
服务器雪崩效应以及处理
1.系统中的雪崩效应
微服务之间往往采用RPC或者HTTP调用,一般都会设置调用超时的限制,或者通过失败重试机制来确保服务成功执行。但如果不考虑服务的熔断和限流,还是很容易产生服务雪崩的。
我们系统中三个服务:订单服务,商品服务,库存服务;
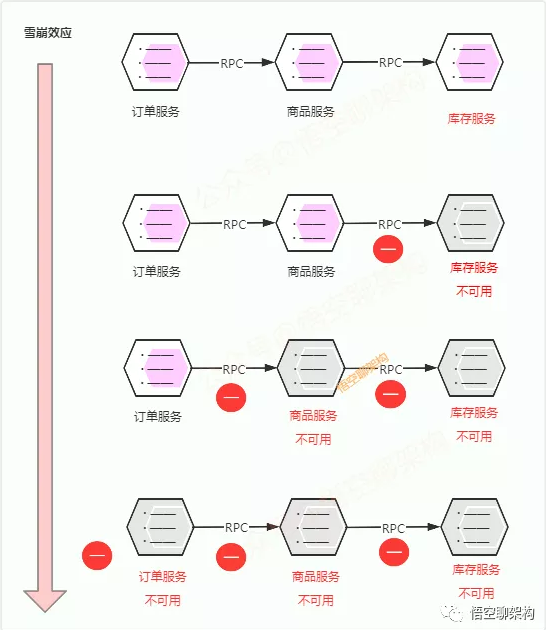
- 下单场景:用户下单了一个商品,客户端调用订单服务来生成预付款订单,订单服务调用商品服务查看下单的哪款商品,商品服务调用库存服务判断这款商品是否有库存,如有库存,则可以生成预付款订单;
- 假定因双十一流量暴增,库存服务不可用(如响应超时等),库存服务收到的很多请求都未处理完,它将无法处理更多请求;
- 而上游的商品服务依赖库存服务,商品服务的超时和重试机制会被执行。商品服务新的调用不断产生,会导致商品服务的调用被大量积压,产生大量的调用等待和重试调用,慢慢耗尽商品服务的资源,比如内存,结果导致商品服务也宕机了;
- 而订单服务也会重走商品服务的老路。结果就是三个服务都不可用了。
2.造成雪崩服务的真实场景
2.1服务提供者不可用
硬件故障:如网络故障,硬盘损坏等;
程序的Bug:如算法需要占用大量CPU的计算时间导致CPU使用率过高。
缓存击穿:比如应用重启;短时间内存是失效的,导致大量请求直接访问到数据库,数据库不堪重负,服务不可用;
秒杀和大促:服务短时间承载不了那么多请求量。
2.2 重试加大流量
用户连续重试:比如用户看到界面上没有响应,所以又操作了一遍,结果又增加一倍请求量
程序重启机制:比如代码中有多次重试的逻辑,一次失败后,过几秒后在重试,重试个三次就取消重试,走异常处理分支了。也是增加了请求量。
2.3 如何防止雪崩
方案:
出问题前预防:限流,主动降级,隔离;
出问题后修复:熔断,被动降级
3.熔断原理和算法
3.1熔断概念
如果在某段时间内,调用某个服务非常慢甚至超时,就可以将这个服务熔断,后续其他服务在调用这个服务就直接返回,告诉其他服务:“已经熔断了,你别调用我了,过段时间再来试下吧。”
3.2如何熔断
熔断有个原则一段时间内 统计失败的次数或失败请求的占比超过一定阀值,就进行熔断。
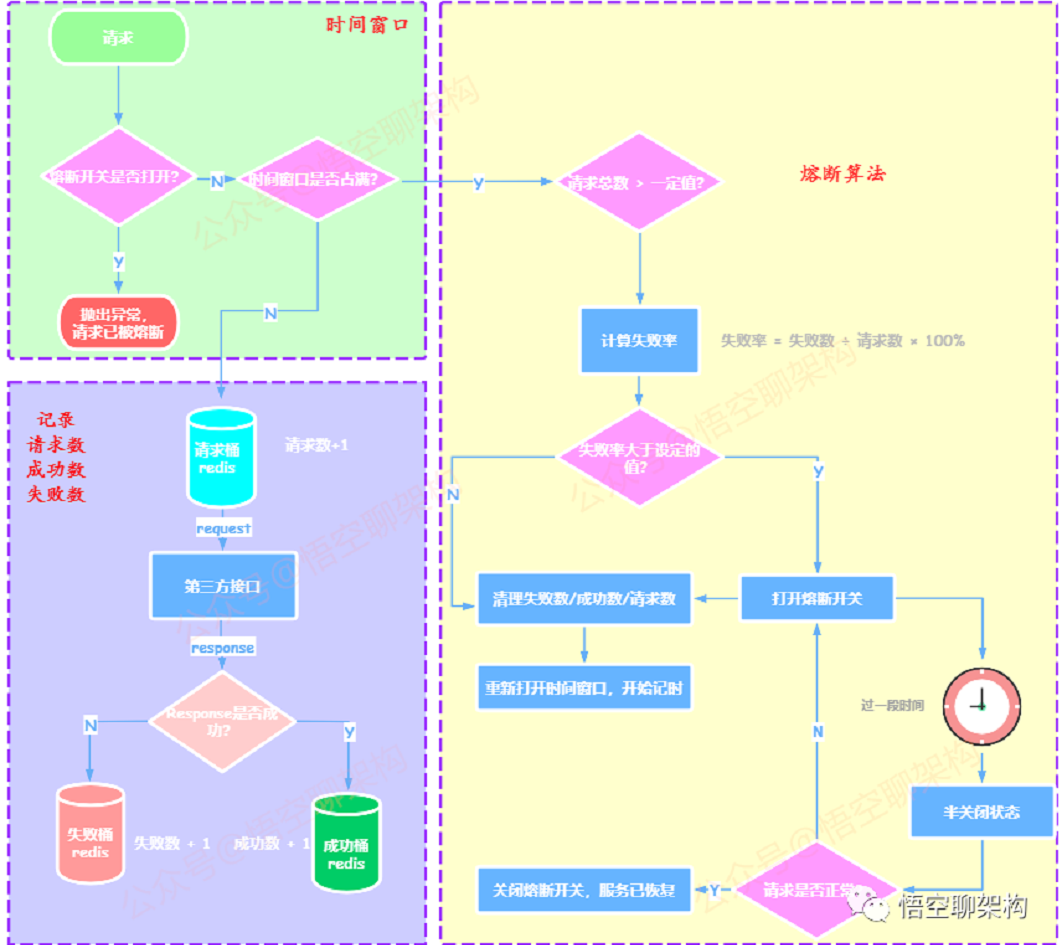
3.3统计请求的算法
- 请求访问到后台服务后,首先判断熔断开关是否打开
- 如果熔断开关已打开,则表明当前请求不能被处理
- 如果熔断开关未打开,则判断时间窗口是否已满
- 如果时间窗口未满,则请求桶中的请求数加1;
- 如果返回的相应有异常,则失败桶的失败数加1,如果返回的响应没有异常,则成功桶的成功数加1;
- 如果时间窗口已满,则开始判断是否需要熔断。
3.4 熔断的恢复算法
- 当熔断后,开关切换到断开状态;
- 过一段时间后,开关切换为半断开状态(Half-Open)。半断开状态下,允许对应程序的一定数量的请求可以去调用服务,如果调用成功,则认为服务可以正常访问了,于是将开关切换为闭合状态;
- 如果半断开状态下,还是有调用失败的情况,则认为服务还没有恢复,开关从断开状态切换到断开状态。
3.5 统计失败率的时间窗口
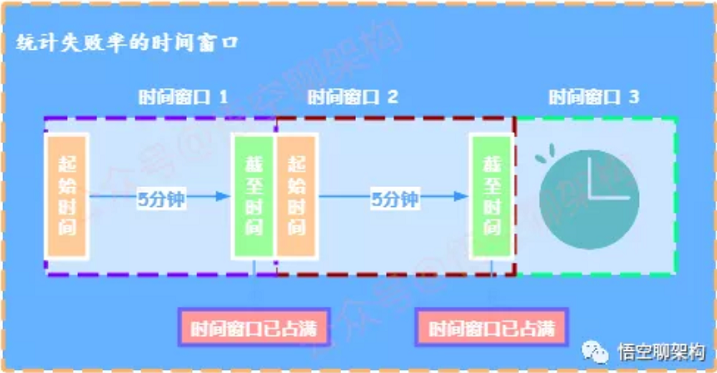
-
时间窗口可以比喻为人坐在窗户边,看外面来往的车辆,一定时间内从窗户外经过的车辆;
-
每次请求,都会判断时间窗口是否已满(如5分钟),如果时间窗口已满,则重新开始计时,且清理请求数/成功数/失败数;
-
注意:第一次开始的起始时间默认为当前时间。
3.6.尝试恢复服务的时间窗口
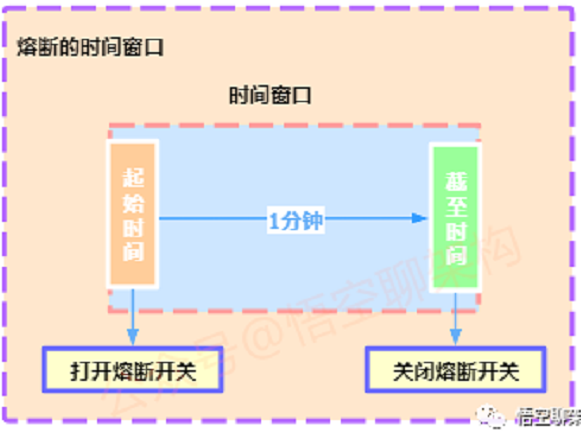
-
开关为断开的状态,经过一定时间后,比如 1 分钟,设置为半断开的状态,尝试发送请求检测服务是否恢复;
-
如果已恢复,则切换状态为关闭状态。如果未恢复,则切换状态为断开的状态,经过 1 分钟后,重复上面的步骤;
-
这里的时间窗口可以根据环境的运行状态进行动态调整,比如第一次是 1 分钟,第二次是 3 分钟,第三次是 10 分钟。
熔断中间件
肯定有人会问了,你这上面讲的原理,难道还真的自己去写这套算法?
答案:是的,项目中我们自己造了一个轮子:熔断器。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号