什么是应用程序二进制接口ABI【转】
转自:https://zhuanlan.zhihu.com/p/386106883
ABI(Application Binary Interface)
ABI 是编译器和链接器遵守的一组规则,以让编译后的程序可以正常工作。ABI里包含很多方面的内容:
- ABI 最大和最重要的部分是规定函数的调用顺序,也称为“调用约定”。调用约定标准化了如何将“函数”转换为汇编代码。
- ABI 还规定了库中公开函数的name(如printf)应该如何表示,以便在链接后可以正确的调用这些库函数并接收参数。
- ABI 还规定可以使用什么类型的数据类型、它们必须如何对齐以及其他低级细节。
- 此外,ABI还涉及操作系统的内容,如可执行文件的格式,虚拟地址空间布局,还有Program Loading and Dynamic Linking等细节。
当然,如果是以上对ABI的理解,仅仅是“只知其然”。更加重要的“所以然”还需要深入了解其中的一些细节。
深入理解ABI最好的方式当然就是直接查看ABI的标准文档,在Linux Standard Base (LSB)里可以找到一些具体的ABI文档,由于这个页面存在很多的文档链接,所以有必要知晓文档之间的一些关系。下面是LSB网站列出众多参考文档链接的页面,我们主要关注其中用红色方框标记的文档。
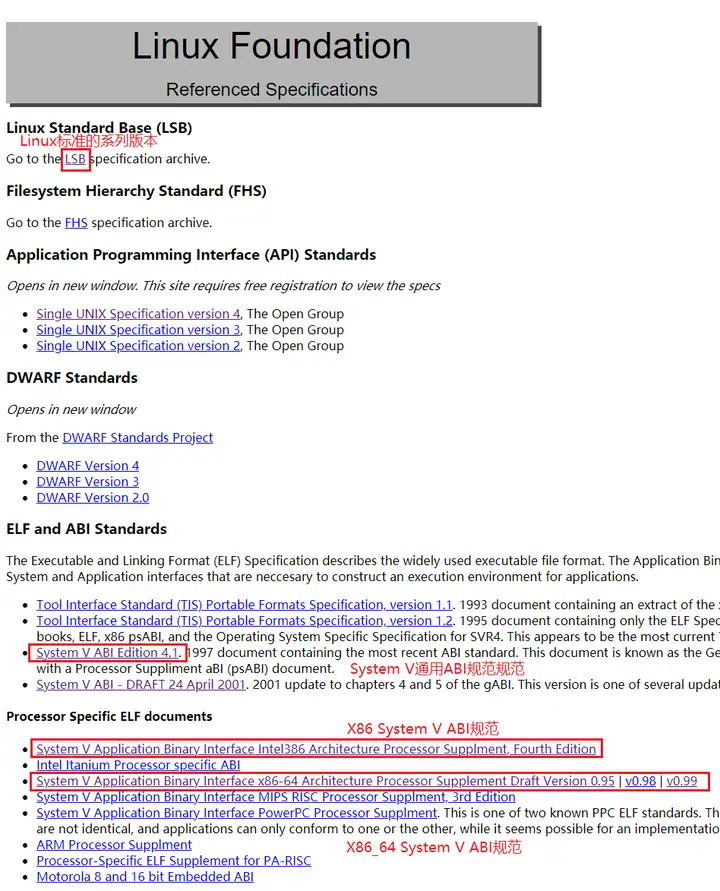
第一个圈出的LSB里指向了Linux标准的系列版本,里面包含了迄今为止Linux制定的标准的各个版本,目前为止最新的版本是LSB 5.0,但我们暂时不需要去看标准中定义的细节。提到这个文档的原因是考虑知识链的完整性。因为Linux的很多标准也不是凭空自己制定的,很多一部分也来自于老大哥UNIX的一些标准,比如Linux ABI标准中的一些内容就是遵循UNIX系统的System V版本所发布的ABI标准。
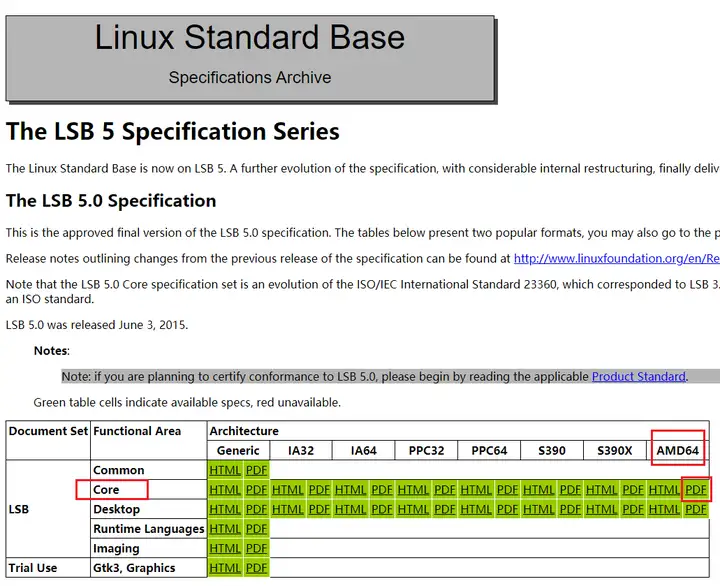
如果我们打开上图中的core/AMD64/PDF,可以在里面看到很多内容都遵循System V ABI中的规范,例如下图所示:

所以我们直接查看System V ABI文档的内容就可以,因为Linux也是遵循这个标准。但是需要说明的是, 由于二进制规范必须包含特定于计算机处理器体系结构的信息,因此一个文档不可能将与所有处理器相关的ABI内容都包含在内。所以,System V ABI严格来说并不是指某个单一的文档,而是一个包含很多规范文档的家族。从组成上来说,System V ABI包含两个基本的部分,一部分是是通用的规范,描述了System V在不同的处理器体系结构实现中保持不变的部分,这部分的内容是由SYSTEM V APPLICATION BINARY INTERFACE Edition 4.1描述,目前是4.1版。另一部分是与处理器体系结构相关的规范,因为涉及到许多不同的处理器体系结构,所以这一部分会有很多的文档,每个文档都是专门用来描述一种特定的处理器体系结构的ABI规范,例如,X86 ABI规范由SYSTEM V APPLICATION BINARY INTERFACE Intel386 Architecture Processor Supplement来描述,而X86_64 ABI的规范由System V Application Binary Interface AMD64 Architecture Processor Supplement来描述。特定于处理器体系结构的ABI规范可以说是对通用ABI规范的补充。在通用ABI规范中涉及到具体的处理器体系结构的内容,都是由第二部分的处理器ABI规范负责补充描述,如下图:

接下来我们就以X86_64的ABI规范为例来查看其ABI文档内包含了哪些内容,并通过简要的阅读其中的部分内容来更好的理解ABI的作用。下图是X86_64 ABI规范的目录,其中我们主要关注红色方框标记出的内容:
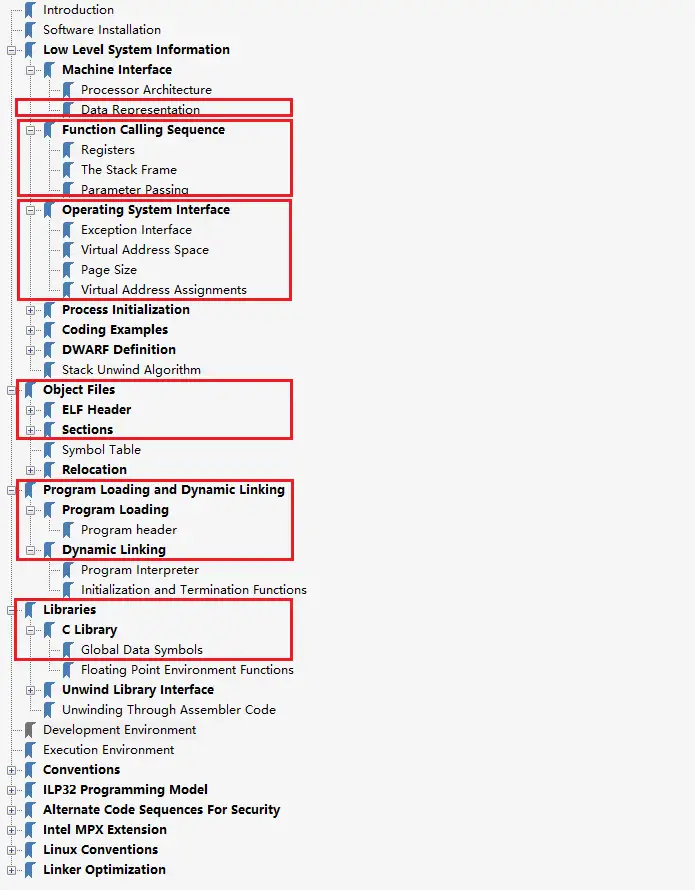
红色标记出的部分是需要关注的内容,接下来就按照红色标记的顺序,在文档中查看这些规范都描述了哪些内容。
Data Representation(数据表示)
Data Representation主要定义了系统基本数据类型的数据宽度,规范中为了描述的方便和准确,特说明在本规范中, byte指的是8位对象,twobyte指的是16位对象,fourbyte指的是32位对象,eightbyte指的是64位对象,sixteenbyte指的是128位对象。定义的系统基本数据类型宽度如下图:
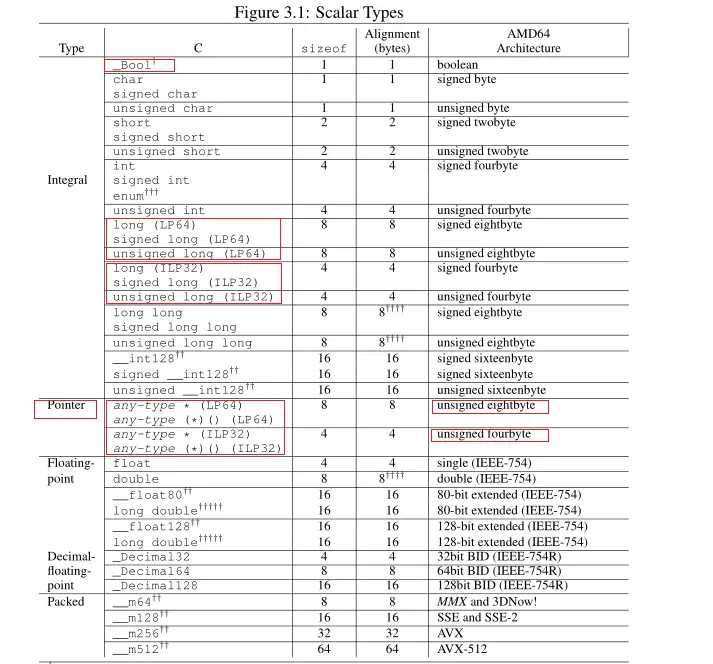
可以看到ABI规范里明确规定了某些数据类型的宽度,在这里面我们还是关注红色标记的类型。
第一个类型是_Bool类型,从C99标准开始,C语言支持布尔类型,类型名字为"_Bool",但是后来C++出现了bool关键字,C99为了让C和C++兼容,增加了一个头文件stdbool.h,里面定义了bool、true、false,让我们可以像C++一样直接使用"bool"来定义布尔类型。X86_64 System V ABI中关于布尔类型是这样描述的: 当存储在内存中时,布尔值被存储为单字节对象(所以布尔类型的变量只占一个字节),其值总是0(假)或1(真)。当存储在整数寄存器中(作为参数传递时除外),寄存器的所有8个字节都是重要的,任何非零值都被认为是真值。
第二个需要关注的类型是long类型。因为这里涉及到两种不同的数据模型,分别是ILP32和LP64。在这两种数据模型里,long类型的宽度是不同的。ILP模型中的"I"代表int类型,L代表"long"类型,P是"Pointer"的意思,代表指针类型,所以ILP32表示的含义是int、long和指针类型的数据宽度是32位的。LP中的"L"同样代表long类型,"P"代表指针类型,所以LP64要求long和指针类型的数据宽度必须是64位的。除了ILP32和LP64外,还有其他的数据模型,如LLP64,这种模型要求long long和指针类型的数据宽度是64位的。各种数据模型对比如下:

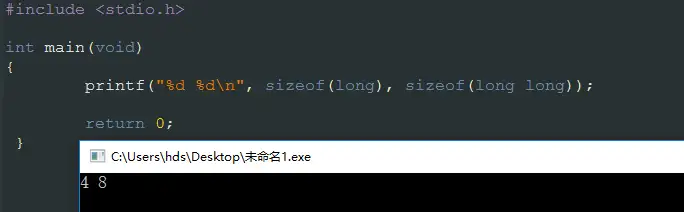
之所以long的数据宽度不一致,是因为标准C中并没有明确规定long类型的长度。在标准C中只规定了长整型(无论无符号或者有符号)至少占用32位,但没有具体说明long宽度。所以在操作系统的ABI中,要明确long类型的宽度。在32位下,Linux和Windows都采用ILP32,但在64位下,Linux采用的是LP64,而Windows采用的是LLP64。所以在Linux下编程,long和long long的宽度都是8个字节,但在Windows下,long是4个字节,long long是8个字节。我们分别在Linux环境和Windows环境里打印long和long long的宽度验证一下:
Windows:
Linux:
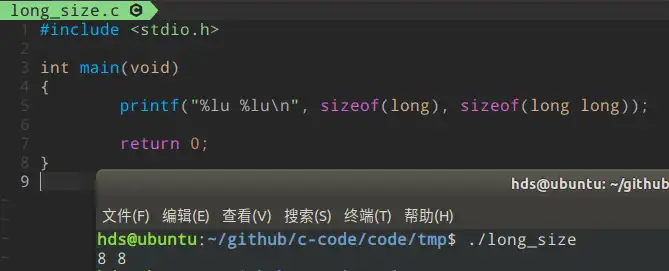
可以看到,Windows采用LLP64,long为4字节,long long为8字节。而Linux采用LP64,所以long为8字节。
同时,System V ABI中还规定了size_t的类型,如下:
The type size_t is defined as unsigned long for LP64 and unsigned int for ILP32.
size_t类型是以字节为单位来计算数据类型长度的。如果系统采用LP64,当我们使用C的sizeof关键字来打印long类型的变量时,其打印格式的占位符就要是"%lu",如果是ILP32,则为"%u"。
对于64位模式,关于不同系统所采用的数据模型和不同数据模型下数据宽度,下图做了一个概要的总结:
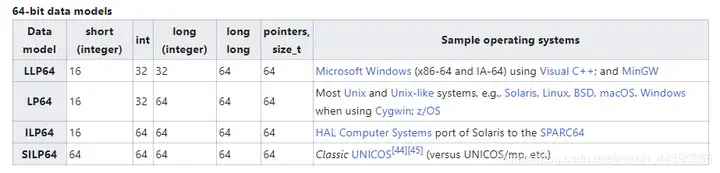
第三个要关注的类型就是指针类型,ILP32是32位系统采用的,所以指针类型是"unsigned fourbyte",即无符号位的4个字节。对于64位系统,Linux采用的是LP64,所以指针类型是"unsigned eightbyte",即无符号位的8个字节。 ABI里还规定了空指针(对于所有类型)的值为零。
总结一下,ABI里关于Data Representation的内容主要就是规定了系统基本数据类型的宽度。
Function Calling Sequence(函数调用约定)
ABI里第二个比较重要的内容就是函数调用序列,其实就是调用约定。函数调用约定里涉及到寄存器怎么使用,参数如何传递(通过堆栈还是用寄存器),谁负责清理堆栈(是调用者清理还是被调用者清理),参数入栈的顺序(从右向左还是其它),栈帧的布局等。调用约定主要是由编译器负责实现的,大概可以理解为下面的过程:
当我们用C语言编写一个函数时,编译器会生成一行汇编代码,如_MyFunction1:,这是一个标签,最终会被汇编程序解析为一个地址(所有的函数名本质都是一个标签地址)。该标签在汇编代码中标记“函数”的“开始”。在C代码中,当我们“调用”这个函数时,底层真正在发生的是让 CPU跳转到该标签的地址并在那里继续执行。
为了准备跳转,编译器必须考虑周全,比如如何为被调用的函数准备参数,跳转之前应该保存哪些东西。如何保证执行完被调用的函数后还能回到之前跳转的地方继续执行。此外,除了跳转之前要做的准备,同样要考虑跳转进入被调用的函数后,要保存哪些东西,怎么接收参数,返回之前又要做哪些清理工作,等等这些内容,其实就是调用约定所规定的。调用约定就像一个清单,编译器遵循它来完成所有这些工作:
- 首先,编译器插入一些汇编代码来保存当前地址,这样当你的“函数”完成后,CPU 就可以返回到跳转之前的地方继续执行。
- 接下来,编译器生成汇编代码以传递参数。一些调用约定规定参数应该放在堆栈上,并且按照从右向左的方向入栈。其他约定规定参数应该放在特定的寄存器中。还有其他约定规定应该使用堆栈和特定寄存器的组合。
- 当然,如果以前这些寄存器中有任何重要的东西,那么这些值现在会被覆盖并永远丢失,因此一些调用约定可能会要求编译器在将参数放入其中之前保存其中的一些寄存器,比如可以可以将要保存的寄存器的值先保存在堆栈上。
- 现在编译器插入一条跳转指令,告诉 CPU 转到它之前创建的标签 (
_MyFunction1:)。此时,CPU就开始执行MyFunction1函数。 - 在函数的最后,编译器会放入一些汇编代码,让 CPU 将返回值写入正确的位置。调用约定将决定返回值是应该放入特定寄存器,还是放入堆栈中。
- 最后要做的就是清理的工作了。调用约定将规定编译器放置清理汇编代码的位置。一些约定要求调用者清理堆栈。这意味着在“函数”完成并且 CPU 跳回到之前的位置后,接下来要执行的代码应该是一些非常具体的清理代码,比如之前如果是通过堆栈将参数传递给被调用的函数,那么现在就将这些空间删除,这种约定属于调用者负责清理堆栈。其他的约定说清理代码的某些特定部分应该在跳回之前位于“函数”的末尾,这种约定属于被调用者清理堆栈。
函数调用约定基本上就是在约定类似于上面的内容,当然这只是形式上的约定,具体的实现则由编译器负责。编译器在实现的时候,遵循的就是函数调用约定里所规定的内容。接下来先看一下System V ABI中对于函数调用约定的具体内容。因为函数调用约定依赖于具体的处理器体系结构,所以在通用的System V ABI中没有函数调用约定的具体内容,需要查看特定于处理器体系结构的System V ABI。因为32位的时代已经过去,所以我们也只关心64位下的函数调用约定,以常见的X86_64体系结构为例,在System V Application Binary Interface AMD64 Architecture Processor Supplement的Function Calling Sequence里描述了X84_64的调用约定。其实调用约定里主要包含了三个内容,寄存器如何使用,栈帧的布局和参数如何传递。
以前的X86只有8个通用寄存器,分别是%eax、%ebx、%ecx、%edx、%esp、%ebp、%esi和%edi。X86_64在原来通用寄存器的基础上扩展了位数外又新增了8个通用寄存器,一共16个64位的通用寄存器,分别是%rax、%rbx、%rcx、%rdx、%rsp、%rbp、%rsi、%rdi、%r8~r15。X86和X86_64寄存器的宽度关系如下图所示:

关于寄存器如何使用,System V ABI里规定了不同寄存器的用途,如下图所示:

简单总结一下:
- %rax:接收函数的返回值。
- %rsp: 堆栈指针%rsp,总是指向最新分配的堆栈帧的末尾。
- %rdi,%rsi,%rdx,%rcx,%r8,%r9传递参数。当Caller调用一个函数的时候,如果向被调函数(Called)传入多个实参,如foo(1,2,3),那么这些寄存器就用来保存这些实参,并且是有顺序的,%rdi保存第一个参数,%rsi保存第二个,以此类推,最多六个可以使用寄存器传递,超出六个的其它参数要使用堆栈传递,并且这些参数是从右向左压入栈中(因为从右向左的顺序利于实现可变参数,下面再细说)。
- %rbp:可选的用作帧指针。可选就是可有可无。这与编译优化有关,%rbp一般被称为帧指针寄存器,用来指向一个新的函数帧的开始处,但这是在没有开启编译优化的情况下%rbp的用途。如果编译时使用了GCC的编译优化,比如-O1,那%rbp就解放了,不再需要它指向栈帧了,所以%rbp和其他的普通寄存器没区别了,可以被当作一个临时的寄存器来使用(后面有实验验证)。
- %rbx,%r10,%r11,%r12,%r13,%14,%15没有特别的规定用途,属于可以随便用的寄存器。但是%rbx、%rbp(用做临时寄存器时)、%12 ~ %r15“属于”调用者, 被调用函数需要保留它们的值。换句话说,被调用的函数必须为其调用者保留这些寄存器的值,也就是被调用函数不能使用这些寄存器。这些寄存器以外的寄存器“属于”被调用的函数。如果调用函数(Caller)想要在函数调用中保留这些寄存器的值,Caller必须将寄存器值保存在它的本地堆栈帧中(后面有例子会看到)。
补充一下,在X86中,因为通用寄存器并不多,所以在X86的调用约定中要求使用堆栈来传递参数。但是X86_64通用寄存器比较多,所以X86_64 System V ABI的调用约定中使用寄存器来传递参数,这样当然会提高性能,因为不需要访问内存堆栈来获取参数。正时因为X86是使用堆栈来传递参数的,所以在一个函数调用结束后,就面临谁来清理用来传递参数的堆栈,也就是调用者(Caller)清理还是被调用者(Called)清理。在X86_64中,虽然使用寄存器来传递参数,但是只有前六个参数可以使用寄存器来传递,超过六个以后的参数同样需要通过堆栈来传递,所以X86_64也会涉及谁负责清理堆栈的问题,但是X86_64 System V ABI规范中没有说明(我在文档中没有看到)谁负责清理堆栈,所以为了验证这个问题,后面会通过实验来观察清理堆栈的行为,来确定堆栈是由调用者(Caller)清理还是被调用者(Called)清理。
什么是栈帧?
C语言属于面向过程语言,它最大特点就是把一个程序分解成若干过程(函数),比如:入口函数是main,然后调用各个子函数。在对应汇编代码中,GCC把过程(函数)转化成栈帧(frame),简单的说,每个栈帧对应一个过程(函数)。在X86_64的典型栈帧结构中,最新分配的堆栈帧实际上包含了两个部分,一个返回地址和当前函数自己的堆栈空间,即一个函数的栈帧 = 返回地址 + 该函数的堆栈空间。但是,返回地址处并不是该函数栈帧开始的地方,%rbp指向的地址才是该函数栈帧真正意义上的起始处,%rsp则始终指向栈帧的末尾,如下图:
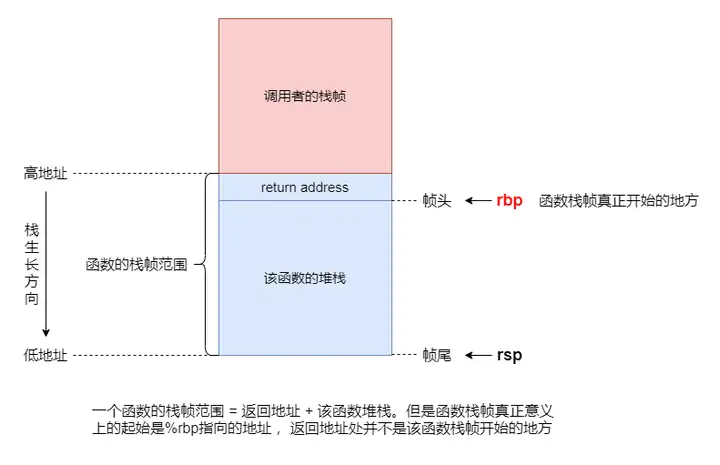
返回地址是call指令的下一条指令的地址。因为当调用call指令去执行另一个函数时要跳转到这个函数执行,在这个函数执行完后,还要继续回来执行call指令后面的指令,所以在去执行新函数之前,要把这个地址保存好。保存的方式就是将call指令的下一条指令地址压入被调函数的栈帧。
栈帧的布局
在X86_64 System V ABI中,定义了栈帧的布局,如下图:
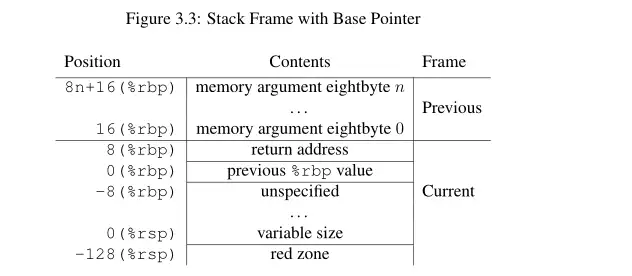
注意:调用函数前的返回地址属于当前新建的栈帧,而不是属于调用者的栈帧。
栈帧的建立
栈帧的建立需要关注调用者和被调用者的栈帧建立过程,因为调用者的栈帧里可以观察调用者如何保存自己的局部变量,和如何为被调用者准备参数。而被调用者的栈帧可以观察被调用者如何接收自己的参数,以及如何销毁自己的堆栈。
下面通过一个例子,将上述函数调用约定的内容应用到实践中,通过观察汇编之后的汇编代码,理解编译器如何实现上述的System V ABI调用约定,并通过分析调用约定理解函数调用过程的具体细节,如何参数传递,栈帧的建立和销毁。一个简单的但可以说明问题的代码示例asm_rsp.c如下:
#include <stdio.h>
int foo(int i)
{
int arry[] = {1, 3, 5};
return arry[i];
}
int main(int argc, char *argv[])
{
int i = 1;
int j = foo(i);
printf("%d %d\n", i, j);
return 0;
}通过汇编命令gcc -S asm_rsp.c -o asm_rsp.s生成汇编程序asm_rsp.s(未启用任何优化)。主要看main函数调用foo函数的过程中,堆栈的变化情况。
下面先以main函数的栈帧建立过程为例。如下是调用者main函数的汇编代码:
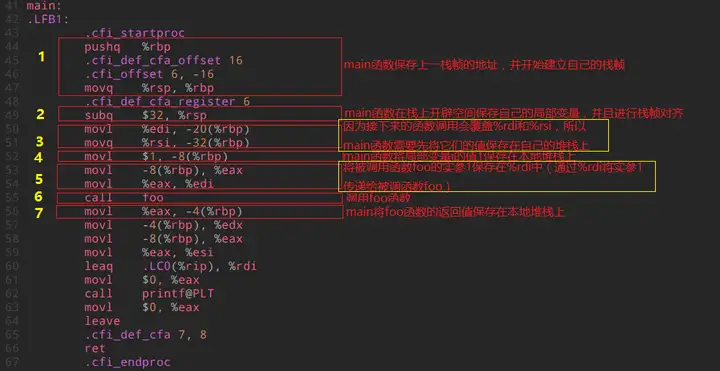
图中简要的写出了main函数栈帧建立过程中的概要描述,并且对于每个关键的步骤进行了标号,分别是1、2、3、4、5、6、7。接下来以图示的方式展示main函数的栈帧建立完整过程。
一个函数被调用后,进入这个函数要做的第一件事就是先保存上一函数的栈帧,然后再保存自己的栈帧。要保存的栈帧地址有两个,但是帧指针寄存器%rbp却只有一个,所以就先将上一函数的栈帧地址保存在自己的堆栈上,然后用%rbp保存自己栈帧的地址。所以对于当前即将要创建的栈帧来说,%rbp始终保存的就是上一个函数栈帧的起始地址。而且这样做有一个好处,因为对即将创建的新栈帧来说%rbp中保存的始终是上一个函数的栈帧开始的地址,所以每次新栈帧中要保存上一栈帧的地址就变的简单,直接将%rbp寄存器中的内容压入堆栈就可以,然后将自己的栈帧地址保存在%rbp,对于接下来的新栈帧亦是如此。这感觉就像多米诺骨牌一样,只要前一个可以撞倒后一个,那么这骨牌就可以一直倒下去,回到函数调用上,就是函数可以一帧一帧的一直调用下去,对每个函数来说,这都是一个通用的做法。
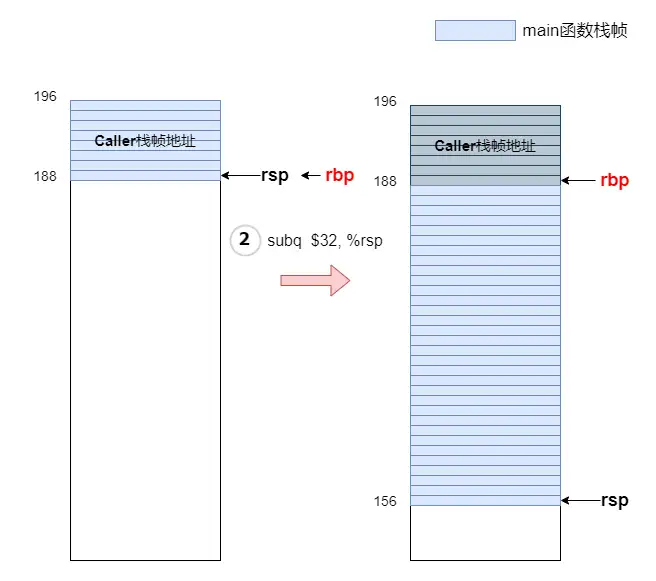
现在回到main函数栈帧的创建上来,下图的过程1表示main函数开始创建自己的栈帧。main先要保存上一栈帧的地址,即将上一栈帧地址压入自己的堆栈,对应的就是汇编指令:pushq %rbp。此时%rsp指向的地址就是main函数栈帧开始的地方了,就是下图中第二个堆栈示意里的地址188。接下来main可以使用%rbp保存自己的栈帧了,因为此时%rsp已经指向了main的栈帧了,所以直接将%rsp的值保存在%rbp就可以了,对应汇编指令:moveq %rsp, %rbp。这个时候%rbp保存的就是main自己的栈帧起始地址,如下图中第三个堆栈示意图:
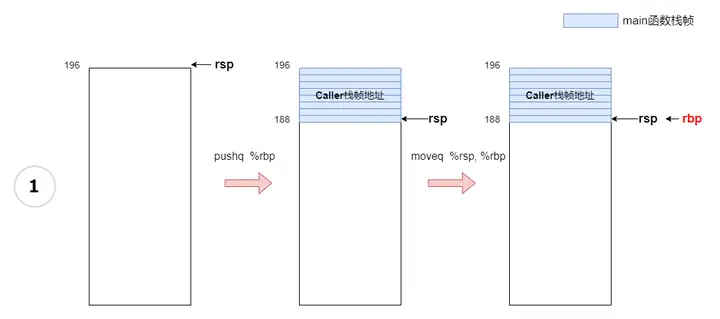
注意%rsp不是向下减少了一个字节,而是减少了8个字节。pushq %rbp可以分解成两步:
subq $8, %rsp # 先将%rsp向下移动8个字节
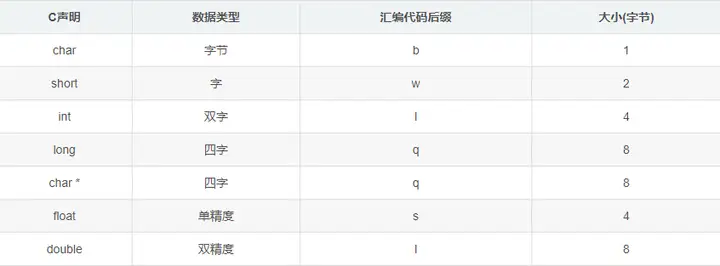
movq %rbp, %rsp # 然后将%rbp中的值复制到%rsp保存的地址处开始往后8个字节的空间内AT&T汇编格式的指令后会跟一个后缀,如movq中,mov指令最后的'q','q'代表quad word(四字),表示数据的尺寸。 '四字'代表8个字节,这是因为Intel将一个'字'定义为16位宽。本身'字'这个含义在早期其实就等同于处理器字长的意思,处理器字长就是处理器内部寄存器的宽度,但是随着32位和64位处理器的出现,'字'不能再等同于处理器字长的意思,所以这里的'字(word)'变成了一个数据单位。那为什么字定义为16位宽?因为Intel是从16位体系结构扩展成32位的,所以早期Intel就用术语"字(word)”表示16位数据类型,并且后来在大多数IA-32处理器特定的文档中也将‘字’定义为16位对象,'双字'定义为32位对象,'四字'定义为64位对象,'双四字'定义为128位对象。因此,称32位数为"双字(double word)",称64位数为"四字(quad word)",现在'字(word)'变成了一个数据单位。下面是我之前总结的一张C语言数据类型与汇编指令中的数据类型对应的表格,如下:
main函数分配自己的栈帧空间:
接下来是被调用者fool函数的汇编代码:(待整理)
栈帧的销毁:(foo函数栈帧的销毁)(待整理)
先写到这里了,时间比较紧,要去写论文了,暂时没时间写完这篇文章了,还有规划的好多内容没写,后面会找时间回来继续写。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号