Linux文件事件监控之Fanotify [二]【转】
转自:https://zhuanlan.zhihu.com/p/206497124
监控流程
上文展示了从sys_open()到fsnotify()之间的call trace,接下来继续追踪在fsnotify()之后的代码路径:
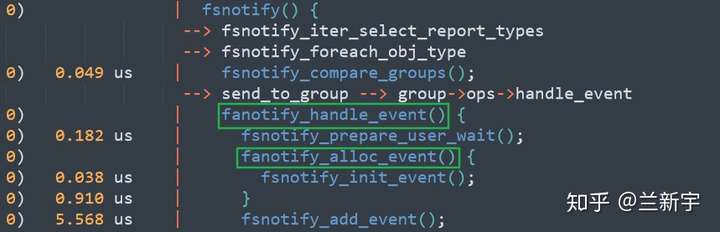
根据ftrace的打印结果,fanotify注册的"handle_event"函数指针会被调用,进而就是通过fanotify_alloc_event(),给要向listerner上报的内容分配内存,并根据和listener约定的事件格式,填写相关的字段:
struct fanotify_event *fanotify_alloc_event(struct fsnotify_group *group,
struct inode *inode, u32 mask, ...)
{
struct fanotify_event *event = kmem_cache_alloc(fanotify_event_cachep, gfp);
fsnotify_init_event(&event->fse, inode); // event->inode = inode;
event->mask = mask;
...
这个约定的事件格式主要是由以下这几部分组成(因为只包含控制信息,而不包含数据信息,所以被称为"metadata"):
struct fanotify_event_metadata {
__u32 event_len;
__aligned_u64 mask;
__s32 fd;
__s32 pid;
...
};
"event_len" 是当前事件的长度(大部分情况下都是定长),"mask" 用于说明发生的是什么事件(包括open/close/read/write),"fd" 代表被监听文件的file descriptor,而"pid" 则是操作被监听文件的进程的编号。自4.20内核引入"FAN_REPORT_TID"这个标志位后,还可以将上报进程PID的行为更改为获取线程的TID。
if (FAN_GROUP_FLAG(group, FAN_REPORT_TID))
event->pid = get_pid(task_pid(current));
else
event->pid = get_pid(task_tgid(current));
大家应该都知道,文件成功open之后,会返回一个文件描述符,可这里文件的open操作被fanotify“劫持”了,还没有完成呢,这个"fd"是怎么来的呢?
此fd实际上是listerner进入内核态后自己创建的(文件描述符这个东西是进程私有的,A进程的fd对B进程来说其实也没有意义),不过在内核态获取fd需要「自力更生」,即调用get_unused_fd_flags()找到一个未使用的文件描述符。
int create_fd(struct fsnotify_group *group, struct fanotify_event *event, struct file **file)
{
int client_fd = get_unused_fd_flags(group->fanotify_data.f_flags);
if (event->path.dentry && event->path.mnt)
struct file *new_file = dentry_open(&event->path,
group->fanotify_data.f_flags | FMODE_NONOTIFY,
current_cred());
return client_fd;
}
同时,fd是给用户态的进程用的,在内核里面,对文件的操作使用的是"struct file",所以对于自行获取的空闲fd,还需要通过fd_install()来把两者关联起来。
struct file *f = NULL;
int fd = create_fd(group, event, &f);
fd_install(fd, f);
【开始等待】
接下来将准备好的上报事件加入notification queue(以下简称"nq"),对于需要等待listener裁决的文件事件,操作文件的进程需要阻塞在这里:

传统的阻塞等待分为两种,其中之一的Interruptible sleep可更快速地响应信号,但是增加了程序编写的难度。在被唤醒的时候,需要检测是等待的事件到来还是被信号打断,如果是被信号打断,则返回"-EINTR",以便用户态程序进一步处理(比如继续睡眠)。
Uninterruptible sleep则消除了这种烦恼,它只会因为事件的到来而被唤醒。但如果等待的事件由于某种原因一直没有发生,就将一直等下去,由于不能被任何信号打断,在这种情况下,你对它可以说是无可奈何。
而这里fanotify用的是2.6.25内核新增的"TASK_KILLABLE"类型,它在其他方面都和uninterruptible sleep一样,但允许被fatal signals(即kill信号)打断。如果陷入异常,可以通过kill信号将其唤醒。
#include <linux/sched.h>
#define TASK_KILLABLE (TASK_WAKEKILL | TASK_UNINTERRUPTIBLE)
【处理事件】
事件已经上报了,接下来就该把舞台的聚光灯转回listener进程了。如果没有在初始化的时候设定"FAN_NONBLOCK",那么listener将采用阻塞读取的方式,直到fanotify的"nq"上有数据产生。在读取的时候,建议使用一个稍大一些的buffer(比如4096字节),这样一次read()调用可以获取多个events,有助于提高效率。
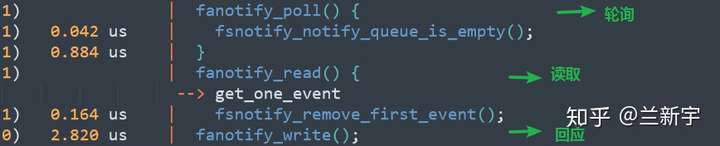
经过对被监控文件的分析,listener将作出放行或者阻止的决定,并通过以下的数据格式,回复给fanotify:
struct fanotify_response {
__s32 fd;
__u32 response;
};
【结束等待】
然后,被监控进程就会被唤醒,"nq"上对应的事件entry使命完成,也将被释放。
finish:
if (fanotify_is_perm_event(mask))
fsnotify_finish_user_wait(iter_info);
至此,一轮监控周期就已完成,现在也可以回答上文提出的那个问题,即为什么有了epoll还需要fanotify。首先,epoll监听的是文件的数据是否ready,它不具备监听文件的open/close事件的能力,此外,epoll也不能对其监听的文件做阻止访问的操作。
可靠性和性能
对于fanotify原理和功能实现的介绍告一段落,回顾整个过程,还有两个问题需要考虑。
- 一是如果fanotify产生事件的速度过快,listener进程来不及处理,那么对于容量有限的"nq"来说,就可能造成缓冲区溢出,进而引起事件丢失的后果。"nq"的大小默认为16384,可通过设置"FAN_UNLIMITED_QUEUE"来解除限制。
但是,如果未处理的事件数量真的过多,解除限制后将加大内存开销,在陷入异常的情况下,甚至可能使内存耗尽。
另外一个面临同样问题的就是配置监听哪些文件和哪些事件的"marks",它的默认值为8192,虽然可以更改为"FAN_UNLIMITED_MARKS"以突破限制,但使用不慎依然面临内存失衡的风险。
- 除了可靠性,性能也是其竞争力的重要一环,而性能问题多半离不开cache。如果listener在上一次已经分析过一个文件,那么当这个文件再次被操作时,fanotify就没有必要再请示listener了。
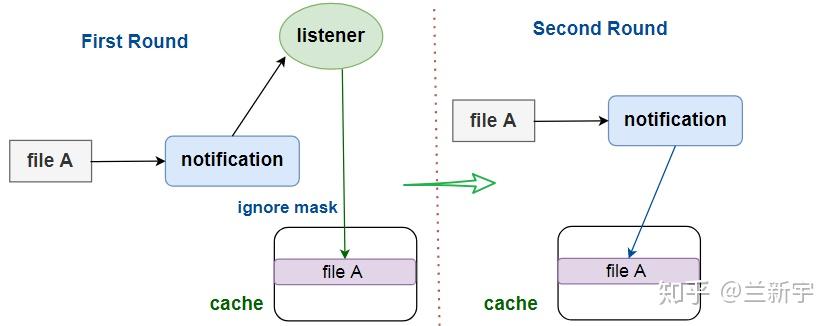
在fanotify中,这是通过listener对文件设置ignore mask来实现的。在同一文件系统内,重命名或移动文件不会改变文件的inode编号,因此其对应的cache entry依然有效。但如果文件的内容发生变化,或者被删除,抑或是移动到了另一文件系统,entry都将会失效。
参考:
原创文章,转载请注明出处。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号