

完整教程:云计算实验1——CentOS中hadoop的安装
本文是对“云计算”课程学习中 hadoop安装实验 的实验步骤记录。若有错误,欢迎交流指正。
实验环境:3台CentOS 7虚拟机,均已配置Java 1.7.0_79
实验目的:安装hadoop(版本2.6.5)
目录
1 虚拟机准备
首先创建三台虚拟机,虚拟机网络配置为桥接模式,并根据自己PC的网络信息,在CentOS中分别配置各自的IP地址,使其和PC位于相同网段。
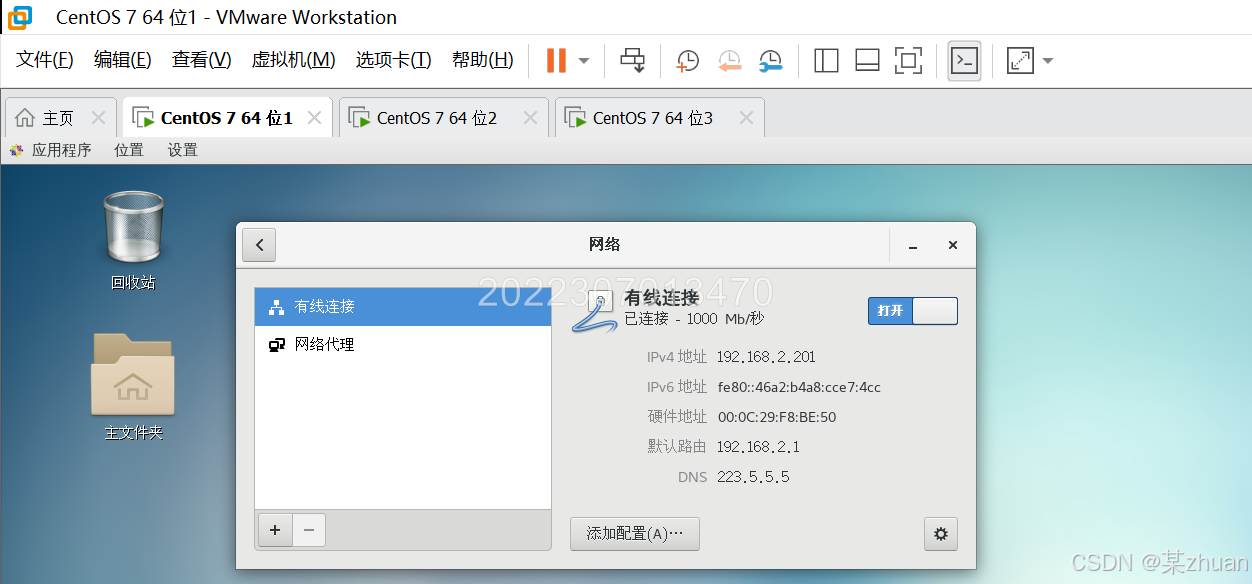
在windows中,使用ssh连接到三台虚拟机。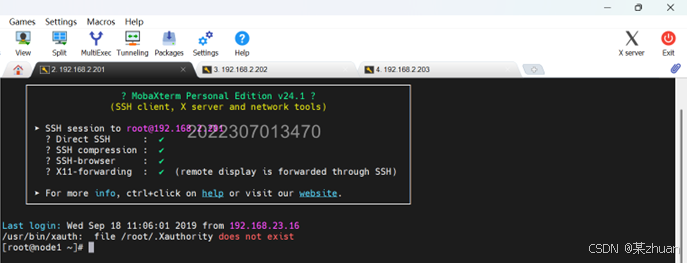
2 配置SSH无密码登录
2.1 配置hosts
首先使用以下命令修改三台机器的名字,我这里命名为node1、node2、node3。
hostnamectl set-hostname 主机名然后配置hosts,三台机器均执行:vi /etc/hosts,添加三台机器对应的IP。注意IP和主机名之间使用tab键隔开。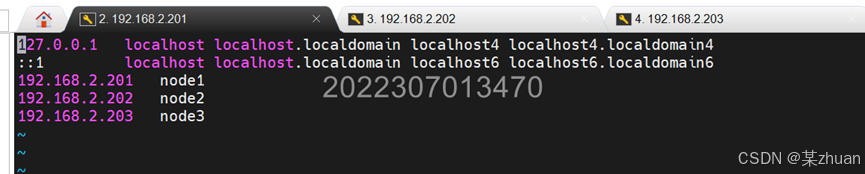
配置好后,通过机器名称互相ping,测试可以联通。
2.2 配置SSH无密码登录
首先生成ssh密钥。在三台机器中执行此命令:
ssh-keygen -t dsa -P '' -f ~/.ssh/id_rsa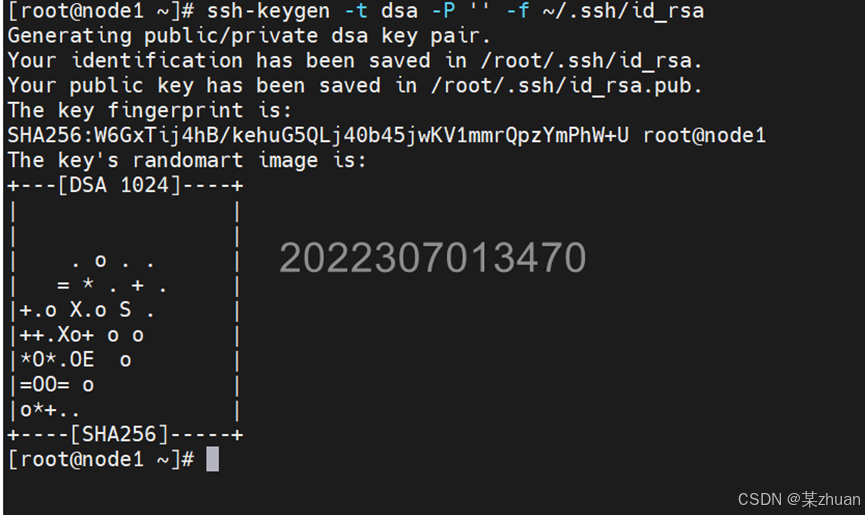
接下来分别将每台机器的公钥记录下来,并将node2和node3的公钥拷贝到node1中。
node1:
cd ~/.ssh
cat id_rsa.pub >> authorized_keysnode2:
cd ~/.ssh
cat id_rsa.pub >> authorized_keys1
scp authorized_keys1 root@node1:~/.ssh/
node3:
cd ~/.ssh
cat id_rsa.pub >> authorized_keys2
scp authorized_keys2 root@node1:~/.ssh/在node1中,将node2和node3的公钥添加进authorized_keys中。
node1:
cat authorized_keys1 >> authorized_keys
cat authorized_keys2 >> authorized_keys在node1中,将合并好的authorized_keys分发到node2和node3中。
scp authorized_keys root@node2:~/.ssh/
scp authorized_keys root@node3:~/.ssh/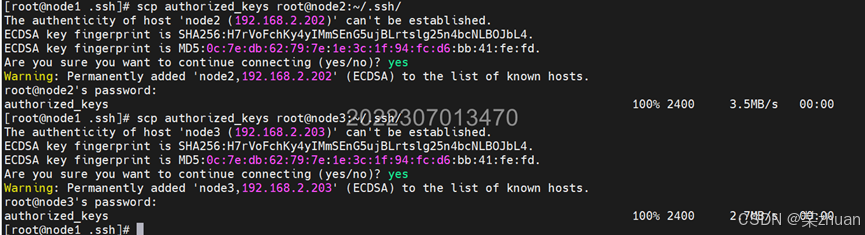
在node2中进行测试,可以无密码登录node1。使用exit退出ssh会话。
3 hadoop的安装
以下命令均在node1中执行。node1中配置好hadoop后,将其拷贝到node2和node3即可。
3.1 解压安装hadoop
首先准备hadoop的安装包,放置到/usr目录中。
由于虚拟机此前配置过hadoop,所以首先删除原机已经有的hadoop
cd /usr
rm -rf hadoop然后解压hadoop,并重命名
tar -xzvf hadoop-2.6.5.tar.gz
mv hadoop-2.6.5 /usr/hadoop
创建运行时需要的文件夹
mkdir /usr/hadoop/tmp
mkdir /usr/hadoop/hdfs
mkdir /usr/hadoop/hdfs/data
mkdir /usr/hadoop/hdfs/name3.2 修改配置文件
3.2.1 hadoop-env.sh
vi /usr/hadoop/etc/hadoop/hadoop-env.sh找到如下内容:export JAVA_HOME=${JAVA_HOME}
将这行内容修改为:export JAVA_HOME=/usr/java/jdk1.7.0_79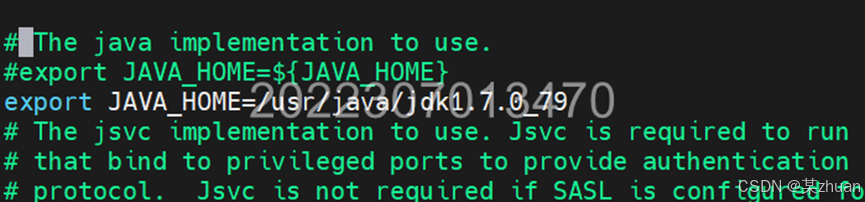
3.2.2 core-site.xml
vi /usr/hadoop/etc/hadoop/core-site.xml在configuration标签之间加入以下内容
hadoop.tmp.dir
/usr/hadoop/cloud
fs.defaultFS
hdfs://node1:80203.2.3 hdfs-site.xml
vi /usr/hadoop/etc/hadoop/hdfs-site.xml在configuration标签之间加入以下内容
dfs.namenode.secondary.http-address
node2:50090
dfs.namenode.secondary.https-address
node2:500913.2.4 配置masters和slaves
cd /usr/hadoop/etc/hadoop/使用vi命令修改masters和slaves两个文件的内容:
vi slavesslaves中,删除localhosts,添加node2、node3
vi mastersmasters中,添加node1
3.3 将hadoop复制到其他节点
在node1中执行以下命令,将配置好的hadoop复制到node2和node3
scp -r /usr/hadoop root@node2:/usr/
scp -r /usr/hadoop root@node3:/usr/3.4 配置环境变量
以下命令在所有机器中均需执行
vi /etc/profile添加以下内容
export HADOOP_HOME=/usr/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
执行以下命令使配置生效
source /etc/profile3.5 hadoop初始化
在node1中执行以下命令
cd /usr/hadoop/bin
./hdfs namenode -format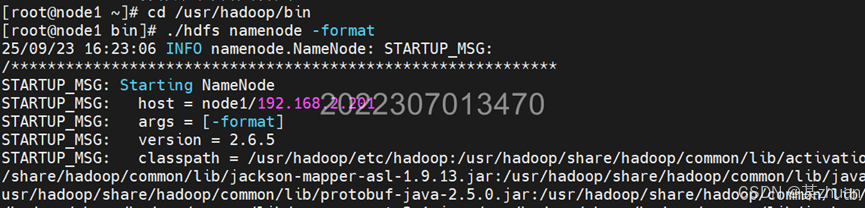
4 启动hadoop进行测试
4.1 启动hadoop
在node1中执行命令,启动hadoop
cd /usr/hadoop/sbin
./start-dfs.sh
检查各节点状态,在各节点中分别执行命令jps
各节点应有的进程如下表所示
| 节点 | 进程 |
|---|---|
| node1 | ResourceManager、NameNode、Jps |
| node2 | DataNode、SecondaryNameNode、Jps |
| node3 | DataNode、Jps |
4.2 浏览器测试
在node1虚拟机中,启动浏览器,地址栏输入node1:50070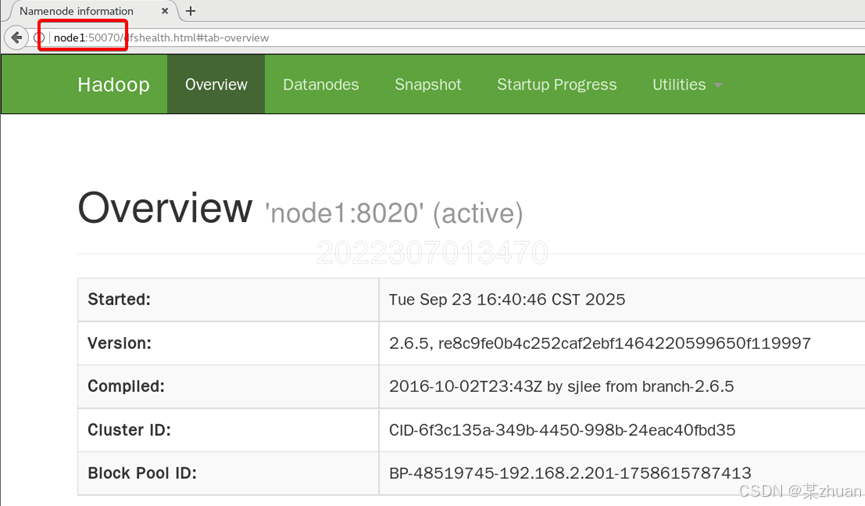
选择datanodes,能看到node2和node3的信息。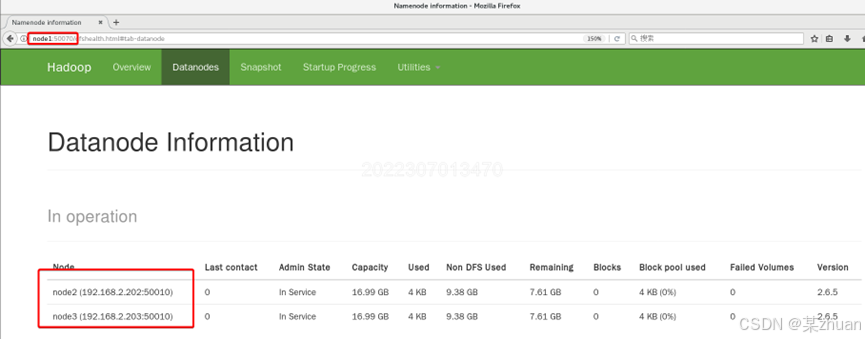
若看不到其他datanode的信息,可排查防火墙状态。在学习过程中,可以直接关闭CentOS防火墙。
systemctl stop firewalld # 本次停止
systemctl disable firewalld # 停用防火墙服务4.3 上传文件测试
向HDFS新建一个测试文件夹
hdfs dfs -mkdir /test选择browse the file system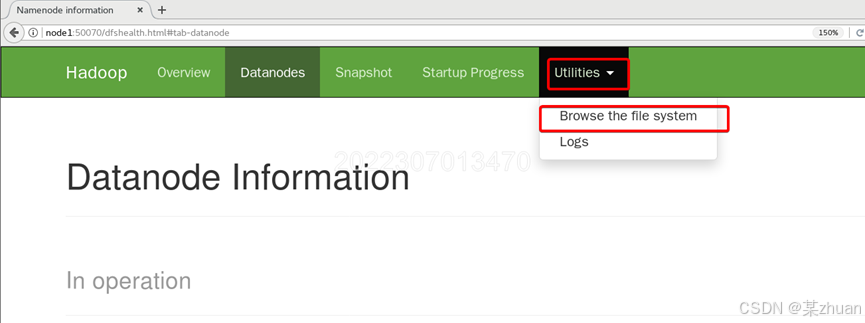
可以看到刚才新建的目录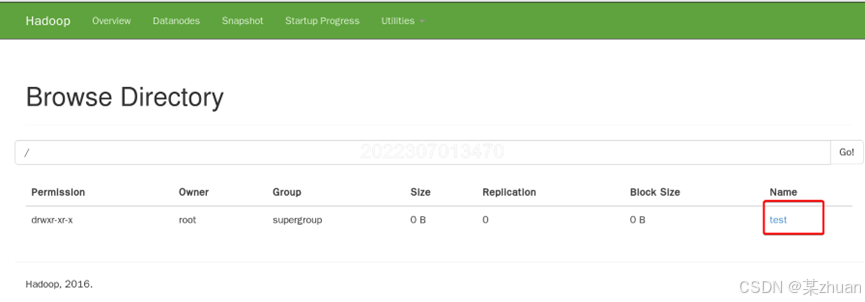
再创建一个测试文件并上传
echo hello > hello.txt
hdfs dfs -put hello.txt /test在test目录中可以看到上传的文件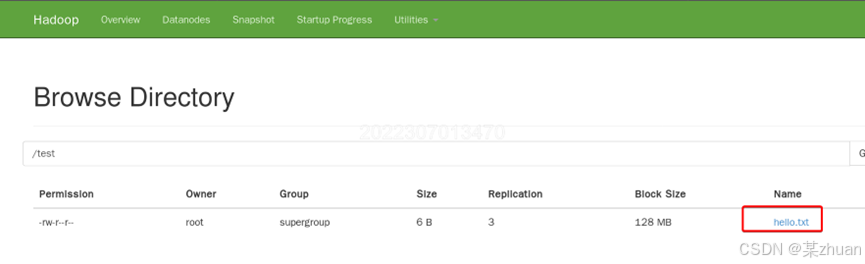
实验至此结束,感谢阅读本文。
文中所有图片均添加水印,严禁任何方式盗用或转载本文及文中图片。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号