第一次个人编程作业
一、作业提交与作业链接
二、计算模块接口的设计与实现过程
(1)真不戳,学计算机真不戳
从看题目开始就想着下班,实在没辙了,还是继续上班吧为了我的晚餐。
(2)开头
首先是面向百度编程,🔍文本查重➡🔍文本相似度
其中看到了不少方法:TF-IDF、Jaro、余弦、BM25等
突然发现,是不是哪里出了什么问题?噢,原来我都没法复制写代码呀。
于是我才开始整编译器,下了又卸了,反反复复终于找到了anacoda3和pycharm。
(3)中间
终于可以面向百度开始了,奈何网上的代码压根儿没有看得懂的。
改变策略:面向百度编程➡面向大佬编程
终于,在询问大佬有关于余弦和bm25等算法后,初步选择了tf-idf。
为了分词的方便用了will哥的代码,但是这也导致了我在输出的时候没法获得相应结果。
再回头看看各位大佬的博客,最后还是选择了杰卡德,用的人不止一个而且还挺不戳,开始行动。
①首先是处理文本使之只剩下汉字
def change(file):
def is_chinese(uchar):
if uchar >= u'\u4e00' and uchar <= u'\u9fa5':
return True
else:
return False
str = ''
for char in file:
if is_chinese(char):
str = str + char
return str
此后便是jieba分词,此处不多介绍
②接下来是杰卡德相似度
#用sklearn的CountVectorizer使文本的词语转换为词频矩阵
cv = CountVectorizer(tokenizer=lambda s: s.split())
#语料库
corpus = [s0, s1]
#使用fit_transform函数计算各个词语出现的次数
vectors = cv.fit_transform(corpus).toarray()
#并集
denominator = numpy.sum(numpy.max(vectors, axis=0))
#交集
numerator = numpy.sum(numpy.min(vectors, axis=0))
#计算杰卡德相似指数
return 1.0 * numerator / denominator
(4)效果
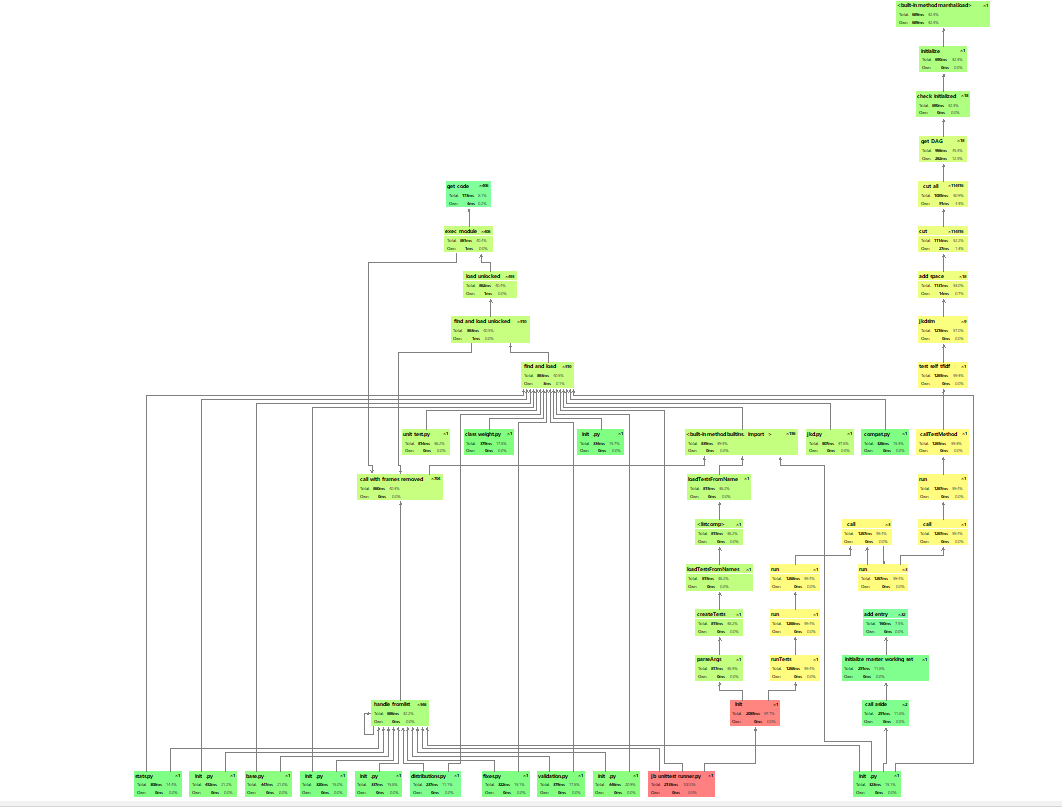
总耗时我还是觉得很好的(毕竟得到很多帮助少走很多弯路) 
四、计算模块部分单元测试展示
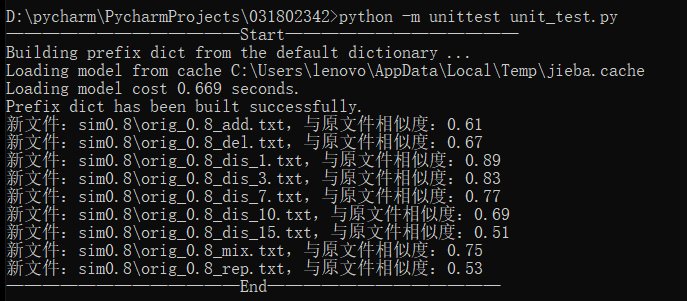
事实上阿天的成绩并不理想,碰巧看到了will哥的解说才知道怎么整这个命令行
五、PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时 | 实际耗时 |
|---|---|---|---|
| Plannning | 计划 | 60 | 90 |
| · Estimate | · 估计这个任务需要多少时间 | 30 | 50 |
| · Development | · 开发 | 360 | 480 |
| · Analysis | · 需求分析 (包括学习新技术) | 120 | 180 |
| · Design Spec | · 生成设计文档 | 30 | 50 |
| · Design Review | · 设计复审 | 30 | 30 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 60 | 90 |
| · Design | · 具体设计 | 120 | 200 |
| · Coding | · 具体编码 | 360 | 500 |
| · Code Review | · 代码复审 | 120 | 120 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 120 | 30 |
| Reporting | 报告 | 90 | 60 |
| · Test Repor | · 测试报告 | 60 | 60 |
| · Size Measurement | · 计算工作量 | 30 | 30 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 20 | 30 |
| · 合计 | 1610 | 2000 |
六、总结
还有部分内容没完成到时候还得再跟进
明显静不下心来,总想着下班到时候真下班就白给了
代码能力一如既往的弱
自己的搜索能力又提升了一个层次

 浙公网安备 33010602011771号
浙公网安备 33010602011771号