Linux创建线程时 内存分配的那些事【转】
转自:https://blog.csdn.net/Z_Stand/article/details/106444952
文章目录
问题描述
问题分析
针对问题1 的猜测:
针对问题2 的猜测:
原理追踪
总结
问题描述
事情开始于一段内存问题,通过gperf工具抓取进程运行过程中的内存占用情况。
分析结果时发现一个有趣的事情,top看到的实际物理内存只有几兆,但是pprof统计的内存信息却达到了几个G(其实这个问题用gperf heap profiler的选项也能很好的验证想法,但是还是想探索一番)。

很明显是创建线程时产生的内存分配,且最终的分配函数是__pthread_create_2_1,这是当前版本glibc创建线程时的实现函数,且在该函数内进行线程空间的分配。
查看进程代码,发现确实有大量的线程创建,我们知道线程是有自己独立的栈空间,top的 RES统计的是当前进程占用物理内存的情况,也就是当用户进程想要申请物理内存的时候会发出缺页异常,进程切换到内核态,由内核调用对应的系统调用取一部分物理内存加入页表交给用户态进程。这个时候,使用的物理内存的大小才会被计算到RES之中。
回到top数据和pprof抓取的内存数据对不上的问题,难道单独线程的创建并不会占用物理内存?
到现在为止可以梳理出以下几个问题:
线程的创建消耗的内存在哪里? (猜测可能在栈上,因为top的VIRT确实很大)
消耗的内存大小 是如何判断的?(目前还不太清楚,不过以上进程代码是创建了800个线程,算下来平均每个线程的大小是10M了)
问题分析
为了单独聚焦线程创建时的内存分配问题,编写如下的简单测试代码,创建800个线程:
#include <cstdio>
#include <cstdlib>
#include <thread>
void f(long id) {
fprintf(stdout, "create thread %ld\n",id);
sleep(10000);
}
int main()
{
long thread_num = 800; // client thread num
std::vector<std::thread> v;
for (long id = 0;id < thread_num; ++id ) {
std::thread t(f,id);
t.detach();
fprintf(stdout, "exit ...\n");
}
printf("\n");
sleep(4000);
return 0;
}
单纯的创建线程,并不做其他的内存分配操作。
为了抓取该进程的内存分配过程,我们加入gperf工具来运行查看。
#当前shell的环境变量中加入tcmalloc动态库的路径
#如果没有tcmalloc,则yum install gperftools即可
env LD_PRELOAD="/usr/lib/libtcmalloc.so"
#编译加入链接tcmalloc的选项
g++ -std=c++11 test.cpp -pthread -ltcmalloc
#使用会生成heap profile的方式启动进程
#开启只监控mmap,mremap,sbrk的系统调用分配内存的方式,并且ctrl+c停止运行时生成heap文件
HEAPPROFILESIGNAL=2 HEAP_PROFILE_ONLY_MMAP=true HEAP_PROFILE_INUSE_INTERVAL=1024 HEAPPROFILE=./thread ./a.out
进程运行的过程中我们使用pmap查看进程内存空间的分配情况
pmap -X PID
输出信息如下
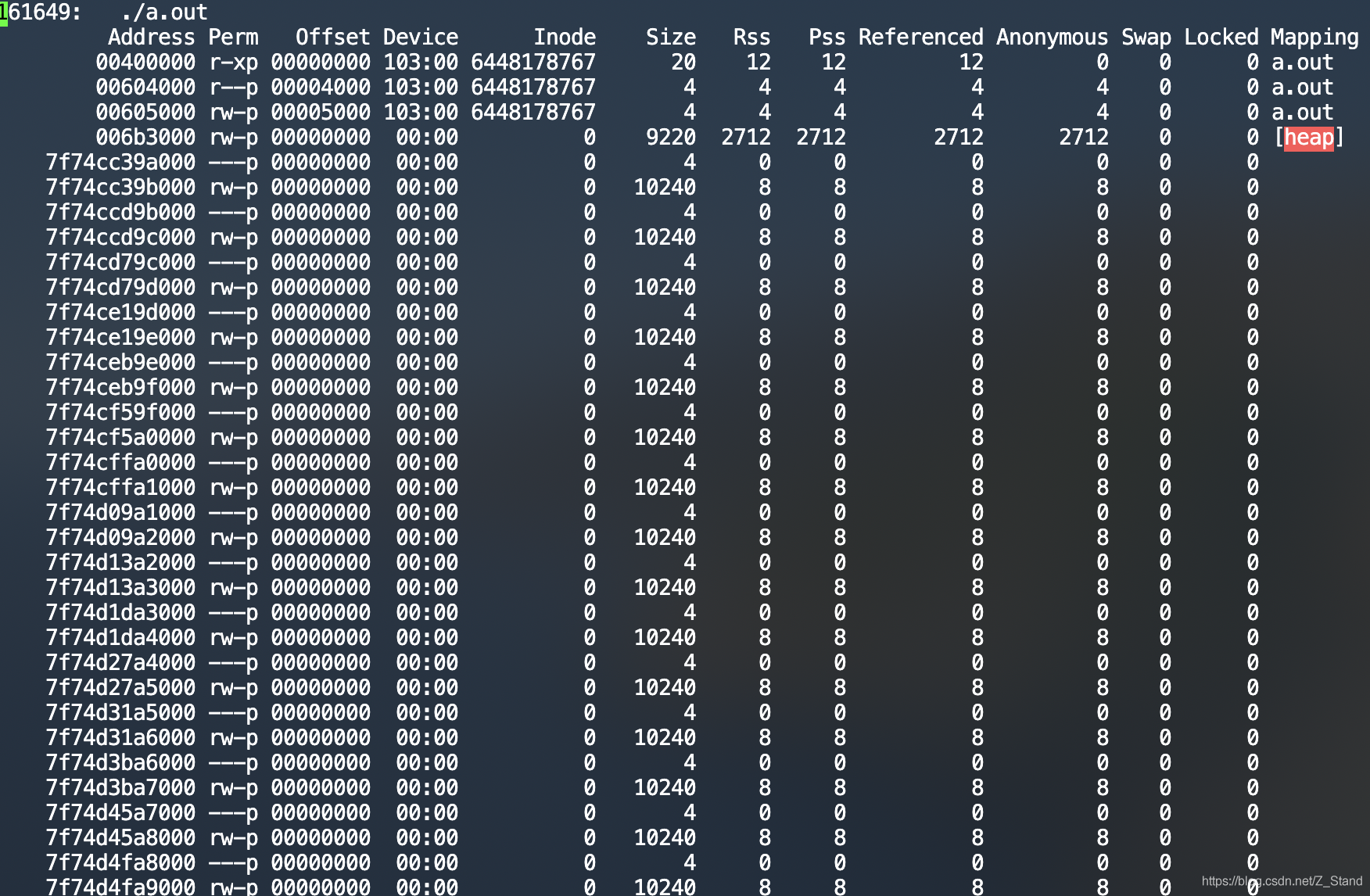
其中:
address为进程的虚拟地址
size为当前字段分配的虚拟内存的大小,单位是KB
Rss为占用的物理内存的大小
Mapping为内存所处的区域
统计了一下size:10240KB 的区域刚好是800个,显然该区域为线程空间。所处的进程内存区域也不在heap上,占用的物理内存大小大小也就是一个指针的大小,8B
使用pmap PID再次查看发现线程的空间都分布在anno区域上,即使用的匿名页的方式

匿名页的描述信息如下:
The amount of anonymous memory is reported for each mapping. Anonymous memory shared with other address spaces is not included, unless the -a option is specified.
Anonymous memory is reported for the process heap, stack, for ‘copy on write’ pages with mappings mapped with MAP_PRIVATE.
即匿名页是使用mmap方式分配的,且会将使用的内存叶标记为MAP_PRIVATE,即仅为进程用户空间独立使用。
针对问题1 的猜测:
到现在为止我们通过工具发现了线程的内存分配貌似是通过mmap,使用匿名页的方式分配出来的,因为匿名页能够和其他进程共享内存空间,所以不会被计入当前进程的物理内存区域。
关于进程的内存分布可以参考进程内存分布,匿名页是在堆区域和栈区域之间的一部分内存区域,pmap的输出我们也能看出来mmapping的那一列。
针对问题2 的猜测:
那为什么会占用10M的虚拟内存呢(size那一列),显然也很好理解了。因为线程是独享自己的栈空间的,所以需要为每个线程开辟属于自己的函数栈空间来保存函数栈帧和局部变量。
ulimit -a能够看到stack size 那一行是属于当前系统默认的进程栈空间的大小。
这里可以通过ulimit -s 2048 将系统的默认分配的栈的大小设置为2M,再次运行程序会发现线程的虚拟内存占用变为了2M
是不是很有趣。
到了这里,我们仅仅是使用工具进行了线程内存的占用分析,但问题并没有追到底层。
原理追踪
我们上面使用了gperf的heap proflie运行了程序,此时我们ctrl+c终端进程之后会在当前目录下生成很多个.heap文件,使用pprof 的svg选项将文件内容导出
pprof --svg a.out thread.0001.heap > thread.svg
将导出的thread.svg放入浏览器中可以看到线程内存占用的一个calltrace,如下(如果程序中链入了glibc以及内核的静态库,估计calltrace会庞大很多):
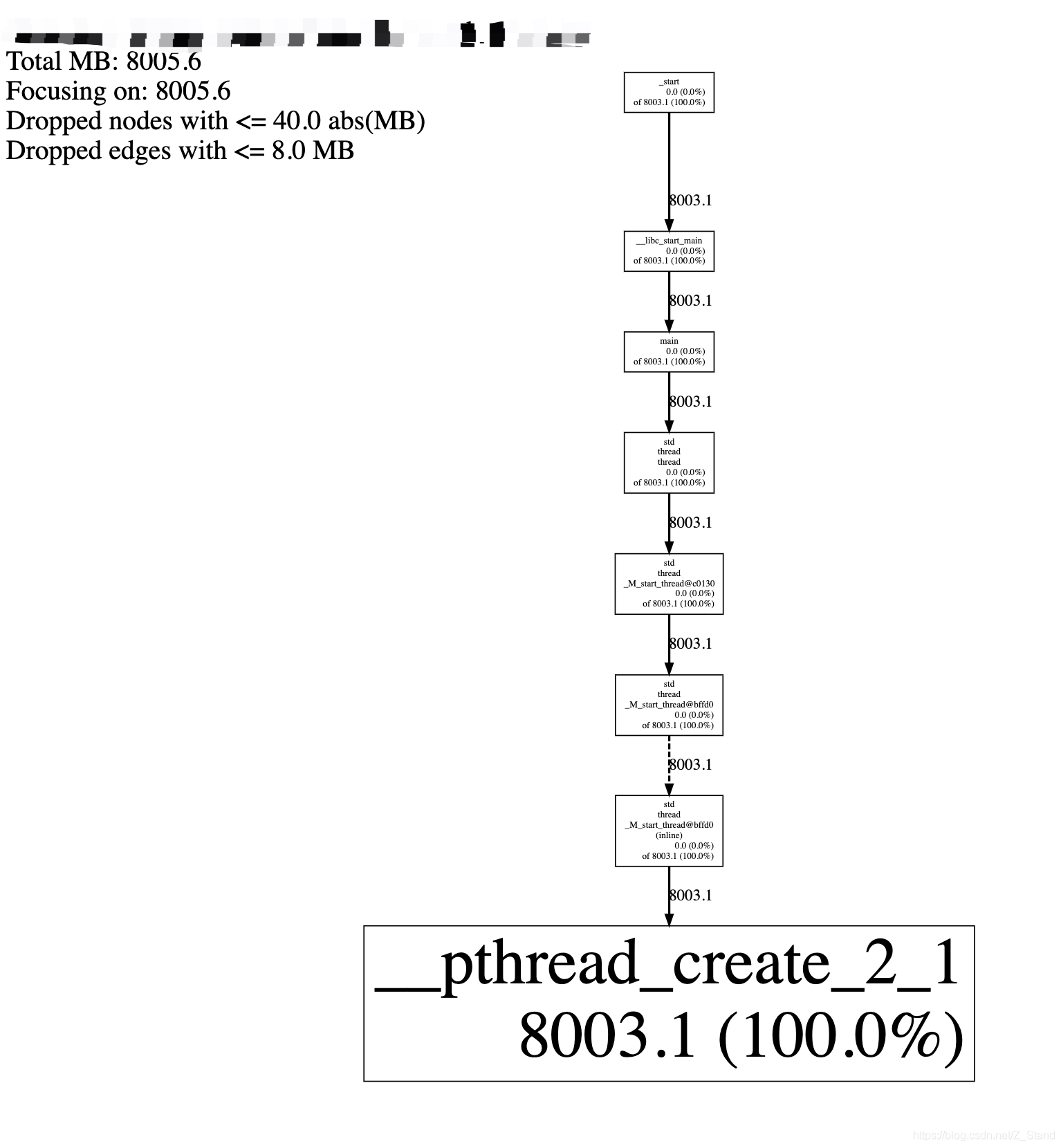
也就是线程创建时的栈空间的分配最终是由函数__pthread_create_2_1分配的。
PS:这里的calltrace 仅仅包括mmap,mremap,sbrk的分配,因为我们在进程运行的时候指定了HEAP_PROFILE_ONLY_MMAP=true 选项,如果各位仅仅想要确认malloc,calloc,realloc等在堆上分配的内存大小可以去掉该选项来运行进程。
输出svg的时候增加pprof的--ignore选项来忽略mmap,sbrk的分配内存,这样的calltrace就没有他们的内存占用了,仅包括堆上的内存占用
pprof --ignore='DoAllocWithArena|SbrkSysAllocator::Alloc|MmapSysAllocator::Alloc' --svg a.out thread.0001.heap > thread.svg
查看glibc的线程创建源码pthread_create.c
函数__pthread_create_2_1 调用ALLOCATE_STACK为线程的数据结构pd分配内存空间。
versioned_symbol (libpthread, __pthread_create_2_1, pthread_create, GLIBC_2_1)
int
__pthread_create_2_1 (newthread, attr, start_routine, arg)
pthread_t *newthread;
const pthread_attr_t *attr;
void *(*start_routine) (void *);
void *arg;
{
......
struct pthread *pd = NULL;
int err = ALLOCATE_STACK (iattr, &pd);
if (__builtin_expect (err != 0, 0)
......
}
ALLOCATE_STACK函数实现入下allocatestack.c:
分配的空间大小会优先从用户设置的pthread_attr属性 attr.stacksize中获取,如果用户进程没有设置stacksize,就会获取系统默认的stacksize的大小。
接下来会调用get_cached_stack函数来获取栈上面可以获得的空间大小size以及所处的虚拟内存空间的地址mem。
最后通过mmap将当前线程所需要的内存叶标记为MAP_PRIVATE和MAP_ANONYMOUS表示当前内存区域仅属于用户进程且被用户进程共享。
详细实现如下:
static int
allocate_stack (const struct pthread_attr *attr, struct pthread **pdp,
ALLOCATE_STACK_PARMS)
{
......
/* Get the stack size from the attribute if it is set. Otherwise we
use the default we determined at start time. */
size = attr->stacksize ?: __default_stacksize;
......
void *mem;
......
/* Try to get a stack from the cache. */
reqsize = size;
pd = get_cached_stack (&size, &mem);
if (pd == NULL)
{
/* To avoid aliasing effects on a larger scale than pages we
adjust the allocated stack size if necessary. This way
allocations directly following each other will not have
aliasing problems. */
#if MULTI_PAGE_ALIASING != 0
if ((size % MULTI_PAGE_ALIASING) == 0)
size += pagesize_m1 + 1;
#endif
/*mmap分配物理内存,并进行内存区域的标记*/
mem = mmap (NULL, size, prot,
MAP_PRIVATE | MAP_ANONYMOUS | MAP_STACK, -1, 0);
if (__builtin_expect (mem == MAP_FAILED, 0))
{
if (errno == ENOMEM)
__set_errno (EAGAIN);
return errno;
}
总结
glibc用户态的调用到最后仍然还是内核态进行实际的物理操作。
至此,关于线程创建时的内存分配追踪就到这里了。我们会发现操作系统的博大精深和环环相扣,使用一个个工具验证自己的猜测, 再从原理发掘前人的设计,这样就会对整个链路有了一个更加深刻的理解。
至于更加底层的内核实现,如何将物理内存与用户进程进行隔离且互不影响,这又是一段庞大复杂的设计链路。有趣的事情很多,慢慢来~
————————————————
版权声明:本文为CSDN博主「z_stand」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/Z_Stand/article/details/106444952

 浙公网安备 33010602011771号
浙公网安备 33010602011771号