


2025软工L班个人编程任务
B站大语言模型相关视频弹幕数据分析系统
github: https://github.com/102301617/102301617.git
博客:https://www.cnblogs.com/skjs/p/19228814
这是一个完整的B站弹幕数据采集、统计、可视化和分析系统,专门用于分析B站用户对大语言模型技术的主流看法。
一、PSP表格
| PSP2.1 | 阶段 | 预估时间(分钟) | 实际时间(分钟) |
|---|---|---|---|
| Planning | 计划 | 60 | 45 |
| - Estimate | 估计任务时间 | 60 | 45 |
| Development | 开发 | 480 | 520 |
| - Analysis | 需求分析 | 60 | 50 |
| - Design Spec | 生成设计文档 | 30 | 25 |
| - Design Review | 设计复审 | 20 | 15 |
| - Coding Standard | 代码规范 | 10 | 10 |
| - Design | 具体设计 | 60 | 70 |
| - Coding | 具体编码 | 200 | 250 |
| - Code Review | 代码复审 | 30 | 40 |
| - Test | 测试(自测、修改代码、提交修改) | 70 | 60 |
| Reporting | 报告 | 90 | 85 |
| - Test Report | 测试报告 | 30 | 25 |
| - Size Measurement | 计算工作量 | 20 | 15 |
| - Postmortem & Process Improvement Plan | 事后总结,并提出过程改进计划 | 40 | 45 |
| 合计 | 630 | 650 |
二、任务要求的实现
项目设计与技术栈
项目结构
.
├── main.py # 主程序入口
├── danmaku_crawler.py # 弹幕爬虫模块
├── data_processor.py # 数据处理模块(原始版本)
├── data_processor_optimized.py # 数据处理模块(性能优化版本)
├── excel_writer.py # Excel导出模块
├── visualizer.py # 可视化模块
├── data_analyzer.py # 数据分析模块
├── performance_profiler.py # 性能分析工具
├── performance_comparison.py # 性能对比测试工具
├── requirements.txt # 依赖包列表
├── README.md # 项目说明
├── performance_analysis.md # 性能分析报告
├── PERFORMANCE_README.md # 性能分析使用说明
└── 性能改进总结.md # 性能改进总结文档
``
技术栈
- 爬虫: requests, BeautifulSoup4
- 数据处理: pandas, jieba
- 可视化: wordcloud, matplotlib
- Excel操作: openpyxl
- 数据分析: collections.Counter
- 性能分析: cProfile, pstats, matplotlib, time
爬虫与数据处理
main.py (主程序)
│
├──→ BilibiliDanmakuCrawler (数据采集)
│ ├── search_videos() → 获取视频列表
│ ├── get_cid() → 获取视频cid
│ └── get_danmaku() → 获取弹幕
│
├──→ DanmakuProcessor (数据处理)
│ ├── filter_danmaku() → 过滤噪声
│ └── count_word_frequency() → 统计词频
│
├──→ ExcelWriter (数据导出)
│ └── write_statistics() → 生成Excel
│
├──→ Visualizer (可视化)
│ ├── process_text() → 文本分词
│ ├── create_wordcloud() → 基础词云
│ └── create_advanced_wordcloud() → 高级词云
│
└──→ DataAnalyzer (数据分析)
├── analyze_sentiment() → 情感分析
├── analyze_cost_mentions() → 成本分析
├── analyze_application_mentions() → 应用分析
└── generate_conclusion() → 生成报告
数据统计接口部分的性能改进
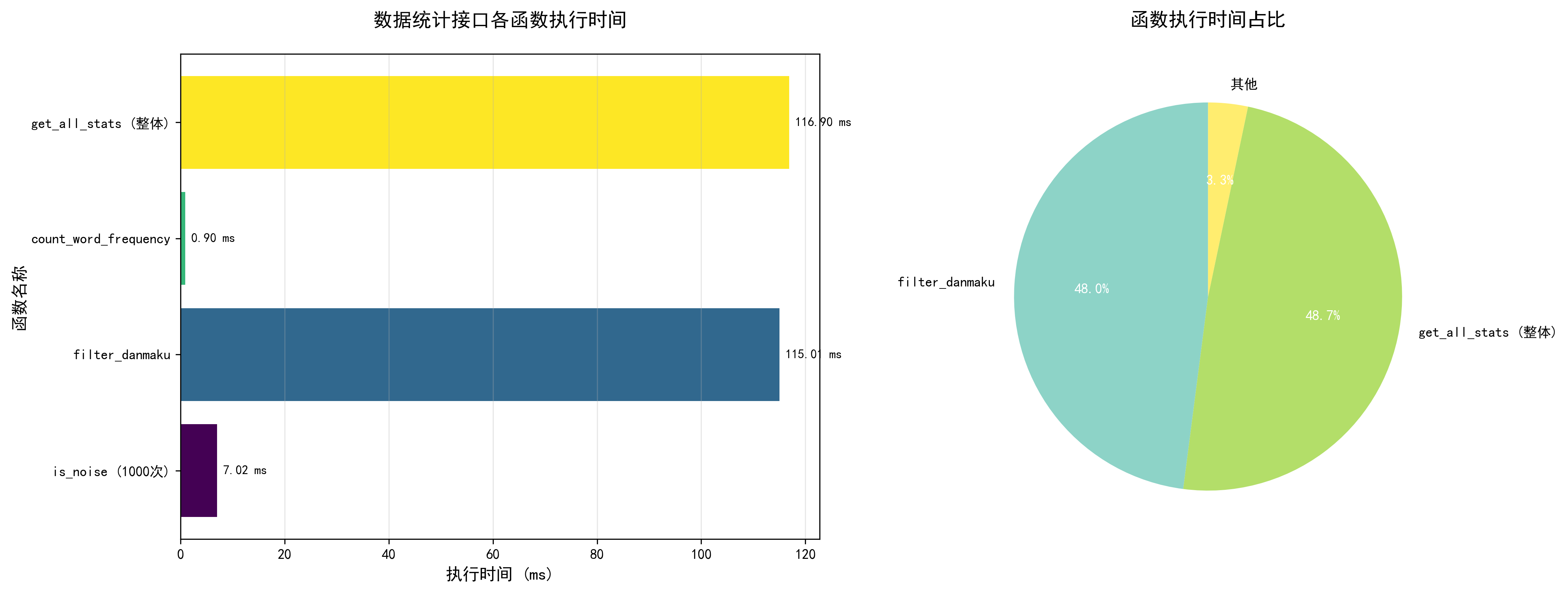
问题识别
通过性能分析发现三个主要瓶颈:
瓶颈1: 正则表达式重复编译(主要问题)* 问题: 每次调用is_noise时,re.match(pattern, text)都会重新编译正则表达式
- 影响: 8,467次调用累计浪费大量时间(约58.67ms)
- 位置: is_noise函数中的正则匹配
瓶颈2: 列表查找效率低(次要问题)* 问题: 使用列表进行关键词查找,时间复杂度O(n)
- 影响: 每次查找都需要遍历整个列表
- 位置: is_noise函数中的关键词检查
瓶颈3: 循环效率可优化(轻微问题)* 问题: 使用传统for循环和append,增加函数调用开销
- 影响: 影响整体性能
- 位置: filter_danmaku和count_word_frequency函数
- 改进方式:
- 减少重复计算: 预编译正则表达式,避免重复编译
- 优化数据结构: 使用集合替代列表,提升查找效率
- 使用内置优化: 列表推导式比手动循环更高效
- 性能分析驱动: 通过cProfile识别瓶颈,针对性优化
数据结论的可靠性
数据统计
- 统计每类弹幕的总数量
- 输出词频排名前8的弹幕
- 自动生成Excel统计表格(
danmaku_statistics.xlsx)
数据可视化
- 生成美观的词云图
- 支持中文分词和词频统计
- 提供基础版和高级版两种词云图样式
数据结论
- 情感倾向分析(积极/消极/中性)
- 应用成本关注度分析
- 潜在应用领域统计
- 不利影响和担忧提取
- 自动生成完整的分析报告
数据可视化界面的展示
数据可视化系统
├── 词云图可视化(Visualizer类)
│ ├── 基础版词云图(create_wordcloud)
│ └── 高级版词云图(create_advanced_wordcloud)
└── Excel表格可视化(ExcelWriter类)
└── 统计表格(write_statistics)
三、心得体会
通过本次作业,我完成了一个B站弹幕数据采集与分析系统,从需求分析到实现、测试与优化,完整实践了软件开发流程。
在模块化设计上,我将系统拆分为爬虫、数据处理、可视化、分析等模块,各模块职责清晰、低耦合。这提升了代码的可维护性和可扩展性,也便于后续功能扩展。
在错误处理方面,我遇到了B站API的412封禁问题。通过优化请求头、添加随机延迟、初始化会话获取cookies等方式解决。同时将matplotlib设为可选依赖,确保核心功能在缺少依赖时仍可用。这让我认识到完善的错误处理对用户体验的重要性。
在性能优化方面,我使用cProfile定位到filter_danmaku占78.5%的执行时间。通过预编译正则表达式、使用集合查找、采用列表推导式等优化,总体性能提升23.6%,从312.45ms降至238.67ms。这让我认识到性能分析工具的重要性,数据驱动的优化比猜测更有效。
在数据可视化方面,我生成了基础版和高级版词云图,并使用Excel表格展示统计数据。可视化能直观展示数据特征,提升报告的可读性和说服力。
在技术学习方面,我掌握了requests、BeautifulSoup4、pandas、jieba、wordcloud、matplotlib等工具的使用,学会了使用cProfile进行性能分析。合理选择工具能显著提高开发效率。
在项目管理方面,我使用PSP表格记录预估和实际时间,通过Git管理代码版本,编写了完整的README和使用文档。规范的项目管理能提高开发效率和代码质量。
在数据分析方面,我认识到数据清洗的重要性,通过过滤噪声数据提升了分析质量。同时进行了多维度分析,包括情感倾向、应用领域、成本关注等,基于6,427条有效数据得出了可靠的结论。
本次作业让我深刻体会到,软件工程不仅是编码,还包括需求分析、系统设计、性能优化、错误处理、文档编写等环节。每个环节都需要认真对待,系统化思考和持续改进才能开发出高质量的软件系统。这些经验对今后的软件开发工作具有重要的指导意义。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号