
使用 C++ 的 StringBuilder 提升 4350% 的性能
使用 C++ 的 StringBuilder 提升 4350% 的性能
英文原文:4350% Performance Improvement with the StringBuilder for C++!
IntroductionIt always starts with a phone call from an irate customer. You're given a program that instead of running, crawls. You check the usual suspects: file IO, database access, even Web service calls: all this, to no avail. You use your favorite profiling tool, which tells you that the culprit is a tiny little function, that writes a long list of strings to a text file. You improve this function by concatenating all the strings into a long one and writing it all in a single operation, instead of hundreds or thousands of writes of a few bytes each. No cigar. You measure how long it takes to write to the file. It's lightning fast. Then, you measure how long it takes to concatenate all the strings. Ages. What's going on? And how can you solve it? You know that .NET programmers use a class named StringBuilder for this purpose. That's a starting point. |
译者信息
介绍经常出现客户端打电话抱怨说:你们的程序慢如蜗牛。你开始检查可能的疑点:文件IO,数据库访问速度,甚至查看web服务。 但是这些可能的疑点都很正常,一点问题都没有。 你使用最顺手的性能分析工具分析,发现瓶颈在于一个小函数,这个函数的作用是将一个长的字符串链表写到一文件中。 你对这个函数做了如下优化:将所有的小字符串连接成一个长的字符串,执行一次文件写入操作,避免成千上万次的小字符串写文件操作。 这个优化只做对了一半。 你先测试大字符串写文件的速度,发现快如闪电。然后你再测试所有字符串拼接的速度。 好几年。 怎么回事?你会怎么克服这个问题呢? 你或许知道.net程序员可以使用StringBuilder来解决此问题。这也是本文的起点。 |
|
BackgroundIf you google "C++ StringBuilder", you'll find quite a few answers. Some of them suggest usingstd::accumulate, which almost does what you need: #include <iostream>// for std::cout, std::endl
#include <string> // for std::string
#include <vector> // for std::vector
#include <numeric> // for std::accumulate
int main()
{
using namespace std;
vector<string> vec = { "hello", " ", "world" };
string s = accumulate(vec.begin(), vec.end(), s);
cout << s << endl; // prints 'hello world' to standard output.
return 0;
}
So far, so good: the problem begins when you have more than a few strings to concatenate, and memory reallocations start to pile up. std::stringprovides the infrastructure for a solution, in functionreserve(). It is meant for our purpose exactly: allocate once, concatenate at will. String concatenation may hit performance ruthlessly with a heavy, blunt instrument. Having some old scars from the last time this particular beast bit me, I fired up Indigo (I wanted to play with some of the shiny new toys in C++11), and typed this partial implementation of aStringBuilder: // Subset of http://msdn.microsoft.com/en-us/library/system.text.stringbuilder.aspx
template <typename chr>
class StringBuilder {
typedef std::basic_string<chr> string_t;
typedef std::list<string_t> container_t; // Reasons not to use vector below.
typedef typename string_t::size_type size_type; // Reuse the size type in the string.
container_t m_Data;
size_type m_totalSize;
void append(const string_t &src) {
m_Data.push_back(src);
m_totalSize += src.size();
}
// No copy constructor, no assignement.
StringBuilder(const StringBuilder &);
StringBuilder & operator = (const StringBuilder &);
public:
StringBuilder(const string_t &src) {
if (!src.empty()) {
m_Data.push_back(src);
}
m_totalSize = src.size();
}
StringBuilder() {
m_totalSize = 0;
}
// TODO: Constructor that takes an array of strings.
StringBuilder & Append(const string_t &src) {
append(src);
return *this; // allow chaining.
}
// This one lets you add any STL container to the string builder.
template<class inputIterator>
StringBuilder & Add(const inputIterator &first, const inputIterator &afterLast) {
// std::for_each and a lambda look like overkill here.
// <b>Not</b> using std::copy, since we want to update m_totalSize too.
for (inputIterator f = first; f != afterLast; ++f) {
append(*f);
}
return *this; // allow chaining.
}
StringBuilder & AppendLine(const string_t &src) {
static chr lineFeed[] { 10, 0 }; // C++ 11. Feel the love!
m_Data.push_back(src + lineFeed);
m_totalSize += 1 + src.size();
return *this; // allow chaining.
}
StringBuilder & AppendLine() {
static chr lineFeed[] { 10, 0 };
m_Data.push_back(lineFeed);
++m_totalSize;
return *this; // allow chaining.
}
// TODO: AppendFormat implementation. Not relevant for the article.
// Like C# StringBuilder.ToString()
// Note the use of reserve() to avoid reallocations.
string_t ToString() const {
string_t result;
// The whole point of the exercise!
// If the container has a lot of strings, reallocation (each time the result grows) will take a serious toll,
// both in performance and chances of failure.
// I measured (in code I cannot publish) fractions of a second using 'reserve', and almost two minutes using +=.
result.reserve(m_totalSize + 1);
// result = std::accumulate(m_Data.begin(), m_Data.end(), result); // This would lose the advantage of 'reserve'
for (auto iter = m_Data.begin(); iter != m_Data.end(); ++iter) {
result += *iter;
}
return result;
}
// like javascript Array.join()
string_t Join(const string_t &delim) const {
if (delim.empty()) {
return ToString();
}
string_t result;
if (m_Data.empty()) {
return result;
}
// Hope we don't overflow the size type.
size_type st = (delim.size() * (m_Data.size() - 1)) + m_totalSize + 1;
result.reserve(st);
// If you need reasons to love C++11, here is one.
struct adder {
string_t m_Joiner;
adder(const string_t &s): m_Joiner(s) {
// This constructor is NOT empty.
}
// This functor runs under accumulate() without reallocations, if 'l' has reserved enough memory.
string_t operator()(string_t &l, const string_t &r) {
l += m_Joiner;
l += r;
return l;
}
} adr(delim);
auto iter = m_Data.begin();
// Skip the delimiter before the first element in the container.
result += *iter;
return std::accumulate(++iter, m_Data.end(), result, adr);
}
}; // class StringBuilder
|
译者信息
背景如果google一下“C++ StringBuilder”,你会得到不少答案。有些会建议(你)使用std::accumulate,这可以完成几乎所有你要实现的: #include <iostream>// for std::cout, std::endl
#include <string> // for std::string
#include <vector> // for std::vector
#include <numeric> // for std::accumulate
int main()
{
using namespace std;
vector<string> vec = { "hello", " ", "world" };
string s = accumulate(vec.begin(), vec.end(), s);
cout << s << endl; // prints 'hello world' to standard output.
return 0;
}
目前为止一切都好:当你有超过几个字符串连接时,问题就出现了,并且内存再分配也开始积累。
std::string在函数reserver()中为解决方案提供基础。这也正是我们的意图所在:一次分配,随意连接。 字符串连接可能会因为繁重、迟钝的工具而严重影响性能。由于上次存在的隐患,这个特殊的怪胎给我制造麻烦,我便放弃了Indigo(我想尝试一些C++11里的令人耳目一新的特性),并写了一个StringBuilder类的部分实现: // Subset of http://msdn.microsoft.com/en-us/library/system.text.stringbuilder.aspx
template <typename chr>
class StringBuilder {
typedef std::basic_string<chr> string_t;
typedef std::list<string_t> container_t; // Reasons not to use vector below.
typedef typename string_t::size_type size_type; // Reuse the size type in the string.
container_t m_Data;
size_type m_totalSize;
void append(const string_t &src) {
m_Data.push_back(src);
m_totalSize += src.size();
}
// No copy constructor, no assignement.
StringBuilder(const StringBuilder &);
StringBuilder & operator = (const StringBuilder &);
public:
StringBuilder(const string_t &src) {
if (!src.empty()) {
m_Data.push_back(src);
}
m_totalSize = src.size();
}
StringBuilder() {
m_totalSize = 0;
}
// TODO: Constructor that takes an array of strings.
StringBuilder & Append(const string_t &src) {
append(src);
return *this; // allow chaining.
}
// This one lets you add any STL container to the string builder.
template<class inputIterator>
StringBuilder & Add(const inputIterator &first, const inputIterator &afterLast) {
// std::for_each and a lambda look like overkill here.
// <b>Not</b> using std::copy, since we want to update m_totalSize too.
for (inputIterator f = first; f != afterLast; ++f) {
append(*f);
}
return *this; // allow chaining.
}
StringBuilder & AppendLine(const string_t &src) {
static chr lineFeed[] { 10, 0 }; // C++ 11. Feel the love!
m_Data.push_back(src + lineFeed);
m_totalSize += 1 + src.size();
return *this; // allow chaining.
}
StringBuilder & AppendLine() {
static chr lineFeed[] { 10, 0 };
m_Data.push_back(lineFeed);
++m_totalSize;
return *this; // allow chaining.
}
// TODO: AppendFormat implementation. Not relevant for the article.
// Like C# StringBuilder.ToString()
// Note the use of reserve() to avoid reallocations.
string_t ToString() const {
string_t result;
// The whole point of the exercise!
// If the container has a lot of strings, reallocation (each time the result grows) will take a serious toll,
// both in performance and chances of failure.
// I measured (in code I cannot publish) fractions of a second using 'reserve', and almost two minutes using +=.
result.reserve(m_totalSize + 1);
// result = std::accumulate(m_Data.begin(), m_Data.end(), result); // This would lose the advantage of 'reserve'
for (auto iter = m_Data.begin(); iter != m_Data.end(); ++iter) {
result += *iter;
}
return result;
}
// like javascript Array.join()
string_t Join(const string_t &delim) const {
if (delim.empty()) {
return ToString();
}
string_t result;
if (m_Data.empty()) {
return result;
}
// Hope we don't overflow the size type.
size_type st = (delim.size() * (m_Data.size() - 1)) + m_totalSize + 1;
result.reserve(st);
// If you need reasons to love C++11, here is one.
struct adder {
string_t m_Joiner;
adder(const string_t &s): m_Joiner(s) {
// This constructor is NOT empty.
}
// This functor runs under accumulate() without reallocations, if 'l' has reserved enough memory.
string_t operator()(string_t &l, const string_t &r) {
l += m_Joiner;
l += r;
return l;
}
} adr(delim);
auto iter = m_Data.begin();
// Skip the delimiter before the first element in the container.
result += *iter;
return std::accumulate(++iter, m_Data.end(), result, adr);
}
}; // class StringBuilder
|
|
The interesting bitsFunctionToString()usesstd::string::reserve()to minimize reallocations. Below you can see the results of a performance test. Functionjoin()usesstd::accumulate(), with a custom functor that uses the fact that its first operand has already reserved memory. You may ask: whystd::listinstead ofstd::vectorforStringBuilder::m_Data? It is common practice to usestd::vectorunless you have a good reason to use another container. Well, I have two:
|
译者信息
有趣的部分函数ToString()使用std::string::reserve()来实现最小化再分配。下面你可以看到一个性能测试的结果。 函数join()使用std::accumulate(),和一个已经为首个操作数预留内存的自定义函数。 你可能会问,为什么StringBuilder::m_Data用std::list而不是std::vector?除非你有一个用其他容器的好理由,通常都是使用std::vector。 好吧,我(这样做)有两个原因: 1. 字符串总是会附加到一个容器的末尾。std::list允许在不需要内存再分配的情况下这样做;因为vector是使用一个连续的内存块实现的,每用一个就可能导致内存再分配。 2. std::list对顺序存取相当有利,而且在m_Data上所做的唯一存取操作也是顺序的。 你可以建议同时测试这两种实现的性能和内存占用情况,然后选择其中一个。 |
|
Measuring performanceTo test performance, I picked a page from Wikipedia, and hard-coded a vector of strings with part of the contents. Then, I wrote two test functions. The first one uses the standard functionclock()and callsstd::accumulate()andStringBuilder::ToString()in two loops, then prints the results. void TestPerformance(const StringBuilder<wchar_t> &tested, const std::vector<std::wstring> &tested2) {
const int loops = 500;
clock_t start = clock(); // Give up some accuracy in exchange for platform independence.
for (int i = 0; i < loops; ++i) {
std::wstring accumulator;
std::accumulate(tested2.begin(), tested2.end(), accumulator);
}
double secsAccumulate = (double) (clock() - start) / CLOCKS_PER_SEC;
start = clock();
for (int i = 0; i < loops; ++i) {
std::wstring result2 = tested.ToString();
}
double secsBuilder = (double) (clock() - start) / CLOCKS_PER_SEC;
using std::cout;
using std::endl;
cout << "Accumulate took " << secsAccumulate << " seconds, and ToString() took " << secsBuilder << " seconds."
<< " The relative speed improvement was " << ((secsAccumulate / secsBuilder) - 1) * 100 << "%"
<< endl;
}
The second one uses the more accurate Posix function clock_gettime(), and also testsStringBuilder::Join()
#ifdef __USE_POSIX199309
// Thanks to <a href="http://www.guyrutenberg.com/2007/09/22/profiling-code-using-clock_gettime/">Guy Rutenberg</a>.
timespec diff(timespec start, timespec end)
{
timespec temp;
if ((end.tv_nsec-start.tv_nsec)<0) {
temp.tv_sec = end.tv_sec-start.tv_sec-1;
temp.tv_nsec = 1000000000+end.tv_nsec-start.tv_nsec;
} else {
temp.tv_sec = end.tv_sec-start.tv_sec;
temp.tv_nsec = end.tv_nsec-start.tv_nsec;
}
return temp;
}
void AccurateTestPerformance(const StringBuilder<wchar_t> &tested, const std::vector<std::wstring> &tested2) {
const int loops = 500;
timespec time1, time2;
// Don't forget to add -lrt to the g++ linker command line.
////////////////
// Test std::accumulate()
////////////////
clock_gettime(CLOCK_THREAD_CPUTIME_ID, &time1);
for (int i = 0; i < loops; ++i) {
std::wstring accumulator;
std::accumulate(tested2.begin(), tested2.end(), accumulator);
}
clock_gettime(CLOCK_THREAD_CPUTIME_ID, &time2);
using std::cout;
using std::endl;
timespec tsAccumulate =diff(time1,time2);
cout << tsAccumulate.tv_sec << ":" << tsAccumulate.tv_nsec << endl;
////////////////
// Test ToString()
////////////////
clock_gettime(CLOCK_THREAD_CPUTIME_ID, &time1);
for (int i = 0; i < loops; ++i) {
std::wstring result2 = tested.ToString();
}
clock_gettime(CLOCK_THREAD_CPUTIME_ID, &time2);
timespec tsToString =diff(time1,time2);
cout << tsToString.tv_sec << ":" << tsToString.tv_nsec << endl;
////////////////
// Test join()
////////////////
clock_gettime(CLOCK_THREAD_CPUTIME_ID, &time1);
for (int i = 0; i < loops; ++i) {
std::wstring result3 = tested.Join(L",");
}
clock_gettime(CLOCK_THREAD_CPUTIME_ID, &time2);
timespec tsJoin =diff(time1,time2);
cout << tsJoin.tv_sec << ":" << tsJoin.tv_nsec << endl;
////////////////
// Show results
////////////////
double secsAccumulate = tsAccumulate.tv_sec + tsAccumulate.tv_nsec / 1000000000.0;
double secsBuilder = tsToString.tv_sec + tsToString.tv_nsec / 1000000000.0;
double secsJoin = tsJoin.tv_sec + tsJoin.tv_nsec / 1000000000.0;
cout << "Accurate performance test:" << endl << " Accumulate took " << secsAccumulate << " seconds, and ToString() took " << secsBuilder << " seconds." << endl
<< " The relative speed improvement was " << ((secsAccumulate / secsBuilder) - 1) * 100 << "%" << endl <<
" Join took " << secsJoin << " seconds."
<< endl;
}
#endif // def __USE_POSIX199309
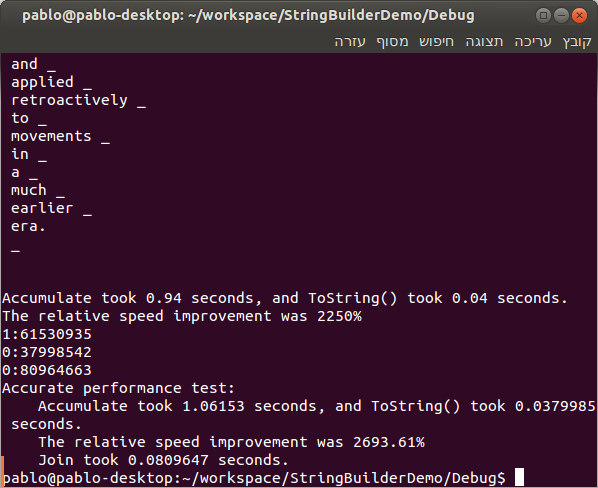
Finally, there is amain()function that calls all others, shows the results on the console, then executes the performance tests: one for the Debug configuration...
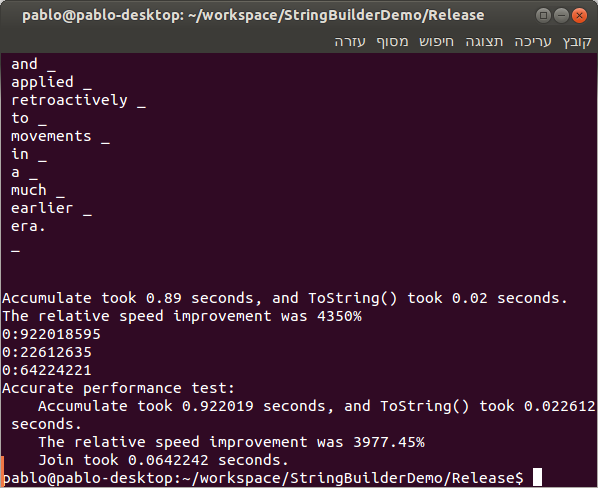
... and one for Release:
See those percentages? Spammers' stocks don't get these numbers! |
译者信息
性能评估为了测试性能,我从Wikipedia获取一个网页,并将其中一部分内容写死到一个string的vector中。 随后,我编写两个测试函数,第一个在两个循环中使用标准函数clock()并调用std::accumulate()和StringBuilder::ToString(),然后打印结果。 void TestPerformance(const StringBuilder<wchar_t> &tested, const std::vector<std::wstring> &tested2) {
const int loops = 500;
clock_t start = clock(); // Give up some accuracy in exchange for platform independence.
for (int i = 0; i < loops; ++i) {
std::wstring accumulator;
std::accumulate(tested2.begin(), tested2.end(), accumulator);
}
double secsAccumulate = (double) (clock() - start) / CLOCKS_PER_SEC;
start = clock();
for (int i = 0; i < loops; ++i) {
std::wstring result2 = tested.ToString();
}
double secsBuilder = (double) (clock() - start) / CLOCKS_PER_SEC;
using std::cout;
using std::endl;
cout << "Accumulate took " << secsAccumulate << " seconds, and ToString() took " << secsBuilder << " seconds."
<< " The relative speed improvement was " << ((secsAccumulate / secsBuilder) - 1) * 100 << "%"
<< endl;
}
第二个则使用更精确的Posix函数clock_gettime(),并测试StringBuilder::Join()。
#ifdef __USE_POSIX199309
// Thanks to <a href="http://www.guyrutenberg.com/2007/09/22/profiling-code-using-clock_gettime/">Guy Rutenberg</a>.
timespec diff(timespec start, timespec end)
{
timespec temp;
if ((end.tv_nsec-start.tv_nsec)<0) {
temp.tv_sec = end.tv_sec-start.tv_sec-1;
temp.tv_nsec = 1000000000+end.tv_nsec-start.tv_nsec;
} else {
temp.tv_sec = end.tv_sec-start.tv_sec;
temp.tv_nsec = end.tv_nsec-start.tv_nsec;
}
return temp;
}
void AccurateTestPerformance(const StringBuilder<wchar_t> &tested, const std::vector<std::wstring> &tested2) {
const int loops = 500;
timespec time1, time2;
// Don't forget to add -lrt to the g++ linker command line.
////////////////
// Test std::accumulate()
////////////////
clock_gettime(CLOCK_THREAD_CPUTIME_ID, &time1);
for (int i = 0; i < loops; ++i) {
std::wstring accumulator;
std::accumulate(tested2.begin(), tested2.end(), accumulator);
}
clock_gettime(CLOCK_THREAD_CPUTIME_ID, &time2);
using std::cout;
using std::endl;
timespec tsAccumulate =diff(time1,time2);
cout << tsAccumulate.tv_sec << ":" << tsAccumulate.tv_nsec << endl;
////////////////
// Test ToString()
////////////////
clock_gettime(CLOCK_THREAD_CPUTIME_ID, &time1);
for (int i = 0; i < loops; ++i) {
std::wstring result2 = tested.ToString();
}
clock_gettime(CLOCK_THREAD_CPUTIME_ID, &time2);
timespec tsToString =diff(time1,time2);
cout << tsToString.tv_sec << ":" << tsToString.tv_nsec << endl;
////////////////
// Test join()
////////////////
clock_gettime(CLOCK_THREAD_CPUTIME_ID, &time1);
for (int i = 0; i < loops; ++i) {
std::wstring result3 = tested.Join(L",");
}
clock_gettime(CLOCK_THREAD_CPUTIME_ID, &time2);
timespec tsJoin =diff(time1,time2);
cout << tsJoin.tv_sec << ":" << tsJoin.tv_nsec << endl;
////////////////
// Show results
////////////////
double secsAccumulate = tsAccumulate.tv_sec + tsAccumulate.tv_nsec / 1000000000.0;
double secsBuilder = tsToString.tv_sec + tsToString.tv_nsec / 1000000000.0;
double secsJoin = tsJoin.tv_sec + tsJoin.tv_nsec / 1000000000.0;
cout << "Accurate performance test:" << endl << " Accumulate took " << secsAccumulate << " seconds, and ToString() took " << secsBuilder << " seconds." << endl
<< " The relative speed improvement was " << ((secsAccumulate / secsBuilder) - 1) * 100 << "%" << endl <<
" Join took " << secsJoin << " seconds."
<< endl;
}
#endif // def __USE_POSIX199309
最后,通过一个main函数调用以上实现的两个函数,将结果显示在控制台,然后执行性能测试:一个用于调试配置。
|
|
Using the codeBefore using the code, consider using ostringstream. As you can see in the comment by mrjeff below, it is faster than the code for this article. You may want to use the code if:
To use the code, just follow what is done inmain(): create an instance of aStringBuilder, fill it usingAppend(),AppendLine()andAdd(), then callToString()to retrieve the result. Like this: int main() {
////////////////////////////////////
// 8-bit characters (ANSI)
////////////////////////////////////
StringBuilder<char> ansi;
ansi.Append("Hello").Append(" ").AppendLine("World");
std::cout << ansi.ToString();
////////////////////////////////////
// Wide characters (Unicode)
////////////////////////////////////
// http://en.wikipedia.org/wiki/Cargo_cult
std::vector<std::wstring> cargoCult
{
L"A", L" cargo", L" cult", L" is", L" a", L" kind", L" of", L" Melanesian", L" millenarian", L" movement",
// many more lines here...
L" applied", L" retroactively", L" to", L" movements", L" in", L" a", L" much", L" earlier", L" era.\n"
};
StringBuilder<wchar_t> wide;
wide.Add(cargoCult.begin(), cargoCult.end()).AppendLine();
// use ToString(), just like .net
std::wcout << wide.ToString() << std::endl;
// javascript-like join.
std::wcout << wide.Join(L" _\n") << std::endl;
////////////////////////////////////
// Performance tests
////////////////////////////////////
TestPerformance(wide, cargoCult);
#ifdef __USE_POSIX199309
AccurateTestPerformance(wide, cargoCult);
#endif // def __USE_POSIX199309
return 0;
}
In any case, beware ofstd::accumulatewhen concatenating more than a handful of strings. |
译者信息
代码使用在使用这段代码前, 考虑使用ostring流。正如你在下面看到Jeff先生评论的一样,它比这篇文章中的代码更快些。 你可能想使用这段代码,如果:
要使用这段代码,只有按照main函数实现的那样就可以了:创建一个StringBuilder的实例,用Append()、AppendLine()和Add()给它赋值,然后调用ToString函数检索结果。 就像下面这样: int main() {
////////////////////////////////////
// 8-bit characters (ANSI)
////////////////////////////////////
StringBuilder<char> ansi;
ansi.Append("Hello").Append(" ").AppendLine("World");
std::cout << ansi.ToString();
////////////////////////////////////
// Wide characters (Unicode)
////////////////////////////////////
// http://en.wikipedia.org/wiki/Cargo_cult
std::vector<std::wstring> cargoCult
{
L"A", L" cargo", L" cult", L" is", L" a", L" kind", L" of", L" Melanesian", L" millenarian", L" movement",
// many more lines here...
L" applied", L" retroactively", L" to", L" movements", L" in", L" a", L" much", L" earlier", L" era.\n"
};
StringBuilder<wchar_t> wide;
wide.Add(cargoCult.begin(), cargoCult.end()).AppendLine();
// use ToString(), just like .net
std::wcout << wide.ToString() << std::endl;
// javascript-like join.
std::wcout << wide.Join(L" _\n") << std::endl;
////////////////////////////////////
// Performance tests
////////////////////////////////////
TestPerformance(wide, cargoCult);
#ifdef __USE_POSIX199309
AccurateTestPerformance(wide, cargoCult);
#endif // def __USE_POSIX199309
return 0;
}
任何情况下,当连接超过几个字符串时,当心std::accumulate函数。 |
|
Now wait a minute!You may ask: Are you trying to sell us premature optimization? I'm not. I agree that premature optimization is bad. This optimization is not premature: it is timely. It is based on experience: I found myself wrestling this particular beast in the past. Optimization based on experience (not stumbling twice on the same stone) is not premature. When we optimize performance, the 'usual suspects' include disk I-O, network access (database, web services), and innermost loops; to these, we should add memory allocation, the Keyser Söze of bad performance. ThanksFirst of all, I'd like to thank Guy Rutenberg, for the code for accurate profiling in Linux. Thanks to Wikipedia, for making the dream of 'information at your fingertips' come true. Thank you for taking the time to read this article. I hope you enjoyed it: in any case, please share your opinion.
|
译者信息
现在稍等一下!你可能会问:你是在试着说服我们提前优化吗? 不是的。我赞同提前优化是糟糕的。这种优化并不是提前的:是及时的。这是基于经验的优化:我发现自己过去一直在和这种特殊的怪胎搏斗。基于经验的优化(不在同一个地方摔倒两次)并不是提前优化。 当我们优化性能时,“惯犯”会包括磁盘I-O操作、网络访问(数据库、web服务)和内层循环;对于这些,我们应该添加内存分配和性能糟糕的 Keyser Söze。 鸣谢首先,我要为这段代码在Linux系统上做的精准分析感谢Rutenberg。 多亏了Wikipedia,让“在指尖的信息”的梦想得以实现。 最后,感谢你花时间阅读这篇文章。希望你喜欢它:不论如何,请分享您的意见。 |



 浙公网安备 33010602011771号
浙公网安备 33010602011771号