打印内容
print(config.sections()) #['ller', 'slito'] 默认不输出'DEFAULT' print(config.default_section) # DEFAULT for key in config['ller']: print(key) #连带打印DEFAULT的字段
4).删除section
config.remove_section('ller') # 删除 config.write(open('example.ini','w')) # 保存
5).查找section
print(config.has_section('ller')) # False print(config.has_section('slito')) # True
6).修改section中的内容
config.set('slito','next','NG') config.write(open('example.ini','w')) # 文件中显示 [slito] next = NG
7.hashlib
将任意长度的明文加密,输出特定字符长度的密文。用于数据保护,如密码。
hashlib中主要提供 SHA1, SHA224, SHA256, SHA384, SHA512 ,MD5 算法
常用的MD5生成32位,SHA256生成64位
import hashlib # 生成md5hash对象 m = hashlib.md5() # 将任意字符生成32为固定长度密文 m.update('hello world'.encode('utf8')) # 打印 print(m.hexdigest()) # 5eb63bbbe01eeed093cb22bb8f5acdc3
8.正则re
正则的应用可以写一个简单的计算器,参考https://www.cnblogs.com/slitobo/articles/9187003.html
1)re.match(patten,str,flag)
从字符串的起始位置匹配一个字符串,没有匹配返回None.括号内的参数为。
patten:匹配模式
str:匹配的字符串
标志位:用于匹配模式的方式,如忽略大小写等。
str = "Slitobo is here" patten = 'is' print(re.match(patten,str)) # None patten = '^s\w+' print(re.match(patten,str,re.I).group()) # Slitobo
# 原字符串 str = "Slitobo is here" # 匹配模式 patten = '(s\w+)\s(\w+s)\s(\w+)' # 返回一个类 <class '_sre.SRE_Match'> print(re.match(patten,str,re.I)) # <_sre.SRE_Match object; span=(0, 15), match='slitobo is here'> # .span()获取下标 print(re.match(patten,str,re.I).span()) #(0, 15) # 打印匹配到的字符串 print(re.match(patten,str,re.I).group()) # slitobo is here # 打印匹配到的第1/2/3个元素,以括号来区分元素位置 print(re.match(patten,str,re.I).group(1)) # slitobo print(re.match(patten,str,re.I).group(2)) # is print(re.match(patten,str,re.I).group(3)) # here # 输出匹配到元素的元组 print(type(re.match(patten,str,re.I).groups())) #<class 'tuple'> print(re.match(patten,str,re.I).groups()) # ('slitobo', 'is', 'here')
2)re.search(patten,str,flag)
扫描整个字符串,返回匹配成功的第一个字符串。找不到返回None.
str = "Slitobo is here is" print(re.search('is',str).group()) # is print(re.search('is',str).span()) # (8, 10) print(re.search('who',str)) #None
3) re.sub(patten,repl,str,count=0)
patten:匹配模式
repl:替换的字符串,可以是函数(替换函数没有实现)
str:要替换的原字符串
count:默认是0,匹配到的全部替换。1表示只替换匹配到的第一个。
str = "Slitobo is here is" ret = re.sub('e','E',str,count=0) print(ret) # Slitobo is hErE is ret1 = re.sub('e','E',str,count=1) print(ret1) # Slitobo is hEre is
4)re.compile(patten,flag)
编译正则表达式,将正则表达式生成一个对象。
# 生成一个patten 对象,用于匹配多个数字 patten = re.compile('\d+') m = patten.match('hello365python') print(m) # None # 从下标5-10开始匹配 m = patten.match('hello365python',5,10) print(m.group()) # 365 #匹配到的开始下标 print(m.start()) # 5 #匹配到的结束下标 print(m.end()) # 8 #匹配到的整个下标 print(m.span()) #(5,8)
patten = re.compile('(\w+)\s(\w+)') m = patten.match('hello python here') print(m.group()) # hello python print(m.span()) # (0, 12) print(m.group(1)) # hello print(m.span(1)) # (0, 5) print(m.group(2)) # python print(m.span(2)) # (6, 12) print(m.groups()) # ('hello', 'python')
5)re.findall(pattern,str,flag)
在字符串中查找所有匹配到的字符串,返回一个列表,没有好到返回空列表。
patten = re.compile('\d+') ret1 = patten.findall('123 python 987 hello') ret2 = patten.findall('run88oob123google456', 0, 10) ret3 = patten.findall('hello python') print(ret1) # ['123', '987'] print(ret2) # ['88', '12'] print(ret3) # []
6)re.finditer(patten,str,flag)
和findall相同,将结果作为一个迭代器返回。
patten = re.compile('\d+') ret1 = patten.finditer('123 python 987 hello') for i in ret1: print(i.group()) # 123 , 987
7)re.split(pattern,str,maxsplit=0,flag)
按照匹配模式进行区分,返回一个列表。
maxsplit=0,默认值,不限制分割次数。maxsplit=1,只分割一次。
str = 'hello,world,iam,here' ret1 = re.split(',',str) ret2 = re.split(',',str,maxsplit=1) a,b,c,d=re.split(',',str) # 用一个参数接受,返回一个列表 print(ret1) # ['hello', 'world', 'iam', 'here'] # maxsplit=1,只进行一次分割 print(ret2) # ['hello', 'world,iam,here'] # 用多个参数接收,返回字符串 print(a,b,c,d) # hello world iam here
7)正则表达式标志位flag
7-1) re.I或者(?i)
忽略匹配中的大小写
ret1 = re.findall('(?i)yes','yes? Yes. YES!!') ret2 = re.findall('yes','yes? Yes. YES!!',re.I) print(ret1) # ['yes', 'Yes', 'YES'] print(ret2) # ['yes', 'Yes', 'YES']
7-2)re.M或者(?m)
多行匹配,每行作为一个对象。
ret1 = re.findall('(?im)(^th[\w ]+)',''' This line is the first anothor line that line,it is test ''') ret2 = re.findall('(^th[\w ]+)',''' This line is the first anothor line that line,it is test ''',re.I|re.M) print(ret1) # ['This line is the first', 'that line'] print(ret2) # ['This line is the first', 'that line']
7-3)re.X或者(?x)
抑制正则表达式中使用空白字符,可以使用#进行注释,简明扼要的正则表达式。
ret = re.search('''(?x) \((\d{3})\) # 区号 [ ] # 空白字符 (\d{3}) - # 横线 (\d{4}) # 终点号码 ''','(800) 555-1222').groups() print(ret) # ('800', '555', '1222')
7-4)(?:)
(?:后面跟正则表达式),不输出
对部分正则表达式进行分组,但并不会保存该分组用于后面的检索和应用。相当于“只匹配,不输出”。
ret = re.findall('(?im)http://(?:\w+\.)*(\w+\.com)',''' http://baidu.com http://www.baidu.com http://ditu.baidu.com''') print(ret) # ['baidu.com', 'baidu.com', 'baidu.com']
7-5)(?P<name>)和(?P=name)和\g<name>
(?P<name>)对分组取名,方便后面调用分组(?P=name)。
# 只取区号和前缀,区号是0571,前缀是7421,生成一个字典 # 如电话号码:(0571) 7421-888 ret = re.search('\((?P<areacode>\d{4})\) (?P<prefix>\d{4})-(?:\d{3})','(0571) 7421-888').groupdict() print(ret) # {'areacode': '0571', 'prefix': '7421'}
(?P<name>) 定义的分组,使用\g<name>进行引用(字符串中)
# 将电话号码:(0571) 7421-888变成(0571) 7421-999 ret = re.sub('\((?P<areacode>\d{4})\) (?P<prefix>\d{4})-(?:\d{3})','(\g<areacode>) \g<prefix>-999','(0571) 7421-888') print(ret) # (0571) 7421-999
(?P<name>) 定义的分组,使用(?P=name)进行引用(正则中)
# 匹配(0571) 7421-888 0571-7421-888 105717421888 ret = re.search('''(?x) # 匹配出(0571) 7421-888 \((?P<areacode>\d{4})\)[ ](?P<prefix>\d{4})-(?P<number>\d{3}) # 空格 [ ] # 匹配出0571-7421-888 (?P=areacode)-(?P=prefix)-(?P=number) # 空格 [ ] # 匹配出105717421888 1(?P=areacode)(?P=prefix)(?P=number) ''','(0571) 7421-888 0571-7421-888 105717421888').group() print(ret) # (0571) 7421-888 0571-7421-888 105717421888
7-6)(?=name)
正向前视断言,输出name前面匹配到的内容。
str = ''' LeBron James kobe bryant slitobo James Allen Iverson ''' # 正向前视断言,将James前面的内容输出 ret = re.findall('\w+(?= James)',str) print(ret) # ['LeBron', 'slitobo']
7-7) (?!name)
反向前视断言,输出name以外的内容
str = ''' sales@slito.com postmaster@slito.com eng@slito.com noreply@slito.com admin@slito.com ''' #匹配以noreply或者postmaster开头的email地址后,根据匹配规则输出其他的地址 ret1 = re.findall('(?m)^(?!noreply|postmaster)(\w+)',str) print(ret1) # ['sales', 'eng', 'admin'] ret2 = re.findall('(?m)^(?!noreply|postmaster)(\w+)\@(\w+\.\w+)',str) print(ret2) # [('sales', 'slito.com'), ('eng', 'slito.com'), ('admin', 'slito.com')]
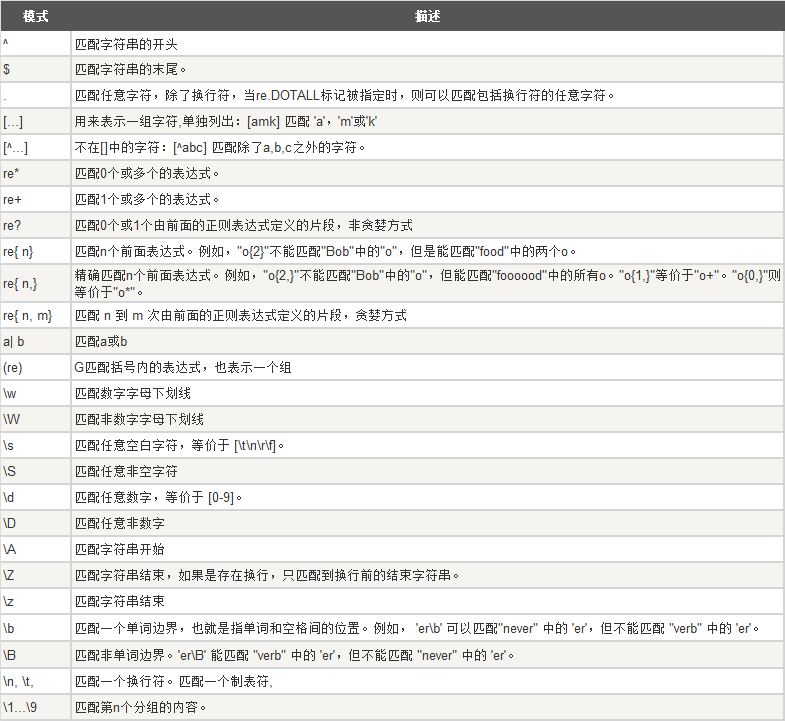
8) 正则表达式模式字符(常用部分)
摘自:菜鸟教程Python3正则表达式模式,http://www.runoob.com/python3/python3-reg-expressions.html
8.json
将内存中的对象(变量)转化为可存储或者传输的动作,称为序列化。
json.dump和json.dumps比较:
json.dump : 将Python原数据类型直接写入文件
json.dumps:先将Python原数据序列化为字符串,将序列化后的内容写入文件
json.load和json.loads比较:
json.load:将json文件内容直接读取出来
json.loads:现将json中的数据读出来(字符串),然后将内容反序列化成python数据类型。
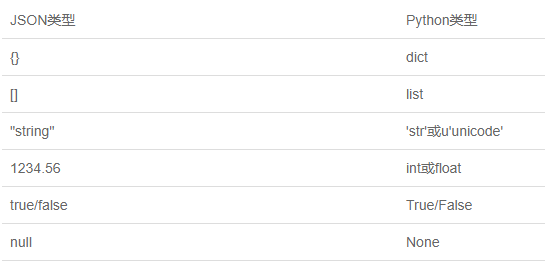
json类型与Python类型对比
8-1)json.dump和json.load
import json dict = { 'name':'slitobo', 'age':'10', 'gender':'male', 'job':'OPS' } # 创建文件 f=open('test.json','w') # 字典写成json文件 json.dump(dict,f) # 读取文件 f=open('test.json','r')
# 从文件句柄中读取数据 data=json.load(f) print(data.keys()) # dict_keys(['name', 'age', 'gender', 'job'])
8-2)json.dumps和json.loads
import json dict = { 'name':'slitobo', 'age':'10', 'gender':'male', 'job':'OPS' } # 将对象转换为字符串 data = json.dumps(dict) print(type(data)) # <class 'str'> # 将字符串写入文件 f = open('text.json','w') f.write(data) f.close() # 将文件中的字符串读取出来 f = open('text.json','r') data = f.read() # 将字符串转换为字典 data = json.loads(data) print(type(data)) # <class 'dict'>
* python的数据类型集合(set)不是json可序列化对象
import json set1 = {1,2,3,4} # <class 'set'> print(type(set1)) json.dumps(set1) # TypeError: Object of type 'set' is not JSON serializable
* Python的元组反序列化后为列表(list)
import json tuple1 = (1,2,3,4) ss = json.dumps(tuple1) f = open('text.json','w') f.write(ss) f = open('text.json','r') data = f.read() data = json.loads(data) print(type(data)) # <class 'list'>
9.pickle
import pickle class foo: def __init__(self,first_name,last_name): self.first_name = first_name self.last_name = last_name def show_fullname(self): print(self.last_name+"."+self.first_name) obj = foo('布莱恩特','科比') # 将对象写入文件 f = open('text.txt','wb') pickle.dump(obj,f,0) # 读取文件中的对象 f = open('text.txt','rb') obj_new = pickle.load(f) obj_new.show_fullname() # 科比.布莱恩特
10.shelve
import shelve class school: def show(self): print('我是对象') obj_school = school() with shelve.open('slitobo.shelve') as write: write['name'] = 'slitobo' write['obj'] = obj_school with shelve.open('slitobo.shelve') as read: name = read['name'] print(name) # slitobo obj1 = read['obj'] obj1.show() # 我是对象 keys = list(read.keys()) print(keys) # ['name', 'obj'] del read['name'] print('name' in read) # False
11.urllib
import urllib.request import urllib.parse import json dic = {'name':'melon','age':18} data = urllib.parse.urlencode(dic) req = urllib.request.Request('http://127.0.0.1:8000/index', data.encode()) opener = urllib.request.urlopen(req) content = json.loads(opener.read().decode())

 浙公网安备 33010602011771号
浙公网安备 33010602011771号