zookeeper&Eureka
0、各类注册中心特性对比
| Nacos | Eureka | Consul | CoreDNS | Zookeeper | |
|---|---|---|---|---|---|
| 一致性协议 | CP+AP | AP | CP | - | CP |
| 健康检查 | TCP/HTTP/MYSQL/Client Beat | Client Beat | TCP/HTTP/gRPC/Cmd | - | Keep Alive |
| 负载均衡策略 | 权重/metadata/Selector | Ribbon | Fabio | RoundRobin | - |
| 雪崩保护 | 有 | 有 | 无 | 无 | 无 |
| 自动注销实例 | 支持 | 支持 | 不支持 | 不支持 | 支持 |
| 访问协议 | HTTP/DNS | HTTP | HTTP/DNS | DNS | TCP |
| 监听支持 | 支持 | 支持 | 支持 | 不支持 | 支持 |
| 多数据中心 | 支持 | 支持 | 支持 | 不支持 | 不支持 |
| 跨注册中心同步 | 支持 | 不支持 | 支持 | 不支持 | 不支持 |
| SpringCloud集成 | 支持 | 支持 | 支持 | 不支持 | 不支持 |
| Dubbo集成 | 支持 | 不支持 | 不支持 | 不支持 | 支持 |
| K8S集成 | 支持 | 不支持 | 支持 | 支持 | 不支持 |
一致性模型。一致性模型本质上是进程与数据存储的约定:如果进程遵循某些规则,那么进程对数据的读写操作都是可预期的。
1、线性一致性:线性一致性是对一致性要求最高的一致性模型,就现有技术是不可能实现的。因为它要求所有操作都实时同步,在分布式系统中要做到全局完全一致时钟现有技术是做不到的。首先通信是必然有延迟的,一旦有延迟,时钟的同步就没法做到一致。当然不排除以后新的技术能够做到,但目前而言线性一致性是无法实现的。
2、顺序一致性:顺序一致性使用的是逻辑时钟来作为分布式系统中的全局时钟,进而所有进程也有了一个统一的参考系对读写操作进行排序,因此所有进程看到的数据读写操作顺序也是一样的。
3、因果一致性:因果一致性进一步弱化了顺序一致性中对读写操作顺序的约束,仅保证有因果关系的读写操作有序,没有因果关系的读写操作(并发事件)则不做保证。也就是说如果是无因果关系的数据操作不同进程看到的值是有可能是不一样,而有因果关系的数据操作不同进程看到的值保证是一样的。
4、最终一致性:最终一致性是更加弱化的一致性模型,因果一致性起码还保证了有因果关系的数据不同进程读取到的值保证是一样的,而最终一致性只保证所有副本的数据最终在某个时刻会保持一致。这是大型分布式系统构建使用最多的一种一致性模型。
而以客户端为中心的一致性包含了四种子模型:
1、单调读一致性:如果一个进程读取数据项 x 的值,那么该进程对于 x 后续的所有读操作要么读取到第一次读取的值要么读取到更新的值。即保证客户端不会读取到旧值。
2、单调写一致性:一个进程对数据项 x 的写操作必须在该进程对 x 执行任何后续写操作之前完成。即保证客户端的写操作是串行的。
3、读写一致性:一个进程对数据项 x 执行一次写操作的结果总是会被该进程对 x 执行的后续读操作看见。即保证客户端能读到自己最新写入的值。
4、写读一致性:同一个进程对数据项 x 执行的读操作之后的写操作,保证发生在与 x 读取值相同或比之更新的值上。即保证客户端对一个数据项的写操作是基于该客户端最新读取的值。
| 单调写一致性 | 读写一致性 | 写读一致性 | 单调读一致性 | |
|---|---|---|---|---|
| 线性一致性 | √ | √ | √ | √ |
| 顺序一致性 | √ | √ | √ | √ |
| 因果一致性 | √ | × | × | √ |
| 最终一致性 | × | × | × | × |
参考《分布式系统原理与范型》
1、CP架构
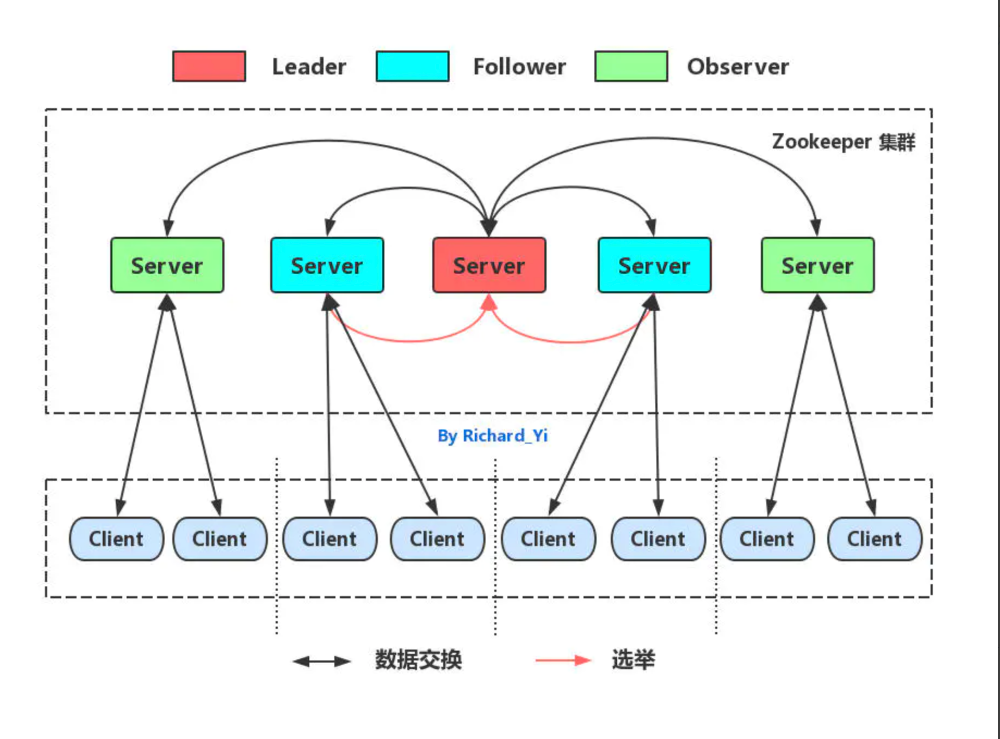
zookeeper是一个分布式协调服务,它为分布式应用程序提供了统一命名服务、状态同步服务、集群管理、分布式应用配置管理等解决方案。2011年,阿里巴巴开源Dubbo分布式服务,ZooKeeper 作为Dubbo其推荐的注册中心,后来在国内,在业界诸君的努力实践下,Dubbo + ZooKeeper 的典型的服务化方案成就了 ZooKeeper 作为注册中心的声名。zookeeper基于zab一致性协议来实现消息广播和崩溃恢复,该协议的核心算法是fast paxos,其强调的是一致性(C),
在事务消息写入时,为尽最大努力保证数据视图一致性,当集群(官方推荐2N+1节点集群)过半数节点写入成功时才能提交该事务,崩溃恢复选主也是类似,少数服从多数,过半数投票成功才算选主成功。
当然ZooKeeper为了保证在集群脑裂分区(P)情况下数据一致性(C),其放弃了可用性(A),所以在集群部分节点或者网络发生故障,master离线的时候,集群将进行崩溃恢复选主,在选主期间,整个集群对外是不可用的,一直持续到选主完成,主从数据同步成功为止。而当跨机房部署zookeeper集群提供注册中心服务时,当部分机房网络故障发生分区时,由于舍弃了可用性(A),也会存在网络分区“孤岛”机房服务间连通性受影响的情况。这些场景都是由CP架构选型所决定的,至于作为注册中心服务CP架构好与不好不是本次的讨论主题,有兴趣可参考阿里的技术文章《阿里巴巴为什么不使用zookeeper做服务发现?》
2、Eureka (AP架构)
Eureka天生就是为服务注册中心而设计的产品,其采用了 C-S 的设计架构,Eureka Server 作为服务注册功能的服务器,其他微服务提供者,使用 Eureka 的客户端连接到 Eureka Server,并维持心跳连接。
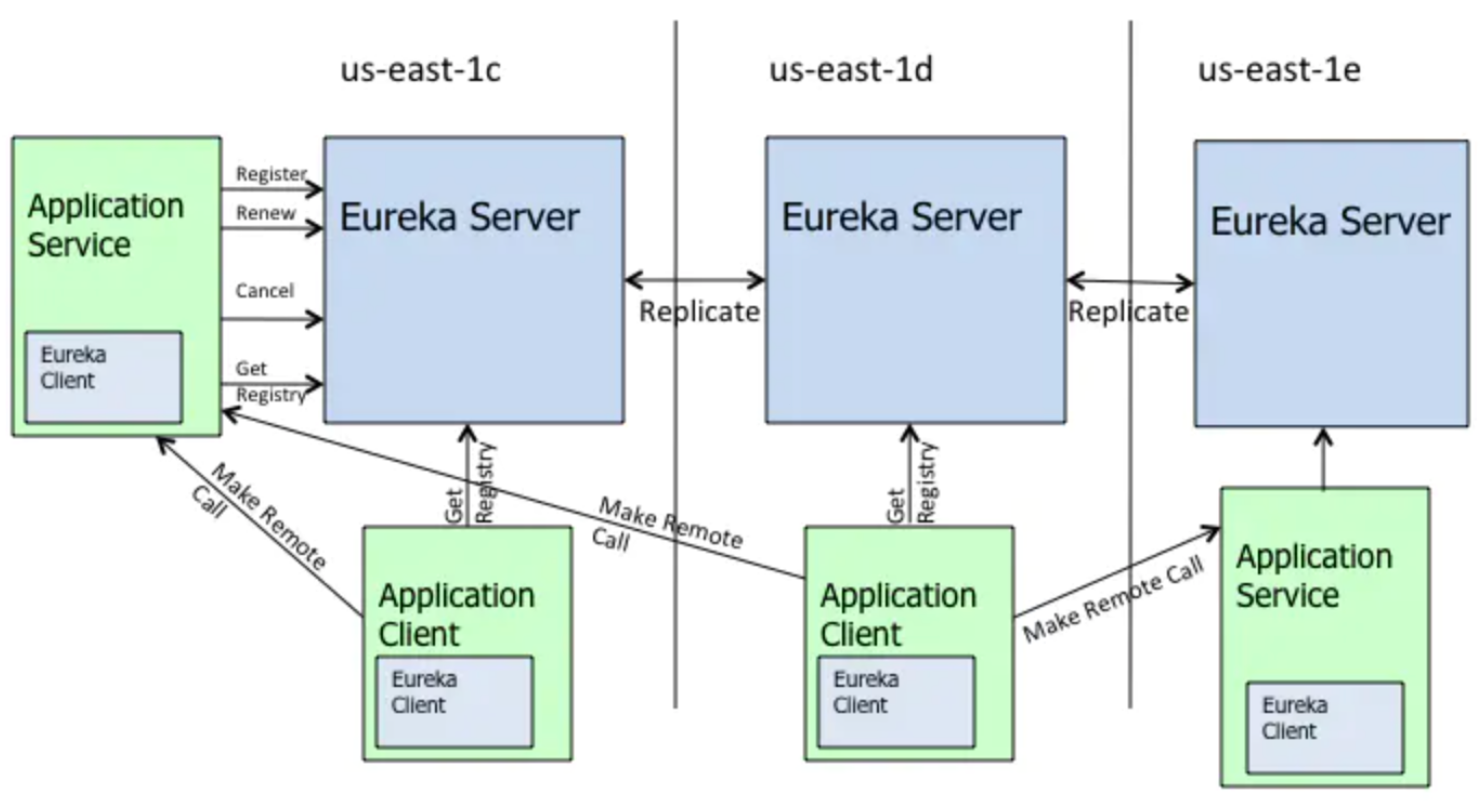
在CAP原则中,Eureka是典型的AP架构原则,整个系统架构设计都是围绕这高可用来做,并且大量使用缓存机制来保证系统的SLA。
1、在Eureka集群中,如果某台服务器宕机,客户端请求会自动切换到新的Eureka节点;当宕机的服务器重新恢复后,Eureka会再次将其纳入到服务器集群管理之中;而对于客户端来说,所有要做的无非是同步一些新的服务注册信息而已。所以,再也不用担心有“掉队”的服务器恢复以后,会从Eureka服务器集群中剔除出去的风险了。Eureka甚至被设计用来应付范围更广的网络分割故障,并实现“0”宕机维护需求。当网络分割故障发生时,每个Eureka节点,会持续的对外提供服务,其接收新的服务注册同时将它们提供给下游的服务发现请求。这样一来,就可以实现在同一个子网中,新发布的服务仍然可以被发现与访问。
2、正常配置下,Eureka内置了心跳服务,用于淘汰一些“濒死”的服务器;如果在Eureka中注册的服务,它的“心跳”变得迟缓时,Eureka会将其整个剔除出管理范围。这是个很好的功能,但是当网络分割故障发生时,这也是非常危险的;因为,那些因为网络问题(注:心跳慢被剔除了)而被剔除出去的服务器本身是很”健康“的,只是因为网络分割故障把Eureka集群分割成了独立的子网而不能互访而已。幸运的是,Netflix考虑到了这个缺陷。如果Eureka服务节点在短时间里丢失了大量的心跳连接(注:可能发生了网络故障),那么这个Eureka节点会进入”自我保护模式“,同时保留那些“心跳死亡“的服务注册信息不过期。此时,这个Eureka节点对于新的服务还能提供注册服务,对于”死亡“的仍然保留,以防还有客户端向其发起请求。当网络故障恢复后,这个Eureka节点会退出”自我保护模式“。所以Eureka的哲学是,同时保留”好数据“与”坏数据“总比丢掉任何”好数据“要更好,所以这种模式在实践中非常有效。
3、Eureka还有客户端缓存功能(注:Eureka分为客户端程序与服务器端程序两个部分,客户端程序负责向外提供注册与发现服务接口)。所以即便Eureka集群中所有节点都失效,或者发生网络分割故障导致客户端不能访问任何一台Eureka服务器;Eureka服务的消费者仍然可以通过Eureka客户端缓存来获取现有的服务注册信息。甚至最极端的环境下,所有正常的Eureka节点都不对请求产生相应,也没有更好的服务器解决方案来解决这种问题时,Eureka的客户端缓存机制,消费者服务仍然可以通过Eureka客户端查询与获取注册服务信息。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号