

相关类可视化图像总结
一、散点图
1.概念
散点图是一种以点的形式表示两个变量之间关系的图表。它通常在二维坐标系中绘制,其中一个变量的值对应横坐标,另一个变量的值对应纵坐标。例如,在研究学生的身高和体重之间的关系时,横坐标可以表示身高(单位:厘米),纵坐标表示体重(单位:千克),每个学生就对应一个点,其位置由身高和体重的数值确定。
2.特点
-
直观展示变量关系:散点图能够直观地展示两个变量之间的相关性。如果点的分布呈现出明显的趋势,比如从左下角到右上角的上升趋势,说明两个变量之间存在正相关关系。例如,随着广告投入费用的增加,产品销售额也增加,散点图上的点就会呈现出这种上升趋势。相反,如果点的分布是从左上角到右下角的下降趋势,说明两个变量之间存在负相关关系。如果点分布得比较杂乱,没有明显的趋势,说明两个变量之间可能没有明显的线性相关关系。
-
可以发现异常值:在散点图中,异常值很容易被识别出来。异常值是指那些明显偏离其他数据点的点。例如,在分析某地区居民收入和消费支出的关系时,大部分居民的收入和消费支出在散点图上呈现出一定的规律,但如果有一个点的收入很高,但消费支出却很低,或者收入很低,但消费支出很高,这个点就可能是异常值。这些异常值可能是数据录入错误,或者是特殊情况,比如某个人有大额的意外收入但没有消费,或者某个人有债务等特殊情况导致消费支出异常。
-
适合多变量分析(扩展到三维或分组):散点图可以通过一些扩展方式来分析多个变量。例如,在三维散点图中,可以增加一个维度来表示第三个变量。或者在二维散点图中,通过颜色、形状等来区分不同的分组。比如在研究不同地区(分组变量)的房价(纵坐标)和人均收入(横坐标)之间的关系时,可以用不同的颜色表示不同的城市,这样可以同时观察到房价和人均收入的关系,以及不同城市之间的差异。
3.应用场景
-
科学研究
-
在物理学中,研究物理量之间的关系时经常用到散点图。例如,研究物体的加速度和作用力之间的关系。通过实验测量不同作用力下物体的加速度,绘制散点图,可以验证牛顿第二定律,即加速度和作用力成正比。
-
在生物学中,可以用来分析生物体的特征之间的关系。比如研究动物的体长和体重之间的关系,通过收集不同动物的体长和体重数据绘制散点图,可以帮助生物学家了解动物体型的生长规律。
-
-
经济学和商业
-
企业可以用散点图来分析销售数据。例如,分析广告支出和产品销量之间的关系。通过绘制散点图,企业可以确定广告投入是否有效,以及在什么程度的广告投入下可以获得较好的销售回报。还可以分析不同产品的价格和销售量之间的关系,以确定产品的定价策略。
-
在宏观经济分析中,可以用来研究不同经济指标之间的关系。比如分析国内生产总值(GDP)增长率和通货膨胀率之间的关系,帮助经济学家制定经济政策。
-
-
社会学和人口学
-
在人口学研究中,可以用来分析人口特征之间的关系。例如,研究人口的年龄和收入之间的关系,或者不同地区的人口密度和生活质量之间的关系。社会学家可以通过散点图来研究社会现象,如教育程度和犯罪率之间的关系,通过收集不同地区的数据绘制散点图,分析是否存在某种趋势,从而为社会政策的制定提供依据。
-
4.代码实现
1 import matplotlib.pyplot as plt 2 import numpy as np 3 4 # 生成随机数据 5 np.random.seed(0) 6 x = np.random.rand(50) 7 y = np.random.rand(50) 8 z = np.random.rand(50) # 第三个变量,用于颜色映射 9 10 # 绘制散点图 11 plt.figure(figsize=(8, 6)) 12 scatter = plt.scatter(x, y, c=z, cmap='viridis', alpha=0.7, label='Random Data') 13 plt.colorbar(scatter, label='Color Scale') # 添加颜色条 14 plt.title('Scatter Plot with Color Mapping') 15 plt.xlabel('X Axis') 16 plt.ylabel('Y Axis') 17 plt.legend() 18 plt.grid(True) 19 plt.show()
二、气泡图
1.概念
气泡图是一种基于散点图的扩展图表类型,它在二维坐标系中通过气泡的位置、大小和颜色来表示多个变量之间的关系。通常,气泡图包含以下三个主要维度:X轴和Y轴变量:这两个维度分别表示两个数值变量,例如销售额和利润;气泡的大小:表示第三个数值变量,例如销售量或市场份额;气泡的颜色(可选):可以表示分类变量或第四个数值变量,例如不同的产品类别或地区。
2.特点
-
多维度数据展示:气泡图能够同时展示多个变量之间的关系,比传统的散点图更具信息量。例如,在分析不同产品的市场表现时,可以同时展示销售额(X轴)、利润(Y轴)、销售量(气泡大小)和产品类别(气泡颜色)。
-
直观性强:气泡的大小和颜色可以直观地反映数据的差异。较大的气泡表示较大的数值,不同的颜色可以区分不同的类别或数值范围。这种直观性使得用户能够快速识别数据中的关键信息。
-
适合复杂数据的可视化:当数据集包含多个变量且变量之间存在复杂的相互关系时,气泡图是一个很好的选择。例如,在分析不同国家的经济发展水平时,可以将人均GDP(X轴)、通货膨胀率(Y轴)、人口规模(气泡大小)和经济发展阶段(气泡颜色)同时展示在一个图中。
-
可扩展性强:气泡图可以通过添加更多的维度(如气泡的透明度、形状等)来进一步丰富数据的表达。例如,透明度可以表示数据的不确定性或置信区间。
3.应用场景
-
商业分析
-
市场分析:分析不同产品或品牌的市场表现。例如,X轴表示市场份额,Y轴表示利润率,气泡大小表示销售额,气泡颜色表示产品类别。通过这种图表,企业可以快速识别哪些产品在市场上表现良好,哪些产品需要改进。
-
客户细分:根据客户的消费行为和特征进行细分。例如,X轴表示客户的购买频率,Y轴表示客户的平均消费金额,气泡大小表示客户的总消费金额,气泡颜色表示客户类型(如新客户、忠诚客户等)。这有助于企业制定针对性的营销策略。
-
-
经济和金融领域
-
股票分析:分析不同股票的收益和风险。例如,X轴表示股票的收益率,Y轴表示股票的风险(如标准差),气泡大小表示股票的市值,气泡颜色表示行业类别。投资者可以通过这种图表快速识别高收益低风险的股票。
-
经济指标分析:分析不同国家或地区的经济指标。例如,X轴表示GDP增长率,Y轴表示失业率,气泡大小表示人口规模,气泡颜色表示地区(如亚洲、欧洲等)。这有助于经济学家分析不同地区的经济状况和发展趋势。
-
-
社会科学研究
-
人口健康研究:分析不同地区的人口健康指标。例如,X轴表示人均寿命,Y轴表示医疗支出占GDP的比例,气泡大小表示人口规模,气泡颜色表示地区。这有助于研究者了解医疗支出与人口健康之间的关系。
-
教育研究:分析不同学校的教育质量。例如,X轴表示学校的平均成绩,Y轴表示学校的师资力量(如教师学历比例),气泡大小表示学校的规模,气泡颜色表示学校的类型(如公立、私立)。这有助于教育部门评估不同学校的教育水平。
-
-
地理和环境科学
-
环境质量分析:分析不同地区的环境质量。例如,X轴表示空气质量指数,Y轴表示水质污染指数,气泡大小表示地区的人口密度,气泡颜色表示地区类型(如城市、农村)。这有助于环保部门识别污染严重的地区并采取措施。
-
自然资源分布:分析不同地区的自然资源分布情况。例如,X轴表示矿产资源储量,Y轴表示水资源储量,气泡大小表示地区的面积,气泡颜色表示地区的经济水平。这有助于资源管理部门合理规划资源开发和利用。
-
4.代码实现
1 import matplotlib.pyplot as plt 2 import numpy as np 3 import pandas as pd 4 5 # 设置 Matplotlib 支持中文显示 6 plt.rcParams['font.sans-serif'] = ['SimHei'] # 指定中文字体为黑体 7 plt.rcParams['axes.unicode_minus'] = False # 正确显示负号 8 9 # 生成随机数据 10 np.random.seed(0) 11 data = { 12 '销售额': np.random.randint(100, 1000, size=50), # 随机生成销售额 13 '利润': np.random.randint(10, 200, size=50), # 随机生成利润 14 '销售量': np.random.randint(10, 100, size=50), # 随机生成销售量 15 '地区': np.random.choice(['北区', '南区', '东区', '西区'], size=50), # 随机生成地区 16 '产品类别': np.random.choice(['A', 'B', 'C', 'D'], size=50) # 随机生成产品类别 17 } 18 19 # 将数据转换为DataFrame 20 df = pd.DataFrame(data) 21 22 # 定义颜色映射 23 color_map = { 24 '北区': 'blue', 25 '南区': 'green', 26 '东区': 'red', 27 '西区': 'purple' 28 } 29 30 # 根据地区为每个点分配颜色 31 df['颜色'] = df['地区'].map(color_map) 32 33 # 绘制气泡图 34 plt.figure(figsize=(12, 8)) 35 36 # 使用散点图绘制气泡图 37 # s参数控制气泡大小,c参数控制气泡颜色 38 scatter = plt.scatter( 39 df['销售额'], # X轴数据 40 df['利润'], # Y轴数据 41 s=df['销售量'] * 10, # 气泡大小(销售量乘以一个系数,使气泡大小更明显) 42 c=df['颜色'], # 气泡颜色 43 alpha=0.7, # 透明度 44 edgecolors='w', # 气泡边缘颜色 45 label=df['产品类别'] # 分类标签 46 ) 47 48 # 添加标题和标签 49 plt.title('气泡图示例:销售额、利润、销售量和地区的分析', fontsize=16) 50 plt.xlabel('销售额', fontsize=14) 51 plt.ylabel('利润', fontsize=14) 52 53 # 添加颜色图例 54 # 由于颜色表示地区,我们手动添加图例 55 legend_labels = list(color_map.keys()) 56 legend_colors = list(color_map.values()) 57 legend_handles = [plt.Line2D([0], [0], marker='o', color='w', label=label, 58 markerfacecolor=color, markersize=10) 59 for label, color in zip(legend_labels, legend_colors)] 60 plt.legend(handles=legend_handles, title='地区') 61 62 # 添加网格线 63 plt.grid(True) 64 65 # 显示图形 66 plt.show()
三、相关图
1.概念
相关图(Correlation Plot)是一种用于展示变量之间相关性强度和方向的可视化工具。它通常以矩阵的形式呈现,每个单元格表示两个变量之间的相关系数(通常是皮尔逊相关系数),并通过颜色或符号的强度来表示相关性的强弱。相关图主要用于分析多个变量之间的线性关系。
2.特点
-
直观展示变量间的相关性:相关图通过颜色或符号的深浅来直观地表示变量之间的相关性强度。颜色越深(或符号越大),表示相关性越强。例如,红色可能表示正相关,蓝色表示负相关,颜色的深浅则表示相关系数的绝对值大小。
-
矩阵形式便于比较:相关图通常以矩阵形式呈现,矩阵的对角线上的单元格表示变量与自身的相关性(通常为1),其他单元格表示不同变量之间的相关性。这种矩阵形式使得用户可以快速比较多个变量之间的关系。
-
快速识别关键变量:通过相关图,可以快速识别出哪些变量之间存在强相关性,从而帮助分析者聚焦于重要的变量组合。这对于数据探索和特征选择非常有帮助。
-
支持多种相关性度量:相关图不仅可以展示皮尔逊相关系数(用于线性关系),还可以展示斯皮尔曼相关系数(用于非线性关系)或其他相关性度量指标,从而适应不同类型的数据。
3.应用场景
-
数据分析和数据探索
-
在数据预处理阶段,相关图可以帮助分析者快速了解数据集中各个变量之间的关系。例如,在一个包含多个经济指标的数据集中,通过相关图可以发现哪些指标之间存在强相关性,从而为后续的模型构建提供依据。
-
-
特征选择
-
在机器学习中,相关图可以帮助识别冗余特征。如果两个特征之间存在非常高的相关性(接近1或-1),则可以考虑去除其中一个特征,以避免多重共线性问题,提高模型的稳定性和解释性。
-
-
金融分析
-
在金融市场中,相关图可以用于分析不同资产之间的相关性。例如,通过分析股票、债券、大宗商品等资产之间的相关性,投资者可以构建多元化的投资组合,降低风险。
-
-
社会科学和心理学研究
-
在社会科学研究中,相关图可以用于分析不同社会现象之间的关系。例如,研究教育水平、收入水平、健康状况等变量之间的相关性,帮助研究者发现潜在的社会问题和因果关系。
-
-
生物医学研究
-
在生物医学领域,相关图可以用于分析基因表达数据、蛋白质相互作用等。例如,通过分析不同基因之间的表达相关性,可以发现基因网络中的关键基因和通路。
-
-
市场研究
-
在市场研究中,相关图可以用于分析消费者行为数据。例如,分析不同产品特征与消费者满意度之间的相关性,帮助企业优化产品设计和营销策略。
-
4.代码实现
1 import pandas as pd 2 import numpy as np 3 import matplotlib.pyplot as plt 4 import seaborn as sns 5 import matplotlib.font_manager as fm 6 import warnings 7 8 # 设置 Matplotlib 支持中文显示 9 plt.rcParams['font.sans-serif'] = ['SimHei'] # 指定中文字体为黑体 10 plt.rcParams['axes.unicode_minus'] = False # 正确显示负号 11 12 # 过滤seaborn相关的FutureWarning,避免控制台刷屏 13 warnings.filterwarnings("ignore", category=FutureWarning, module="seaborn") 14 15 def generate_sample_data(n=100): 16 """生成示例数据,包含收入、年龄等字段""" 17 np.random.seed(42) 18 return pd.DataFrame({ 19 '收入': np.random.normal(5000, 1000, n), 20 '年龄': np.random.normal(35, 10, n), 21 '工作年限': np.random.normal(8, 4, n), 22 '支出': np.random.normal(4000, 800, n), 23 '存款': np.random.normal(50000, 20000, n) 24 }) 25 26 def plot_correlation_heatmap(data, method='pearson', annot=True, figsize=(8, 6)): 27 """绘制相关系数热力图,调整为更紧凑尺寸""" 28 # 处理异常值,替换inf为NaN并删除含NaN的行 29 data = data.replace([np.inf, -np.inf], np.nan).dropna() 30 corr_matrix = data.corr(method=method) 31 32 plt.figure(figsize=figsize) 33 sns.heatmap( 34 corr_matrix, annot=annot, cmap='coolwarm', 35 square=True, linewidths=.5, vmin=-1, vmax=1 36 ) 37 plt.title(f'{method.capitalize()}相关系数热力图', fontsize=15) 38 plt.tight_layout() # 自动优化布局 39 plt.show() 40 def plot_pairwise_correlation(data, vars=None, kind='scatter', diag_kind='kde', figsize=(8, 6)): 41 data = data.replace([np.inf, -np.inf], np.nan).dropna() 42 43 # 用seaborn的pairplot绘图,同时获取绘图对象g 44 g = sns.pairplot( 45 data, vars=vars, kind=kind, diag_kind=diag_kind, 46 plot_kws={'s': 20, 'alpha': 0.6} # 缩小散点大小,让点更清晰 47 ) 48 49 # 优化布局:减小子图之间的间距 50 g.fig.subplots_adjust( 51 left=0.08, right=0.98, 52 top=0.85, # 增大顶部空间,为标题留出更多位置 53 bottom=0.1, 54 wspace=0.2, 55 hspace=0.2 # 调整水平和垂直间距 56 ) 57 58 # 设置标题,调整位置和字体大小,避免挤压 59 g.fig.suptitle('变量间成对关系图', fontsize=15, y=0.98) # 调整标题的垂直位置 60 61 # 遍历子图,调整坐标轴字体大小,让坐标轴更清晰 62 for ax in g.axes.flatten(): 63 ax.tick_params(labelsize=10) 64 plt.show() 65 66 if __name__ == "__main__": 67 df = generate_sample_data() 68 plot_correlation_heatmap(df) 69 plot_pairwise_correlation(df)
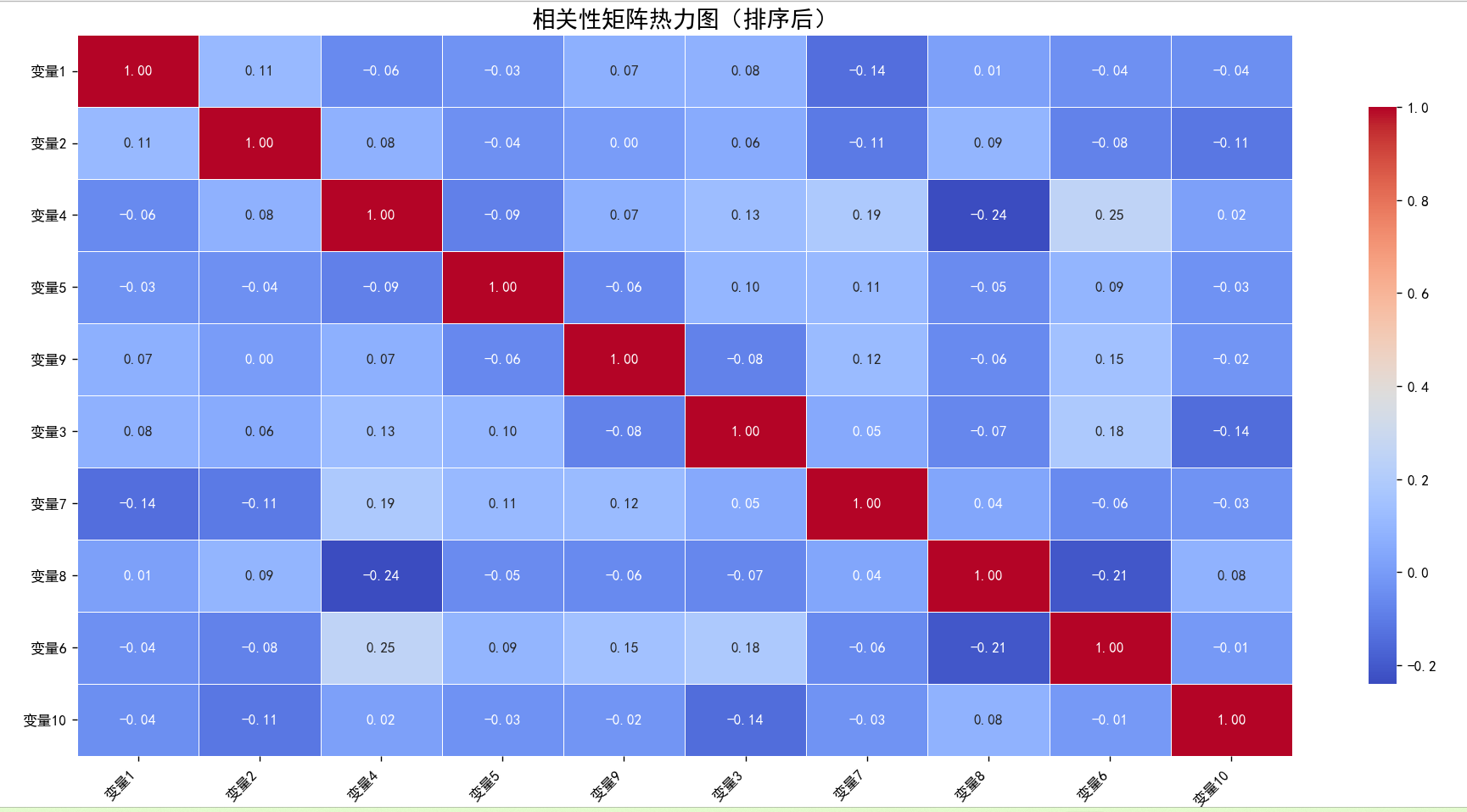
四、热力图
1.概念
热力图(Heatmap)是一种通过颜色的变化来表示数据大小或强度的可视化图表。它通常以矩阵或表格的形式呈现,每个单元格的颜色深浅表示该单元格对应数据的大小。热力图的核心在于利用颜色的视觉差异来直观地展示数据的分布和变化趋势。
2.特点
-
直观性强:热力图通过颜色的变化直观地展示数据的大小和分布情况。颜色通常从浅到深(或从冷色调到暖色调)表示数据值从小到大的变化。例如,浅蓝色表示较低的数值,深红色表示较高的数值,这种直观性使得用户可以快速识别数据中的热点区域。
-
适合大规模数据展示:热力图能够有效地处理大规模数据集,尤其是在数据量较大且需要快速识别模式时。例如,在地理信息系统(GIS)中,热力图可以展示人口密度、交通流量等数据,帮助用户快速识别高密度或高流量区域。
-
多维度数据可视化:热力图可以同时展示多个维度的数据。例如,在一个矩阵热力图中,行和列可以分别表示不同的变量,单元格的颜色表示这两个变量之间的某种度量(如相关性、频率等)。这种多维度的展示方式使得热力图在复杂数据可视化中非常有用。
-
灵活的颜色编码:热力图可以根据数据的性质和分析需求选择不同的颜色编码方案。例如,对于温度数据,可以使用从蓝色(低温)到红色(高温)的颜色渐变;对于人口密度数据,可以使用从浅黄色到深绿色的颜色渐变。这种灵活性使得热力图能够适应各种应用场景。
3.应用场景
-
地理信息系统(GIS)
-
人口密度分析:通过热力图展示某个地区的人口密度分布,帮助城市规划者识别高密度区域,以便合理规划基础设施和公共服务。
-
交通流量分析:在交通管理中,热力图可以展示道路的交通流量,帮助交通部门识别拥堵区域,优化交通信号灯设置或规划新的交通线路。
-
犯罪率分析:警察部门可以使用热力图展示犯罪事件的发生频率,识别高犯罪率区域,从而有针对性地部署警力。
-
-
生物医学研究
-
基因表达分析:在基因组学中,热力图可以展示不同样本中基因的表达水平,帮助研究人员识别基因表达的模式和差异,发现潜在的生物标志物。
-
蛋白质相互作用网络:通过热力图展示蛋白质之间的相互作用强度,帮助研究人员理解蛋白质网络的结构和功能。
-
-
商业和市场分析
-
销售数据分析:企业可以使用热力图展示不同地区或不同时间段的销售数据,识别销售热点区域或时间段,从而优化营销策略。
-
客户行为分析:通过热力图展示客户在网站上的点击行为或购买行为,帮助企业了解客户偏好,优化网站布局或产品推荐。
-
-
气象和环境科学
-
温度分布:在气象学中,热力图可以展示地面温度或大气温度的分布,帮助气象学家分析天气模式和气候变化。
-
污染分布:环境科学家可以使用热力图展示空气污染或水质污染的分布,识别污染源和高污染区域,制定相应的治理措施。
-
-
社会科学
-
社会网络分析:在社会科学研究中,热力图可以展示人与人之间的关系强度或互动频率,帮助研究者分析社会网络的结构和动态。
-
投票行为分析:通过热力图展示不同地区或群体的投票行为,帮助政治学家分析选举结果和选民偏好。
-
-
软件开发和用户体验
-
用户界面分析:通过热力图展示用户在软件或网站界面上的操作行为(如鼠标点击、停留时间等),帮助开发人员优化界面设计,提升用户体验。
-
系统性能分析:在软件性能测试中,热力图可以展示系统的资源使用情况(如CPU、内存等),帮助开发人员识别性能瓶颈。
-
4.代码实现
1 import numpy as np 2 import pandas as pd 3 import seaborn as sns 4 import matplotlib.pyplot as plt 5 from sklearn.cluster import SpectralClustering 6 7 # 设置 Matplotlib 支持中文显示 8 plt.rcParams['font.sans-serif'] = ['SimHei'] # 指定中文字体为黑体 9 plt.rcParams['axes.unicode_minus'] = False # 正确显示负号 10 11 # 生成随机数据 12 np.random.seed(0) 13 data = { 14 '变量1': np.random.randn(100), 15 '变量2': np.random.randn(100), 16 '变量3': np.random.randn(100), 17 '变量4': np.random.randn(100), 18 '变量5': np.random.randn(100), 19 '变量6': np.random.randn(100), 20 '变量7': np.random.randn(100), 21 '变量8': np.random.randn(100), 22 '变量9': np.random.randn(100), 23 '变量10': np.random.randn(100) 24 } 25 26 # 将数据转换为DataFrame 27 df = pd.DataFrame(data) 28 29 # 计算相关性矩阵 30 corr_matrix = df.corr() 31 32 # 使用谱聚类方法对行和列进行排序 33 # 注意:将affinity设置为'precomputed',因为corr_matrix是一个预计算的亲和性矩阵 34 sc = SpectralClustering(n_clusters=3, affinity='precomputed', random_state=0) 35 clusters = sc.fit_predict(1 - corr_matrix.abs()) # 使用1 - abs(corr_matrix)作为距离矩阵 36 37 # 按照聚类结果对行和列进行排序 38 sorted_indices = np.argsort(clusters) 39 sorted_corr_matrix = corr_matrix.iloc[sorted_indices, sorted_indices] 40 41 # 绘制热力图 42 plt.figure(figsize=(12, 10)) 43 sns.heatmap( 44 sorted_corr_matrix, 45 annot=True, # 显示每个单元格的数值 46 cmap='coolwarm', # 使用冷暖色系 47 fmt=".2f", # 数值格式 48 linewidths=.5, # 单元格之间的分隔线宽度 49 cbar_kws={"shrink": .8}, # 调整颜色条的大小 50 xticklabels=sorted_corr_matrix.columns, # X轴标签 51 yticklabels=sorted_corr_matrix.columns # Y轴标签 52 ) 53 54 # 添加标题和标签 55 plt.title('相关性矩阵热力图(排序后)', fontsize=16) 56 plt.xticks(rotation=45, ha='right') # 旋转X轴标签以便更好地显示 57 plt.yticks(rotation=0) # Y轴标签保持水平 58 plt.tight_layout() # 调整布局以防止标签被截断 59 60 # 显示图形 61 plt.show()
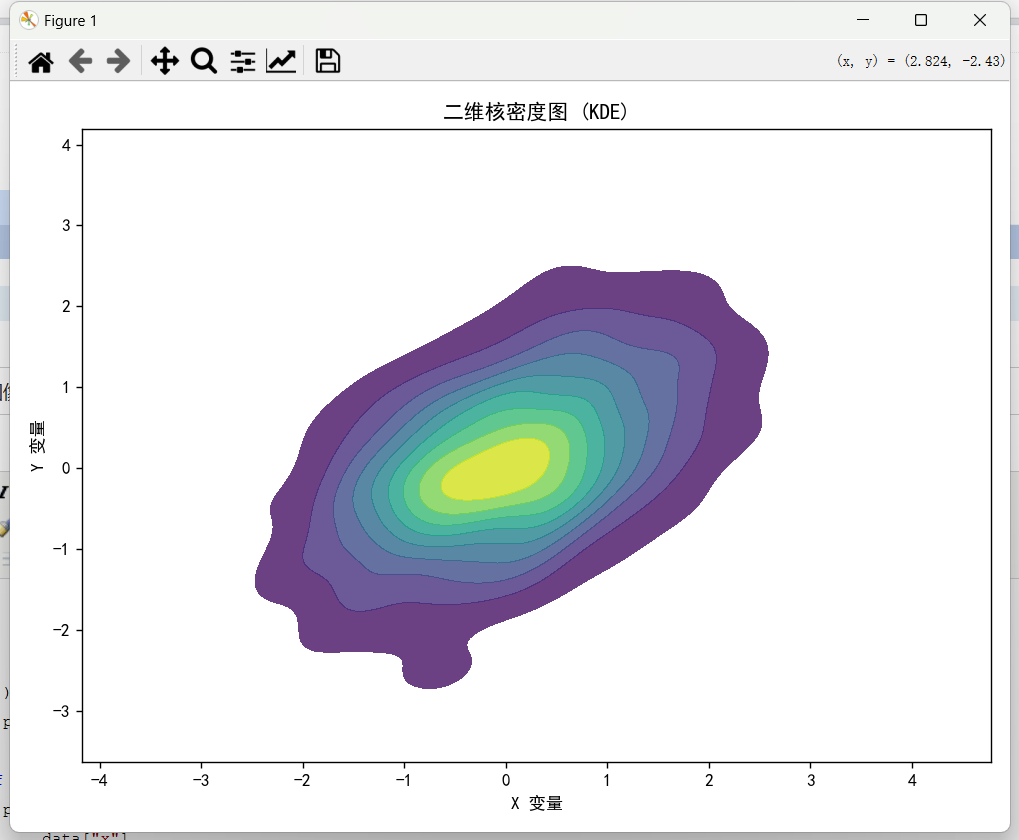
五、二维密度图
1.概念
二维密度图(2D Density Plot)是一种用于展示两个变量之间联合分布密度的可视化工具。它通过颜色或等高线的形式来表示两个变量同时出现的频率或概率密度。二维密度图本质上是对散点图的扩展,但它不仅仅是简单地展示数据点,而是通过平滑或聚合的方式,更直观地展示数据的分布形态。
2.特点
-
直观展示联合分布:二维密度图能够直观地展示两个变量的联合分布情况。与散点图相比,它避免了数据点过于密集导致的视觉混乱问题,通过颜色或等高线的形式清晰地展示数据的密度分布。
-
平滑处理数据:二维密度图通常会对数据进行平滑处理(如使用核密度估计KDE),从而生成连续的密度曲面。这种平滑处理使得数据的分布更加清晰,能够更好地反映数据的整体趋势和模式。
-
突出密度变化:二维密度图通过颜色的深浅或等高线的密集程度来表示密度的高低。颜色越深或等高线越密集,表示该区域的数据点越多,密度越高。这种可视化方式能够帮助用户快速识别数据的热点区域。
-
灵活的可视化形式:二维密度图可以以多种形式呈现,包括填充颜色的密度图(heatmap形式)、等高线图(contour plot)或两者的结合。用户可以根据具体需求选择最适合的可视化方式。
3.应用场景
-
统计分析
-
探索数据分布:在数据探索阶段,二维密度图可以帮助分析者快速了解两个变量之间的联合分布情况。例如,在研究身高和体重的关系时,通过二维密度图可以直观地看到数据的分布形态,判断是否存在某种模式或趋势。
-
识别异常值:通过观察密度图中的低密度区域或孤立的高密度区域,可以发现数据中的异常值或异常模式。
-
-
生物医学研究
-
基因表达分析:在基因组学中,二维密度图可以用来展示两个基因表达水平的联合分布,帮助研究人员分析基因之间的协同表达模式。
-
临床数据研究:在临床研究中,二维密度图可以用于展示患者的两个生理指标(如血压和血糖)的联合分布,帮助医生识别潜在的健康风险。
-
-
金融分析
-
资产相关性分析:在金融市场中,二维密度图可以用来展示不同资产之间的价格波动联合分布,帮助投资者评估资产组合的风险和相关性。
-
风险评估:通过分析金融指标(如利率和汇率)的联合分布,金融机构可以更好地评估市场风险。
-
-
地理信息系统(GIS)
-
空间数据分布:在地理分析中,二维密度图可以用来展示地理空间数据的分布,例如人口密度、交通流量等。通过颜色或等高线的形式,可以直观地识别出高密度区域。
-
环境数据监测:在环境科学中,二维密度图可以用来展示污染物浓度的分布,帮助研究人员识别污染源和高污染区域。
-
-
市场研究
-
消费者行为分析:在市场分析中,二维密度图可以用来展示消费者的两个行为指标(如购买频率和购买金额)的联合分布,帮助企业了解消费者行为模式。
-
市场细分:通过二维密度图,企业可以识别不同市场细分群体的行为特征,从而制定更有针对性的营销策略。
-
-
气象和气候研究
-
气象数据分布:在气象学中,二维密度图可以用来展示气象变量(如温度和湿度)的联合分布,帮助气象学家分析天气模式和气候变化。
-
气候模型验证:通过将观测数据与模型预测结果的二维密度图进行对比,可以验证气候模型的准确性。
-
4.代码实现
1 import numpy as np 2 import pandas as pd 3 import seaborn as sns 4 import matplotlib.pyplot as plt 5 import warnings 6 7 # 设置 Matplotlib 支持中文显示 8 plt.rcParams['font.sans-serif'] = ['SimHei'] # 指定中文字体为黑体 9 plt.rcParams['axes.unicode_minus'] = False # 正确显示负号 10 # 过滤FutureWarning警告 11 warnings.filterwarnings("ignore", category=FutureWarning) 12 13 def generate_data(): 14 np.random.seed(42) 15 x = np.random.normal(0, 1, 1000) 16 y = 0.5 * x + np.random.normal(0, 0.8, 1000) 17 return pd.DataFrame({"x": x, "y": y}) 18 19 def plot_2d_density(data, method="kde", cmap="viridis"): 20 plt.figure(figsize=(8, 6)) 21 22 # 数据预处理 23 data = data.replace([np.inf, -np.inf], np.nan).dropna() 24 25 if method == "kde": 26 sns.kdeplot( 27 data=data, 28 x="x", 29 y="y", 30 fill=True, 31 cmap=cmap, 32 alpha=0.8, 33 levels=10, 34 ) 35 plt.title("二维核密度图 (KDE)") 36 37 elif method == "hex": 38 plt.hexbin( 39 data["x"], 40 data["y"], 41 gridsize=20, 42 cmap=cmap, 43 edgecolors="w", 44 ) 45 plt.colorbar(label="密度") 46 plt.title("二维六边形分箱密度图 (Hexbin)") 47 48 else: 49 raise ValueError("method 仅支持 'kde' 或 'hex'") 50 51 plt.xlabel("X 变量") 52 plt.ylabel("Y 变量") 53 plt.tight_layout() 54 plt.show() 55 56 if __name__ == "__main__": 57 df = generate_data() 58 plot_2d_density(df, method="kde", cmap="viridis")
六、总结
|
图表类型 |
特点 |
优点 |
缺点 |
应用场景 |
|---|---|---|---|---|
|
散点图 |
以平面直角坐标系中点的坐标(x、y值),直观呈现两个连续变量的关系,如线性 / 非线性相关、分布趋势 |
简单直观,能清晰展示变量间关联趋势;可发现异常点;适配基础数据分析场景 |
数据点过多易重叠,掩盖分布细节;仅直接呈现二维关系,多变量需额外处理 |
分析两变量关联(如身高与体重、广告投入与销量);识别数据分布模式(聚类、离散等) |
|
气泡图 |
在散点图基础上,用气泡大小表示第三个变量,颜色还可拓展第四变量信息 |
在散点图优势上,增加维度展示,同屏呈现多变量关联 |
维度过多时,气泡易重叠、布局混乱;大小 / 颜色编码的变量,数值感知易有偏差 |
市场分析(销售额、利润、市场份额关联);城市数据(人口、GDP、面积对应关系);多指标的样本对比(如产品销量、利润率、客户满意度) |
|
相关图(相关系数矩阵可视化) |
展示多个变量间相关系数矩阵,以数值、颜色等表示相关强度(绝对值大小)和方向(正负) |
清晰呈现多变量间整体相关格局,便于快速找强相关关系 |
仅体现线性相关程度,难展示非线性关联;系数计算依赖数据分布,异常值影响大 |
金融资产相关性分析(优化投资组合);生物学基因表达关联研究;市场营销(客户特征与购买行为相关挖掘);机器学习特征选择(筛除高相关特征) |
|
热力图 |
用颜色矩阵展示数据值大小,直观呈现二维数据的分布模式、热点区域 |
视觉冲击力强,快速定位数据 “热点”“冷点”;适配矩阵类数据、二维分布场景 |
数值精度展示弱,仅看趋势;颜色映射需谨慎调试,否则易误导解读 |
基因表达数据(不同基因、样本的表达量分布);时间序列数据(如年度各月销售热力分布);用户行为点击数据(网页板块关注度);矩阵数据可视化(混淆矩阵、距离矩阵等) |
|
二维密度图 |
通过颜色或等高线展示二维数据的分布密度,突出数据聚类、密度趋势,适配大数据量 |
解决散点图数据重叠问题,清晰呈现数据密度分布;识别隐含的聚类、分布形态 |
抽象度高,对参数(如核函数、网格精度)敏感;难精准对应原始数据点 |
金融数据(股价、成交量的分布密度关联);空间数据(地理经纬度、人口密度分布);生物数据(实验样本二维指标的密度聚类);大数据量下的双变量分布分析 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号