
大数据之Apache Sqoop
Apache Sqoop,是在Hadoop生态体系和RDBMS体系之间传送数据的一种工具。来自于Apache软件基金会提供。
Sqoop工作机制是将导入或导出命令翻译成mapreduce程序来实现。在翻译出的mapreduce中主要是对inputformat和outputformat进行定制。
Hadoop生态系统包括:HDFS、Hive、Hbase等
RDBMS体系包括:Mysql、Oracle、DB2等
Sqoop可以理解为:“SQL 到 Hadoop 和 Hadoop 到SQL”。
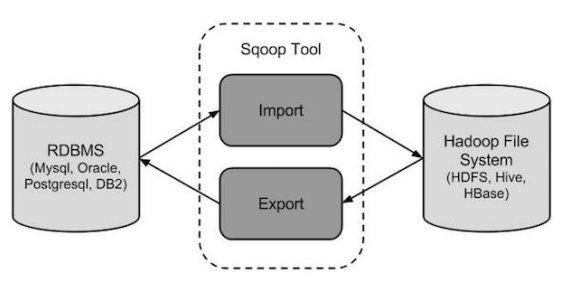
站在Apache立场看待数据流转问题,可以分为数据的导入导出:
Import:数据导入。RDBMS----->Hadoop
Export:数据导出。Hadoop---->RDBMS
1. sqoop安装
安装sqoop的前提是已经具备java和hadoop的环境。
最新稳定版: 1.4.6
配置文件修改:
1 cd /export/servers/sqoop/conf 2 mv sqoop-env-template.sh sqoop-env.sh 3 vi sqoop-env.sh 4 export HADOOP_COMMON_HOME= /export/servers/hadoop-2.7.5 5 export HADOOP_MAPRED_HOME= /export/servers/hadoop-2.7.5 6 export HIVE_HOME= /export/servers/hive
加入mysql的jdbc驱动包
1 cp /hive/lib/mysql-connector-java-5.1.32.jar /export/servers/sqoop/lib/
验证启动
1 bin/sqoop list-databases \ 2 --connect jdbc:mysql://node03:3306/ \ 3 --username root --password 123456
本命令会列出所有mysql的数据库。
到这里,整个Sqoop安装工作完成。
2.Sqoop导入
“导入工具”导入单个表从RDBMS到HDFS。表中的每一行被视为HDFS的记录。所有记录都存储为文本文件的文本数据,下面的语法用于将数据导入HDFS。
1 $ sqoop import (generic-args) (import-args)
2.1. 全量导入mysql表数据到HDFS
下面的命令用于从MySQL数据库服务器中的emp表导入HDFS。
1 bin/sqoop import \ 2 #指定导入的目标数据库信息 3 --connect jdbc:mysql://node-1:3306/userdb \ 4 --username root \ 5 --password 123456\ 6 #如果存在目标文件夹,就删除,否则创建 7 --delete-target-dir \ 8 #指定导入到的目标文件夹 9 --target-dir /sqoopresult \ 10 #指定要导出的表 11 --table emp 12 #指定启动几个Mapreduce 13 --m 1
其中--target-dir可以用来指定导出数据存放至HDFS的目录;
为了验证在HDFS导入的数据,请使用以下命令查看导入的数据:
hdfs dfs -cat /sqoopresult/part-m-00000
可以看出它会在HDFS上默认用逗号,分隔emp表的数据和字段。可以通过
--fields-terminated-by '\t'来指定分隔符。
3. 全量导入mysql表数据到HIVE
3.1. 方式一:先复制表结构到hive中再导入数据
将关系型数据的表结构复制到hive中
1 #Sqoop操作指令,创建hivetable 2 bin/sqoop create-hive-table \ 3 #指定MySQL连接方式,与要导出的表名 4 --connect jdbc:mysql://node-1:3306/sqoopdb \ 5 --table emp_add \ 6 --username root \ 7 --password hadoop \ 8 #导入到的Hive数仓中的表,格式是数据库名.表名 9 --hive-table test.emp_add_sp
从关系数据库导入文件到hive中
#Sqoop操作指令--导入 bin/sqoop import \ #设置数据源MySQL的连接方式与表名 --connect jdbc:mysql://node-1:3306/sqoopdb \ --username root \ --password hadoop \ --table emp_add \ #导入到Hive的指定表信息 --hive-table test.emp_add_sp \ #hive的操作方式,导入 --hive-import \ --m 1
3.2. 方式二:直接复制表结构数据到hive中
1 #Sqoop操作方式 导入 2 bin/sqoop import \ 3 #指定数据源信息MySQL连接方式与要导出的表 4 --connect jdbc:mysql://node-1:3306/userdb \ 5 --username root \ 6 --password hadoop \ 7 --table emp_conn \ 8 #hive的操作方式 以及要导入到的数据库,不用指定表因为直接创建一个一模一样数据结构的表 9 --hive-import \ 10 --m 1 \ 11 --hive-database test;
4. 导入表数据子集(where过滤)
--where可以指定从关系数据库导入数据时的查询条件。它执行在数据库服务器相应的SQL查询,并将结果存储在HDFS的目标目录。
1 bin/sqoop import \ 2 --connect jdbc:mysql://node-1:3306/sqoopdb \ 3 --username root \ 4 --password hadoop \ 5 #where语句就是根据指定的数据源然后直接跟上where语句查出指定结果集导入到目标表 6 --where "city ='sec-bad'" \ 7 --target-dir /wherequery \ 8 --table emp_add --m 1
5. 导入表数据子集(query查询)
注意事项:
使用query sql语句来进行查找不能加参数--table ;
并且必须要添加where条件;
并且where条件后面必须带一个$CONDITIONS 这个字符串;
并且这个sql语句必须用单引号,不能用双引号;
1 bin/sqoop import \ 2 --connect jdbc:mysql://node-1:3306/userdb \ 3 --username root \ 4 --password hadoop \ 5 --target-dir /wherequery12 \ 6 #后面的$CONDITIONS是固定写法,必须有 7 --query 'select id,name,deg from emp WHERE id>1203 and $CONDITIONS' \ 8 #根据id进行分区跟下面的MapReduce进行对应 9 --split-by id \ 10 --fields-terminated-by '\t' \ 11 --m 2
sqoop命令中,--split-by id通常配合-m 10参数使用。用于指定根据哪个字段进行划分并启动多少个maptask。
6. 增量导入
在实际工作当中,数据的导入,很多时候都是只需要导入增量数据即可,并不需要将表中的数据每次都全部导入到hive或者hdfs当中去,这样会造成数据重复的问题。因此一般都是选用一些字段进行增量的导入, sqoop支持增量的导入数据。
增量导入是仅导入新添加的表中的行的技术。
--check-column (col)
用来指定一些列,这些列在增量导入时用来检查这些数据是否作为增量数据进行导入,和关系型数据库中的自增字段及时间戳类似。
注意:这些被指定的列的类型不能使任意字符类型,如char、varchar等类型都是不可以的,同时-- check-column可以去指定多个列。
--incremental (mode)
append:追加,比如对大于last-value指定的值之后的记录进行追加导入。lastmodified:最后的修改时间,追加last-value指定的日期之后的记录
--last-value (value)
指定自从上次导入后列的最大值(大于该指定的值),也可以自己设定某一值
6.1. Append模式增量导入
1 bin/sqoop import \ 2 --connect jdbc:mysql://node-1:3306/userdb \ 3 --username root --password hadoop \ 4 --table emp --m 1 \ 5 --target-dir /appendresult \ 6 #指定增量导入的模式 7 --incremental append \ 8 #指定根据什么字段进行判断是否是新增加的数据 9 --check-column id \ 10 #指定最后一次导入的指定字段的数据 11 --last-value 1205
6.2. Lastmodified模式增量导入
1 bin/sqoop import \ 2 --connect jdbc:mysql://node-1:3306/userdb \ 3 --username root \ 4 --password hadoop \ 5 --table customertest \ 6 --target-dir /lastmodifiedresult \ 7 #指定根据什么字段判断是否是新增数据 8 --check-column last_mod \ 9 #设置导入模式为最后修改模式 10 --incremental lastmodified \ 11 #设置最后一次修改时间,但是不要直接复制最后数据库的修改时间否则会最后一条数据重复,应该在数据库最后修改时间上加一秒钟或者一分钟 12 --last-value "2014-02-28 18:42:06" \ 13 --m 1 \ 14 --append
这是因为采用lastmodified模式去处理增量时,会将大于等于last-value值的数据当做增量插入。
6.3. Lastmodified模式:append、merge-key
使用lastmodified模式进行增量处理要指定增量数据是以append模式(附加)还是merge-key(合并)模式添加
1 bin/sqoop import \ 2 --connect jdbc:mysql://node-1:3306/userdb \ 3 --username root \ 4 --password hadoop \ 5 --table customertest \ 6 --target-dir /lastmodifiedresult \ 7 --check-column last_mod \ 8 --incremental lastmodified \ 9 --last-value "2014-02-28 18:42:06" \ 10 --m 1 \ 11 #根据什么字段进行合并,一般是根据主键ID 12 --merge-key id
由于merge-key模式是进行了一次完整的mapreduce操作,
因此最终我们在lastmodifiedresult文件夹下可以看到生成的为part-r-00000这样的文件,会发现id=1的name已经得到修改,同时新增了id=6的数据。
7. Sqoop导出
将数据从Hadoop生态体系导出到RDBMS数据库导出前,目标表必须存在于目标数据库中。
export有三种模式:
-
- 默认操作是从将文件中的数据使用INSERT语句插入到表中。
- 更新模式:Sqoop将生成UPDATE替换数据库中现有记录的语句。
- 调用模式:Sqoop将为每条记录创建一个存储过程调用。
以下是export命令语法:
$ sqoop export (generic-args) (export-args)
7.1. 默认模式导出HDFS数据到mysql
默认情况下,sqoop export将每行输入记录转换成一条INSERT语句,添加到目标数据库表中。如果数据库中的表具有约束条件(例如,其值必须唯一的主键列)并且已有数据存在,则必须注意避免插入违反这些约束条件的记录。如果INSERT语句失败,导出过程将失败。此模式主要用于将记录导出到可以接收这些结果的空表中。通常用于全表数据导出。
导出时可以是将Hive表中的全部记录或者HDFS数据(可以是全部字段也可以部分字段)导出到Mysql目标表。要先创建好MySQL的表。
1 #Sqoop导出模式 2 bin/sqoop export \ 3 #设置mysql链接信息 4 --connect jdbc:mysql://node-1:3306/userdb \ 5 --username root \ 6 --password hadoop \ 7 #要导入到mysql的表 8 --table employee \ 9 #从哪个文件夹下的文件进行导出 10 --export-dir /emp/emp_data
7.2. 相关配置参数
--input-fields-terminated-by '\t'
指定文件中的分隔符
--columns
选择列并控制它们的排序。当导出数据文件和目标表字段列顺序完全一致的时候可以不写。否则以逗号为间隔选择和排列各个列。没有被包含在–columns后面列名或字段要么具备默认值,要么就允许插入空值。否则数据库会拒绝接受sqoop导出的数据,导致Sqoop作业失败
--export-dir 导出目录,在执行导出的时候,必须指定这个参数,同时需要具备--table或--call参数两者之一,--table是指的导出数据库当中对应的表,
--call是指的某个存储过程。
--input-null-string --input-null-non-string
如果没有指定第一个参数,对于字符串类型的列来说,“NULL”这个字符串就回被翻译成空值,如果没有使用第二个参数,无论是“NULL”字符串还是说空字符串也好,对于非字符串类型的字段来说,这两个类型的空串都会被翻译成空值。比如:
--input-null-string "\\N" --input-null-non-string "\\N"
7.3. 更新导出(updateonly模式)
7.3.1. 参数说明
-- update-key,更新标识,即根据某个字段进行更新,例如id,可以指定多个更新标识的字段,多个字段之间用逗号分隔。
-- updatemod,指定updateonly(默认模式),仅仅更新已存在的数据记录,不会插入新纪录。
1 bin/sqoop export \ 2 --connect jdbc:mysql://node-1:3306/userdb \ 3 --username root --password hadoop \ 4 #指定导入到的mysql表 5 --table updateonly \ 6 --export-dir /updateonly_2/ \ 7 #指定更新标识 8 --update-key id \ 9 #指定更新导出模式 10 --update-mode updateonly
7.4. 更新导出(allowinsert模式)
7.4.1. 参数说明
-- update-key,更新标识,即根据某个字段进行更新,例如id,可以指定多个更新标识的字段,多个字段之间用逗号分隔。
-- updatemod,指定allowinsert,更新已存在的数据记录,同时插入新纪录。实质上是一个insert & update的操作。
1 bin/sqoop export \ 2 --connect jdbc:mysql://node-1:3306/userdb \ 3 --username root --password hadoop \ 4 #指定mysql的接收表 5 --table allowinsert \ 6 #指定从hive的哪个文件夹进行导出 7 --export-dir /allowinsert_2/ \ 8 #指定更新标识字段 9 --update-key id \ 10 #指定更新导出模式 11 --update-mode allowinsert
8.Sqoop job作业
8.1. job 语法
$ sqoop job (generic-args) (job-args)
[-- [subtool-name] (subtool-args)]
$ sqoop-job (generic-args) (job-args)
[-- [subtool-name] (subtool-args)]
8.2. 创建job
1 #指定Sqoop的操作模式Job 2 bin/sqoop job \ 3 #设置job的名称 4 --create skyjob \ 5 #Job的操作模式为import 6 -- import \ 7 #设置mysql的链接信息 8 --connect jdbc:mysql://node-1:3306/userdb \ 9 --username root \ 10 --password hadoop \ 11 #导入到hdfs的指定文件夹 12 --target-dir /sqoopresult333 \ 13 #指定导出的table 14 --table emp --m 1
注意import前要有空格
8.3. 验证job
‘--list’ 参数是用来验证保存的作业。下面的命令用来验证保存Sqoop作业的列表。
1 bin/sqoop job --list
8.4. 检查job
‘--show’ 参数用于检查或验证特定的工作,及其详细信息。以下命令和样本输出用来验证一个名为skyjob的作业。
1 bin/sqoop job --show skyjob
8.5. 执行job
‘--exec’ 选项用于执行保存的作业。下面的命令用于执行保存的作业称为itcastjob。
1 bin/sqoop job --exec skyjob
8.6. 免密执行job
sqoop在创建job时,使用--password-file参数,可以避免输入mysql密码,如果使用--password将出现警告,并且每次都要手动输入密码才能执行job,sqoop规定密码文件必须存放在HDFS上,并且权限必须是400。并且检查sqoop的sqoop-site.xml是否存在如下配置:
1 <property> 2 <name>sqoop.metastore.client.record.password</name> 3 <value>true</value> 4 <description>If true, allow saved passwords in the metastore. 5 </description> 6 </property>
1 bin/sqoop job \ 2 --create itcastjob1 \ 3 -- import \ 4 --connect jdbc:mysql://cdh-1:3306/userdb \ 5 --username root \ 6 #密码存放的路径 7 --password-file /input/sqoop/pwd/skymysql.pwd \ 8 --target-dir /sqoopresult333 \ 9 --table emp --m 1
以上就是Sqoop的相关内容,明天又是个晴天。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号