Hadoop组件
一.Hadoop组件介绍
1.HDFS(分布式文件系统)——核心
HDFS是整个hadoop体系的基础,负责数据的存储与管理。HDFS有着高容错性(fault-tolerant)的特点,并且设计用来部署在低廉的(low-cost)硬件上。而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。它提供了一次写入多次读取的机制,数据以块的形式,同时分布在集群不同物理机器上。
NameNode:master节点,每个HDFS集群只有一个,管理HDFS的名称空间和数据块映射信息,配置相关副本信息,处理客户端请求。
DataNode:slave节点,存储实际数据,并汇报状态信息给NameNode,默认一个文件会备份3份在不同的DataNode中,实现高可靠性和容错性。
Secondary NameNode:辅助NameNode,实现高可靠性,定期合并fsimage和fsedits,推送给NameNode;紧急情况下辅助和恢复NameNode,但其并非NameNode的热备份。
2.Hive(基于Hadoop的数据仓库)
Hive定义了一种类似SQL的查询语言(HQL),将SQL转化为MapReduce任务在Hadoop上执行。
Hive是基于Hadoop的数据仓库工具,可以用来对HDFS中存储的数据进行查询和分析,通过SQL查询分析需要的内容,查询Hive使用的SQL语句简称Hive SQL(HQL)
HQL用于运行存储在Hadoop上的查询语句,Hive让不熟悉MapReduce开发人员也能编写数据查询语句,然后这些语句被翻译为Hadoop上面的MapReduce任务。
Hive还允许用户编写自己定义的函数UDF,用来在查询中使用。
Hive与Hadoop的关系:
Hive构建在Hadoop之上,HQL中对查询语句的解释、优化、生成查询计划是由Hive完成的。Hive读取的所有数据都是存储在Hadoop文件系统中。Hive查询计划被转化为MapReduce任务,在Hadoop中执行。
Hive与数据库的异同:
从结构上来看,Hive和数据库除了拥有类似的查询语言,再无类似之处
3.Zookeeper(分布式协作服务)
解决分布式环境下的数据管理问题:统一命名,状态同步,集群管理,配置同步等。
Hadoop的许多组件依赖于Zookeeper,它运行在计算机集群上面,用于管理Hadoop操作。
角色:
在ZooKeeper中没有选择传统的Master/Slave概念,而是引入了leader、follower和observer三种角色,follower和observer都只能提供读服务
4.HBase(分布式列存数据库)
HBase是一个建立在HDFS之上,面向列的针对结构化数据的可伸缩、高可靠、高性能、分布式和面向列的动态模式数据库。
HBase提供了对大规模数据的随机、实时读写访问,同时,HBase中保存的数据可以使用MapReduce来处理,它将数据存储和并行计算完美地结合在一起。
功能应用:
既然HBase是数据库,那么数据库从根本上来说就是存储表Table的,但是必须注意HBase并非是传统的关系型数据库(例如MySQL、Oracle),而是非关系型数据库,因为HBase是一个面向列的分布式存储系统。
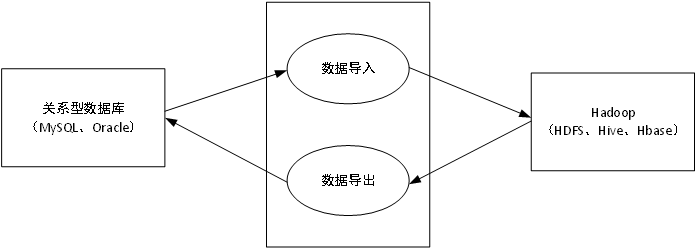
5.Sqoop(数据ETL/同步工具)
可将Hadoop下的mysql和hive数据库的数据增删改
Sqoop利用数据库技术描述数据架构,用于在关系数据库、数据仓库和Hadoop之间转移数据
Sqoop是一个用于在Hadoop和关系数据库服务器之间传输数据的工具。它用于从关系数据库(如MySQL,Oracle)导入数据到Hadoop HDFS,并从Hadoop文件系统导出到关系数据库
6.Flume(日志收集工具)
它将数据从产生、传输、处理并最终写入目标的路径的过程抽象为数据流,在具体的数据流中,数据源支持在Flume中定制数据发送方,从而支持收集各种不同协议数据。
功能:
(1)日志收集:任何一个生产系统在运行过程中都会产生大量的日志,日志往往隐藏了很多有价值的信息
将分散在各个生产系统中的日志收集起来
(2)数据处理:Flume提供对数据进行简单处理,并写入到各种数据接受方的能力
二,大数据平台相关运行状态
1.大数据平台常用组件端口号汇总

2.通过界面查看大数据平台状态
通过大数据平台Hadoop的用户界面可以查看平台的计算资源和存储资源
在浏览器输入http://master:8088/cluster/nodes
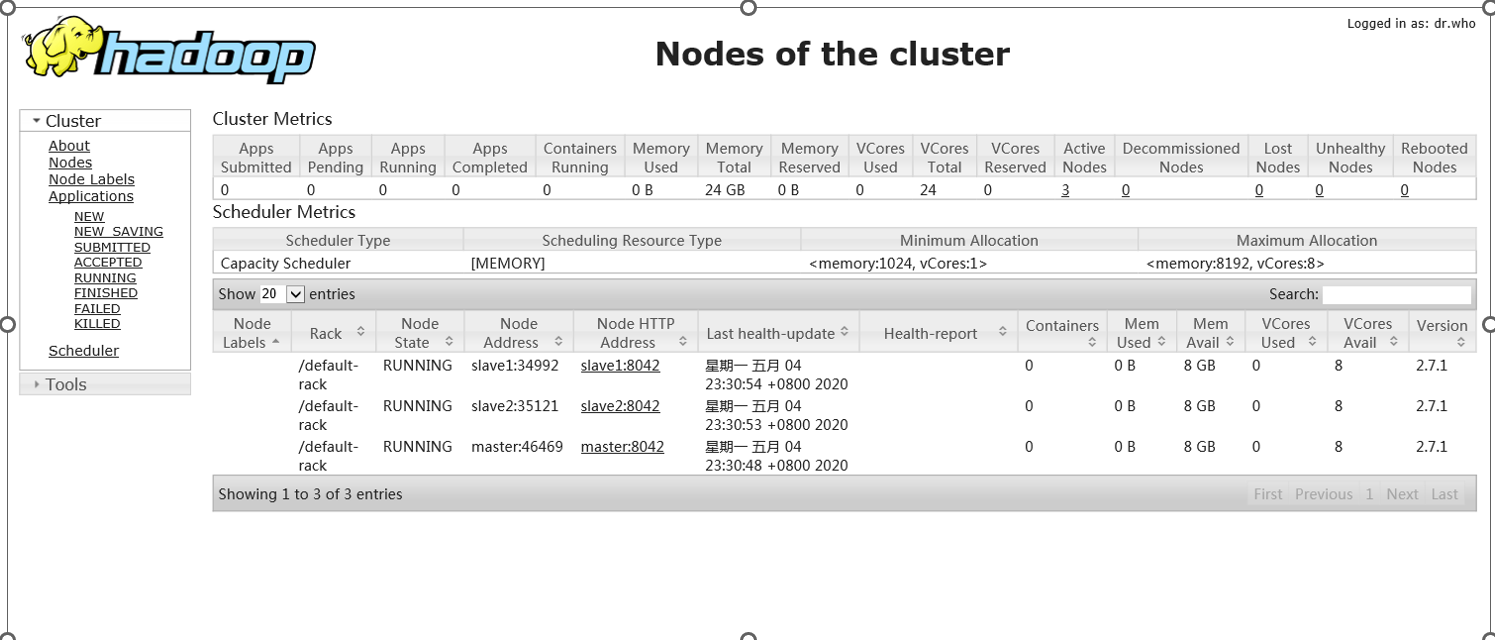
3.查看Hadoop的运行状态
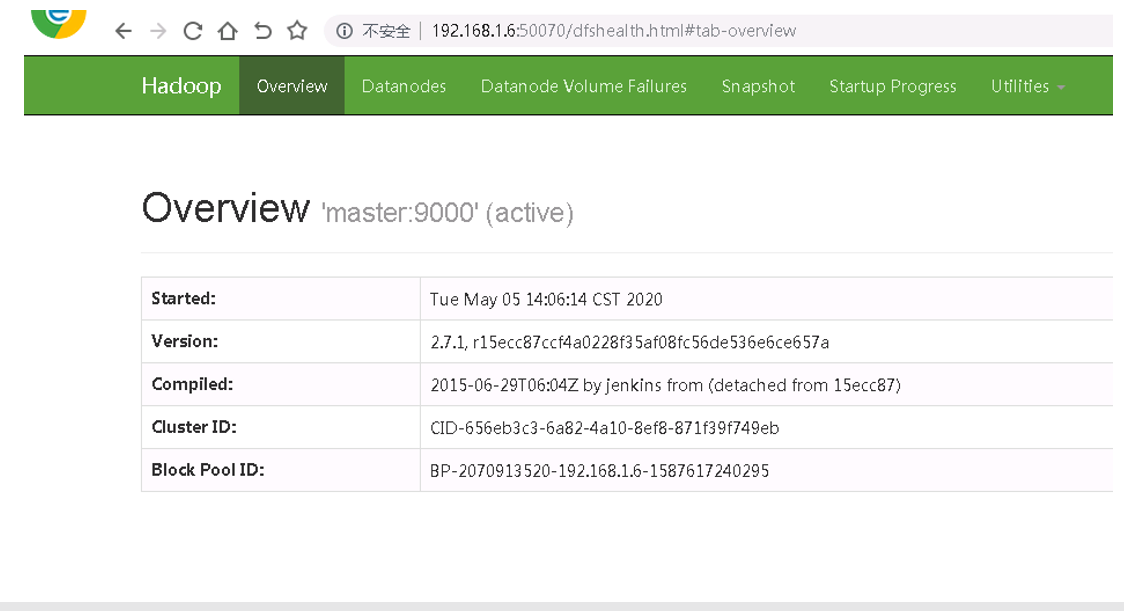
大数据平台Hadoop提供了一个简单的web访问接口,网址是 http://master:50070 ,主菜单包含状态总览、数据节点、挂载失败节点、快照、日记等状态
4.通过界面监控HDFS状态:
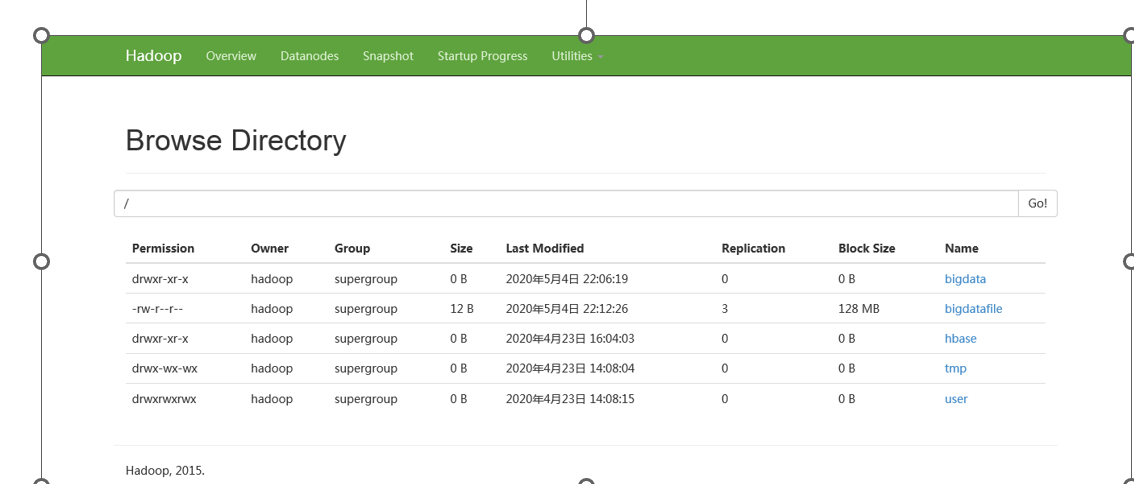
在配置好Hadoop集群之后,可以通过浏览器登录“ http://master:50070 ”访问HDFS文件系统,点击Utilities-->Browse The File Systerm
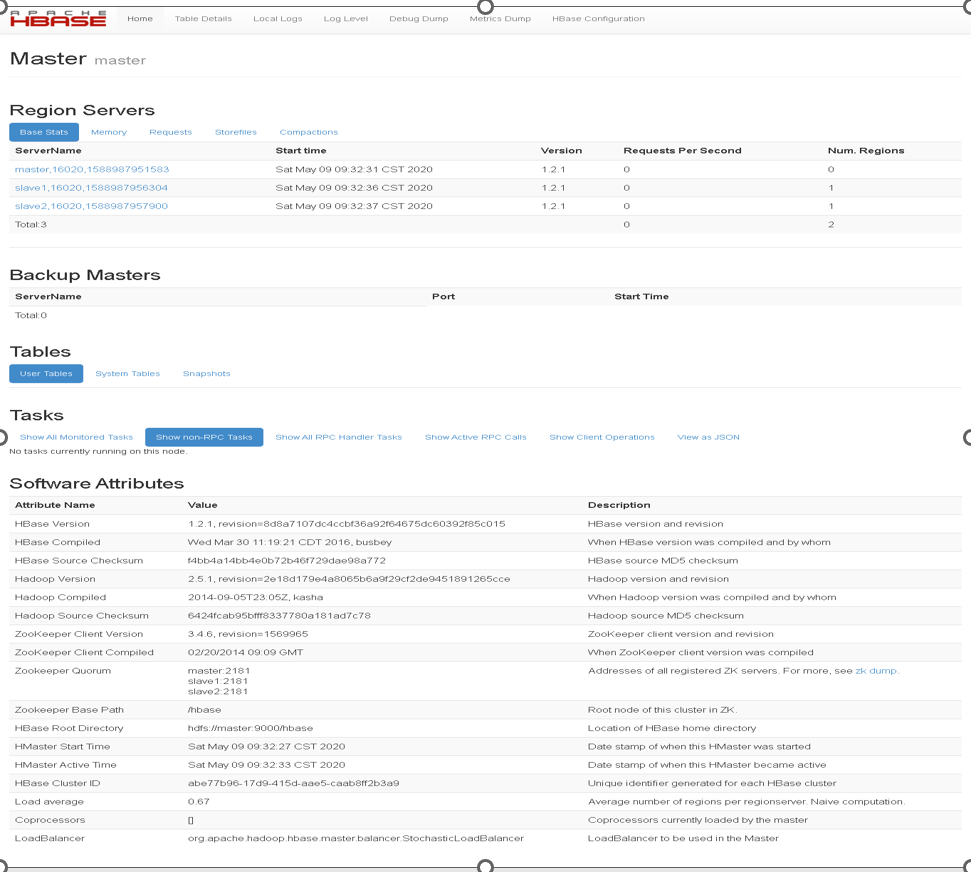
5.通过界面监控HBase的状态:
安装部署好HBase后,可以通过用户界面来访问HBase的状态、日记等相关信息。访问Web 用户界面地址分别为:master:60010 ;slave1:60010 ;slave2:60010
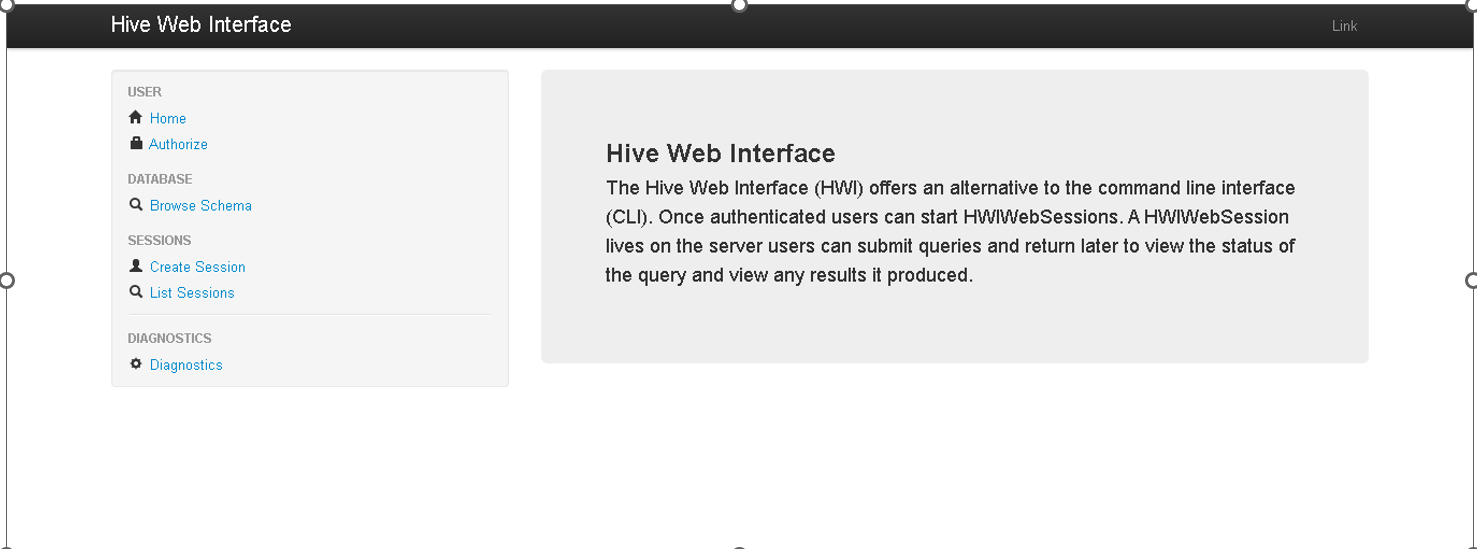
6.通过界面监控Hive的状态
在浏览器中输入 http://master:9999/hwi ,回车即显示Hive Web Interface的主界面

 浙公网安备 33010602011771号
浙公网安备 33010602011771号