

文本数据可视化
实验名称
文本数据可视化
实验目的
1. 了解什么是文本可视化
2. 掌握文本可视化的相关技术
3. 文本信息的提取和可视表达
4. 本次实验是将某一文本进行可视化生成词云图片
5. 尝试构造文本指纹
实验原理
文本是语言和沟通的载体,文本的含义以及读者对文本的理解需求均纷繁复杂。例如,对于同一个文本,不同的人的解读也是不一样的,有的人希望了解文本中涉及到的事物,而有的人希望得到文本中的关键词。鉴于对文本信息需求的多样性,需要从不同层级提取与呈现文本信息。一般把对文本的理解 需 求 分 成 三 级 : 词 汇 级 ( Lexical Level ) 、 语 法 级(Syntactic Level)和语义级(Semantic Level)。不同级的信息挖掘方法也不同,词汇级当然是用各类分词算法,语法级用一些句法分析算法,语义级用主题抽取算法。文本文档的类别多种多样,包括单文本、文档集合和时序文本数据三大类,这使得文本信息的需求更为丰富。
实验环境
Python:v3.6
实验步骤
1、读入txt文本数据数据来源:实验-第六章文件夹,千千阙歌-歌词.txt

2、安装matplotlib、jieba、wordcloud
3、编写代码,构造不同形状的词云。
提示:
(1)读入 txt 文本数据
(2)结巴中文分词,生成字符串,默认精确模式,如果不通过分词,无法直接生成正确的中文词云
(3)生成词云图,需要注意的是 WordCloud 默认不支持中文,所以这里需已下载好的中文字库
- 词云图
1 import jieba 2 from wordcloud import WordCloud 3 import matplotlib.pyplot as plt 4 5 # 读取文本数据 6 with open('千千阙歌-歌词.txt', 'r', encoding='utf-8') as file: 7 text = file.read() 8 9 # 使用结巴中文分词 10 seg_list = jieba.cut(text, cut_all=False) 11 seg_text = ' '.join(seg_list) 12 13 # 设置中文字体路径 14 font_path = 'simkai.ttf' 15 16 # 生成词云图 17 wordcloud = WordCloud(font_path=font_path, width=800, height=400, background_color='white').generate(seg_text) 18 19 # 显示词云图 20 plt.imshow(wordcloud, interpolation='bilinear') 21 plt.axis('off') # 关闭坐标轴 22 plt.show() 23 24 # 保存词云图 25 wordcloud.to_file('wordcloud.png')

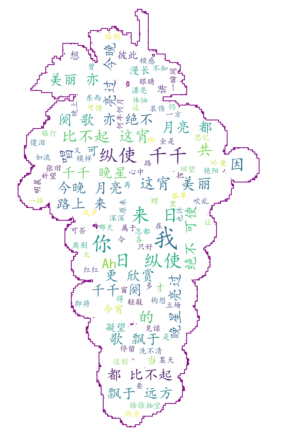
- 修改形状的词云图
1 import jieba 2 import numpy as np 3 from PIL import Image 4 import matplotlib.pyplot as plt 5 from wordcloud import WordCloud, ImageColorGenerator 6 7 # 读取文本数据 8 with open('千千阙歌-歌词.txt', 'r', encoding='utf-8') as file: 9 text = file.read() 10 11 # 使用结巴中文分词 12 seg_list = jieba.cut(text, cut_all=False) 13 seg_text = ' '.join(seg_list) 14 15 # 设置中文字体路径 16 font_path = 'simkai.ttf' 17 18 # 读取形状掩码图像 19 mask_image = np.array(Image.open('葡萄.png')) # 替换为你的形状掩码图像文件 20 21 # 生成词云图 22 wordcloud = WordCloud(font_path=font_path, width=800, height=400, background_color='white', mask=mask_image, max_font_size=100).generate(seg_text) 23 # 生成颜色映射 24 image_colors = ImageColorGenerator(mask_image) 25 26 # 显示词云图 27 plt.imshow(wordcloud.recolor(color_func=image_colors), interpolation='bilinear') 28 plt.axis('off') # 关闭坐标轴 29 plt.show() 30 31 # 保存词云图 32 wordcloud.to_file('wordcloud_shape.png')
4、文献指纹练习(Literature Fingerprinting)
数据来源:实验-第六章文件夹,《师说》-韩愈.txt,尝试构造该文本内容的文献指纹。
要求:将操作步骤逐一展示,描述背后的原理。内容要求有层次有逻辑。
(1)初始化与文本加载
操作步骤:
创建 LiteratureFingerprint 类的实例,传入文本文件路径(如 《师说》-韩愈.txt)。
调用 _load_text 方法加载文本内容。
调用 _preprocess_text 方法对文本进行预处理。
原理: _load_text 方法:读取文本文件内容,确保文件编码为 UTF-8。 preprocess_text 方法:对文本进行清洗,保留中文字符和古文标点(如“,”“。”“;”等),去除其他无关字符。
相关代码:
1 class LiteratureFingerprint: 2 def __init__(self, file_path): 3 self.file_path = file_path 4 self.text = self._load_text() 5 self.processed_text = self._preprocess_text()
(2)文本预处理
使用正则表达式去除文本中的非中文字符和非古文标点符号。
保留的字符包括中文字符(\u4e00-\u9fa5)和古文标点(如“,”“。”“;”等)。
原理:
正则表达式 [^\u4e00-\u9fa5。,、;:「」『』()] 匹配所有非中文字符和非古文标点的字符,并将其替换为空字符串。
这一步是为了减少噪声,确保后续分析的准确性。
相关代码:
1 def _preprocess_text(self): 2 cleaned_text = re.sub(r'[^\u4e00-\u9fa5。,、;:「」『』()]', '', self.text) 3 return cleaned_text
(3)特征提取
- 词频特征的操作步骤及原理
操作步骤:
使用 jieba.lcut 对预处理后的文本进行分词。
过滤掉停用词(如“之”“乎”“者”等)和单字词。
统计词频,并提取频率最高的前 top_n 个词。
原理:
分词:中文文本需要分词处理,因为中文是以词为基本单位的。
停用词过滤:停用词在文本中频繁出现但对语义贡献较小,去除停用词可以提高特征的有效性。
词频统计:通过 Counter 统计词频,提取高频词作为特征。
- n-gram 特征的操作步骤及原理
操作步骤:
jieba.lcut 对预处理后的文本进行分词。构造 n-gram 序列(默认为 2-gram)。
统计 n-gram 的频率,并提取频率最高的前 top_n 个。
原理:
n 个词作为一个特征单元,能够捕捉词序信息。 统计频率:通过 Counter 统计 n-gram 的频率,提取高频 n-gram 作为特征。
- 结构特征操作步骤及原理
计算每个段落的平均长度。
使用正则表达式匹配判断句(如“……者,……也”)的数量。
判断句匹配:通过正则表达式匹配特定的句式结构,捕捉文本的语言风格特征。
相关代码:
1 def _get_word_freq(self, top_n=20): 2 """获取词频特征""" 3 words = jieba.lcut(self.processed_text) 4 stopwords = ['之', '乎', '者', '也', '而', '其', '于', '曰'] 5 words = [w for w in words if w not in stopwords and len(w) > 1] 6 return Counter(words).most_common(top_n) 7 8 def _get_ngrams(self, n=2, top_n=10): 9 """获取n-gram特征""" 10 words = jieba.lcut(self.processed_text) 11 ngrams = [tuple(words[i:i + n]) for i in range(len(words) - n + 1)] 12 return Counter(ngrams).most_common(top_n) 13 14 def _get_structure_features(self): 15 """获取结构特征""" 16 paragraphs = [p for p in self.text.split('\n') if p.strip()] 17 avg_len = sum(len(p) for p in paragraphs) / len(paragraphs) if paragraphs else 0 18 pattern = r'[\u4e00-\u9fa5]+者,[\u4e00-\u9fa5]+也' 19 judgment_sentences = len(re.findall(pattern, self.processed_text)) 20 21 return { 22 'paragraph_count': len(paragraphs), 23 'avg_paragraph_length': round(avg_len, 2), 24 'judgment_sentences': judgment_sentences 25 }
(4)指纹生成
调用 _get_word_freq、_get_ngrams 和 _get_structure_features 方法,提取词频、n-gram 和结构特征。
将所有特征组合成一个字典。
使用 hashlib.sha256 对特征字典进行哈希编码,生成唯一的哈希 ID。
返回文献指纹,包含哈希 ID 和所有特征。
原理:
哈希编码:通过哈希算法将特征字典转换为一个唯一的哈希值,便于快速比较和存储。
指纹结构:指纹包含哈希 ID 和详细的特征信息,便于后续分析和比对。
相关代码:
1 def generate_fingerprint(self): 2 """生成文献指纹""" 3 features = { 4 'word_freq': self._get_word_freq(), 5 'bigrams': self._get_ngrams(n=2), 6 'structure': self._get_structure_features() 7 } 8 9 # 生成哈希ID 10 hash_obj = hashlib.sha256(json.dumps(features, ensure_ascii=False).encode('utf-8')) 11 fingerprint = { 12 'hash_id': hash_obj.hexdigest(), 13 'features': features 14 } 15 16 return fingerprint
(5)指纹显示
调用 generate_fingerprint 方法生成文献指纹。
打印指纹信息,包括哈希 ID 和所有特征。
原理:
格式化输出:将指纹信息以清晰的格式打印出来,便于查看和分析。
相关代码:
1 def display_fingerprint(self): 2 """打印指纹信息""" 3 fp = self.generate_fingerprint() 4 print("《师说》文献指纹") 5 print("=" * 50) 6 print(f"Hash ID: {fp['hash_id']}") 7 print("\n特征提取结果:") 8 9 print("\n1. 高频词汇:") 10 for word, freq in fp['features']['word_freq']: 11 print(f"{word}: {freq}", end=" | ") 12 13 print("\n\n2. 高频二元组:") 14 for ngram, freq in fp['features']['bigrams']: 15 print(f"{''.join(ngram)}: {freq}", end=" | ") 16 17 print("\n\n3. 结构特征:") 18 for k, v in fp['features']['structure'].items(): 19 print(f"{k}: {v}", end=" | ") 20 print("\n" + "=" * 50)
(6)实验结果
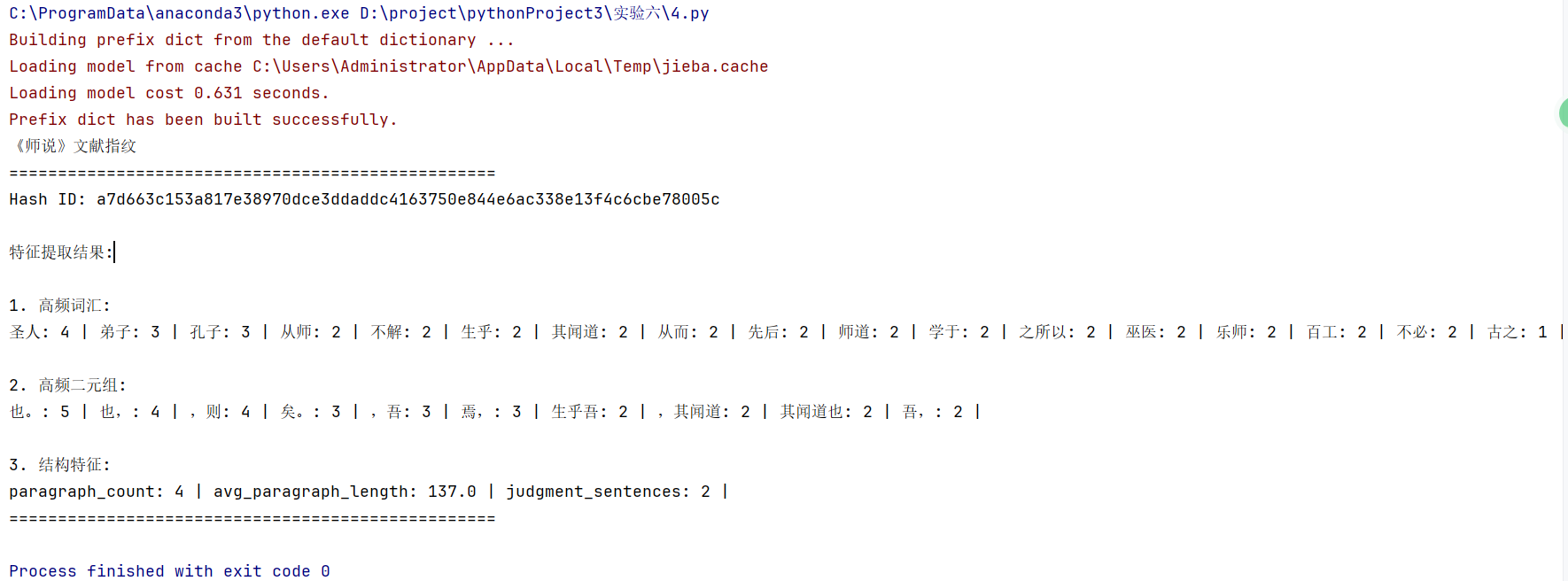
实验总结
本次实验以“文本数据可视化”为核心,通过具体案例系统实践了文本信息的提取、处理与可视化呈现。在词云生成环节,针对《千千阙歌》歌词,首先利用Python的`jieba`库进行精确分词,将歌词拆解为“今宵”“离别”“月亮”等高频词汇,避免单字堆砌;随后通过指定`simkai.ttf`中文字体路径,解决了`WordCloud`默认不支持中文的乱码问题;最后加载“葡萄.png”掩码图像并匹配颜色,使词云按特定轮廓分布且色彩协调,直观展现歌词的情感主题。在文献指纹构建部分,以《师说》为样本,通过自定义类完成全流程处理:先用正则表达式过滤非中文字符,保留“者,……也”等古文句式;再从词频(如“学者”“师道”)、2-gram(如“惑而”“从师”)和结构特征(段落数量、判断句频次)多维度提取文本特征;最后通过`hashlib.sha256`生成唯一哈希ID,形成包含内容与风格信息的文本“指纹”,可用于查重或风格比对。实验中解决了分词不精准、字体显示异常等问题,深化了对文本可视化三层需求(词汇级、语法级、语义级)的理解。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号